Gerard de Melo's Projects and Resources (original) (raw)
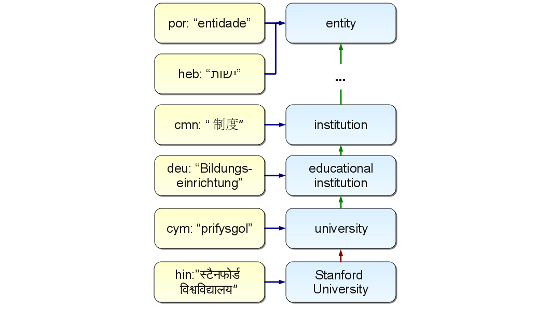
One of the largest multilingual knowledge graphs, transforming the well-known WordNet database into a massively multilingual resource covering over 1 million words and several million named entities in a single semantically organized hierarchy. This is based on machine learning along with the MENTA extension based on Wikipedia. Our derivative project OpenWordNet-PT (GitHub) is being used by Google Translate.
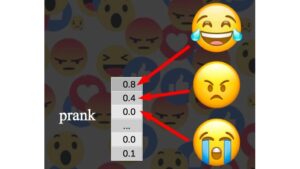
Datasets and resources for sentiment analysis and fine-grained emotion analysis, in part available for multiple languages.

We contributed to this massive data augmentation library.

A community effort to create a massive evaluation suite for large language models.

Pyramid Evaluation of summary quality using Automated Knowledge extraction — A method for evaluating the quality of a summary (e.g., one written by students) using the Pyramid method, which is known to be significantly more reliable than the ROUGE method when evaluating individual summaries.
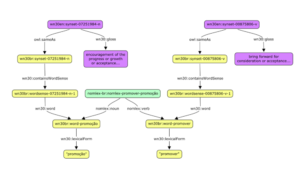
Lexical resource providing information about Portuguese nominalizations.
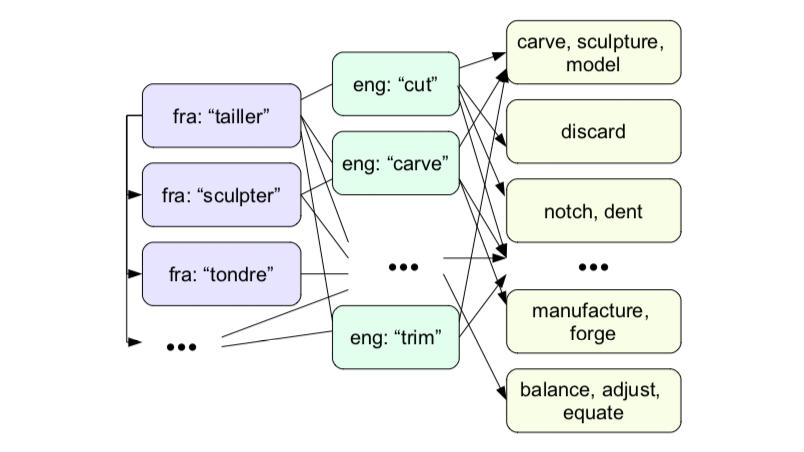
Thesauri in many languages, obtained by translating Roget's Thesaurus using task-specific statistical techniques
Large spelling correction training datasets that enable deep learning-powered context-sensitive spelling correction.
Cross-Lingual Code-Switching Dataset 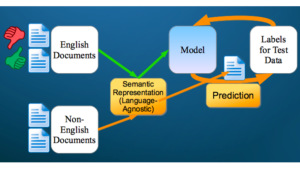
A dataset to evaluate cross-lingual representation learning and text classification systems. This benchmark requires training on English training data but testing on documents that mix English and non-English words.

A new more user-friendly browsing interface for the FrameNet lexical semantic resource, which describes the semantic roles of sentences and words.

A Swedish thesaurus based on Sven Casper Bring's Svenskt ordförråd ordnat i begreppsklasser but reorganized and modernized.