Slide View : Parallel Programming :: Fall 2019 (original) (raw)
Why Parallelism? Why Efficiency?
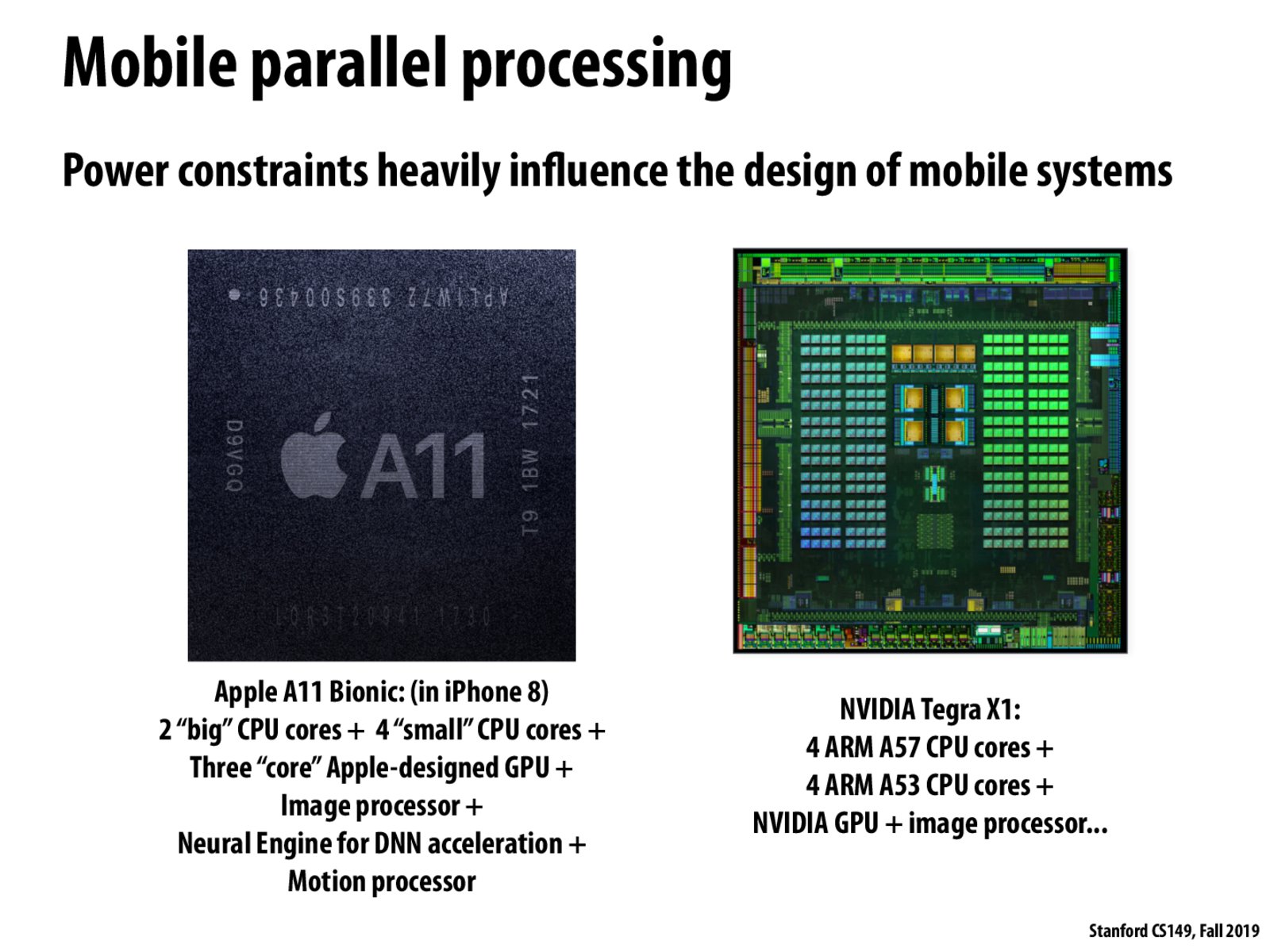
Previous|Next--- Slide 48 of 52
Back to Lecture Thumbnails

siyuliu3
I'm just curious about the neural accelerator. Is there a breakdown of that architecture? How is that different from a GPU?

dkumazaw
Here is an interesting blog post that may be of interest to you from Google on the Cloud TPU architecture. The performance gain seems to come from the way in which data are passed around multipliers; they carefully avoid memory i/o, thereby alleviating the so called von Neumann bottleneck that general-purpose processors like GPUs have faced. https://cloud.google.com/blog/products/ai-machine-learning/what-makes-tpus-fine-tuned-for-deep-learning
Copyright 2019 Stanford University