Systematic Identification of Gene Families for Use as “Markers” for Phylogenetic and Phylogeny-Driven Ecological Studies of Bacteria and Archaea and Their Major Subgroups (original) (raw)
Abstract
With the astonishing rate that genomic and metagenomic sequence data sets are accumulating, there are many reasons to constrain the data analyses. One approach to such constrained analyses is to focus on select subsets of gene families that are particularly well suited for the tasks at hand. Such gene families have generally been referred to as “marker” genes. We are particularly interested in identifying and using such marker genes for phylogenetic and phylogeny-driven ecological studies of microbes and their communities (e.g., construction of species trees, phylogenetic based assignment of metagenomic sequence reads to taxonomic groups, phylogeny-based assessment of alpha- and beta-diversity of microbial communities from metagenomic data). We therefore refer to these as PhyEco (for phylogenetic and phylogenetic ecology) markers. The dual use of these PhyEco markers means that we needed to develop and apply a set of somewhat novel criteria for identification of the best candidates for such markers. The criteria we focused on included universality across the taxa of interest, ability to be used to produce robust phylogenetic trees that reflect as much as possible the evolution of the species from which the genes come, and low variation in copy number across taxa.
We describe here an automated protocol for identifying potential PhyEco markers from a set of complete genome sequences. The protocol combines rapid searching, clustering and phylogenetic tree building algorithms to generate protein families that meet the criteria listed above. We report here the identification of PhyEco markers for different taxonomic levels including 40 for “all bacteria and archaea”, 114 for “all bacteria (greatly expanding on the ∼30 commonly used), and 100 s to 1000 s for some of the individual phyla of bacteria. This new list of PhyEco markers should allow much more detailed automated phylogenetic and phylogenetic ecology analyses of these groups than possible previously.
Introduction
In the 1970s, pioneering studies were carried out by Carl Woese and colleagues to analyze the sequences of fragments of rRNA genes [1], [2], [3]. They demonstrated that by analyzing the sequence information found in the small subunit rRNA (ssu-rRNA), we can place the diverse cellular organisms in a tree of life. The ssu-rRNA also led Woese et. al. to propose the existence of the Archaea, the so-called third domain of life in addition to the already known Bacteria and Eukaryotes. Since then, ssu-rRNA has been widely adopted as a “_phylogenetic marker_” for studies of diverse living organisms. The ssu-rRNA gene has many advantages to play such a role. It is present universally in all cellular organisms. The sequences of ssu-rRNA have desirable patterns such as diverse regions separated by highly conserved regions. The conservation at the sequence and structure level facilitate the studies that require sequence alignments, while sequence variations provide valuable information for analysis of both recent and ancient evolutionary events.
Since (and even before) the time of Woese's work on rRNA, other genes have been developed into widely used and robust phylogenetic markers for various taxa. However for global studies of microorganisms, ssu-rRNA genes are still the phylogenetic marker of choice. A related topic to general studies of the phylogeny of microbes is that for a long time, scientists only studied cultured microbial organisms and left out the overwhelming majority that could not be cultured in the lab. A fundamental shift occurred when researchers started examining rRNA genes from organisms never grown in the lab. This work accelerated in particular when the polymerase chain reaction (PCR) methodology was adapted to ssu-rRNA studies. The highly conserved regions of the ssu-rRNA allow one to design oligonucleotide primers to amplify the ssu-rRNA genes by PCR for a diverse range of species. Using “universal primers” in PCR, scientists can amplify ssu-rRNA from a wide variety of taxa directly from the environment in a single reaction. The culture-independent PCR amplification and sequencing of ssu-rRNA from an unprecedented variety of communities is enriching ssu-rRNA sequence collections exponentially. By the start of 2012, the SILVA ssu-rRNA database has reached 2,492,653 sequences, while the RDP database has included 2,110,258 ssu-rRNA sequences. With next generation sequencing there are also billions if not trillions of available partial ssu-rRNA sequences. Thus in addition to its use as a phylogenetic marker, ssu-rRNA became a key “ecological marker” for studies of microbes.
Despite the power and ongoing potential of ssu-rRNA based studies of microbial diversity, using this gene – or just this gene – has its limitations. For example, the extensive variation in copy number of ssu-rRNA genes among different organisms poses major challenges for using ssu-rRNA as an ecological marker [12], [13], [14]. This is because researchers try to use counts of the number of sequences retrieved from a particular group to estimate relative abundance of such groups. Although methods have been developed to try and correct for the variance in rRNA copy number, but they are imperfect. Another limitation of ssu-rRNA only studies is that all so-called “universal primers” for PCR amplification of ssu-RNA genes have different degrees of bias — they usually prefer certain taxonomic groups over others. In addition, phylogenetic trees built from one gene do not always reflect the true evolution history of species under study. Any gene, including ssu-rRNA, is subject to horizontal gene transfer, convergent evolution, or evolution rate variations between different phylogenetic groups [16], [17], [18] and other forces that can lead to the trees of that gene not accurately reflecting the history of species.
Over the years researchers have attempted to identify, develop and use other marker genes to for microbial diversity studies to compensate for the limitations of ssu-RNA genes as markers. One example is the recombinase A gene family that includes bacterial RecA, archaea RadA and RadB, eukaryotic Rad51 and Rad57, phage UvsX. The genes in the recA superfamily are crucial for recombination and DNA repair, are nearly universally present, and have (compared to ssu-rRNA) low variation in copy number between taxa. Another example is RNA polymerase beta subunit (RpoB) gene, which is responsible for transcription initiation and elongation [24], [25], [26]. Both genes have been widely used in phylogenetic studies of bacteria, archaea, and eukaryota. In terms of use as phylogenetic markers, protein-coding genes have some advantages over ssu-rRNA including that they may have less (or at least different) nucleotide compositional bias than ssu-rRNAs.
There are two major challenges for using protein-coding genes as phylogenetic markers for broad studies of microbial diversity. First, PCR amplification technology, which is the driving force behind using ssu-rRNA for microbial diversity studies, does not work as easily for protein coding genes. This is because DNA level variations can be observed even for highly conserved protein domains at the amino acid level. On one hand, such DNA level variations are valuable for the studies of closely related organisms; on the other hand, the primers for PCR amplification of these genes need to be degenerate, sometimes extremely so. Thus phylogenetic analysis of protein-coding genes has largely focused on cultured organisms because of the limited ability to sequence such genes from unknown organisms using PCR-based methods. Metagenomics, the direct sequencing of the organisms present in the environmental samples without PCR, has made protein based phylogenetic analysis and phylogeny-driven ecological analysis of uncultured organisms feasible.
In general, metagenomics is opening up the possibility that any gene can be used for studies of microbial diversity. However, one challenge in this is the lack of knowledge about what genes are suitable for such studies. For broad studies of microbial diversity (e.g., studies of the diversity of all bacteria in metagenomic data or whole-genome phylogenetics of all bacteria) the most widely used sets of genes include about 30 genes (e.g., 31 in and).
Though the previously identified marker gene sets are useful, we became interested in revisiting marker gene identification and in developing and using a system that would be updated in multiple areas. Some of the key limitations in the previously identified marker sets included that they were selected when only a small number of genomes were available, the methods behind their identification were not fully automated, the sets were focused on the highest level taxonomic groups and thus missed genes that could be useful for more narrow focus on specific subgroups of bacteria or archaea and the sets were focused largely on markers for phylogenetic studies not for phylogeny-driven ecological studies.
We report here the development of an automated approach to identify phylogenetic and phylogenetic ecology markers (we refer to these “PhyEco” markers). Our approach takes a set of complete genome sequences and applies a variety of criteria for assessing the gene families present in those genomes for their potential use as PhyEco markers. The criteria we use includes universality across the taxa of interest (which is important for multiple reasons), ability to be used to produce robust phylogenetic trees that reflect as much as possible the evolution of the species from which the genes come (which helps control for issues like convergent evolution and lateral gene transfer), and low variation in copy number across taxa (which is advantageous when using markers for estimates of relative abundance of taxa). The protocol takes all the proteins in all the genomes under consideration and, using rapid searching and clustering algorithms, generates protein families from that complete protein set. Phylogenetic trees are then built for each family, and subgroups in the trees (i.e., clades) are automatically sampled and evaluated for the criteria listed above. Potential PhyEco marker families are then further assessed using multiple comparative and phylogenetic analyses.
Our systematic approach reveals 40 PhyEco marker candidates spanning the domains of bacteria and archaea. Our analysis also identified 74 bacterial specific PhyEco markers, which, with the 40 bacterial and archaeal markers, brings the total to 114 PhyEco markers that can be used for analysis of bacteria. In addition, our analysis revealed 100 s – 1000 s of phyla-specific PhyEco marker genes. Recently, a paper was published from Wang and Wu describing a similar approach to identify taxa specific phylogenetic markers at the phylum level. Our methods are different than those used by Wang and Wu and our results also have differences. We discuss some of the similarities and differences in more detail in the Results and Discussion section. Most importantly, we believe the new list of PhyEco markers we have identified should allow much more detailed automated phylogenetic and phylogenetic ecology analyses of these groups than possible previously.
Results and Discussion
De novo identification of protein families from massive and ever increasing genome data sets by a bottom up approach
For our study here we decided that it was important to first perform a de novo build of protein families from currently available genome data sets (i.e., we did not want to rely on existing protein family information). Largely we chose this approach because of concerns about the possibility of bias in the existing protein family data sets related to their being created and built when the sampling of genomes was phylogenetically very limited. To carry out a de novo identification of protein families we would first need to search all the proteins from all the genomes of interest against each other (e.g., by using an all vs. all BLAST search). Then we would need to group these proteins into families based on the results of such searches. Given the large number of genomes available for bacteria and archaea, such all vs. all searching and then clustering would be computationally very intensive. Furthermore, we wanted to be able to do such a de novo build again and again in some sort of automated manner as more genomes became available. Such an accelerating and increasing costly approach was not possible within the scope of this project. The computational infrastructure we had available for this work could comfortably handle de novo gene family building and analysis for ∼200 bacterial and/or archaeal genomes at a time.
The limitation outlined above led us to develop a “bottom up” strategy for identifying PhyEco markers. This strategy worked in the following general way: the total set of genomes was divided into subgroups based on phylogeny and taxonomy of the species from which the genomes came. In most cases subgroups corresponded to phyla. However, there were too many genomes for some phyla (e.g., proteobacteria) and thus we further subdivided the group (in the case of the proteobacteria we divided it into the five major classes – alpha, beta, gamma, delta and epsilon). Then for each of these subgroups we carried out all vs. all searches using BLASTP of the proteins encoded in the genomes. Following this, for each subgroup we used the results of the all vs. all search to create protein families using the MCL clustering algorithm.
The use of MCL for gene family building has some advantages and disadvantages. The main advantages relate to speed and ability to control the granularity of the output clustering. However this comes with a risk of splitting up what should be single families into separate clusters. To compensate (at least somewhat) for this risk of splitting, after the MCL clustering is run, the left over sequences are clustered using a more aggressive single linkage clustering method. This allows the recovery of some additional protein families that were artificially split by the MCL method.
Identifying PhyEco markers from protein family sets
To identify PhyEco markers we screened through the complete protein family data sets using four criteria: universality, evenness (in copy number), monophyly and uniqueness. We selected these specific metrics for multiple reasons. Universality (how widely found the gene family is for a group in question) is important for phylogenetic studies because the more universal (for a particular group) a gene is, the less missing data one would have in a data set for phylogenetic analysis. For ecological studies, universality is important because it allows one to assume that if a representative of that taxonomic group were present it would be likely to have that particular gene. Evenness in copy number is important in particular in the estimation of the relative abundance of taxa in environments. Regarding “monophyly”, what we wanted to do was develop a metric that would allow us to identify those cases where the genes from the taxonomic group in question were monophyletic in the phylogenetic tree for the whole family. For example consider a hypothetical protein family “A” being screened PhyEco marker potential for the Cyanobacteria. We wanted to know, in a phylogenetic tree including all homologs of protein family A, if the proteins from Cyanobacteria all grouped together as a single clade. In order to identify PhyEco markers that captured our current understanding of phylogenetic/taxonomic structure of bacteria and archaea, we examine phylogenetic trees to make sure they are monophyletic for the phyla and classes that are regarded as monophyletic based on previous phylogenetic studies (e.g.,). Finally, we developed a “uniqueness” test as a way to measure how well we were able to distinguish members of the PhyEco marker family of interest from other families. This test is based on how we currently search for members of a particular family in a genomic or metagenomic data set. We do this by creating a hidden markov model (HMM) representing a sequence alignment of the family, and then we search the data sets of interest for sequences in the family using the HMM. A family's HMM (and thus the family) is determined to be unique if a HMM search against all families retrieves all the target family members as top hits with a comfortable distance from sequences in other families.
For identification of PhyEco markers for each of the subgroups we used these metrics in a mostly qualitative manner. For a protein family to be included in the list for a group, it had to be present in all members of the group (universal) in a single copy (even). This was a very strict set of criteria to use. In the future we will likely have to relax this approach a bit as more and more genomes that are incomplete become available but could be useful to include.
After PhyEco marker families have been identified for each subgroup, we then coalesce them together to identify PhyEco markers for the “higher” taxonomic levels. For example the families in the different classes of proteobacteria were compared to identify proteobacteria-wide PhyEco marker families. In addition, the PhyEco markers for each of the bacterial phyla were compared to identify bacterial-wide PhyEco markers. The comparison across subgroups is done in the following way. Consensus sequences are generated for each PhyEco marker family for each subgroup. These are then all compared to each other and clustered using single-linkage clustering to identify which subgroup specific PhyEco marker families are related to each other (see Methods for more detail). Once we coalesced together the families from the lower levels we then scored candidate PhyEco families for the “higher” levels using measures of universality, evenness and monophyly with quantitative metrics for each as described in the Methods.
As mentioned in the Introduction, a recent paper from Wang and Wu is similar to our work described here in a few ways. The focus on their work is similar in that they also attempted to identify taxa specific phylogenetic markers at the phylum level. One similarity is that we both attempted to identify genes that were universal and had low variance in copy number between taxa. Specifically, Wang and Wu focused on identifying “ubiquitous, single-copy genes.” One key difference is we have introduced formal metrics for assessing marker genes in multiple parameters: universality (analogous to their ubiquity but with a more formal mathematical measurement), evenness in copy number (which is similar to their search for single-copy genes in that any gene that is single-copy in everything would have a high evenness score) and monophyly. Our assessment of monophyly is a way to characterize the evolutionary history of a gene family. Wang and Wu also attempted to assess the evolutionary history of a gene family by using the Prunier program [37] to search for cases of possible lateral gene transfer. Our approaches in terms of evolutionary history were very different here though the goals are similar in ways. Another difference between our work and that of Wang and Wu is that our metrics allow us to explicitly evaluate and rank potential markers in the context of all currently available bacteria and archaeal genome sequences (and we present the results of such evaluation – see below). Other differences between our approach and theirs include that we make use of a “uniqueness” metric to determine how different one family is from other families. Thus, we believe our study provides a clearer quantitative picture of the characteristics of the PhyEco markers.
We are experimenting with another strategy to avoid large-scale de novo gene family building in the future. We have been involved in creating a database of gene families for all the sequenced genomes called SFAMs with an updating protocol that adds future sequences into existing gene families and only builds novel gene families if necessary [38]. In theory, this database could be used directly and the families could be screened for criteria of interest (such as universality, evenness, uniqueness, and monophyly) for any taxonomic group of interest.
A diverse sampling of a taxonomic group is essential for PhyEco marker identification
For the analyses reported here, we focused only on phylogenetic groups for which a large number of complete genome sequences were available. Specifically, we considered the following taxonomic groups: “all bacteria and archaea”, “all bacteria”, “all archaea”, each phylum of bacteria for which there were more than a few genomes (there were generally not enough genomes for specific archaeal phyla to subdivide the archaea up), and the classes within the proteobacteria phylum (there are many genomes for each class due to biases in genome sequencing efforts).
We have identified taxonomic group-specific PhyEco marker candidates systematically for 17 taxonomic groups (Table 1). The number of candidate PhyEco markers varies for different taxonomic groups: e.g., the Deinococcus-Thermus phylum has 974 PhyEco markers, while Firmicutes has only 87. Because of the low number of genomes and low phylogenetic diversity at the phyla level, Deinococcus-Thermus, Thermotogae and Chlamydiae have exceptionally high number of PhyEco markers (the fewer genomes the less likely there is to have something unusual in one of the genomes that would remove a gene from our list – and the lower the phylogenetic diversity the more genes there will be that are shared). Taxonomic groups with more genomes and higher phylogenetic diversity tend to have fewer PhyEco marker genes using our criteria. The most diverse groups have about 100, they can be regarded as “core” genes that are relatively resistant to gene duplication, deletions and transfer [39], [40], [41]. We have identified 560 PhyEco markers for Cyanobacteria, an extraordinary large number for such a phylogenetic diverse group. The presence of many photosynthesis related genes contributes to the large number [41]. Certain lineages, such as Gammaproteobacteria, have such large numbers of genomes from a limited number of species that we have to use phylogenetic trees to select and effectively reduce the number of genomes to facilitate de novo gene family building. But for most phyla of bacteria and archaea, more genome sequences are in order to more accurately identify good PhyEco markers. Efforts such as the phylogeny-driven Genomic Encyclopedia of Bacteria and Archaea (GEBA) project which focuses on cultured organisms and culture independent genome sampling efforts [42], [43] would be very beneficial to continue in relation to PhyEco marker identification.
Table 1. Summary of taxonomic group-specific PhyEco marker candidates.
| Taxonomic group | Genome Number | Gene Number | PD Coverage | Monophyletic Value | PhyEco Marker Candidates |
|---|---|---|---|---|---|
| Bacteria and Archaea | 666 | 2,271,359 | 82.70 | NA | 40 |
| Archaea | 62 | 145,415 | 12.15 | 100.00 | 106 |
| Bacteria | 604 | 2,125,944 | 69.23 | 100.00 | 114 |
| Actinobacteria | 63 | 267,783 | 6.84 | 100.00 | 136 |
| Bacteroides | 25 | 71,531 | 5.12 | 100.00 | 286 |
| Chlamydiae | 13 | 13,823 | 0.69 | 100.00 | 560 |
| Chloroflexi | 10 | 33,577 | 2.66 | 100.00 | 323 |
| Cyanobacteria | 36 | 124,080 | 2.88 | 100.00 | 590 |
| Deinococcus-Thermus | 5 | 14,160 | 0.98 | 100.00 | 974 |
| Firmicutes | 106 | 312,309 | 13.49 | 88.70 | 87 |
| Spirochaetes | 18 | 38,832 | 2.68 | 100.00 | 176 |
| Thermotogae | 9 | 17,037 | 1.60 | 100.00 | 684 |
| Alphaproteobacteria | 94 | 347,287 | 8.66 | 100.00 | 121 |
| Betaproteobacteria | 56 | 266,362 | 3.71 | 100.00 | 311 |
| Gammaproteobacteria | 126 | 483,632 | 10.63 | 79.67 | 118 |
| Deltaproteobacteria | 25 | 102,115 | 4.42 | 100.00 | 206 |
| Epsilonproteobacteria | 18 | 33,416 | 2.43 | 100.00 | 455 |
Properties of the “All Bacteria and Archaea” PhyEco marker set
Our analysis identified 40 PhyEco markers for the group “all bacteria and archaea” (Table 1). We have assessed these markers in a few ways. First, examination of phylogenetic trees of each of these PhyEco markers shows that for each, Archaea and Bacteria form two distinctive clades (Figure 1). In addition, we examined the properties of each of these markers within the lower taxonomic groups in our data set. For example, one of the “all Bacteria and Archaea” PhyEco markers corresponds to ribosomal protein S2. For all 18 of the taxonomic groups examined in our analysis (e.g., all Bacteria, all Archaea, and the major bacterial subgroups) this protein also showed up as PhyEco marker. All organisms have a single copy of ribosomal protein S2 gene, and each of the 18 taxonomic group forms a monophyletic clade in the family phylogenetic tree. All the other 39 “all bacteria and archaea” PhyEco markers were identified as PhyEco markers at a minimum of seven taxonomic levels (Figure 1). These results are not overly surprising since we inferred the “all bacteria and archaea” markers by building up from the lower levels. But in theory it is possible that something would not work in this approach. For our “building up” method might not work as we expected. In addition, there might be more conflicts that we expect between taxonomy (which is largely on ssu-rRNA phylogeny) and protein family phylogeny. Another key feature of the “all bacteria and archaea” PhyEco markers is their functional roles in organisms. The vast majority of them are associated with the translation processes (Table 1): 30 ribosomal protein subunit genes, 1 translation initial factor, 1 translation elongation factor, and 3 rRNA synthesis related genes. The rest of are involved in protein metabolism including peptide degradation and exporting, RNA degradation, heme biosynthesis and purine nucleotide synthesis.
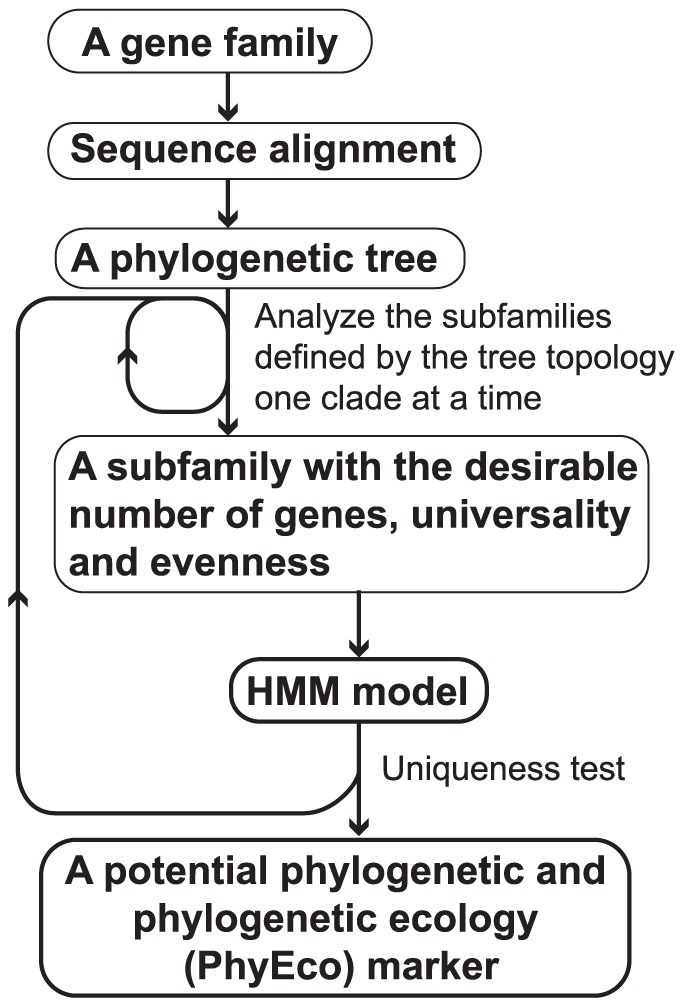
Figure 1. Flow chart of the PhyEco marker identification pipeline.
Properties of the “All Bacteria” PhyEco marker set
Our analysis identified 74 PhyEco markers for the group “all bacteria.” As with the “all bacteria and archaea” PhyEco markers we assessed these in a variety of ways. As expected, all 74 have very low variance in copy number between bacterial genomes and almost all are present in only a single copy in all bacterial genomes. Interestingly, many have no obvious counterpart in archaea (Figure 2). In terms of lower taxonomic groups (in this case – the subgroups within the bacteria), each of the 74 “all bacteria” PhyEco markers was also identified as a PhyEco marker for at least six taxonomic groups (Figure 2). Similar to the “all archaea and bacteria” markers, translation related gene families dominate the list of “all bacteria” markers (Table S1): fourteen are ribosomal protein genes; ten are related to tRNA synthesis and modification; three are involved in translation initiation, elongation and termination; others are for ribosome rescue and recycle, and small subunit rRNA processing. DNA replication and repair related gene families are abundant in the list: four families are related to DNA synthesis and twelve are involved in DNA repair. Others of these bacterial PhyEco marker gene families are involved in transcription, RNA degradation, protein trafficking and degradation, cell division and shaping and signal transduction. Various biosynthesis related families are also included in the PhyEco markers, including the synthesis of cofactors, peptidoglycan, pyrimidine, fatty acid and heme. Interestingly, three of the “all bacteria” PhyEco marker candidates have no functional annotation and apparently have not been studied functionally even though their distribution patterns among the bacterial genomes strongly suggest that they are potentially involved in essential processes.
Figure 2. The universality, evenness and monophyletic value of the 40 Bacterial/Archaeal PhyEco marker candidates in different taxonomic groups.

PhyEco marker genes for the taxonomic groups are highlighted with white boxes.
The automated pipeline for phylogenomic analysis AMPHORA (co-developed by one of us) included 31 phylogenetic markers for bacteria according to previous experiments. We are glad to see 30 of the original 31 AMPHORA markers are included in our list of PhyEco markers: 18 are included in the “bacteria and archaea” PhyEco markers, while twelve are included the “all bacteria” PhyEco markers (Table 2, Table S1). The only AMPHORA marker missing from our list is the phosphoglycerate kinase gene (pgk). The phosphoglycerate kinase gene family is a good marker candidate at only 5 taxonomic levels (Bacteria, Chlamydiae, Cyanobacteria, Thermotogae, Gammaproteobacteria), thus is not qualified to be one of the 114 core PhyEco markers of bacteria in this release.
Table 2. Summary of the 40 PhyEco marker candidates identified for the group “Bacteria plus Archaea.”.
| Marker ID | Gene Family Descriptions | Correspondent AMPHORA Marker |
|---|---|---|
| BA00001 | ribosomal protein S2 | rpsB |
| BA00002 | ribosomal protein S10 | rpsJ |
| BA00003 | ribosomal protein L1 | rplA |
| BA00004 | translation elongation factor EF-2 | - |
| BA00005 | translation initiation factor IF-2 | - |
| BA00006 | metalloendopeptidase | - |
| BA00007 | ribosomal protein L22 | - |
| BA00008 | ffh signal recognition particle protein | - |
| BA00009 | ribosomal protein L4/L1e | rplD |
| BA00010 | ribosomal protein L2 | rplB |
| BA00011 | ribosomal protein S9 | rpsI |
| BA00012 | ribosomal protein L3 | rplC |
| BA00013 | phenylalanyl-tRNA synthetase beta subunit | - |
| BA00014 | ribosomal protein L14b/L23e | rplN |
| BA00015 | ribosomal protein S5 | - |
| BA00016 | ribosomal protein S19 | rpsS |
| BA00017 | ribosomal protein S7 | - |
| BA00018 | ribosomal protein L16/L10E | rplP |
| BA00019 | ribosomal protein S13 | rpsM |
| BA00020 | phenylalanyl-tRNA synthetase α subunit | - |
| BA00021 | ribosomal protein L15 | - |
| BA00022 | ribosomal protein L25/L23 | - |
| BA00023 | ribosomal protein L6 | rplF |
| BA00024 | ribosomal protein L11 | rplK |
| BA00025 | ribosomal protein L5 | rplE |
| BA00026 | ribosomal protein S12/S23 | - |
| BA00027 | ribosomal protein L29 | - |
| BA00028 | ribosomal protein S3 | rpsC |
| BA00029 | ribosomal protein S11 | rpsK |
| BA00030 | ribosomal protein L10 | - |
| BA00031 | ribosomal protein S8 | - |
| BA00032 | tRNA pseudouridine synthase B | - |
| BA00033 | ribosomal protein L18P/L5E | - |
| BA00034 | ribosomal protein S15P/S13e | - |
| BA00035 | Porphobilinogen deaminase | - |
| BA00036 | ribosomal protein S17 | - |
| BA00037 | ribosomal protein L13 | rplM |
| BA00038 | phosphoribosylformylglycinamidine cyclo-ligase | rpsE |
| BA00039 | ribonuclease HII | - |
| BA00040 | ribosomal protein L24 | - |
Availability
The gene families of potential PhyEco markers listed in Table 1 and Table S1, as well as phyla-specific PhyEco markers, are available for download. The package includes hidden markov model profiles, amino acid sequences and alignments. The phylogenetic trees, perl scripts for calculating gene family universality, evenness and monophyletic values, as well as the numeric values of the three measurements for Figure 2 and 3 are also available and accessible from: http://edhar.genomecenter.ucdavis.edu/~dwu/BAmarker/.
Figure 3. The universality, evenness and monophyletic value of the 74 Bacterial specific PhyEco marker candidates in different taxonomic groups.

PhyEco marker genes for the taxonomic groups are highlighted with white boxes.
We have also uploaded the files to Figshare, which can be accessed from: http://figshare.com/articles/Systematically_identify_phylogenetic_markers_at_different_taxonomic_levels_for_bacteria_and_archaea/722713
Conclusion
The approach we describe here can be used for any taxonomic group and can also be automated for keeping up with the explosion in genome sequences that are coming. A core set of robust “PhyEco markers” has many uses and the metrics we describe here can help in objectively selecting candidates for such markers. We note that in the future it will likely be even better to go beyond just PhyEco marker genes and to incorporate information about additional gene families in analysis of genomes and metagenomes. One promising approach is to identify families for which the presence indicates a particular clade [44]. We have taken an alternative approach, that is to build resources and tools that will allow phylogenetic analysis of all families in genomes or metagenomes. This is one of the reasons behind the development of SFAMs database [38], and also the development of PhyloSift – a computational tool which can make use of any family in automated phylogenetic analyses of metagenomic data.
Methods
Genome selection and database setup
Bacterial and archaeal genomes from the IMG database were selected for phylogenetic marker identification. Only genomes that were complete were included. We started our marker identification process at 15 different taxonomic levels: the domain Archaea; the phyla Actinobacteria, Bacteroides, Chlamydiae, Chloroflexi, Cyanobacteria, Firmicutes, Spirochetes, Deinococcus-Thermus and Thermotogae; the classes Alphaproteobacteria, Betaproteobacteria, Gammaproteobacteria, Deltaproteobacteria and Epsilonproteobacteria. Genomes that have undergone major genome reductions, such as those of Mycoplasma [45], [46] and gammaproteobacteria endosymbionts [47], [48], were not included in this study. Only one strain of the same species within Gammaproteobacteria was selected if other strains did not contribute to the phylogenetic diversity (PD) in the phylogenetic tree of bacteria.
A ssu-rRNA phylogenetic tree was built for all the genomes in the selection. Alignments of ssu-rRNAs were extracted from the greengenes database[49]. Fasttree was used for ssu-rRNA tree building[50].
Measurement of universality, evenness, monophyly and uniqueness for gene families for identifying PhyEco marker candidates
To determine if a family is a suitable candidate of a PhyEco marker for a given taxonomic group, we developed four measurements: universality, evenness, monophyly, and uniqueness.
Universality
How widely distributed a family is across a taxonomic group. Universality is defined by equation 1:
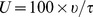 |
(1) |
|---|
U is the universality value of a family, t is the total number of genomes in the taxonomic group of interest, and n is the number of genomes in which the family can be found.
Evenness
How uniform the number of representatives per genome is for a family for a taxonomic group. Evenness is defined by equation 2:
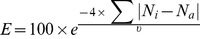 |
(2) |
|---|
E is evenness value of a family, Ni is the number of family members from the genome i, Na is the average number of family members per genome, n is the number of genomes in which the family can be found.
Monophyly
For any family, how monophyletic are the representatives from a particular taxonomic group in a phylogenetic tree of the family across all genomes. We developed a “monophyletic value”, which is based on Shannon entropy [51], to measure the topological distribution of a family member in a tree. If a family member can be broken into a number of monophyletic clades, the monophyletic value is defined by equation 3:
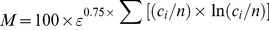 |
(3) |
|---|
M is the monophyletic value, n is the total number of family members in the tree, ci is the number of family members in the monophyletic clade i.
We note our monophyly metric was designed to identify cases where the phylogenetic tree of a particular gene family is similar to the expected phylogenetic tree for the species being analyzed. However, the metric we used only reflects tree topology, and it is only effective in capturing almost perfect monophyletic clades. We are in the process of improving the monophyletic measurement to be more robust and reflect both tree topologies and branch lengths.
Uniqueness
How distinct is the family in question from other families. For this test we used profile hidden Markov models (profile HMMs) [52] of each family. Uniqueness was measured in terms of the results of searches of the family HMM profile against all the peptide sequences encoded in the genomes in the taxonomic group. The HMM search bit-score of any non-family-member sequence has to be lower than all the family members for a gene family to be considered unique. The larger the distances between the family-members and non-family-members, the more “unique” the family is. For the analysis reported in this paper we used the following approach:
Pmember is the worst hmmsearch P value of the family members, Pnonmember is the best hmmsearch P value of non-family members, we only consider a family distinct if Pmember and Pnonmember satisfy the following condition:
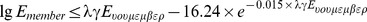 |
(4) |
|---|
Identification of PhyEco markers for a taxonomic group
All vs. all BLASTP searches were performed for the peptide sequences encoded in all the genomes in a taxonomic group of interest using an expected value cutoff of 1e-10. Those pairs of proteins for the BLASTP hits covered 80% of the query and hit sequences were considered “linked”. The BLASTP similarity scores were retrieved for all links. The Markov Cluster Algorithm (MCL clustering) was performed for the links using an inflation value of two. The resulting MCL clusters were regarded as families. The families with four to 2000 members were then used for PhyEco marker identification.
Each family was analyzed separately for potential as a PhyEco marker using the protocol illustrated in the flowchart in Figure 1. First, the peptide sequences from the family are aligned by MUSCLE [53] and then a phylogenetic tree is inferred from the alignment using Fasttree [50]. The subfamilies defined by the clades in the tree are then analyzed one at a time for universality and evenness. Those subfamilies that met the following criteria were considered for further analysis as PhyEco candidates: present in all or all but one of the genomes (universal) and present only once in all or all but one of the genomes (even). For each subfamily that passed the universality and evenness screening, the sequences were aligned by MUSCLE [53] and HMM models were built from the alignments by HMMER3 [52]. The HMM for each subfamily was then searched against the entire collection of proteins for all the genomes in the phylogenetic group of interest [52]. Subfamily uniqueness was measured as described above with only those passing the selection criteria being identified as “unique.” The final list of PhyEco markers for any group were thus those that passed the universality, evenness and uniqueness tests of this protocol.
As discussed above, the MCL method has the potential to mistakenly split up families that should be together. To attempt to correct for this limitation, we carried out single linkage clustering to build another round of gene families. First, BLASTP links that connected to members of PhyEco marker families were excluded. Second, gene families were built by using the single-linkage clustering algorithm on the remaining BLASTP links. Finally, the gene families were subjected to the same protocol as outline above to identify additional PhyEco marker candidates.
Identification of PhyEco markers for “higher groups” by coalescing together markers from “lower” groups
In our bottom up approach, to identify PhyEco markers for the “higher” level taxonomic groups (e.g., all bacteria plus archaea) we needed to coalesce together PhyEco markers identified for each “lower” level phylogenetic group. This coalescing was done in the following way. First, one representative sequence was generated from each of the PhyEco markers' HMM models by hmmemit from HMMER3[52]. Then, an “All vs. All” BLASTP was performed for the representative sequences using an e-value cutoff of 1e-3. This was followed by single linkage clustering of the BLASTP results to generate clusters of lower level PhyEco markers that were similar to each other. We focused subsequent analysis on the 404 of these clusters that contained more than three of the lower level PhyEco marker representative sequences. For each of the 404 clusters, alignments were built with MUSCLE [53] followed by phylogenetic tree inference using Fasttree [50].
All clades in the trees that contain single representative from different taxonomic groups in the study were gathered, and the uniqueness of was measured using the approach outlined above. 382 “unique” clades were identified that each covered more than four taxonomic groups, and all the sequences they represented were retrieved to form 382 superfamilies. For each of these 382 superfamilies, a HMM profile was built and hmmsearch was performed against all complete bacterial and archaeal genomes [52]. The hmmsearch results were manually examined, and additional sequences identified by the search were retrieved and included in the superfamily. Alignments were built for all the superfamilies by MUSCLE [53] and phylogenetic trees were built by PHYML using JTT models [54]. Then, for each of the 382 superfamilies, universality, evenness and monophyletic values were calculated at each of the following 18 taxonomic levels: the domain Archaea and Bacteria; the phyla Actinobacteria, Bacteroides, Chlamydiae, Chloroflexi, Cyanobacteria, Firmicutes, Proteobacteria, Spirochaetes, Deinococcus-Thermus and Thermotogae; the super-class beta/gamma proteobacteria; the classes Alphaproteobacteria, Betaproteobacteria, Gammaproteobacteria, Deltaproteobacteria and Epsilonproteobacteria.
We then used these results to select PhyEco markers for the different “higher” taxonomic groups. To select PhyEco markers for the group “all bacteria and archaea” we required the product of universality, evenness and monophyletic values to be greater than 729,000 for at least a subset of taxonomic levels. We picked this value because it represents the value we would see with a score of 90 for each metric. We required this value to be exceeded in a minimum of seven of the taxonomic levels measured including the “all bacteria” and “all archaeal” sets. 40 families meeting this criterion were identified. To select PhyEco markers for the group “all bacteria” we again required the product of universality, evenness and monophyletic values to exceed 729,000 for a subset of the taxonomic levels included in this group. In this case we required this value to be exceeded in a minimum of six of the taxonomic levels measured (including the “all bacteria” one). 74 “all bacteria” PhyEco markers were identified with these restrictions.
Supporting Information
Table S1
Summary of 74 PhyEco marker candidates identified for the group “Bacteria”.
(DOC)
Funding Statement
Funding for this work was provided by the Gordon and Betty Moore Foundation (grant #1660 and #3300, website: http://www.moore.org/). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1.Balch WE, Magrum LJ, Fox GE, Wolfe RS, Woese CR (1977) An ancient divergence among the bacteria. J Mol Evol 9: 305–311. [DOI] [PubMed] [Google Scholar]
- 2.Fox GE, Stackebrandt E, Hespell RB, Gibson J, Maniloff J, et al. (1980) The phylogeny of prokaryotes. Science 209: 457–463. [DOI] [PubMed] [Google Scholar]
- 3.Woese CR, Fox GE (1977) Phylogenetic structure of the prokaryotic domain: the primary kingdoms. Proc Natl Acad Sci U S A 74: 5088–5090. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Nawrocki EP, Kolbe DL, Eddy SR (2009) Infernal 1.0: inference of RNA alignments. Bioinformatics 25: 1335–1337. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Wu D, Hartman A, Ward N, Eisen JA (2008) An automated phylogenetic tree-based small subunit rRNA taxonomy and alignment pipeline (STAP). PLoS One 3: e2566. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Pace NR (1997) A molecular view of microbial diversity and the biosphere. Science 276: 734–740. [DOI] [PubMed] [Google Scholar]
- 7.Hugenholtz P, Goebel BM, Pace NR (1998) Impact of culture-independent studies on the emerging phylogenetic view of bacterial diversity. J Bacteriol 180: 4765–4774. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Lane DJ, Pace B, Olsen GJ, Stahl DA, Sogin ML, et al. (1985) Rapid determination of 16S ribosomal RNA sequences for phylogenetic analyses. Proc Natl Acad Sci U S A 82: 6955–6959. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Weisburg WG, Barns SM, Pelletier DA, Lane DJ (1991) 16S ribosomal DNA amplification for phylogenetic study. J Bacteriol 173: 697–703. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Pruesse E, Quast C, Knittel K, Fuchs BM, Ludwig W, et al. (2007) SILVA: a comprehensive online resource for quality checked and aligned ribosomal RNA sequence data compatible with ARB. Nucleic Acids Res 35: 7188–7196. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Cole JR, Wang Q, Cardenas E, Fish J, Chai B, et al. (2009) The Ribosomal Database Project: improved alignments and new tools for rRNA analysis. Nucleic Acids Res 37: D141–145. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Klappenbach JA, Dunbar JM, Schmidt TM (2000) rRNA operon copy number reflects ecological strategies of bacteria. Appl Environ Microbiol 66: 1328–1333. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Klappenbach JA, Saxman PR, Cole JR, Schmidt TM (2001) rrndb: the Ribosomal RNA Operon Copy Number Database. Nucleic Acids Res 29: 181–184. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Acinas SG, Sarma-Rupavtarm R, Klepac-Ceraj V, Polz MF (2005) PCR-induced sequence artifacts and bias: insights from comparison of two 16S rRNA clone libraries constructed from the same sample. Appl Environ Microbiol 71: 8966–8969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Kembel SW, Wu M, Eisen JA, Green JL (2012) Incorporating 16S gene copy number information improves estimates of microbial diversity and abundance. PLoS Comput Biol 8: e1002743. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Yap WH, Zhang Z, Wang Y (1999) Distinct types of rRNA operons exist in the genome of the actinomycete Thermomonospora chromogena and evidence for horizontal transfer of an entire rRNA operon. J Bacteriol 181: 5201–5209. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Beiko RG, Doolittle WF, Charlebois RL (2008) The impact of reticulate evolution on genome phylogeny. Syst Biol 57: 844–856. [DOI] [PubMed] [Google Scholar]
- 18.Gevers D, Cohan FM, Lawrence JG, Spratt BG, Coenye T, et al. (2005) Opinion: Re-evaluating prokaryotic species. Nat Rev Microbiol 3: 733–739. [DOI] [PubMed] [Google Scholar]
- 19.Lloyd AT, Sharp PM (1993) Evolution of the recA gene and the molecular phylogeny of bacteria. J Mol Evol 37: 399–407. [DOI] [PubMed] [Google Scholar]
- 20.Eisen JA (1995) The RecA protein as a model molecule for molecular systematic studies of bacteria: comparison of trees of RecAs and 16S rRNAs from the same species. J Mol Evol 41: 1105–1123. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Sandler SJ, Hugenholtz P, Schleper C, DeLong EF, Pace NR, et al. (1999) Diversity of radA genes from cultured and uncultured archaea: comparative analysis of putative RadA proteins and their use as a phylogenetic marker. J Bacteriol 181: 907–915. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Stassen NY, Logsdon JM Jr, Vora GJ, Offenberg HH, Palmer JD, et al. (1997) Isolation and characterization of rad51 orthologs from Coprinus cinereus and Lycopersicon esculentum, and phylogenetic analysis of eukaryotic recA homologs. Curr Genet 31: 144–157. [DOI] [PubMed] [Google Scholar]
- 23.Yang S, VanLoock MS, Yu X, Egelman EH (2001) Comparison of bacteriophage T4 UvsX and human Rad51 filaments suggests that RecA-like polymers may have evolved independently. J Mol Biol 312: 999–1009. [DOI] [PubMed] [Google Scholar]
- 24.Mollet C, Drancourt M, Raoult D (1997) rpoB sequence analysis as a novel basis for bacterial identification. Mol Microbiol 26: 1005–1011. [DOI] [PubMed] [Google Scholar]
- 25.Puhler G, Leffers H, Gropp F, Palm P, Klenk HP, et al. (1989) Archaebacterial DNA-dependent RNA polymerases testify to the evolution of the eukaryotic nuclear genome. Proc Natl Acad Sci U S A 86: 4569–4573. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Oxelman B, Yoshikawa N, McConaughy BL, Luo J, Denton AL, et al. (2004) RPB2 gene phylogeny in flowering plants, with particular emphasis on asterids. Mol Phylogenet Evol 32: 462–479. [DOI] [PubMed] [Google Scholar]
- 27.Venter JC, Remington K, Heidelberg JF, Halpern AL, Rusch D, et al. (2004) Environmental genome shotgun sequencing of the Sargasso Sea. Science 304: 66–74. [DOI] [PubMed] [Google Scholar]
- 28.Wu D, Wu M, Halpern A, Rusch DB, Yooseph S, et al. (2011) Stalking the fourth domain in metagenomic data: searching for, discovering, and interpreting novel, deep branches in marker gene phylogenetic trees. PLoS ONE 6: e18011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Hasegawa M, Hashimoto T (1993) Ribosomal RNA trees misleading? Nature 361: 23. [DOI] [PubMed] [Google Scholar]
- 30.Wu M, Eisen JA (2008) A simple, fast, and accurate method of phylogenomic inference. Genome Biol 9: R151. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Ciccarelli FD, Doerks T, von Mering C, Creevey CJ, Snel B, et al. (2006) Toward automatic reconstruction of a highly resolved tree of life. Science 311: 1283–1287. [DOI] [PubMed] [Google Scholar]
- 32.Wang Z, Wu M (2013) A Phylum-Level Bacterial Phylogenetic Marker Database. Mol Biol Evol. [DOI] [PubMed]
- 33.Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ (1990) Basic local alignment search tool. J Mol Biol 215: 403–410. [DOI] [PubMed] [Google Scholar]
- 34.Enright AJ, Van Dongen S, Ouzounis CA (2002) An efficient algorithm for large-scale detection of protein families. Nucleic Acids Res 30: 1575–1584. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Wu D, Hugenholtz P, Mavromatis K, Pukall R, Dalin E, et al. (2009) A phylogeny-driven genomic encyclopaedia of Bacteria and Archaea. Nature 462: 1056–1060. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Markowitz VM, Chen IM, Palaniappan K, Chu K, Szeto E, et al. (2012) IMG: the Integrated Microbial Genomes database and comparative analysis system. Nucleic Acids Res 40: D115–122. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Abby SS, Tannier E, Gouy M, Daubin V (2010) Detecting lateral gene transfers by statistical reconciliation of phylogenetic forests. BMC Bioinformatics 11: 324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Sharpton TJ, Jospin G, Wu D, Langille MG, Pollard KS, et al. (2012) Sifting through genomes with iterative-sequence clustering produces a large, phylogenetically diverse protein-family resource. BMC Bioinformatics 13: 264. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Mushegian AR, Koonin EV (1996) A minimal gene set for cellular life derived by comparison of complete bacterial genomes. Proc Natl Acad Sci U S A 93: 10268–10273. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Gil R, Silva FJ, Pereto J, Moya A (2004) Determination of the core of a minimal bacterial gene set. Microbiol Mol Biol Rev 68: 518–537. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Mulkidjanian AY, Koonin EV, Makarova KS, Mekhedov SL, Sorokin A, et al. (2006) The cyanobacterial genome core and the origin of photosynthesis. Proc Natl Acad Sci U S A 103: 13126–13131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Woyke T, Xie G, Copeland A, Gonzalez JM, Han C, et al. (2009) Assembling the marine metagenome, one cell at a time. PLoS ONE 4: e5299. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Woyke T, Tighe D, Mavromatis K, Clum A, Copeland A, et al. (2010) One bacterial cell, one complete genome. PLoS ONE 5: e10314. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Segata N, Waldron L, Ballarini A, Narasimhan V, Jousson O, et al. (2012) Metagenomic microbial community profiling using unique clade-specific marker genes. Nat Methods 9: 811–814. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Himmelreich R, Hilbert H, Plagens H, Pirkl E, Li BC, et al. (1996) Complete sequence analysis of the genome of the bacterium Mycoplasma pneumoniae. Nucleic Acids Res 24: 4420–4449. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Dewall MT, Cheng DW (2011) The minimal genome: a metabolic and environmental comparison. Brief Funct Genomics 10: 312–315. [DOI] [PubMed] [Google Scholar]
- 47.Shigenobu S, Watanabe H, Hattori M, Sakaki Y, Ishikawa H (2000) Genome sequence of the endocellular bacterial symbiont of aphids Buchnera sp. APS. Nature 407: 81–86. [DOI] [PubMed] [Google Scholar]
- 48.Wu D, Daugherty SC, Van Aken SE, Pai GH, Watkins KL, et al. (2006) Metabolic complementarity and genomics of the dual bacterial symbiosis of sharpshooters. PLoS Biol 4: e188. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.DeSantis TZ, Hugenholtz P, Larsen N, Rojas M, Brodie EL, et al. (2006) Greengenes, a chimera-checked 16S rRNA gene database and workbench compatible with ARB. Appl Environ Microbiol 72: 5069–5072. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Price MN, Dehal PS, Arkin AP (2010) FastTree 2—approximately maximum-likelihood trees for large alignments. PLoS ONE 5: e9490. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Shannon CE (1997) The mathematical theory of communication. 1963. MD Comput 14: 306–317. [PubMed] [Google Scholar]
- 52.Eddy SR (2009) A new generation of homology search tools based on probabilistic inference. Genome Inform 23: 205–211. [PubMed] [Google Scholar]
- 53.Edgar RC (2004) MUSCLE: multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res 32: 1792–1797. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Guindon S, Delsuc F, Dufayard JF, Gascuel O (2009) Estimating maximum likelihood phylogenies with PhyML. Methods Mol Biol 537: 113–137. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Table S1
Summary of 74 PhyEco marker candidates identified for the group “Bacteria”.
(DOC)