Hundreds of variants clustered in genomic loci and biological pathways affect human height (original) (raw)
. Author manuscript; available in PMC: 2011 Apr 14.
Published in final edited form as: Nature. 2010 Sep 29;467(7317):832–838. doi: 10.1038/nature09410
Abstract
Most common human traits and diseases have a polygenic pattern of inheritance: DNA sequence variants at many genetic loci influence phenotype. Genome-wide association (GWA) studies have identified >600 variants associated with human traits1, but these typically explain small fractions of phenotypic variation, raising questions about the utility of further studies. Here, using 183,727 individuals, we show that hundreds of genetic variants, in at least 180 loci, influence adult height, a highly heritable and classic polygenic trait2,3. The large number of loci reveals patterns with important implications for genetic studies of common human diseases and traits. First, the 180 loci are not random, but instead are enriched for genes that are connected in biological pathways (_P_=0.016), and that underlie skeletal growth defects (P<0.001). Second, the likely causal gene is often located near the most strongly associated variant: in 13 of 21 loci containing a known skeletal growth gene, that gene was closest to the associated variant. Third, at least 19 loci have multiple independently associated variants, suggesting that allelic heterogeneity is a frequent feature of polygenic traits, that comprehensive explorations of already-discovered loci should discover additional variants, and that an appreciable fraction of associated loci may have been identified. Fourth, associated variants are enriched for likely functional effects on genes, being over-represented amongst variants that alter amino acid structure of proteins and expression levels of nearby genes. Our data explain ∼10% of the phenotypic variation in height, and we estimate that unidentified common variants of similar effect sizes would increase this figure to ∼16% of phenotypic variation (∼20% of heritable variation). Although additional approaches are needed to fully dissect the genetic architecture of polygenic human traits, our findings indicate that GWA studies can identify large numbers of loci that implicate biologically relevant genes and pathways.
In Stage 1 of our study, we performed a meta-analysis of GWA data from 46 studies, comprising 133,653 individuals of recent European ancestry, to identify common genetic variation associated with adult height. To enable meta-analysis of studies across different genotyping platforms, we performed imputation of 2,834,208 single nucleotide polymorphisms (SNPs) present in the HapMap Phase 2 European-American reference panel4. After applying quality control filters, each individual study tested the association of adult height with each SNP using an additive model (Supplementary Methods). The individual study statistics were corrected using the genomic control (GC) method5,6 and then combined in a fixed effects based meta-analysis. We then applied a second GC correction on the meta-analysis statistics, although this approach may be overly conservative when there are many real signals of association (Supplementary Methods). We detected 207 loci (defined as 1Mb on either side of the most strongly associated SNP) as potentially associated with adult height (P<5×10-6).
To identify loci robustly associated with adult height, we took forward at least one SNP (Supplementary Methods) from each of the 207 loci reaching P<5×10-6 into an additional 50,074 samples (Stage 2) that became available after completion of our initial meta-analysis. In the joint analysis of our Stage 1 and Stage 2 studies, SNPs representing 180 loci reached genome-wide significance (P<5×10-8; Supplementary Figures 1 and 2, Supplementary Table 1). Additional tests, including genotyping of a randomly-selected subset of 33 SNPs in an independent sample of individuals from the 5th-10th and 90th-95th percentiles of the height distribution (N=3,190)7, provided further validation of our results, with all but two SNPs showing consistent direction of effect (sign test P<7×10-8) (Supplementary Methods, Supplementary Table 2).
Genome wide association studies can be susceptible to false positive associations from population stratification7. We therefore performed a family-based analysis, which is immune to population stratification in 7,336 individuals from two cohorts with pedigree information. Alleles representing 150 of the 180 genome-wide significant loci were associated in the expected direction (sign test P<6×10-20; Supplementary Table 3). The estimated effects on height were essentially identical in the overall meta-analysis and the family-based sample. Together with several other lines of evidence (Supplementary Methods), this indicates that stratification is not substantially inflating the test statistics in our meta-analysis.
Common genetic variants have typically explained only a small proportion of the heritable component of phenotypic variation8. This is particularly true for height, where >80% of the variation within a given population is estimated to be attributable to additive genetic factors9, but over 40 previously published variants explain <5% of the variance10-17. One possible explanation is that many common variants of small effects contribute to phenotypic variation, and current GWA studies remain underpowered to detect the majority of common variants. Using five studies not included in Stage 1, we found that the 180 associated SNPs explained on average 10.5% (range 7.9-11.2%) of the variance in adult height (Supplementary Methods). Including SNPs associated with height at lower significance levels (0.05>_P_>5×10-8) increased the variance explained to 13.3% (range 9.7-16.8%) (Figure 1a)18. In addition, we found no evidence that non-additive effects including gene-gene interaction would increase the proportion of the phenotypic variance explained (Supplementary Methods, Supplementary Tables 5 and 6).
Figure 1. Phenotypic variance explained by common variants.


(a) Variance explained is higher when SNPs not reaching genome-wide significance are included in the prediction model. The y-axis represents the proportion of variance explained at different _P_-value thresholds from Stage 1. Results are given for five studies that were not part of Stage 1. *Proportion of variation explained by the 180 SNPs. (b) Cumulative number of susceptibility loci expected to be discovered, including already identified loci and as yet undetected loci. The projections are based on loci that achieved a significance level of P<5×10-8 in the initial scan and the distribution of their effect sizes in Stage 2. The dotted red line corresponds to expected phenotypic variance explained by the 110 loci that reached genome-wide significance in Stage 1, were replicated in Stage 2 and had at least 1% power.
As a separate approach, we used a recently developed method19 to estimate the total number of independent height-associated variants with effect sizes similar to the ones identified. We obtained this estimate using the distribution of effect sizes observed in Stage 2 and the power to detect an association in Stage 1, given these effect sizes (Supplementary Methods). The cumulative distribution of height loci, including those we identified and others as yet undetected, is shown in Figure 1b. We estimate that there are 697 loci (95% confidence interval (CI): 483-1040) with effects equal or greater than those identified, which together would explain approximately 15.7% of the phenotypic variation in height or 19.6% (95% CI: 16.2-25.6) of height heritability (Supplementary Table 4). We estimated that a sample size of 500,000 would detect 99.6% of these loci at P<5×10-8. This figure does not account for variants that have effect sizes smaller than those observed in the current study and, therefore, underestimates the contribution of undiscovered common loci to phenotypic variation.
A further possible source of missing heritability is allelic heterogeneity – the presence of multiple, independent variants influencing a trait at the same locus. We performed genome-wide conditional analyses in a subset of Stage 1 studies, including a total of 106,336 individuals. Each study repeated the primary GWA analysis but additionally adjusted for SNPs representing the 180 loci associated at P<5×10-6 (Supplementary Methods). We then meta-analysed these studies in the same way as for the primary GWA study meta-analysis. Nineteen SNPs within the 180 loci were associated with height at P<3.3×10-7 (a Bonferroni-corrected significance threshold calculated from the ∼15% of the genome covered by the conditioned 2Mb loci; Supplementary Methods, Table 1, Figure 2, Supplementary Figure 3). The distances of the second signals to the lead SNPs suggested that both are likely to be affecting the same gene, rather than being coincidentally in close proximity. At 17 of 17 loci (excluding two contiguous loci in the HMGA1 region), the second signal occurred within 500kb, rather than between 500kb and 1 Mb, of this lead SNP (binomial test _P_=2×10-5). Further analyses of allelic heterogeneity may identify additional variants that increase the proportion of variance explained. For example, within the 180 2Mb loci, a total of 45 independent SNPs reached P<1×10-5 when we would expect <2 by chance.
Table 1. Secondary signals at associated loci after conditional analysis.
| Second signal SNP | Conditioned SNP | Chr | Second signal SNP position | Distance of conditioned SNP from index SNP (bp) | HapMapa r2 | Second signal _P_-value after conditioning | Second signal _P_-value pre-conditioning | Geneb |
|---|---|---|---|---|---|---|---|---|
| rs2280470 | rs16942341 | 15 | 87196630 | 6721 | 0.009 | 1×10-14 | 1×10-15 | ACAN |
| rs10859563 | rs11107116 | 12 | 92644470 | 141835 | 0.003 | 3×10-12 | 8×10-10 | SOCS2 |
| rs750460 | rs5742915 | 15 | 72028559 | 95127 | 0.004 | 4×10-12 | 7×10-08 | PML |
| rs6938239 | rs2780226* | 6 | 34791613 | 484583 | 0.019 | 6×10-12 | 9×10-14 | HMGA1 |
| rs7652177 | rs572169 | 3 | 173451771 | 196650 | 0.006 | 7×10-11 | 1×10-11 | GHSR |
| rs7916441 | rs2145998 | 10 | 80595583 | 196119 | 0.112 | 6×10-10 | 3×10-07 | PPIF |
| rs3792752 | rs1173727 | 5 | 32804391 | 61887 | 0.02 | 7×10-10 | 4×10-08 | NPR3 |
| rs10958476 | rs7460090 | 8 | 57258362 | 98355 | 0.02 | 1×10-09 | 5×10-13 | SDR16C5 |
| rs2353398 | rs7689420 | 4 | 145742208 | 45594 | 0.022 | 2×10-09 | 1×10-10 | HHIP |
| rs2724475 | rs6449353 | 4 | 17555530 | 87056 | 0.098 | 2×10-09 | 8×10-16 | LCORL |
| rs2070776 | rs2665838 | 17 | 59361230 | 41033 | 0.15 | 9×10-09 | 1×10-14 | GH region |
| rs1401796 | rs227724 | 17 | 52194758 | 60942 | 0.005 | 2×10-08 | 7×10-07 | NOG |
| rs4711336 | rs2780226* | 6 | 33767024 | 540046 | 0.111 | 3×10-08 | 5×10-08 | HMGA1 |
| rs6892884 | rs12153391 | 5 | 170948228 | 187815 | 0 | 4×10-08 | 2×10-05 | FBXW11 |
| rs1367226 | rs3791675 | 2 | 55943044 | 21769 | 0.204 | 4×10-08 | 0.1245 | EFEMP1 |
| rs2421992 | rs17346452 | 1 | 170507874 | 187964 | 0.019 | 5×10-08 | 1×10-05 | DNM3 |
| rs225694 | rs7763064 | 6 | 142568835 | 270147 | 0.001 | 1×10-07 | 2×10-06 | GPR126 |
| rs10187066 | rs12470505 | 2 | 219223003 | 393610 | 0.022 | 2×10-07 | 5×10-08 | IHH |
| rs879882 | rs2256183 | 6 | 31247431 | 241077 | 0.016 | 2×10-07 | 8×10-08 | MICA |
Figure 2. Example of a locus with a secondary signal before (a) and after (b) conditioning.


The plot is centered on the conditioned SNP (purple diamond) at the locus. r2 is based on the CEU HapMap II samples. The blue line and right hand Y axis represent CEU HapMap II recombination rates. Created using LocusZoom (http://csg.sph.umich.edu/locuszoom/).
Whilst GWA studies have identified many variants robustly associated with common human diseases and traits, the biological significance of these variants, and the genes on which they act, is often unclear. We first tested the overlap between the 180 height-associated variants and two types of putatively functional variants, nonsynonymous (ns) SNPs and cis-eQTLs (variants strongly associated with expression of nearby genes). Height variants were 2.4-fold more likely to overlap with cis-eQTLs in lymphocytes than expected by chance (47 variants: _P_=4.7×10-11) (Supplementary Table 7) and 1.7-fold more likely to be closely correlated (_r_2≥0.8 in HapMap CEU) with nsSNPs (24 variants _P_=0.004) (Supplementary Methods, Supplementary Table 8). Although the presence of a correlated eQTL or nsSNP at an individual locus does not establish the causality of any particular variant, this enrichment shows that common functional variants contribute to the causal variants at height-associated loci. We also noted five loci where the height associated variant was strongly correlated (_r2_>0.8) with variants associated with other traits and diseases (P<5×10-8), including bone mineral density, rheumatoid arthritis, type 1 diabetes, psoriasis and obesity, suggesting that these variants have pleiotropic effects on human phenotypes (Supplementary Methods; Supplementary Table 9).
We next addressed the extent to which height variants cluster near biologically relevant genes; specifically, genes mutated in human syndromes characterized by abnormal skeletal growth. We limited this analysis to the 652 genes occurring within the recombination hotspot-bounded regions surrounding each of the 180 index SNPs. We showed that the 180 loci associated with variation in normal height contained 21 of 241 genes (8.7%) found to underlie such syndromes (Supplementary Table 10), compared to a median of 8 (range 1-19) genes identified in 1,000 matched control sets of regions (P<0.001: 0 observations of 21 or more skeletal growth genes among 1,000 sets of matched SNPs). In 13 of these 21 loci the closest gene to the most associated height SNP in the region is the growth disorder gene, and in 9 of these cases, the most strongly associated height SNP is located within the growth disorder gene itself (Supplementary Methods, Supplementary Table 11). These results suggest that GWA studies may provide more clues about the identity of the functional genes at each locus than previously suspected.
We also investigated whether significant and relevant biological connections exist between the genes within the 180 loci, using two different computational approaches. We used the GRAIL text-mining algorithm to search for connectivity between genes near the associated SNPs, based on existing literature20. Of the 180 loci, 42 contained genes that were connected by existing literature to genes in the other associated loci (the pair of connected genes appear in articles that share scientific terms more often than expected at P<0.01). For comparison, when we used GRAIL to score 1,000 sets of 180 SNPs not associated with height (but matched for number of nearby genes, gene proximity, and allele frequency), we only observed 16 sets with 42 or more loci with a connectivity P<0.01, thus providing strong statistical evidence that the height loci are functionally related (_P_=0.016) (Figure 3a). For the 42 regions with GRAIL connectivity P<0.01, the implicated genes and SNPs are highlighted in Figure 3b. The most strongly connected genes include those in the Hedgehog, TGF-beta, and growth hormone pathways.
Figure 3. Loci associated with height contain genes related to each other.
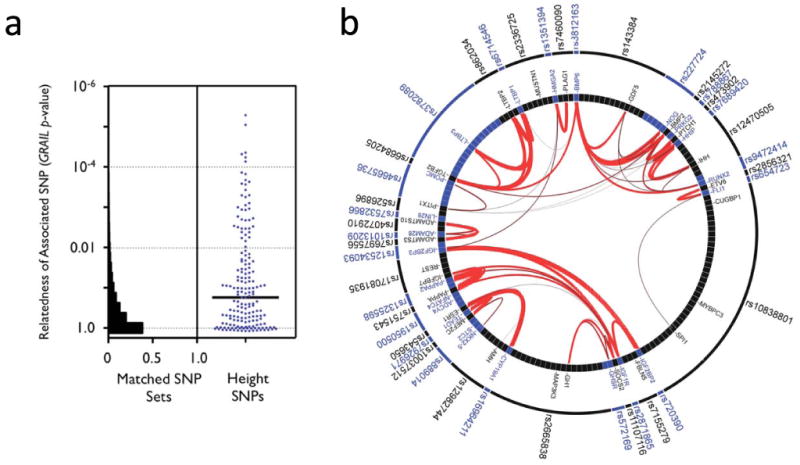
(a) 180 height-associated SNPs. The y-axis plots GRAIL _P_-values on a log scale. The histogram corresponds to the distribution of GRAIL _P_-values for 1,000 sets of 180 matched SNPs. The scatter plot represents GRAIL results for the 180 height SNPs (blue dots). The black horizontal line marks the median of the GRAIL _P_-values (_P_=0.14). The top 10 keywords linking the genes were: ‘growth’, ‘kinase’, ‘factor’, ‘transcription’, ‘signaling’, ‘binding’, ‘differentiation’, ‘development’, ‘insulin’, ‘bone’. (b) Graphical representation of the connections between SNPs and corresponding genes for the 42 SNPs with GRAIL P<0.01. Thicker and redder lines imply stronger literature-based connectivity.
As a second approach to find biological connections, we applied a novel implementation of gene set enrichment analysis (GSEA) (Meta-Analysis Gene-set Enrichment of variaNT Associations, MAGENTA21) to perform pathway analysis (Supplementary Methods). This analysis revealed 17 different biological pathways and 14 molecular functions nominally enriched (P<0.05) for associated genes, many of which lie within the validated height loci. These gene-sets include previously reported11,13 (e.g. Hedgehog signaling) and novel (e.g. TGF-beta signaling, histones, and growth and development-related) pathways and molecular functions (Supplementary Table 12). Several SNPs near genes in these pathways narrowly missed genome-wide significance, suggesting that these pathways likely contain additional associated variants. These results provide complementary evidence for some of the genes and pathways highlighted in the GRAIL analysis. For instance, genes such as TGFB2 and LTBP1-3 highlight a role for the TGF-beta signaling pathway in regulating human height, consistent with the implication of this pathway in Marfan syndrome22.
Finally, to examine the evidence for the potential involvement of specific genes at individual loci, we aggregated evidence from our data (eQTLs, proximity to the associated variant, pathway-based analyses), and human and mouse genetic databases (Supplementary Table 13). Of 32 genes with highly correlated (_r2_>0.8) nsSNPs, several are newly identified strong candidates for playing a role in human growth. Some are in pathways enriched in our study (such as ECM2, implicated in extracellular matrix), while others have similar functions to known growth-related genes, including FGFR4 (FGFR3 underlies several classic skeletal dysplasias23) and STAT2 (STAT5B mutations cause growth defects in humans24). Interestingly, Fgfr4-/- Fgfr3-/- mice show severe growth retardation not seen in either single mutant25, suggesting that the FGFR4 variant might modify _FGFR3_-mediated skeletal dysplasias. Other genes at associated loci, such as NPPC and NPR3 (encoding the C-type natriuretic peptide and its receptor), influence skeletal growth in mice and will likely also influence human growth17. Many of the remaining 180 loci have no genes with obvious connections to growth biology, but at some our data provide modest supporting evidence for particular genes, including C3orf63, PML, CCDC91, ZNFX1, ID4, RYBP, SEPT2, ANKRD13B, FOLH1, LRRC37B, MFAP2, SLBP, SOCS5, and ZBTB24 (Supplementary Table 13).
We have identified >100 novel loci that influence the classic polygenic trait of normal variation in human height, bringing the total to 180. Our results have potential general implications for genetic studies of complex traits. We show that loci identified by GWA studies highlight relevant genes: the 180 loci associated with height are non-randomly clustered within biologically relevant pathways and are enriched for genes that are involved in growth-related processes, that underlie syndromes of abnormal skeletal growth, and that are directly relevant to growth-modulating therapies (GH1, IGF1R, CYP19A1, ESR1). The large number of loci with clearly relevant genes suggests that the remaining loci could provide potential clues to important and novel biology.
We provide the strongest evidence yet that the causal gene will often be located near the most strongly associated DNA sequence variant. At the 21 loci containing a known growth disorder gene, that gene was on average 81 kb from the associated variant, and in over half of the loci it was the closest gene to the associated variant. Despite recent doubts about the benefits of GWA studies26, this finding suggests that GWA studies are useful mapping tools to highlight genes that merit further study. The presence of multiple variants within associated loci could help localize the relevant genes within these loci.
By increasing our sample size to >100,000 individuals, we identified common variants that account for approximately 10% of phenotypic variation. Although larger than predicted by some models26, this figure suggests that GWA studies, as currently implemented, will not explain a majority of the estimated 80% contribution of genetic factors to variation in height. This conclusion supports the idea that biological insights, rather than predictive power, will be the main outcome of this initial wave of GWA studies, and that new approaches, which could include sequencing studies or GWA studies targeting variants of lower frequency, will be needed to account for more of the “missing” heritability. Our finding that many loci exhibit allelic heterogeneity suggests that many as yet unidentified causal variants, including common variants, will map to the loci already identified in GWA studies, and that the fraction of causal loci that have been identified could be substantially greater than the fraction of causal variants that have been identified.
In our study, many associated variants are tightly correlated with common nsSNPs, which would not be expected if these associated common variants were proxies for collections of rare causal variants, as has been proposed27. Although a substantial contribution to heritability by less common and/or quite rare variants may be more plausible, our data are not inconsistent with the recent suggestion28 that a large number of common variants of very small effect mostly explain the regulation of height.
In summary, our findings indicate that additional approaches, including those aimed at less common variants, will likely be needed to dissect more completely the genetic component to complex human traits. Our results also strongly demonstrate that GWA studies can identify large numbers of loci that together implicate biologically relevant pathways and mechanisms. We envision that thorough exploration of the genes at associated loci through additional genetic, functional, and computational studies will lead to novel insights into human height and other polygenic traits and diseases.
Methods summary
The primary meta-analysis (Stage 1) included 46 GWA studies of 133,653 individuals. The in-silico follow up (Stage 2) included 15 studies of 50,074 individuals. All individuals were of European ancestry and >99.8% were adults. Details of genotyping, quality control, and imputation methods of each study are given in Supplementary Methods Table 1-2. Each study provided summary results of a linear regression of age-adjusted, within-sex Z scores of height against the imputed SNPs, and an inverse-variance meta-analysis was performed in METAL (http://www.sph.umich.edu/csg/abecasis/METAL/). Validation of selected SNPs was performed through direct genotyping in an extreme height panel (N=3,190) using Sequenom iPLeX, and in 492 Stage 1 samples using the KASPar SNP System. Family-based testing was performed using QFAM, a linear regression-based approach that uses permutation to account for dependency between related individuals29, and FBAT, which uses a linear combination of offspring genotypes and traits to determine the test statistic30. We used a previously described method to estimate the amount of genetic variance explained by the nominally associated loci (using significance threshold increments from P<5×10-8 to P<0.05)18. To predict the number of height susceptibility loci, we took the height loci that reached a significance level of P<5×10-8 in Stage 1 and estimated the number of height loci that are likely to exist based on the distribution of their effect sizes observed in Stage 2 and the power to detect their association in Stage 1. Gene-by-gene interaction, dominant, recessive and conditional analyses are described in Supplementary Methods. Empirical assessment of enrichment for coding SNPs used permutations of random sets of SNPs matched to the 180 height-associated SNPs on the number of nearby genes, gene proximity, and minor allele frequency. GRAIL and GSEA methods have been described previously20,21. To assess possible enrichment for genes known to be mutated in severe growth defects, we identified such genes in the OMIM database (Supplementary Table 10), and evaluated the extent of their overlap with the 180 height-associated regions through comparisons with 1000 random sets of regions with similar gene content (±10%).
Supplementary Material
1
Acknowledgments
A number of participating studies are members of CHARGE and ENGAGE consortia. We acknowledge funding from the Academy of Finland (104781, 117797, 120315, 121584, 126925, 129269, 129494, 129680, 213506); Affymetrix, Inc for genotyping services (N02-HL-6-4278); Agency for Science, Technology and Research of Singapore (A*STAR); ALF/LUA Gothenburg; Althingi (the Icelandic Parliament); Amgen; AstraZeneca AB; Australian National Health and Medical Research Council (241944, 389875, 389891, 389892, 389938, 442915, 442981, 496739, 496688, 552485, 613672); Australian Research Council (DP0770096); Biocentrum Helsinki; Boston Obesity Nutrition Research Center (DK46200); British Diabetes Association; British Heart Foundation (PG/02/128); British Heart Foundation Centre for Research Excellence, Oxford; CamStrad; Cancer Research UK; Centre for Neurogenomics and Cognitive Research (CNCR-VU); Chief Scientist Office of the Scottish Government (CSO) (CZB/4/279); Council of Health of the Academy of Finland; DIAB Core project of the German Network of Diabetes; Diabetes UK; Donald W. Reynolds Foundation; Emil and Vera Cornell Foundation; Erasmus MC; Estonian Government (SF0180142s08); European Commission (201413, ECOGENE:205419, BBMRI:212111, OPENGENE:245536, ENGAGE:HEALTH-F4-2007-201413, EURODIA:LSHG-CT-2004-518153, EU/WLRT-2001-01254, HEALTH-F2-2008-ENGAGE, HEALTH-F4-2007-201550, LSH-2006-037593, LSHG-CT-2006-018947, LSHG-CT-2006-01947, Procardis:LSHM-CT-2007-037273, POLYGENE:LSHC-CT-2005, QLG1-CT-2000-01643, QLG2-CT-2002-01254, DG XII, Marie Curie Intra-European Fellowship); Eve Appeal; Finish Ministry of Education; Finnish Diabetes Research Foundation; Finnish Diabetes Research Society; Finnish Foundation for Cardiovascular Research; Finnish Medical Society; Finska Läkaresällskapet; Folkhälsan Research Foundation; Fondation LeDucq; Foundation for Life and Health in Finland; Foundation for Strategic Research (SSF); GEN-AU-Programme “GOLD”; Genetic Association InformationNetwork (GAIN); German Bundesministerium fuer Forschung und Technology (01 AK 803 A-H, 01 IG 07015 G); German Federal Ministry of Education and Research (BMBF) (01GS0831); German Ministry for Health, Welfare and Sports; German Ministry of Cultural Affairs; German Ministry of Education, Culture and Science; German National Genome Research Net (NGFN2 and NGFNplus) (01GS0823, 01ZZ0103, 01ZZ0403, 01ZZ9603, 03ZIK012); German Research Council (KFO-152); GlaxoSmithKline; Göteborg Medical Society; Gyllenberg Foundation; Helmholtz Center Munich; Juvenile Diabetes Research Foundation International (JDRF) (U01 DK062418); Karolinska Institute; Knut and Alice Wallenberg Foundation; Lundberg Foundation; March of Dimes (6-FY-09-507); MC Health; Medical Research Council UK (G0000649, G0000934, G0500539, G0600331, G0601261, G9521010D, PrevMetSyn); Microarray Core Facility of the Interdisciplinary Centre for Clinical Research (IZKF) (B27); Mid-Atlantic Nutrition and Obesity Research Center of Maryland (P30 DK072488); Ministry of Health and Department of Educational Assistance (South Tyrol, Italy); Ministry of Science, Education and Sport of the Republic of Croatia (216-1080315-0302); Montreal Heart Institute Foundation; Närpes Health Care Foundation; National Institute for Health Research (NIHR) Cambridge Biomedical Research Centre; NIHR Oxford Biomedical Research Centre; NIHR comprehensive Biomedical Research Centre; National Institutes of Health (263-MA-410953, AA014041, AA07535, AA10248, AA13320, AA13321, AA13326, CA047988, CA49449, CA50385, CA65725, CA67262, CA87969, DA12854, DK062370, DK063491, DK072193, DK079466, DK080145, DK58845, HG002651, HG005214, HG005581, HL043851, HL084729, HL69757, HL71981, K08-AR055688, K23-DK080145, K99-HL094535, M01-RR00425, MH084698, N01-AG12100, N01-AG12109, N01-HC15103, N01-HC25195, N01-HC35129, N01-HC45133, N01-HC55015, N01-HC55016, N01-HC55018 through N01-HC55022, N01-HC55222, N01-HC75150, N01-HC85079 through N01-HC85086, N01-HG65403, R01-AG031890, R01 CA104021, R01-DK068336, R01-DK073490, R01-DK075681, R01-DK075787, R01-HL086694, R01-HL087641, R01-HL087647, R01-HL087652, R01-HL087676, R01-HL087679, R01-HL087700, R01-HL088119, R01-HL59367, R01-MH059160, R01-MH59565, R01-MH59566, R01-MH59571, R01-MH59586, R01-MH59587, R01-MH59588, R01-MH60870, R01-MH60879, R01-MH61675, R01-MH63706, R01-MH67257, R01-MH79469, R01-MH81800, RL1-MH083268, T32-HG00040, U01-CA098233, U01-GM074518, U01-HG004399, U01-HG004402, U01-HL080295, U01-HL084756, U01-HL72515, U01-MH79469, U01-MH79470, U54-RR020278, UL1-RR025005, Z01-AG00675, Z01-AG007380, Z01-HG000024; contract HHSN268200625226C; ADA Mentor-Based Postdoctoral Fellowship; Pew Scholarship for the Biomedical Sciences); Netherlands Genomics Initiative (NGI)/Netherlands Consortium for Healthy Aging (NCHA) (050-060-810); Netherlands Organisation for Scientific Research (NWO) (Investments nr. 175.010.2005.011, 911-03-012); Netherlands Organization for the Health Research and Development (ZonMw) (10-000-1002); Netherlands Scientific Organization (904-61-090, 904-61-193, 480-04-004, 400-05-717, Center for Medical Systems Biology (NOW Genomics), SPI 56-464-1419); NIA Intramural Research Program; Nordic Center of Excellence in Disease Genetics; Novo Nordisk Foundation; Ollqvist Foundation; Oxford NIHR Biomedical Research Centre; Paavo Nurmi Foundation; Perklén Foundation; Petrus and Augusta Hedlunds Foundation; Queensland Institute of Medical Research; Radboud University Nijmegen Medical Centre; Research Institute for Diseases in the Elderly (014-93-015); Royal Swedish Academy of Science; Sahlgrenska Center for Cardiovascular and Metabolic Research (A305:188); Siemens Healthcare, Erlangen, Germany; Signe and Ane Gyllenberg Foundation; Sigrid Juselius Foundation; Social Insurance Institution of Finland; Social Ministry of the Federal State of Mecklenburg-West Pomerania; South Tyrolean Sparkasse Foundation; Stockholm County Council (560183); Support for Science Funding programme; Susan G. Komen Breast Cancer Foundation; Swedish Cancer Society; Swedish Cultural Foundation in Finland; Swedish Foundation for Strategic Research; Swedish Heart-Lung Foundation; Swedish Medical Research Council (K2007-66X-20270-01-3, 8691); Swedish National Cancer Institute; Swedish Research Council; Swedish Society of Medicine; Swiss National Science Foundation (33CSCO-122661); Torsten and Ragnar Söderberg's Foundation; Vandervell Foundation; Västra Götaland Foundation; Wellcome Trust (072960, 075491, 079557, 079895, 083270, 068545/Z/02, 076113/B/04/Z, 076113/C/04/Z, 076113/C/04/Z, 077016/Z/05/Z, 081682/Z/06/Z, 084183/Z/07/Z, 085301/Z/08/Z, 086596/Z/08/Z, 091746/Z/10/Z; WT Research Career Development Fellowship); Western Australian Genetic Epidemiology Resource and the Western Australian DNA Bank (both National Health and Medical Research Council of Australia Enabling Facilities). Detailed list of acknowledgments by study is given in the Supplementary Information.
Footnotes
Author Contributions: Full author contributions and roles are listed in the Supplementary Information.
References
- 1.Hindorff LA, et al. Potential etiologic and functional implications of genome-wide association loci for human diseases and traits. Proc Natl Acad Sci U S A. 2009;106:9362–7. doi: 10.1073/pnas.0903103106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Galton F. Regression towards mediocrity in hereditary stature. J R Anthropol Inst. 1885;5:329–348. [Google Scholar]
- 3.Fisher RA. The Correlation Between Relatives on the Supposition of Mendelian Inheritance. Transactions of the Royal Society of Edinburgh. 1918;52:399–433. [Google Scholar]
- 4.Frazer KA, et al. A second generation human haplotype map of over 3.1 million SNPs. Nature. 2007;449:851–61. doi: 10.1038/nature06258. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Devlin B, Roeder K. Genomic control for association studies. Biometrics. 1999;55:997–1004. doi: 10.1111/j.0006-341x.1999.00997.x. [DOI] [PubMed] [Google Scholar]
- 6.Reich DE, Goldstein DB. Detecting association in a case-control study while correcting for population stratification. 2001;20:4–16. doi: 10.1002/1098-2272(200101)20:1<4::AID-GEPI2>3.0.CO;2-T. [DOI] [PubMed] [Google Scholar]
- 7.Campbell CD, et al. Demonstrating stratification in a European-American population. Nature Genet. 2005;37:868–872. doi: 10.1038/ng1607. [DOI] [PubMed] [Google Scholar]
- 8.Manolio TA, et al. Finding the missing heritability of complex diseases. Nature. 2009;461:747–53. doi: 10.1038/nature08494. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Visscher PM, et al. Assumption-Free Estimation of Heritability from Genome-Wide Identity-by-Descent Sharing between Full Siblings. PLoS Genet. 2006;2:e41. doi: 10.1371/journal.pgen.0020041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Weedon MN, et al. A common variant of HMGA2 is associated with adult and childhood height in the general population. Nat Genet. 2007;39:1245–1250. doi: 10.1038/ng2121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Weedon MN, et al. Genome-wide association analysis identifies 20 loci that influence adult height. Nat Genet. 2008;40:575–83. doi: 10.1038/ng.121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Sanna S, et al. Common variants in the GDF5-UQCC region are associated with variation in human height. Nat Genet. 2008;40:198–203. doi: 10.1038/ng.74. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Lettre G, et al. Identification of ten loci associated with height highlights new biological pathways in human growth. Nat Genet. 2008;40:584–91. doi: 10.1038/ng.125. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Soranzo N, Rivadeneira F, Chinappen-Horsley U, Malkina I. Meta-analysis of genome-wide scans for human adult stature in humans identifies novel loci and associations with measures of skeletal frame size. PLoS Genet. 2009;5:e1000445. doi: 10.1371/journal.pgen.1000445. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Gudbjartsson DF, et al. Many sequence variants affecting diversity of adult human height. Nat Genet. 2008;40:609–15. doi: 10.1038/ng.122. [DOI] [PubMed] [Google Scholar]
- 16.Johansson A, et al. Common variants in the JAZF1 gene associated with height identified by linkage and genome-wide association analysis. Hum Mol Genet. 2009;18:373–80. doi: 10.1093/hmg/ddn350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Estrada K, et al. A genome-wide association study of northwestern Europeans involves the C-type natriuretic peptide signaling pathway in the etiology of human height variation. Hum Mol Genet. 2009;18:3516–24. doi: 10.1093/hmg/ddp296. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Purcell SM, et al. Common polygenic variation contributes to risk of schizophrenia and bipolar disorder. Nature. 2009;460:748–52. doi: 10.1038/nature08185. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Park JH, et al. Estimation of effect size distribution from genome-wide association studies and implications for future discoveries. Nat Genet. 2010;42:570–5. doi: 10.1038/ng.610. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Raychaudhuri S, et al. Identifying relationships among genomic disease regions: predicting genes at pathogenic SNP associations and rare deletions. PLoS Genet. 2009;5:e1000534. doi: 10.1371/journal.pgen.1000534. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Segrè AV, et al. Common Inherited Variation in Mitochondrial Genes is not Enriched for Associations with Type 2 Diabetes or Related Glycemic Traits. PLoS Genet. 2010 doi: 10.1371/journal.pgen.1001058. In Press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Neptune ER, et al. Dysregulation of TGF-beta activation contributes to pathogenesis in Marfan syndrome. Nat Genet. 2003;33:407–11. doi: 10.1038/ng1116. [DOI] [PubMed] [Google Scholar]
- 23.Superti-Furga A, Unger S. Nosology and classification of genetic skeletal disorders: 2006 revision. Am J Med Genet A. 2007;143:1–18. doi: 10.1002/ajmg.a.31483. [DOI] [PubMed] [Google Scholar]
- 24.Kofoed EM, et al. Growth hormone insensitivity associated with a STAT5b mutation. N Engl J Med. 2003;349:1139–47. doi: 10.1056/NEJMoa022926. [DOI] [PubMed] [Google Scholar]
- 25.Weinstein M, Xu X, Ohyama K, Deng CX. FGFR-3 and FGFR-4 function cooperatively to direct alveogenesis in the murine lung. Development. 1998;125:3615–23. doi: 10.1242/dev.125.18.3615. [DOI] [PubMed] [Google Scholar]
- 26.Goldstein DB. Common genetic variation and human traits. N Engl J Med. 2009;360:1696–8. doi: 10.1056/NEJMp0806284. [DOI] [PubMed] [Google Scholar]
- 27.Dickson SP, Wang K, Krantz I, Hakonarson H, Goldstein DB. Rare variants create synthetic genome-wide associations. PLoS Biol. 2010;8:e1000294. doi: 10.1371/journal.pbio.1000294. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Yang J, et al. Common SNPs explain a large proportion of the heritability for human height. Nat Genet. 2010;42:565–9. doi: 10.1038/ng.608. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Purcell S, et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet. 2007;81:559–75. doi: 10.1086/519795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Laird NM, Horvath S, Xu X. Implementing a unified approach to family-based tests of association. Genet Epidemiol. 2000;19(1):S36–42. doi: 10.1002/1098-2272(2000)19:1+<::AID-GEPI6>3.0.CO;2-M. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
1