Dong Won Lee (original) (raw)
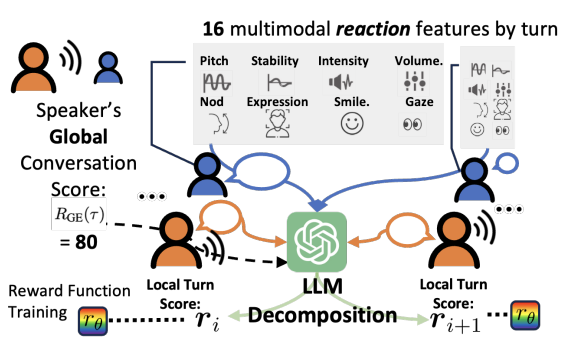 |
Aligning Dialogue Agents with Global Feedback via Large Language Model Reward Decomposition Dong Won Lee,Hae Won Park,Cynthia Breazeal,Louis-Philippe Morency, In Submission , 2025 paper We introduce a framework which uses a frozen large language model (LLM) to decompose global session-level feedback into fine-grained turn-level rewards for dialogue agents. Our method works in both text-only and multimodal settings (using cues like pitch and gaze), enabling reinforcement learning without dense supervision. The resulting reward models improve dialogue quality in human evaluations, showing that LLMs can effectively serve as general-purpose reward decomposers. |
|---|---|
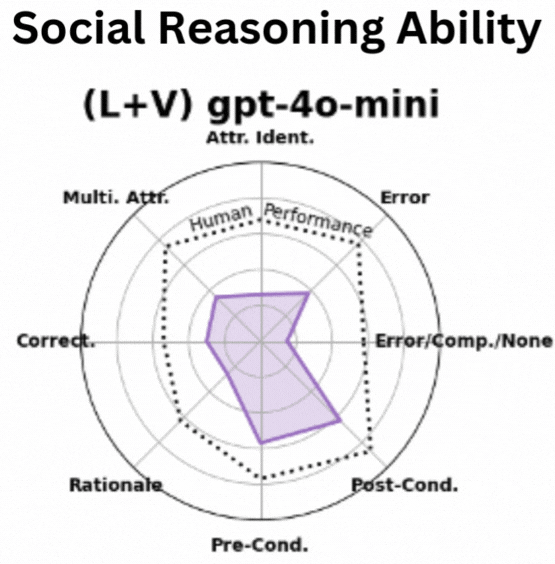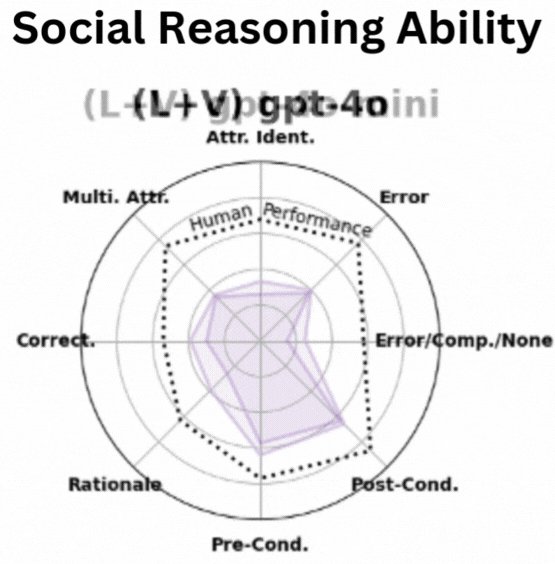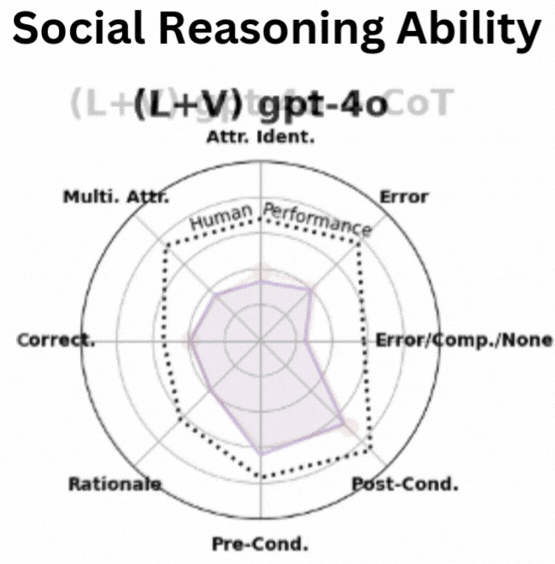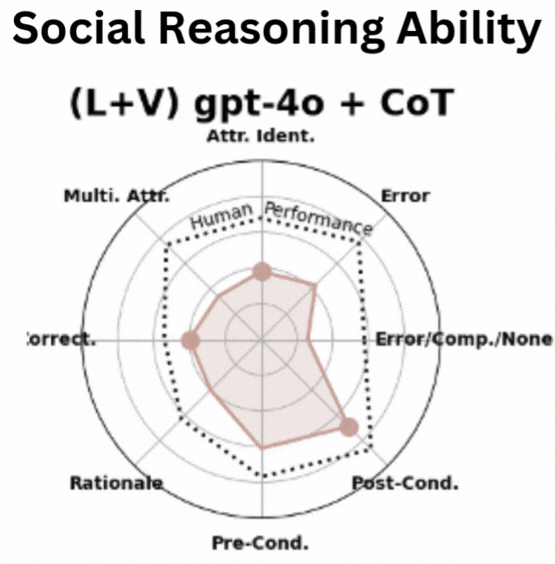 |
Social Human Robot Embodied Conversation (SHREC) Dataset: Benchmarking Foundational Models’ Social Reasoning Dong Won Lee,Yubin Kim,Denison Guvenoz,Sooyeon Jeong,Parker Malachowsky,Louis-Philippe Morency,Cynthia Breazeal,Hae Won Park In Submission , 2025 website /paper We introduce a large-scale collection of datasets of real-world human-robot interaction videos with 10K+ annotations to benchmark AI models' ability to identify and reason social interactions, providing a foundation for advancing socially intelligent AI. |
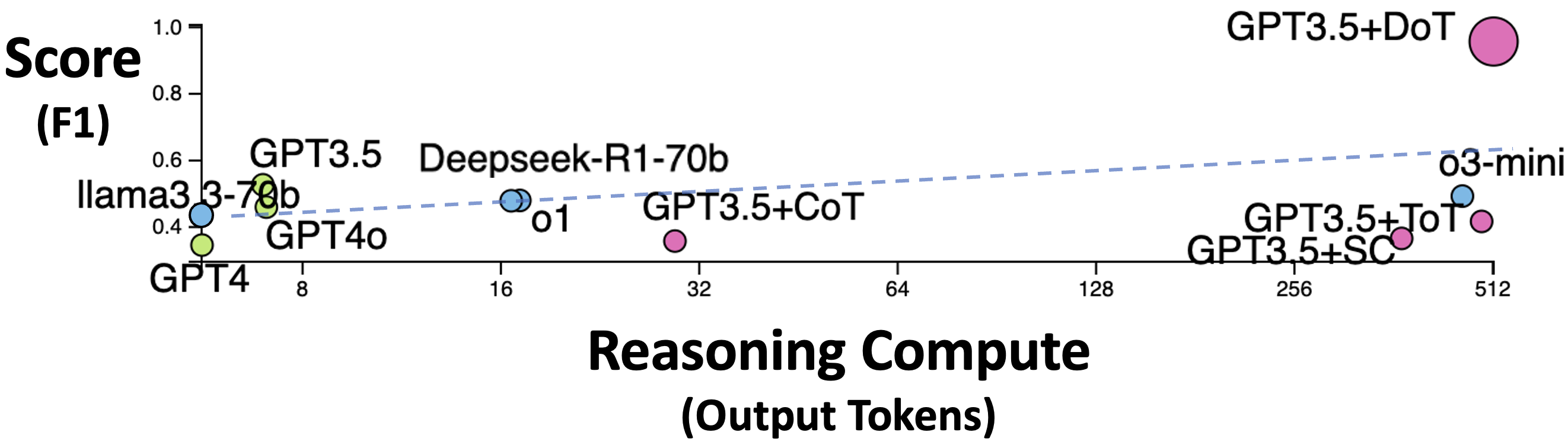 |
Does “Reasoning” with Large Language Models Improve Recognizing, Generating and Reframing Unhelpful Thoughts? Yilin Qi*,Dong Won Lee*,Cynthia Breazeal,Hae Won Park ACL, NLP for Positive Impact Workshop, 2025 paper We show that augmenting older models like GPT-3.5 with reasoning strategies (e.g. DoT, CoT, Self-Consistency) outperforms state-of-the-art pre-trained models (e.g., DeepSeek-R1, o1) in recognizing and reframing unhelpful thoughts. |
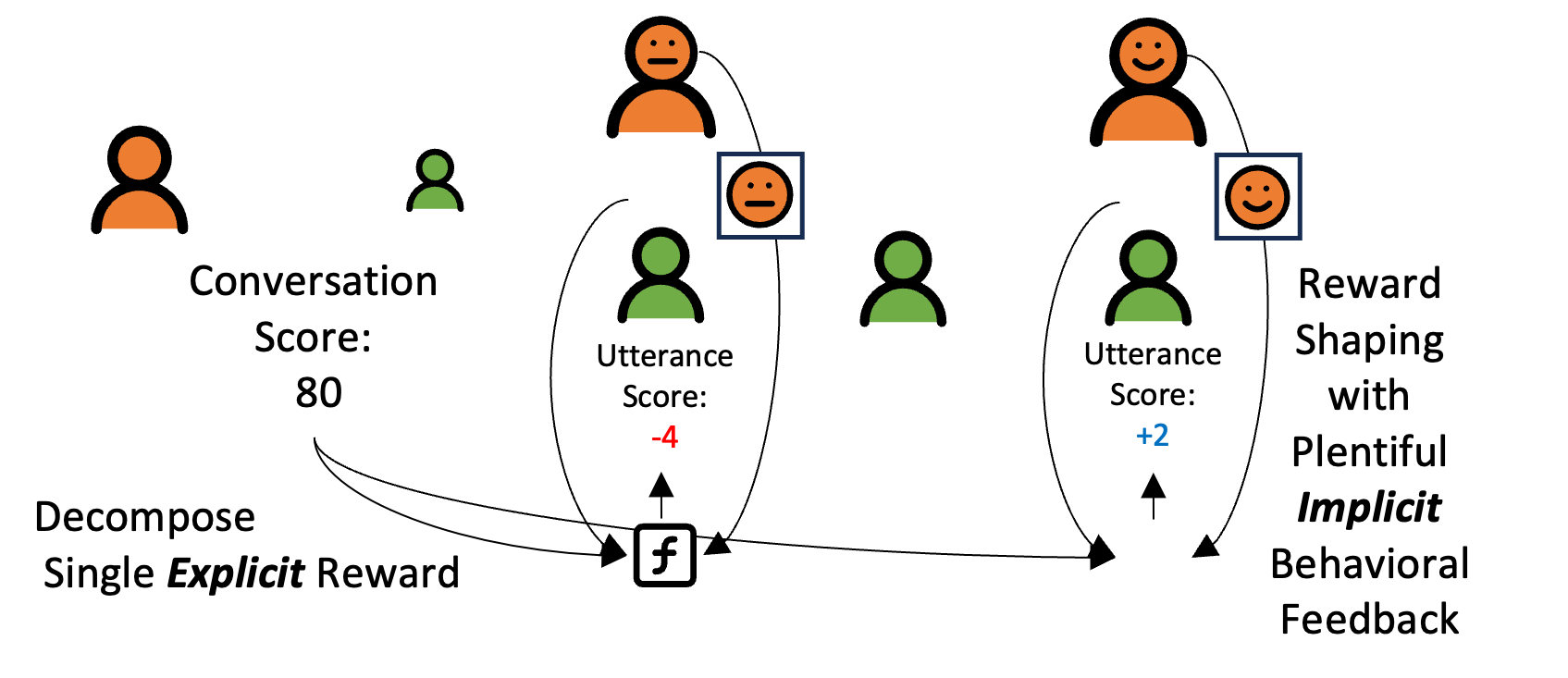 |
Global Reward to Local Rewards: Multimodal-Guided Decomposition for Improving Dialogue Agents Dong Won Lee,Hae Won Park,Yoon Kim,Cynthia Breazeal,Louis-Philippe Morency EMNLP , 2024 (Oral) paper /code /huggingface We introduce an approach named GELI, which automatically decomposes a single Global Explicit post-interaction score while incorporating Local Implicit feedback from multimodal signals to adapt a language model to become more conversational. |
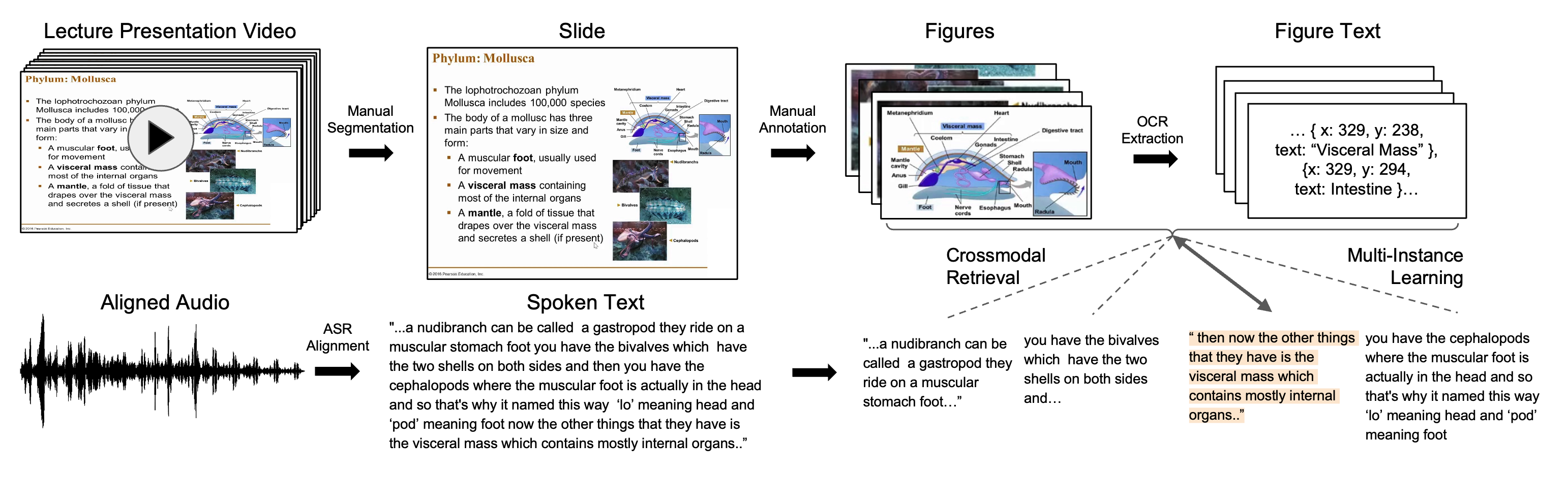 |
Lecture Presentations Multimodal Dataset: Towards Understanding Multimodality in Educational Videos Dong Won Lee,Chaitanya Ahuja,Paul Pu Liang,Sanika Natu,Louis-Philippe Morency ICCV, 2023 paper /code We introduce the Multimodal Lecture Presentations dataset and PolyViLT a multimodal transformer trained with a multi-instance learning loss. We propose a large-scale benchmark testing the capabilities of machine learning models in multimodal understanding of educational content. |
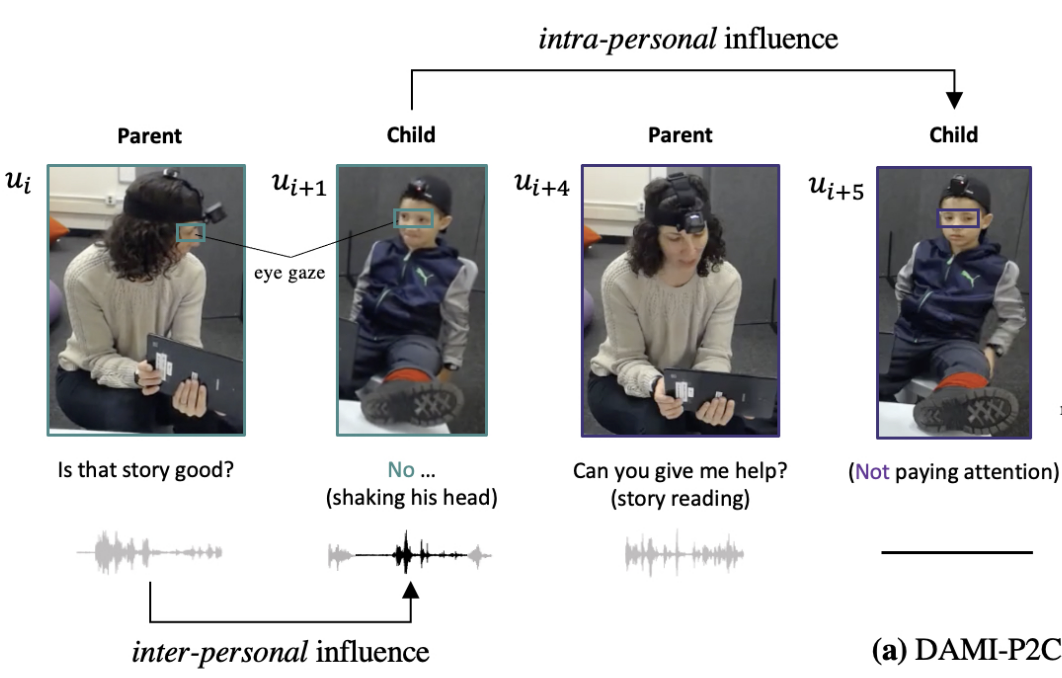 |
HIINT: Historical, Intra-and Inter-personal Dynamics Modeling with Cross-person Memory Transformer Yubin Kim,Dong Won Lee,Paul Pu Liang,Sharifa Algohwinem,Cynthia Breazeal,Hae Won Park ICMI, 2023 paper We model the Historical, Intra-and Inter-personal (HIINT) Dynamics in conversation by incorporating memory modules in the Cross-person Memory Transformer to address temporal coherence and better represent the context of conversational behaviors. |
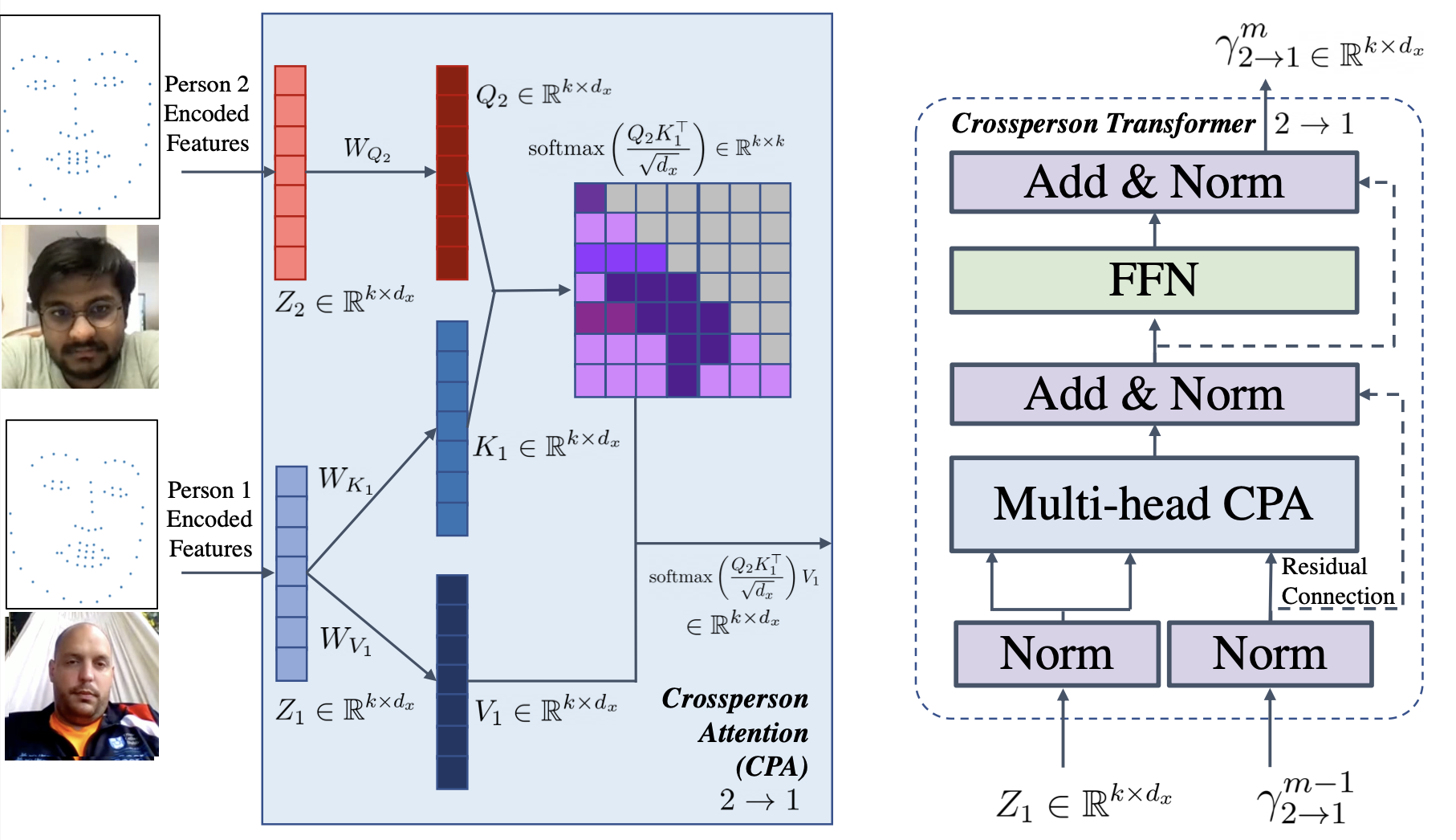 |
Multipar-T: Multiparty-Transformer for Capturing Contingent Behaviors in Group Conversations Dong Won Lee,Yubin Kim,Rosalind Picard,Cynthia Breazeal,Hae Won Park IJCAI, 2023 (Oral) paper We introduce a new transformer architecture to model contingent behaviors in multiparty group conversations. |
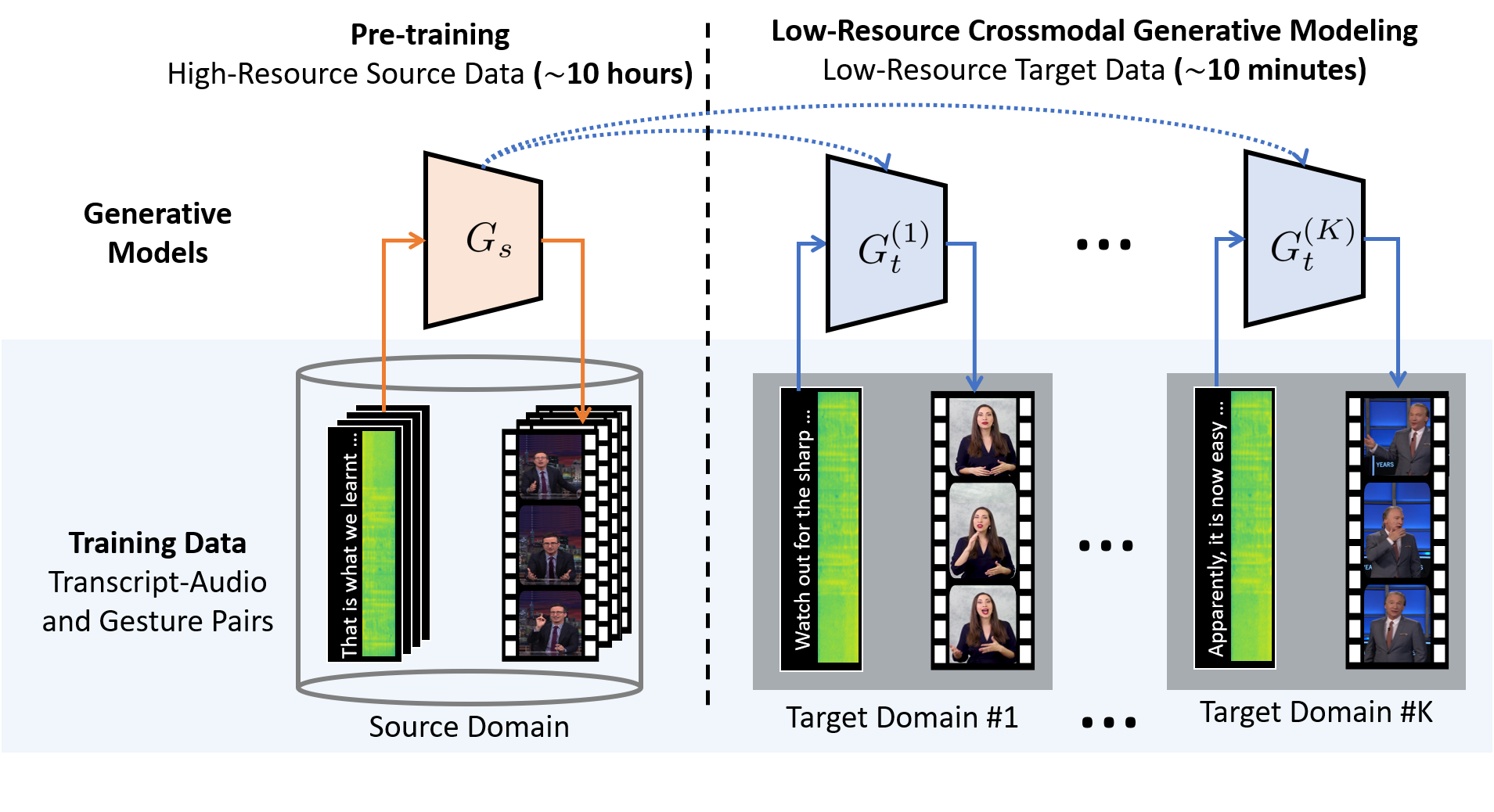 |
Low-resource Adaptation for Personalized Co-Speech Gesture Generation Chaitanya Ahuja, Dong Won Lee,Louis-Philippe Morency CVPR, 2022 paper / We propose a new approach in crossmodal generative modeling in low-resource settings in the hopes to to create a personalized gesture generation model (e.g. as part of a personalized avatar) with limited data from a new speaker. |
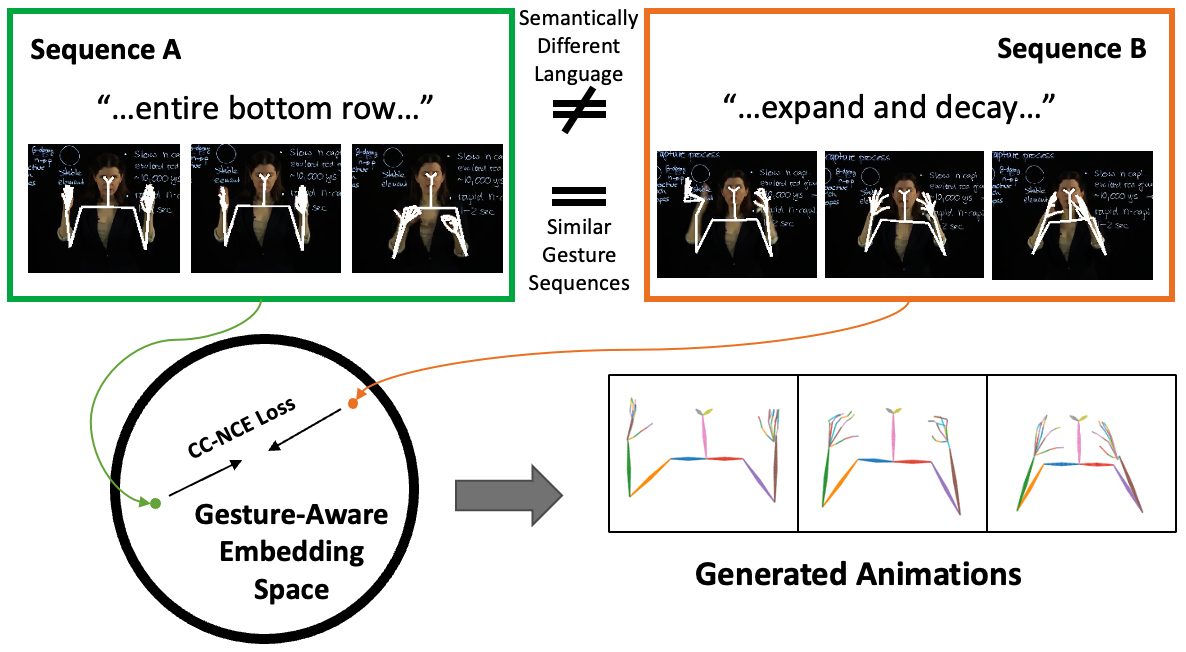 |
Crossmodal clustered contrastive learning: Grounding of spoken language to gestures Dong Won Lee, Chaitanya Ahuja,Louis-Philippe Morency ICMI, GENEA Workshop, 2021 paper /presentation video /code We propose a new crossmodal contrastive learning loss to encourage a stronger grounding between gestures and spoken language. |
 |
No Gestures Left Behind: Learning Relationships between Spoken Language and Freeform Gestures Chaitanya Ahuja, Dong Won Lee, Ryo Ishii,Louis-Philippe Morency EMNLP, Findings, 2020 paper /code We study relationships between spoken language and co-speech gestures to account for the long tail of text-gesture distribution. |
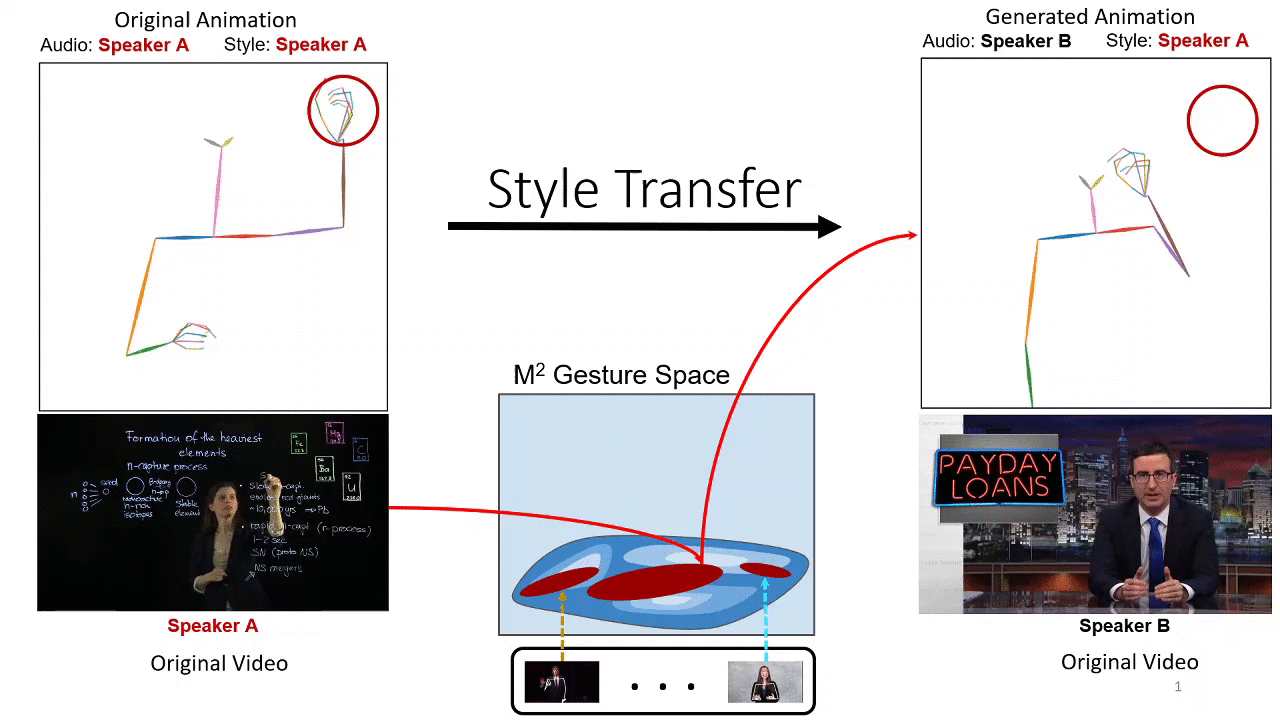 |
Style Transfer for Co-Speech Gesture Animation: A Multi-Speaker Conditional Mixture Approach Chaitanya Ahuja, Dong Won Lee, Yukiko I. Nakano,Louis-Philippe Morency ECCV, 2020 project page /paper /code We propose a new style transfer model to learn individual styles of speaker's gestures. |
Planned Submissions
06/2024: EMNLP 2024
Mentors
I have been blessed to meet amazing mentors who have guided me to become a better researcher (and more importantly, a good person). I believe that I can only repay what they've done for me by assisting others in their journey in any way I can. Please don't hesitate to reach out!
Mentors and Advisors: (in Alphabetical Order)
- Ben Eysenbach - CMU
- Chaitanya Ahuja - CMU
- Cynthia Breazeal - MIT
- David Kosbie - CMU
- Hae Won Park - MIT
- Louis-Phillipe Morency - CMU
- Mark Stehlik - CMU
- Paul Pu Liang - CMU
- Roz Picard - MIT
- Yoon Kim - MIT
- Sid Sen - Microsoft Research