Game Angst (original) (raw)

Low-Fragmentation, High-Performance Memory Allocation in Despair Engine
I recently wrote about dlmalloc and how it is a poor choice for a memory allocator for console games. As I explained in my previous article, dlmalloc has two major limitations. It manages a pool of address space composed of discrete regions called segments. It can easily add segments to grow its pool of address space, but it can’t easily remove segments to return address space to the OS. Additionally, it doesn’t distinguish between physical and virtual memory, which means that it can’t take advantage of virtual memory’s ability to combat fragmentation.
During the development of FEAR 3, to address these limitations, I implemented a new general-purpose allocator based on dlmalloc called dsmalloc. Dsmalloc makes two important improvements to dlmalloc.
The first improvement is in how dsmalloc treats segments. In dsmalloc, segments are always managed as completely distinct regions of memory. Dsmalloc will never coalesce adjacent segments. Because of this, dsmalloc tracks segments much more closely than dlmalloc. By overlaying a second intrusive data structure in the free bits of the boundary tag structure used to track individual allocations, dsmalloc can, in constant time and with no memory overhead, determine with every free operation when a segment is no longer occupied and can be returned to the system.
The second improvement is that dsmalloc recognizes the difference between reserved address space and allocated memory. Unlike dlmalloc, which uses two callbacks to allocate and free system memory, dsmalloc exposes four callbacks, two to reserve and release segment-sized regions of virtual address space, and two to commit and decommit page-sized subregions of segments.
Just as dsmalloc never leaves any unoccupied segments reserved, it also never leaves any unoccupied pages committed.
typedef void* (*ReserveSegmentFunc)(size_t size);
typedef void (*ReleaseSegmentFunc)(void* ptr, size_t size);
typedef int (*CommitPageFunc)(void* ptr, size_t size);
typedef void (*DecommitPageFunc)(void* ptr, size_t size);MemorySpace* CreateMemorySpace(
size_t initialCapacity,
ReserveSegmentFunc reserveSegmentFunc,
ReleaseSegmentFunc releaseSegmentFunc,
CommitPageFunc commitPageFunc,
DecommitPageFunc decommitPageFunc,
size_t pageSize,
size_t segmentGranularity,
size_t segmentThreshold );
These two extensions are implemented without any additional memory overhead compared to dlmalloc and with very little computational overhead. The added cost is a few percent in targeted tests, but in a real-world scenario the performance difference between dlmalloc and dsmalloc isn’t even measurable.
The great thing about these two changes to dlmalloc is that they enable a wide range of allocation strategies that otherwise wouldn’t be feasible.
Individual systems within the Despair Engine are free to create separate dsmalloc instances (or regions) for their own use. Because dsmalloc instances are so aggressive about returning memory to the system, they incur minimal internal fragmentation costs and can coexist gracefully with other system allocators. Thread-safety is left to the users of dsmalloc, so individual systems can bypass thread synchronization costs entirely or at least use local locks to avoid contention with other allocators. Using separate dsmalloc instances also provides systems with easier tracking of memory allocations, tighter enforcement of budgets, and, if their allocation patterns exhibit temporal or spatial locality within their own systems, reduced external fragmentation.
For systems that don’t want to bother with using a custom allocator (which, frankly, most don’t), Despair Engine provide a common allocator which services request from the tradition global allocation functions like operator new, malloc, and XMemAlloc. This common allocator also utilizes dsmalloc instances under the hood.
The common allocator creates one dsmalloc instance for allocations larger than 256 bytes and 20 dsmalloc instances covering allocations at every 8 byte size interval less than 64 bytes and every 16 byte interval between 64 and 256 bytes. The instance for large allocations uses a 32 megabyte segment size and 64 kilobyte pages whereas the small allocation instances use 64 kilobyte segments. Using page-sized segments for the small allocation regions is a minor optimization that removes the need for dsmalloc to track address reservation and memory commission separately for these regions.
Bucketing small allocations into so many discrete regions significantly reduces external fragmentation in our games, despite creating a modest increase in internal fragmentation. Since only allocations within a single region need to be synchronized, it also has a side benefit of greatly reducing contention between allocations from multiple threads.
It is worth noting that since the various small allocation regions are essentially used for fixed-size allocations, they could be more efficiently implemented as dedicated fixed-block allocators. We have such an implementation in the engine, but dsmalloc (like dlmalloc) already implements an internal small, fixed-block allocation optimization, so in practice it is more convenient to use dsmalloc instances for everything and almost as efficient.
One key benefit of using dsmalloc instances for small allocations instead of a pure fixed-block allocator is that it offers us more flexibility in how the small allocation regions are configured. At the time I was implementing this in FEAR 3, minimizing fragmentation was our top concern, but in the future we might choose to prioritize thread synchronization efficiency over memory consumption. Instead of routing allocations to regions based on their size, we could create just a few small allocation regions and cycle between them based on thread contention. The idea is to allow a thread to try to lock a region for allocation, but rather than waiting if the region is already in use by another thread, simply move on to another region and try again.
Dsmalloc is flexible enough to support both of these strategies efficiently or, in fact, any hybrid combination of the two.
The dsmalloc callbacks are designed to be easily mappable to OS functions such as VirtualAlloc in Windows, but sometimes these functions are too expensive to be used directly. To improve performance, on some platforms the Despair general allocator utilizes a commit cache. The commit cache is a simple direct-mapped cache that sits between the dsmalloc commit callback and the OS. Dsmalloc already optimizes allocation order to maximize cache efficiency, and this benefits the commit cache as well. A 32 megabyte commit cache is probably overly generous, but it guarantees that OS-level calls don’t show up in our profiles even during content streaming transitions.
Having the cache implemented external to dsmalloc is also useful. When memory is extremely tight, anything that doesn’t utilize the general allocator could fail even though memory is still available in the commit cache. In those extreme cases the commit cache can be manually prompted to return pages to the system ensuring that OS-level allocations never fail because the memory they need is held in a cache.
There is one additional complication that plagues the consoles. On both the Xbox 360 and the Playstation 3, the GPU does not share the CPU’s memory mapping unit. On the Xbox 360 the GPU requires physically contiguous memory for all resources and on the PS3 the GPU has a separate MMU with only 1 megabyte page granularity. Since we use dsmalloc with 64 kilobyte pages to minimize fragmentation, this means we’re susceptible to physical memory fragmentation when it comes to resources allocated for the GPU. On the Xbox 360, unbeknownst to many developers, the OS copes with this automatically. When a physical allocation request can’t be satisfied due to physical memory fragmentation, the Xbox 360 operating system locks the entire address space and defragments physical memory pages (by memcpy’ing physical pages and remapping virtual addresses) to accommodate the request.
On the PS3 the OS doesn’t provide this service automatically, but the same basic need exists. 64 kilobyte pages must be locked and relocated to generate contiguous 1 megabyte pages appropriate for the GPU. Thankfully with a little bit of acrobatics it is possible to do just that without violating certification requirements.
Although the operation is every bit as expensive as it sounds, it proved necessary to keep FEAR 3 from crashing. FEAR 3 ran dangerously close to the limits of memory on the Playstation 3 and survived only by allowing flexible budgets for every kind of memory. GPU allocations in main memory varied by over 100% between streaming regions so not only did CPU addressable memory need to be defragmented for use by the GPU, GPU addressable memory had to be defragmented continually and returned to the CPU. The really expensive CPU defragmentation provided a safety net against crashes at all times, but thankfully it was only needed at major chapter transitions where a load screen was expected and a 100 ms hitch was infinitely preferable to an out and out crash.
When I undertook to rewrite the Despair memory allocator near the end of FEAR 3, the overarching goal was to never fail to satisfy an allocation request due to prior memory usage patterns. If a level fit just barely into memory after a fresh boot, we wanted it to fit equally well in memory after a hundred hours of continuous play. While I can’t pretend that fragmentation doesn’t exist at all in the system I devised, I can say that it was so dramatically reduced that we were able to establish an upper bound on fragmentation and enforce budgets for our content that were reliable regardless of the order or duration in which the game was played.
The new Despair memory allocator based on dsmalloc ran the same content as the old memory allocator on all platforms with a slightly lower lower bound on memory, a much lower upper bound on memory, and it even managed a slightly lower run-time performance cost.
Tagged: Despair Engine · optimization
Scalable Concurrency in Despair Engine
In my last article I promised a follow-up description of the memory allocation system that I wrote for Despair Engine during the development of F.E.A.R. 3. Before I get to that, however, I’ve been inspired by Charles Bloom‘s recent posts on the job queue system that is apparently part of RAD Game Tools‘ Oodle, and I thought it might be interesting to describe the current job system and thread layout in Despair.
The “concurrency manager” in Despair Engine consists of worker threads and job queues. By default there is one pool of worker threads that share a single job queue, referred to as public workers, and some number of additional worker threads, each with its own job queue, referred to as private workers.
The job queues and their worker threads are relatively simple constructs. Jobs can be added to a queue from any thread and, when jobs are added, they create futures which can be used to wait on the job’s completion. A job queue doesn’t directly support any concept of dependencies between jobs or affinities to limit which worker threads a job can run on.
Jobs are fetched by worker threads in strictly FIFO order, but with multiple worker threads servicing a single queue, that doesn’t provide many guarantees on the order in which jobs are processed. For example, jobs A and B, enqueued in that order, may be fetched consecutively by worker threads 1 and 2. Because these tasks are asynchronous, worker thread 2 might actually manage to start and finish processing job B before worker thread 1 has done any meaningful work on job A.
What this means in practice is that any job added to the public worker queue must be able to be processed on any public worker thread and concurrently with any other job in the queue. If a job really needs to enforce a dependency with other jobs, it can do so by either waiting on the futures of the jobs it is dependent on or by creating the jobs that are dependent on it at the end of its execution. Combinations of these techniques can be used to create almost arbitrarily complex job behavior, but such job interactions inhibit maximum parallelism so we try to avoid them in our engine.
Public worker threads are mostly used by data-parallel systems that divide their work into some multiple of the number of public workers, enqueue jobs for each worker, and then, at some later point in the frame, wait on all the jobs’ futures. Examples of systems like this are animation, cloth simulation, physics, effects, and rendering. Although all of the users of the public job queue try to provide as much time as possible between adding work to the queue and blocking on its completion, work in the public job queue is considered high-priority and latency intolerant.
Systems that have work that can be processed asynchronously, but doesn’t meet the requirements of the public job queue, create private job queues. The primary reason for using a private job queue is that the work is long but latency tolerant, and we don’t want it delaying the latency intolerant work in the public job queue.
In Fracture, terrain deformation was processed in a private worker thread, consuming as much as 15 ms a frame but at low priority.
Terrain deformation in Fracture
Starting with F.E.A.R. 3, decals have used a private worker thread. The decal thread generates and clips geometry from a queue. Although the queue might hold several hundred milliseconds of work, it will happily take only what time slices it can get from a single thread until it finishes its backlog.
We also use private worker threads for systems that have restrictions on their degree of parallelism or that perform primarily blocking work. Save data serialization, background resource loading, audio processing, network transport, and, on the PC, communication with the primary Direct3D context fall into this category.
I’ve had occasion over the years to use the Despair concurrency manager for a wide variety of tasks with a wide range of requirements, and I have very few complaints. I find the system simple and intuitive, and it is usually immediately obvious, given a new task, whether a private or public job queue is appropriate. I’ve occasionally wished for a richer set of scheduling options within the job queues themselves, but I ultimately believe that complex scheduling requirements are a symptom of bad multithreaded design and that if complex scheduling truly is justified, it is better handled within the jobs themselves.
The one area where scheduling has given me a lot of trouble, however, and where I wish we could offer some improvement, is in the interaction of public and private worker threads. When the platform, code, and content are reasonably stable, it isn’t too difficult to arrange the public and private workers such that they share the available processor resources efficiently.
On the Xbox 360, for example, where there are 6 hardware threads available, we have the main thread with affinity to hardware thread 0, four public worker threads with separate affinity to hardware threads 1, 2, 3, and 5, and most of our private worker threads sharing affinity with hardware thread 4. This arrangement ensures that the main thread and the public workers are never interrupted by the private worker threads, and it means that the private workers get a roughly equal share of an entire hardware thread. We know exactly how fast the hardware is and we can predict with a high degree of accuracy how much work each private worker will receive, so we don’t need to worry about oversubscription or underutilization of hardware thread 4.
In cases where the private worker threads aren’t sharing the load in a way we consider optimal, we can tweak either the hardware thread affinity or the software thread priorities to get the behavior we want. For example, in F.E.A.R. 3 we offloaded some marshaling of data for network transport to a private worker thread. Jobs for that thread were generated near the end of each frame and they had to be completed near the beginning of the following frame. If the private workers were left to the OS scheduler, the decal thread might preempt the network thread during that crucial window and cause a stall in the next frame. Since we knew the network thread never generated more than 5-6 ms of single-threaded work, we could safely boost its thread priority and ensure that it was never preempted by decals.
In another case where we weren’t 100% satisfied with the default scheduling of a private worker, we moved the private worker to share a hardware thread with one of the public workers but also lowered its thread priority. The luxury of a fixed, single-process platform is that we can hand tune the thread layout and be confident that our results will match those of our customers.
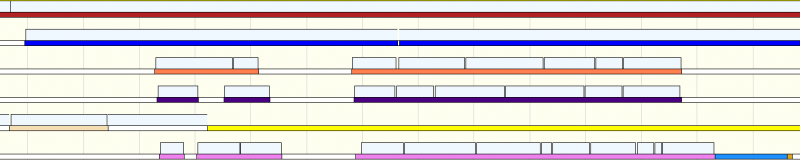
Example hardware thread utilization in F.E.A.R. 3, as captured by PIX on the Xbox 360
In the capture above you can see examples of both the situations I described. The thin colored lines represent software threads and the thick blocks above them represent individual jobs. A high priority audio thread, shown in yellow, interrupts a job on hardware thread 4, but that’s okay because the job being interrupted is latency tolerant. Later in the frame another thread, shown in light blue, schedules nicely with the latency intolerant jobs in the pink public worker on hardware thread 5.
The PC is where things get messy. On the PC we worry most about two different configurations. One is the low end, which for us is a dual core CPU, and the other is the high end, which is a hyper-threaded quad core CPU.
Currently, on the PC we allocate MAX(1, num_logical_processors-2) public worker threads. On a hyper-threaded quad core that means 6 public worker threads and on a dual core that means just 1 public worker thread. Unlike on the Xbox 360, however, we don’t specify explicit processor affinities for our threads, nor do we adjust thread priorities (except for obvious cases like an audio mixer thread). We don’t know what other processes might be running concurrently with our game and, with variations in drivers and platform configurations, we don’t even know what other third-party threads might be running in our process. Constraining the Windows scheduler with affinities and thread priorities will likely lead to poor processor utilization or even thread starvation.
That’s the convention wisdom anyway, but it sure doesn’t look pretty in profiles. From a bird’s eye view the job system appears to work as expected on the PC. As the number of cores increase, the game gets faster. Success! If it weren’t for our internal thread profiler and the Concurrency Visualizer in Visual Studio 2010 we’d probably have been happy with that and moved on.
On high-end PCs things aren’t too bad. Both our job queue visualization and Visual Studio’s thread visualization sometimes show disappointing utilization of our public workers, but that’s not necessarily a problem. We know we’re oversubscribed because we have more software threads created by the engine than there are hardware threads and there are at least 3 other third-party threads in our process doing meaningful work not to mention the other processes in the system. One of the benefits of a thread pool is that the number of participating threads can scale with the environment. Thankfully the behavior we usually see in these cases is fewer public workers tackling more jobs rather than all public workers starting jobs and then some being preempted, which would block the job queue until they can be rescheduled.
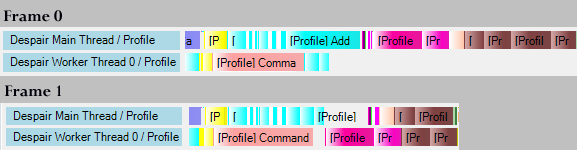
Job visualization from the same portion of two adjacent frames on a dual core PC
The image above is an example from our internal thread profiler. I had to zoom and crop it a bit to fit on the page, but what you’re seeing is the same portion of two frames on a dual core machine. The colored blocks represent jobs. You can see in the first frame a long stretch in which the main thread is processing jobs while the single worker thread is sitting idle. The next frame shows the intended behavior, with both the main thread and the worker thread processing jobs equally. We can’t visualize third-party threads or other processes with our internal profiler, so we have to turn to Visual Studio’s profiler to see what’s preempting our worker in that first frame. In our case it is usually the video driver or audio processor, but really any thread could be at fault. The more active threads in the system, including our own private workers, the more likely this sort of interference becomes.
The other behavior that is a little disappointing on many-core PCs is the high percentage of cross-core context switches. The Windows scheduler prioritizes quite a few factors above keeping a thread on its current core, so it isn’t too big a surprise for threads to jump cores in an oversubscribed system. The cost is some nebulous decrease in CPU cache coherency that is all but impossible to measure. Short of setting explicit processor affinities for our threads, which hurts overall performance, I haven’t had any luck improving this behavior. I had hoped to combat this effect with SetThreadIdealProcessor, but I haven’t actually been able to detect any change in scheduling when calling this function so we don’t use it.
On a high-end PC, as Louis C.K. might say, these are first world problems. With 8 logical processors we can afford to be less than perfect. From my profiles, even the best PC games are barely utilizing 30% of an 8 processor PC, and we’re comfortably within that range so I’m not complaining.
On dual core machines these issues can’t be ignored. With only two hardware threads, we’re now massively oversubscribed. The particularly difficult situation that we have to cope with is when all of our private workers are fully occupied at the same time. As I explained earlier, the decal thread is latency tolerant, but it can buffer far more than a single frame’s worth of work. This means that, left unchallenged, it alone can consume a full core for a full frame. Video drivers usually have their own threads which might, under heavy load, consume 25% of a core, audio might want another 20%, and Steam another 20%. All told we can have two thirds of a core’s worth of work in miscellaneous secondary threads and another full cores’s worth of work in the decal thread. That’s 1.7 cores worth of work competing on a level playing field with the main job queue on a machine with only 2 cores!
For most of these threads we have a general optimization problem more than a concurrency problem. We don’t have much flexibility in when or how they run, we just need to lower their cost. The decal thread, on the other hand, is different. Its purpose is to periodically consume far more work than would normally be budgeted for a single frame and to amortize the cost of that work over multiple frames. If it is impacting the execution of other threads then it isn’t doing its job.
My first reaction to this problem was, as usual, to wish for a more sophisticated scheduler in the public job queue. It seemed as though an easy solution would be to stick decal jobs in the public job queue and to instruct the scheduler to budget some fraction of every second to decal processing while trying to schedule decal jobs only at times when no other jobs are pending. After some consideration, however, I realized that this was asking too much of the scheduler and, perversely, would still require a lot of work in the decal system itself. Since the job scheduler isn’t preemptive, even a powerful system of budgets and priorities would rely on the jobs themselves being of sufficiently small granularity. The decal system would have to break up large jobs to assist the scheduler or, similarly, implement a cooperative yielding strategy that returned control to the scheduler mid-execution.
In addition to assisting the scheduler, the decal system would also have to become aware of how its rate of production was being throttled. Since decal resources are recycled using a heuristic that is heavily LRU, the decal system must manage the rate of input requests to match the rate of production in order to ensure that decals aren’t being recycled as soon as they are created.
It seems that any additional complexity added to the job scheduler is going to require equal complexity to be added to the decal system in order to take advantage of it. That’s always a red flag for me in systems design.
I’m still weighing some options for dealing with the decal thread, but my current favorite is to swallow my fears and seek help from the OS thread scheduler. If we reduce the thread priority of the decal thread under Windows, it will only be given time when the cores would otherwise be idle. However, since Windows implements thread boosts, even in a completely saturated environment the decal thread won’t starve completely. Nevertheless, this is a risky strategy because it creates the ability for the decal thread to block other threads through priority inversion. This probably isn’t a scalable long-term solution, but given our current thread layout and hardware targets, it achieves the desired result.
The difficulty of achieving maximum throughput on multicore processors is something that is often talked about in games, but what is less often talked about is how much harder this is on the PC than on the consoles. Maximizing throughout on high-end PCs is great, but, as I’ve shown, it must be done without sacrificing response time on low-end PCs. With our current approach I’ve been pretty pleased with our progress in this area, but I’m nevertheless having a hard time envisioning a day when we can fully utilize the resources of an 8 processor machine and still continue to provide a compatible play experience on a lowly dual core.
Hopefully by that time we’ll have broad support for GPGPU tasks as well as the scheduling flexibility to rely on them for more of our latency tolerant work.
Tagged: concurrency · Despair Engine · F.E.A.R. 3 · Fracture · optimization
The Hole That dlmalloc Can’t Fill
dlmalloc
Dlmalloc is a general-purpose memory allocator developed by Doug Lea since 1987. It is highly optimized, easily portable, and elegantly designed. It functions as a drop-in replacement for malloc and the source has been generously released into the public domain. The code is also an absolute joy to read, with every line conveying volumes of careful intention—optimizations, bug fixes, and refinements thoughtfully integrated over the years. With so many positive attributes to recommend it, it is no wonder dlmalloc has become the gold standard for memory allocators and a popular choice for game developers. It is also really unfortunate, because dlmalloc is a terrible allocator for today’s game consoles.
To understand why this is, you must first have an overview of dlmalloc’s interface and how it works. Dlmalloc manages a pool of address space composed of one or more discrete regions called segments. Dlmalloc’s pool can optionally grow or shrink through user-provided callbacks to allocate new segments and free unused ones. The “grow” callback is triggered when dlmalloc can’t satisfy an allocation request within its currently managed pool of memory and the “shrink” callback is triggered when dlmalloc detects that a segment is no longer occupied by any allocations. The grow callback is typically implemented with OS-level functions that allocate memory such as VirtualAlloc, mmap, or sbrk.
Dlmalloc is a boundary tag allocator at its heart, so segments are treated like new nodes in an intrusive linked list and are written with small headers or footers. The important thing to note about this is that dlmalloc requires that all memory it manages be readable and writable. The grow callback can return virtual memory, but it must already be committed (mapped to physical memory) in order for dlmalloc to function.
Another important characteristic of dlmalloc is that while it can return segments through the use of the shrink callback, it is not very aggressive in doing so. Segments are stored in a linked list and the only way for dlmalloc to coalesce adjacent segments or find empty segments is to perform a linear traversal of that list. For some users segments may be very large in size and very small in number so the linear traversal is cheap, but for most users segment management isn’t worth the cost, and dlmalloc’s default configuration is to only consider the most recently allocated segment when looking for segments to merge or release.
This is significant because it means dlmalloc’s callbacks can’t be used to allocate and commit individual pages of virtual memory. Trying to use dlmalloc with a segment equivalent to a virtual memory page would be prohibitively expensive or pointless depending on the configuration.
So to summarize, dlmalloc has no support for virtual memory.
This may seem like a crippling limitation for such a popular allocator, but in practice it affects very few systems. In fact, if a system meets any of the following requirements, dlmalloc’s blind spot when it comes to virtual memory is almost completely irrelevant.
Demand Paging
Almost all general-purpose computers these days have an operating system that features demand paging. With demand paging, the operating system keeps track of which pages of virtual memory are needed by the system and tries to keep only those pages resident in memory. In other words, dlmalloc doesn’t have to bother with the difficult work of committing and decommitting pages because the OS is already doing a pretty good job of it.
More Physical Memory than Virtual Address Space
In the consumer space, most applications are 32-bit and run on machines with more than 2 gigabytes of memory. This includes the most recent big-budget PC games like Crysis, Battlefield, Call of Duty, and Batman since they all have minimum system requirements of at least 2 gigabytes of main memory. If dlmalloc can commit all of the available address space without penalty, it has no reason not to do it.
No Virtual Memory or Predictable Allocation Pattern
Embedded systems are likely to have no virtual memory or to have very predictable allocation patterns that don’t benefit from virtual memory. The fact that dlmalloc sacrifices virtual memory support and dynamic segment management in favor of speed and simplicity is actually a perk for embedded systems.
Which Brings Us to Modern Consoles
Modern game consoles are unusual in that they don’t match any of the above criteria. Both the Xbox 360 and the Playstation 3 have rich support for virtual memory, but the operating systems on the two consoles offer limited or no support for demand paging. The Xbox 360 has 512 megabytes of physical memory to back its virtual address space and the Playstation 3 has 256 megabytes. Both consoles provide games with significantly more virtual address space than physical memory, so there is a huge potential upside to managing them separately.
Why We Care About Virtual Memory
In the absence of demand paging, virtual memory exists for one purpose only—to reduce the cost of fragmentation. Fragmentation occurs in any allocator that manages variable-sized blocks of memory which can be freed in arbitrary order. Consider the diagrams below. The green blocks are allocations in a system with 10 megabytes of memory. In the first diagram, most of the available memory has been allocated in variable-sized amounts. In the second diagram, some of those allocations have been freed. There are more than 4 megabytes of memory available in diagram 2, but even a 2 megabyte allocation will fail because there are no contiguous blocks of memory large enough to place it. This phenomenon is known as fragmentation.
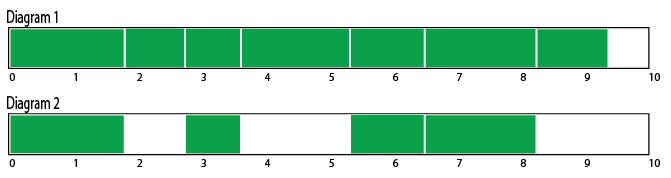
Fragmentation can be a huge problem with any general-purpose allocator. The less predictable an application’s allocation patterns and the larger the range of its allocation sizes, the more susceptible it is to allocation failure due to fragmentation. Most console games are large, complex systems integrating code from multiple sources and trying to satisfy a wide range of allocation patterns. At the same time, the game industry is very competitive, so console games are expected to take maximum advantage of the console hardware’s capabilities. You simply can’t do that without tackling the problem of memory fragmentation.
The most surefire way to avoid memory fragmentation is to only manage memory in fixed-size blocks. If every allocation is the same size, any hole left by one allocation can be filled perfectly by another. Unfortunately requiring that all memory requests be the same size is unreasonable, and trying to do so naively will only result in even more memory waste. This is where virtual memory comes in.
Virtual memory subdivides all physical memory into fixed-size blocks, known as pages, and provides a mechanism for contiguous allocations of virtual memory to span multiple nonadjacent pages. By adding this level of indirection, an application can be given an address the behaves like a block of contiguous memory, but under the hood is made up of separate fixed-size allocations of physical memory. This completely removes the problem of physical memory fragmentation, though it obviously creates the problem of virtual memory fragmentation. If virtual memory is limited to the same size as physical memory, you’re no better off than when you started. However, if virtual memory is allowed to be much larger than physical memory, even though fragmentation still exists, it is much less likely to ever cause an allocation failure.
The reason why virtual memory can be larger than physical memory is that unused pages of virtual memory don’t have to be backed by physical memory. As the name implies, it is virtual resource.
The next set of diagrams shows the exact same sequence of memory allocations as the earlier diagrams, but this time using a slightly larger pool of virtual memory. Allocations in virtual memory are still marked in green and free regions are still marked in white, but now the diagram is divided into 1 megabyte pages and any pages which are backed by physical memory are shaded with diagonal lines. In order for an allocation to succeed, it must fit into a free region of virtual memory that is backed by physical pages, ie. white areas shaded with diagonal lines.
In diagram 3 all 10 megabytes of physical memory are allocated, but there are still more than two megabytes of virtual memory available. A new 2 megabyte allocation could fit in virtual memory, but it will still fail because it can’t be backed by physical memory. In diagram 4 some allocations have been freed, and not only is there still 2 megabytes of contiguous virtual memory available, there are two free 1 megabyte physical memory pages available to back it. Diagram 5 shows the successful addition of a new 2 megabyte allocation, the same allocation that would have failed without virtual memory in diagram 2. If you count the number of physical pages that are allocated in diagram 5, you’ll see that we haven’t exceeded the system limit of 10 megabytes.
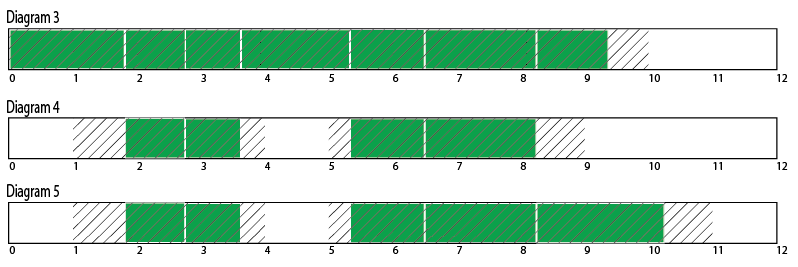
Notice that while we’ve succeeded in allocating an additional 2 megabytes despite fragmentation, we still have more than 2 megabytes of virtual memory left and yet we can’t service another 2 megabyte request. Virtual memory itself is now too fragmented. We could increase the amount of virtual memory without penalty to make room for another 2 megabyte allocation, but it doesn’t help because although we have 2 megabytes of physical memory that isn’t being used, we don’t have 2 free physical memory pages to back the new allocation.
For virtual memory to be an effective solution to fragmentation, you need a lot more virtual address space than physical memory and you need as small a page size as possible. On the Xbox 360 the default page size is 64 kilobytes and the on the Playstation 3 it is 1 megabyte, but both consoles support a range of page sizes. The best page size on consoles for compromising between performance and fragmentation is 64 KB, which begs the question, “why does the Playstation 3 default to 1 megabyte?” The answer is simple: the Playstation 3 uses dlmalloc for its general-purpose allocator and since dlmalloc doesn’t take advantage of virtual memory, there is no point in using a smaller page size!
Hopefully by now I’ve convinced you of the value of virtual memory and why dlmalloc isn’t the right choice for console games. In the future I’ll describe the general-purpose memory allocator I wrote for Despair Engine and how I used it to combat fragmentation. As a bonus, I’ll explain the larger memory management framework that I built on top of the allocator to reduce thread contention and to ensure that the entirety of memory is available to a heterogeneous set of processors, despite their non-unified views of virtual memory.
Tagged: Despair Engine · optimization
CrossStitch 2.0: Dynamic Shader Linking in a Statically Linked World
In my last article, I described the first generation of CrossStitch, the shader assembly system used in MechAssault 2. Today I’m going to write about the second generation of CrossStitch, the one used in Fracture.
Development on CrossStitch 2.0 began with the development of Day 1’s Despair Engine. This was right at the end of MechAssault 2, when the Xbox 360 was still an Apple G5 and the Cell processor was going to be powering everything from super computers to kitchen appliances in a few years. It is hard to believe looking back, but at that time we were still debating whether to adopt a high-level shading language for graphics. There were respected voices on the platform side insisting that the performance advantage of writing shaders in assembly language would justify the additional effort. Thankfully I sided with the HLSL proponents, but that left me with the difficult decision of what to do about CrossStitch.
CrossStitch was a relatively simple system targeting a single, very constrained platform. HLSL introduced multiple target profiles, generic shader outputs, and literal constants, not to mention a significantly more complex and powerful language syntax. Adding to that, Despair Engine was intended to be cross-platform, and we didn’t even have specs on some of the platforms we were promising to support. Because of this, we considered the possibility of dispensing with dynamic shader linking entirely and adopting a conventional HLSL pipeline, implementing our broad feature set with a mixture of compile-time, static, and dynamic branching. In the end, however, I had enjoyed so much success with the dynamic shader linking architecture of MechAssault 2, I couldn’t bear to accept either the performance cost of runtime branching or the clunky limitations of precomputing all possible shader permutations.
The decision was made: Despair Engine would feature CrossStitch 2.0. I don’t recall how long it took me to write the first version of CrossStitch 2.0. The early days of Despair development are a blur because we were supporting the completion of MechAssault 2 while bootstrapping an entirely new engine on a constantly shifting development platform and work was always proceeding on all fronts. I know that by December of 2004, however, Despair Engine had a functional implementation of dynamic shader linking in HLSL.
CrossStitch 2.0 is similar in design to its predecessor. It features a front-end compiler that transforms shader fragments into an intermediate binary, and a back-end linker that transforms a chain of fragments into a full shader program. The difference, of course, is that now the front-end compiler parses HLSL syntax and the back-end linker generates HLSL programs. Since CrossStitch 1.0 was mostly limited to vertex shaders with fixed output registers, CrossStitch 2.0 introduced a more flexible model for passing data between pipeline stages. Variables can define and be mapped to named input and output channels; and each shader chain requires an input signature from the stage preceding it and generates an output signature for the stage following it.

A sampling of early HLSL shader fragments.
CrossStitch’s primary concern is GPU runtime efficiency, so it is nice that shaders are compiled with full knowledge of the data they’ll be receiving either from vertex buffers or interpolators. If, for example, some meshes include per-vertex color and some don’t, the same series of shader fragments will generate separate programs optimized for each case. It turns out that this explicit binding of shader programs to attributes and interpolators is a common requirement of graphics hardware, and making the binding explicit in CrossStitch allows for some handy optimizations on fixed consoles.
The early results from CrossStitch 2.0 were extremely positive. The HLSL syntax was a nice break from assembly, and the dynamic fragment system allowed me to quickly and easily experiment with a wide range of options as our rendering pipeline matured. Just as had happened with MechAssault 2, the feature set of Despair expanded rapidly to become heavily reliant on the capabilities of CrossStitch. The relationship proved circular too. Just as CrossStitch facilitated a growth in Despair’s features, Despair’s features demanded a growth in CrossStitch’s capabilities.
The biggest example of this is Despair’s material editor, Façade. Façade is a graph-based editor that allows content creators to design extremely complex and flexible materials for every asset. The materials are presented as a single pipeline flow, taking generic mesh input attributes and transforming them through a series of operations into a common set of material output attributes. To implement Façade, I both harnessed and extended the power of CrossStitch. Every core node in a Facade material graph is a shader fragment. I added reflection support to the CrossStich compiler, so adding a new type of node to Façade is as simple as creating a new shader fragment and annotating its public-facing variables. Since CrossStitch abstracts away many of the differences between pipeline stages, Façade material graphs don’t differentiate between per-vertex and per-pixel operations. The flow of data between pipeline stages is managed automatically depending on the requirements of the graph.
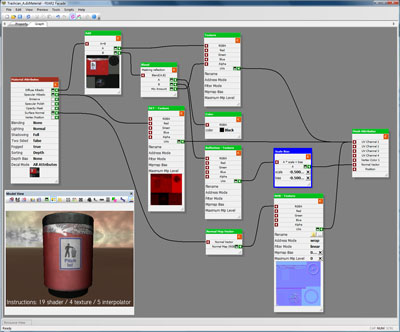
Façade Material Editor
It was about 6 months after the introduction of Façade when the first cracks in CrossStitch began to appear. The problem was shader compilation times. On MechAssault 2 we measured shader compilation times in microseconds. Loading a brand new level with no cached shader programs in MechAssault 2 might cause a half-second hitch as a hundred new shaders were compiled. If a few new shaders were encountered during actual play, a couple of extra milliseconds in a frame didn’t impact the designers’ ability to evaluate their work. Our initial HLSL shaders were probably a hundred times slower to compile than that on a high-end branch-friendly PC. By the end of 2005 we had moved to proper Xbox 360 development kits and our artists had mastered designing complex effects in Façade. Single shaders were now taking as long as several seconds to compile, and virtually every asset represented a half-dozen unique shaders.
The unexpected 4-5 decimal order of magnitude increase in shader compilation times proved disastrous. CrossStitch was supposed to allow the gameplay programmers, artists, and designers to remain blissfully ignorant of how the graphics feature set was implemented. Now, all of a sudden, everyone on the team was aware of the cost of shader compilation. The pause for shader compilation was long enough that it could easily be mistaken for a crash, and, since it was done entirely on the fly, on-screen notification of the event couldn’t be given until after it was complete. Attempts to make shader compilation asynchronous weren’t very successful because at best objects would pop in seconds after they were supposed to be visible and at worst a subset of the passes in a multipass process would be skipped resulting in unpredictable graphical artifacts. Making matters worse, the long delays at level load were followed by massive hitches as new shaders were encountered during play. It seemed like no matter how many times a designer played a level, new combinations of lighting and effects would be encountered and repeated second-long frame rate hitches would make evaluating the gameplay impossible.
Something had to be done and fast.
Simple optimization was never an option, because almost the entire cost of compilation was in the HLSL compiler itself. Instead I focused my efforts on the CrossStitch shader cache. The local cache was made smarter and more efficient, and extended so that multiple caches could be processed simultaneously. That allowed the QA staff to start checking in their shader caches, which meant tested assets came bundled with all their requisite shaders. Of course content creators frequently work with untested assets, so there was still a lot of unnecessary redundant shader compilation going on.
To further improve things we introduced a network shader cache. Shaders were still compiled on-target, but when a missing shader was encountered it would be fetched from a network server before being compiled locally. Clients updated servers with newly compiled shaders, and since Day 1 has multiple offices and supports distributed development, multiple servers had to be smart enough to act as proxies for one another.
With improvements to the shader cache, life with dynamic, on-the-fly shader compilation was tolerable but not great. The caching system has only had a few bugs in its lifetime, but it is far more complicated than you might expect and only really understood by a couple of people. Consequently, a sort of mythology has developed around the shader cache. Just as programmers will suggest a full rebuild to one another as a possible solution to an inexplicable code bug, content creators and testers can be heard asking each other, “have you tried deleting your shader cache?”
At the same time as I was making improvements to the shader cache, I was also working towards the goal of having all shaders needed for an asset compiled at the time the asset was loaded. I figured compiling shaders at load time would solve the in-game hitching problem and it also seemed like a necessary step towards my eventual goal of moving shader compilation offline. Unfortunately, doing that without fundamentally changing the nature and usage of CrossStitch was equivalent to solving the halting problem. CrossStitch exposes literally billions of possible shader programs to the content, taking advantage of the fact that only a small fraction of those will actually be used. Which fraction, however, is determined by a mind-bending, platform-specific tangle of artist content, lua script, and C++ code.
I remember feeling pretty pleased with myself at the end of MechAssault 2 when I learned that Far Cry required a 430 megabyte shader cache compared to MA2’s svelte 500 kilobyte cache. That satisfaction evaporated pretty quickly during the man-weeks I spent tracking down unpredicted shader combinations in Fracture.
Even so, by the time we entered full production on Fracture, shader compilation was about as good as it was ever going to get. A nightly build process loaded every production level and generated a fresh cache. The build process updated the network shader cache in addition to updating the shader cache distributed with resources, so the team had a nearly perfect cache to start each day with.
As if the time costs of shader compilation weren’t enough, CrossStitch suffered from an even worse problem on the Xbox 360. Fracture’s terrain system implemented a splatting system that composited multiple Facade materials into a localized über material, and then decomposed the über material into multiple passes according the register, sampler, and instruction limits of the target profile. The result was some truly insane shader programs.

The procedurally generated material for one pass of a terrain tile in Fracture.
A few Fracture terrain shaders took over 30 seconds to compile and consumed over 160 megabytes of memory in the process. Since the Xbox 360 development kits have no spare memory, this posed a major problem. There were times when the content creators would generate a shader that could not be compiled on target without running out of memory and crashing. It has only happened three times in five years, but we’ve actually had to run the game in a special, minimal memory mode in order to free up enough memory to compile a necessary shader for a particularly complex piece of content. Once the shader is present in the network cache, the offending content can be checked in and the rest of the team is none the wiser.
Such things are not unusual in game development, but it still kills me to be responsible for such a god-awful hack of a process.
And yet, CrossStitch continues to earn its keep. Having our own compiler bridging the gap between our shader code and the platform compiler has proved to be a very powerful thing. When we added support for the Playstation 3, Chris modified the CrossStitch back-end to compensate for little differences in the Cg compiler. When I began to worry that some of our shaders were interpolator bound on the Xbox 360, the CrossStitch back-end was modified to perform automatic interpolator packing. When I added support for Direct3D 10 and several texture formats went missing, CrossStitch allowed me to emulate the missing texture formats in late-bound fragments. There doesn’t seem to be a problem CrossStitch can’t solve, except, of course, for the staggering inefficiency of its on-target, on-the-fly compilation.
For our next project I’m going to remove CrossStitch from Despair. I’m going to do it with a scalpel if possible, but I’ll do it with a chainsaw if necessary. I’m nervous about it, because despite my angst and my disillusionment with dynamic shader compilation, Day 1’s artists are almost universally fans of the Despair renderer. They see Façade and the other elements of Despair graphics as a powerful and flexible package that lets them flex their artistic muscles. I can’t take that away from them, but I also can’t bear to write another line of code to work around the costs of on-the-fly shader compilation.
It is clear to me now what I didn’t want to accept five years ago. Everyone who has a say in it sees the evolution of GPU programs paralleling the evolution of CPU programs: code is static and data is dynamic. CrossStitch has had a good run, but fighting the prevailing trends is never a happy enterprise. Frameworks like DirectX Effects and CgFx have become far more full-featured and production-ready than I expected, and I’m reasonably confident I can find a way to map the majority of Despair’s graphics features onto them. Whatever I come up with, it will draw a clear line between the engine and its shaders and ensure that shaders can be compiled wherever and whenever future platforms demand.
Tagged: CrossStitch · Despair Engine · Fracture · rendering
CrossStitch: A Configurable Pipeline for Programmable Shading
Some pieces of code are a source of great pride and some pieces of code are a source of terrible shame. It is due to the nature of game development, I believe, that many of the most interesting pieces of code I write eventually become both. That is certainly the case with the CrossStitch shader assembler, my first significant undertaking in the field of computer graphics.
CrossStitch has been the foundation of Day 1’s graphics libraries for over seven years now, and for almost half of that time it has been a regular source of frustration and embarrassment for me. What I’d like to do is vent my frustration and write an article explaining all the ways in which I went wrong with CrossStitch and why, despite my hatred of it, I continue to put up with it. But before I can do that I need to write this article, a remembrance of where CrossStitch came from and how I once loved it so much.
My first job in the game industry had me implementing the in-game UI for a flight simulator. When that project was canceled, I switched to an adventure game, for which I handled tools and 3dsmax exporter work and later gameplay and graphical scripting language design. A couple years later I found myself in charge of the networking code for an action multiplayer title, and shortly after that I inherited the AI and audio code. Next I came back to scripting languages for a bit and worked with Lua integration, then I spent six months writing a physics engine before becoming the lead on the Xbox port of a PS2 title. I only had a few people reporting to me as platform lead, so my responsibilities ended up being core systems, memory management, file systems, optimization, and pipeline tools.
When I interviewed at Day 1, one of the senior engineers asked me what I thought my greatest weakness was as a game developer and I answered honestly that although I’d worked in almost every area of game development, I’d had little or no exposure to graphics. Imagine my surprise when less than a month after he hired me the studio director came to me and asked if I’d be willing to step into the role of graphics engineer. It turned out that both of Day 1’s previous graphics engineers had left shortly before my arrival, and the company was without anyone to fill the role. I was excited for the challenge and the opportunity to try something new, so I quickly accepted the position and went to work.
This left me in a very strange position, however. I was inheriting the graphics code from MechAssault, so I had a fully working, shippable code base to cut my teeth on, but I was also inheriting a code base with no owner in a discipline for which I had little training, little experience, and no available mentor. The title we were developing was MechAssault 2, and given that it was a second generation sequel to an unexpected hit, there was a lot of pressure to overhaul the code and attempt a major step forward in graphics quality.
The MechAssault 1 graphics engine was first generation Xbox exclusive, which meant fixed-function hardware vertex T&L and fixed-function fragment shading. As I began to familiarize myself with the code base and the hardware capabilities, I realized that in order to implement the sort of features that I envisioned for MechAssault 2, I’d need to convert the engine over to programmable shading. The Xbox had phenomenal vertex shading capability and extremely limited fragment shading capability, so I wanted to do a lot of work in the vertex shader and have the flexibility to pass data to the fragment shader in whatever clever arrangement would allow me to use just a couple instructions to apply whatever per-pixel transformations were necessary to get attractive results on screen.
The problem was that shaders are monolithic single-purpose programs and the entire feature set and design of the graphics engine were reliant on the dynamic, mix-and-match capabilities of the fixed-function architecture. This is where my lack of experience in graphics and my lack of familiarity with the engine became a problem, because although I was feeling held back by it, I didn’t feel comfortable cutting existing features or otherwise compromising the existing code. I wanted the power of programmable shading, but I needed it in the form of a configurable, fixed-function-like pipeline that would be compatible with the architecture I had inherited.
I pondered this dilemma for a few days and eventually a plan for a new programmable shader pipeline started to emerge. I asked the studio director if I could experiment with converting the graphics engine from fixed-function to programmable shaders, and he found two weeks in the schedule for me to try. Our agreement was that in order to claim success at the end of two weeks, I had to have our existing feature set working in programmable shaders and I had to be able to show no decrease in memory or performance.
My plan was to write a compiler and linker for a new type of shader program, called shader fragments. Instead of an object in the game having to specify its entire shader program in a single step, the code path that led to rendering an object would be able to add any number of shader fragments to a list, called a shader chain, and finally the chain would be linked together into a full shader program in time for the object to draw.
My first task was to define the syntax for shader fragments. I had very limited time so I started with an easily parsable syntax, XML. Fragments consisted of any number of named variables, any number of constant parameters, and a single block of shader assembly code. Named variables were either local or global in scope, and they could specify several options such as default initialization, input source (for reading data from vertex attributes), output name (for passing data to fragment shaders), and read-only or write-only flags.
I wrote a simple C preprocessor, an XML parser, and a compiler to transform my fragments into byte-code. Compiled fragments were linked directly into the executable along with a header file defining the constant parameter names. Rendering of every object began with clearing the current shader chain and adding a fragment that defined some common global variables with default values. For example, diffuse was a global, one-initialized variable available to every shader chain and screen_pos was a global variable mapped to the vertex shader position output. Once the default variables were defined, a mesh might add a new fragment that defined a global variable, vertex_diffuse, with initialization from a vertex attribute and additional global variables for world-space position and normals. Depending on the type of mesh, world-space position might be a rigid transformation of the vertex position, a single or multi-bone skinned transformation of the vertex position, or a procedurally generated position from a height field or particle system.
 Common variables were defined for all shader chains. Common variables were defined for all shader chains. |
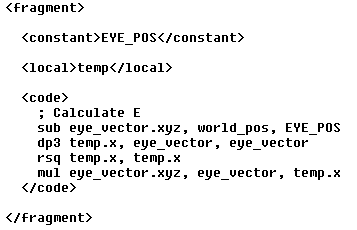 A shader fragment for generating the eye vector. A shader fragment for generating the eye vector. |
|---|
With world-space position and normals defined, other systems could then add fragments to accumulate per-vertex lighting into the global diffuse variable and to modulate diffuse by material_diffuse or vertex_diffuse. Systems could also continue to define new variables and outputs, for example per-vertex fog or, in the case of per-pixel lighting, tangent space. Precedence rules also allowed fragments to remap the inputs or outputs or change the default initialization of variables defined in earlier fragments.
 Custom height fog was implemented in shader fragments. Custom height fog was implemented in shader fragments. |
 Particles were generated in shader fragments. Particles were generated in shader fragments. |
|---|
The final step in rendering an object was to transform the active shader chain into a shader program. Shader programs were compiled on the fly whenever a new shader chain was encountered, resulting in a small but noticeable frame rate hitch. Luckily, the shader programs were cached to disk between runs so the impact of new shader compilations was minimal. I had promised to add no additional CPU or GPU cost to rendering, so I put a lot of care into the code for adding shader fragments to shader chains and for looking up the corresponding shader programs.
It was a nerve-racking few weeks for me, however, because it wasn’t until I’d implemented the entire system and replaced every fixed-function feature supported by the engine with equivalent shader fragments that I was able to do side-by-side performance comparisons. Amazingly, the CPU costs ended up being nearly indistinguishable. Setting state through the fixed-function calls or setting shader constants and shader fragments was so close in performance that victory by even a narrow margin couldn’t be determined.
The results on the GPU were equally interesting. The vertex shader implementation outperformed the fixed-function equivalent for everything except lighting. Simple materials with little or no lighting averaged 10 – 20% faster in vertex shader form. As the number of lights affecting a material increased, however, the margin dropped until the fixed-function implementation took the lead. Our most complex lighting arrangement, a material with ambient, directional, and 3 point lights, was 25% slower on the GPU when implemented in a vertex shader. With the mix of materials in our MechAssault levels, the amortized results ended up being about a 5% drop in vertex throughput. This wasn’t a big concern for me, however, because we weren’t even close to being vertex bound on the Xbox, and there were several changes I wanted to make to the lighting model that weren’t possible in fixed-function but would shave a few instructions off the light shaders.
The studio director was pleased with the results, so I checked in my code and overnight the game went from purely fixed-function graphics to purely programmable shaders. The shader fragment system, which I named CrossStitch, opened up the engine to a huge variety of GPU-based effects, and the feature set of the engine grew rapidly to become completely dependent on shader fragments. By the time we shipped MechAssault 2, our rendering was composed of over 100 unique shader fragments. These fragments represented billions of possible shader program permutations, though thankfully only a little more than 500 were present in our final content.
Here are some examples of features in MechAssault 2 that were made possible by shader fragments:
- a new particle effects system which offloaded some of the simulation costs to the GPU
- procedural vertex animation for waving flags and twisting foliage
- a space-warp effect attached to certain explosions and projectiles that deformed the geometry of nearby objects
- mesh bloating and stretching modifiers for overlay shields and motion blur effects
- GPU-based shadow volume extrusion
- per-vertex and per-pixel lighting with numerous light types and variable numbers of lights
- GPU-based procedural UV generation for projected textures, gobo lights, and decals
- content-dependent mesh compression with GPU-based decompression
 A mech explosion deforms nearby objects. A mech explosion deforms nearby objects. |
|---|
By the end of MechAssault 2 I was convinced CrossStitch was the only way to program graphics. I absolutely loved the dynamic shader assembly model I’d implemented, and I never had a second’s regret over it. It was fast, memory efficient, and allowed me to think about graphics in the way I found most natural, as a powerful configurable pipeline of discrete transformations. If only the story could end there.
In the future I’ll have to write a follow up to this article describing how CrossStitch evolved after MechAssault 2. I’ll have to explain how it grew in sophistication and capability to keep pace with the advances in 3-D hardware, to support high-level language syntax and to abstract away the increasing number of programmable hardware stages. I’ll have to explain why the path it followed seemed like such a good one, offering the seduction of fabulous visuals at minimal runtime cost. But most importantly, I’ll have to explain how far along that path I was before I realized it was headed in a direction I didn’t want to be going, a direction completely divergent with the rest of the industry.
Tagged: CrossStitch · MechAssault · rendering