Planet Python (original) (raw)
Last update: July 06, 2025 01:43 AM UTC
July 04, 2025
PyPy
PyPy v7.3.20 release
PyPy v7.3.20: release of python 2.7, 3.11
The PyPy team is proud to release version 7.3.20 of PyPy after the previous release on Feb 26, 2025. The release fixes some subtle bugs in ctypes andOrderedDict and makes PyPy3.11 compatible with an upcoming release of Cython.
The release includes two different interpreters:
- PyPy2.7, which is an interpreter supporting the syntax and the features of Python 2.7 including the stdlib for CPython 2.7.18+ (the
+is for backported security updates) - PyPy3.11, which is an interpreter supporting the syntax and the features of Python 3.11, including the stdlib for CPython 3.11.13.
The interpreters are based on much the same codebase, thus the double release. This is a micro release, all APIs are compatible with the other 7.3 releases.
We recommend updating. You can find links to download the releases here:
We would like to thank our donors for the continued support of the PyPy project. If PyPy is not quite good enough for your needs, we are available fordirect consulting work. If PyPy is helping you out, we would love to hear about it and encourage submissions to our blog via a pull request to https://github.com/pypy/pypy.org
We would also like to thank our contributors and encourage new people to join the project. PyPy has many layers and we need help with all of them: bug fixes,PyPy and RPython documentation improvements, or general help with making RPython's JIT even better.
If you are a python library maintainer and use C-extensions, please consider making a HPy / CFFI / cppyy version of your library that would be performant on PyPy. In any case, cibuildwheel supports building wheels for PyPy.
What is PyPy?
PyPy is a Python interpreter, a drop-in replacement for CPython It's fast (PyPy and CPython performance comparison) due to its integrated tracing JIT compiler.
We also welcome developers of other dynamic languages to see what RPython can do for them.
We provide binary builds for:
- x86 machines on most common operating systems (Linux 32/64 bits, Mac OS 64 bits, Windows 64 bits)
- 64-bit ARM machines running Linux (
aarch64) and macos (macos_arm64).
PyPy supports Windows 32-bit, Linux PPC64 big- and little-endian, Linux ARM 32 bit, RISC-V RV64IMAFD Linux, and s390x Linux but does not release binaries. Please reach out to us if you wish to sponsor binary releases for those platforms. Downstream packagers provide binary builds for debian, Fedora, conda, OpenBSD, FreeBSD, Gentoo, and more.
What else is new?
For more information about the 7.3.20 release, see the full changelog.
Please update, and continue to help us make pypy better.
Cheers, The PyPy Team
Real Python
The Real Python Podcast – Episode #256: Solving Problems and Saving Time in Chemistry With Python
What motivates someone to learn how to code as a scientist? How do you harness the excitement of solving problems quickly and make the connection to the benefits of coding in your scientific work? This week on the show, we speak with Ben Lear and Christopher Johnson about their book "Coding For Chemists."
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
July 03, 2025
Mike Driscoll
Python eBook Fourth of July Sale
Happy Fourth of July! I am hosting a sale for the 4th of July weekend, where you can get 25% off most of my books and courses.

Here are the books included in the sale and the direct links with the 25% coupon already applied:
- Python 101
- Python 201: Intermediate Python
- ReportLab: PDF Processing in Python
- Jupyter Notebook 101
- Creating GUI Applications with wxPython
- Pillow: Image Processing with Python
- Automating Excel with Python
- The Python Quiz Book
- Python Logging
- JupyterLab 101
I hope you’ll check out the sale, but even if you don’t, I hope you have a great holiday weekend!
The post Python eBook Fourth of July Sale appeared first on Mouse Vs Python.
Armin Ronacher
Tools: Code Is All You Need
If you've been following me on Twitter, you know I'm not a big fan of MCP (Model Context Protocol) right now. It's not that I dislike the idea; I just haven't found it to work as advertised. In my view, MCP suffers from two major flaws:
- It isn’t truly composable. Most composition happens through inference.
- It demands too much context. You must supply significant upfront input, and every tool invocation consumes even more context than simply writing and running code.
A quick experiment makes this clear: try completing a GitHub task with the GitHub MCP, then repeat it with the gh CLI tool. You'll almost certainly find the latter uses context far more efficiently and you get to your intended results quicker.
But MCP is the Future!
I want to address some of the feedback I've received on my stance on this. I evaluated MCP extensively in the context of agentic coding, where its limitations were easiest to observe. One piece of feedback is that MCP might not make a ton of sense for general code generation, because models are already very good at that but they make a lot of sense for end-user applications, like, say, automating a domain-specific task in a financial company. Another one is that I need to look at the world of the future, where models will be able to reach many more tools and handle much more complex tasks.
My current take is that my data indicates that current MCP will always be harder to use than writing code, primarily due to the reliance on inference. If you look at the approaches today for pushing towards higher tool counts, the proposals all include a layer of filtering. You pass all your tools to an LLM and ask it to filter it down based on the task at hand. So far, there hasn't been much better approaches proposed.
The main reason I believe this will most likely also hold true — that you shouldn't be using MCP in its current form even for non-programming, domain-specific tasks — is that even in those cases code generation just is the better choice because of the ability to compose.
Replace Yourself With A Shellscript
The way to think about this problem is that when you don't have an AI, and you're solving a problem as a software engineer, your tool of choice is code. Perhaps as a non-software engineer, code is out of reach. Many many tasks people do by hand are actually automatable through software. The challenge is finding someone to write that software. If you're working in a niche environment and you're not a programmer yourself, you might not pick up a programming book to learn how to code, and you might not find a developer willing to provide you with a custom piece of software to solve your specific problem. And yes, maybe your task requires some inference, but many do need them all the time.
There is a reason we say “to replace oneself with a shell script”, it's because that has been happening for a long time. With LLMs and programming, the idea is that rather than replacing yourself with a shell script, you're replacing yourself with an LLM. But you run into three problems: cost, speed, and general reliability. All these problems are what we need to deal with before we can even think of tool usage or MCP. We need to figure out how to ensure that our automated task actually works correctly at scale.
Automation at Scale
The key to automation is really to automate things that will happen over and over. You're not going to automate a one-shot change that will never recur. You're going to start automating the things where the machine can truly give you a productivity boost because you're going to do it once or twice, figure out how to make it work, and then have the machine repeat it a thousand times. For that repetition, there's a very strong argument to be made for always using code. That's because if we instruct the machine to use inference to do it, it might work, particularly for small tasks, but it requires validation which can take almost the same time as doing it in the first place. Getting an LLM to calculate for you sort of works, but it's much better for the LLM to write the Python code to do the calculation. Why? First, you can review the formula, not the calculated result. We can write it ourselves or we can use the LLM as a judge to figure out if the approach is correct. Don't really have to validate that Python calculates correct, you can rely on that. So, by opting for code generation for task solving, we get a little closer to being able to verify and validate the process ourselves, rather than hoping the LLM inferred correctly.
This obviously goes way beyond calculation. Take, for instance, this blog. I converted this entire blog from reStructuredText to Markdown recently. I put this conversion off for a really long time, partly because I was a little too lazy. But also, when I was lazy enough to consider deploying an LLM for it, I just didn't trust it to do the conversion itself without regressing somewhere. I was worried that if it ran out of context, it might start hallucinating text or change wording slightly. It's just that I worried about subtle regressions too much.
I still used an LLM for it, but I asked it to do that transformation in a different way: through code.
LLM to Code to LLM
- I asked the LLM to perform the core transformation from reStructuredText to Markdown but I also asked it to do this in a way that uses the underlying AST (Abstract Syntax Tree). So, I instructed it to parse the reStructuredText into an actual reStructuredText AST, then convert that to a Markdown AST, and finally render it to HTML, just like it did before. This gave me an intermediate transformation step and a comparable end result.
- Then, I asked it to write a script that compares the old HTML with the new HTML, performs the diffing after some basic cleanup it deemed necessary for comparison. I asked it to consider what kind of conversion errors were actually acceptable. So, it read through its own scripts to see where it might not match the original output due to known technical limitations (e.g., footnotes render differently between the Markdown library I'm using and the reStructuredText library, so even if the syntax matches correctly, the HTML would look different). I asked it to compensate for this in that script.
- After that was done, I asked it to create a third script, which I could run over the output of hundreds of files to analyze the differece to go back into the agentic loop for another iteration tep.
Then I kicked this off in a loop. I did not provide all the posts, I started with 10 until differences were low and then had it do it for all. It did this for maybe 30 minutes or so until I came back to it and found it in a pretty acceptable state.
What's key about this transformation is not so much that the LLM was capable of pulling it off, but that I actually trusted this process at the end because I could review the approach. Not only that, I also tried to ask another LLM what it thinks of the code that another LLM wrote, and the changes. It gave me much higher confidence that what was going on would not lose data. It felt right to me. It felt like a mechanical process that was fundamentally correct, and I was able to observe it and do spot checks. At worst, the regressions were minor Markdown syntax errors, but the text itself wouldn't have been corrupted.
Another key here is also that because the inference is rather constant, the cost of inference in this process scales with the number of iteration steps and the sample size, but it doesn't depend on how many documents I'm wanting to convert overall. Eventually, I just had it run over all documents all the time but running it over 15 docs vs 150 docs is more or less the same effort, because the final LLM based analysis step did not have that many more things to review (it already skipped over all minor differences in the files).
MCP Cannot Do That
This is a long-winded way of saying that this entire transformation went through code. It's a pipeline that starts with human input, produces code, does an LLM as a judge step and iterates. And you can take this transformation and apply it to a general task as well.
To give an example, one MCP you might be using is Playwright. I find it very hard to replace Playwright with a code approach for all cases because what you're essentially doing is remotely controlling your browser. The task you're giving it largely involves reading the page, understanding what's on it, and clicking the next button. That's the kind of scenario where it's very hard to eliminate inference at each step.
However, if you already know what the page is — for instance, if you're navigating your own app you're working on — then you can actually start telling it to write a Playwright Python script instead and run that. This script can perform many of those steps sequentially without any inference. I've noticed that this approach is significantly quicker, and because it understands your code, it still generally produces correct results. It doesn't need to navigate, read page contents, find a button, or press an input in real-time. Instead, it will write a single Python script that automates the entire process in one go, requiring very little context by comparison.
This process is repeatable. Once the script is written, I can execute it 100, 200, or even 300 times without requiring any further inference. This is a significant advantage that an MCP typically cannot offer. It's incredibly challenging to get an LLM to understand generic, abstract MCP tool calls. I wish I could, for example, embed an MCP client directly into a shell script, allowing me to run remote MCP services efficiently via code generation, but actually doing that is incredibly hard because the tools are not written with non inference based automation in mind.
Also, as ironic as it is: I'm a human, not an MCP client. I can run and debug a script, I cannot even figure out how to reliably do MCP calls. It's always a gamble and incredibly hard to debug. I love using the little tools that Claude Code generates while generating code. Some of those I had it convert into long term additions to my development process.
Where does this take us?
I don't know. But it's an interesting moment to think what we could potentially do to make code generation for purposeful agentic coding better. The weird thing is that MCP is actually pretty great when it works. But it feels in the current form too much like a dead end that cannot be scaled up, particularly to automation at scale because it relies on inference too much.
So maybe we need to look at ways to find a better abstraction for what MCP is great at, and code generation. For that that we might need to build better sandboxes and maybe start looking at how we can expose APIs in ways that allow an agent to do some sort of fan out / fan in for inference. Effectively we want to do as much in generated code as we can, but then use the magic of LLMs after bulk code execution to judge what we did.
I can also imagine that it might be quite interesting to do code generation in a way that also provides enough context for an LLM to explain in human language to a non programmer what the script is doing. That might enable these flows to be used by human users that are not developers themselves.
In any case I can only encourage people to bypass MCP and to explore what else is possible. LLMs can do so much more if you give them the power to write code.
Further Reading
Here are some more posts you might want to read or videos you might want to watch:
- My Agentic Coding Talk where I go into this topic a bit.
- Drew Breunig's post “How to fix your context” which covers some attempts to improve MCP tool selection if you cannot avoid it.
- Manuel Odendahl's excellent “MCPs are Boring” talk from AI Engineer that was one of the first to point to the challenges with MCP.
Quansight Labs Blog
Escaping Contravariance Hell
Protocols and TypeVars
July 02, 2025
Real Python
Python 3.14 Preview: Template Strings (T-Strings)
Python 3.14’s t-strings allow you to intercept and transform input values before assembling them into a final representation. Unlike f-strings, which produce a str object, t-strings resolve to a Template instance, allowing you to safely process and customize dynamic content.
One of the key benefits of t-strings is their ability to help prevent security vulnerabilities like SQL injection and XSS attacks. They’re also valuable in other fields that rely on string templates, such as structured logging.
By the end of this tutorial, you’ll understand that:
- Python t-strings are a generalization of f-strings, designed to safely handle and process input values.
- The main components of a t-string include static string parts and interpolations, which are accessible through the
Templateclass. - You process t-strings by iterating over their components, using attributes such as
.strings,.interpolations, and.valuesfor safe and customized handling.
Python t-strings enhance both security and flexibility in string processing tasks. This tutorial will guide you through understanding t-strings, comparing them with f-strings, and exploring their practical use cases in Python programming.
Take the Quiz: Test your knowledge with our interactive “Python 3.14 Preview: Template Strings (T-Strings)” quiz. You’ll receive a score upon completion to help you track your learning progress:

Exploring String Templates Before Python 3.14
Creating string templates that you can populate with specific values dynamically is a common requirement in programming. A string template is a string that contains placeholders—special markers representing variable values—that you can dynamically replace at runtime.
You’ll often use templates to generate text or structured content by filling these placeholders with actual data. Before Python 3.14, the language provided several tools that allowed you to interpolate and format values in your strings:
- string formatting operator (%)
- str.format()
- f-strings
- string.Template
- format()
- string.Formatter.parse()
You can use all these tools to create and process string templates. Of course, each has its own unique strengths and weaknesses.
The String Formatting Operator (%)
The string formatting operator (%), inspired by C’s printf() syntax, is the oldest string formatting and interpolation tool in Python. Here’s a quick example of how you can use this operator to create and process templates:
In this example, you have two variables containing data. The first contains a string, and the second holds an integer value. Then, you define a string template using the %s and %d syntax to define placeholders or replacement fields. The s means that the first field must be filled with a string, and the d indicates that the field accepts decimal integer values. These are known as conversion types.
Finally, you use the % operator to dynamically interpolate the variables’ content into the template and build a new string.
This operator also allows you to apply formatting rules to the input values. For example, here’s how you can format currency values:
In this example, the template contains the literal dollar sign ($) to indicate that the formatted value represents a USD amount. The $ character is not part of the formatting syntax itself but part of the output.
Then, you have a replacement field that starts with the string formatting operator (%) followed by the string ".2f". This string is a format specifier that formats any input number as a floating-point value with a precision of two digits.
You can format a string inline using the % operator by passing the values directly. This approach combines the template and the data in a single step, but it doesn’t allow you to reuse the template later on:
When you have a complex template, the string formatting operator’s syntax can become cumbersome and hard to read:
Read the full article at https://realpython.com/python-t-strings/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Quiz: Python 3.14 Preview: Template Strings (T-Strings)
Evaluate your grasp of Python’s t-strings, which provide a structured and secure way to handle string templates.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Django Weblog
Django bugfix release issued: 5.2.4
Today we've issued the 5.2.4 bugfix release.
The release package and checksums are available from our downloads page, as well as from the Python Package Index.
The PGP key ID used for this release is Natalia Bidart: 2EE82A8D9470983E
Talk Python to Me
#512: Building a JIT Compiler for CPython
Do you like to dive into the details and intricacies of how Python executes and how we can optimize it? Well, do I have an episode for you. We welcome back Brandt Bucher to give us an update on the upcoming JIT compiler for Python and why it differs from JITs for languages such as C# and Java.
Episode sponsors
Posit
Talk Python Courses
Links from the show
PyCon Talk: What they don't tell you about building a JIT compiler for CPython: youtube.com
Specializing, Adaptive Interpreter Episode: talkpython.fm
Watch this episode on YouTube: youtube.com
Episode #512 deep-dive: talkpython.fm/512
Episode transcripts: talkpython.fm
--- Stay in touch with us ---
Subscribe to Talk Python on YouTube: youtube.com
Talk Python on Bluesky: @talkpython.fm at bsky.app
Talk Python on Mastodon: talkpython
Michael on Bluesky: @mkennedy.codes at bsky.app
Michael on Mastodon: mkennedy
Seth Michael Larson
Open Source Security work isn't “Special”
I gave this keynote at OpenSSF Community Day NA 2025 in Denver, Colorado. There will be a YouTube video recording available at a later date. This talk was given as the Security-Developer-in-Residence at the Python Software Foundation, a role which is sponsored by Alpha-Omega. Thanks to Alpha-Omega for supporting security in the Python ecosystem.
To understand why security is special, we have to take a look at why open source is an amazing thing. For many components of open source, users that have the time, desire, and expertise are able to contribute meaningfully to projects. As a maintainer of an open source project, this is awesome!

Users and contributors can work on the areas they are interested in, like triaging bug reports, engaging with the community, or writing great docs. For smaller open source projects this is especially important, there’s only one or a few maintainers and they can’t do it all on their own sustainably.
But not for security, right? Security is special.

Only a select few are supposed to be able to handle vulnerability reports, configure the repository and package manager settings, and secure the release process. This tight association between security work and maintainers is what I’d like to try to pull apart today.
Maintainers, especially for smaller projects, are almost always experts in the domain of the project, not necessarily in security. But the expectations of open source projects means that maintainers feel compelled to do this work to keep their project and users safe.
And those expectations for security today, that security work is done by few rather than many, combined with the secretive nature of security work means that maintainers often feel isolated.
Maintainers don’t see how other projects are triaging vulnerabilities and can’t learn from each other. They can’t compare notes on what they are seeing and whether they are doing the right thing. Isolation in security work breeds a culture of fear. Fear of doing the wrong thing and making your users unsafe.

This private conversation was published with permission from Marcelo, maintainer of Starlette, a popular Python library that powers FastAPI.
He was seeing security reports that seemed convincing but they were also confusing. He asked for my help and together we determined the reports were generated with an LLM and were meaningless. I later published an article about “slop security reports” that other projects were seeing too, including curl, Python, Django, and others. But none of us would know what the others were seeing without sharing.

Smaller projects are shaped by their tools, not the other way around. Small projects don’t have the time and resources to make a square peg fit into a circular hole when it comes to any type of tooling, including security. They don’t have time to create bots and wrappers and bend these tools to work for them, like many larger projects do.
This means that whatever is available or the default experience is probably what they work with, and often our tools encode the assumption that “only maintainers do security work”.
Of the top 10,000 open source packages with GitHub repositories identified by Ecosystems dataset, 35% are owned by a GitHub user, not a GitHub organization. This has huge implications for what features are available to those projects and who is able to do security work at all.

Security tools and vulnerability reports often introduce an asymmetry by creating work to do without resolving the issues identified. Fixing security issues while weighing user expectations, performance, and backwards compatibility is a tough job. This is the reason maintainers are often hesitant to adopt security scanners and tools, because adoption is easy but being on the hook to triage the findings forever is hard.
If a bunch of your limited time with a project is spent doing work that isn’t aligned with your interests in the project, this can lead to burnout which only makes the problem worse.
This image is from the changelog of libexpat which states that the project is understaffed and without funding and is in need of help responding to findings from fuzzing the project within the standard 90 day grace period.
So what can we all do to make security work less “special” and more like other open source contributions?

I propose a new model for open source security contributions, where security work is completed by trusted individuals that aren’t necessarily maintainers on behalf of projects. This model break the assumption that maintainers are the only ones that can do security work, especially for smaller projects.
These “security contributors” could be maintainers or contributors of other open source projects that know about security, they could be foundations offering up resources to their ecosystem, or engineers at companies helping their dependency graph.
Even if you’re not contributing security work directly to an open source project, I think there’s reframing, re-engineering, and rethinking work that we can all do to make this model successful.
Now I know what you might be thinking: “What about XZ?” XZ often comes up during conversations involving trust in contributors to open source projects, but I’m not convinced it’s the show-stopper it’s often portrayed as.

The technologies to discover the backdoor trigger of XZ already exist but had not yet been adopted by the project, such as reproducible builds, build provenance, capability analysis, or using a canonical URL to download source code.
Malicious contributors have always been a problem for open source and the solution can’t be that we just stop trusting each other or accepting help from our community. We lose something bigger than the XZ-utils backdoor if we let this incident define how open source security works going forward.
We have to be able to build trust amongst contributors and projects and security work can’t all fall on maintainers. If we want open source sustainability then we cannot let XZ-utils define open source security.

So what can we all do to nurture this more sustainable model of open source security contribution?
We can all use our voices and experiences to build a more positive and healthy security culture and overcome the isolation inherent to security work.

Sharing and encouraging the sharing experiences shows others that they’re not the only ones that think this is difficult. Seeing others sharing experiences shows that it’s okay to ask for help and to not be perfect, instead the focus should be on always improving.

If you’re a public contributor to open source security, making yourself visible and approachable is a great way to begin building trust in the communities you participate in. Conferences and in-person meetups are excellent venues for promoting positive security culture and building trust amongst a community.
There is something about being in-person that really let’s people be vulnerable and talk honestly about what they are experiencing and their problems which sometimes is exactly what we need to hear. When I’m at conferences I also like to offer up 1-on-1 time to discuss security issues with maintainers or help them adopt new security features.

TLS and public key infrastructure scale trust of the internet and web, we need more technologies that scale trust in open source contributions.
We should continue contributing to and adopting technologies that enable trust for open source projects and contributions. This is especially meaningful when the technology is added to existing tooling like package managers and build tools. Technologies like build reproducibility, build provenance, and capability analysis can all minimize the risk from adding more privileged contributors.

We need platforms and tools to update their underlying assumptions about who does security work for projects to support this new open source security contribution model.
Separating maintenance responsibilities and security work is beneficial for users wanting to help projects, too. If we assume that the securing and maintaining are linked, then it becomes a more difficult task to be able to offer help to open source projects. Some projects do not have the governance in place to transition from one to many maintainers. Some maintainers want to continue owning the project roadmap and vision.
Getting your manager on-board with you maintaining a project is a difficult and amorphous ask compared to more tightly defined “security work” for an open source dependency your team uses. Open Source Program Offices (OSPOs) could use this model to concretely show how they are benefiting their whole open source supply-chain, and not only the larger projects that are able to receive grant funding.
I don’t think this change happens overnight, but we need to think about where we might go. From my experience working in open source, security work isn’t the special sauce, it’s always trust.
Whether you’re an open source user, a contributor to OpenSSF or other security working groups, or a developer of tools for open source projects, I hope I’ve inspired you that we need to think beyond current models of how security work is done for open source projects to achieve sustainable open source security.
Python⇒Speed
330× faster: Four different ways to speed up your code
Note: The original version of this article was slightly different, e.g. with 500x speedup; I reworked it to make the argument clearer.
If your Python code is slow and needs to be fast, there are many different approaches you can take, from parallelism to writing a compiled extension. But if you just stick to one approach, it’s easy to miss potential speedups, and end up with code that is much slower than it could be.
To make sure you’re not forgetting potential sources of speed, it’s useful to think in terms of practices. Each practice:
- Speeds up your code in its own unique way.
- Involves distinct skills and knowledge.
- Can be applied on its own.
- Can also be applied together with other practices for even more speed.
To make this more concrete, in this article I’ll work through an example where I will apply multiple practices. Specifically I’ll be demonstrating the practices of:
- Efficiency: Getting rid of wasteful or repetitive calculations.
- Compilation: Using a compiled language, and potentially working around the compiler’s limitations.
- Parallelism: Using multiple CPU cores.
- Process: Using development processes that result in faster code.
We’ll see that:
- Applying just the Practice of Efficiency to this problem gave me an almost 2× speed-up.
- Applying just the Practice of Compilation gave me a 10× speed-up.
- When I applied both, the result was even faster.
- Following up with the Practice of Parallelism gave even more of a speedup, for a final speed up of 330×.
July 01, 2025
PyCoder’s Weekly
Issue #688: Checking Dicts, DuckDB, Reading shelve.py, and More (July 1, 2025)
#688 – JULY 1, 2025
View in Browser »

Statically Checking Python Dicts for Completeness
To keep code concerns separate you might have two data structures (like an Enum and a dict) that are supposed to change in sequence: adding a value to the Enum requires you to add a similar value in the dict. This is common when separating business logic from UI code. This article shows you ways of making sure the corresponding changes happen together.
LUKE PLANT
Python Jobs
Sr. Software Developer (Python, Healthcare) (USA)
Articles & Tutorials
New Python Client Library for Google Data Commons
Google Data Commons announced the general availability of its new Python client library for the Data Commons. The goal of the library is to enhance how students, researchers, analysts, and data scientists access and leverage Data Commons.
KARA MOSCOE • Shared by Ariana Gaspar
How I’ve Run Major Projects
If you want to progress to being a technical lead, you need to understand how to manage projects. This post talks about the skills you need, and how often times it is mostly about being organized.
BEN KUHN
Projects & Code
Events
Happy Pythoning!
This was PyCoder’s Weekly Issue #688.
View in Browser »
[ Subscribe to 🐍 PyCoder’s Weekly 💌 – Get the best Python news, articles, and tutorials delivered to your inbox once a week >> Click here to learn more ]
Real Python
Implementing the Factory Method Pattern in Python
This video course explores the Factory Method design pattern and its implementation in Python. Design patterns became a popular topic in late 90s after the so-called Gang of Four (GoF: Gamma, Helm, Johson, and Vlissides) published their book Design Patterns: Elements of Reusable Object-Oriented Software.
The book describes design patterns as a core design solution to reoccurring problems in software and classifies each design pattern into categories according to the nature of the problem. Each pattern is given a name, a problem description, a design solution, and an explanation of the consequences of using it.
The GoF book describes Factory Method as a creational design pattern. Creational design patterns are related to the creation of objects, and Factory Method is a design pattern that creates objects with a common interface.
This is a recurrent problem that makes Factory Method one of the most widely used design patterns, and it’s very important to understand how it works and know how to apply it.
By the end of this video course, you’ll:
- Understand the components of Factory Method
- Recognize opportunities to use Factory Method in your applications
- Know how to modify existing code and improve its design by using the pattern
- Be able to identify opportunities where Factory Method is the appropriate design pattern
- Know how to choose an appropriate implementation of Factory Method
- Understand how to implement a reusable, general purpose solution of Factory Method
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Mike Driscoll
Creating a Website with Sphinx and Markdown
Sphinx is a Python-based documentation builder. The Python documentation is written using Sphinx. The Sphinx project supports using ReStructuredText and Markdown, or a mixture of the two. Each page of your documentation or website must be written using one of those two formats.
The original Python 101 website uses an old version of Sphinx, for example.
In this tutorial, you will learn how to use Sphinx to create a documentation site. Here is an overview of what you’ll learn:
- Getting the dependencies
- Setting up the site
- Making Markdown work in Sphinx
- Building your Sphinx site
- Adding content to your site
Let’s start by installing all the packages you need to get Sphinx working!
Getting the Dependencies
You will need the following packages to be able to use Sphinx and Markdown:
- sphinx
- myst-parser
You should install these package in a Python virtual environment. Open up your terminal and pick a location where you would like to create a new folder. Then run the following command:
python -m venv NAME_OF_VENV_FOLDER
Once you have the virtual environment, you need to activate it. Go into the Scripts folder and run the activate command in there.
Now you can install the dependencies that you need using pip, which will install them to your virtual environment.
Here’s how to install them using pip:
python -m pip install myst-parser sphinx
Once your packages are installed, you can learn how to set up your site!
Setting Up the Site
Now that your packages are installed, you must set up your Sphinx website. To create a barebones Sphinx site, run the following command inside your virtual environment:
sphinx-quickstart NAME_OF_SITE_FOLDER
It will ask you a series of questions. The Sphinx documentation recommends keeping the source and build folders separate. Otherwise, you can set the other fields as needed or accept the defaults.
You will now have the following tree structure in your SITE_FOLDER:

You will work with the files and directories in this structure for the rest of the tutorial.
The next step on your Sphinx journey is to enable Markdown support.
Making Markdown Work in Sphinx
Go into the source directory and open the conf.py file in your favorite Python IDE. Update the extensions and the source_suffix variables to the following (or add them if they do not exist):
extensions = ['myst_parser']
source_suffix = ['.rst', '.md']
These changes tell Sphinx to use the Myst parser for Markdown files. You also leave ReStructuredText files in there so that your Sphinx website can handle that format.
You now have enough of your site available to build it and ensure it works.
Building Your Sphinx Site
You can now build a simple site with only an index page and the auto-generated boilerplate content. In your terminal, run the following command in the root of your Sphinx folder:
sphinx-build -M html .\source\ .\build\
The HTML files will be created inside the build/html folder. If you open the index page, it will look something like this:

Good job! You now have a Sphinx website!
Now you need to add some custom content to it.
Adding Content to Your Site
You can add ReStructuredText or Markdown files for each page of your site. You must update your index.rst file to add those pages to your table of contents using the toctree section:
.. toctree:: :maxdepth: 2 :caption: Contents:
SUB_FOLDER/acknowledgments.md doc_page1.md OTHER_FOLDER/sub_doc_page1.md
Let’s add some real content. Create a new file called decorators.md in the root folder that contains the index.rst file. Then enter the following text in your new Markdown file:
Python: All About Decorators
Decorators can be a bit mind-bending when first encountered and can also be a bit tricky to debug. But they are a neat way to add functionality to functions and classes. Decorators are also known as a “higher-order function”. This means that they can take one or more functions as arguments and return a function as its result. In other words, decorators will take the function they are decorating and extend its behavior while not actually modifying what the function itself does.
There have been two decorators in Python since version 2.2, namely classmethod() and staticmethod(). Then PEP 318 was put together and the decorator syntax was added to make decorating functions and methods possible in Python 2.4. Class decorators were proposed in PEP 3129 to be included in Python 2.6. They appear to work in Python 2.7, but the PEP indicates they weren’t accepted until Python 3, so I’m not sure what happened there.
Let’s start off by talking about functions in general to get a foundation to work from.
The Humble Function
A function in Python and in many other programming languages is just a collection of reusable code. Some programmers will take an almost bash-like approach and just write all their code in a file with no functions. The code just runs from top to bottom. This can lead to a lot of copy-and-paste spaghetti code. Whenever two pieces of code do the same thing, they can almost always be put into a function. This will make updating your code easier since you’ll only have one place to update them.
Make sure you save the file. Then, re-run the build command from the previous section. Now, when you open the index.html file, you should see your new Markdown file as a link that you click on and view.
Wrapping Up
Sphinx is a powerful way to create documentation for your projects. Sphinx has many plugins that you can use to make it even better. For example, you can use sphinx-apidoc to automatically generate documentation from your source code using the autodoc extension.
If you are an author and you want to share your books online, Sphinx is a good option for that as well. Having a built-in search functionality makes it even better. Give Sphinx a try and see what it can do for you!
The post Creating a Website with Sphinx and Markdown appeared first on Mouse Vs Python.
Zero to Mastery
[June 2025] Python Monthly Newsletter 🐍
67th issue of Andrei Neagoie's must-read monthly Python Newsletter: Fastest Python, MCP Eats The World, Optimize Your Python, and much more. Read the full newsletter to get up-to-date with everything you need to know from last month.
Tryton News
Newsletter July 2025

In the last month we focused on fixing bugs, improving the behaviour of things, speeding-up performance issues - building on the changes from our last release. We also added some new features which we would like to introduce to you in this newsletter.
For an in depth overview of the Tryton issues please take a look at our issue tracker or see the issues and merge requests filtered by label.
Changes for the User
Accounting, Invoicing and Payments
Now we provide a dedicated list view to display the children lines on budget forms.
As we do not need the full record name but just the current name when editing a child from its parent form.
User Interface
We now converted Unidentified Image Errors into more user friendly validation errors. The normalisation/preprocess of images using PIL (Python Image Library) may raise these exceptions.
Now we keep selected rows on xxx2Many widget on reload.
We now limit the height of the completion drop downs and the actions are set sticky to be always visible.
System Data and Configuration
In order to have always the same results no matter of the order of the lines, we now round the tax amount of each line before adding it to the total tax.
In the past we rounded the tax amount per line after it was added to the total tax. With the used bankers rounding the issue is that when the result is like .xy5 (if rounding precision is set to 2 digits) it may be rounded up or down depending if the y-digit is even or odd.
New Releases
We released bug fixes for the currently maintained long term support series
7.0 and 6.0, and for the penultimate series 7.6, 7.4 and 7.2.
1 post - 1 participant
Seth Michael Larson
Hand-drawn QR codes
I really like QR codes. Recently I purchased a new sticky-note-like pad from a new local stationery store in Minneapolis. The sheets have a 10x10 grid and 2x10 grid.

I knew what I wanted to do, I wanted to create a QR code on a sheet. The smallest QR code (besides micro QR codes) is "version 1" which uses 21x21 pixels. We'll have to split the squares in half and then use some of the margin.
Version 1 QR codes can hold URLs up to 17 bytes long using the lowest data quality setting. Unfortunately https://sethmlarson.dev is 23 bytes long, so I'll have to improvise. I went with sethmlarson.dev instead, as this will prompt many QR code scanners to "search" for the term resulting in my website.
Note that a lovely reader informed me shortly after publication that indeed I can include my full domain name in a version 1 QR code by using all capital letters instead of lowercase. TIL that the "alphanumeric" character set for QR codes actually contains symbols for URLs like
:and/.Expect an updated QR code published after lunch today. :)
I created my reference using the qrcode package on the Python Package Index. Don't forget the -n option with echo to not include a trailing newline.
$ echo -n "HTTPS://SETHMLARSON.DEV" | qr --error-correction=L
I drew the corner squares (known as "position patterns") and then started trying to scan the QR code as a gradually filled in other pixels. Once I had drawn the "timing lines" between the top left and bottom left position I could see that my scanner "wanted" to see something in my drawing.

I continued adding the top timing line and data and then the scanner could start to see the whole square as a QR code. If you look closely I even made a mistake here in the data a bit, but in the end this didn't matter even on the lowest error-correction level.

Finally, my QR code was complete! Scanning the QR code was quite finicky because the paper was curling up off the flat surface. I could only get the scan to work when I held the paper flat. However, hanging the QR code from my monitor worked extremely well, even when scanning from a distance.

I hope this inspires you to try hand-drawing something on grid paper 🖤🤍 If you're looking for more grid-based inspiration, take a look at GRID WORLD, a web art piece by Alexander Miller.
June 30, 2025
Real Python
Use TorchAudio to Prepare Audio Data for Deep Learning
Ever wondered how machine learning models process audio data? How do you handle different audio lengths, convert sound frequencies into learnable patterns, and make sure your model is robust? This tutorial will show you how to handle audio data using TorchAudio, a PyTorch-based toolkit.
You’ll work with real speech data to learn essential techniques like converting waveforms to spectrograms, standardizing audio lengths, and adding controlled noise to build machine and deep learning models.
By the end of this tutorial, you’ll understand that:
- TorchAudio processes audio data for deep learning, including tasks like loading datasets and augmenting data with noise.
- You can load audio data in TorchAudio using the
torchaudio.load()function, which returns a waveform tensor and sample rate. - TorchAudio normalizes audio by default during loading, scaling waveform amplitudes between -1.0 and 1.0.
- A spectrogram visually represents the frequency spectrum of an audio signal over time, aiding in frequency analysis.
- You can pad and trim audio in TorchAudio using
torch.nn.functional.pad()and sequence slicing for uniform audio lengths.
Dive into the tutorial to explore these concepts and learn how they can be applied to prepare audio data for deep learning tasks using TorchAudio.
Take the Quiz: Test your knowledge with our interactive “Use TorchAudio to Prepare Audio Data for Deep Learning” quiz. You’ll receive a score upon completion to help you track your learning progress:

Learn Essential Technical Terms
Before diving into the technical details of audio processing with TorchAudio, take a moment to review some key terms. They’ll help you grasp the basics of working with audio data.
Waveform
A waveform is the visual representation of sound as it travels through air over time. When you speak, sing, or play music, you create vibrations that move through the air as waves. These waves can be captured and displayed as a graph showing how the sound’s pressure changes over time. Here’s an example:
 A Sample Waveform of a 440 Hz Wave
A Sample Waveform of a 440 Hz Wave
This is a waveform of a 440 Hz wave, plotted over a short duration of 10 milliseconds (ms). This is called a time-domain representation, showing how the wave’s amplitude changes over time. This waveform shows the raw signal as it appears in an audio editor. The ups and downs reflect changes in loudness.
Amplitude
Amplitude is the strength or intensity of a sound wave—in other words, how loud the sound is to the listener. In the previous image, it’s represented by the height of the wave from its center line.
A higher amplitude means a louder sound, while a lower amplitude means a quieter sound. When you adjust the volume on your device, you’re actually changing the amplitude of the audio signal. In digital audio, amplitude is typically measured in decibels (dB) or as a normalized value between -1 and 1.
Frequency
Frequency is how many times a sound wave repeats itself in one second, measured in hertz (Hz). For example, a low bass note is a sound wave that repeats slowly, about 50–100 Hz. In contrast, a high-pitched whistle has a wave that repeats much faster, around 2000–3000 Hz.
In music, different frequencies create different musical notes. For instance, the A4 note that musicians use to tune their instruments is exactly 440 Hz. Now, if you were to look at the frequency plot of the 440 Hz waveform from before, here’s what you’d see:
 A Frequency Domain Plot of a 440 Hz Wave
A Frequency Domain Plot of a 440 Hz Wave
This plot displays the signal in the frequency domain, which shows how much of each frequency is present in the sound. The distinct peak at 440 Hz indicates that this is the dominant frequency in the signal, which is exactly what you’d expect from a pure tone. While time-domain plots—like the one you saw earlier—reveal how the sound’s amplitude changes over time, frequency-domain plots help you understand which frequencies make up the sound.
The waveform you just explored was from a 440 Hz wave. You’ll soon see that many examples in audio processing also deal with this mysterious frequency. So, what makes it so special?
Note: The 440 Hz frequency (A4 note) is the international standard pitch reference for tuning instruments. Its clear, single-frequency nature makes it great for audio tasks. These include sampling, frequency analysis, and waveform representation.
Now that you understand frequency and how it relates to sound waves, you might be wondering how computers actually capture and store these waves.
Sampling
When you record sound digitally, you’re taking snapshots of the audio wave many times per second. Each snapshot measures the wave’s amplitude at that instant. This is called sampling. The number of snapshots taken per second is the sampling rate, measured in hertz (Hz).
Read the full article at https://realpython.com/python-torchaudio/ »
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Quiz: Use TorchAudio to Prepare Audio Data for Deep Learning
In this quiz, you’ll test your understanding of audio fundamentals and how to Use TorchAudio to Prepare Audio Data for Deep Learning.
You’ll revisit fundamental terminology and how to:
- Install and import TorchAudio
- Load audio waveform datasets
- Apply signal transforms
Work through these questions to check your knowledge about building audio workflows for machine learning in Python.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Django Weblog
Our 2024 Annual Impact Report
Django has always been more than just a web framework; it’s a testament to what a dedicated community can build together. Behind every Django release, bug fix, or DjangoCon is a diverse network of people working steadily to strengthen our open-source ecosystem. To celebrate our collective effort, the Django Software Foundation (DSF) is excited to share our 2024 Annual Impact Report 🎉
In this report, you’ll discover key milestones, narratives of community folks, the impact of the events running throughout the year, and much more, ramping up to how we’re laying the groundwork for an even more resilient and inclusive Django community.
Why we publish this report
Transparency is essential for our community-driven organization. Everyone deserves to know how our work and investments translate into real impact. It’s more than just statistics. It’s our way to:
- Show how your contributions make a difference, with vibrant highlights from the past year.
- Reflect on community progress, recognizing the people and ideas that keep Django thriving.
- Invite more individuals and organizations to get involved.
Looking ahead: call to action
As we make progress through 2025, the Django Software Foundation remains dedicated to strengthening the ecosystem that supports developers, contributors, and users around the world. With a growing network of working groups, community initiatives, and the commitment of volunteers, we’re focused on nurturing the people and executing ideas that make Django what it is: the web framework for perfectionists with deadlines.
Help keep this momentum strong by supporting Django through any of the following ways:
- Donate to Django to support future development
- Convince your company to become a Corporate Member
- Join the Foundation as an Individual Member
- Get involved with the working groups
- Join our community on the Django Forum or Discord server.
- Follow and re-share our posts on Mastodon, on Bluesky, or on X.
- Follow our page on LinkedIn.
Thank you, everyone, for your dedication and efforts. Here’s to another year of collaboration, contribution, and shared success!
Any feedback or questions about our report? Come say hi in our feedback thread on the Django forum.
Python Bytes
#438 Motivation time
Topics covered in this episode:
- * Python Cheat Sheets from Trey Hunner*
- * Automatisch*
- * mureq-typed*
- * My CLI World*
- Extras
- Joke
About the show
Sponsored by Posit: pythonbytes.fm/connect
Connect with the hosts
- Michael: @mkennedy@fosstodon.org / @mkennedy.codes (bsky)
- Brian: @brianokken@fosstodon.org / @brianokken.bsky.social
- Show: @pythonbytes@fosstodon.org / @pythonbytes.fm (bsky)
Join us on YouTube at pythonbytes.fm/live to be part of the audience. Usually Monday at 10am PT. Older video versions available there too.
Finally, if you want an artisanal, hand-crafted digest of every week of the show notes in email form? Add your name and email to our friends of the show list, we'll never share it.
Brian #1: Python Cheat Sheets from Trey Hunner
- Some fun sheets
Michael #2: Automatisch
- Open source Zapier alternative
- Automatisch helps you to automate your business processes without coding.
- Use their affordable cloud solution or self-host on your own servers.
- Automatisch allows you to store your data on your own servers, good for companies dealing with sensitive user data, particularly in industries like healthcare and finance, or those based in Europe bound by General Data Protection Regulation (GDPR).
Michael #3: mureq-typed
- Single file, zero-dependency alternative to requests. Fully typed. Modern Python tooling.
- Typed version of mureq (covered in 2022 on episode 268)
- Intended to be vendored in-tree by Linux systems software and other lightweight applications.
mureq-typedis a drop-in, fully API compatible replacement for mureq updated with modern Python tooling:- Type checked with mypy, ty, and pyrefly.
- Formatted with black, no ignore rules necessary.
- Linted with ruff (add these rules for
mureq.pyto yourper-file-ignores).
Brian #4: My CLI World
- Frank Wiles
- Encouragement to modify your command line environment
- Some of Franks tools
- Also some aliases, like gitpulllog
- Notes
- We covered poethepoet recently, if just just isn’t cutting it for you.
- I tried to ilke starship, bit for some reason with my setup, it slows down the shell too much.
Extras
Brian:
- Interesting read of the week: New theory proposes time has three dimensions, with space as a secondary effect
- Michael's: New quantum theory of gravity brings long-sought 'theory of everything' a crucial step closer
Joke:
Brian read a few quotes from the book
Disappointing Affirmations, by Dave Tarnowski
- “You are always just a moment away from your next worst day ever. Or your next best day ever, but let’s be realistic.”
- “You can be anything you want. And yet you keep choosing to be you. I admire your dedication to the role.”
- “Today I am letting go of the things that are holding me back from the life that I want to live. Then I’m picking them all up again because I have separation anxiety.”
June 27, 2025
Hugo van Kemenade
Run coverage on tests
I recommendrunning coverage on your tests.
Here’s a couple of reasons why, from the past couple of months.
Example one #
When writing tests, it’s common to copy and paste test functions, but sometimes you forget to rename the new one (see also: theLast Line Effect).
For example:
def test_get_install_to_run_with_platform(patched_installs):
i = installs.get_install_to_run("<none>", None, "1.0-32")
assert i["id"] == "PythonCore-1.0-32"
assert i["executable"].match("python.exe")
i = installs.get_install_to_run("<none>", None, "2.0-arm64")
assert i["id"] == "PythonCore-2.0-arm64"
assert i["executable"].match("python.exe")
def test_get_install_to_run_with_platform(patched_installs):
i = installs.get_install_to_run("<none>", None, "1.0-32", windowed=True)
assert i["id"] == "PythonCore-1.0-32"
assert i["executable"].match("pythonw.exe")
i = installs.get_install_to_run("<none>", None, "2.0-arm64", windowed=True)
assert i["id"] == "PythonCore-2.0-arm64"
assert i["executable"].match("pythonw.exe")
The tests pass, but the first one is never run because its name is redefined. This clearly shows up as a non-run test in the coverage report. In thiscase, we only need to rename one of them, and both are covered and pass.
But sometimes there’s a bug in the test which would cause it to fail, but we just don’t know because it’s not run.
Tip 2: pytest’s parametrize is a great way to combine similar test functions with different input data.
Example two #
This is more subtle:
im = Image.new("RGB", (1, 1))
for colors in (("#f00",), ("#f00", "#0f0")):
append_images = (Image.new("RGB", (1, 1), color) for color in colors)
im_reloaded = roundtrip(im, save_all=True, append_images=append_images)
assert_image_equal(im, im_reloaded)
assert isinstance(im_reloaded, MpoImagePlugin.MpoImageFile)
assert im_reloaded.mpinfo is not None
assert im_reloaded.mpinfo[45056] == b"0100"
for im_expected in append_images:
im_reloaded.seek(im_reloaded.tell() + 1)
assert_image_similar(im_reloaded, im_expected, 1)
It’s not so obvious when looking at the code, but Codecov highlights a problem:
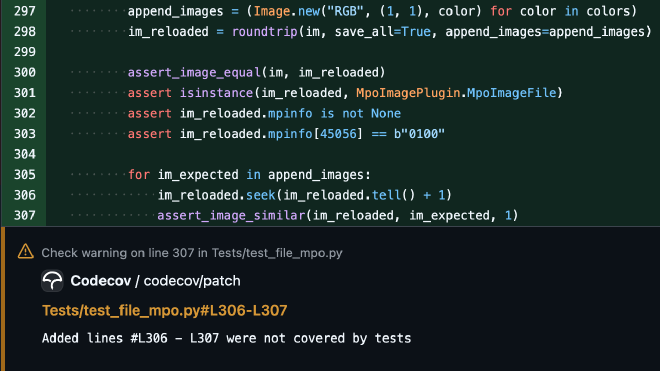
The append_images generator is being consumed inside roundtrip(), so we have nothing to iterate over in the for loop – hence no coverage. Thefix is to use a list instead of a generator.
Header photo: Misplaced manhole cover (CC BY-NC-SA 2.0 Hugo van Kemenade).
Real Python
The Real Python Podcast – Episode #255: Structuring Python Scripts & Exciting Non-LLM Software Trends
What goes into crafting an effective Python script? How do you organize your code, manage dependencies with PEP 723, and handle command-line arguments for the best results? Christopher Trudeau is back on the show this week, bringing another batch of PyCoder's Weekly articles and projects.
[ Improve Your Python With 🐍 Python Tricks 💌 – Get a short & sweet Python Trick delivered to your inbox every couple of days. >> Click here to learn more and see examples ]
Luke Plant
Statically checking Python dicts for completeness
In Python, I often have the situation where I create a dictionary, and want to ensure that it is complete – it has an entry for every valid key.
Let’s say for my (currently hypothetical) automatic squirrel-deterring water gun system, I have a number of different states the water tank can be in, defined using an enum:
from enum import StrEnum class TankState(StrEnum): FULL = "FULL" HALF_FULL = "HALF_FULL" NEARLY_EMPTY = "NEARLY_EMPTY" EMPTY = "EMPTY"
In a separate bit of code, I define an RGB colour for each of these states, using a simple dict.
TANK_STATE_COLORS = { TankState.FULL: 0x00FF00, TankState.HALF_FULL: 0x28D728, TankState.NEARLY_EMPTY: 0xFF9900, TankState.EMPTY: 0xFF0000, }
This is deliberately distinct from my TankState code and related definitions, because it relates to a different part of the project - the user interface. The UI concerns shouldn’t be mixed up with the core logic.
This dict is fine, and currently complete. But I’d like to ensure that if I add a new item to TankState, I don’t forget to update the TANK_STATE_COLORS dict.
With a growing ability to do static type checks in Python, some people have asked how we can ensure this using static type checks. The short answer is, we can’t (at least at the moment).
But the better question is “how can we (somehow) ensure we don’t forget?” It doesn’t have to be a static type check, as long as it’s very hard to forget, and if it preferably runs as early as possible.
Instead of shoe-horning everything into static type checks, let’s just make use of the fact that this is Python and we can write any code we want at module level. All we need to do is this:
TANK_STATE_COLORS = { # … } for val in TankState: assert val in TANK_STATE_COLORS, f"TANK_STATE_COLORS is missing an entry for {val}"
That’s it, that’s the whole technique. I’d argue that this is a pretty much optimal, Pythonic solution to the problem. No clever type tricks to debug later, just 2 lines of plain simple code, and it’s impossible to import your code until you fix the problem, which means you get the early checking you want. Plus you get exactly the error message you want, not some obscure compiler output, which is also really important.
It can also be extended if you want to do something more fancy (e.g. allow some values of the enum to be missing), and if it does get in your way, you can turn it off temporarily by just commenting out a couple of lines.
That’s not quite it
OK, in a project where I’m using this a lot, I did eventually get bored of this small bit of boilerplate. So, as a Pythonic extension of this Pythonic solution, I now do this:
TANK_STATE_COLORS: dict[TankState, int] = { TankState.FULL: 0x00FF00, TankState.HALF_FULL: 0x28D728, TankState.NEARLY_EMPTY: 0xFF9900, TankState.EMPTY: 0xFF0000, } assert_complete_enumerations_dict(TANK_STATE_COLORS)
Specifically, I’m adding:
- a type hint on the constant
- a call to a clever utility function that does just the right amount of Python magic.
This function needs to be “magical” because we want it to produce good error messages, like we had before. This means it needs to get hold of the name of the dict in the calling module, but functions don’t usually have access to that.
In addition, it wants to get hold of the type hint (although there would be other ways to infer it without a type hint, there are advantages this way), for which we also need the name.
The specific magic we need is:
- the clever function needs to get hold of the module that called it
- it then looks through the module dictionary to get the name of the object that has been passed in
- then it can find type hints, and do the checking.
So, because you don’t want to write all that yourself, the code is below. It also supports:
- having a tuple of
Enumtypes as the key - allowing some items to be missing
- using
Literalas the key. So you can do things like this:
X: dict[typing.Literal[-1, 0, 1], str] = {
-1: "negative",
0: "zero",
1: "positive",
}
assert_complete_enumerations_dict(X)
It’s got a ton of error checking, because once you get magical then you really don’t want to be debugging obscure messages.
Enjoy!
I hereby place the following code into the public domain - CC0 1.0 Universal.
import inspect
import itertools
import sys
import typing
from collections.abc import Mapping, Sequence
from enum import Enum
from frozendict import frozendict
def assert_complete_enumerations_dict[T](the_dict: Mapping[T, object], , allowed_missing: Sequence[T] = ()):
"""
Magically assert that the dict in the calling module has a
value for every item in an enumeration.
The dict object must be bound to a name in the module.
It must be type hinted, with the key being an Enum subclass, or Literal.
The key may also be a tuple of Enum subclasses
If you expect some values to be missing, pass them in allowed_missing
"""
assert isinstance(the_dict, Mapping), f"{the_dict!r} is not a dict or mapping, it is a {type(the_dict)}"
frame_up = sys._getframe(1) # type: ignore[reportPrivateUsage]
assert frame_up is not None
module = inspect.getmodule(frame_up)
assert module is not None, f"Couldn't get module for frame {frame_up}"
msg_prefix = f"In module {module.__name__},"
module_dict = frame_up.f_locals
name: str | None = None
# Find the object:
names = [k for k, val in module_dict.items() if val is the_dict]
assert names, f"{msg_prefix} there is no name for {the_dict}, please check"
# Any name that has a type hint will do, there will usually be one.
hints = typing.get_type_hints(module)
hinted_names = [name for name in names if name in hints]
assert (
hinted_names
), f"{msg_prefix} no type hints were found for {', '.join(names)}, they are needed to use assert_complete_enumerations_dict"
name = hinted_names[0]
hint = hints[name]
origin = typing.get_origin(hint)
assert origin is not None, f"{msg_prefix} type hint for {name} must supply arguments"
assert origin in (
dict,
typing.Mapping,
Mapping,
frozendict,
), f"{msg_prefix} type hint for {name} must be dict/frozendict/Mapping with arguments to use assert_complete_enumerations_dict, not {origin}"
args = typing.get_args(hint)
assert len(args) == 2, f"{msg_prefix} type hint for {name} must have two args"
arg0, _ = args
arg0_origin = typing.get_origin(arg0)
if arg0_origin is tuple:
# tuple of Enums
enum_list = typing.get_args(arg0)
for enum_cls in enum_list:
assert issubclass(
enum_cls, Enum
), f"{msg_prefix} type hint must be an Enum to use assert_complete_enumerations_dict, not {enum_cls}"
items = list(itertools.product((list(enum_cls) for enum_cls in enum_list)))
elif arg0_origin is typing.Literal:
items = typing.get_args(arg0)
else:
assert issubclass(
arg0, Enum
), f"{msg_prefix} type hint must be an Enum to use assert_complete_enumerations_dict, not {arg0}"
items = list(arg0)
for item in items:
if item in allowed_missing:
continue
# This is the assert we actually want to do, everything else is just error checking:
assert item in the_dict, f"{msg_prefix} {name} needs an entry for {item}"
PyPodcats
Episode 9: With Tamara Atanasoska
Learn about Tamara's journey. Tamara has been contributing to open source projects since 2012. She participated in Google Summer of Code to contribute to projects like Gnome and e-cidadania.Learn about Tamara's journey. Tamara has been contributing to open source projects since 2012. She participated in Google Summer of Code to contribute to projects like Gnome and e-cidadania.
We interviewed Tamara Atanasoska.
Tamara has been contributing to open source projects since 2012. She participated in Google Summer of Code to contribute to projects like Gnome and e-cidadania.
She is now a maintainer of Fairlearn, an open-source, community-driven project to help data scientists improve fairness of AI systems.
Hear how Django helps her feel empowered, and how the PyLadies Berlin community has helped her feel welcomed as a new immigrant in Germany.
In this episode, Tamara shares perspective about open source contributions, maintain, mentorship, and her experience in running beginner-friendly sprints.
Be sure to listen to the episode to learn all about Tamara’s inspiring story!
Topic discussed
- Introductions
- Getting to know Tamara
- Her role at :probabl.
- Her role as an open source maintainer for Fairlearn
- What is Fairlearn and discussion about fairness in AI
- The challenges in getting feedback from the users about the Fairlearn project
- How she get started with Python and Django
- Her political participation that led her to contributing to civic engagement open source project during Google Summer of Code
- How Django helps her feel empowered
- Her experience with hacker spaces
- How the Python and PyLadies Berlin community helps her feel welcomed as a new immigrant in Berlin
- How she gives back to the community by speaking, mentoring, and leading sprints
- How she approaches mentorship, and why it is part of her core values.
- Her ideas about leading beginner-friendly sprints
- Her future endeavors
Note
This episode was recorded in March 2025. Tamara is still a software engineer, but no longer works at probabl.
To find out more about what she is currently up to, check her LinkedIn profile.
Links from the show
- Fairlearn: https://fairlearn.org/
- Fairlearn Community Survey: https://docs.google.com/forms/d/e/1FAIpQLSeOTRNgAc2RYnDDO5-GE7scMysPHrBLs8XV21ZP--XATr34aA/viewform
- :probabl.: https://probabl.ai/
- scikit-learn: https://scikit-learn.org/
- e-cidadania GitHub repository: https://github.com/cidadania/e-cidadania
- Google Summer of Code 2012: https://opensource.googleblog.com/2012/05/macedonia-google-summer-of-code-meetups.html
- PyLadies Berlin: https://berlin.pyladies.com/en/
- Tamara’s Substack: https://holophrase.substack.com/
- Tamara’s website: https://tamaraatanasoska.github.io/about/