Lecture #10: Polynomial Identity Testing, and Parallel Matchings (original) (raw)
1. Matrix multiplication checking
The matrix multiplication checking problem is to verify the process of matrix multiplication: Given three matrices , , and , is it the case that ? The fastest known deterministic algorithm is to actually multiply and and compare the result to —this takes time, where is the exponent of matrix multiplication, and currently due to an algorithm of Coppersmith and Winograd. Note that an easy lower bound on the running time of any randomized algorithm for matrix multiplication verification is since the input has to at least be read (see Lecture 4 for more details on this). We will now give a randomized algorithm (in co-) which takes only time.
Let us introduce some notation for the rest of the course: means “choose uniformly at random from the set ”. Our checking problem algorithm is as follows:
(We’re imagining working over the reals; if the matrices are over the field , the computations should also carried out over the field . The proofs remain unchanged.) Now if , our algorithm always outputs the correct answer. If , the algorithm may output the wrong answer. We now bound the probability of such an error.
First, we need a simple lemma:
Lemma 1Given -digit strings and , .
Proof: Suppose . Let and . We can write and . This gives us
We can invoke the Principle of Deferred Decisions (see Section 3.5 of M&R) to assume that we’ve first picked all the values for . Then we can write
where we use the fact that can only be either or (or neither), and a randomly chosen will take that value with probability at most half.
Theorem 2 (Freivalds)If , our algorithm fails with probability at most .
Proof: If , then there is at least one row in , say , that differs from the corresponding row in C. Apply Lemma 1 with and . The probability that is at most . For the algorithm to output Yes, we must have . Therefore, the probability of failure for the algorithm is at most .
2. Polynomial identity checking
In the polynomial identity checking problem, we are given two multi-variate polynomials and each with degree ; again we are computing in some field . We may not be given the polynomials explicity, so we may not be able to read the polynomials in poly-time — we just have “black-box” access for evaluating a polynomial. Given these two polynomials, the problems is to determine if the polynomials are equal: i.e., if , or equivalently, . Letting , it suffices to check if a given polynomial is identically zero. There is no known poly-time algorithm for this problem. But we will now show that it is in co-.
First consider the univariate case. We can pick distinct values at random from . If for all values for , then . This follows from the basic and super-useful fact, that for any field , a polynomial of degree at most over that field can have at most roots.
This approach does not directly apply to the multivariate case; in fact, the polynomial over two variables over the reals has an infinite number of roots. Over the finite field , the degree- polynomial over variables
has roots (when ).
However, things still work out. Roughly speaking, we can handle the multivariate case by fixing variables and applying the result from the univariate case. Consider the following algorithm, which assumes we have some subset with .
Pick .
Evaluate .
If 0, return .
Theorem 3 (Schwartz (1980), Zippel (1979))If, in the above algorithm, the polynomial , we have
Proof: By induction on . The base case is the univariate case described above. With , we want to compute . Let be the largest power of . We can rewrite
for some polynomials and . Now we consider two events. Let be the event that evaluates to , and be the event that evaluates to .
We can rewrite the probability that is as:
Let us first bound the probability of , or the probability that . The polynomial has degree and fewer varaibles, so we can use the inductive hypothesis to obtain
Similarly, given (or ), the univariate polynomial has degree . Therefore, again by inductive hypothesis,
We can substitute into the expression above to get
This completes the inductive step.
Polynomial identity testing is a powerful tool, both in algorithms and in complexity theory. We will use it to find matchings in parallel, but it arises all over the place. Also, as mentioned above, there is no poly-time deterministic algorithm currently known for this problem. A result of Impagliazzo and Kabanets (2003) shows that proving that the polynomial identity checking problem is in would imply that either cannot have poly-size non-uniform circuits, or Permanent cannot have poly-size non-uniform circuits. Since we are far from proving such strong lower bounds, the Impagliazzo-Kabanets result suggest that deterministic algorithms for polynomial identity checking may require us to develop significantly new techniques.
For more on the polynomial identity checking problem, see Section 7.2 in M&R. Dick Lipton’s blog has an interesting post on the history of the theorem, as well as comparisons of the results of Schwartz, Zippel, and DeMillo-Lipton. One of the comments points out that the case when was known at least as far back as Ore in 1922; his proof appears as Theorem 6.13 in the book Finite Fields by Lidl and Niederreiter; a different proof by Dana Moshkowitz appears here.
3. Perfect matchings in bipartite graphs
We will look at a simple sequential algorithm to determine whether a perfect matching exists in a given bipartite graph or not. The algorithm is based on polynomial identity testing from the previous section.
A bipartite graph is specified by two disjoint sets and of vertices, and a set of edges between them. A perfect matching is a subset of the edge set such that every vertex has exactly one edge incident on it. Since we are interested in perfect matchings in the graph , we shall assume that . Let and . The algorithm we study today has no error if does not have a perfect matching (no instance), and errs with probability at most if does have a perfect matching (yes instance). This is unlike the algorithms we saw in the previous lecture, which erred on no instances.
Definition 4The Tutte matrix of bipartite graph is an matrix with the entry at row and column ,
(Apparently, Tutte came up a matrix for general graphs, and this one for bipartite graphs is due to Jack Edmonds, but we’ll stick with calling it the Tutte matrix.)
The determinant of the Tutte matrix is useful in testing whether a graph has a perfect matching or not, as the following lemma shows. Note that we do not think of this determinant as taking on some numeric value, but purely as a function of the variables .
Lemma 5 There exists a perfect matching in
Proof: We have the following expression for the determinant :
where is the set of all permutations on , and is the sign of the permutation . There is a one to one correspondence between a permutation and a (possible) perfect matching in . Note that if this perfect matching does not exist in (i.e. some edge ) then the term corresponding to in the summation is 0. So we have
where is the set of perfect matchings in . This is clearly zero if , i.e., if has no perfect matching. If has a perfect matching, there is a and the term corresponding to is . Additionally, there is no other term in the summation that contains the same set of variables. Therefore, this term is not cancelled by any other term. So in this case, .
This lemma gives us an easy way to test a bipartite graph for a perfect matching — we use the polynomial identity testing algorithm of the previous lecture on the Tutte matrix of . We accept if the determinant is not identically 0, and reject otherwise. Note that has degree at most . So we can test its identity on the field , where is a prime number larger than . From the analysis of the polynomial testing algorithm, we have the following :
The above algorithm shows that Perfect Matching for bipartite graphs is in RP. (The non-bipartite case may appear as a homework exercise.) Also, this algorithm for checking the existence of a perfect matching can be easily converted to one that actually computes a perfect matching as follows:
Pick .
Check if has a perfect matching.
If “Yes”, output to be in the matching and recurse on , the graph obtained after the removal of vertices and .
If “No”, recurse on , the graph obtained after removing the edge .
Note that this algorithm seems inherently sequential; it’s not clear how to speed up its running time considerably by using multiple processors. We’ll consider the parallel algorithm in the next section.
Some citations: the idea of using polynomial identity testing to test for matchings is due to Lovász. The above algorithm to find the matching runs in time , where is the time to multiply two -matrices. (It is also the time to compute determinants, and matrix inverses.) Rabin and Vazirani showed how to compute perfect matchings in general graphs in time , where . Recent work of Mucha and Sankowski, and Harvey show how to use these ideas (along with many other cool ones) to find perfect matchings in general graphs in time .
4. A parallel algorithm for finding perfect matchings
However, we can give a slightly different algorithm (for a seemingly harder problem), that indeed runs efficiently on parallel processors. The model here is that there are polynomially many processors run in parallel, and we want to solve the problem in poly-logarithmic depth using polynomial work. We will use the fact that there exist efficient parallel algorithms for computing the determinant of a matrix to obtain our parallel algorithm for finding perfect matchings.
We could try the following “strawman” parallel algorithm:
Use a processor for every edge that tests (in parallel) if edge is in some perfect matching or not. For each edge that lies in some perfect matching, the processor outputs the edge, else it outputs nothing.
We are immediately faced with the problem that there may be several perfect matchings in the graph, and the resulting output is not a matching. The algorithm may in fact return all the edges in the graph. It will only work if there is a unique perfect matching.
So instead of testing whether an edge is in some perfect matching or not, we want to test whether an edge is in a specific perfect matching or not. The way we do this is to put random weights on the edges of the graph and test for the minimum weight perfect matching. Surprisingly, one can prove that the minimum weight perfect matching is unique with a good probability, even when the weights are chosen from a set of integers from a relatively small range.
Lemma 6Let and . For every element there is a weight picked u.a.r. from . The weight of subset is . Then
Proof: We will estimate the probability that the minimum weight set is not unique. Let us define an element to be tied if
It is easy to see that there exists a tied element if and only if the minimum weight subset is not unique. Below we bound the probability that a fixed element is tied. The result will then follow using a union bound.\par We use the principle of deferred decisions. Let us fix the weights of all the elements except . We want to bound . Let
with assigned the value 0. It is easy to see that is tied iff . So,
The last inequality is because there is at most on value for for which . This holds irrespective of the particular values of the other s. So , and
Thus .
Now we can look at the parallel algorithm for finding a perfect matching. For each edge , we pick a random weight , from , where is the number of edges in . Let the sets denote all the perfect matchings in . Then the Isolation Lemma implies that there is a unique minimum weight perfect matching with at least a half probability. We assign the value to the variables in the Tutte matrix . Let denote the resulting matrix. We use the determinant of to determine the weight of the min-weight perfect matching, if it is unique, as suggested by the following lemma.
Lemma 7Let be the weight of the minimum weight perfect matching in . Then,
Proof: If has no perfect matching, it is clear from lemma 5 that . \par Now consider that case when has a unique min-weight perfect matching. From the expression of the determinant, we have
where is the weight of the perfect matching corresponding to and is the set of all perfect matchings in . Since there is exactly one perfect matching of weight and other perfect matchings have weight at least , this evaluates to an expression of the form . Clearly, this is non-zero, and the largest power of 2 dividing this is .\par Now consider the case when has more than one min-weight perfect matchings. In this case, if the determinant is non-zero, every term in the sumation is a power of 2, at least . So divides .
We refer to the submatrix of obtained by removing the -th row and -th column by . Note that this is a matrix corresponding to the bipartite graph . The parallel algorithm would run as follows.
Pick random weights for the edges of . (In the following steps, we assume that we’ve isolated the min-weight perfect matching.)
Compute the weight of the min-weight perfect matching from (using the parallel algorithm for computing the determinant): this is just the highest power of that divides .
If , output “no perfect matching”.
For each edge do, in parallel,:
Evaluate .
If , output nothing.
Else, find the largest power of 2, , dividing .
If , output .
Else, output nothing.
It is clear that, if has no perfect matching, this algorithm returns the correct answer. Now suppose has a unique minimum weight perfect matching, we claim Lemma 7 ensures that precisely all the edges in the unique min-weight perfect matching are output. To see this, consider an edge not in the unique min weight perfect matching. From the lemma, is either zero (so the edge will not be output), or is at least as large as the min-weight perfect matching in . Since the min-weight perfect matching is unique and does not contain edge , this implies will be strictly larger than , and this edge will not be output in this case either. Finally, if an edge is in the unique min-weight perfect matching, removing this edge from the matching gives us the unique min-weight perfect matching in . So, in this case and the edge is output.
Thus, if has a perfect matching, this algorithm will isolate one with probability at least , and will output it—hence we get an RNC algorithm that succeeds with probability at least on “Yes” instances, and never makes mistakes on “No” instances.
Finally, some more citations. This algorithm is due to Mulmuley, Vazirani and Vazirani; the first RNC algorithm for matchings had been given earlier by Karp, Upfal, and Wigderson. It is an open question whether we can find perfect matchings deterministically in parallel using poly-logarithmic depth and polynomial work, even for bipartite graphs.



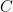













-digit strings
and
,
.








![\displaystyle \Pr[a \cdot x - b \cdot x = 0] = \Pr\left[x_i = \frac{\alpha - \beta}{b_i - a_i}\right] \le \frac{1}{2},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5Ba+%5Ccdot+x+-+b+%5Ccdot+x+%3D+0%5D+%3D+%5CPr%5Cleft%5Bx_i+%3D+%5Cfrac%7B%5Calpha+-+%5Cbeta%7D%7Bb_i+-+a_i%7D%5Cright%5D+%5Cle+%5Cfrac%7B1%7D%7B2%7D%2C&bg=f7f7f7&fg=000000&s=0&c=20201002)


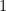

, our algorithm fails with probability at most
.
























.
.
, we have
![\displaystyle \Pr[Q(r1, \ldots, rn) = 0] \le \frac{d}{|S|}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5BQ%28r1%2C+%5Cldots%2C+rn%29+%3D+0%5D+%5Cle+%5Cfrac%7Bd%7D%7B%7CS%7C%7D.&bg=f7f7f7&fg=000000&s=0&c=20201002)
![{\Pr[Q(r_1, \ldots, r_n) = 0]}](https://s0.wp.com/latex.php?latex=%7B%5CPr%5BQ%28r_1%2C+%5Cldots%2C+r_n%29+%3D+0%5D%7D&bg=f7f7f7&fg=000000&s=0&c=20201002)








![\displaystyle \begin{array}{rcl} \Pr[Q(r) = 0] = \Pr[\mathcal{E}_1] & = & \Pr[ \mathcal{E}_1 \mid \mathcal{E}_2 ] \Pr[\mathcal{E}_2] + \Pr[\mathcal{E}_1 \mid \lnot \mathcal{E}_2 ] \Pr[\lnot \mathcal{E}_2 ] \\ & \leq & \Pr[\mathcal{E}_2] + \Pr[\mathcal{E}_1 \mid \lnot \mathcal{E}_2] \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%5CPr%5BQ%28r%29+%3D+0%5D+%3D+%5CPr%5B%5Cmathcal%7BE%7D_1%5D+%26+%3D+%26+%5CPr%5B+%5Cmathcal%7BE%7D_1+%5Cmid+%5Cmathcal%7BE%7D_2+%5D+%5CPr%5B%5Cmathcal%7BE%7D_2%5D+%2B+%5CPr%5B%5Cmathcal%7BE%7D_1+%5Cmid+%5Clnot+%5Cmathcal%7BE%7D_2+%5D+%5CPr%5B%5Clnot+%5Cmathcal%7BE%7D_2+%5D+%5C%5C+%26+%5Cleq+%26+%5CPr%5B%5Cmathcal%7BE%7D_2%5D+%2B+%5CPr%5B%5Cmathcal%7BE%7D_1+%5Cmid+%5Clnot+%5Cmathcal%7BE%7D_2%5D+%5Cend%7Barray%7D+&bg=f7f7f7&fg=000000&s=0&c=20201002)


![\displaystyle \Pr[\mathcal{E}_2]=\Pr[A(r_2, \ldots, r_n) = 0] \le \frac{d-k}{|S|}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPr%5B%5Cmathcal%7BE%7D_2%5D%3D%5CPr%5BA%28r_2%2C+%5Cldots%2C+r_n%29+%3D+0%5D+%5Cle+%5Cfrac%7Bd-k%7D%7B%7CS%7C%7D.&bg=f7f7f7&fg=000000&s=0&c=20201002)



![\displaystyle \Pr[\mathcal{E}_1 \mid \lnot \mathcal{E}_2]=\Pr[Q(x_1, r_2, \ldots, r_n) = 0 \; | \; A(r_2, \ldots, r_n) \ne 0] \le \frac{k}{|S|}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CPr%5B%5Cmathcal%7BE%7D_1+%5Cmid+%5Clnot+%5Cmathcal%7BE%7D_2%5D%3D%5CPr%5BQ%28x_1%2C+r_2%2C+%5Cldots%2C+r_n%29+%3D+0+%5C%3B+%7C+%5C%3B+A%28r_2%2C+%5Cldots%2C+r_n%29+%5Cne+0%5D+%5Cle+%5Cfrac%7Bk%7D%7B%7CS%7C%7D.&bg=f7f7f7&fg=000000&s=0&c=20201002)
![\displaystyle \begin{array}{rcl} \Pr[Q(r) = 0] & \leq & \Pr[\mathcal{E}_2] + \Pr[\mathcal{E}_1 \mid \lnot \mathcal{E}_2] \\ & \le & \frac{d-k}{|S|} + \frac{k}{|S|} = \frac{d}{|S|} \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%5CPr%5BQ%28r%29+%3D+0%5D+%26+%5Cleq+%26+%5CPr%5B%5Cmathcal%7BE%7D_2%5D+%2B+%5CPr%5B%5Cmathcal%7BE%7D_1+%5Cmid+%5Clnot+%5Cmathcal%7BE%7D_2%5D+%5C%5C+%26+%5Cle+%26+%5Cfrac%7Bd-k%7D%7B%7CS%7C%7D+%2B+%5Cfrac%7Bk%7D%7B%7CS%7C%7D+%3D+%5Cfrac%7Bd%7D%7B%7CS%7C%7D+%5Cend%7Barray%7D+&bg=f7f7f7&fg=000000&s=0&c=20201002)
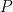











matrix
with the entry at row
and column
,


There exists a perfect matching in


![{[n]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%5D%7D&bg=f7f7f7&fg=000000&s=0&c=20201002)












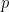

.
has a perfect matching.
to be in the matching and recurse on
and
.
, the graph obtained after removing the edge



and
. For every element
there is a weight
picked u.a.r. from
. The weight of subset
is
. Then
![\displaystyle \Pr[ \text{ minimum weight set among } S1,\cdots ,Sk \text{ is unique } ] \ge\frac12.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPr%5B+%5Ctext%7B+minimum+weight+set+among+%7D+S1%2C%5Ccdots+%2CSk+%5Ctext%7B+is+unique+%7D+%5D+%5Cge%5Cfrac12.+&bg=f7f7f7&fg=000000&s=0&c=20201002)




![{\Pr_{w_i}[ e_i \text{ is tied } \mid w_1,\cdots,w_{i-1},w_{i+1},w_m]}](https://s0.wp.com/latex.php?latex=%7B%5CPr_%7Bw_i%7D%5B+e_i+%5Ctext%7B+is+tied+%7D+%5Cmid+w_1%2C%5Ccdots%2Cw_%7Bi-1%7D%2Cw_%7Bi%2B1%7D%2Cw_m%5D%7D&bg=f7f7f7&fg=000000&s=0&c=20201002)


![\displaystyle \begin{array}{rcl} & & Pr_{w_i}[ e_i \text{ is tied } \mid w_1,\cdots,w_{i-1},w_{i+1},w_m] \\ &=& Pr_{w_i}[w_i=W^- - W^+ \mid w_1,\cdots,w_{i-1},w_{i+1},w_m] \\ &\le& \frac{1}{2m}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%26+%26+Pr_%7Bw_i%7D%5B+e_i+%5Ctext%7B+is+tied+%7D+%5Cmid+w_1%2C%5Ccdots%2Cw_%7Bi-1%7D%2Cw_%7Bi%2B1%7D%2Cw_m%5D+%5C%5C+%26%3D%26+Pr_%7Bw_i%7D%5Bw_i%3DW%5E-+-+W%5E%2B+%5Cmid+w_1%2C%5Ccdots%2Cw_%7Bi-1%7D%2Cw_%7Bi%2B1%7D%2Cw_m%5D+%5C%5C+%26%5Cle%26+%5Cfrac%7B1%7D%7B2m%7D.+%5Cend%7Barray%7D+&bg=f7f7f7&fg=000000&s=0&c=20201002)

![{\Pr[e_i \text{ is tied } ] \le \frac{1}{2m}}](https://s0.wp.com/latex.php?latex=%7B%5CPr%5Be_i+%5Ctext%7B+is+tied+%7D+%5D+%5Cle+%5Cfrac%7B1%7D%7B2m%7D%7D&bg=f7f7f7&fg=000000&s=0&c=20201002)
![\displaystyle \Pr[ \exists \text{ a tied element }] \le\sum_{i=1}^m \Pr[e_i \text{ is tied} ] \le \frac12.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPr%5B+%5Cexists+%5Ctext%7B+a+tied+element+%7D%5D+%5Cle%5Csum_%7Bi%3D1%7D%5Em+%5CPr%5Be_i+%5Ctext%7B+is+tied%7D+%5D+%5Cle+%5Cfrac12.&bg=f7f7f7&fg=000000&s=0&c=20201002)
![{\Pr[ \text{ minimum weight set is unique } ] \ge\frac12}](https://s0.wp.com/latex.php?latex=%7B%5CPr%5B+%5Ctext%7B+minimum+weight+set+is+unique+%7D+%5D+%5Cge%5Cfrac12%7D&bg=f7f7f7&fg=000000&s=0&c=20201002)

![{[2m-1]}](https://s0.wp.com/latex.php?latex=%7B%5B2m-1%5D%7D&bg=f7f7f7&fg=000000&s=0&c=20201002)




be the weight of the minimum weight perfect matching in









that divides
.
, output nothing.
, dividing
, output

