Simplified syntax for RDF (original) (raw)
This is a complementary proposal for a simplified RDF syntax inspired by Tim'sstrawman draft. A reference implementation is available.
Requirements for the syntax:
- simplicity: self-explanatory
- as context-free as possible
- allow mixing XML with RDF XML attributes controlling the behavior of the RDF processor that are used in this document are:
- rdf:instance (says that the containing tag is a class name)
- rdf:for (the containing tag is a property name, the value of the attribute is the subject URI)
- rdf:resource (the containing tag is a property name, the value of the attribute is the object URI) rdf:instance cannot be used together with rdf:for orrdf:resource.
Pure RDF
RDF follows a property-centric approach. Let the syntax reflect it. Every XML tag encountered during processing is considered to be a property name, unless explicitly overriden. For a tag to be a class name, it must carry the XML attributerdf:instance. Example:
Poo Strawman 1999-05-24 Boston Who knowsThe RDF model of the example is:
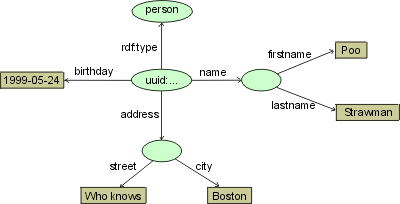
Tag interpretation does not switch back and forth between class name and property name. Instead, RDF processor can determine in a context-free fashion that the tag name is a class iff it carries rdf:instance. In all other cases, tag name denotes a property.
Complete parsing algorithm
Definition: The function "URI getUniqueURI(Element el)"is a one-to-one function that returns a unique URI for a given XML element (relative to the URI of the document). The function could be based on the XPath specs.
Definition: The function "Resource getSubject(Element el)"is defined as follows:
- if el has attribute rdf:instance, the value of the function is the value of rdf:instance
- if el has attribute rdf:resource, the value of the function is the value of rdf:resource
- if el has neither rdf:instance, nor rdf:resource, return getUniqueURI(el)
- otherwise undefined In the subsequent definition, PCDATA is used interchangeably with "PCDATA or CDATA".
Definition: The function "RDFNode getObject(Element el)"is defined as follows:
- if el has attribute rdf:resource, the value of the function is the value of rdf:resource
- if el has no rdf:resource and no subelements, the value of the function is a literal representing PCDATA of el. Empty literal, if el is empty.
- if el has subelements, return getUniqueURI(el)
- otherwise undefined Algorithm: For a given XML subtree with the root element el, the corresponding RDF model is generated according to the following algorithm:
void generateRDF(Element el) {
if hasRDFInstanceAtt(el) {
createTriple( valueOfRDFInstanceAtt(el), rdf:type, el.getTagName() ); // ***
} else { // has no rdf:instance
if hasRDFForAtt(el)
subject = valueOfRDFForAtt(el);
else
subject = getSubject(el.getParent());
createTriple( subject, el, getObject(el) );
}
for every ch in children(el)
generateRDF(ch);
}
***: do not explicitly generate triples of the kind (subject, rdf:type, rdfs:Resource)
FIXME: shoud we prohibit that both child and parent have rdf:instance?
Examples
Example: Serialization for figure 1 in RDF M&S
Ora Lassila
is equivalent to
<rdfs:Resource rdf:instance="" title="undefined" rel="noopener noreferrer">http://www.w3.org/Home/Lassila">
Ora Lassila
Example: Serialization for figure 2 in RDF M&S
Ora Lassila lassila@w3.orgExample: Serialization for figure 3 in RDF M&S
Ora Lassila lassila@w3.orgNotes
- Neither rdf:RDF nor rdf:Description are needed any more. RDF processor skips all valid XML until it finds a tag having rdf:instanceor rdf:for.
- getSubject() and getObject() are NOT recursive. Therefore, application of the parsing algorithm is structurally equivalent with a depth-first traversal of XML subtree.
- There is no abbreviated syntax any more.
- This document does not consider reification. For the sake of simplicity, reification should probably be expressed on a lower level of granularity, i.e. reifying a single statement at a time.
Mixing RDF with XML
THIS SECTION IS OBSOLETE: see "Bridging the Gap between RDF and XML"
To mix RDF with XML the parser needs a clue wrt whether the XML elements under consideration are RDF-transparent or should be evaluated as RDF. It would be helpful to have a mechanism for the parser to make this distinction based on the namespace of the element (I'm tempted to say something like "rdfns:dc=..." albeit I'm aware of the problems of this approach).
If there is such mechanism, the above algorithm can be modified to "see through" all non-RDF tags (we are talking about hints for the parser, so what about (mis)using processing instructions for that purpose a la <?rdfns http://... ?rdfns>).
Example:
**<t:WebPage** xmlns="" xmlns:rdf="..." xmlns:t="..." xmlns:dc="..."
rdf:instance="">
...
...Last modified by: **Me**
Sergey Melnik, Nov 19, 1999. Last change: Dec 16, 1999