 |
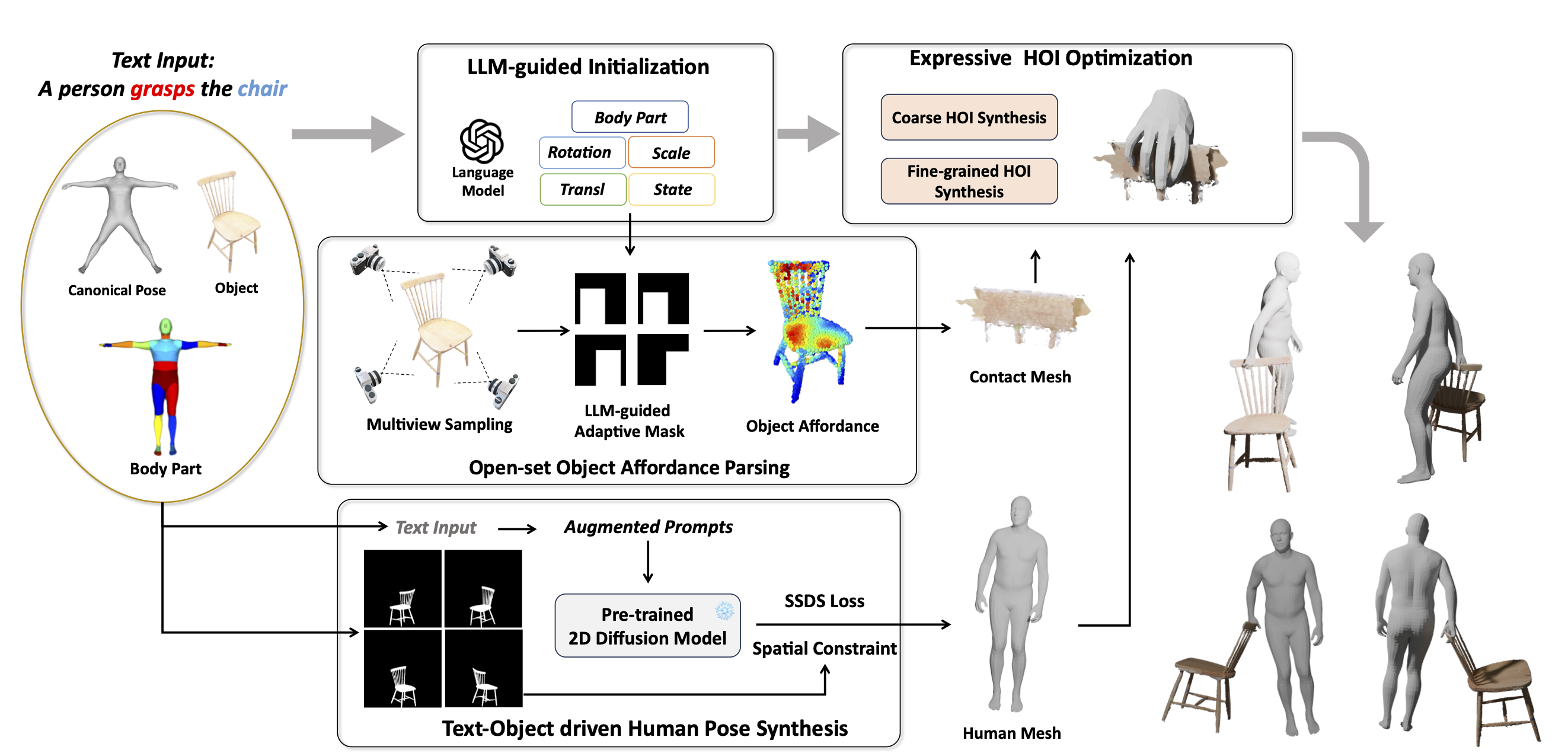
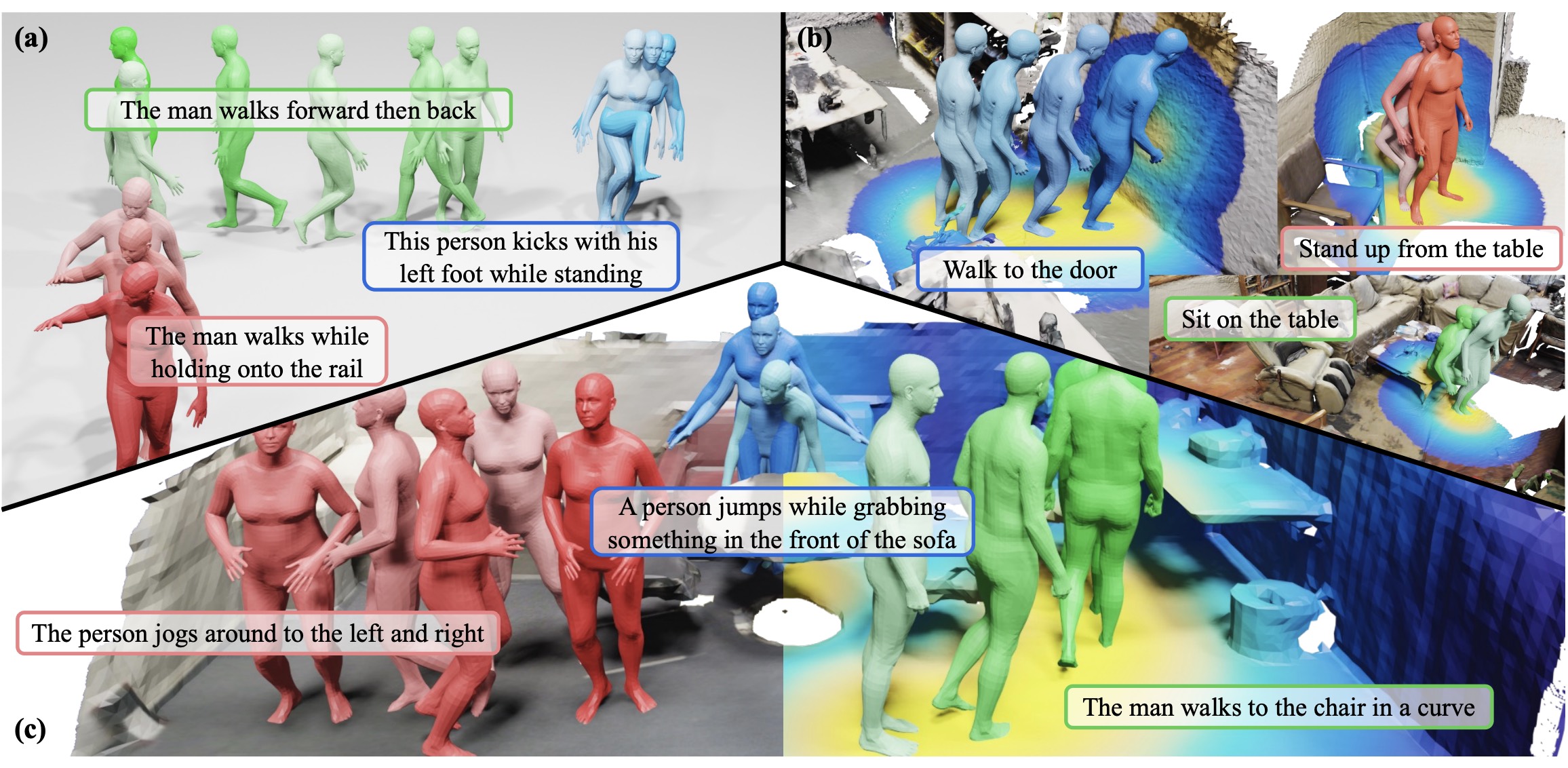
InteractAnything: Zero-shot Human Object Interaction Synthesis via LLM Feedback and Object Affordance Parsing Jinlu Zhang ,Yixin Chen,Zan Wang,Jie Yang,Yizhou Wang,Siyuan Huang IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 Highlight Project page/Paper Abstract In this work, we propose a novel zero-shot 3D HOI generation framework without training on specific datasets, leveraging the knowledge from large-scale pre-trained models. |
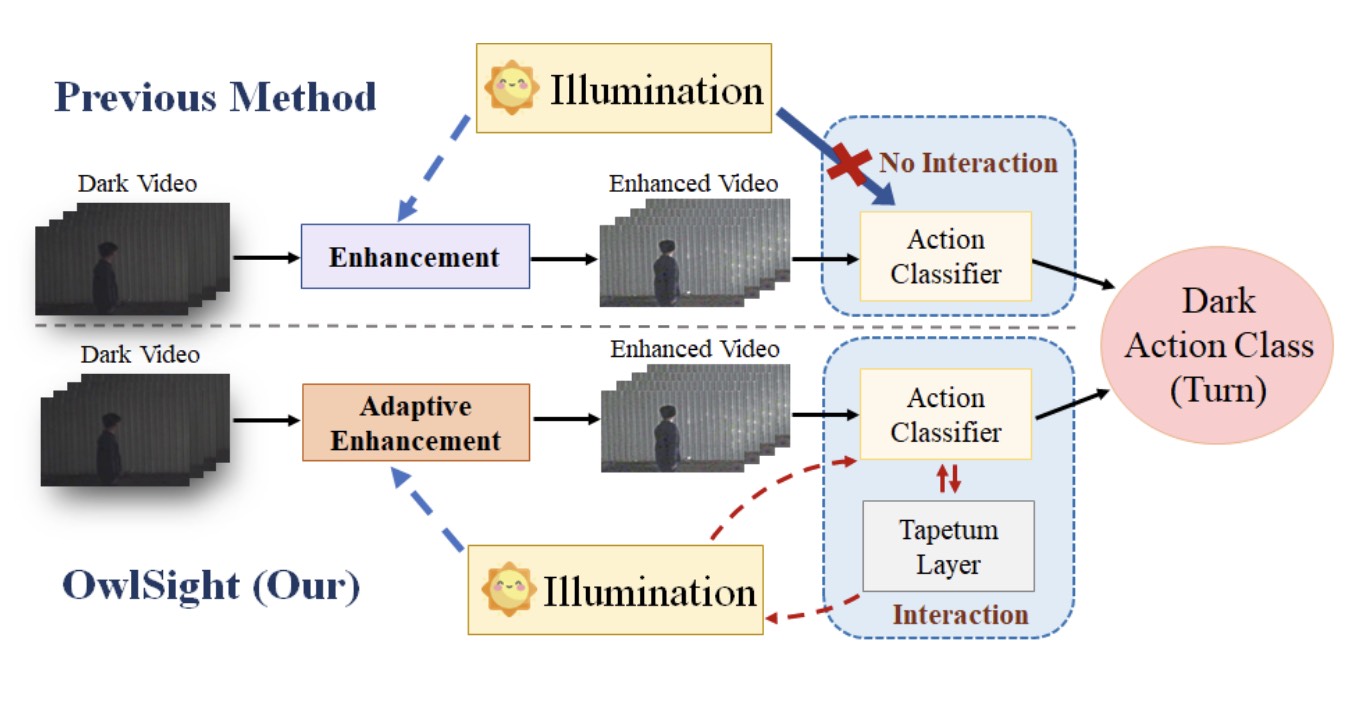 |
OwlSight: A Robust Illumination Adaptation Framework for Dark Video Human Action Recognition Shihao Cheng*,Jinlu Zhang*, Yue Liu, Aoran Xiao,Zhigang Tu IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2025 Paper Abstract We propose OwlSight, a biomimetic-inspired framework with whole-stage illumination enhancement to interact with action classification for accurate dark video human action recognition. |
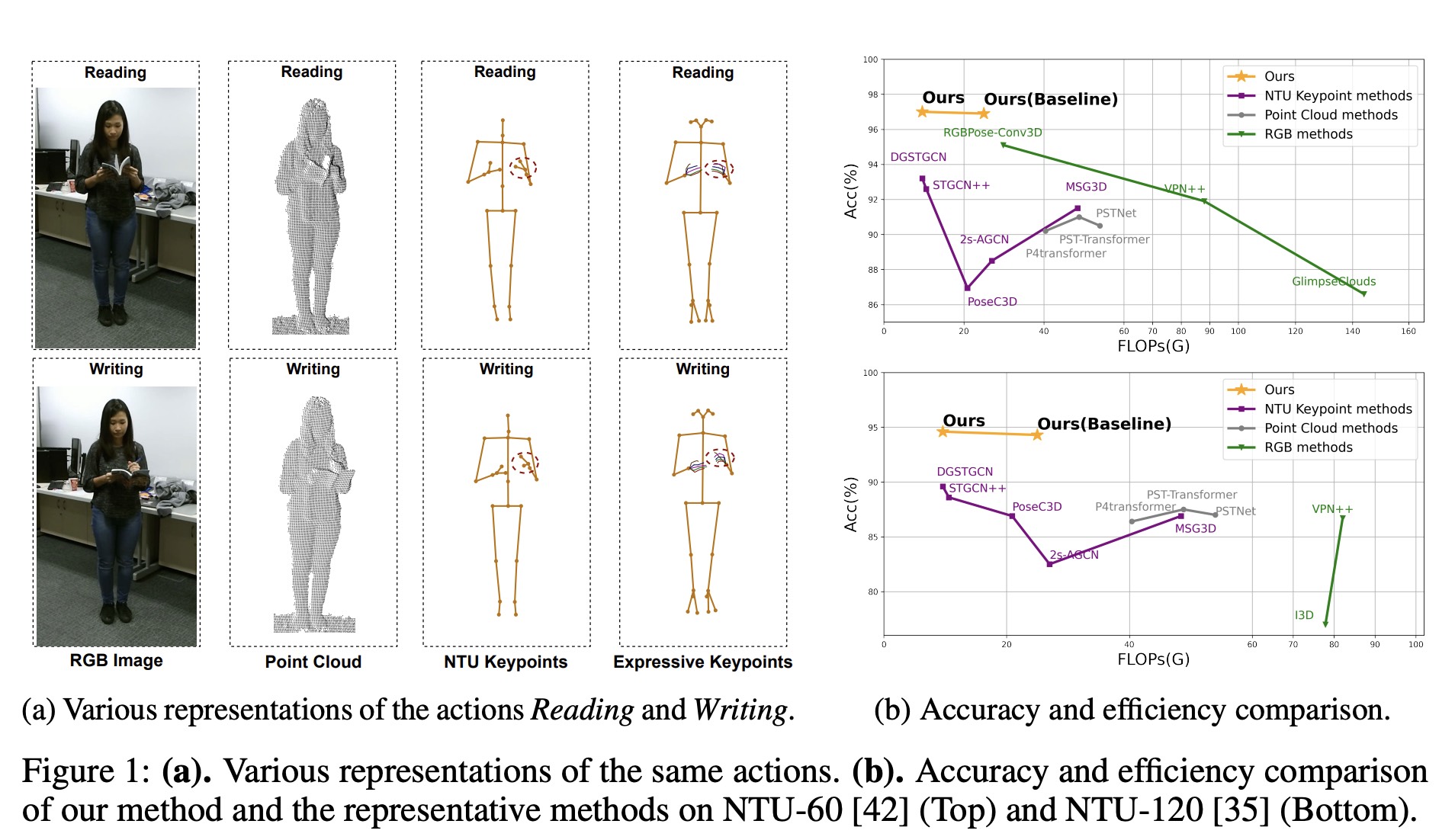 |
Expressive Keypoints for Skeleton-based Action Recognition via Progressive Skeleton Evolution Yijie Yang*,Jinlu Zhang*,Jiaxu Zhang, Bo Du,Zhigang Tu IEEE Transactions on Image Processing (TIP), 2025 Paper/ Code Abstract In this work, we propose Expressive Keypoints that incorporates hand and foot details to form a fine-grained skeletal representation, to improve the discriminative ability for existing models in discerning intricate human actions. |
 |
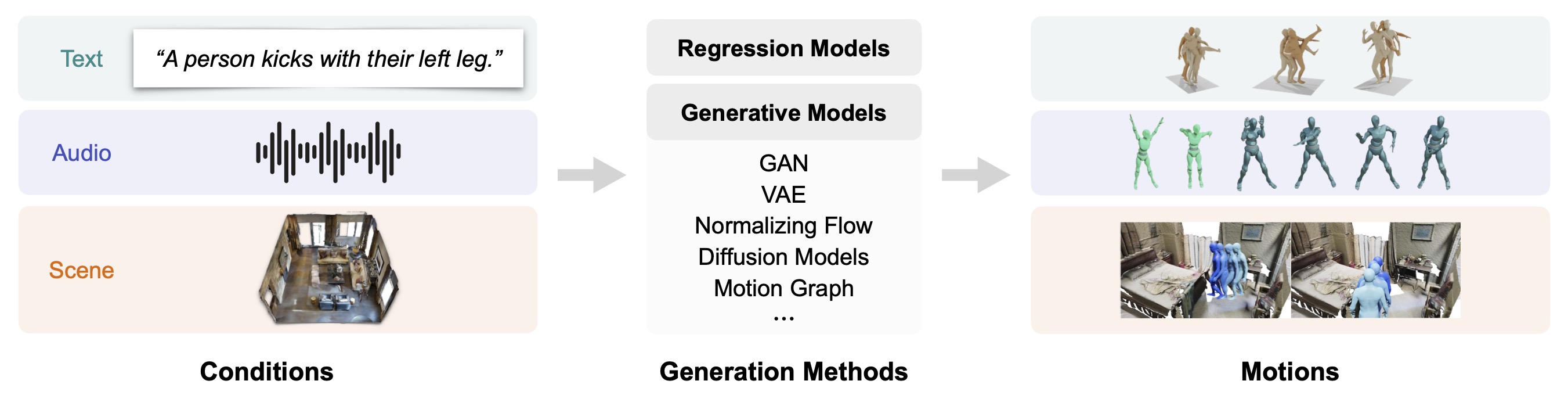
Move as You Say Interact as You Can: Language-guided Human Motion Generation with Scene Affordance Zan Wang,Yixin Chen,Baoxiong Jia,Puhao Li,Jinlu Zhang ,Jingze Zhang,Tengyu Liu,Yixin Zhu,Wei Liang,Siyuan Huang IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 Highlight Project page/Paper/ Code Abstract In this work, we introduce a novel two-stage framework that employs scene affordance as an intermediate representation, effectively linking 3D scene grounding and conditional motion generation. Our framework comprises an Affordance Diffusion Model (ADM) for predicting explicit affordance map and an Affordance-to-Motion Diffusion Model (AMDM) for generating plausible human motions. |
 |
Human Motion Generation: A Survey Wentao Zhu, Xiaoxuan Ma, Dongwoo Ro, Hai Ci, Jinlu Zhang, Jiaxin Shi, Feng Gao, Qi Tian, Yizhou Wang IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024 Paper Abstract A comprehensive survey of recent advances in human motion generation, covering the technical evolution, key challenges, and future directions in this rapidly developing field. |
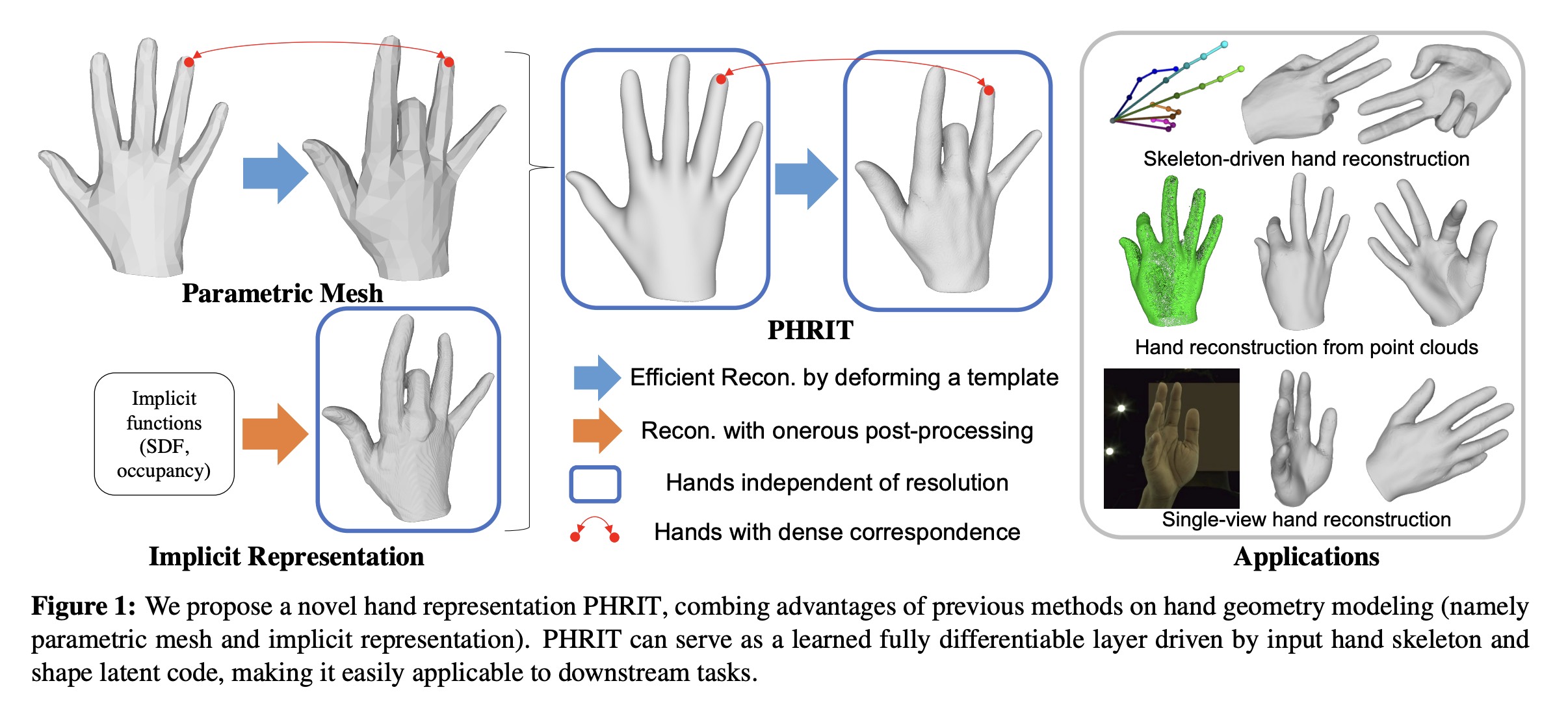 |
PHRIT: Parametric Hand Representation with Implicit Template Zhisheng Huang, Yujin Chen, Di Kang, Jinlu Zhang , Zhigang Tu IEEE/CVF International Conference on Computer Vision (ICCV), 2023 Paper Abstract We propose PHRIT, a novel approach for parametric hand mesh modeling with an implicit template that combines the advantages of both parametric meshes and implicit representations. Our method represents deformable hand shapes using signed distance fields (SDFs) with part-based shape priors, utilizing a deformation field to execute the deformation. |
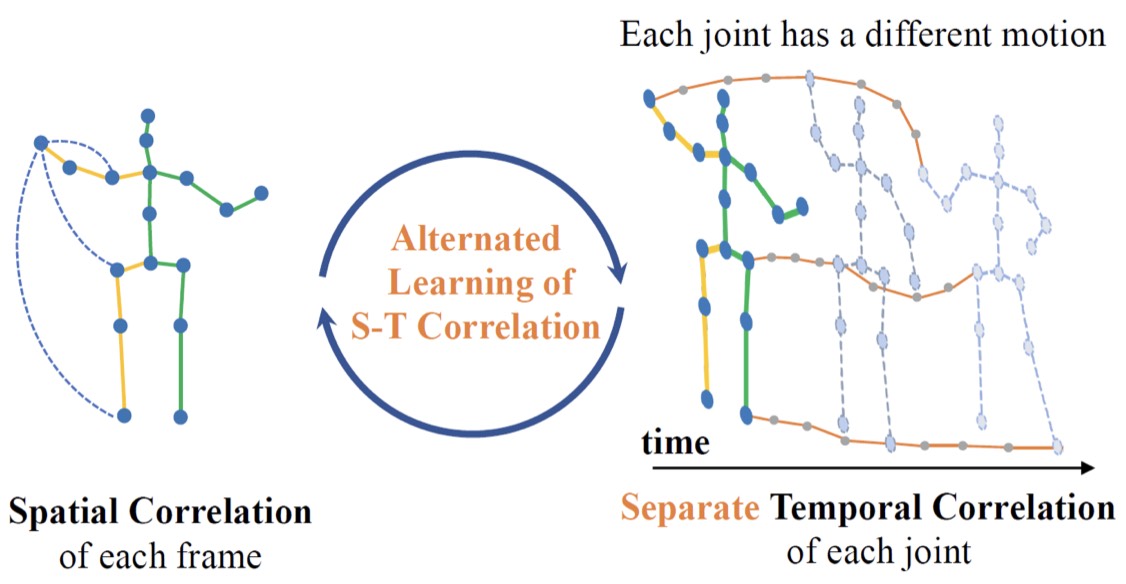 |
MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video Jinlu Zhang ,Zhigang Tu ,Jianyu Yang ,Yujin Chen ,Junsong Yuan IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 Paper/ Video/Code/ Bibtex Abstract We propose MixSTE (Mixed Spatio-Temporal Encoder), which has a temporal transformer to separately model the temporal motion of each joint and a spatial transformer to learn inter-joint spatial correlation. |
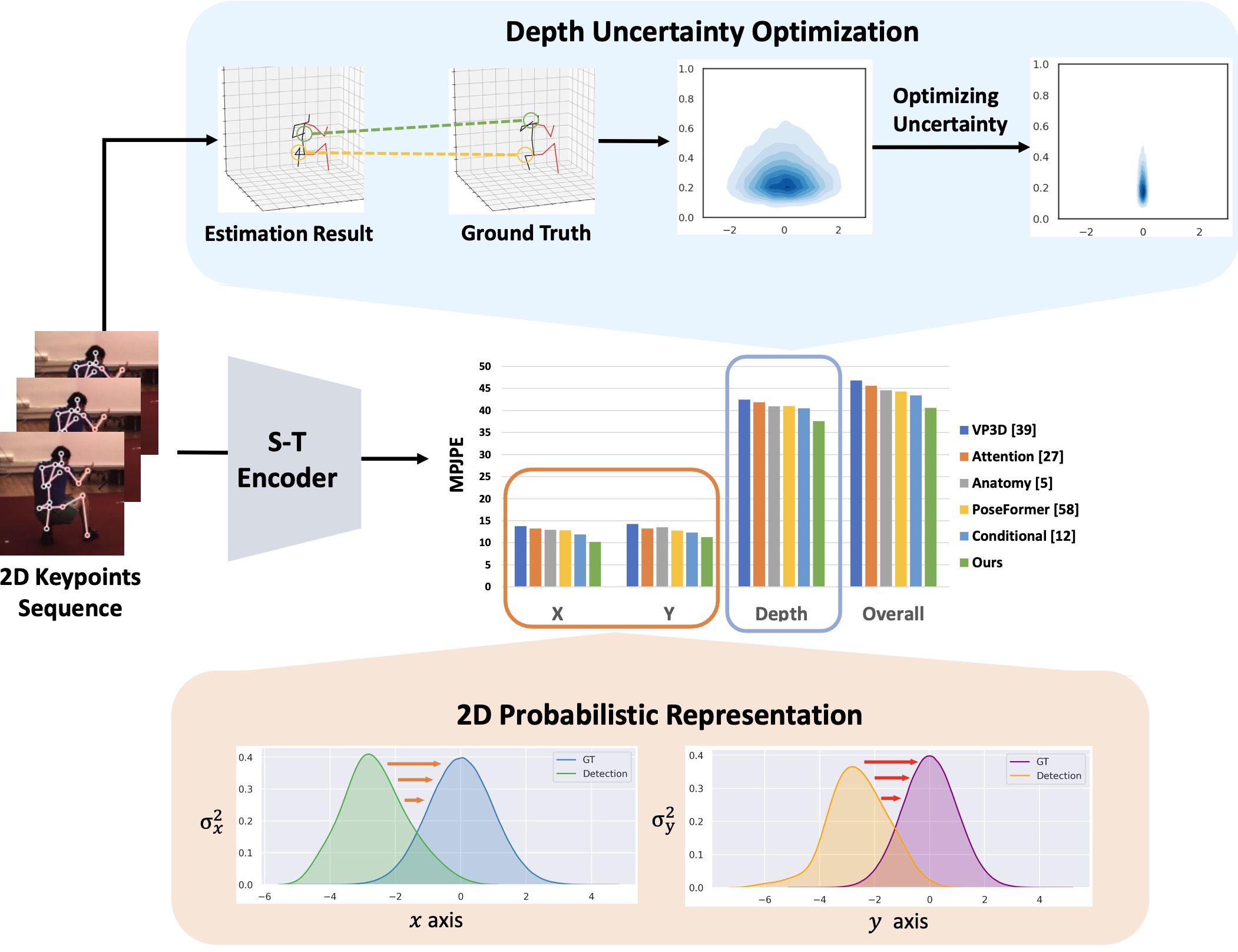 |
Uncertainty-Aware 3D Human Pose Estimation from Monocular Video Jinlu Zhang ,Yujin Chen ,Zhigang Tu ACM International Conference on Multimedia (ACM MM), 2022 Paper Abstract We propose an uncertainty-aware method to quantify and optimize the depth and 2D detection input respectively. |