Wells: Orthographic diacritics (original) (raw)
Orthographic diacritics and multilingual computing
J.C. Wells
Dept. of Phonetics and Linguistics, University College London
Article published in Language Problems and Language Planning, 24.3 (2001).
Summary. Diacritics— marks above, through, or below letters — are used in many orthographies to remedy the shortcomings of the ordinary Latin alphabet. The author catalogues the various diacritics that are in use for spelling different languages, describing what they look like and what they are used for. He also analyses the problems of using accented letters in a multilingual computing environment, and discusses the extent to which these problems have been resolved, with particular reference to Unicode.
1. The alphabet | Is the ordinary alphabet enough? | Combining two letters | Inventing a new letter | Inventing a diacritic | The apostrophe | Alphabetical ordering | Orthographies
2. Diacritics above. | Acute accent | Grave accent | Circumflex accent | Caron (wedge) | Breve | Macron | Dot | Diaeresis | Tilde | Double acute | Ring | Hook | Two diacritics combined | Typography
3. Diacritics through and below | Slash | Bar | Horn | Cedilla | Comma | Tail | Dot
4. Coding and keyboarding | The seven-bit problem | Eight-bit partial solutions | The sixteen-bit solution | Unicode | Keyboarding | Final words
- - Sommaire | Resumo | References
This document uses Unicode to encode characters that include diacritics. You should be able to see accented letters on your screen here: ĉ ĕ ķ Ậ ễ (the penultimate character should have two marks, one above and one below, while the last should have two superior diacritics). If you cannot see them, please get hold of a more comprehensive Unicode font and install it on your system, e.g. the freely available Gentium (download).
Internet Explorer 6 users, set your browser to View | Encoding | Auto-select; Netscape 6 users, to View | Character coding | Auto-detect.
You may also find it helpful to use View | Text Size (or equivalent) to enlarge the text where necessary and make it easier to read.
1. The alphabet
1.1 Is the ordinary alphabet enough?
There are many languages in the world that use the Latin alphabet: more, in fact, than use any other script. English, however, is one of the very few among them for which the standard spelling makes use of just the basic set of 26 letters. Almost all the remainder supplement this set by making use of letters with diacritics (accent marks). In this article we discuss the various diacritics that are so used and the problems this has given rise to in a multilingual computing environment — problems now arguably on the way to a satisfactory solution through the adoption of the international standard known as Unicode.
From a linguist’s point of view, spelling is not a particularly important aspect of a language; indeed in the linguistic sense it is hardly part of language at all. But it has a high profile for the layman, because of its prominent visibility. Letters bearing unfamiliar diacritics catch the layman’s eye in a way that details of a language’s syntax, morphology, semantics, and pragmatics, even its phonetics, do not. This leads to the strange situation that often the only thing a layman knows about this or that language — Czech, for example, or Polish — is that it uses particular orthographic diacritics.
First, though, we must ask another question: what is the purpose of using diacritics? Why do languages need to supplement the Latin alphabet in this way? The answer, clearly, is that without some such device the existing alphabet was felt not to be adequate for the language to which it was to be applied.
The Latin alphabet did well enough in representing the phonological system of Latin, but faces a problem whenever it is to be used for a language whose phonetics involves sounds that Latin did not have. A case in point is the palatoalveolar fricative [ʃ], in English often spelled sh, but in some languages represented as š or ŝ or ş. Another is the the velar nasal [ŋ], spelled as ng in various languages.
Accented letters are one of the possible ways of repairing the inadequacies of the Latin alphabet and thus solving this problem. They do not, however, constitute the only way. Let us first look at the various other techniques that have been devised to cope when the ordinary alphabet is not enough.
1.2 Combining two letters
First, special combinations of letters can be used. The sh in English ship is a device used by English spelling to overcome the problem that we have no single letter in the alphabet that denotes the relevant sound, [ʃ]. This sound was not a phoneme of Latin, and our Latin-derived alphabet has no letter for it. By using the two letters sh (each of which on its own indicates a quite different sound), we can get round the problem. A two-letter combination of this sort is called a digraph.
The sh digraph, like others, has the disadvantage that there may be cases where we want the relevant letters to be interpreted separately rather than together, as in the word mishap. This can lead to uncertainty or ambiguity.
Other languages use other digraphs for the same sound: French ch, Dutch sj, Italian sc, Polish sz. German uses a three-letter combination (a trigraph), namely sch; so sometimes does Norwegian, with skj (but also the digraphs sj, sk).
In the German word singen ‘sing’ the letters ng correspond to a single sound [ŋ], the velar nasal. The same is true in most people’s pronunciation of the English word sing. This sound, likewise, was not a phoneme of Latin, which is why there is no separate letter for it. Again, we have solved the problem by using a digraph.
Another familiar digraph is ch. It is used in a number of different Latin-alphabet orthographies, but with a wide range of different meanings. In English it most often represents the sound [ʧ], as in cheap (a voiceless palato-alveolar affricate), though it stands for other sounds in machine and choir. In French, as mentioned above, it represents the fricative [ʃ], while in German it stands for [x] and [ç] (depending on what sound precedes). In Italian it shows that the letter c retains its ordinary sound [k] in a position where it would otherwise be interpreted as [ʧ].
The sound [ɲ], the palatal nasal, is represented in French and Italian spelling by the digraph gn, but in Portuguese by nh and in Catalan and various African languages by ny. The palatal lateral, [ʎ], is represented in Spanish spelling by the digraph ll (though nowadays speakers of Spanish increasingly boycott the palatal lateral in favour of a simple palatal semivowel or fricative). But in Italian spelling the palatal lateral is shown as gl, and in Portuguese as lh. There are many more examples like these.
1.3 Inventing a new letter
A second option is that of inventing a new letter and adding it to the alphabet. It may be based on an existing letter. Thus for example for the spelling of Icelandic the three letters æ ð þ have been added to the Latin alphabet. (Modern Latin-alphabet letters require a distinct uppercase form, so we also have Æ Ð Þ.) The first is a ligature of the existing letters Aa and Ee. The second is based on Dd, and could be seen for the uppercase form Ð as involving the addition of a diacritic — though this explanation would not suffice for the lowercase ð, where the basic shape is different. The third came from the runic alphabet.
The distinction between a digraph and a separate letter is not always altogether clear. This question arises with æ. Is it to be counted in some sense as a plus e, or as a new letter? The same uncertainty applies to other ligatures, such as French œ and German ß (from sz).
A special situation arises in the case of Croatian and Serbian, formerly regarded as a single language Serbo-Croat. Croatian is written in the Latin alphabet, Serbian usually in Cyrillic. Serbo-Croat could be written with either alphabet: but the Latin alphabet uses digraphs dz dž lj nj where Cyrillic has a single letter for each (ѕ, џ, љ, њ). These Serbo-Croat digraphs are likewise treated as single letters. (The digraph dz/ѕ is actually Macedonian rather than Serbian.)
The Latin alphabet itself, now standardized, contains in its history many points of interest. In Roman times the letter G was created as a variant of C,where previously there had been no such distinction. The difference between uppercase (capital) and lowercase (small) letters is medieval, and was unknown in classical times. The differences between Ii and Jj, and between Uu and Vv, are relatively modern, as is the new letter Ww, unknown in Latin. On these various developments see Sampson, 1985: 108-113.
Certain West African languages, particularly in Ghana, make use of the additional letters ŋ, ɲ, ɛ and ɔ, taken from the International Phonetic Alphabet(IPA). Since the IPA uses only lowercase, uppercase counterparts Ŋ, Ɲ, Ɛ and Ɔ also had to be devised. For the first of these, an alternative shape to the enlarged eng is 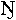 .
.
The current spelling of Azerbaijani, Tatar, and perhaps other languages former written in Cyrillic, includes another IPA character, the schwa, ə. It, too, needs an upper-case form: Ə. But in Nigeria, sources say (details sought), an alternative upper-case form Ǝ may be used.
Still in West Africa, Hausa spelling supplements the Latin alphabet with the hooked letters Ɓɓ Ɗɗ Ƙƙ, letters incorporated into the Pan-Nigerian alphabet along with hooked Ƴƴ (which is replaced in Hausa orthography by 'Y'y). Although these all involve the incorporation of a hook of some kind, it is not really an independent diacritic mark in the sense discussed below.
For Greenlandic an additional ĸ was formerly used for a uvular stop distinct from that denoted by Kk, although now it has been replaced by the simpler q, which has the advantage of having an upper-case form Q.
Associated with the modern Latin alphabet, there are also various written characters — hardly letters — which are used to extend it. Examples include the ampersand &, the percentage mark %, the at-sign @, the hash-mark (number sign) #, and even the forward slash (solidus) / and the exclamation mark !. The last two of these are actually used alphabetically, representing clicks, in a number of languages of Southern Africa, as is the mathematicians’ ≠. And then there are the currency symbols: the widely used $ and the more parochial £, €, ¥, ¢ and others.
1.4 Inventing a diacritic
The third option for overcoming the shortcomings of an alphabet is the main theme of this article: extending it by adding a distinguishing mark, a diacritic, to an existing letter, so creating a new, accented, letter. It is convenient to classify diacritics according to where they are placed relative to the base letter. In section 2 we consider the various diacritics that can be placed above a letter, as seen in é, è, ê. In section 3 we consider those that can be placed through or below a letter, as ø, ç.
We need to define more closely what we mean by a diacritic. For instance, is the superior dot in i a diacritic? To answer this question, we need recourse to the linguistic principle of opposition (contrast). Given that the ordinary Latin alphabet does not contain a letter i without the dot, it follows that the dot is a nondistinctive constituent of the letter i (and likewise in j). So it does not count as a diacritic. On the other hand in the Turkish spelling reform of the 1920’s a new letter was devised, just such a dotless ı, while the Turkish alphabet also kept an ordinary i. At the same time a capital dotted İ was devised as the upper-case counterpart of i, while the dotless capital I took on the role of the upper-case counterpart of the new ı. (Compare the ordinary Latin alphabet, in which upper-case dotless I is paired with dotted lower-case i.) In the context of this reformed spelling of Turkish, the dot on i can indeed be considered a diacritic.
A further complication is the convention of removing the dot from i and j when adding a diacritic over them, as in í, ì, î, ĵ. In the Baltic countries, however, the dot is sometimes retained in these circumstances. The awkwardness of a diacritic over i is no doubt what lies behind the customary romanization of Japanese long vowels as â ê ô û (or ā ē ō ū) but ii.
1.5 The apostrophe
As one last preliminary point, we must say a few words about the apostrophe ʼ. This mark is not normally placed over, through or under a letter, as diacritics are. Nevertheless from some points of view its role is similar to that of a diacritic. It is true that in many languages it is used to indicate the omission of a letter: this is how it is used in English (isnʼt, weʼll, Bobʼs, sizzlinʼ) and in French (cʼest lʼeau). But sometimes it has a diacritic-like role — in Swahili, for example, where ng’ stands for the single sound [ŋ], as against the letter sequence ng, which stands for two sounds, a nasal plus [g]. Likewise with Breton chʼ, which stands for the voiceless velar fricative [x], while simple ch, as in French, stands for the palatoalveolar [ʃ]. This same function of showing that two adjacent letters are not to be taken as a digraph is performed in Catalan by a mid dot in ŀl, which stands for a geminated dental lateral; the sequence ll would be taken as a digraph implying a palatal lateral.
In Afrikaans the indefinite article is written ʼn and pronounced [ǝ]. This appears to be the only use of ʼn in that language. In any case, in Unicode the pre-composed character "is retained only to provide compatibility with other coding systems, and its use is generally deprecated" (Hein 1996).
In the cases of Catalan ŀ and Afrikaans ʼn we seem to have a straightforward linear sequence of signs: l plus mid dot, apostrophe plus n. Nevertheless, they are both sometimes considered to be separate letters, and Unicode provides separate codings for them.
In some orthographies the apostrophe has the function of an ordinary letter of the alphabet, representing the glottal stop [ʔ]. It is used in this way in the romanization (transliteration) of Arabic, where as well the reversed apostrophe ‘ is used to represent the pharyngeal [ʕ]. In Hawaiian, the officially preferred form for the letter representing the glottal stop is a reversed apostrophe ‘, as in the native spelling of the island Hawai‘i. Neither the apostrophe nor the reversed apostrophe has a separate upper-case form.
As we shall shortly see, the apostrophe also acts as a variant of a genuine diacritic in the Czech/Slovak symbols ť ď.
1.6 Alphabetical ordering
There are one or two points that arise in connection with the question of what counts as a separate letter. In the spelling of some languages, digraphs are taken as separate letters (text elements) for purposes of alphabetical ordering, so that ch, for example, might be placed after c and before d, rather than between ce and ci. In Welsh alphabetical order, the digraph ng comes between g and h. In Dutch the digraph ij is often written in a special close-kerned form, ij; sometimes it can be replaced by the single letter y; in both cases it is alphabetized between x and z. The Serbo-Croat digraphs (1.3 above) are also treated as separate letters.
The same question arises with accented letters. Is a letter bearing a diacritic treated the same as one without, or does it count as a different letter (text element)? Again, there are different conventions in different languages. In German, for example, ä is alphabetized as simple a or as ae, while in Swedish it is treated as a separate letter, with its own alphabetic place at the end of the alphabet, after x y z å and followed finally by ö.
In Estonian, both z and the accented letters appear in what may be considered unexpected places. The latter part of the Estonian alphabet is ordered thus: p r s š z ž t u v õ ä ö ü.
1.7 Orthographies
The present discussion is restricted to the Latin alphabet, and to recognized orthographies that are in general everyday use. The principles involved, though, are general. We note in passing that the Greek alphabet traditionally used a complex system of multiple diacritics, though recent reforms have greatly simplified this. Cyrillic diacritics are mostly attached to the base letter, creating what may perhaps better be seen as new letters. The Arabic and Hebrew scripts, among others, make extensive use of diacritics for indicating vowels, often optionally; this is something not found in Latin-alphabet orthographies. In some ways, the dots in standard Arabic letters might qualify as diacritics (note the difference between ر and ز and between س and ش) — particularly so in the extensions of the Arabic alphabet to cater for the needs of languages such as Sindhi, Persian, Urdu and Pashto. Japanese kana script, too, uses ゛ and ゜ essentially as diacritics, as in は ha, ば ba, ぱ pa.
In this survey we exclude from the discussion the use of diacritics in the writing systems of languages that are not generally written and read. We thus exclude orthographies or transcription systems mainly used by linguists, dialectologists or missionaries. There are of course marginal cases that might well have been included, e.g. Livonian and various dialects of Sámi or Romany. We also exclude diacritics used only for special purposes and ignored in everyday usage, for example the tone-marking sometimes used in literary Croatian, Slovene and Lithuanian. We exclude accented letters used only in the transliteration of Indic, Semitic or other writing systems. And we ignore scientific and mathematical notation.
2. Diacritics above
A diacritic is a mark placed above, through or below a letter, in order to indicate a sound different from that indicated by the letter without the diacritic.
We consider first the superior diacritics, those placed above the letter.
2.1 Acute accent: ´
We start with the acute accent mark. It is used in Spanish, Áá Éé Íí Óó Úú, to show a stressed vowel, where that stress is not in accordance with the default word stress rule. In Czech, on the other hand, it indicates a long vowel, Áá Éé Íí Óó Úú Ýý. In Irish, likewise, it denotes vowel length. And so too in Slovak; but in this language the syllabic consonants l and r can also be long, and are then accordingly written with an acute accent, Ĺĺ Ŕŕ.
There is a wide range of other applications of this diacritic. In French Éé it denotes a half-close (high-mid) vowel. This diacritic is often retained in French words borrowed into English, as résumé. In Polish Óó the acute accent denotes a fully close (high) vowel [u]. In Icelandic Áá it represents a falling diphthong [au]; in the same language, Éé represents a rising diphthong [je] (Böðvarsson 1977). In Welsh an acute accent on a vowel letter indicates both that the vowel is stressed (against the usual rule of penultimate stress placing) and also that it is short. It also occasionally (Thomas 1996: 779) serves to disambiguate the letters i and w, which can stand for either consonants or vowels: only a letter standing for a vowel can bear an accent. For this reason, the accented letter ẃ may (very rarely) be encountered.
In the Polish consonant letters Ćć Ńń Śś Źź it denotes the ‘palatalization’ of the sound in question, i.e. alveopalatals [ʨ] etc. An example is seen in the name of the city of Ł?dź [wuʨ].
In the spelling of Vietnamese an acute accent denotes the high tone. Linguists, too often use it to denote high tone (pitch), particularly in the analysis of African languages; and that is its current IPA meaning. It is used in this meaning in the orthography of Yoruba, for example. Since Yoruba nasals are sometimes syllabic, and therefore tonal, its orthography also includes Ḿḿ and Ńń.
Previously, though, phoneticians, with the sanction of the IPA, used it to symbolize a rising tone. This is the meaning it has in the well-known romanization of Modern Standard Chinese, Pinyin, namely tone 2, a rising tone (though Pinyin is often written without tone-marks).
In Dutch an acute accent is used to show emphasis, rather in the way that English can use emboldening or italicization. Only function words can be treated in this way. For example, if emphasized the words na, een, voor can be written ná, één, vóór. In the case of één, the acute accents can also serve to indicate that this is the numeral ‘one’ rather than the indefinite article.
The angle at which an acute accent is written may vary stylistically. For example, it is usual for an acute accent to be at a steeper angle, and further to the right, in Polish typography than in French, Italian, Spanish, Czech, Hungarian and other languages. For this reason, it has been claimed that this Polish diacritic, known as kreska or kreseczka, is not really an acute accent (Twardoch, 1997). In the Arial Unicode MS font, there does seem to be a slight difference between the accent on ś and that on é. The character ó is used both in Polish and in Czech: should the typographer distinguish between them? "Fortunately, the OpenType font format allows language-sensitive glyph substitution. The designer will be able to create alternative variants of the oacute character and to substitute the one with a steeper accent when the text is typeset in Polish." (Twardoch, 1997)
2.2 Grave accent: `
The mirror image of an acute accent is a grave accent. It is used in the orthography of French on Èè to denote a half-open (low-mid) vowel, but on Àà and Ùù in a purely arbitrary way, allowing a visual distinction between such pairs of homophones as a ‘has’ and à ‘to’, ou ‘or’ and où ‘where’. It is sometimes retained in French words borrowed into English, as crème, pied à terre.
In the spelling of Italian and Catalan Àà Èè Òò represent stressed vowels, indicating simultaneously that the vowel is open or half-open. In the spelling of Scottish Gaelic, however, the grave accent has the same function as the acute accent in Irish Gaelic or Czech, namely to indicate a long vowel. In Welsh, on the other hand, it is occasionally used to indicate the shortness of a vowel, in cases of possible ambiguity (Thomas 1996: 781). Since Welsh includes w and y among its vowel letters, the possibility exists of spellings including ẁ and ỳ.
In Vietnamese the grave accent denotes a low tone. This is also its current IPA meaning, and used in the orthography of various African languages. Since Yoruba nasals are sometimes syllabic, and therefore tonal, Yoruba orthography also includes M̀m̀ and Ǹǹ. But in the Pinyin romanization of Chinese the grave accent indicates tone 4, the falling tone, which is its older (now obsolete) IPA meaning.
2.3 Circumflex accent: ˆ
Another diacritic familiar from French spelling is the circumflex accent. In French Ââ Êê Îî Ôô Ûû the circumflex indicates the loss of a historical consonant. For example, fête derives from Latin festum, goût from Latin gustus. The circumflex is sometimes retained in French words borrowed into English, as with the placename Nîmes.
In Welsh spelling the main function of the circumflex is to denote a long vowel in those positions in a word where its length is not predictable by rule. Since Welsh, as we have seen, uses not only a e i o u but also w and y as vowel letters, the set ofcircumflexed letters found in its spelling logically comprises not only Ââ Êê Îî Ôô Ûû but also Ŵŵ and Ŷŷ, as in the words tŵr ‘tower’, tŷ ‘house’. As mentioned above, the circumflex is also used to denote long vowels in the romanization (transliteration) of Japanese.
Whereas in Welsh it stands for a vowel, in Chichewa Ŵŵ stands for a consonant, namely a bilabial fricative, IPA [β] (as against the labial-velar approximant [w] written w). This letter can be seen on Malawian postage stamps, with the name of the country written Malaŵi. Chichewa is a local variety of the language more widely known as Nyanja (Chinyanja, Cinyanja).
In Afrikaans, the circumflex on Êê and Ôô indicates a half-open long vowel, [ɛː, ɔː], as against the half-close vowels written Ee Oo. In Portuguese, on the other hand, Ââ Êê Ôô stand for stressed relatively close vowels, [ɐ, e, o], while the same letters with an acute accent stand for stressed relatively open vowels [a, ɛ, ɔ]. In Vietnamese spelling, Êê Ôô likewise denote half-close vowels, but Ââ is used to indicate a half-open back unrounded vowel [ʌ].
In Romanian both Ââ and Îî stand for the close central vowel [ɨ]. The first is used, if at all, only in the name of the country, its people and its language.
In Esperanto Ĉĉ Ĝĝ Ĥĥ Ĵĵ Ŝŝ stand for [ʧ ʤ x ʒ ʃ], as against [ʦ g h j s] for their uncircumflexed counterparts.
2.4 Caron (wedge): ˇ
Combining an acute accent and a grave, or turning a circumflex upside down, yields the diacritic known variously as a caron, a wedge, or a hacek. It is familiar to linguists and Slavists in such letters as š and ž. Taking these names in reverse order, the last, properly háček, is the Czech for ‘little hook’. ‘Wedge’ is self-explanatory, referring to its shape. The term ‘caron’, however, is wrapped in mystery. Incredibly, it seems to appear in no current dictionary of English, not even the OED. Yet it is the term used without discussion for this diacritic in as authoritative and influential a source as The Unicode Standard (1991, 2000).
In the orthographies of Czech, Slovak, Croatian, Slovene and various other languages, Šš Žž represent palato-alveolar (postalveolar) fricatives, [ʃ ʒ]. Czech etc. Čč represents the corresponding voiceless affricate [ʧ]. These languages have no separate symbol for the voiced affricate, using instead the digraph dž. The letter ǰ (for IPA [ʤ]) is an invention of linguists, but apparently not used in any standard orthography. In Czech and Slovak Ňň stands for a palatal nasal.
In the case of the Czech vowel letter Ěě the caron symbolizes the palatalization of the preceding consonant. Czech Řř stands for a speech sound found perhaps only in that language, namely a fricative trill, for which the IPA formerly offered the symbol [ɼ] but now uses [r̝] (i.e. the letter r with a diacritic indicating closer articulation). It is found, of course, in the name of the composer Dvořák. Lastly, Czech and Slovak also make use of caron-bearing uppercase letters Ť Ď; but the corresponding lowercase letters, while sometimes handwritten with carons, are usually printed as ť ď, i.e. with a closely following apostrophe. These letters represent the sounds [c ɟ], palatal plosives, historically palatalized dentals. The close-linked apostrophe also appears (in some fonts) for the caron in Slovak Ľľ, representing a palatalized lateral [lʲ].
The caron stands for tone 3 in the Pinyin romanization of Chinese, a falling-rising tone. Its current IPA meaning, on the other hand, is a rising tone.
2.5 Breve: ˘
The breve is similar to the caron, but differs in being rounded rather than pointed. It is familiar to classicists as the ‘short sign’ used over vowels in Latin and other languages to denote the shortness of a vowel: Ăă Ĕĕ Ĭĭ Ŏŏ Ŭŭ Y̆y̆. This is mainly for pedagogical purposes.
The breve is used on Ăă in both Romanian and Vietnamese spelling to denote a mid central vowel [ə]. In Malay, the same sound was previously often written ĕ, though the current spelling uses ordinary e, which is now ambiguous as between [ə]and [e] (although dictionaries may distinguish them by writing é for the latter).
In Esperanto the breve is used on Ŭŭ to symbolize a semivowel, namely the second element in the diphthongs aŭ eŭ [au eu].
The only use of the breve on a consonant letter appears to be in Turkish Ğğ, which represents a historical voiced velar fricative now lost as such but causing compensatory lengthening of the preceding vowel.
There are one or two other uses of the breve restricted (as with Latin) to special purposes rather than everyday orthographies. For instance, although one of the rival romanizations of Korean uses digraphs, eo and eu, to represent the back unrounded vowels [ʌ ɯ], orthographically ᅥ and ᅳ, another widely encountered romanization uses Ŏŏ Ŭŭ.
2.6 Macron: ˉ
If Latin short vowels are shown pedagogically with the breve, how are long vowels shown? With a horizontal bar above, known as a macron, or less technically as a ‘long sign’, thus Āā Ēē Īī Ōō Ūū Ȳȳ. This device is also used for philological and pedagogical purposes in various other languages, e.g. Old English; and since OE used æ as one of its vowel letters, we also find ǣ in grammars and texts.
The macron is also applied in four vowel letters used in the orthography of Latvian (Āā Ēē Īī Ūū), where again it denotes a long vowel, as in the Latvian name of the capital city Rīga. It has the same function in the Polynesian languages Maori and Hawaiian, applied to five vowel letters (Āā Ēē Īī Ōō Ūū).
The macron is also sometimes used to represent tone. In Pinyin it indicates the first tone of Chinese, which is high and level. In Yoruba it indicates a mid tone, but is used only in the combinations M̄m̄ and N̄n̄.
A macron must not be confused with an overline, which is not a diacritic, but a form of text-decoration. Macrons on successive letters are separate; overlines link up.
Mācrōns | Overlines
2.7 Dot: ˙
We have already discussed the dot in the letters i and j. What other letters is it used with? The record for dot above appears to be held by Maltese, in the spelling of which we find the letters Ċċ Ġġ Żż, standing respectively for [ʧ ʤ z]. In the spelling of Lithuanian, Ėė represents a half-close vowel. In that of Polish, Żż stands for [ʒ]. This Polish dot diacritic must not be confused with the acute accent, ź, which is also used in Polish and which is distinct from the dot.
In the orthography of Ibo (Igbo), Ṅṅ stands for a velar nasal, IPA [ŋ]. The same convention applies in the transliteration of Hindi and Sanskrit.
In spelling Irish, a superior dot was formerly used with many of the consonant letters to indicate one of the consonantal mutations, for instance ḃ ṁ (more usually using a distinctive Gaelic typeface). Nowadays a digraph is used instead, thus bh, mh.
2.8 Diaeresis: ¨
The diaeresis, umlaut or trema, two dots above a letter, is familiar from German, where Ää Öö Üü represent front vowels [ɛ ø y]. The first and second of these letters are also used in Swedish in the same sense. Properly speaking, ‘umlaut’ is the name of a phonological process rather than a diacritic; yet umlaut is probably the most widely used term in English as the name of this diacritic. The diaeresis may be retained in German words borrowed into English, as Götterdämmerung.
In various other languages, including French and Spanish, a diaeresis has the function of indicating that two vowel letters are not to be taken as a digraph, but that separate vowel sounds are to be pronounced (hiatus). In addition to the German diaeresis letters, Ëë Ïï Ÿÿ too are used in this way. This is sometimes to be seen in the spelling of classical names in English, thus Danaë, Laocoön. An attempt to popularize such spellings as coöperation (co-operation) has not been successful.
In Albanian spelling ë stands for a schwa [ə], although in practice (and depending on dialect) it is often silent.
2.9 Tilde: ˜
The tilde on Spanish Ññ is well known. This letter represents a palatal nasal, IPA [ɲ].It is sometimes retained in Spanish words borrowed into English, as el Niño. As we saw above, the corresponding sound in Portuguese is written as the digraph nh. The Galicians, whose language is in a sense intermediate between Castilian Spanish and Portuguese, are in disagreement whether to write ñ or nh.
In Breton spelling ñ has a different implication, namely nasalization of the preceding vowel. In that of Portuguese the nasalization of a vowel is represented by a tilde over the vowel letter itself, thus Ãã Õõ. In Greenlandic the same convention applies with Ĩĩ and Ũũ. It has also been adopted by the IPA.
In orthography of Guaraní we find not only Ãã Ẽẽ Ĩĩ Õõ Ũũ Ỹỹ to indicate nasalized vowels (the last having the quality of a central vowel, IPA [ɨ]), but also g̃ for a velar nasal consonant.
In Estonian, however, the spelling õ denotes not a nasalized vowel, but an unrounded mid back [ɤ]. In Vietnamese the tilde indicates a high-rising tone, with glottalized voice quality, e.g. ũ.
2.11 Double acute, ˝
The double acute is a speciality of Hungarian spelling. Since Hungarian writes umlauted Öö and Üü for its short front rounded vowels, and an acute to denote vowel length, there is some logic in writing the long front rounded vowels, IPA [øː yː], as Őő and Űű. The first of these letters is seen in the spelling of the placename Győr.
2.12 Ring, ˚
A familiar letter in the spelling of Swedish, Danish and Norwegian is the a with a ring above, Åå. It represents an [o]-type vowel, historically more open than that written o. In Danish it replaced an earlier digraph aa in the twentieth century. Hence the city of Århus is in English still often spelled Aarhus.
On the other hand the ring in Czech Ůů denotes merely a long vowel.
2.13 Hook: ̉
The last over-the-letter diacritic for us to list is a speciality of Vietnamese spelling, the hook. In shape it resembles a tiny question mark without the dot underneath, thus: Ảả Ẻẻ Ỉỉ Ỏỏ Ủủ Ỷỷ. Its function is as a tone mark, denoting a fall-rise tone (hỏi) with simultaneous tense voice quality.
2.14 Two diacritics combined
The spelling of Vietnamese often calls for a two diacritical marks on a single vowel letter. Such cases reflect the logical combination of two separate diacritics, one relating to vowel quality and the other to tone. The vowel phonemes of Vietnamese are written as Aa Ââ Ăă Ee Êê Ii Oo Ơơ Uu Ưư (with Yy as a variant of Ii). For the six contrastive tones, the first is left unmarked in spelling, while the remainder are shown with an acute accent, a grave accent, a hook, a tilde and a dot-under respectively. Tones 2 to 5 thus give rise to double accents over the letter in the cases of Ấấ Ầầ Ẩẩ Ẫẫ Ắắ Ằằ Ẳẳ Ẵẵ Ếế Ềề Ểể ỄễỐố Ồồ Ổổ Ỗỗ. For example, in ấ (a with an acute accent over a circumflex) the acute shows high tone (tone 2), while the circumflex indicates the mid vowel quality.
In pedagogical and philological works on Latin and other old languages there is a convention of showing that a vowel may be either short or long by placing both short and long signs (breve and macron) over the letter, with the breve on top. This is not found in any everyday orthographies, and Unicode does not provide for it explicitly.
2.15 Typography
Typists often had only one version of a particular diacritic available (if that). When attached to a variety of base letters, a single version of a diacritic did not always give very satisfactory results. For example, the circumflexes in î and Ô ought ideally to be at quite different heights. The ones in Î and Ŵ ideally require different horizontal positioning, corresponding to the very different widths of the baseforms.This is why printers (and now computer screens) normally prefer a ready-made combination of base form and diacritic.
The difficulty of finding room for a diacritic above an upper-case letter has led to the convention sometimes applied to French spelling, namely that acute, grave and circumflex accents may be omitted on a capital letter. To compose a document containing them in MS Word it may be necessary to check a box under Tools/Options/Edit, ‘Allow accented uppercase in French’.
That brings us to the end of the diacritics placed above the letter. We turn now to those placed somewhere else.
3. Diacritics through and below
Unlike diacritics over, most of those positioned through or under the base letter are normally attached to it rather than detached.
3.1 Slash /
Two diacritics are placed through the letter rather than above or below it. The first is the one seen in the Danish-Norwegian letter Øø. This symbolizes a half-close front rounded vowel, and the IPA adopted the lower-case letter as a phonetic symbol with the same meaning.
There is some doubt as to the appropriate name for this diacritic. The first edition of the Unicode standard (1991) called it slash, and indeed it resembles the forward slash or solidus /. By the third edition (2000), Unicode has altered this to ‘stroke’. This term is open to the objection that Unicode also uses ‘stroke’ as the name for the bar (3.2). Thus the earlier ‘slash’ seems to be less open to misinterpretation.
The other orthographic diacritic that uses a through slash is the Polish Łł. This stands for what was historically a velarized lateral (IPA [ɫ]), but in modern Polish is a semivowel [w]. It is seen in many Polish names, such as Wojtyła, Wałęsa, Łódź. For a useful discussion of its typographical design features, see Twardoch 1997.
3.2 Bar -
The other diacritic placed through a letter is the bar. It differs from the slash by being horizontal rather than sloping. It is seen, for example, in the Croatian letter Đđ, which represents a palatalized [dʲ], and indeed is alternatively written as the digraph dj. The same letter Đđ in the Vietnamese alphabet stands for [d] (while plain Dd stands for a dental fricative [ð]). Barred Đđ is also used in writing some varieties of Sámi (Lappish), as is the parallel barred Ŧŧ. In Sámi these letters stand for fricatives of the [ð θ] type. Typographically, the upper-case barred Đ is not necessarily distinguished from the uppercase Icelandic edh, Ð. However the lower-case characters are distinct: Croatian-Vietnamese-Sámi đ but Icelandic-Faeroese-Old English ð.
In Maltese, barred Ħħ represents a voiceless pharyngeal fricative, and the IPA has adopted the lower-case letter as the phonetic symbol for this sound.
As far as standard Latin-alphabet orthographies are concerned, it appears that the slash and the bar are in complementary distribution, so that the terminological problem over ‘stroke’ is perhaps irrelevant. However, when we consider phonetic symbols we must distinguish them. The IPA includes not only the slashed ø but also the barred ɵ. The latter stands for a rounded schwa, i.e. a central rather than a front vowel. (It is also, regrettably, subject to confusion with the theta θ, which derived from the Greek alphabet and incorporates no diacritic.) Americanist non-IPA phonetic usage includes a barred‑l ƚ, which is in principle distinct from the Polish slashed‑l ł. This character stands for a voiceless lateral, IPA [ɬ]. However, the only specimen of Navajo orthography I have found on the web, Ts'óshí 1982, uses a Polish-style ł instead.
In Polish, lastly, the standard z‑dot Żż is sometimes replaced, in handwritten or decorative styles, by a barred Z̵z̵.
3.3 Horn ̛
Vietnamese spelling requires not only a large number of letters with diacritics, but also the special hooked vowel letters Ơơ and Ưư. These are on the borderline between letter-plus-diacritic and separate letter. However, they are clearly based on Oo Uu,from which they differ by the addition of a horn attached the right side of the letter. They represent the unrounded mid and close back vowels, [ɤ ɯ].
3.4 Cedilla ¸
Various kinds of tail can be attached to letters. The best known is the cedilla seen in the French Çç. In shape it is similar to a comma, but different in that it resembles a small figure 5 without the top bar. In French it symbolizes simple [s], the sound also represented by plain c before the letters e, i, y. This letter is also used in modern Turkish spelling, but there it stands for a voiceless palatoalveolar affricate, IPA [ʧ] (as against the simple c, which stands for the voiced equivalent, [ʤ]).
In Turkish a cedilla is also used with s, thus Şş, standing for a voiceless palatoalveolar fricative, IPA [ʃ]. This letter is also used in Romanian, with the same meaning; and Romanian spelling also has a cedilla‑t, Ţţ, which stands for a dental affricate, [ts].
3.5 Comma ,
In Latvian spelling there is a diacritic very similar to a cedilla, but its shape is rather that of a comma. It symbolizes various ‘soft’ (palatal or palatalized) consonants: Ķķ Ļļ Ņņ Ŗŗ. There is also an upper-case Ģ, but the corresponding lower-case letter has its diacritic placed above, thus ģ. The reason for this change in position for the diacritic is obvious: the letter g, with its descender below the line, lacks space for a diacritic below. The raised comma is also reversed, becoming like an opening single quote.
In Romanian typography a comma may actually be preferred to a cedilla on Şş and Ţţ. The Unicode standard now, in the third edition, provides separate codings for these four characters so that either cedilla or comma may be specified for Romanian.
3.6 Tail (ogonek) ˛
The tail used in Polish spelling, known by its Polish name as an ogonek, is found in the letters Ąą and Ęę. It denotes a nasalized, or formerly nasalized, vowel; in many positions these letters nowadays stand for a vowel plus a nasal consonant.
The neighbouring language, Lithuanian, also uses this diacritic, indeed more widely, since it is seen in Ąą Ęę Įį Ųų. In Lithuanian it indicates merely a long vowel. The remaining vowel letter with ogonek, Ǫǫ, is used in the spelling of Sámi and Old Icelandic.
Typographically, the Polish tail "should be smoothly connected to the base glyph, it should be a part of the glyph" (Twardoch 1997). Furthermore, "it should be noted that the Polish and Lithuanian traditions in drawing the ogonek differ."
In Americanist transcriptions/orthographies of Amerindian languages, the tail is used to show nasalization. Thus Ąą Ęę Įį Ǫǫ are used in the orthography of Navajo, as seen in Ts'óshí 1982. They may in turn be combined with an acute accent.
3.7 Dot ̣
The last of the diacritics found in established orthographies is a simple dot below the letter. It is used in Vietnamese, where it is a tone mark symbolizing a combination of low tone and glottalized or tense voice: Ạạ Ẹẹ Ịị Ọọ Ợợ Ụụ Ựự Ỵỵ. As noted above, Vietnamese spelling allows the accumulation of two diacritics on the same letter. Hence this dot can accompany various diacritics above the letter: Ậậ Ặặ Ệệ Ộộ.
In Yoruba, a dot below is used for two purposes. In Ẹẹ and Ọọ it denotes a half-open vowel (nowadays classified by phoneticians as characterized by the absence of advanced tongue root, -ATR), as against the half-close, advanced-tongue-root vowels written as plain Ee Oo. These dotted letters can be combined with acute or grave tonemarks, e.g. ẹ́ ọ̀. Dotted Ṣṣ represents a palatoalveolar fricative, IPA [ʃ]. In some fonts or styles a subscript vertical line is used instead: E̩e̩ O̩o̩ S̩s̩. For example, in Bamgboṣe 1966 the diacritic is printed as a dot in the serif font of the main text, but as a vertical line in the sans serif font of the examples. According to Hein 1996, although the dot is widely used, purists prefer the vertical line. In the orthography of another Nigerian language, Ibo (Igbo), the dot is used only for -ATR vowels, in Ịị Ọọ Ụụ.
We also find the dot in transliterations (romanizations) of languages that use a non-Latin alphabet. It is used, for example, in the romanization of Hindi and other languages of South Asia, to represent retroflex consonants, thus Ṭt ̣ Ḍḍ Ṇṇ Ṣṣ (= IPA [ʈ ɖ ɳ ʂ]). It is also used in the romanization of Arabic, to represent the so-called ‘emphatic’ consonants, Ṭṭ Ḍḍ Ṣṣ, which phonetically are characterized by pharyngealization (= IPA [tˁ dˁ sˁ]).
This brings us to the end of the catalogue of diacritics used in Latin-alphabet orthographies. We leave aside the many other diacritics used in phonetic notation or in mathematics. We finish by looking at some practical considerations.
4. Coding and keyboarding
4.1 The seven-bit problem
Some years ago any kind of diacritic presented a problem to computer users. Indeed, it is not so very long since computers were unable to cope with anything beyond the 26 upper-case and 26 lower-case letters of the Latin alphabet, along with the numerals and a few punctuation and other marks.
These were the ‘printable characters’ of the 7-bit ASCII code. There are still applications (e.g. some e-mail clients) that are restricted to these 94 characters (plus the space character). They are displayed in Fig. 1.
| □ ! " # $ % & ' ( ) * + , - . / |
|---|
| 0 1 2 3 4 5 6 7 8 9 : ; < = > ? |
| @ A B C D E F G H I J K L M N O |
| P Q R S T U V W X Y Z [ \ ] ^ _ |
| ` a b c d e f g h i j k l m n o |
| p q r s t u v w x y z { | } ~ □ |
Fig.1. These 96 characters comprise the ASCII character set. The first is a space character, the last is a control character (DEL), leaving 94 visible characters.
Those who wish to use letters with diacritics cannot do so while remaining within ASCII. A text written in ASCII must either forego them, or else use various substitute workarounds involving digraphs. For example, a' or a+ might be used in place of á, and s', s`, or s^ in place of ś or š or ŝ.
(Just as accented letters can be ‘ASCII-ized’, so can other scripts. The SAMPA phonetic alphabet, for example, is an ASCII-ization of the entire International Phonetic Alphabet, replacing all non-ASCII characters by ASCII surrogates. See the SAMPA website, www.phon.ucl.ac.uk/home/sampa/home.htm.)
4.2 Eight-bit partial solutions
With the move to 8-bit text representations, a further 128 code positions became available. In countries speaking English or other Western European languages, this range was exploited by extending ASCII to provide additional letters for those languages. The Latin-1 character set (ISO/IEC 8859-1) comprises ASCII plus the additional characters they need — the letters Ææ Ðð Þþ ß, and a range of letters with diacritics: à á â ã ä å ç è é ê ë ì í î ï ñ ò ó ô õ ö ù ú û ü ý ÿ and their upper-case counterparts (fig. 2). This provides for all the needs of German, Spanish, French (except for the ligature œ), Italian, Portuguese and the Scandinavian languages.
| ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ □ ® ¯ |
|---|
| ° ± ² ³ ´ µ ¶ · ¸ ¹ º » ¼ ½ ¾ ¿ |
| À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î Ï |
| Ð Ñ Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß |
| à á â ã ä å æ ç è é ê ë ì í î ï |
| ð ñ ò ó ô õ ö ÷ ø ù ú û ü ý þ ÿ |
Fig.2. Latin-1 Supplement. The first character is a non-breaking space, and another is a soft hyphen. This leaves 94 visible characters.
But Latin-1 offers little or nothing for the Latin-alphabet languages of Eastern Europe, or for those that use Cyrillic, Greek, or other scripts. This led to the creation of a number of other 8-bit character sets based on ASCII but extending it in other ways. They include Latin-2 for Eastern Europe (Polish, Czech, Hungarian etc.), Latin-3 nominally for Southern Europe (Turkish, Maltese, Esperanto), Latin-4 for the Baltic countries (Lithuanian, Latvian), and so on. Accordingly, Latin-2 includes ready-made accented characters such as ą č ł ś, while Latin-3 includes ĉ ğ ħ ş and Latin-4 ā į ķ. Other ASCII extensions provided for the Cyrillic, Greek, Arabic and Hebrew alphabets respectively. All retain the ASCII values for the first 128 code positions. All are standardized as parts of ISO/IEC 8859.
One particular problem here is that those who needed to combine various languages within a single document often have to switch character set in passing from one language to the other. For example, Polish is not fully covered in Latin-4, and Lithuanian is not fully covered in Latin-2. An 8-bit document combining Polish and Lithuanian will have to switch character sets each time it switches language. The same applies in the case of Russian and French or Greek and German.
But text processing based on a single byte — eight bits — is unacceptably restricted. Even though still used in most computing systems, the ASCII 7-bit code space and its 8-bit extensions are inexorably limited to 128 and 256 code positions respectively. This is inadequate in the global computing environment. Meanwhile, users of other scripts — notably the Chinese, Japanese and Koreans — have already devised a variety of multi-byte solutions.
4.3 The sixteen-bit solution
Written Chinese calls for thousands of distinct characters. Japanese and Korean have their own scripts but also make use of Chinese characters. In East Asia there are a number of mutually incompatible multi-byte encoding standards to address this problem. Hopefully this situation will in time be rectified by the general adoption of the internationally agreed standard, Unicode.
With the arrival of MS Word 97 (and its successors Word 2000, Word XP), users of Windows 95 or Windows NT (and now Windows me, Windows 2000 Pro, and Windows XP Home/Pro) have at last acquired the ability to use an extended range of characters within a document without switching character set. These recent versions of Word can also save documents as HTML, encoding the characters in Unicode form as numeric entities or as UTF-8 (see below). Furthermore, Windows is now routinely supplied, at least in Europe, with fonts incorporating an extensive subset of Unicode known as WGL4. This comprises everything needed for the languages of Europe, including the characters covered in the various ASCII extensions mentioned above.
The Windows laptop I acquired in mid-2000 came with Unicode fonts going beyond WGL4 to include Hebrew and Arabic as well as assorted arrows, mathematical symbols, and the like. One font supplied (Lucida Sans Unicode) even incorporated the entire Unicode range of IPA phonetic symbols.
Microsoft has made available a Windows font, Arial Unicode MS, which covers all of Unicode version 2.0, some 51,180 glyphs. It is included with Microsoft Office 2000. For a time it could be downloaded free of charge from the Microsoft website, although this facility has now been withdrawn.
The web is only gradually adopting Unicode, as ordinary users gradually acquire the software that can cope with it. Of currently available browsers, Internet Explorer 5 and 6 appear able to display any Unicode character (subject, of course, to a suitable Unicode font having been installed). Netscape Navigator 4 lagged behind, though Navigator 6 copes excellently. [Updated 2001-2002]
4.4 Unicode
Unicode was devised, and is maintained, by the Unicode Consortium with the participation of all the major computer manufacturers and software companies, including Apple, Compaq, Hewlett-Packard, IBM, Microsoft, and Sun. It is the default encoding for HTML and XML.
Every Unicode character is identified by a hexadecimal code number of four (or more) digits, formulaically U+xxxx etc.. Two hexadecimal digits are required to encode one byte (256 code positions); thus four digits encode two bytes (65,536 codepositions). Version 3 of Unicode contained 49,194 characters from the worldʼs scripts (the current version 4 contains many more). These include Middle Eastern, South Asian, and East Asian scripts. Over 25,000 of these are Chinese characters.
For example, a has the code number U+0061. This is identical to its ASCII number, hex 61, which corresponds to decimal 97. Danish-Norwegian-Swedish å is U+00E5, identical to its Latin-1 number, decimal 229.
- Block 0041-007A is known as Basic Latin and is identical with ASCII. The Unicode number is the ASCII number with two leading zeroes.
- Block 0080-00FF is the Latin-1 Supplement and is identical with the Latin-1 extension of ASCII.
The remaining accented letters, and various punctuation and other related characters, are found in three further blocks.
- Block 0100-017F is called Latin Extended-A. When added to the Basic Latin and Latin-1 Supplement blocks, it provides for virtually all European Latin-alphabet languages.
- Block 0180-024F is called Latin Extended-B. With its help one can also, for example, write the hooked letters of Hausa and the tone-marked vowels of Chinese Pinyin. It also includes an exceptional set of digraph codes for the Serbo-Croat digraphs discussed above (1.3). This is useful in certain computer applications, which may need to perform one-to-one transliteration between the Latin and Cyrillic alphabets. Varying forms of capitalization then require that three case-forms be supplied for each, rather than the usual two (uppercase and lowercase): all-uppercase DZ, titlecase Dz, and lowercase dz, each of which has a separate Unicode number
- Block 1E00-1EFF is called Latin Extended Additional. It comprises only letters with diacritics. Among them are the double diacritics of Vietnamese and the dots under used for the transliteration or romanization of Indian languages.
Unicode provides for several different forms of character encoding. One is the default 16-bit form, using the raw hexadecimal code numbers. It is also known as UTF-16. Another form of encoding is known as UTF-8, designed for ease of use with existing ASCII-based systems. It is a variable-length encoding, in which part of the first byte indicates the number of bytes to follow within the byte sequence that encode the given character. The ASCII range (0000-007F) is encoded as a single byte. Latin 1 Supplement, Latin Extended-A, and Latin Extended-B characters are encoded as two bytes, as are Middle Eastern and Indian scripts. Chinese characters are encoded as three bytes, as are those of Latin Extended Additional. Straightforward algorithms are available to convert UTF-16 to UTF-8 or vice versa.
Diacritics are represented in Unicode both as separate characters and as part of prefabricated characters. They have been allocated Unicode numbers as follows:
- as parts of ready-made characters, in the Latin blocks discussed above.
- as combining diacritical marks, in the block 0300-0362. For example, the grave accent is U+0300. Combining diacritical marks are ordered after the base letter to which they refer. Thus the ad-hoc combination s with a grave accent would be represented by the code for s followed by the code for the grave accent. The sequence a, combining diaeresis, u unambiguously encodes äu, not aü.
- as separate spacing modifier letters. Some are found in the Basic Latin or Latin-1 Supplement blocks, others in the block 02B0-02FF. They cater for occasions when a diacritic needs to be referred to independently of any base character with which it might be associated.
4.5 Keyboarding
Various standard keyboards are in use in different countries. They take different approaches to the question of how accented characters are entered.
Windows users can install a number of different logical keyboards and switch between them. One might normally use the UK keyboard, but switch to an American, a Hungarian or a Russian keyboard when required. This will normally be associated with switching between different code pages.
- In some cases, a ready-made character may be assigned a key and entered by a single keystroke. This is typically the case with ä and ö on German and Swedish keyboards, and with é on French ones.
- In other cases, the diacritic is assigned to a dead key. The user first types the diacritic, then the base character. This was the system used with many mechanical typewriters. It is found on Eastern European Windows keyboards, e.g. Czech.
- A ready-made character may be assigned to a key combination, requiring that the AltGr key, or Ctrl and Alt together, be held down while a key is struck. This method is used for the euro symbol, €, on the current UK Windows keyboard.
- Characters in the range up to U+00FF (decimal 255) can be entered by using the Alt key and the numerical keypad. The code must be entered in decimal with a leading zero. Thus Å, U+00C5, ASCII C5 hex (= 197 decimal), can be inserted by typing 0197 on the numerical keypad while holding down the Alt key.
- For the purposes of an HTML document, such as a web page, any Unicode character can be encoded as a numeric entity. The character ń, n‑acute, has the Unicode hexadecimal number 0144, for which the decimal equivalent is 324. So it can be represented in an HTML document as ń or as ń. These codes will be rendered by a Unicode-compliant browser as ń.
- Applications may provide ready-made shortcuts or macros. My version of Word allows me to enter à as Ctrl‑`, a. The letter Å can be entered as Ctrl-Shift-@, Shift-A. In the versions of MS Word 97/2000 supplied in Western Europe, no macros are provided for characters other than those of Latin-1.
- Applications may provide an Insert Symbol or Insert Character command, allowing one to choose a character from a menu.
- Applications may allow the user to define a suitable macro. The procedure is very straightforward in Word: Insert, Symbol, choose the character, Shortcut Key, choose the key combination, Assign, Close. In Word it is also possible to use the AutoCorrect feature to achieve thesame result: see the article Eureka by Quirke and Holser, and my addendum to it.
Final words
At the time I wrote the original article we were still waiting for complete Unicode fonts. By summer 2001 this deficiency had been remedied, for Windows users at least, by the Arial Unicode MS mentioned above (4.3). See further my article The IPA in Unicode and Alan Wood's Unicode Resources. Subsequently Victor Gaultney made his Gentium font available, for both Windows and Macintosh systems, and in November 2002 I changed the style sheet of this document to make it the font of choice.
The problem of entering, displaying, processing and printing diacritics, if not yet solved everywhere, is at least on the way to a solution. We are moving from a time in which a diacritic was a problem to a time in which all things are possible.
SOMMAIRE
Les signes diacritiques et les ordinateurs multilingues. Les signes diacritiques — signes graphiques adjoints au-dessus, à travers, ou au-dessous des lettres — se trouvent dans les orthographies de beaucoup de langues avec le but de remédier les insuffisances de l’alphabet latin ordinaire. L’auteur catalogue les divers signes diacritiques dont on se sert pour orthographier les langues, en signalant leurs aspects et leurs applications. Il analyse en plus les problèmes d’utilisation des lettres accentuées dans un milieu d’ordinateurs multilingues, et discute jusqu’à quelle mesure ces problèmes ont été resolues, avec un appel particulier à l’Unicode.
RESUMO
Ortografiaj diakritiloj kaj multlingva komputado. Diakritiloj (kromsignoj) —supersignoj, trasignoj kaj subsignoj — estas uzataj en multaj ortografioj por ripari la mankojn de la ordinara Latina alfabeto. La aŭtoro katalogas la kromsignojn troviĝantajn en la ortografio de diversaj lingvoj, klarigante kiel ili aspektas kaj kiel ili estas uzataj. Li analizas ankaŭ la problemojn leviĝantajn ĉe la uzo de kromsignitaj literoj en multlingva komputada medio, kaj diskutas ĝis kiu grado oni trovis solvon al tiuj problemoj, kun aparta konsidero de Unikodo.
REFERENCES
Orthographic information for many of the languages mentioned in the article isto be found in Comrie (ed.), 1987. In that book I found Đình-Hoà Nguyễn’s chapter on Vietnamese particularly useful. For Icelandic I have drawn on Böðvarsson 1977, and for Welsh on Thomas 1996. In revising this article in summer 2001 I consulted Alvestrand 1995 and Hein 1996, though these useful databases do not appear to be 100% reliable. There is extensive documentation of fonts, code pages and character sets on the Microsoft website, www.microsoft.com/typography.
Alvestrand, Harald Tveit, 1995. Characters and character sets for various languages. http://www.alvestrand.no/ietf/lang-chars.txt
Bamgboṣe, Ayọ, 1966. A grammar of Yoruba. Cambridge: Cambridge University Press.
Böðvarsson, Árni, 1977. Islanda lingvo. Enkonduko en la gramatikon.Reykjavík: Islanda Esperanto-Asocio.
Comrie, Bernard (ed.), 1987. The World’s Major Languages. London: Croom Helm.
Haupenthal, Reinhard (ed.), 2000.Festlibro por André Albault. Malaucène: Edition Iltis.
Hein, Indrek, 1996. Letter database. Institute of the Estonian Language. http://www.eki.ee/index.html.en
Pullum, Geoffrey K. and William A. Ladusaw, 1996. Phonetic symbol guide. Second edition. Chicago: University of Chicago Press.
Sampson, Geoffrey, 1985. Writing systems. London: Hutchinson.
Taylor, Conrad. http://www.ideography.co.uk/library/pdf/charsets.pdf
Thomas, Peter Wynn, 1996. Gramadeg y Gymraeg. Caerdydd: Gwasg Prifysgol Cymru.
Ts'óshí 1982. Sacred mountains. In Between Sacred Mountains: Navajo Stories and Lessons from the Land assembled by the Rock Point Community School. http://www.hanksville.org/voyage/poems/motherearth/sacredmtnsnav.php3
Twardoch, Adam, 1997. Polish diacritics: how to?. http://studweb.euv-frankfurt-o.de/twardoch/f/en/typo/ogonek/intro.html
Unicode Consortium, The, 2000, The Unicode Standard, Version 3.0. Reading, MA: Addison Wesley Longman.
This article originated as a lecture given at the World Esperanto Congress held in Prague, 1996. It was published in book form in that language as a chapter of Haupenthal (ed.) 2000. This English version has been very extensively revised and updated. Last update: 2001 10 24, minor corrections 2002 02 16, 2002 11 19, 2005 01 11, 2006 03 27