Challenge – Algonauts Project 2023 (original) (raw)

How the Human Brain Makes Sense of Natural Scenes
Challenge Overview
Understanding how the human brain works is one of the key challenges that science and society face. The Algonauts Challenge proposes a test of how well computational models do today. This test is intrinsically open andquantitative. This will allow us to precisely assess the progress in explaining the human brain.
At every blink our eyes are flooded by a massive array of photons—and yet, we perceive the visual world as ordered and meaningful. The primary target of the 2023 Challenge is predicting human brain responses to complex natural visual scenes, using the largest available brain dataset for this purpose.
Watching a visual scene activates large swathes of the human cortex. We pose the question: How well does your computational model account for these activations?
Watch the first video above for an introduction to the Algonauts 2023 Challenge and a detailed walkthrough of the development kit. When you are ready to participate, the second video will guide you through the CodaLab competition submission process.

Competition
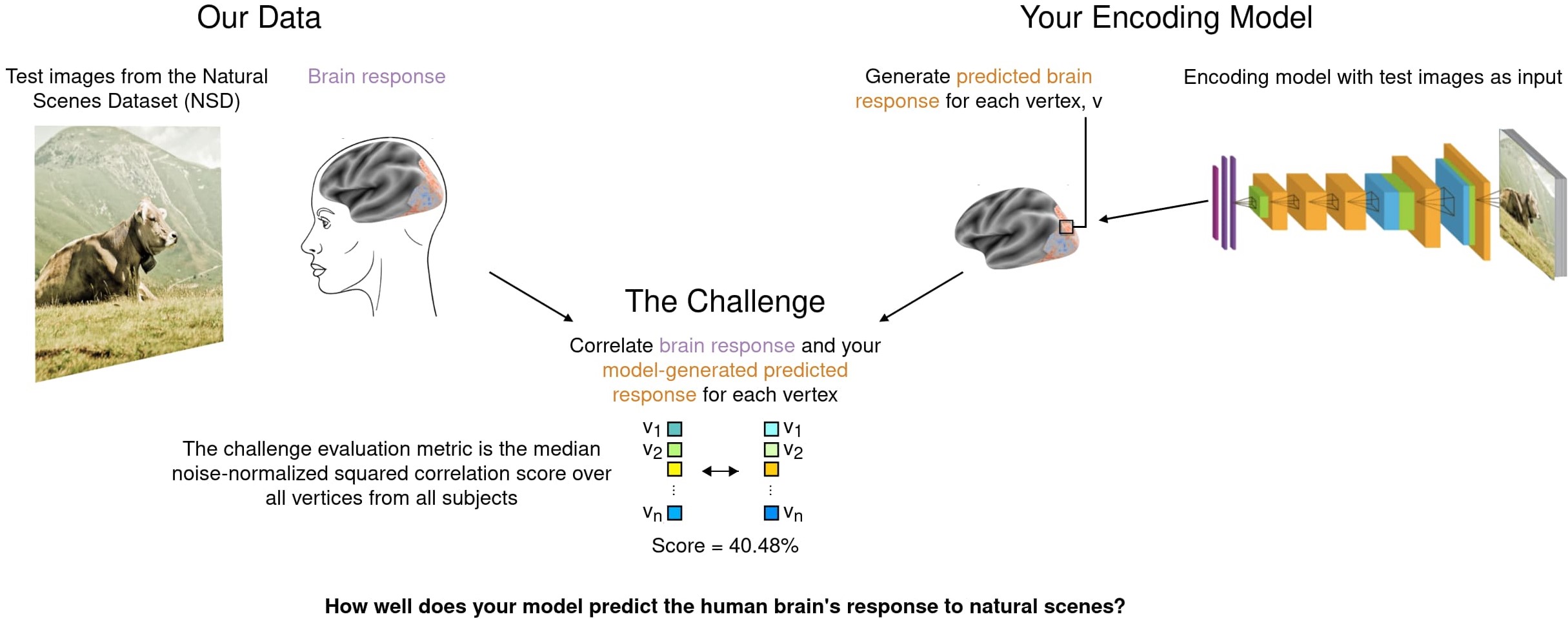
The main goal of the Algonauts Project 2023 Challenge is to use computational models to predict brain responses recorded while participants view complex natural visual scenes.
Current computational models in AI are parameter rich and data-hungry. We thus partner with the Natural Scenes Dataset (NSD) team to provide the largest available set of brain responses to complex natural scenes. The NSD provides brain responses from 8 human participants to in total 73,000 different visual scenes. The brain responses were measured with functional MRI.
Learn more about the stimuli and fMRI dataset used in the 2023 Challenge
The goal of the Challenge is to predict brain responses across the whole visual brain. That is where the most reliable responses to images were found.
We provide i) a set of images and ii) the corresponding brain responses recorded while human participants viewed those images. With that, participants are expected to build computational models to predict brain responses for images which brain data we held out.
Participants submit predicted responses (for the provided set of brain surface vertices) in the format described in the development kit. We score the submission by measuring the predictivity for each vertex in the selected set for all the subjects and display the overall mean predictivity in the leaderboard calculated across all vertices and all subjects.
Participate in the 2023 Challenge
Challenge Data
Download the data for the Algonauts Project 2023 Challenge
Train Data
- Images: For each of the 8 subjects there are [9841, 9841, 9082, 8779, 9841, 9082, 9841, 8779] different images (in '.png' format). As an example, the first training image of subject 1 is named 'train-0001_nsd-00013.png'. The first index ('train-0001') orders the images to match the stimulus images dimension of the fMRI train split data. This indexing starts from 1. The second index ('nsd-00013') corresponds to the 73,000 NSD image IDs that you can use to map the image back to the original '.hdf5' NSD image file (which contains all the 73,000 images used in the NSD experiment), and from there to the COCO dataset images for metadata). The 73,000 NSD images IDs in the filename start from 0, so that you can directly use them for indexing the '.hdf5' NSD images in Python. Note that the images used in the NSD experiment (and here in the Algonauts 2023 Challenge) are cropped versions of the original COCO images. Therefore, if you wish to use the COCO image metadata you first need to adapt it to the cropped image coordinates. You can find code to perform this operation here.
- fMRI: Along with the train images we share the corresponding fMRI visual responses (as '.npy' files) of both the left hemisphere ('lh_training_fmri.npy') and the right hemisphere ('rh_training_fmri.npy'). The fMRI data is z-scored within each NSD scan session and averaged across image repeats, resulting in 2D arrays with the number of images as rows and as columns a selection of the vertices that showed reliable responses to images during the NSD experiment. The left (LH) and right (RH) hemisphere files consist of, respectively, 19,004 and 20,544 vertices, with the exception of subjects 6 (18,978 LH and 20,220 RH vertices) and 8 (18,981 LH and 20,530 RH vertices) due to missing data.
Test Data
- Images: For each of the 8 subjects there are [159, 159, 293, 395, 159, 293, 159, 395] different images (in '.png' format). The file naming scheme is the same as for the train images.
- fMRI: The corresponding fMRI visual responses are not released.
Region-of-Interest (ROI) Indices
The visual cortex is divided into multiple areas having different functional properties, referred to as regions-of-interest (ROIs). Along with the fMRI data we provide ROI indices for selecting vertices belonging to specific visual ROIs, that Challenge participants can optionally use at their own discretion (e.g., to build different encoding models for functionally different regions of the visual cortex). However, the Challenge evaluation score is computed over all available vertices, and not over any single ROI. For the ROI definition please see the NSD paper. Note that not all ROIs exist in all subjects. Following is the list of ROIs provided (ROI class file names in parenthesis):
- Early retinotopic visual regions (prf-visualrois): V1v, V1d, V2v, V2d, V3v, V3d, hV4.
- Body-selective regions (floc-bodies): EBA, FBA-1, FBA-2, mTL-bodies.
- Face-selective regions (floc-faces): OFA, FFA-1, FFA-2, mTL-faces, aTL-faces.
- Place-selective regions (floc-places): OPA, PPA, RSC.
- Word-selective regions (floc-words): OWFA, VWFA-1, VWFA-2, mfs-words, mTL-words.
- Anatomical streams (streams): early, midventral, midlateral, midparietal, ventral, lateral, parietal.
ROIs surface plots. Visualizations of subject 1 ROIs on surface plots. Different ROIs are represented using different colors. The names of missing ROIs are left in black.
Development Kit
We provide a Colab tutorial in Python where we take you all the way from data input to Challenge submission. In particular, we show you how to:
- Load and visualize the fMRI data, its ROIs, and the corresponding image conditions.
- Build linearizing encoding models using a pretrained AlexNet architecture, evaluate them, and visualize the resulting prediction accuracy.
- Prepare the predicted brain responses to the test images in the right format for submission to the Challenge website.
Leaderboard
The Algonauts Project 2023 Challenge Leaderboard. The Challenge Score is the mean noise-normalized encoding accuracy of our held-out brain data across the vertices of all subjects and hemispheres (see details). View the leaderboard on CodaLab here.
Challenge Evaluation Metric
To determine how well your models encode brain responses (i.e., the models' encoding accuracy) we compare your submitted predicted brain data (the one predicted by your model to the left out test images) to the empirically measured brain responses. Specifically, we (1) correlate the predicted test fMRI data with the corresponding ground truth fMRI data (across image conditions, independently for each vertex), (2) square the correlation coefficients of each vertex, and (3) normalize the resulting value of each vertex by its noise ceiling. Your leaderboard ranking metric is determined by the mean noise-normalized encoding accuracy across all the vertices of all subjects and hemispheres:
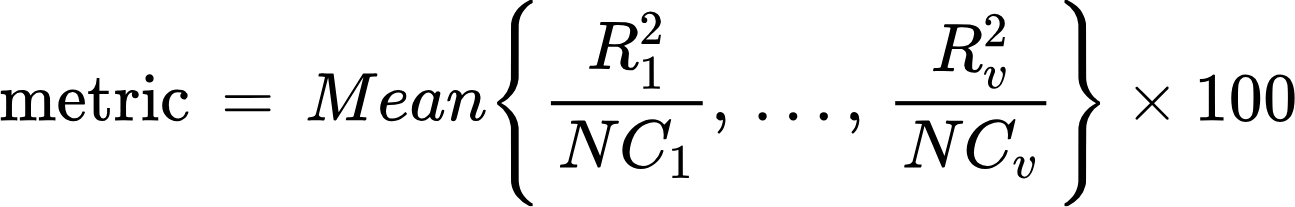
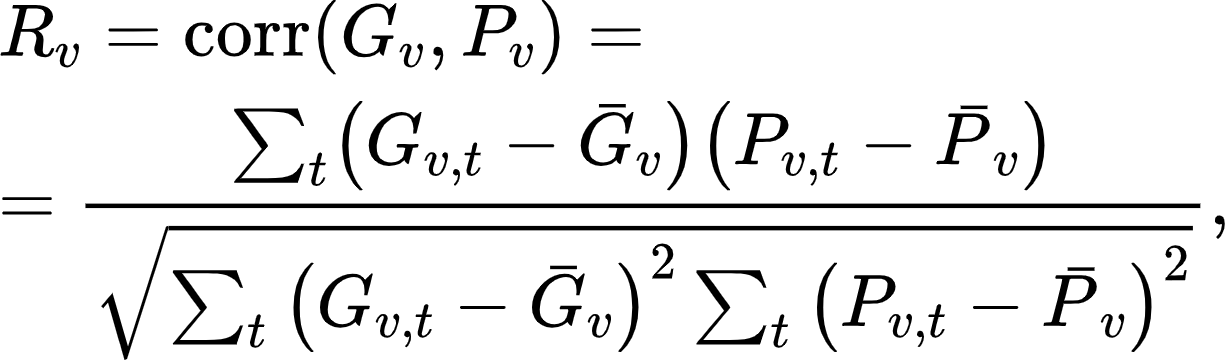
where ν is the index of vertices (over all subjects and hemispheres),t is the index of the test stimuli images, G and P correspond to, respectively, the ground truth and predicted fMRI test data, Ḡ and P̄ are the ground truth and predicted fMRI test data averaged across test stimuli images, R is the Pearson correlation coefficient between G and P, and NC is the noise ceiling.
How to Predict Brain Data Using Computational Models?
There are different ways to predict brain data using computational models. We put close to no restrictions on how you do so (see Challenge Rules). However, a commonly used approach is to use linearizing encoding models, and we provide a development kit to implement such a model.
Click here to learn more about linearizing encoding
Challenge Rules and Best Practices
1. Participants can make a maximum of 3 submissions per day and 250 submissions over the entire competition. Each challenge participant can only compete using one account. Creating multiple accounts to increase the number of possible submissions will result in disqualification to the challenge.
2. Participants can use any (external) data for model building and any model. However, participants that use the test set for training will be disqualified (in particular brain data generated using the test set). Also, if you ever had access to the fMRI test data you cannot participate in the challenge.
3. Participants should be ready to upload a short report (~4-8 pages) describing their model building process for their best model to a preprint server (e.g. bioRxiv, arXiv) and send the PDF or preprint link to the organizers by filling out this form. You must submit the Challenge report by the Challenge report submission deadline to be considered for the evaluation of challenge outcomes. While all reports are encouraged to link to their code (e.g. GitHub), sharing code is mandatory for the top three submissions. Participants that do not make their approach open and transparent cannot be considered.
Important Dates
| Train data, test stimuli, and development kit released: | January 14th, 2023 |
|---|---|
| Challenge submission deadline: | July 26th, 2023 at 11:59pm (UTC-4) |
| Challenge report/code submission deadline: | August 2nd, 2023 |
| Challenge results released: | August 10th, 2023 |
| Sessions at CCN 2023: | August 25–26th, 2023 |
If you participate in the Challenge, use this form to submit the Challenge report and code.
Acknowledgements
This research was funded by DFG (CI-241/1-1, CI241/1-3,CI-241/1-7) and ERC grant (ERC-2018-StG) to RMC; NSF award (1532591) in Neural and Cognitive Systems, the Vannevar Bush Faculty Fellowship program funded by the ONR (N00014-16-1-3116) and MIT-IBM Watson AI Lab to AO; the Alfons and Gertrud Kassel foundation to GR. Collection of the NSD dataset was supported by NSF IIS-1822683 and NSF IIS-1822929.