Using custom Element classes in lxml (original) (raw)
lxml has very sophisticated support for custom Element classes. You can provide your own classes for Elements and have lxml use them by default for all elements generated by a specific parser, only for a specific tag name in a specific namespace or even for an exact element at a specific position in the tree.
Custom Elements must inherit from the lxml.etree.ElementBase class, which provides the Element interface for subclasses:
from lxml import etree
class honk(etree.ElementBase): ... @property ... def honking(self): ... return self.get('honking') == 'true'
This defines a new Element class honk with a property honking.
The following document describes how you can make lxml.etree use these custom Element classes.
Contents
- Background on Element proxies
- Element initialization
- Setting up a class lookup scheme
- Generating XML with custom classes
- Implementing namespaces
Background on Element proxies
Being based on libxml2, lxml.etree holds the entire XML tree in a C structure. To communicate with Python code, it creates Python proxy objects for the XML elements on demand.
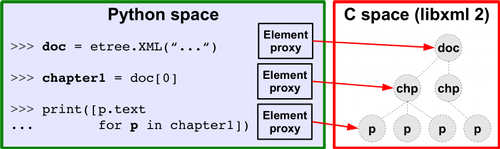
The mapping between C elements and Python Element classes is completely configurable. When you ask lxml.etree for an Element by using its API, it will instantiate your classes for you. All you have to do is tell lxml which class to use for which kind of Element. This is done through a class lookup scheme, as described in the sections below.
Element initialization
There is one thing to know up front. Element classes must not have an __init___ or __new__ method. There should not be any internal state either, except for the data stored in the underlying XML tree. Element instances are created and garbage collected at need, so there is normally no way to predict when and how often a proxy is created for them. Even worse, when the __init__ method is called, the object is not even initialized yet to represent the XML tag, so there is not much use in providing an __init__ method in subclasses.
Most use cases will not require any class initialisation or proxy state, so you can content yourself with skipping to the next section for now. However, if you really need to set up your element class on instantiation, or need a way to persistently store state in the proxy instances instead of the XML tree, here is a way to do so.
There is one important guarantee regarding Element proxies. Once a proxy has been instantiated, it will keep alive as long as there is a Python reference to it, and any access to the XML element in the tree will return this very instance. Therefore, if you need to store local state in a custom Element class (which is generally discouraged), you can do so by keeping the Elements in a tree alive. If the tree doesn't change, you can simply do this:
proxy_cache = list(root.iter())
or
proxy_cache = set(root.iter())
or use any other suitable container. Note that you have to keep this cache manually up to date if the tree changes, which can get tricky in cases.
For proxy initialisation, ElementBase classes have an _init()method that can be overridden, as oppose to the normal __init__()method. It can be used to modify the XML tree, e.g. to construct special children or verify and update attributes.
The semantics of _init() are as follows:
- It is called once on Element class instantiation time. That is, when a Python representation of the element is created by lxml. At that time, the element object is completely initialized to represent a specific XML element within the tree.
- The method has complete access to the XML tree. Modifications can be done in exactly the same way as anywhere else in the program.
- Python representations of elements may be created multiple times during the lifetime of an XML element in the underlying C tree. The _init() code provided by subclasses must take special care by itself that multiple executions either are harmless or that they are prevented by some kind of flag in the XML tree. The latter can be achieved by modifying an attribute value or by removing or adding a specific child node and then verifying this before running through the init process.
- Any exceptions raised in _init() will be propagated through the API call that lead to the creation of the Element. So be careful with the code you write here as its exceptions may turn up in various unexpected places.
Setting up a class lookup scheme
The first thing to do when deploying custom element classes is to register a class lookup scheme on a parser. lxml.etree provides quite a number of different schemes that also support class lookup based on namespaces or attribute values. Most lookups support fallback chaining, which allows the next lookup mechanism to take over when the previous one fails to find a class.
For example, setting the honk Element as a default element class for a parser works as follows:
parser_lookup = etree.ElementDefaultClassLookup(element=honk) parser = etree.XMLParser() parser.set_element_class_lookup(parser_lookup)
There is one drawback of the parser based scheme: the Element() factory does not know about your specialised parser and creates a new document that deploys the default parser:
el = etree.Element("root") print(isinstance(el, honk)) False
You should therefore avoid using this factory function in code that uses custom classes. The makeelement() method of parsers provides a simple replacement:
el = parser.makeelement("root") print(isinstance(el, honk)) True
If you use a parser at the module level, you can easily redirect a module level Element() factory to the parser method by adding code like this:
module_level_parser = etree.XMLParser() Element = module_level_parser.makeelement
While the XML() and HTML() factories also depend on the default parser, you can pass them a different parser as second argument:
element = etree.XML("") print(isinstance(element, honk)) False
element = etree.XML("", parser) print(isinstance(element, honk)) True
Whenever you create a document with a parser, it will inherit the lookup scheme and all subsequent element instantiations for this document will use it:
element = etree.fromstring("", parser) print(isinstance(element, honk)) True el = etree.SubElement(element, "subel") print(isinstance(el, honk)) True
For testing code in the Python interpreter and for small projects, you may also consider setting a lookup scheme on the default parser. To avoid interfering with other modules, however, it is usually a better idea to use a dedicated parser for each module (or a parser pool when using threads) and then register the required lookup scheme only for this parser.
Default class lookup
This is the most simple lookup mechanism. It always returns the default element class. Consequently, no further fallbacks are supported, but this scheme is a nice fallback for other custom lookup mechanisms. Specifically, it also handles comments and processing instructions, which are easy to forget about when mapping proxies to classes.
Usage:
lookup = etree.ElementDefaultClassLookup() parser = etree.XMLParser() parser.set_element_class_lookup(lookup)
Note that the default for new parsers is to use the global fallback, which is also the default lookup (if not configured otherwise).
To change the default element implementation, you can pass your new class to the constructor. While it accepts classes for element, comment andpi nodes, most use cases will only override the element class:
el = parser.makeelement("myelement") print(isinstance(el, honk)) False
lookup = etree.ElementDefaultClassLookup(element=honk) parser.set_element_class_lookup(lookup)
el = parser.makeelement("myelement") print(isinstance(el, honk)) True el.honking False el = parser.makeelement("myelement", honking='true') etree.tostring(el) b'' el.honking True
root = etree.fromstring( ... '', parser) root.honking True print(root[0].text) comment
Namespace class lookup
This is an advanced lookup mechanism that supports namespace/tag-name specific element classes. You can select it by calling:
lookup = etree.ElementNamespaceClassLookup() parser = etree.XMLParser() parser.set_element_class_lookup(lookup)
See the separate section on implementing namespaces below to learn how to make use of it.
This scheme supports a fallback mechanism that is used in the case where the namespace is not found or no class was registered for the element name. Normally, the default class lookup is used here. To change it, pass the desired fallback lookup scheme to the constructor:
fallback = etree.ElementDefaultClassLookup(element=honk) lookup = etree.ElementNamespaceClassLookup(fallback) parser.set_element_class_lookup(lookup)
root = etree.fromstring( ... '', parser) root.honking True print(root[0].text) comment
Attribute based lookup
This scheme uses a mapping from attribute values to classes. An attribute name is set at initialisation time and is then used to find the corresponding value in a dictionary. It is set up as follows:
id_class_mapping = {'1234' : honk} # maps attribute values to classes
lookup = etree.AttributeBasedElementClassLookup( ... 'id', id_class_mapping) parser = etree.XMLParser() parser.set_element_class_lookup(lookup)
And here is how to use it:
a.honking # id does not match ! Traceback (most recent call last): AttributeError: 'lxml.etree._Element' object has no attribute 'honking'
a[0].honking False a[1].honking True
This lookup scheme uses its fallback if the attribute is not found or its value is not in the mapping. Normally, the default class lookup is used here. If you want to use the namespace lookup, for example, you can use this code:
fallback = etree.ElementNamespaceClassLookup() lookup = etree.AttributeBasedElementClassLookup( ... 'id', id_class_mapping, fallback) parser = etree.XMLParser() parser.set_element_class_lookup(lookup)
Custom element class lookup
This is the most customisable way of finding element classes on a per-element basis. It allows you to implement a custom lookup scheme in a subclass:
class MyLookup(etree.CustomElementClassLookup): ... def lookup(self, node_type, document, namespace, name): ... if node_type == 'element': ... return honk # be a bit more selective here ... ... else: ... return None # pass on to (default) fallback
parser = etree.XMLParser() parser.set_element_class_lookup(MyLookup())
root = etree.fromstring( ... '', parser) root.honking True print(root[0].text) comment
The .lookup() method must return either None (which triggers the fallback mechanism) or a subclass of lxml.etree.ElementBase. It can take any decision it wants based on the node type (one of "element", "comment", "PI", "entity"), the XML document of the element, or its namespace or tag name.
Tree based element class lookup in Python
Taking more elaborate decisions than allowed by the custom scheme is difficult to achieve in pure Python, as it results in a chicken-and-egg problem. It would require access to the tree - before the elements in the tree have been instantiated as Python Element proxies.
Luckily, there is a way to do this. The PythonElementClassLookupworks similar to the custom lookup scheme:
class MyLookup(etree.PythonElementClassLookup): ... def lookup(self, document, element): ... return MyElementClass # defined elsewhere
parser = etree.XMLParser() parser.set_element_class_lookup(MyLookup())
As before, the first argument to the lookup() method is the opaque document instance that contains the Element. The second arguments is a lightweight Element proxy implementation that is only valid during the lookup. Do not try to keep a reference to it. Once the lookup is finished, the proxy will become invalid. You will get an AssertionError if you access any of the properties or methods outside the scope of the lookup call where they were instantiated.
During the lookup, the element object behaves mostly like a normal Element instance. It provides the properties tag, text, tail etc. and supports indexing, slicing and the getchildren(), getparent()etc. methods. It does not support iteration, nor does it support any kind of modification. All of its properties are read-only and it cannot be removed or inserted into other trees. You can use it as a starting point to freely traverse the tree and collect any kind of information that its elements provide. Once you have taken the decision which class to use for this element, you can simply return it and have lxml take care of cleaning up the instantiated proxy classes.
Sidenote: this lookup scheme originally lived in a separate module calledlxml.pyclasslookup.
Generating XML with custom classes
Up to lxml 2.1, you could not instantiate proxy classes yourself. Only lxml.etree could do that when creating an object representation of an existing XML element. Since lxml 2.2, however, instantiating this class will simply create a new Element:
el = honk(honking='true') el.tag 'honk' el.honking True
Note, however, that the proxy you create here will be garbage collected just like any other proxy. You can therefore not count on lxml.etree using the same class that you instantiated when you access this Element a second time after letting its reference go. You should therefore always use a corresponding class lookup scheme that returns your Element proxy classes for the elements that they create. TheElementNamespaceClassLookup is generally a good match.
You can use custom Element classes to quickly create XML fragments:
class hale(etree.ElementBase): pass class bopp(etree.ElementBase): pass
el = hale( "some ", honk(honking = 'true'), bopp, " text" )
print(etree.tostring(el, encoding='unicode')) some text
Implementing namespaces
lxml allows you to implement namespaces, in a rather literal sense. After setting up the namespace class lookup mechanism as described above, you can build a new element namespace (or retrieve an existing one) by calling theget_namespace(uri) method of the lookup:
lookup = etree.ElementNamespaceClassLookup() parser = etree.XMLParser() parser.set_element_class_lookup(lookup)
namespace = lookup.get_namespace('http://hui.de/honk')
and then register the new element type with that namespace, say, under the tag name honk:
namespace['honk'] = honk
If you have many Element classes declared in one module, and they are all named like the elements they create, you can simply usenamespace.update(globals()) at the end of your module to declare them automatically. The implementation is smart enough to ignore everything that is not an Element class.
After this, you create and use your XML elements through the normal API of lxml:
xml = '' honk_element = etree.XML(xml, parser) print(honk_element.honking) True
The same works when creating elements by hand:
honk_element = parser.makeelement('{http://hui.de/honk}honk', ... honking='true') print(honk_element.honking) True
Essentially, what this allows you to do, is to give Elements a custom API based on their namespace and tag name.
A somewhat related topic are extension functions which use a similar mechanism for registering Python functions for use in XPath and XSLT.
In the setup example above, we associated the honk Element class only with the 'honk' element. If an XML tree contains different elements in the same namespace, they do not pick up the same implementation:
xml = ('' ... '' ... '') honk_element = etree.XML(xml, parser) print(honk_element.honking) True print(honk_element[0].honking) Traceback (most recent call last): ... AttributeError: 'lxml.etree._Element' object has no attribute 'honking' print(honk_element[1].text) comment
You can therefore provide one implementation per element name in each namespace and have lxml select the right one on the fly. If you want one element implementation per namespace (ignoring the element name) or prefer having a common class for most elements except a few, you can specify a default implementation for an entire namespace by registering that class with the empty element name (None).
You may consider following an object oriented approach here. If you build a class hierarchy of element classes, you can also implement a base class for a namespace that is used if no specific element class is provided. Again, you can just pass None as an element name:
class HonkNSElement(etree.ElementBase): ... def honk(self): ... return "HONK" namespace[None] = HonkNSElement # default Element for namespace
class HonkElement(HonkNSElement): ... @property ... def honking(self): ... return self.get('honking') == 'true' namespace['honk'] = HonkElement # Element for specific tag
Now you can rely on lxml to always return objects of type HonkNSElement or its subclasses for elements of this namespace:
xml = ('' ... '' ... '') honk_element = etree.fromstring(xml, parser)
print(type(honk_element)) <class 'HonkElement'> print(type(honk_element[0])) <class 'HonkNSElement'>
print(honk_element.honking) True print(honk_element.honk()) HONK
print(honk_element[0].honk()) HONK print(honk_element[0].honking) Traceback (most recent call last): ... AttributeError: 'HonkNSElement' object has no attribute 'honking'
print(honk_element[1].text) # uses fallback for non-elements comment
Since lxml 4.1, the registration is more conveniently done with class decorators. The namespace registry object is callable with a name (or None) as argument and can then be used as decorator.
honk_elements = lookup.get_namespace('http://hui.de/honk')
@honk_elements(None) ... class HonkNSElement(etree.ElementBase): ... def honk(self): ... return "HONK"
If the class has the same name as the tag, you can also leave out the call and use the blank decorator instead:
@honk_elements ... class honkel(HonkNSElement): ... @property ... def honking(self): ... return self.get('honking') == 'true'
xml = '' honk_element = etree.fromstring(xml, parser)
print(type(honk_element)) <class 'honkel'> print(type(honk_element[0])) <class 'HonkNSElement'>