File: ip-anon.py (original) (raw)
#!/usr/bin/python3 """
ip-anon.py, a tactical script coded in Python3 Why this script? - https://learning-python.com/privacy-policy.html Admin: © 2019-2020, by M. Lutz (learning-python.com), no warranties provided.
For all HTML pages in a website's folder tree, add a line to Google Analytics JavaScript code to anonymize IP addresses, iff this line has not already been added by static template expansion (e.g., by genhtml) or manual edits. See main logic at the end of this file for command-line usage or the console screenshot at https://learning-python.com/ip-anon.png.
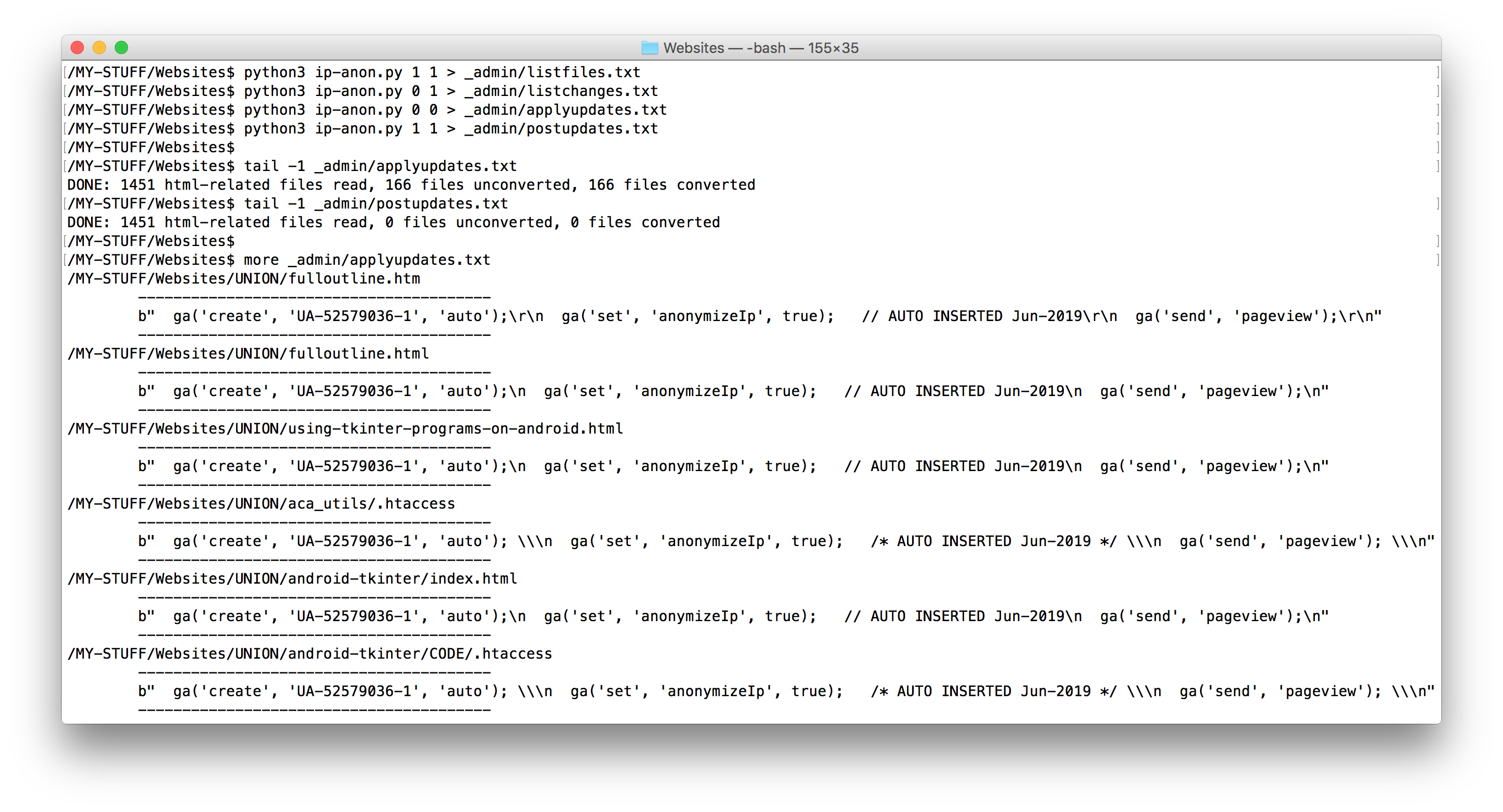{kind=link}
This can be used as a one-time update for all the web pages in a site, and rerun by build scripts to catch new files. In the host site's case, it was used to temporarily convert code in oddballs that are edited manually outside the website tree and copied in (e.g., program docs and Apache auto-index text) or are otherwise outside the scope of template expansion, until these outliers can be manually updated and propagated to the site folder. It:
- Handles mixed Unicode encodings by using bytes-mode files and ASCII-only text
- Handles mixed eoln (end-of-line) sequences by inspecting file content
- Converts code in both HTML files and .htaccess files' IndexHeadInsert text
- Assumes a specific code/line structure - adapt for your files as needed
CONFIGURATION Edit the code settings below to tailor this script for your site as needed. You may also need to expand the "isHtml" test below to check/fix additional file types. At this site, just one other file was harboring the analytics code and required a manual edit - a ".txt" HTML template used by the showcode.py file-viewer script. Your site's mileage may naturally vary.
UNICODE CAUTION This script's use of bytes-mode files and ASCII-text matching assumes that all the HTML-related files in your site's tree use Unicode encodings that store ASCII text with one ASCII byte per character. This scheme works for mixes that include UTF-8, Latin-1, CP-1252, and others, but will fail to find matches in any UTF-16 or UTF-32 files lurking in your tree (their ASCII text is not simple bytes). If the latter applies, you may need to instead use text-mode files and try multiple Unicode encodings in turn until one succeeds. See this site's genhtml and showcode programs for examples of this approach. Luckily, UTF-16 and its multibyte ilk are rarely used for web content today.
"""
import os nhtml = nsans = nfixed = 0 # global counters
Edit the following uppercase settings for your site's files
Sitedir = '/Users/me/MY-STUFF/Websites/UNION' # Catalina path [Apr-2020] Copymodtimes = True # keep modtimes? [Apr-2020]
Sendcmd = b"ga('send', 'pageview');" # insert set before this Anoncmd = b"ga('set', 'anonymizeIp', true);"
Htmlfiledoc = b' // AUTO INSERTED Jun-2019' Htaccessdoc = b' /* AUTO INSERTED Jun-2019 */' # where eolns stripped
Addline = b' ' + Anoncmd + Htmlfiledoc # fixed for htaccess later
Edit the following if your site's filenames or needs differ
isHtml = lambda filename: filename.lower().endswith(('.html', '.htm')) isHtaccess = lambda filename: filename.lower() == '.htaccess'
def convert(path, isHtaccess, nofileupdates=True): """ ------------------------------------------------------------------------------ Convert a single file, adding a JavaScript "set" line before "send".
Auto-inserts work, but some files are copied from originals in Code/
and still need to be manually patched there too. Per ahead, this is
bytes-based (to avoid encoding guesses), and checks the file to see
which eoln to use on the added line (to retain the file's eoln formatting).
Special case: adds a trailing '\' in Apache .htaccess IndexHeadInsert text.
For .htaccess, also replaces '//' comment in added line with '/* */' form:
a '//' line comment won't work, because Apache strips eolns in the inserted
text - all lines after the '//' would be ignored by JavaScript as comment.
New [Apr-2020]: Copymodtimes=True retains a changed file's prior modtime,
so it won't register as a difference in incremental backups; use this for
site publishing scripts that rerun files though this script on each build,
else this script's change can mask the status of files' actual content.
------------------------------------------------------------------------------
"""
global nfixed
lines = open(path, 'rb').readlines()
# use the same elon as file
beoln = b'\r\n' if any(b'\r\n' in x for x in lines) else b'\n'
# add trailing slash in .htaccess
addline = (Addline + b' \\' if isHtaccess else Addline) + beoln
# change comment forms for code in .htaccess insert
if isHtaccess: addline = addline.replace(Htmlfiledoc, Htaccessdoc)
for ix in range(len(lines)):
if lines[ix].lstrip().startswith(Sendcmd):
lines.insert(ix, addline) # add set before send
print('\t' + '-'*40, end='\n\t')
print(b''.join(lines[ix-1:ix+2])) # preview the update
print('\t' + '-'*40)
if nofileupdates:
pass
else:
nfixed += 1
if Copymodtimes:
prevtime = os.path.getmtime(path)
file = open(path, 'wb')
file.writelines(lines) # update the file
file.close()
if Copymodtimes:
os.utime(path, (prevtime, prevtime))
break
else:
print('****NOT AUTO CONVERTED:', path) # matching differeddef findAndConvert(listfilesonly=False, nofileupdates=True): """ ------------------------------------------------------------------------------ Find HTML files without a JavaScript "set" line, and pass on to convert().
This now uses bytes-mode files to avoid Unicode encodings altogether. This
scheme works here because text matching is ASCII only. By contrast, genhtml
tags matched may be any text (including non-ASCII), and showcode's text reply
requires an encoding type for proper display in web browsers. Bytes mode
here sidesteps the issue of guessing encodings in a mixed-encoding tree.
Caveat: bytes mode also assumes all HTML files use encodings that store ASCII
text as simple bytes; they do at this site, but see UNICODE CAUTION above.
About eolns: naively adding a '\n' on Unix would result in mixed '\r\n' and
'\n' eolns in files created in Windows, because bytes files do not map eolns
to/from '\n'. Addressed by a file precheck to determine which to use (and
assume the file's eolns are uniform); this seems better than text mode, which
would map all eolns read and written to Unix's '\n', thereby dropping any
Windows eolns in the (few) files that have them.
Prior (abandoned) text-mode notes: the latin1 encoding works as a utf8 fallback
(instead of cp1252) because of "passthrough": if text is both loaded and saved
as latin1, any cp1252 bytes are retained intact because they are loaded and
saved as their raw byte values by the latin1 decoder (see genhtml, showcode).
------------------------------------------------------------------------------
"""
global nhtml, nsans
for (dir, subs, files) in os.walk(Sitedir):
for file in files:
if isHtml(file) or isHtaccess(file):
nhtml += 1
path = os.path.join(dir, file)
byts = open(path, 'rb').read()
if (Sendcmd in byts) and (Anoncmd not in byts):
nsans += 1
print(path)
if not listfilesonly:
convert(path, isHtaccess(file), nofileupdates)if name == 'main': # #----------------------------------------------------------------------------- # When run as a script: # python3 ip-anon.py 1 1 => list unconverted files only # python3 ip-anon.py 0 1 => list unconverted files and preview changes only # python3 ip-anon.py 0 0 => list both and apply updates to unconverted files #----------------------------------------------------------------------------- # import sys if len(sys.argv) == 3: listfilesonly, nofileupdates = (int(x) for x in sys.argv[1:]) # 2 optional args else: listfilesonly, nofileupdates = False, True # show filenames + preview changes
findAndConvert(listfilesonly, nofileupdates)
print('DONE: %d html-related files read, %d files unconverted, %d files converted'
% (nhtml, nsans, nfixed))