Planet Clojure (original) (raw)
Da Bot Updates the Old Shotgun Meme
Sometimes, you just gotta have a little fun. I don't know what I was doing other than clicking random things when I landed on this Reddit thread about "How to shoot yourself in the foot using different programming languages"
I don't know...I wasn't laughing at this list nearly as much as I remembered laughing at it 20 something years ago. So, without further ado, I turn to da bot:
Me: There's an old meme about how each programming language provides a way to shoot yourself in the foot. However, when I read it, it's fairly outdated and also doesn't always accurately describe the language. Can you provide a fresh modern take on the top 50 all-time popular languages?
Da Bot: Absolutely! Here's a modernized and humorous take on how you might "shoot yourself in the foot" using 50 of the most popular programming languages, blending common pitfalls, stereotypes, and recent trends:
Top 50 Programming Languages and How They Let You Shoot Yourself in the Foot (2025 Edition)
- Python – You shoot yourself in the foot, but it's so elegant that you don't realize it until runtime.
- JavaScript – You shoot yourself in the foot, but it only happens if you're using
==instead of===. Or maybe it just turns your foot intoundefined. - Java – You write 200 lines of boilerplate just to load the gun. The JVM throws a
FootNotFoundException. - C – You shoot yourself in the foot, the whole OS crashes, and you blame it on user error.
- C++ – You shoot yourself in the foot, then the compiler shoots you for misusing templates.
- C# – You shoot yourself in the foot, but .NET politely logs it and shows you a GUI about safe gun handling.
- Go – You shoot yourself in the foot, and the compiler shrugs: "That’s how we do it here—no exceptions, no generics (well, sorta now), no crying."
- Rust – You tried to shoot yourself in the foot, but the borrow checker wouldn't let you.
- Swift – You shoot yourself in the foot, but only if the optional gun isn't
nil. - Kotlin – You shoot yourself in the foot, but with 30% less boilerplate than Java.
- TypeScript – You shoot yourself in the foot, but at least the compiler warned you ahead of time.
- Ruby – You shoot yourself in the foot with one line of code so beautiful it brings tears to your eyes. Then Rails reloads and shoots the other one.
- PHP – You shoot yourself in the foot, and it works, but later it turns out it was your kneecap.
- Perl – You shoot yourself in the foot, but the regex you used means no one can tell how.
- R – You shoot yourself in the foot and then spend 3 hours generating a ggplot of your injury.
- MATLAB – You shoot yourself in the foot, but only if you remembered to pay for the Gun Toolbox™.
- SQL – You shoot yourself in the foot and then
DROP FOOT;. - Shell (Bash) – You shoot yourself in the foot with
rm -rf /and wonder why your terminal went silent. - Assembly – You manually load the bullet into the chamber, fire the shot, and debug the foot.
- Haskell – You define the concept of a foot as a monad, and shooting becomes a lazy evaluation that never happens.
- Elixir – You shoot yourself in the foot, but the process crashes and is seamlessly restarted.
- Erlang – You shoot yourself in the foot, but 1,000 lightweight processes catch the bullet and keep running.
- Scala – You shoot yourself in the foot using a functional gun inside an object-oriented casing and then explain why it was better than Java.
- Dart – You shoot yourself in the foot, but Flutter makes it look beautiful on both iOS and Android.
- Lua – You shoot yourself in the foot, but it's embedded in a video game so no one notices.
- Objective-C – You shoot yourself in the foot, and the syntax bruises your eyes more than the bullet bruises your foot.
- VB.NET – You shoot yourself in the foot and your foot shows a message box: "An error has occurred."
- Fortran – You shoot yourself in the foot, but only if the dataset is from 1970 and written in ALL CAPS.
- COBOL – You shoot yourself in the foot, but the bank is still processing it 40 years later.
- F# – You shoot yourself in the foot in a purely functional way. Then explain it to no one because no one else is using F#.
- Julia – You shoot yourself in the foot, but it vectorizes the process for efficiency.
- Groovy – You shoot yourself in the foot, but it feels like Java... just looser and more "chill."
- Powershell – You shoot yourself in the foot and every computer on the network—remotely.
- Delphi (Pascal) – You shoot yourself in the foot with an elegant GUI app… in 1995.
- Tcl – You shoot yourself in the foot and use a GUI toolkit from 1992 to display the wound.
- Hack – You shoot yourself in the foot, but Facebook tells you it's a feature.
- Nim – You try to shoot yourself in the foot, but it compiles to C so fast you forget what language you're using.
- Crystal – You shoot yourself in the foot, and Ruby fans call it beautiful while C fans call it fast.
- Zig – You shoot yourself in the foot, but at least the build system didn't.
- V – You try to shoot yourself in the foot, but the gun isn’t implemented yet.
- Racket (Scheme) – You shoot your foot with parentheses. So many parentheses.
- Smalltalk – You shoot yourself in the foot by sending a
#shoot:message to your foot object. - Ada – You can't shoot yourself in the foot because the compiler prevented you from misusing the gun. But your code is now 800 lines long.
- Lisp – You
(shoot '(your foot))and(enjoy 'pain). - Prolog – You declare the rules for shooting yourself in the foot, but the interpreter can’t prove it.
- Clojure – You shoot yourself in the foot, but it's immutable now, so the wound is conceptual.
- OCaml – You shoot yourself in the foot, but pattern match the blood spatter into a beautiful recursive function.
- AWK – You shoot yourself in the foot line by line in a log file.
- Haxe – You shoot yourself in the foot and then compile the same shot for 5 different platforms.
- BQN / APL – You shoot your foot using a single obscure symbol, and no one else understands how.
Would you like this formatted for printing or shared as a graphic/poster?
SQL pipelines: reducing some of the accidental structure in SQL
OSS updates March and April 2025
In this post I'll give updates about open source I worked on during March and April 2025.
To see previous OSS updates, go here.
I'd like to thank all the sponsors and contributors that make this work possible. Without you the below projects would not be as mature or wouldn't exist or be maintained at all! So a sincere thank you to everyone who contributes to the sustainability of these projects.

Current top tier sponsors:
Open the details section for more info about sponsoring.
Sponsor info
If you want to ensure that the projects I work on are sustainably maintained, you can sponsor this work in the following ways. Thank you!
- Github Sponsors
- The Babaska or Clj-kondo OpenCollective
- Ko-fi
- Patreon
- Clojurists Together
On to the projects that I've been working on!
Blog posts
I blogged about an important improvement in babashka regarding type hints here.
Interviews
Also I did an interview with Jiri from Clojure Corner by Flexiana, viewable here.
Updates
Here are updates about the projects/libraries I've worked on in the last two months.
- babashka: native, fast starting Clojure interpreter for scripting.
- Improve Java reflection based on provided type hints (read blog post here)
- Add compatibility with the fusebox library
- Fix virtual
ThreadBuilderinterop - Add
java.util.concurrent.ThreadLocalRandom - Add
java.util.concurrent.locks.ReentrantLock - Add classes:
*java.time.chrono.ChronoLocalDate
*java.time.temporal.TemporalUnit
*java.time.chrono.ChronoLocalDateTime
*java.time.chrono.ChronoZonedDateTime
*java.time.chrono.Chronology - #1806: Add
cheshire.factorynamespace (@lread) - Bump GraalVM to
24 - Bump SCI to
0.9.45 - Bump edamame to
1.4.28 - #1801: Add
java.util.regex.PatternSyntaxException - Bump core.async to
1.8.735 - Bump cheshire to
6.0.0 - Bump babashka.cli to
0.8.65
- clerk: Moldable Live Programming for Clojure
- Replace tools.analyzer with a more light-weight analyzer which also adds support for Clojure 1.12
- squint: CLJS syntax to JS compiler
- #653: respect
:context exprincompile-string - #657: respect
:context exprinset!expression - #659: fix invalid code produced for REPL mode with respect to
return - #651 Support
:require+:rename+ allow renamed value to be used in other :require clause - Fix #649: reset ns when compiling file and fix initial global object
- Fix #647: emit explicit
nullwhen written in else branch ofif - Fix #640: don't emit anonymous function if it is a statement (@jonasseglare)
- Fix #643: Support lexicographic compare of arrays (@jonasseglare)
- Fix #602: support hiccup-style shorthand for id and class attributes in
#jsxand#html - Fix #635:
rangefixes - Fix #636: add
run! defclass: elide constructor when not provided- Fix #603: don't emit multiple returns
- Drop constructor requirement for
defclass
- #653: respect
- clj-kondo: static analyzer and linter for Clojure code that sparks joy.
- #2522: support
:config-in-nson:missing-protocol-method - #2524: support
:redundant-ignoreon:missing-protocol-method - #1292: NEW linter:
:missing-protocol-method. See docs - #2512: support vars ending with
., e.g.py.according to clojure analyzer - #2516: add new
--reproflag to ignore home configuration - #2493: reduce image size of native image
- #2496: Malformed
deftypeform results inNPE - #2499: Fix
(alias)bug (@Noahtheduke) - #2492: Report unsupported escape characters in strings
- #2502: add end locations to invalid symbol
- #2511: fix multiple parse errors caused by incomplete forms
- document var-usages location info edge cases (@sheluchin)
- Upgrade to GraalVM 24
- Bump datalog parser
- Bump built-in cache
- #2522: support
- SCI: Configurable Clojure/Script interpreter suitable for scripting
- Fix #957:
sci.async/eval-string+should return promise with:val nilfor ns form rather than:val <Promise> - Fix #959: Java interop improvement: instance method invocation now leverages type hints
- Fix #942: improve error location of invalid destructuring
- Add
volatile?to core vars - Fix #950: interop on local in CLJS
- Bump edamame to
1.4.28
- Fix #957:
- quickdoc: Quick and minimal API doc generation for Clojure
- Fix #32: fix anchor links to take into account var names that differ only by case
- Revert source link in var title and move back to
<sub> - Specify clojure 1.11 as the minimal Clojure version in
deps.edn - Fix macro information
- Fix #39: fix link when var is named multiple times in docstring
- Upgrade clj-kondo to
2025.04.07 - Add explicit
org.babashka/clidependency
- CLI: Turn Clojure functions into CLIs!
- process: Clojure library for shelling out / spawning sub-processes
- html: Html generation library inspired by squint's html tag
- cherry: Experimental ClojureScript to ES6 module compiler
- Add
cljs.pprint/pprint - Add
add-tap - Bump squint compiler common which brings in new
#htmlid and class shortcuts + additional features and optimizations, such as an optimization foraset
- Add
- nbb: Scripting in Clojure on Node.js using SCI
- Add better Deno +
jsr:dependency support, stay tuned.
- Add better Deno +
- instaparse-bb: Use instaparse from babashka
- Several improvements which makes babashka compatible with test.chuck. See this screenshot!
- edamame: Configurable EDN/Clojure parser with location metadata
- #117: throw on triple colon keyword
- fs - File system utility library for Clojure
- #141:
fs/matchdoesn't match when root dir contains glob or regex characters in path - #138: Fix
fs/update-fileto support paths (@rfhayashi)
- #141:
- sql pods: babashka pods for SQL databases
- Upgrade to GraalVM 23, fixes encoding issue with Korean characters
{kind=link}
Other projects
These are (some of the) other projects I'm involved with but little to no activity happened in the past month.
Click for more details
- rewrite-edn: Utility lib on top of
- deps.clj: A faithful port of the clojure CLI bash script to Clojure
- scittle: Execute Clojure(Script) directly from browser script tags via SCI
- rewrite-clj: Rewrite Clojure code and edn
- pod-babashka-go-sqlite3: A babashka pod for interacting with sqlite3
- tools-deps-native and tools.bbuild: use tools.deps directly from babashka
- http-client: babashka's http-client
- http-server: serve static assets
- bbin: Install any Babashka script or project with one comman
- sci.configs: A collection of ready to be used SCI configs.
- Added a configuration for
cljs.spec.alphaand related namespaces
- Added a configuration for
- qualify-methods
- Initial release of experimental tool to rewrite instance calls to use fully qualified methods (Clojure 1.12 only0
- neil: A CLI to add common aliases and features to deps.edn-based projects.
- tools: a set of bbin installable scripts
- sci.nrepl: nREPL server for SCI projects that run in the browser
- babashka.json: babashka JSON library/adapter
- squint-macros: a couple of macros that stand-in for applied-science/js-interop and promesa to make CLJS projects compatible with squint and/or cherry.
- grasp: Grep Clojure code using clojure.spec regexes
- lein-clj-kondo: a leiningen plugin for clj-kondo
- http-kit: Simple, high-performance event-driven HTTP client+server for Clojure.
- babashka.nrepl: The nREPL server from babashka as a library, so it can be used from other SCI-based CLIs
- jet: CLI to transform between JSON, EDN, YAML and Transit using Clojure
- pod-babashka-fswatcher: babashka filewatcher pod
- lein2deps: leiningen to deps.edn converter
- cljs-showcase: Showcase CLJS libs using SCI
- babashka.book: Babashka manual
- pod-babashka-buddy: A pod around buddy core (Cryptographic Api for Clojure).
- gh-release-artifact: Upload artifacts to Github releases idempotently
- carve - Remove unused Clojure vars
- 4ever-clojure - Pure CLJS version of 4clojure, meant to run forever!
- pod-babashka-lanterna: Interact with clojure-lanterna from babashka
- joyride: VSCode CLJS scripting and REPL (via SCI)
- clj2el: transpile Clojure to elisp
- deflet: make let-expressions REPL-friendly!
- deps.add-lib: Clojure 1.12's add-lib feature for leiningen and/or other environments without a specific version of the clojure CLI
Models are messy
Our last episode was with Fogus. It was a great episode where we learn from his experience as a core contributor. The next episode is on Tuesday, May 6 with special guest JP Monetta. Please watch us live so you can ask questions in the chat.
If you want to learn Clojure, there’s no better way than Beginner Clojure, my signature course for those new to the language. I’ve recently rebuilt the introduction module to teach better, so there’s never been a better time to buy. The point of that module is to give you a deep experience with Clojure (and FP+Data-Driven Programming) as quickly as possible.
Models are messy
I am not a Platonic Idealist. I do not believe that the round table I’m working at is some pale shadow of the ideal circle. At best, circle is a mathematical abstraction that’s easy to define and analyze which happens to approximate the real table well enough to be useful. It is the abstract circle that is the pale shadow of the real table. Circles are just ideas.
So I guess that makes me a Materialist. But as I write this, I realize how much of a process it was for me to arrive at that conclusion. And even describing it took some work. And by learning that about myself, I realized a profound truth: Many people are idealists unconsciously.
One problem is that materialism is often conflated with anti-intellectualism. If the material world is primary, maybe it calls into question studying the idealized world of geometry and algebra. Maybe math isn’t important. But, no, it doesn’t. Materialism acknowledges that geometry and algebra are simply useful mental tools—not the ultimate essence or the source of all truth.
I sometimes wonder, as one does, about the marriage between empirical experiment and mathematical abstraction that has led to the recent explosion of scientific understanding. Why is it that mathematics has been so fruitful at describing the world we discover through experiments? Mustn’t mathematics be a fundamental part of the universe? Is mathematics discovered? Or is it invented by us?
Those are fun questions, but I’m not going to explore them deeply here. I will simply say that it was Buckminster Fuller who got me thinking about all of this stuff. He said there are no zero-dimensional points in the real-world. There are no one-dimensional lines. There are no two-dimensional planes. Everything we can experience is three-dimensional. So he didn’t base his geometry on points and lines and planes. Instead, he always used real objects to explore the nature of space. I still think about that. He went back to first principles and built up an understanding based on empirical exploration instead of abstractions.
The world is messy. Everything is complicated. When I talk about creating a domain model, one of the common pushbacks I get is from people who worry I’m advocating for creating an over-idealized model. One that sounds good but misses all the rich detail of the messy world.
Nothing is further from the truth. In fact, your domain model should enable all of the messy details that you need to capture. The level of abstraction most mathematics achieves is too clean. However, abstraction is the basis for how software works. Software for managing a farm does not operate on real sheep. Yet the sheep are represented.
No, what I’m suggesting is that we must represent the structures we encounter in the world in the software. The structure is often messy. But there is often a deeper, underlying order to it, as in my example of combining simple Boolean predicates to build up a representation of the messy voting laws.
Many real world “laws” are actually rules that apply most of the time but they have a number of exceptions. That itself is the structure we must capture—general rules with exceptions. Many real-world processes are mostly continuous—they’re continuous with a known discontinuity. That’s fine. Those discontinuities can often be handled at a higher level. It’s kind of the complement of finding order at a lower level. Move the messiness to a higher level.
It reminds me a lot of the way I recommend people deal with algebraic properties in property-based testing. People often get caught up looking for extremely regular properties, like the commutativity of addition.
What I recommend is using the formula of commutativity as a starting point—a kind of inspiration.
Ask about whether the order of arguments matter, how they matter, when they matter. You could find some rich patterns there that are worth capturing as properties for your domain.
For instance, merge for maps is commutative if you know the two maps don’t share any keys. So you start with the basic formula and you adorn it with the real-world detail you’re looking for.
Likewise, the order of checks arriving at the bank doesn’t matter—as long as you have enough balance for all checks to clear:
let bill be the $x check to for the power bill (debit to your account)
let paycheck be the $y weekly paycheck (credit to your account)
That is, if you’ve got the money to pay the bill, it doesn’t matter which order the checks are cleared. But if you don’t have the money and the bill clears first, you might get an overdraft fee.
Remember, commutativity is just a nice idea that corresponds to some things we see in the world. We can adapt it, like any mathematical notion, to make it useful to our purposes. Putting the simpler definition of commutativity ahead of what we encounter in the real world is latent Platonic idealism. We have to reject that idealism. The real world is where the action happens. And its rich detail is what makes it interesting enough to model in software. When you’re building a model, avoid the temptation to make a perfect gem. Instead, aim to honor the imperfections. But don’t be an anti-intellectual and reject modeling outright. Modeling is what enables the magic we wield. So are you an idealist of a materialist—or an anti-intellectual?
When You Get to Be Smart Writing a Macro
Day-to-day programming isn’t always exciting. Most of the code we write is pretty straightforward: open a file, apply a function, commit a transaction, send JSON. Finding a problem that can be solved not the hard way, but smart way, is quite rare. I’m really happy I found this one.
I’ve been using hashp for debugging for a long time. Think of it as a better println. Instead of writing
(println "x" x)you write
#p xIt returns the original value, is shorter to write, and doesn’t add an extra level of parentheses. All good. It even prints original form, so you know which value came from where.
Under the hood, it’s basically:
(defn hashp [form]
`(let [res# ~form]
(println '~form res#)
res#))Nothing mind-blowing. It behaves like a macro but is substituted through a reader tag, so defn instead of defmacro.
Okay. Now for the fun stuff. What happens if I add it to a thread-first macro? Nothing good:
user=> (-> 1 inc inc #p (* 10) inc inc)
Syntax error macroexpanding clojure.core/let at (REPL:1:1).
(inc (inc 1)) - failed: vector? at: [:bindings] spec: :clojure.core.specs.alpha/bindingsMakes sense. Reader tags are expanded first, so it replaced inc with (let [...] ...) and then tried to do threading. Wouldn’t fly.
We can invent a macro that would work, though:
(defn p->-impl [first-arg form fn & args]
(let [res (apply fn first-arg args)]
(println "#p->" form "=>" res)
res))
(defn p-> [form]
(list* 'p->-impl (list 'quote form) form))
(set! *data-readers* (assoc *data-readers* 'p-> #'p->))Then it will expand to
user=> '(-> 1 inc inc #p-> (* 10) inc inc)
(-> 1
inc
inc
(p->-impl '(* 10) * 10)
inc
inc)and, ultimately, work:
user=> (-> 1 inc inc #p-> (* 10) inc inc)
#p-> (* 10) => 30
32Problem? It’s a different macro. We’ll need another one for ->>, too, so three in total. Can we make just one instead?
Turns out you can!
Trick is to use a probe. We produce an anonymous function with two arguments. Then we call it in place with one argument (::undef) and see where other argument goes.
Inside, we check where ::undef lands: first position means we’re inside ->>, otherwise, ->:
((fn [x y]
(cond
(= ::undef x) <thread-last>
(= ::undef y) <thread-first>))
::undef)Let’s see how it behaves:
(macroexpand-1
'(-> "input"
((fn [x y]
(cond
(= ::undef x) <thread-last>
(= ::undef y) <thread-first>))
::undef)))
((fn [x y]
(cond
(= ::undef x) <thread-last>
(= ::undef y) <thread-first>))
"input" ::undef)
(macroexpand-1
'(->> "input"
((fn [x y]
(cond
(= ::undef x) <thread-last>
(= ::undef y) <thread-first>))
::undef)))
((fn [x y]
(cond
(= ::undef x) <thread-last>
(= ::undef y) <thread-first>))
::undef "input")If we’re not inside any thread first/last macro, then no substitution will happen and our function will just be called with a single ::undef argument. We handle this by providing an additional arity:
((fn
([_]
<normal>)
([x y]
(cond
(= ::undef x) <thread-last>
(= ::undef y) <thread-first>)))
::undef)And boom:
user=> #p (- 10)
#p (- 10)
-10
user=> (-> 1 inc inc #p (- 10) inc inc)
#p (- 10)
-7
user=> (->> 1 inc inc #p (- 10) inc inc)
#p (- 10)
7#p was already very good. Now it’s unstoppable.
You can get it as part of Clojure+.
CIDER 1.18 (“Athens”)
Great news, everyone - CIDER 1.18 (“Athens”) is out!
This is a huge release that has an equal amount of new features, improvements to the existing ones, and also trimming down some capabilities in the name of improved efficiency and maintainability.
I’m too lazy to write a long release announcement today, so I’ll just highlight the most important aspects of CIDER 1.18 and how they fit our broader vision for the future of CIDER.
Let’s go!
Reduced surface area
- CIDER 1.18 dropped support for Boot and Emacs 26. Boot development has been frozen for many years, and it’s now a long past due to migrate to other build tools.
- CIDER no longer bundles Puget dependency. Puget is still supported as a pretty-printer for all CIDER output, but you need to add it to dependencies explicitly.
- Haystack is no longer included. With it, we removed some largely unknown facilities for parsing printed stacktraces and presenting them inside
*cider-error*buffer. - Replaced the outdated
thunknyc/profiledependency with a homegrown implementation in Orchard.
I’m happy that we continue on the path of reducing the 3rd-party dependencies incider-nrepl and rely more and more on functionality optimized for our use-cases, living in Orchard. Looking back, at some of the decisions I’ve taken in the past - I sometimes regret going overboard with the feature set (we have so many features today, that even I occasionally forget about some of them) and the dependencies needed to provide certain features. Going forward I hope to gradually reduce the feature set and the dependencies by:
- removing features that are rarely used
- making certain dependencies optional (instead of bundling everything with
cider-nrepl)
Inspector
Our beloved inspector got a lot better!
- New analytics module (orchard#329) (shows you some useful info about the data you’re inspecting)
- Table view mode (orchard#331) (I think you’ll totally love this!)
- Pretty-printing mode (#3813) and a command to separately pretty-print the currently inspected value (#3810)
That’s how the analytics and the table view look:
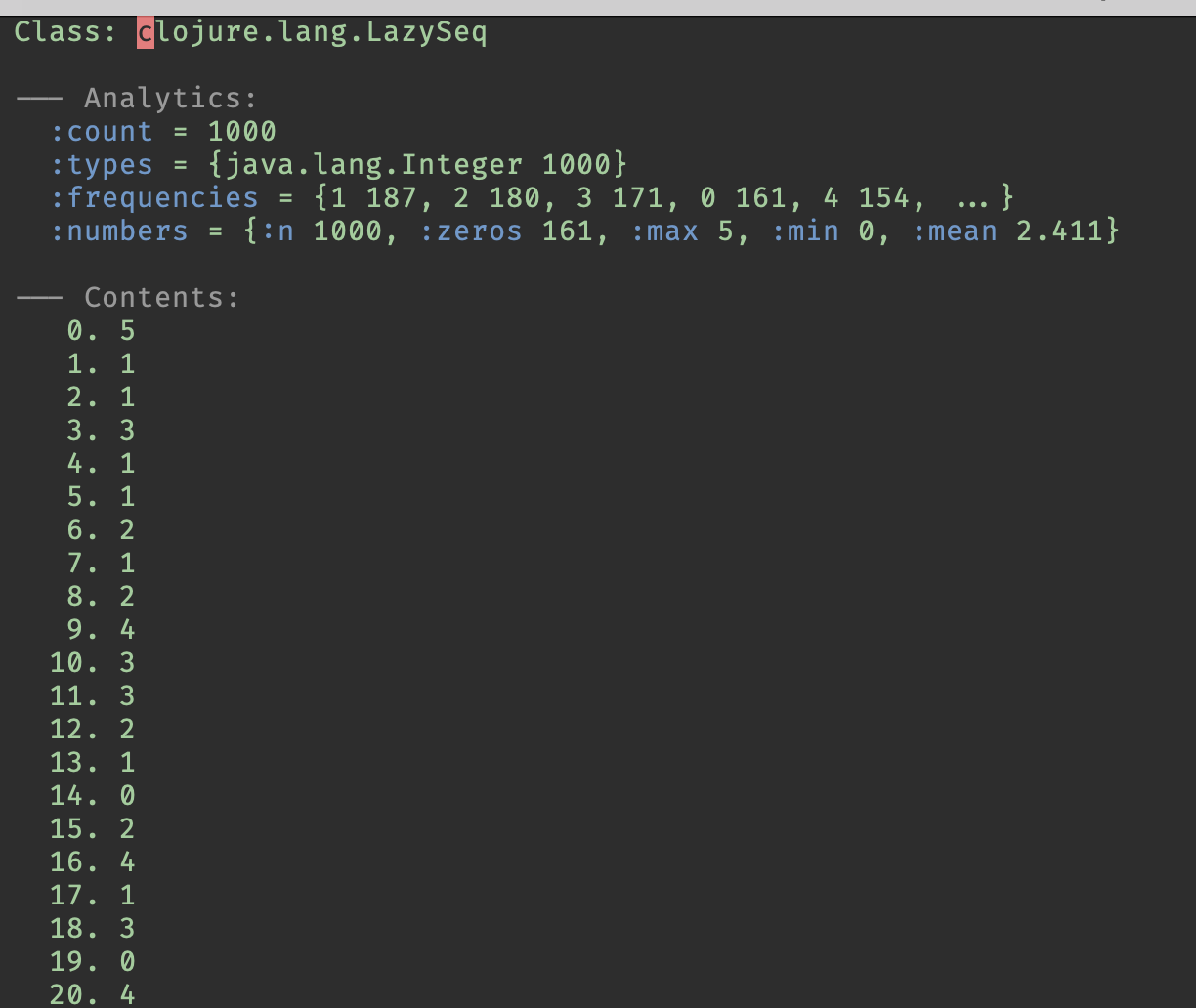
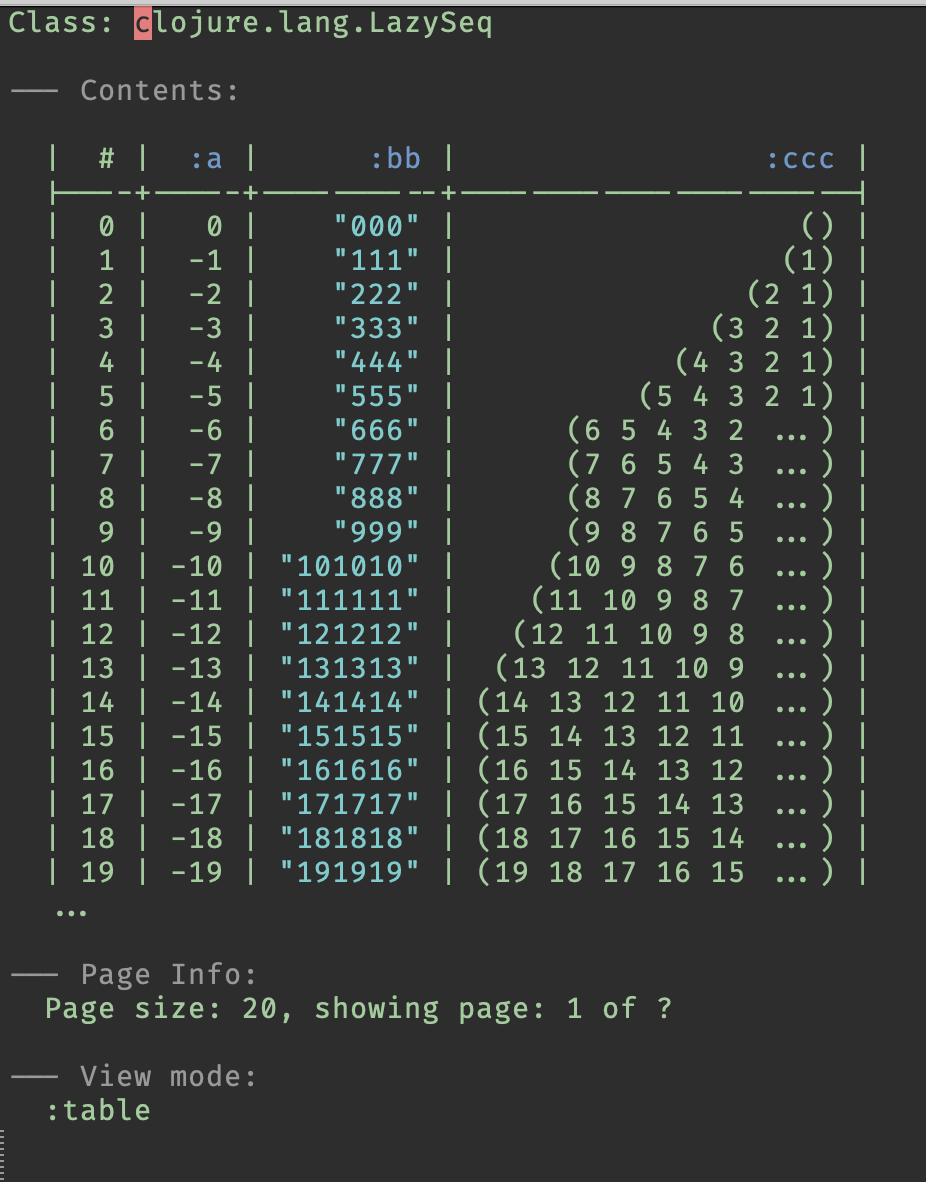
Cool stuff!
Error handling
- In exchange for removing Haystack, CIDER now allows jumping to munged Clojure functions and Java methods anywhere from the source buffers or the REPL. This means that you can press
M-.on printed frames likeclojure.core$with_bindings_STAR_.doInvokeorclojure.lang.Compiler$InvokeExpr.evalwithin the exception, and CIDER will take you there. - Stacktrace processing has been greatly simplified and optimized. You may notice that the delay between an exception occuring and
*cider-error*buffer popping up disappeared, especially in big projects. - Ex-data is now always displayed for each exception cause which has it, albeit in an abbreviated form. You can click or press
RET(a.k.a.Enter) on to open it in the inspector (#3807).
I’m guessing some of those changes might be considered slightly controversial (especially the last item), but I think they are a bit step towards simplicity and more internal consistency.
Misc features
- Completions got better with priority-based sorting and fuzzy-matching enabled by default (so you can complete unimported short classnames, and things like
cji,rkv, etc.) - The middleware that powers dynamic font-locking was made trememdously faster and more memory efficient on both Clojure and Emacs sides of CIDER. Again, this effect would be more pronounced in large codebases. This optimization is well overdue, and perhaps it will encourage more editors to embrace the
track-statemiddleware, as I think it’s one of the coolest aspects of CIDER. - Added support for dynamic indentation in clojure-ts-mode (#3803)
Side note - I’ve been spending a lot of time on clojure-ts-mode lately and it’s shaping up pretty nicely. If you’re happy with clojure-mode there’s no real reason to switch yet, but if you’ve experienced performance issues with font-locking on indentation you may want to check out clojure-ts-mode.
I’m happy to report that I’ve also finally started to clean up the numerous compilation warnings introduced in Emacs 29. Most of the meaningful problems are now addressed and the bulk of the remaining work is related to a new rule for quoting ' in docstrings, which is annoying but not particularly important.
Epilogue
This release is named “Athens” for a reason - Athens is one of the greatest cities in the world1 and I think that’s one of the greatest CIDER releases!
For me that’s one of the most important CIDER releases in the past couple of years, if not the most important. We’ve tackled a lot of long-standing problems and we’ve started to simplify the internals of CIDER. The feedback we got from the “State of CIDER” survey really helped us with some of the decisions - stay tuned for a detailed analysis of all the feedback we’ve collected there.
As usual - a huge shoutout to all the contributors and “Clojurists Together” for their support! A special thanks to Sashko Yakushev, who has been firing on all cylinders lately, and was once again the driving force behind most of the work in this release. You’re a legend, buddy!
Sadly, the amount of financial support CIDER is receiving has dropped a lot in the past 3 years (by about 50%). I hope the situation will change, as solid and predictable financial backing is the only way to ensure the long-term future of CIDER and friends.
This is all I have for you today. I hope you’ll have as much fun using it, as we had developing it! Keep hacking!
Call for Sponsors: Reagent React 19 support
Next-level backends with Rama: personalized content moderation in 60 LOC
This is part of a series of posts exploring programming with Rama, ranging from interactive consumer apps, high-scale analytics, background processing, recommendation engines, and much more. This tutorial is self-contained, but for broader information about Rama and how it reduces the cost of building backends so much (up to 100x for large-scale backends), see our website.
Like all Rama applications, the example in this post requires very little code. It’s easily scalable to millions of reads/writes per second, ACID compliant, high performance, and fault-tolerant from how Rama incrementally replicates all state. Deploying, updating, and scaling this application are all one-line CLI commands. No other infrastructure besides Rama is needed. Comprehensive monitoring on all aspects of runtime operation is built-in.
In this post, I’ll explore implementing a “mute” feature on a social network, where users can hide content from any number of other users from appearing. Code will be shown in both Clojure and Java, with the total code being 60 lines for Clojure and 80 lines for Java. You can download and play with the Clojure implementation in this repository or the Java implementation in this repository.
There are two ways to approach implementing a feature like this. The first approach is to delete content from muted users from the underlying feeds. However, this approach has two drawbacks. First, it’s not possible if multiple users are viewing the same content as a user may be muted by one viewer but not another. Second, deleting the underlying content means it won’t show up if the user is unmuted, which is undesirable.
Instead, I’ll show how to implement this by filtering the content on read. This enables the same content to be viewed with different mute settings by multiple viewers, and it makes unmuting work as desired. The filtering must be implemented efficiently so as not to unacceptably increase the latency of fetching content for the frontend. Doing many roundtrips back and forth to the backend for a page of content would create too much latency, and this implementation will require just a single roundtrip per page of content.
Backend storage
Indexed datastores in Rama, called PStates (“partitioned state”), are much more powerful and flexible than databases. Whereas databases have fixed data models, PStates can represent infinite data models due to being based on the composition of the simpler primitive of data structures. PStates are distributed, durable, high-performance, and incrementally replicated. Each PState is fine-tuned to what the application needs, and an application makes as many PStates as needed. In this case, we’ll need one PState to store content and another PState to track which users are muted by each user.
Different applications may store content differently – perhaps each user has their own feed like Twitter, perhaps there’s a global feed with content for everyone, or other variations. Implementing muting by filtering on read isn’t any different in any of these cases, so for this example each user will have their own feed of content. The PState for each user’s feed will be defined like this:
ClojureJava
| 1234 | (declare-pstate topology posts {Long (vector-schema Post {:subindex? true})}) |
|---|
| 123 | topology.pstate("$$posts", PState.mapSchema(Long.class, PState.listSchema(Map.class).subindexed())); |
|---|
This declares the PState as a map of lists, with the keys being 64-bit user IDs and the list values being post data. The name of a PState always begins with$$. For each user, it tracks their feed as a list of content. The inner list is declared as “subindexed”, which instructs Rama to store the elements individually on disk rather than the whole list read and written as one value. Subindexing enables nested data structures to have billions of elements and still be read and written to extremely quickly. This PState can support many queries in less than one millisecond: get the number of posts on a user’s feed, get a single post at a particular index, or get all posts between two indices.
The second PState tracks all the users muted by each user:
ClojureJava
| 1234 | (declare-pstate topology mutes {Long (set-schema Long {:subindex? true})}) |
|---|
| 123 | topology.pstate("$$mutes", PState.mapSchema(Long.class, PState.setSchema(Long.class).subindexed())); |
|---|
The top-level key is a 64-bit user ID, and each set value is a muted user ID. The inner set is subindexed since it can be of arbitrary size. Like the last PState, this PState supports many queries in less than a millisecond: get the number of mutes for a user, check whether a particular user is muted for a user, or get a range of muted users from the inner set.
Let’s now review the broader concepts of Rama in order to understand how these PStates will be materialized and used.
Rama concepts
A Rama application is called a “module”. In a module you define all the storage and implement all the logic needed for your backend. All Rama modules are event sourced, so all data enters through a distributed log in the module called a “depot”. Most of the work in implementing a module is coding “ETL topologies” which consume data from one or more depots to materialize any number of PStates. Modules look like this at a conceptual level:

Modules can have any number of depots, topologies, and PStates, and clients interact with a module by appending new data to a depot or querying PStates. Although event sourcing traditionally means that processing is completely asynchronous to the client doing the append, with Rama that’s optional. By being an integrated system Rama clients can specify that their appends should only return after all downstream processing and PState updates have completed.
A module deployed to a Rama cluster runs across any number of worker processes across any number of nodes, and a module is scaled by adding more workers. A module is broken up into “tasks” like so:

A “task” is a partition of a module. The number of tasks for a module is specified on deploy. A task contains one partition of every depot and PState for the module as well as a thread and event queue for running events on that task. A running event has access to all depot and PState partitions on that task. Each worker process has a subset of all the tasks for the module.
Coding a topology involves reading and writing to PStates, running business logic, and switching between tasks as necessary.
Materializing the PStates
Let’s first implement the part of the module that materializes these PStates. Then, we’ll implement the query that will dynamically filter content based on a user’s mutes.
The first step to coding the module is defining the depots:
ClojureJava
| 12345 | (defmodule ContentModerationModule [setup topologies] (declare-depot setup *post-depot (hash-by :to-user-id)) (declare-depot setup *mute-depot (hash-by :user-id)) ) |
|---|
| 1234567 | public class ContentModerationModule implements RamaModule { @Override public void define(Setup setup, Topologies topologies) { setup.declareDepot("*post-depot", Depot.hashBy("to-user-id")); setup.declareDepot("*mute-depot", Depot.hashBy("user-id")); } } |
|---|
This declares a Rama module called “ContentModerationModule” with two depots. The first depot is called*post-depotand will receive all “post” data. Objects appended to a depot can be any type. The second argument of declaring the depot is called the “depot partitioner” – more on that later.
The second depot is called*mute-depotand will receive mute and unmute events.
Part of designing Rama modules is determining how many depots to have and how to split different types of data across depots. In this case, post objects go into one depot while both mute and unmute events go in the same depot. Data should go into the same depot when there’s an ordering relationship between them, and they should otherwise go into separate depots so consumers don’t need to filter out data they’re not interested in. There’s an ordering relationship between mutes and unmutes – imagine a user were spamming the mute/unmute buttons over and over causing tons of events to be appended. If they were sent to separate depots, they could be processed in a different order than they were appended, producing the wrong result. Putting them in the same depot ensures they’re processed in the exact order they were appended. On the other hand, there’s no ordering relationship between posts and mutes/unmutes, so they can go in separate depots.
To keep the example simple, the data appended to the depots will bedefrecordobjects for the Clojure version andHashMapobjects for the Java version. To have a tighter schema on depot records you could instead use Thrift, Protocol Buffers, or a language-native tool for defining the types. Here’s the functions that will be used to create depot data:
ClojureJava
| 123 | (defrecord Post [from-user-id to-user-id content]) (defrecord Mute [user-id muted-user-id]) (defrecord Unmute [user-id unmuted-user-id]) |
|---|
| 1234567891011121314151617181920212223 | public static Map createPost(long fromUserId, long toUserId, String content) { Map ret = new HashMap(); ret.put("from-user-id", fromUserId); ret.put("to-user-id", toUserId); ret.put("content", content); return ret; } public static Map createMute(long userId, long mutedUserId) { Map ret = new HashMap(); ret.put("type", "mute"); ret.put("user-id", userId); ret.put("muted-user-id", mutedUserId); return ret; } public static Map createUnmute(long userId, long unmutedUserId) { Map ret = new HashMap(); ret.put("type", "unmute"); ret.put("user-id", userId); ret.put("unmuted-user-id", unmutedUserId); return ret; } |
|---|
Next, let’s begin defining the topology to consume data from the depots and materialize the PStates. Here’s the declaration of the topology with the PStates:
ClojureJava
| 1234567891011121314 | (defmodule ContentModerationModule [setup topologies] (declare-depot setup *post-depot (hash-by :to-user-id)) (declare-depot setup *mute-depot (hash-by :user-id)) (let [topology (stream-topology topologies "core")] (declare-pstate topology posts {Long (vector-schema Post {:subindex? true})}) (declare-pstate topology mutes {Long (set-schema Long {:subindex? true})}) )) |
|---|
| 123456789101112131415 | public class ContentModerationModule implements RamaModule { @Override public void define(Setup setup, Topologies topologies) { setup.declareDepot("*post-depot", Depot.hashBy("to-user-id")); setup.declareDepot("*mute-depot", Depot.hashBy("user-id")); StreamTopology topology = topologies.stream("core"); topology.pstate("$$posts", PState.mapSchema(Long.class, PState.listSchema(Map.class).subindexed())); topology.pstate("$$mutes", PState.mapSchema(Long.class, PState.setSchema(Long.class).subindexed())); } } |
|---|
This defines a stream topology called “core”. Rama has two kinds of topologies, stream and microbatch, which have different properties. In short, streaming is best for interactive applications that need single-digit millisecond update latency, while microbatching has update latency of a few hundred milliseconds and is best for everything else. Streaming is used here because an interactive application like this should have immediate feedback on posts, mutes, and unmutes being fully processed.
Notice that the PStates are defined as part of the topology. Unlike databases, PStates are not global mutable state. A PState is owned by a topology, and only the owning topology can write to it. Writing state in global variables is a horrible thing to do, and databases are just global variables by a different name.
Since a PState can only be written to by its owning topology, they’re much easier to reason about. Everything about them can be understood by just looking at the topology implementation, all of which exists in the same program and is deployed together. Additionally, the extra step of appending to a depot before processing the record to materialize the PState does not lower performance, as we’ve shown in benchmarks. Rama being an integrated system strips away much of the overhead which traditionally exists.
Let’s now add the code to materialize the$$postsPState:
ClojureJava
| 1234567891011121314151617 | (defmodule ContentModerationModule [setup topologies] (declare-depot setup *post-depot (hash-by :to-user-id)) (declare-depot setup *mute-depot (hash-by :user-id)) (let [topology (stream-topology topologies "core")] (declare-pstate topology posts {Long (vector-schema Post {:subindex? true})}) (declare-pstate topology mutes {Long (set-schema Long {:subindex? true})}) (<<sources topology (source> *post-depot :> {:keys [*to-user-id] :as *post}) (local-transform> [(keypath *to-user-id) AFTER-ELEM (termval *post)] posts)))) |
|---|
| 12345678910111213141516171819202122 | public class ContentModerationModule implements RamaModule { @Override public void define(Setup setup, Topologies topologies) { setup.declareDepot("*post-depot", Depot.hashBy("to-user-id")); setup.declareDepot("*mute-depot", Depot.hashBy("user-id")); StreamTopology topology = topologies.stream("core"); topology.pstate("$$posts", PState.mapSchema(Long.class, PState.listSchema(Map.class).subindexed())); topology.pstate("$$mutes", PState.mapSchema(Long.class, PState.setSchema(Long.class).subindexed())); topology.source("*post-depot").out("*post") .each(Ops.GET, "*post", "to-user-id").out("*to-user-id") .localTransform("$$posts", Path.key("*to-user-id") .afterElem() .termVal("*post")); } } |
|---|
The code to materialize that PState is only a few lines, but there’s a lot to unpack here. The business logic is implemented with dataflow. Rama’s dataflow API is exceptionally expressive, able to intermix arbitrary business logic with loops, conditionals, and moving computation between tasks. This post is not going to explore all the details of dataflow as there’s simply too much to cover. Full tutorials for Rama dataflow can be found on our website for the Java API and for the Clojure API.
Let’s go over each line of this code. The first step is subscribing to the depot:
ClojureJava
| 12 | (<<sources topology (source> *post-depot :> {:keys [*to-user-id] :as *post}) |
|---|
| 12 | topology.source("*post-depot").out("*post") .each(Ops.GET, "*post", "to-user-id").out("*to-user-id") |
|---|
This subscribes the topology to the depot*post-depotand starts a reactive computation on it. Operations in dataflow do not return values. Instead, they emit values that are bound to new variables. In the Clojure API, the input and outputs to an operation are separated by the:>keyword. In the Java API, output variables are bound with the.outmethod.
Whenever data is appended to that depot, the data is emitted into the topology. The Java versions binds the emit into the variable*postand then gets the fields “to-user-id” from the map into the variable*to-user-id, while the Clojure version captures the emit as the variable*postand also destructures the “to-user-id” field into the variable*to-user-id. All variables in Rama code begin with a*. The subsequent code runs for every single emit.
Remember that last argument to the depot declaration called the “depot partitioner”? That’s relevant here. Here’s that image of the physical layout of a module again:
The depot partitioner determines on which task the append happens and thereby on which task computation begins for subscribed topologies. In this case, the depot partitioner says to hash by the “to-user-id” field of the appended data. The target task is computed by taking the hash and modding it by the total number of tasks. This means data with the same ID always go to the same task, while different IDs are evenly spread across all tasks.
Rama gives a ton of control over how computation and storage are partitioned, and in this case we’re partitioning by the hash of “to-user-id” since that’s how we want the PState to be partitioned. This allows us to easily locate the task storing posts for any particular user.
The next line completes this part of the topology by writing the post into the PState:
ClojureJava
| 12 | (local-transform> [(keypath *to-user-id) AFTER-ELEM (termval *post)] posts) |
|---|
| 1234 | .localTransform("$$posts", Path.key("*to-user-id") .afterElem() .termVal("*post")); |
|---|
The PState is updated with the “local transform” operation. The transform takes in as input the PState$$postsand a “path” specifying what to change about the PState. When a PState is referenced in dataflow code, it always references the partition of the PState that’s located on the task on which the event is currently running.
Paths are a deep topic, and the full documentation for them can be found here. A path is a sequence of “navigators” that specify how to hop through a data structure to target values of interest. A path can target any number of values, and they’re used for both transforms and queries. In this case, the path navigates by the key*to-user-idto the list of posts for that user. The next navigator, calledAFTER-ELEMin Clojure andafterElem()in Java, navigates to the “void” element after the end of the list. Setting that “void” element to a value with the “term val” navigator causes that value to be appended to that list.
Let’s now add the code to materialize the$$mutesPState:
ClojureJava
| 12345678910111213141516171819202122232425262728 | (defmodule ContentModerationModule [setup topologies] (declare-depot setup *post-depot (hash-by :to-user-id)) (declare-depot setup *mute-depot (hash-by :user-id)) (let [topology (stream-topology topologies "core")] (declare-pstate topology posts {Long (vector-schema Post {:subindex? true})}) (declare-pstate topology mutes {Long (set-schema Long {:subindex? true})}) (<<sources topology (source> *post-depot :> {:keys [*to-user-id] :as *post}) (local-transform> [(keypath *to-user-id) AFTER-ELEM (termval *post)] posts) (source> *mute-depot :> *data) (<<subsource *data (case> Mute :> {:keys [*user-id *muted-user-id]}) (local-transform> [(keypath *user-id) NONE-ELEM (termval *muted-user-id)] mutes) (case> Unmute :> {:keys [*user-id *unmuted-user-id]}) (local-transform> [(keypath *user-id) (set-elem *unmuted-user-id) NONE>] mutes) )))) |
|---|
| 12345678910111213141516171819202122232425262728293031323334353637 | public class ContentModerationModule implements RamaModule { @Override public void define(Setup setup, Topologies topologies) { setup.declareDepot("*post-depot", Depot.hashBy("to-user-id")); setup.declareDepot("*mute-depot", Depot.hashBy("user-id")); StreamTopology topology = topologies.stream("core"); topology.pstate("$$posts", PState.mapSchema(Long.class, PState.listSchema(Map.class).subindexed())); topology.pstate("$$mutes", PState.mapSchema(Long.class, PState.setSchema(Long.class).subindexed())); topology.source("*post-depot").out("*post") .each(Ops.GET, "*post", "to-user-id").out("*to-user-id") .localTransform("$$posts", Path.key("*to-user-id") .afterElem() .termVal("*post")); topology.source("*mute-depot").out("*data") .each(Ops.GET, "*data", "type").out("*type") .each(Ops.GET, "*data", "user-id").out("*user-id") .ifTrue(new Expr(Ops.EQUAL, "*type", "mute"), Block.each(Ops.GET, "*data", "muted-user-id").out("*muted-user-id") .localTransform("$$mutes", Path.key("*user-id") .voidSetElem() .termVal("*muted-user-id")), Block.each(Ops.GET, "*data", "unmuted-user-id").out("*unmuted-user-id") .localTransform("$$mutes", Path.key("*user-id") .setElem("*unmuted-user-id") .termVoid())); } } |
|---|
Once again, let’s go through the new code line by line:
ClojureJava
| 1 | (source> *mute-depot :> *data) |
|---|
| 1 | topology.source("*mute-depot").out("*data") |
|---|
This adds a new depot subscription to*mute-depotto the same topology. Topologies can subscribe to any number of depots, and each source subscription is processed independently. This code binds emits from that depot to the variable*data.
This depot emits “mute” and “unmute” events. Mutes should add to the PState, while unmutes should remove from the PState. The subsequent code adds a conditional on the type of*data:
ClojureJava
| 123 | .each(Ops.GET, "*data", "type").out("*type").each(Ops.GET, "*data", "user-id").out("*user-id").ifTrue(new Expr(Ops.EQUAL, "*type", "mute"), |
|---|
The Java and Clojure versions implement this a little differently since the Clojure version is using first-class types while the Java version is using plain maps with a “type” key inside.
The Clojure version uses <<subsource , which is a convenient way to dispatch code on the type of an object. You could also use <<if or <<cond for this, but the<<subsourceversion is a little more concise.
The Java version fetches the “type” and “user-id” fields from the map into the variables*typeand*user-id.*user-idwill be used a little later. It then uses.ifTrueto check if*typeis equal to “mute”. The “then” branch of that conditional will handle mutes, and then “else” branch will handle unmutes.
The next bit of code handles mutes:
ClojureJava
| 123 | (case> Mute :> {:keys [*user-id *muted-user-id]}) (local-transform> [(keypath *user-id) NONE-ELEM (termval *muted-user-id)] mutes) |
|---|
| 12345 | Block.each(Ops.GET, "*data", "muted-user-id").out("*muted-user-id") .localTransform("$$mutes", Path.key("*user-id") .voidSetElem() .termVal("*muted-user-id")), |
|---|
In the Clojure version,case>begins a handler for a particular type given to the surrounding<<subsourceform. Thiscase>handlesMuteobjects.case>allows the object given to<<subsourceto be further destructured in its emit. Here it destructures*user-idand*muted-user-idfrom*data.
The Java version fetches the “muted-user-id” field from the map into the variable*muted-user-id.
Then, the “local transform” operation is invoked to update the$$mutesPState. The path used is similar to the path from the earlier “local transform”, but the inner data structure being updated is a set instead of a list. The path first navigates to the inner set by the key*user-id. The next navigator, calledNONE-ELEMin Clojure andvoidSetElemin Java, navigates to the “void” element of the set. Setting that “void” element to a value causes that value to be added to that set.
Adding to a set is idempotent, so if the frontend were to append multiple mutes for the same user in a row, the mute for that user will only exist one time in the set.
The last part of the topology handles unmutes:
ClojureJava
| 123 | (case> Unmute :> {:keys [*user-id *unmuted-user-id]}) (local-transform> [(keypath *user-id) (set-elem *unmuted-user-id) NONE>] mutes) |
|---|
| 12345 | Block.each(Ops.GET, "*data", "unmuted-user-id").out("*unmuted-user-id") .localTransform("$$mutes", Path.key("*user-id") .setElem("*unmuted-user-id") .termVoid()) |
|---|
This is the inverse of the previous case. The Clojure version declares acase>to handleUnmuteobjects and destructure*user-idand*unmuted-user-id. The Java version is the “else” branch of the.ifTrueand starts by fetching “unmuted-user-id” from the map into the variable*unmuted-user-id.
Then, a “local transform” is done to remove the user from the set of mutes. The path first navigates to the inner set by the key*user-id. The next navigator, calledset-elemin Clojure andsetElemin Java, navigates to the specified element of the set if it exists. If the element doesn’t exist, the path navigates nowhere and the transform is a no-op. The last navigator removes the element from the set. Removing elements with paths is done in Clojure withNONE>and in Java with.termVoid(). This navigator sets the element to “void”, which causes it to be removed from its containing data structure.
That completes the materialization of$$postsand$$mutes. Now we’re ready to move on to implementing an efficient query to fetch a page from$$postswith muted content filtered out.
Implementing the query
At a high-level, the query needs to fetch some number of posts for a user starting from an index. For example, “fetch 10 posts for user ID 123 starting from index 75”. Because any number of posts could be filtered by muting, the fetched posts are not necessarily consecutive and many more posts may need to be read from the PState to find the desired number of posts from non-muted users. If you’re looking for 10 posts, you may need to read 11 posts, 20 posts, 100 posts, or more depending on how many posts get filtered. Since the total number of posts that needs to be read cannot be known in advance, a loop of some sort is needed to continue scanning until the desired number of posts is found.
With that in mind, here’s the algorithm to implement the query “fetch 10 posts for user ID 123 starting from index 75”:
- Set N=10, START_OFFSET=75
- Read posts for user ID 123 from PState
$$postsfrom indices START_OFFSET to START_OFFSET + N - For each post, check if the poster is muted by user ID 123 in the
$$mutesPState - Set NUM_FETCHED_POSTS equal to the number of posts remaining after filtering
- If NUM_FETCHED_POSTS is less than N, go back to step 2 with N set to (N – NUM_FETCHED_POSTS) and START_OFFSET set to START_OFFSET + N
This algorithm iteratively fetches content from the$$postsPState until the desired number of posts is found.
In the case of a user having a ton of mutes set as well as a lot of posts, it’s possible this algorithm could take a long time to scan through the$$postsPState to find the desired number of posts. If this is a concern, the algorithm could be enhanced to have an upper limit on the number of times it loops. This implementation won’t do that, but it’s easy to add if needed.
This will be implemented via a predefined query in the module called a “query topology”. Query topologies are programmed with the exact same dataflow API as we already used to implement the ETL topology. All the behavior of this algorithm – looping, checking posts to see if they should be filtered, and aggregating results will all be done within the module. This means the client doing the query only has to make one request to the backend. If the client implemented this algorithm client-side, it would have to make many requests adding a lot of overhead for all the roundtrips. Implementing as a query topology eliminates all that overhead which minimizes the latency of the query.
Query topologies are like functions in Java or Clojure. They take in any number of input arguments and return one value as the result. As such, query topologies can be decomposed into multiple query topologies just like you can decompose a function’s implementation into multiple functions. This query will be implemented with two query topologies. The first will fetch a page of posts and filter them according to mute settings. The second will use the first query topology and loop until the desired number of posts have been found.
Implementing the first query topology
Let’s start with the first query topology. Here it is defined in the module:
ClojureJava
| 123456789101112131415161718192021222324252627282930313233343536373839 | (defmodule ContentModerationModule [setup topologies] (declare-depot setup *post-depot (hash-by :to-user-id)) (declare-depot setup *mute-depot (hash-by :user-id)) (let [topology (stream-topology topologies "core")] (declare-pstate topology posts {Long (vector-schema Post {:subindex? true})}) (declare-pstate topology mutes {Long (set-schema Long {:subindex? true})}) (<<sources topology (source> *post-depot :> {:keys [*to-user-id] :as *post}) (local-transform> [(keypath *to-user-id) AFTER-ELEM (termval *post)] posts) (source> *mute-depot :> *data) (<<subsource *data (case> Mute :> {:keys [*user-id *muted-user-id]}) (local-transform> [(keypath *user-id) NONE-ELEM (termval *muted-user-id)] mutes) (case> Unmute :> {:keys [*user-id *unmuted-user-id]}) (local-transform> [(keypath *user-id) (set-elem *unmuted-user-id) NONE>] mutes) ))) (<<query-topology topologies "get-posts-helper" [*user-id *start-offset *end-offset :> *posts] (|hash *user-id) (local-select> [(keypath *user-id) (srange *start-offset *end-offset) ALL] posts :> {:keys [*from-user-id] :as *post}) (local-select> [(keypath *user-id) (view contains? *from-user-id)] mutes :> *muted?) (filter> (not *muted?)) (|origin) (aggs/+vec-agg *post :> *posts)) ) | | --------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051 | public class ContentModerationModule implements RamaModule { @Override public void define(Setup setup, Topologies topologies) { setup.declareDepot("*post-depot", Depot.hashBy("to-user-id")); setup.declareDepot("*mute-depot", Depot.hashBy("user-id")); StreamTopology topology = topologies.stream("core"); topology.pstate("$$posts", PState.mapSchema(Long.class, PState.listSchema(Map.class).subindexed())); topology.pstate("$$mutes", PState.mapSchema(Long.class, PState.setSchema(Long.class).subindexed())); topology.source("*post-depot").out("*post") .each(Ops.GET, "*post", "to-user-id").out("*to-user-id") .localTransform("$$posts", Path.key("*to-user-id") .afterElem() .termVal("*post")); topology.source("*mute-depot").out("*data") .each(Ops.GET, "*data", "type").out("*type") .each(Ops.GET, "*data", "user-id").out("*user-id") .ifTrue(new Expr(Ops.EQUAL, "*type", "mute"), Block.each(Ops.GET, "*data", "muted-user-id").out("*muted-user-id") .localTransform("$$mutes", Path.key("*user-id") .voidSetElem() .termVal("*muted-user-id")), Block.each(Ops.GET, "*data", "unmuted-user-id").out("*unmuted-user-id") .localTransform("$$mutes", Path.key("*user-id") .setElem("*unmuted-user-id") .termVoid())); topologies.query("get-posts-helper", "*user-id", "*start-offset", "*end-offset").out("*posts") .hashPartition("*user-id") .localSelect("$$posts", Path.key("*user-id") .sublist("*start-offset", "*end-offset") .all()).out("*post") .each(Ops.GET, "*post", "from-user-id").out("*from-user-id") .localSelect("$$mutes", Path.key("*user-id") .view(Ops.CONTAINS, "*from-user-id")).out("*muted?") .keepTrue(new Expr(Ops.NOT, "*muted?")) .originPartition() .agg(Agg.list("*post")).out("*posts"); } } |
|---|
Once again, let’s go through the topology definition line by line to understand how it works:
ClojureJava
| 12 | (<<query-topology topologies "get-posts-helper" [*user-id *start-offset *end-offset :> *posts] |
|---|
| 1 | topologies.query("get-posts-helper", "*user-id", "*start-offset", "*end-offset").out("*posts") |
|---|
This declares a query topology named “get-posts-helper” that takes in input arguments*user-id,*start-offset, and*end-offset. It declares the return variable*posts, which will be bound by the end of the topology execution.
The next line gets the query to the task of the module containing the data for that user ID:
ClojureJava
| 1 | .hashPartition("*user-id") |
|---|
The line does a “hash partition” by the value of*user-id. Partitioners relocate subsequent code to potentially a new task, and a hash partitioner works exactly like the aforementioned depot partitioner. The details of relocating computation, like serializing and deserializing any variables referenced after the partitioner, are handled automatically. The code is linear without any callback functions even though partitioners could be jumping around to different tasks on different nodes.
When the first operation of a query topology is a partitioner, query topology clients are optimized to go directly to that task. You’ll see an example of invoking a query topology in the next section.
The next bit of code fetches all posts in the requested range:
ClojureJava
| 12 | (local-select> [(keypath *user-id) (srange *start-offset *end-offset) ALL] posts :> {:keys [*from-user-id] :as *post}) |
|---|
| 12345 | .localSelect("$$posts", Path.key("*user-id") .sublist("*start-offset", "*end-offset") .all()).out("*post").each(Ops.GET, "*post", "from-user-id").out("*from-user-id") |
|---|
A “local select” does a query on the partition of the PState that’s on the same task on which the event is running. This path first navigates to the list of posts for the key*user-id. It then navigates to the “sublist” between*start-offsetand*end-offset. At this point the path is navigated to a single list of values. The last navigator navigates to each individual element of that sublist, causing the “local select” to emit one time for each post in that range.
What’s happening here is very different from “regular” programming, where you call a function which returns one value as the result. In dataflow programming, operations can emit any number of times. You can think of the output of an operation as being the input arguments to the rest of the topology. When an operation emits, it invokes the “rest of the topology” with those arguments (the “rest of the topology” is also known as the “continuation”). This is a powerful generalization of the concept of a function, which as you’re about to see enables very elegant code.
The code after the “local select” is now operating on a single post at a time, and you’ll see how the results are aggregated together at the end. The output of the “local select” is bound to the variable*post. The Clojure version destructures the fieldfrom-user-idfrom that object into the variable*from-user-id, and the Java version fetches the field “from-user-id” from the map into the variable*from-user-id.
The next line checks to see if that user is muted:
ClojureJava
| 12 | (local-select> [(keypath *user-id) (view contains? *from-user-id)] mutes :> *muted?) |
|---|
| 123 | .localSelect("$$mutes", Path.key("*user-id") .view(Ops.CONTAINS, "*from-user-id")).out("*muted?") |
|---|
This code does a “local select” on the$$mutesPState. Since the$$mutesPState stores data with the same partitioning scheme as the$$postsPState – by the hash of the top-level key – the code does not need to switch to a different task with a partitioner before querying.
The query emits a single boolean to the variable*muted?on whether that user who made the post is muted or not. The path first navigates to the inner set by the key*user-id. The next navigator,view, runs a function on the navigated value. The function can be any Java or Clojure function, and it’s given as arguments the navigated value plus any additional arguments given toview. In this case it just checks if the posting user ID is contained in the set.
The next line filters out posts from muted users:
ClojureJava
| 1 | .keepTrue(new Expr(Ops.NOT, "*muted?")) |
|---|
This operation,filter>in Clojure and.keepTruein Java, emits exactly one time if its input is true and otherwise doesn’t emit. Just like how the “local select” call differs from regular functions by emitting many times, this differs from regular functions by potentially not emitting at all. No values are captured for the output since this operation doesn’t emit any values when it emits, but you can still think of its emit as invoking the “rest of the topology”.
In this case, the code only continues for users that aren’t muted.
The next line is:
The “origin partitioner” relocates computation to the task where the query began execution. Every query topology must use the origin partitioner exactly once and as the last partitioner used.
The last line of the query topology aggregates the remaining posts together:
ClojureJava
| 1 | (aggs/+vec-agg *post :> *posts) |
|---|
| 1 | .agg(Agg.list("*post")).out("*posts"); |
|---|
Up until here, the query topology has been just like the ETL topology. Every line processed emits from the preceding line and emitted some number of times itself. Aggregators in dataflow are different in that they’re collecting all emits that happened in the execution of the query topology and combining them into a single value.
Query topologies are “batch blocks”, which have expanded dataflow capabilities including aggregation. Batch blocks can also do inner joins, outer joins, subqueries, and everything else possible with relational languages. You can find the full documentation for batch blocks here, with Clojure-specific documentation here.
This particular aggregator combines all the remaining posts into a single list into the variable*posts.*postsis the same variable name as declared earlier for the output of the query topology.
This completes the first query topology.
Implementing the second query topology
Let’s now implement the second query topology, which uses the first query topology inside a loop to find the desired number of posts. Here’s the full definition:
ClojureJava
| 1234567891011121314151617181920212223 | (<<query-topology topologies "get-posts" [*user-id *from-offset *limit :> *ret] (|hash *user-id) (loop<- [*query-offset *from-offset *posts [] :> *posts *next-offset] (local-select> [(keypath *user-id) (view count)] posts :> *num-posts) (- *limit (count *posts) :> *fetch-amount) (min *num-posts (+ *query-offset *fetch-amount) :> *end-offset) (invoke-query "get-posts-helper" *user-id *query-offset *end-offset :> *fetched-posts) (reduce conj *posts *fetched-posts :> *new-posts) (<<cond (case> (= *end-offset *num-posts)) (:> *new-posts nil) (case> (= (count *new-posts) *limit)) (:> *new-posts *end-offset) (default>) (continue> *end-offset *new-posts) )) (|origin) (hash-map :posts *posts :next-offset *next-offset :> *ret)) | | ------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| 1234567891011121314151617181920212223242526272829 | topologies.query("get-posts", "*user-id", "*from-offset", "*limit").out("*ret") .hashPartition("*user-id") .each(() -> new ArrayList()).out("*posts") .loopWithVars(LoopVars.var("*query-offset", "*from-offset"), Block.localSelect("$$posts", Path.key("*user-id").view(Ops.SIZE)).out("*num-posts") .each(Ops.MINUS, "*limit", new Expr(Ops.SIZE, "*posts")).out("*fetch-amount") .each(Ops.MIN, "*num-posts", new Expr(Ops.PLUS, "*query-offset", "*fetch-amount")).out("*end-offset") .invokeQuery("get-posts-helper", "*user-id", "*query-offset", "*end-offset").out("*fetched-posts") .each((List posts, List fetchedPosts) -> posts.addAll(fetchedPosts), "*posts", "*fetched-posts") .cond(Case.create(new Expr(Ops.EQUAL, "*end-offset", "*num-posts")) .emitLoop(null), Case.create(new Expr(Ops.EQUAL, new Expr(Ops.SIZE, "*posts"), "*limit")) .emitLoop("*end-offset"), Case.create(true) .continueLoop("*end-offset")) ).out("*next-offset") .originPartition() .each((List posts, Integer nextOffset) -> { Map ret = new HashMap(); ret.put("posts", posts); ret.put("next-offset", nextOffset); return ret; }, "*posts", "*next-offset").out("*ret"); |
|---|
Once again, let’s go through this line by line:
ClojureJava
| 1 | (<<query-topology topologies "get-posts" [*user-id *from-offset *limit :> *ret] |
|---|
| 1 | topologies.query("get-posts", "*user-id", "*from-offset", "*limit").out("*ret") |
|---|
This declares the query topology “get-posts” with input arguments*user-id,*from-offset, and*limit. It declares the return variable*ret, which will be bound by the end of the topology execution.
Just like the first query topology, the next line gets the query to the task of the module containing the data for that user ID:
ClojureJava
| 1 | .hashPartition("*user-id") |
|---|
The next bit of code begins the loop that will run for as many iterations as necessary to find the desired number of posts for non-muted users:
ClojureJava
| 123 | (loop<- [*query-offset *from-offset *posts [] :> *posts *next-offset] |
|---|
| 12 | .each(() -> new ArrayList()).out("*posts").loopWithVars(LoopVars.var("*query-offset", "*from-offset"), |
|---|
Loops in dataflow first declare “loop variables” which are in scope for the body of the loop and are set to new values each time the loop is recurred. The Clojure version declares two loop variables,*query-offsetand*posts, which are initialized to*from-offsetand[]respectively. The Java version will collect posts into a mutableArrayList, so it initializes thatArrayListinto the variable*postsbefore the loop. The Java version’s only loop var is*query-offsetwhich is initialized to*from-offset.
Loops can be emitted from any number of times (with:>in Clojure and.emitLoopin Java), and each emit runs the code after the loop with the emitted values. The Clojure version binds the emitted values from this loop as*postsand*next-offsetin the binding vector. The Java version specifies emitted loop values at the end of the loop body. Again, since the Java version is accumulating posts into a mutable value its loop will only emit the one value*next-offset.
This query topology will return the fetched posts as well as this*next-offsetvalue. In order for the frontend to paginate to the next page of posts, it needs to know where the prior query topology left off in its traversal. Returning*next-offsethere lets the frontend know exactly where to begin for the next page. Additionally, this query topology will return “null” for*next-offsetif it reached the end of the list of posts, which indicates to the frontend that it reached the last page.
The first query topology needs to know the range of offsets to fetch from the subindexed list of posts. The next line starts to prepare for that by querying for the total number of posts in the PState for this user:
ClojureJava
| 1 | (local-select> [(keypath *user-id) (view count)] posts :> *num-posts) |
|---|
| 1 | .localSelect("$$posts", Path.key("*user-id").view(Ops.SIZE)).out("*num-posts") |
|---|
This “local select” call is similar to the earlier one, usingviewto run a function on the nested list to get the total number of posts and bind that to*num-posts. Fetching the size of a subindexed list is a fast sub-millisecond query even if the list has billions of elements.
The next two lines determine the last offset that will be fetched:
ClojureJava
| 12 | (- *limit (count *posts) :> *fetch-amount) (min *num-posts (+ *query-offset *fetch-amount) :> *end-offset) |
|---|
| 1234 | .each(Ops.MINUS, "*limit", new Expr(Ops.SIZE, "*posts")).out("*fetch-amount").each(Ops.MIN, "*num-posts", new Expr(Ops.PLUS, "*query-offset", "*fetch-amount")).out("*end-offset") |
|---|
The number of posts remaining to fetch is simply the number of desired posts,*limit, subtracted by the number of posts fetched so far. This is bound to the variable*fetch-amount. The last offset to query is the minimum of the last offset in the subindexed list and*fetch-amountoffsets after the query offset. The result of that is bound to*end-offset.
The next line invokes the first query topology to get the posts between those offsets from non-muted users:
ClojureJava
| 12 | (invoke-query "get-posts-helper" *user-id *query-offset *end-offset :> *fetched-posts) |
|---|
| 1234 | .invokeQuery("get-posts-helper", "*user-id", "*query-offset", "*end-offset").out("*fetched-posts") |
|---|
Invoking another query topology is just like invoking a function. It’s given input arguments and then emits a single value. In this case it emits a list of posts. Query topologies can also invoke themselves, or query topologies can be mutually recursive. This is discusses in this section of the docs.
The next line adds the fetched posts to the list of accumulated posts so far:
ClojureJava
| 1 | (reduce conj *posts *fetched-posts :> *new-posts) |
|---|
| 12 | .each((List posts, List fetchedPosts) -> posts.addAll(fetchedPosts), "*posts", "*fetched-posts") |
|---|
The Clojure version appends all the fetched posts into*poststo produce the new variable*new-posts. The Java version uses a lambda to add the fetched posts into theArrayListwith itsaddAllmethod. It gives the lambda the arguments from dataflow*postsand*fetched-posts, which become the arguments to the lambda. This code shows how arbitrary Java code can be injected into dataflow, and you can also do so with method references as well.
The code now needs to determine what to do depending on the current state. There are two cases to check: “has it reached the end of the list of posts?”, and “has it found the desired number of posts?”. If the answer to either of those is true, traversal is finished and it should finish the query topology execution. Otherwise, it should continue traversing.
You could implement this with nested “if” conditionals (<<ifin the Clojure API and.ifTruein the Java API), but Rama provides a more elegant way to express code that needs to check more than one condition through its “cond” operation. The next code begins this form of conditional like so:
This operation is given a series of “cases” to check. The first case that evaluates to true will have its body run and then no other cases will be checked.
The first case is whether it has reached the end of the list of posts:
ClojureJava
| 12 | (case> (= *end-offset *num-posts)) (:> *new-posts nil) |
|---|
| 12 | Case.create(new Expr(Ops.EQUAL, "*end-offset", "*num-posts")) .emitLoop(null), |
|---|
It’s reached the end when the*end-offsetcomputed earlier is the same as the total number of posts. The subsequent code is the body of the “case”, which can be any amount of arbitrary dataflow code. In this case, there’s only one line which says to emit from the loop. As explained earlier, the loop emits the “next offset” which will be included in the return value so the frontend knows where to begin in order to query the next page of content. The Clojure version emits the full accumulation of posts along withnilfor the “next offset”, which indicates it reached the end of the list of posts. The Java version just emitsnullfor the “next offset”.
The next case checks if the desired number of posts from non-muted users was found:
ClojureJava
| 12 | (case> (= (count *new-posts) *limit)) (:> *new-posts *end-offset) |
|---|
| 12 | Case.create(new Expr(Ops.EQUAL, new Expr(Ops.SIZE, "*posts"), "*limit")) .emitLoop("*end-offset"), |
|---|
The desired number of posts has been found if the size of the list of accumulated posts is equal to the*limitargument for the query topology. The body of this case emits from the loop. The Clojure version emits the full accumulation of posts along with*end-offsetfor the “next offset”. The Java version just emits*end-offsetfor the “next offset”.
Finally, the last case invokes another iteration of the loop:
ClojureJava
| 12 | (default>) (continue> *end-offset *new-posts) |
|---|
| 12 | Case.create(true) .continueLoop("*end-offset"))).out("*next-offset") |
|---|
Usingdefault>in the Clojure API is the same as saying(case> true). The body of this case invokes the next iteration of the loop withcontinue>in the Clojure API andcontinueLoopin the Java API. This runs the loop from the start with new values for the loop vars.
The.outin the Java version binds the output of the loop into the variable*next-offset, which in the Clojure version was specified in the binding vector at the beginning of the loop.
The next line, which is after the loop, invokes the required “origin partitioner”:
Finally, the end of the query topology packages together the posts and “next offset” into a single map for the return value:
ClojureJava
| 1 | (hash-map :posts *posts :next-offset *next-offset :> *ret) |
|---|
| 123456 | .each((List posts, Integer nextOffset) -> { Map ret = new HashMap(); ret.put("posts", posts); ret.put("next-offset", nextOffset); return ret; }, "*posts", "*next-offset").out("*ret"); |
|---|
This map is bound to the variable*ret, which is the same as the output variable for the query topology specified in the beginning.
This completes the definition of the query to fetch a page of content for a user. Since it’s executing entirely in the module, the query is extremely efficient since the client only has to make a single request. All the overhead of making network requests and serializing/deserializing values back and forth is completely avoided.
Interacting with the module
Let’s now take a look at how you would interact with the module to do appends and queries, such as from a web server. Here’s an example of how you would get clients to the depots and query topology:
ClojureJava
| 1234567891011121314151617 | (def manager (open-cluster-manager {"conductor.host" "1.2.3.4"})) (def post-depot (foreign-depot manager "nlb.content-moderation/ContentModerationModule" "*post-depot")) (def mute-depot (foreign-depot manager "nlb.content-moderation/ContentModerationModule" "*mute-depot")) (def get-posts (foreign-query manager "nlb.content-moderation/ContentModerationModule" "get-posts" )) |
|---|
| 1234567 | Map config = new HashMap();config.put("conductor.host", "1.2.3.4");RamaClusterManager manager = RamaClusterManager.open(config);Depot postDepot = manager.clusterDepot("nlb.ContentModerationModule", "*post-depot");Depot muteDepot = manager.clusterDepot("nlb.ContentModerationModule", "*mute-depot");QueryTopologyClient<Map> getPosts = manager.clusterQuery("nlb.ContentModerationModule", "get-posts"); |
|---|
A “cluster manager” connects to a Rama cluster by specifying the location of its “Conductor” node. The “Conductor” node is the central node of a Rama cluster, which you can read more about here. From the cluster manager, you can retrieve clients to any depots, PStates, or query topologies for any module. The objects are identified by the module name and their name within the module.
Here’s an example of appending a new post to the depot using the function defined earlier to create the data:
ClojureJava
| 1 | (foreign-append! post-depot (->Post 100 101 "Hello!")); |
|---|
| 1 | postDepot.append(createPost(100, 101, "Hello!")); |
|---|
This adds a post from user 100 to user 101 with the content “Hello!”. Appending mutes and unmutes to the mute depot works exactly the same way, just with different data to a different depot.
Here’s an example of invoking the query topology to get a page of content:
ClojureJava
| 1 | (foreign-invoke-query get-posts 101 0 10) |
|---|
| 1 | getPosts.invoke(101L, 0, 10); |
|---|
This looks no different than invoking any other function, but it’s actually executing remotely on a cluster. It fetches 10 posts starting from offset 0 for user 101. This returns a hash map containing the list of posts and the start offset to use for the next page, just as defined in the query topology.
Summary
There’s a lot to learn with Rama, but you can see from this example application how much you can accomplish with very little code. Building efficient content moderation like this is no small feat, but with Rama it only took 60 lines of code in Clojure and 80 lines of code in Java. There’s no additional work needed for deployment, updating, and scaling since that’s all built-in to Rama. For an experienced Rama programmer, a project like this takes only a few hours to fully develop, test, and have ready for deployment.
This example particularly demonstrates the power of colocating computation and storage. The ability for a query topology to do a looping computation with arbitrary logic over multiple colocated PStates is both powerful and extremely performant.
As mentioned earlier, there’s a Github project for the Clojure version and for the Java version containing all the code in this post. Those projects also have tests showing how to unit test modules in Rama’s “in-process cluster” environment.
You can get in touch with us at consult@redplanetlabs.com to schedule a free consultation to talk about your application and/or pair program on it. Rama is free for production clusters for up to two nodes and can be downloaded at this page.
How to choose the target language for a migration
How to choose the target language for a migration? There are moments in the life of a software system—and in the life of those responsible for it—when you feel trapped.
Trapped by a language that once served you well but now feels like a cage. You have an important application, something your business depends on, but the technology it’s built on is making your life miserable. Every change feels like climbing a mountain and you find yourself thinking, “Why is this so hard?”
You don’t think about migrating just because things are slightly inconvenient. You consider migration when the pain becomes too much and you know something has to change.
So you wait longer than you should and then you start thinking: “What if we move to a different language?”
But this brings you to the first, most critical obstacle: which language? You know migration isn’t a small task. It will take time, effort, and resources. And the last thing you want is to jump out of the frying pan and into the fire.
Maybe you’re not the one who chose the current language. Maybe you inherited this situation. Maybe you’ve spent years patching things up, keeping everything running. But now it’s your decision—and if you pick the wrong target language, you will have to own that mistake.
Luckily, choosing wisely isn’t rocket science. There are a few key principles to guide you, principles that can help you make a choice you won’t regret.
In a previous article, we explored how to choose a target language specifically when migrating from RPG. Many of the same concerns apply here, but in this article, we’re going broader. We’ll explore how to pick the right language for any migration, from any outdated or problematic technology.
And if you are specifically dealing with RPG? Go check out that original article for in-depth advice.
Now, let’s see what really matters when you’re deciding where to go next.
Factor 1 – Why are you considering a migration?
To pick the language that will solve your problems, we first need to figure out what your problems are.
You might be facing one—or several—of these recurring issues:
1. Talent Is Drying Up
Maybe your system was built in a language that no developer under 40 or 50 even recognizes. Your developers are hard to find, harder to keep, and they’re heading for retirement faster than you can replace them.
This is the most common reason we see for migrations.
Even if you’re managing for now, you can feel the walls closing in. Fast-forward a few years, and it won’t just be a problem—it’ll be a crisis.
2. You’re Stuck on Outdated Hardware
Some languages are tied to specific hardware, especially older systems. You’re stuck running on proprietary machines, while the rest of the world has moved on to standard servers or the cloud.
You want freedom:
- Freedom to scale.
- Freedom to choose your vendors.
- Freedom to stop paying a premium for ancient, specialized equipment that no longer provides advantages oer alternatives.
But your language is just not offering you that choice.
3. The Language Itself Is Dying
Sometimes, it’s not just about people or hardware—it’s about the ecosystem.
- No updates.
- No security patches.
- No libraries.
- No community.
Even if you can train new developers, you’d still be fighting a losing battle.
4. Performance Is Breaking You
Maybe your system worked great when you started. But now? You’ve grown. You’re a victim of your own success. More users, more data, more demand—and your current tech just can’t keep up.
What’s Driving You?
These are the most typical reasons for migrations. If you’re migrating for something else, I’d love to hear about it—you can find my contacts on the website.
But here’s why this matters: your reason for migrating shapes your decision.
- If it’s about finding developers, cloud support, or getting away from a dying platform? The answer is usually simple: pick a popular, well-supported language and move on.
- If it’s about performance, or something more specific? You’ll need to weigh other factors.
So start here: why are you migrating? That answer will be one of the most important inputs in choosing your next language.
Factor 2 – What Kind of Organization Are You?
Let’s not overthink this.
- If you do not need your language of choice to be your competitive advantage, because software is just an enabler for your main activities, then just pick something safe, stable, and boring. You don’t need clever. You need solid.
- Are you a tech-first company? Are you looking for a differentiator that could give you an edge? Do you see yourself in Beating the Averages? Then the right choice for you could be getting less mainstream language: it may have been Ruby a few years ago. Today could be Elixir, Rust, or Clojure.
Factor 3 – What Is the Domain of Your Application?
Some domains naturally gravitate towards specific languages. This means that you can find talent familiar with your domain if you pick one of these languages. Also, in that ecosystem, there will be libraries and know-how that serve your domain particularly well.
- Finance, Banking, Insurance? → Java or **C#**Why: Stability, performance, tons of enterprise-grade libraries, and strong typing help prevent critical mistakes.
- Data Science, Machine Learning, Automation? → PythonWhy: Huge ecosystem (Pandas, NumPy, TensorFlow), easy to write, fast for prototyping.
- Enterprise Applications (ERP, CRM, HR Systems)? → Java, C#, or PythonWhy: Mature ecosystems, cloud-ready, long-term support, proven scalability.
- DevOps, Infrastructure, Tooling? → Go, Python, or Ruby Why: Go is fast and great for CLI tools; Python and Ruby are scriptable and flexible.
- Media Processing (Video, Audio, Image)? → C++, Rust, or Python (with C/C++ backends).
Why: Performance critical, often hardware-bound. - Telecommunications / Distributed Systems? → Erlang, Elixir, or GoWhy: Built for concurrency, fault tolerance, message passing.
Factor 4 – What Is the Expected Lifetime of the Application?
Ok, predicting the future is always a gamble.
But just because we can’t know for sure doesn’t mean we can’t use common sense to make reasonable decisions.
There’s a huge difference between building something you’ll use for 2 years and something you plan to keep alive for 20 years.
If it is something you expect to need for the short-Term (5 years or less), then you’ve got more flexibility, you can maybe even a bit opportunistic:
- You might choose a language that’s quick to develop in.
- One that has plenty of available developers right now, possibly at lower rates.
- You can focus on short-term costs and speed, rather than worrying about what the tech world will look like in a decade.
Basically, for short-lived projects, you optimize for the now, not the distant future.
But if you expect to keep the application long-Term (10 or more years), then stability is non-negotiable.
Now you need to think about:
- Will I still find developers for this language in 10 years?
- Will the tools, libraries, and frameworks I’m using still be supported?
- Will the language itself still be evolving, or at least maintained?
This is where it pays to play it safe.
Here’s a simple rule: don’t pick a language that isn’t already one of the top 5 most popular.
Why? Because popularity today doesn’t guarantee survival tomorrow—but it does give you odds in your favor.
- Popular languages have huge communities.
- They have momentum behind them—companies, developers, educators all invested in keeping them alive.
- If a language is thriving now, it’s far more likely to have strong support and active development for years to come.
Languages like Java, Python, C#, JavaScript, and even Go have reached a critical mass. There’s infrastructure, training, and a market built around them. That doesn’t make them future-proof, but it makes them a sensible bet. Which is the best we can do: if you and me could predict the future we would not be in this line of business.
Factor 5 – How difficult is to migrate to that language
Some migrations are just harder than others, so if time and money to get your migration done are something to keep in mind, you need to consider this factor.
Not all target languages are created equal when it comes to migration difficulty.
The bigger the gap between your current language and your new language in terms of execution model, the harder it will be to migrate.
- **Procedural → Object-Oriented?**Tough, but doable. This is your RPG or COBOL to Java, Python, or C# kind of move. It takes some effort to rethink things, but there are established patterns to help.
- **Procedural → Functional?**That’s a whole different beast. Moving from something like RPG or COBOL to Elixir, Haskell, or Clojure? Now there is a mismatch making the translation much more challenging.
It’s not impossible, but it’s harder, riskier, and more expensive.
Factor 6 – What Skills Do You Have In-House?
Sometimes, you’re not starting from scratch. Sure, one application might be stuck in an old, painful language—but what about the rest of your system?
- Do you have other modules or services written in something modern?
- Do you have teams already working with Python, Java, or C# on other parts of your stack?
- Have you built any internal tools, even small ones, that rely on newer tech?
If so, let’s leverage that.
If your team already runs other services in, say, Python, then moving the legacy system into Python means:
- You’ve got people in-house who can help.
- You’ve already solved deployment issues for that stack.
- You might even have libraries, utilities, or processes built around it.
This is especially critical for small organizations, where you can’t afford to spread yourselves thin. You just don’t have the luxury of hiring teams for every language.
If you’ve already got something working in a modern language, lean into that.
For small teams, having too many languages is a recipe for: Higher costs, Slower development and Hiring nightmares.
Sometimes, unfortunately, you’re stuck: The only language your team knows is the one you want to leave behind. So, well, that means you can pick whatever language you want, because anyway you will have to retrain your team (or hire a new one).
So what?
Alright, we’ve gone through six different factors. You’ve seen arguments pulling you in one direction, and others pulling you the opposite way.
| Factor | Key Considerations | Impact on Language Choice |
|---|---|---|
| 1. Why Are You Migrating? | Talent scarcity, outdated hardware, dying ecosystem, poor performance. | Drives whether you need a popular, well-supported, or high-performance language. |
| 2. Type of Organization | Are you tech-first or using software as a tool? | Tech-first may consider niche languages for advantage; others should pick safe, stable, mainstream options. |
| 3. Domain of Application | Certain industries favor specific languages (e.g., Java in Finance, Python in Data Science). | Picking a language aligned with your domain offers better talent, tools, and community support. |
| 4. Expected Lifetime of Application | Short-term (<5 years) or long-term (10+ years). | Short-term allows flexibility; long-term demands stable, popular, and future-proof languages. |
| 5. Difficulty of Migration | Procedural to OOP is easier; Procedural to Functional is harder. | Choose a language closer to your current paradigm if time, cost, and risk are major concerns. |
| 6. In-House Skills | Existing team experience, current technologies used elsewhere in the system. | Leveraging existing skills reduces training costs and simplifies deployment, especially for small organizations. |
So what now? What decision should you actually take?
I’m not going to pretend I can give you some magical thumb rule that works for everyone. That would be arrogant—and frankly, misleading. The truth is, you need to weigh these factors for your specific situation. Only you know your team, your problems, your goals.
If you’ve read all this, reflected, and you’re still stuck, here’s my advice:
- **Pick one of the most popular languages.**Popular means safe. Popular means you’ll find developers. Popular means tools, libraries, support.
- **If in doubt, just go with Java.**It’s not sexy, but it’s reliable, scalable, and everywhere.
But if you are not yet convinced you can always hire a consultant. Sure, you should be ready to spend some time and money. And in the end they’ll probably say: “Go with Java.”
When asking around consider that every developer has a personal bias. I personally love static typing. If it were up to me, everything would be written in Kotlin but I know that’s not the best choice for every company, every team, or every project that’s why you didn’t hear me push it much in this article (it took some will to refrain from doing so).
Hopefully this article was useful to you. Maybe you already had a gut feeling when you started reading and this article helped you cross the line and make that decision.
If it helped—great. That was the point.
If not, and you’re still thinking about it, or want to tell me what I should’ve covered instead?
Feel free to reach out. My contact info is on the website.
You can share your thoughts—or, if you really hated this, just send me a friendly insult.
Thanks for reading. Now go make the right call for you.
The post How to choose the target language for a migration appeared first on Strumenta.
Introducing core.async.flow
core.async 1.9.808-alpha1 is now available, featuring the first release of core.async.flow. You can read more about core.async.flow in the rationale and the docs.
core.async.flow is in alpha state - all APIs are still subject to change but we welcome your feedback as we move towards a non-alpha release.
This release also adds datafy support for channels and buffers.
core.async.flow-monitor
In addition, we are today releasing core.async.flow-monitor v0.1.0, which is a tool for visualizing a flow’s processes as SVG (viewable inline in Calva or Cursive!), and dynamically monitoring and interacting with flows as they are running.
Towards the cutest neural network and dubious ideas for a code CAD language
Towards the cutest neural network
I recently needed to use a microcontroller to estimate the pose (translation and orientation) of an object using readings from six different sensors. Since the readings were non-linear and coupled with each other, an explicit analytical solution was out of the question.
I figured I’d have a go at using a simple neural network to approximate it:
- Generate training data (on my computer) using a forward simulation (pose to sensor readings)
- Train a lil’ neural network (a few dense layers, 100’s of parameters, tops) to approximate the inverse mapping function (sensor readings to pose)
- Deploy this network on my microcontroller (Cortex-M0, 16 kB RAM, 32 kB flash) to actually do the inference
Since neural networks have been around since the 1980’s, I figured it’d be straightforward. A quick background search uncovered lots of promising leads too, especially regarding “quantization”, which I wanted to do as my microcontroller doesn’t have hardware support for floating point operations.
However, this turned out to be much more difficult than I’d anticipated. It seems like my use case — end-to-end training of a simple dense neural network with integer-only inference — is quite uncommon.
The vast majority of papers and software libraries I found turned out to be complex, heavyweight (in terms of inference code size), and have lots of unstated assumptions and background requirements.
To make a web design analogy: It felt like I kept falling into npm create-react-app rabbit holes rather than what I wanted: The moral equivalent of opening index.html with notepad.exe and typing <h1>Welcome to my Homepage</h1>.
I’m writing up my notes to:
- checkpoint my understanding of the space and current best solution
- help anyone else who simply wants a wholesome lil’ universal function approximator with low conceptual and hardware overhead
- solicit “why don’t you just …” emails from experienced practitioners who can point me to the library/tutorial I’ve been missing =D
Mathematics won’t render properly in an email, so if you’re interested you’ll have to click over to my website to see my plan for making the cutest neural network.
Dubious ideas for a code CAD language
Back in 2022 I explored a pen/gesture-based user interface for 2D drawing with constraint solvers and recently I decided to make a more general 3D, BRep-based system.
I’d ultimately like something graphical, but since I’ll be building the system with textual code, I’ll need some textual notation to use for debugging, recording test cases, etc. I don’t want to spend the next few months/years reading screenfuls of EDN, JSON, or (have mercy) that incomplete, unparsable stuff Rust’s Debug prints.
So that’s how I ended up starting to design a programming language. After all, I’ve got to come up with semantics for my system anyway, and if I’ve got to do that and have to come up with a concise notation, I might as well put them together into a language, right?
The closest prior art I’m aware of is Build123d, a Python library that provides “builder-style” and “algebra-style” APIs to the OpenCascade BRep kernel.
The primary differentiators I’ll be focusing on are:
- a 2D constraint system, similar to sketches in trad CAD (SolidWorks, Inventor, OnShape, etc.)
- reusability mechanisms for sketches and features/geometry that compose with the constraint system (something more like logic programming than typical function calling)
- interactive graphical interface, supporting bimodal editing with the textual notation in the spirit of Ravi Chugh’s and Brian Hempel’s work
For the language itself, I’m leaning towards Julia-style multiple dispatch based on types, with optional argument names for disambiguation.
My hope is that this mechanism will allow for concise specifications. For example, a cylinder could be specified with either a diameter or a radius:
(defn cylinder ([diameter: Length height: Length] (extrude height (sketch (circle diameter))))
([radius: Length height: Length] (cylinder :diameter (* radius 2) height)))
Lots of details to sort out here. For example, both of these methods have the same type arity (length, length), so for an invocation like (cylinder 1mm 2mm), should I:
- default to the first method (and rely on editor inlay argument name hints to prevent confusion), or
- force the argument names to be specified? (all of the names, or just enough to disambiguate the method?)
Multiple dispatch could also be used to simplify the “happy path” by having some methods define necessary conversions. E.g., a solid extrusion requires a closed profile, but in the general case a sketch may not have exactly one closed profile. So the extrude invoked by the first cylinder method above would only make sense if extrude was defined something like:
(defn extrude ([distance: Length sketch: Sketch] (extrude distance (get-unique-closed-profile-or-throw sketch)))
([distance: Length profile: Profile] ...))
That said, I haven’t implemented a language with multiple dispatch and type inference, and I expect there are tons of tricky interactions — if you have any recommendations, advice, or just want to get into trouble with me on this, please drop me a line!
Follow up: graph-directed autocomplete
Last newsletter I was wondering about graph-directed autocomplete as a way to have the computer “do what I mean” and figure out how to compose functions to map provided arguments to a desired type.
My motivating example was “figure out how to make an axis from a circular face”, and I’m happy to report that such a system can be implemented in a few lines of Clojure:
(def fns "A list of [function-name arg-types return-type]" [["plane, three point" [:point :point :point] :plane] ["axis, normal to plane through point" [:plane :point] :axis] ["point, edge start" [:edge] :point] ["point, edge mid" [:edge] :point] ["point, edge end" [:edge] :point] ["plane, containing edge" [:edge] :point] ["point, arc centerpoint" [:arc] :point] ["point, circle centerpoint" [:circle] :point] ["edge, from points" [:point :point] :edge] ["plane, circle" [:circle] :plane] ["plane, arc" [:arc] :plane]])
(def all-types (->> (flatten fns) (filter keyword?) set))
(def all-fns (concat fns ;; add fns which construct a type from id (for [t all-types] [(name t) [:id] t])))
(def fn-name->type (into {} (for [[name _ return-type] all-fns] [name return-type])))
(defn possible-arglists "For a given function signature and possible expressions indexed by type, find all possible args" [signature type->exprs] (->> (apply clojure.math.combinatorics/cartesian-product (map type->exprs signature)) ;;don't allow an expression to be used multiple times (filter (fn [args] (= (count args) (count (set args)))))))
(defn expand "expand set of exprs by applying all possible fns with all possible permutations of args" [exprs] (let [type->exprs (->> exprs (group-by (comp fn-name->type first)))]
(into exprs
(for [[name signature _] all-fns
args (possible-arglists signature type->exprs)]
(into [name] args)))))(comment ;; what can you do with two points? (expand #{["point" 1] ["point" 2]}) ;; => #{["point" 1] ;; ["point" 2] ;; ["edge, from points" ["point" 1] ["point" 2]] ;; ["edge, from points" ["point" 2] ["point" 1]]} ;; leave them as is or make two different directed edges )
(defn autocomplete ([exprs target-type] (autocomplete exprs target-type 3))
([exprs target-type max-iterations] (->> (iterate expand exprs) (take max-iterations) last (filter #(= target-type (fn-name->type (first %)))))))
(comment ;; the motivating problem: how can you get an arc from an axis? (autocomplete #{["arc" 1]} :axis) ;; => (["axis, normal to plane through point" ;; ["plane, arc" ["arc" 1]] ;; ["point, arc centerpoint" ["arc" 1]]]) ;; just one solution: use the arc to get a plane and a point, then use those to get an axis. )
We all know computers can search graphs like this, but it’s still fun to actually write it out.
The next step would be to extend this with:
- subtyping: e.g., circle and arc are both edges, so should be valid arguments to a function
["length" :edge :length] - runtime predicates: e.g., not all edges correspond to a closed profile, so the autocomplete shouldn’t propose
["edge-to-profile" :edge :profile]for open edges
Also: shout out to newsletter reader Xavier who suggested I look at OnShape’s Mate Connector concept as another way to solve this selection problem. My programmer interpretation of mate connectors is that they’re reified interfaces for parts, such that rather than relating specific geometry (faces, edges, etc.) between parts, you define and relate mate connectors so that the relationship is robust to later changes to the underlying “implementation” (geometry/topology) of the parts.
Misc stuff.
Several people wrote after my last newsletter to ask where I find so many articles and esoteric YouTube videos. Well, over the winter I moved my 3x weekly 90 minute cardio routine onto a stationary bike in a gym.
The gym has wifi.
- Sometimes the reason you can’t find people you resonate with is because you misread the ones you meet
- An interactive-speed Linux computer on a tiny board you can easily build with only 3 8-pin chips
- How I use LLMs - Awesome overview from a boss.
- Clocks Made By Vasilis
- “turns out coca-cola people model the back emf of the dispensor’s flow control module by taylor expansion of pressure into 26 terms of 6 features (time, voltage etc.), and got ~90% accuracy +- 10 psi.” x.com post
- Splash-free urinals for global sustainability and accessibility: Design through physics and differential equations
- Visually Stable UI
- The Spade Programming Language is a nice lookin’ hardware description language — their Blinky (for software people) makes me want to have a go at programming an FPGA sometime…
- GARF: Learning Generalizable 3D Reassembly for Real-World Fractures. The computer figures out how to put broken stuff back together.
- A Lagrange Multipliers Refresher, For Idiots Like Me
- Haptick is a Stewart platform spacemouse built using SMD resistors as strain gauges.
- If You’re So Smart, Why Can’t You Die? What does AI tell us about the word “intelligence?”
- Designing type inference for high quality type errors
Automatic Type Conversion in Clojure
Code
;; automatic_type_casting.clj
42
(type 42)
(type 42.5)
(+ 42 42.5)
(type (+ 42 42.5))
42.7M
(type 42.7M)
(+ 42.5 42.7M)
(type (+ 42.5 42.7M))
(type (+ 42 42.0))
(type 994824757458783748579437258798745.278375725925479247582945754M)
(type (+ 1
994824757458783748579437258798745.278375725925479247582945754M))
(str 42)
(str 42 " is the ultimate answer")
(Integer/parseInt "42")
(type (Integer/parseInt "42"))
(type (
+ (Integer/parseInt "42") 42))
(Double/parseDouble "42.5")
(Integer/parseInt "42")
(Integer/parseInt 42.5)Babashka Java interop, reflection and type hints
Consider the following Clojure code:
(def thread-pool (java.util.concurrent.Executors/newCachedThreadPool))
(def fut (.submit thread-pool (fn [] 3)))
@fut ;;=> ?
I didn't use any type hints, but the names of the vars should give you an idea what's happening:
- a thread pool is created
- a piece of work in the form of a function is submitted
- the thread pool returns a future which we can dereference to do a blocking wait and get the result.
What result would you expect this program to give? My initial guess would be 3.
However, in babashka the result would sometimes be nil (version 1.12.199 on macOS Apple silicon does for example). I've seen this happen in JVM Clojure too in CI (given no type hints, and thus relying on Clojure reflection). I discovered this problem when trying to make bb run the fusebox library and executing its test suite in CI using babashka.
What's the mechanism behind this flakiness? The .submit method in the snippet above is overloaded. When Clojure is doing reflection, it finds the most suitable method for .submit given the instance object and the arguments. In this case the type of the instance object (the thread-pool value) is of type java.util.concurrent.ThreadPoolExecutor, which has three overloads (inherited from java.util.concurrent.AbstractExecutorService):
public Future<?> submit(Runnable task)public <T> Future<T> submit(Runnable task, T result)public <T> Future<T> submit(Callable<T> task)
Only two of those match the number of arguments we used in the snippet, so we are left with:
public Future<?> submit(Runnable task)public <T> Future<T> submit(Callable<T> task)
Clojure's reflector will try to see if the argument type to .submit matches any of these methods. Since we called it with a function, in this case it matches both. If multiple methods match, it will try to pick the most specific method using clojure.lang.Compiler/subsumes. Since Runnable and Callable are two distinct types (one doesn't inherit from the other), Clojure's reflector just returns the first method it deemed most suitable. So it could be either method. The java documentation mentions the submit method with the Runnable argument first, but this isn't necessarily the order in which Java reflection will list those methods. I have found out that the order may even be indeterministic over multiple CI runs and JVM implementations or versions. What the exact cause of this indeterminism is, I don't know, but I found out the hard way that it exists 😅.
So when does the above snippet return nil? When the Runnable overload is chosen, since Runnable is an interface with run method that returns void (which is nil in Clojure). Let me show this using a snippet that uses JVM Clojure type hinting, where we don't rely on reflection:
(set! *warn-on-reflection* true)
(def ^java.util.concurrent.ThreadPoolExecutor thread-pool
(java.util.concurrent.Executors/newCachedThreadPool))
(def fut (.submit thread-pool ^Runnable (fn [] 3)))
@fut ;; => nil
Now let's do the same with Callable:
(set! *warn-on-reflection* true)
(def ^java.util.concurrent.ThreadPoolExecutor thread-pool
(java.util.concurrent.Executors/newCachedThreadPool))
(def fut (.submit thread-pool ^Callable (fn [] 3)))
@fut ;; => 3
So we see the issue: depending on the overload of .submit we get a different value when we dereference the future, either nil or the value returned from the function.
So far, babashka has relied exclusively on runtime reflection to implement Java interop. So we do get into a problem with the above snippet, unless we add type hints. But so far babashka, or more specifically, SCI hasn't made use of type hints to determine the most suitable method. The Clojure compiler does this, but as you know, SCI interprets code and doesn't make use of the clojure Compiler. It does use a forked version of clojure.lang.Reflector, clojure's runtime reflection code, aptly renamed to sci.impl.Reflector. So far, pretty much the only change to that code was making some methods public that were used internally by SCI. To fix the above problem, SCI now actually makes use of type hints and passes these to sci.impl.Reflector. So in the newly published version of babashka, this code:
(def thread-pool (java.util.concurrent.Executors/newCachedThreadPool))
(def fut (.submit thread-pool ^Callable (fn [] 3)))
@fut ;;=> 3
will consistently return 3 and when changing Callable to Runnable, you'll get nil. Note that the above snippet will still have the ambiguous behavior in JVM Clojure, since it doesn't have enough type hints to figure out the right method at compile time and clojure.lang.Reflector does nothing with type hints. Once the Clojure compiler finds out that you're calling .submit on a java.util.concurrent.ExecutorService though, the code will run with the expected method.
Can you think of more methods in the Java standard library which have this ambiguity when relying solely on Clojure reflection? I'd love to hear about those to see if they work reliably in babashka given some extra help through type hints.
Thanks to Tim Pote for thinking along when fixing the issues in babashka and reading a preview of this blog post.
Compiling Clojure to WebAssembly
Post about compiling clojure to a web assembly module using GraalVM native image.