Graduate School of Informatics (original) (raw)
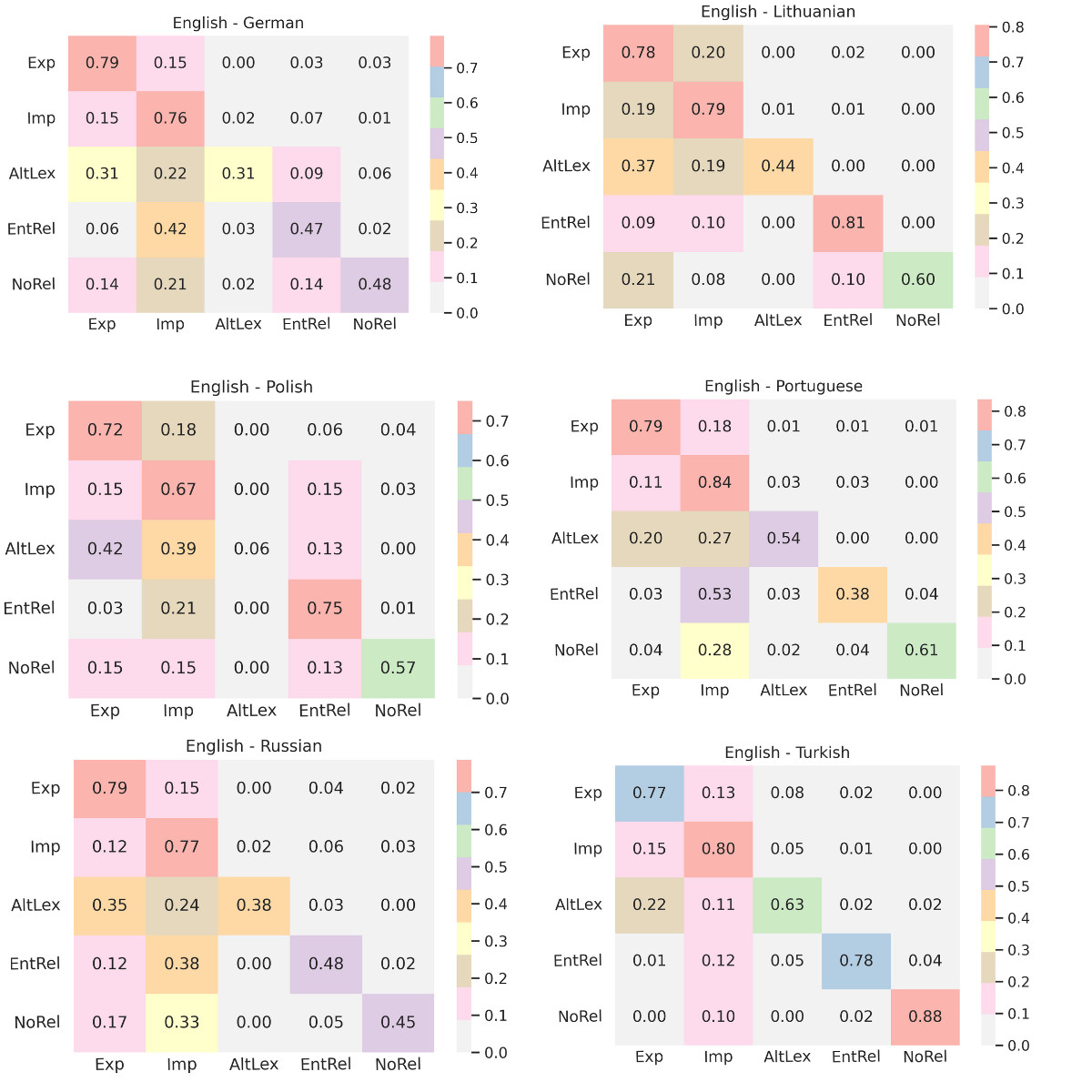
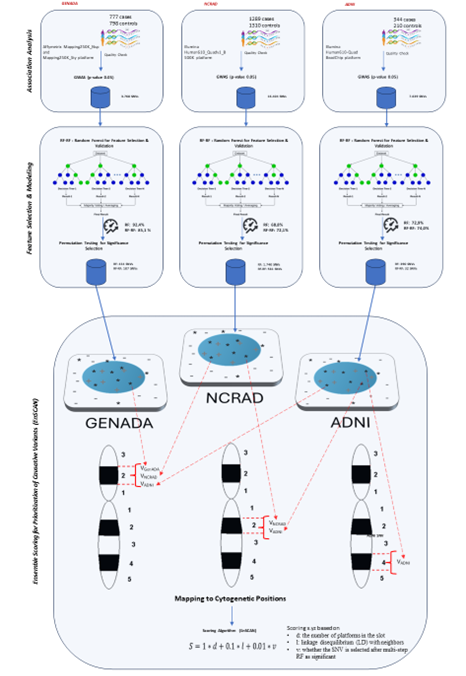
Introducing the EnSCAN framework, we propose a pioneering algorithm to consolidate selected variants even across distinct platforms, thereby prioritizing candidate causative loci and enhancing ML outcomes through combining prior information captured from each multi-model of each dataset. The proposed ensemble algorithm utilizes chromosomal locations of SNVs by mapping to cytogenetic bands, along with the proximities between pairs and multi-model via Random Forest validations to prioritize SNVs and candidate causative genes for Alzheimer Disease. The scoring method is scalable and can be applied to any multi-platform genotyping study. We present how the proposed EnSCAN scoring algorithm prioritizes the candidate causative variants related to LOAD among three GWAS datasets.
Date: 06.09.2024 / 16:00 Place: B-116
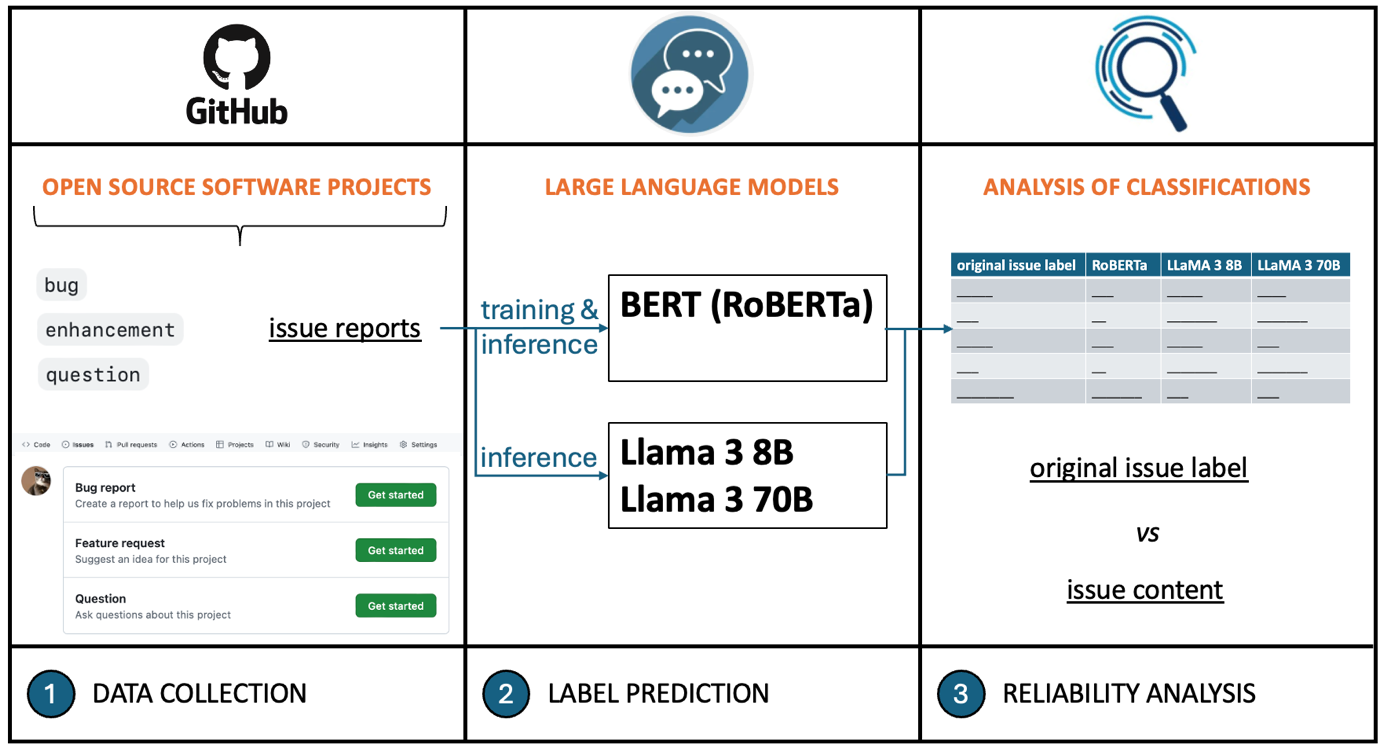
In the evolving landscape of open source software projects, effective issue management remains a pivotal aspect of sustaining project success. Issue reports provide valuable information as they are created for reporting bugs, requesting new features, or asking questions about a software product. The high number of issue reports, which vary widely in quality, requires accurate issue classification mechanisms to prioritize work and manage resources effectively. Properly assigned issue labels are crucial for effective project management and for the reliability of research conducted to improve issue management as they often assume the assigned issue labels as the ground truth. This study aims to assess the reliability of the assigned issue labels in open source software development projects to improve issue management processes. The research involves collecting two datasets of issue reports from open source software development projects hosted on GitHub. Experiments were conducted with the state-of-the-art large language models for issue label classification. Furthermore, a qualitative analysis was performed to evaluate the relevance of the assigned issue labels with respect to the content of the issues. The empirical study performed on issue reports revealed a significant mismatch between the assigned labels and the actual content of the issues. The study also demonstrated the effectiveness of the state-of-the-art large language models in classifying issue labels, highlighting concerns about the reliability of issue labels in open source software development projects.
Date: 06.09.2024 / 11:00 Place: A-108
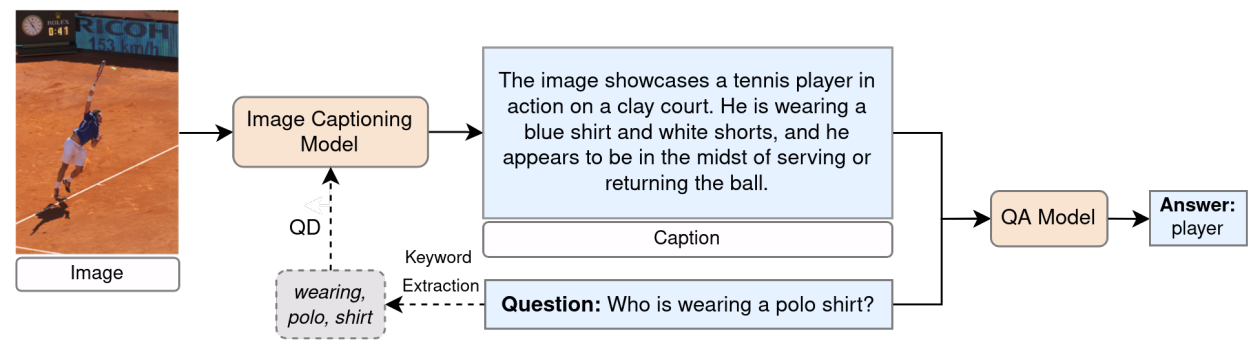
Visual Question Answering (VQA) is defined as an AI-complete task that requires understanding, reasoning, and inference of both visual and language content. Despite recent advancements in neural architectures, zero-shot VQA remains a significant challenge due to the demand for advanced generalization and reasoning skills. This thesis aims to explore the capabilities of recent Large Language Models (LLMs) in zero-shot VQA. Specifically, it evaluates the performance of multimodal LLMs such as CogVLM, GPT-4, and GPT-4o on the GQA dataset, which includes a diverse range of questions designed to assess reasoning abilities. A new framework for VQA is proposed, leveraging LLMs and integrating image captioning as an intermediate step. Additionally, the thesis examines the effect of different prompting techniques on VQA performance. Evaluations are conducted on questions that vary semantically and structurally. The findings highlight the potential of using image captions and optimized prompts to enhance VQA performance under zero-shot setting.
Date: 04.09.2024 / 13:30 Place: A-212
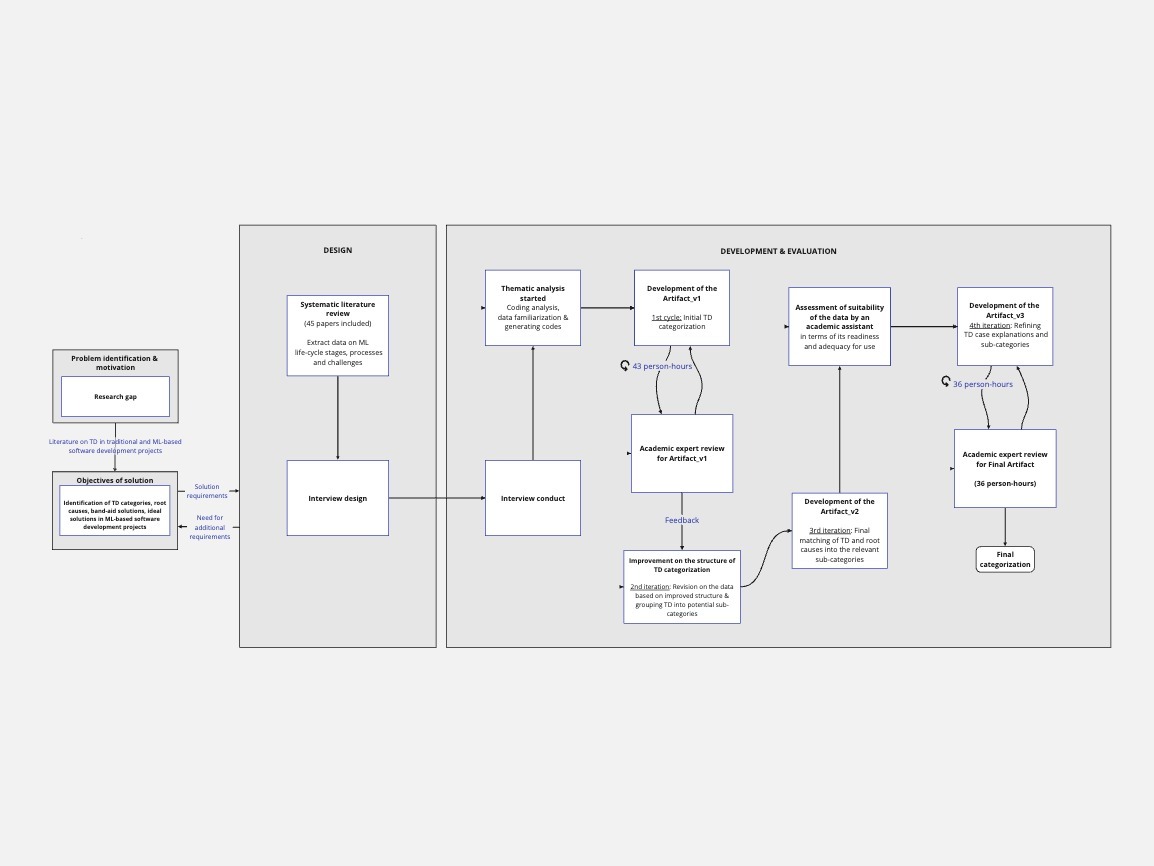
Pelin Dayan Akman, Analysis of Technical Debt in ML-based Software Development Projects
This research addresses the multifaceted nature of Technical Debt (TD) in Machine Learning (ML) projects, distinct from traditional software projects due to their probabilistic nature and data dependency. The study systematically examines how TD manifests across various dimensions in ML projects, identifying root causes, impacts, and band-aid solutions contributing to its persistence. ML-specific TD was categorized through thematic analysis of interviews with industry professionals. The findings were reviewed by academic experts in multiple iterations. This study fills a gap in the literature and offers practical insights for managing TD in ML contexts, as well as a TD-oriented structure for its assessment.
Date: 06.09.2024 / 09:30 Place: A-212
This thesis investigates cross-linguistic differences in realizing discourse relations, centered on the TED-MDB corpus. By developing a framework for aligning discourse relation annotations in parallel corpora, the study explores variations in discourse relation realization, semantic shifts, and inter-sentential encoding patterns across languages. Key findings highlight the importance of discourse relation linking, revealing differences in the translation of discourse connectives. Also, this study develops method for bilingual lexicon induction from aligned data, supporting pragmatic studies and natural language processing systems. Future work includes adapting discourse relation-aligned data to Linked Language Open Data (LLOD) standards for better accessibility and interoperability.
Date: 04.09.2024 / 10:00 Place: A-212