Computational Perception & Cognition (original) (raw)
Today, science and technology is at the threshold of paradigm-shifting discoveries. However, an obstacle remains: as technology grows exponentially, our understanding of the human mind does not. We are approaching an era in which the benefits of a highly technologized society won't be fully realized unless we are able to understand how humans encode, process, retain, predict and imagine. To this end, we combine methods from computer science, neuroscience and cognitive science to explain and model how perception and cognition are realized in human and machine. Our research bridges from theory to experiments to applications, accelerating the rate at which discoveries are made by solving problems through a multi-disciplinary way of thinking.

Highlight: What's The Human Brain Doing? Let's See!
At the Imagination in Action: AI frontiers and implications by MIT CSAIL and Forbes in June 2023, Aude Oliva presented the lab work on building tools to visualize human brain processes. These spatio-temporal brain maps can show how the human brain reacts to visual, audio, verbal or tactile stimuli, making them relevant tools to characterize brain disorders, being perceptual, cognitive, emotional or motor. See the Forbes article and video for more.

Highlight: Helping computer vision and language models understand what they see
AI models often struggle to understand concepts, like the arrangement of items in a scene. For instance, a vision and language model might recognize the cup and table in an image, but fail to grasp that the cup is sitting on the table. In a paper to be presented at CVPR 2024, we have demonstrated a new technique that utilizes computer-generated data to help vision and language models overcome this shortcoming. We use synthetic data to improve a model's ability to grasp conceptual information, which could enhance automatic captioning and question-answering systems and help machine-learning models understand the concepts in a scene. Project website.

Highlight: MIT Ignite: Generative AI Entrepreneurship Competition
MIT Ignite, co-lead by Aude Oliva, is a competition on Generative AI open to all MIT students and postdocs. Students can submit projects that could influence sectors such as climate sustainability, human health, workforce dynamics, ethical AI deployment, and more. The projects with the highest potential for real-world impact and innovation were recognized with awards from the MIT-IBM Watson AI Lab. See MIT Ignite webpage for more information, and the MIT News.

Highlight: Generative AI and Its Implications to Societies
In a series of ILP start-up conferences in Osaka, Tokyo and Seoul, Aude Oliva will participate in panels and give keynotes on Generative AI and Its Implications to Societies, discussing use-inspired MIT research projects in AI and their translational impact, in domains ranging from scientific discovery and education to industrial cases.

Highlight: Memorability May Be Universal
A WIRED article mentioning work by Wilma Bainbridge and Zoya Bylinskii, alumni of the lab, as well as Camilo Fosco, describes how visual memorability may be universal, and generalizable across visual domains and people. A long decade topic of the Oliva lab, memorability of a new stimuli can be evaluated by deep neural networks, and has specific temporal and spatial neural brain signatures. For a review, see this chapter.

Highlight: MURI Award: Neuro-inspired distributed deep learning
Agrawal, Fiete and Oliva of MIT, together with faculty from Harvard and Berkeley, have been awarded a 5 year MURI grant for developing machine-learning approaches inspired by how biological intelligence encodes and retrieve memory. The team seeks to develop practical ML algorithms for generalization to new tasks, lifelong learning without catastrophic forgetting, and transfer across sensory modalities.

Highlight: Amazon and MIT research symposium
As inaugural lead of the Science Hub between MIT and Amazon, Aude Oliva created a portfolio of twenty projects during the first year of the initiative, with many teams presenting cutting edge projects and results on AI and robotics, conversational AI and computer vision, at the 2022 Science Hub symposium at MIT.

Highlight: Break Through Tech AI
The Break Through Tech AI Program at the MIT Schwarzman College of Computing is helping women and underrepresented groups in computing across the Greater Boston area, gain the skills they need to get jobs in the fastest-growing areas of tech: data science, machine learning, and artificial intelligence. This fall, participants had the opportunity to work on machine learning projects, under the guidance of Dr. Aude Oliva. See the MIT News article for more.

Highlight: In machine learning, synthetic data can offer real performance improvements
Teaching a machine to recognize human actions has many potential applications. Researchers are turning to synthetic datasets; but are synthetic data as "good" as real data? How well does a model trained with these data perform when it's asked to classify real human actions? A team of researchers at MIT, the MIT-IBM Watson AI Lab, and Boston University found that models trained on synthetic data can be more accurate than other models in some cases, which could eliminate privacy, copyright, and ethical concerns from using real data. See the MIT News article.
Funded by MIT-IBM Watson AI Lab

Highlight: Artificial intelligence system learns concepts shared across video, audio, and text
Humans observe the world through a combination of different modalities, like vision, hearing, and our understanding of language. Machines, on the other hand, interpret the world through data that algorithms can process. MIT researchers have now developed a machine learning technique that learns to represent data in a way that captures concepts which are shared between visual and audio modalities. Their model can identify where certain action is taking place in a video and label it. This technique could someday be utilized to help robots learn about concepts in the world through perception, more like the way humans do. See the MIT News article.
Funded by the MIT-IBM Watson AI Lab and its member companies, Nexplore and Woodside, and the MIT Lincoln Laboratory

Highlight: MIT and Amazon launch Science Hub collaboration
The Science Hub, a collaboration between MIT and Amazon, launched Oct 4, 2021. The Science Hub aims to support research, education, and outreach efforts in areas of mutual interest, beginning with artificial intelligence and robotics in the first year. Administered at MIT by the Schwarzman College of Computing, the Science Hub aims to ensure that the benefits of artificial intelligence and robotics innovations are shared broadly—both through education and by advancing research—and that participation in the research is broadened to encompass diverse, interdisciplinary scholars, and other innovators. Aude Oliva, senior research scientist and director of strategic industry engagement at the SCC, will be the principal investigator for the hub. See articles by The Tech and the Schwarzman College of Computing.
Highlight: The Algonauts Project 2021 Challenge
The quest to understand the nature of human intelligence and engineer more advanced forms of artificial intelligence are becoming increasingly intertwined. The Algonauts Project brings biological and machine intelligence researchers together on a common platform to exchange ideas and advance both fields. In its launch year, 2019, the challenge focused on explaining brain responses as human subjects studied still images. The challenge returns this year, centered around video perception and understanding. The 2021 challenge will focus on explaining responses in the human brain as subjects watch short video clips of everyday actions. Sign up and get involved here!
Funded by Vannevar Bush Faculty Fellowship, MIT-IBM Watson AI Lab, ERC, DFG

Highlight: Toward a machine learning model that can reason about everyday actions
The ability to reason abstractly about events as they unfold is a defining feature of human intelligence. Organizing the world into abstract categories does not come easily to computers, but in recent years researchers have inched closer by training machine learning models on words and images infused with structural information about the world, and how objects, animals, and actions relate. In a new study at the European Conference on Computer Vision (ECCV), researchers unveiled a hybrid language-vision model that can compare and contrast a set of dynamic events captured on video to tease out the high-level concepts connecting them. See the MIT News article and project webpage for more.
Funded by the MIT-IBM Watson AI Lab
Highlight: Shrinking Deep Learning's Carbon Footprint
Deep learning has driven much of the recent progress in artificial intelligence, but as demand for computation and energy to train ever-larger models increases, many are raising concerns about the financial and environmental costs. To address the problem, researchers at MIT and the MIT-IBM Watson AI Lab are experimenting with ways to make software and hardware more energy efficient, and in some cases, more like the human brain. See the MIT News article for more.

Highlight: What jumps out in a photo changes the longer we look
In a paper at CVPR 2020, we show that human attention moves in distinctive ways the longer we stare at an image, and that these viewing patterns can be replicated by artificial intelligence models. The work suggests immediate ways of improving how visual content is teased and eventually displayed online. See the MIT News article for more.
Funded by Vannevar Bush Faculty Fellowship, STL@CSAIL, MIT Quest, Adobe
Highlight: The Algonauts Project
The quest to understand the nature of human intelligence and engineer more advanced forms of artificial intelligence are increasingly intertwined. The Algonauts Project brings biological and artificial intelligence researchers together on a common platform to exchange ideas and advance both fields. Our first challenge and workshop, Explaining the Human Visual Brain, will focus on building computer vision models that simulate how the brain sees and recognizes objects, a topic that has long fascinated neuroscientists and computer scientists. Challenge results and a workshop to be held at MIT, on July 19-20, 2019. See this short paper for more.
Funded by NSF, MIT-IBM Watson AI Lab, MIT Quest for Intelligence

Highlight: Moments in Time: A Large-Scale Dataset for Event Understanding
We release the first version of Moments in Time dataset, a large-scale, human-annotated one million video dataset capturing visual and/or audible actions, produced by humans, animals, objects or nature that together shall allow for the recognition of compound activities occurring at longer time scales.
Funded by MIT-IBM Watson AI Lab

Highlight: Quantifying Interpretability of Deep Neural Networks: Seeing through the artificial box
In a computer vision paper and talk at CVPR 2017, the team proposes a general framework called Network Dissection that allows to quantify and compare what artificial units of deep neural networks learn, offering a tool to see what visual deep NNs learn, making the neural network box more transparent. See the website for more information and some related news: MIT news, TechCrunch, Quartz
Funded by NSF, Vannevar Bush Faculty Fellowship, Toyota, Google, Amazon, NVidia

Highlight: How good is your eyesight?
With more than 8 million hits, ASAP Science video explains the principle behind our hybrid image illusion, using the bi-portrait of Marilyn Monroe and Albert Einstein. Knowing how the visual system works, hybrid images allow to create multi-layered images, where what you see from afar is different from what you see near by. A chapter on the hybrid image illusion (A. Oliva & P.G. Schyns) is in press in the Oxford Compendium of Visual Illusions.

Highlight: 10,000+ Face photographs
We have released a new image dataset, the 10k US Adult Faces Database, with over 10,000 pictures of faces that match the distribution of the adult US population, along with memorability and attribute scores for 2,200+ of them. This dataset goes along with the new article by Bainbridge, Isola and Oliva in Journal of Experimental Psychology: General (2013), on the intrinsic memorability of faces. The memorability scores of this dataset are also used in Khosla et al (2013), ICCV.
Funded by NSF, Google & Xerox
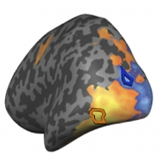
Highlight: The Brain Discerning Taste for Size
The human brain can recognize thousands of different objects, but neuroscientists have long grappled with how the brain organizes object representation — in other words, how the brain perceives and identifies different objects. Now researchers at MIT’s Computer Science and Artificial Intelligence Lab (CSAIL) and Department of Brain and Cognitive Sciences have discovered that the brain organizes objects based on their physical size (See MIT News Article and The Scientist article). Article in Neuron (Konkle & Oliva, 2012).
Funded by National Eye Institute

Highlight: What Makes a Picture Memorable?
At the World Memory Championships, athletes compete to recall massive amounts of information; contestants must memorize and recall sequences of abstract images and the names of people whose faces are shown in photographs. While these tasks might seem challenging, our research suggests that images that possess certain properties are memorable. Our findings can explain why we have all had some images stuck in our minds, but ignored or quickly forgotten others. A short news article, and our 2014 article in IEEE Pattern Analysis and Machine Intelligence (PAMI).
Funded by National Science Foundation, Google and Xerox

Highlight: What Makes a Data Visualization Memorable?
An ongoing debate in the Visualization community concerns the role that visualization types play in data understanding. In human cognition, understanding and memorability are intertwined. As a first step towards being able to ask questions about impact and effectiveness, here we ask: “What makes a visualization memorable?” We ran a large scale memory study and discovered that observers are very consistent in which visualizations they find memorable and forgettable. Article in IEEE Trans. on Visualization and Computer Graphics, Harvard News Release.
Funded by National Science Foundation, Google and Xerox

Highlight: Two for the View of One: The Art of Hybrid Images
Artists, designers, and visual scientists have long been searching for ways to make multiples meanings out of a single image. This article reviews a method Phillipe Schyns and Aude Oliva developed named Hybrid images, which are static pictures with two stable interpretations that change depending on the image’s viewing distance or size: one that appears when the image is viewed up-close, and the other that appears from afar. Hybrid images can be used to create compelling prints and photographs in which the observer experiences different percepts when interacting with the image. A recent short article in Art & Perception. The original technique was published in Schyns & Oliva (1994) to study how images are processed by the visual system.