Save the Disappearing Web!: Various Initiatives on Web Archiving (original) (raw)
本記事は日本データベース協会発行『データベースNo.21』(2002)より転載したものです。
消えゆくウェブを救え!
~動き出すウェブ・アーカイビング~
国立国会図書館総務部企画課電子図書館推進室 廣瀬 信己
1. はじめに
"Not Found"
――言わずと知れたエラーメッセージである。ある調査(1)によると、ウェブページの約半数はおよそ二年でアクセスできなくなってしまうという。なぜインターネット上の情報資源はこのように脆く、儚いのだろうか。
紙媒体の資料であれば、図書館や文書館に代表されるように、情報資源の保存を図る社会的システムが存在する。また、紙という物理的媒体に固定されていることから、数十年、数百年後に、埋もれていた文献が発見されることも少なくない。一方、インターネットに象徴されるデジタル情報資源は、ひとたび更新、削除等が行われると、それ以前の情報は跡形もなく消滅してしまう。インターネット上を流通する社会的に有用かつ莫大な情報は、ただ消費されるためだけに生産され、そして日々失われているのである。
海外では、こうした刻々と現れては消えゆくウェブ情報を収集し、文化資産として将来世代のために保存していこうという試みが既に複数存在する。また、日本においても国立国会図書館を中心に小規模ながらプロジェクトが開始されつつある。本稿ではこうしたウェブ・アーカイビングの考え方とその動きについて、国内外の事例等を交えながら紹介することとしたい。
2.ウェブ・アーカイビングの基本
ウェブ・アーカイビングを行う際の最も代表的な手段はウェブ・ロボットである。ウェブ・ロボットとはウェブ情報を自動的に収集するためのソフトウェアで、本来サーチエンジン等のインデキシングに用いられるソフトウェアであるが、アーカイビングにも転用することができる。
ロボットを動作させるにあたって基本となる概念が「起点」(2)と「深さ」(3)だ。ロボットは、起点となるURLを指定すると、再帰的にハイパーリンクをたどりながら指定された深さまで収集を行う。
収集したファイルはそのままでは必ずしも保管サーバー内で適切に利用することができない。ファイル同士のリンク関係が元のウェブ・サーバー内でのみ機能する絶対リンクによって記述されている場合、リンク関係がすべて切れてしまうからだ。したがって、これらのリンク関係をもう一度再構築する処理を保管サーバー内で行う必要がある。この際には元のオリジナルのファイルも別途保管するなどして、原本性の保持にも留意することが重要だ。
3. 海外の動き
3-1. 二つのアプローチ
ウェブ・アーカイビングを行うにあたっては世界的にみて二つの異なったアプローチが存在する。それは「選択的収集」と「バルク収集」である。選択的収集とは、個々のウェブ上の情報資源について、サイト単位、あるいは資料単位で、言わば「一冊」ずつ収集を行っていく方法である。一方、バルク収集とは、一国全体、あるいは世界全体のウェブ情報を一括して収集する方法である。前者は、情報資源単位で書誌的なメタデータを作成することによってきめ細かいアーカイブの構築が可能であるが、一つ一つの収集に膨大な人的コストを必要とするため、現実的にはごくわずかな量のアーカイブしか構築できないという欠点がある。一方、後者は収集作業をほとんど自動化できるため、低コストで大規模なアーカイブが構築可能であるが、均質性を欠く玉石混交のアーカイブとなってしまうほか、コンテンツ更新時の再収集頻度を情報資源ごとに個別に設定することができない等の欠点がある。
3-2. 海外の動き
世界で最も大規模なウェブ・アーカイブを構築しているのは、米国のアレクサ・インターネット社である。1600万サイト、100テラバイト、100億ページを超える世界最大のウェブ・コレクションを有しており、「ウェイバック・マシーン」(4)と呼ばれるシステムによって、既に失われたウェブサイトの閲覧が可能である。日本のサイトも多数収録されており、省庁再編前の行政情報や破綻した企業の当時の経営情報を入手できるなどなかなか興味深い。
一方、選択的収集を行っている代表例は、オーストラリア国立図書館が構築している「PANDORA」(5)である。詳細な選書ガイドラインが策定されており、オーストラリアを代表する政府、学会、民間団体の情報など、約2,000サイト、320ギガバイトのウェブ情報がアーカイブされている。粒度(6)は資料単位からサイト単位までさまざまであり、約3分の1はそれぞれの情報資源の更新に合わせて複数回再収集されている。
その他、米国議会図書館が「Minerva」(7)と呼ばれる選択的収集のプロジェクトを進めているほか、スウェーデン王立図書館、フィンランド国立図書館は一国全体のウェブ情報をバルク収集するプロジェクトを進めている(8)。
選択的収集、バルク収集には双方とも一長一短があり、どちらの方法論を採用すべきかについては判断が分かれるところである。本年一月開催の「ウェブ・アーカイビングに関する国際シンポジウム」(9)の後に行われた関係者による懇談会においては、可能な限り両方のアプローチを採用することが望ましい、との意見が大勢であった。
4. 国立国会図書館の取り組み
国立国会図書館では、「ネットワーク系電子情報については当分の間契約により選択的に収集する」とした納本制度調査会答申(平成11年2月22日)(10)に基づき、当面主に政府情報、学術情報等を中心に選択的なウェブ・アーカイビングを行っていく計画である。また、平成12年度から平成14年度にかけての三カ年計画で、ウェブ情報等を収集・組織化するプロトタイプモデル「WARP」(仮称、「Web Archiving Program」の略)の開発に取り組んでいる。
4.1 WARPの全体像
WARPの全体像を図1に示す。ウェブ情報の収集は、発行機関に協力を依頼し包括的な許諾を得た上で実施する。収集手段としては、ロボット収集のほか、ファイル転送、電子メール、CD-R等の記憶媒体による送付の4つの手段を想定している。収集した情報にはダブリン・コア準拠の書誌的なメタデータ(11)を付与し、時系列管理された形で図書館のサーバーに蓄積する。また、蓄積した情報は図書館のウェブサイト上に公開し、利用・提供を行う予定である。
4.2 メタデータ構造
WARPのメタデータ構造は便宜的に三段階のものとして把えると分かりやすい。それは「契約レベル」「書誌レベル」「個体レベル」である(図2)。
(1)契約レベル
「契約」とはウェブ情報の収集にあたって各機関と締結する著作権の許諾契約を指し、契約データベースにはその契約内容が格納される。契約レベルのメタデータとしては、機関名、連絡先、収集方法、収集可能範囲、収集禁止範囲、再収集頻度、利用提供条件などがある。
(2)書誌レベル
(1)の契約に基づき、当該サイト内のさまざまな情報を収集するわけであるが、その一タイトルごとの収集情報に設定されるのが書誌レベルのメタデータである。タイトルや著者等の書誌的なメタデータのほか、収集条件として収集可能範囲・収集禁止範囲・再収集頻度、ロボット動作条件として深さ・動作時間・アクセスエラータイムアウト時間、さらに利用提供条件などがある。
(3)個体レベル
「個体」とは実際に収集したフォルダやファイルから成る最小のひとまとまりを指す。各情報資源はあらかじめ設定された頻度にしたがって再収集されるわけであるが、その個々の「版」であると言ってもよい。個体レベルのメタデータとしては、図書館のサーバー内のどこに保管されているかを示す保管URLや、収集日、個体登録日などがある。
4.3 業務モデル
さて、本節では具体的にどのように業務を行っていくかについて概観していくことにしたい。業務フローは、大きく「新規収集」と「再収集」の2つに分けられる(図3)。
「新規収集」の業務は次の8つのプロセスからなる。
(1)一次調査
インターネット上のウェブサイトの調査・分析を行い、収集対象候補となる発行機関を洗い出す。
(2)許諾交渉・契約
発行機関に対し、著作権の許諾交渉を行い、契約を締結する。
(3)二次調査
発行機関のウェブサイトに対して詳細な調査を行い、収集すべき個々の情報資源を洗い出し、特定する。どのURLを起点としてどの程度の深さまで収集するのかを具体的に定める必要がある。
(4)書誌の仮作成
二次調査に基づいてリストアップされた情報資源について、タイトルやURL等の簡単なメタデータを仮作成する。
(5)収集・再収集条件設定
二次調査に基づき、収集条件・再収集条件の設定を行う。収集方法には「即時収集」と「夜間収集」の2つがある。
(6)収集
収集指示後は「未収集」「収集中」「収集済」等の収集進行状況が確認できる。
(7)トリミング・個体登録
収集完了後、必要に応じてトリミング(12)を行った上で個体として登録する。
(8)書誌の登録
最後に、必要なメタデータを記述し、利用提供条件等を設定した上で、書誌の登録を行う。
なお、再収集については紙幅の都合で割愛するが、頻繁に更新されるウェブ情報の特性を踏まえ、更新検知や再収集のスケジューリング等の機能を備えている。
4.4 WARPの今後
国立国会図書館では平成14年度のできるだけ早い時期に試行的な収集を開始する予定である。実際の収集にあたっては、粒度の問題や収集エラー等、さまざまな課題に直面するだろう。
また、ウェブ・アーカイビングを含めたネットワーク系電子情報全体の納本制度のあり方については、現在納本制度審議会(13)において審議・検討が進められている。
WARPという業務モデルは言わば、ウェブという新しい情報資源を、従来の伝統的な図書館資料の収集・整理の枠組みに当てはめようとした、一種の実験である。前述のとおり選択的収集には膨大な人的コストを要すること、ウェブ情報は図書や雑誌に比べ量的に遙かに莫大である(14)ことなどから考えるに、この業務モデルが今後とも大胆かつ柔軟な改良を必要とすることは想像に難くない。しかし、我々がウェブ・アーカイビングという未知の領域に挑み、さまざまな試行錯誤を重ねていくにあたり、少なくともWARPは象徴的な第一歩となりうるのではないかと自負している。
5.ウェブ・アーカイビングの課題と将来
5.1 動的ウェブ・深層ウェブ
ウェブ・アーカイビングには、納本制度や著作権等の法的観点、収集モデルやメタデータ、識別子等の技術的観点の両面において、さまざまな課題が山積している。しかしその中でも、バルク収集、選択的収集に共通の課題としてぜひ触れておきたいのが、動的ウェブ(dynamic web)、あるいは深層ウェブ(deep web)の問題である。すなわち、現在の一般的なロボットでは、フラッシュやスクリプト等を用いて作られた動的なウェブや、データベース等から情報が生成される深層ウェブを収集することが困難なのだ。有用かつ規模の大きい情報資源ほど、使い勝手を良くするためにデータベース化される傾向があるため、特に深層ウェブが収集できないことは大きな問題である。このような問題に対しては、例えば、フィンランド国立図書館が深層ウェブ(15)の納入を義務づける方向で納本制度を検討しているほか、デンマーク王立図書館が電子商取引やオンラインサービス等を収集する試みを検討している(8)。
5.2 ウェブ・アーカイビングの将来
ウェブ・アーカイビングは将来にさまざまな可能性を秘めた極めて発展性の高いテーマである。収集されたウェブ・アーカイブの中にリンクやブックマークを設定すれば、人々は「リンク切れ」という事態から解放されるだろう。ウェブ・アーカイブの中に対してサブジェクト・ゲートウェイ(16)等のナビゲーション・サービスを構築することも可能かもしれない。バルク収集したウェブ情報は、ウェブの規模や特性等を探る調査や、大量のデータから目的の情報を探し出す研究等にも、有用なサンプルを提供してくれるに違いない。後世の学者や研究者は、過去のウェブを「発掘」し、当時の政治・経済・文化・科学の諸活動を理解しようと、「デジタル考古学」(7)の研究に勤しむかもしれない。
ウェブという新たな人類の知的所産を、過去から未来へと流れる時間の中で、どのように語り継いでゆけばよいのか、それは現代を生きる我々に課せられた大いなる使命なのである。
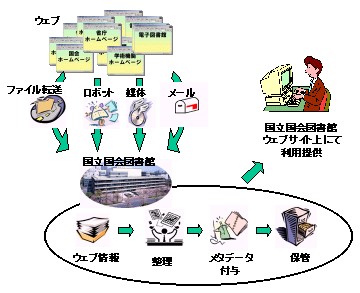
図1 WARPの全体像
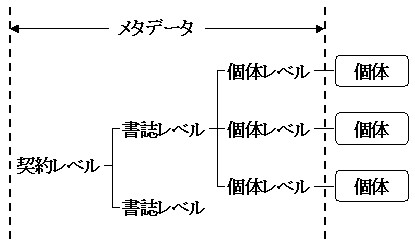
図2 メタデータ構造
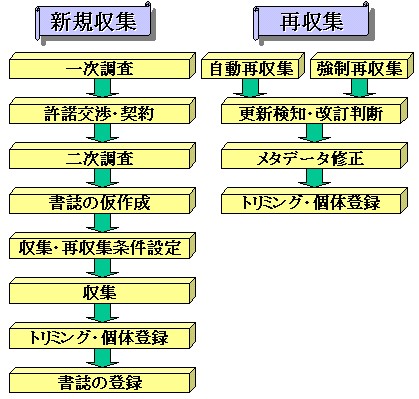
図3 業務フロー
注・参考文献
- 細野公男他.文化的価値のある情報メディアの体系的保存政策の基礎的研究,2001.3
- 起点とはロボットが収集を開始するページである。
- 例えばa.htmlからb.htmlへのリンクがあり、b.htmlからc.htmlへのリンクがあり、c.htmlからd.htmlへのリンクがあった場合、a.htmlを起点として、それぞれb.htmlは深さ1、c.htmlは深さ2、d.htmlは深さ3となる。
- http://www.archive.org
- http://pandora.nla.gov.au
- もともとは粉状物体の粒子の大きさの度合の意味だが、ここではウェブ情報を収集する際に、どの程度の大きさの情報量を一単位として扱うかの度合を指す。
- William Y. Arms, Roger Adkins, Cassy Ammen, Allene Hayes. Collecting and Preserving the Web: The Minerva Prototype. RLG DigiNews. Vol.5, No.2
- 廣瀬信己.北欧諸国におけるウェブ・アーカイビングの現状と納本制度.国立国会図書館月報.490号,p.14-22 (2002.1)
- 2002年1月30日、国立国会図書館の主催により、米国議会図書館、デンマーク王立図書館、オーストラリア国立図書館から専門家を招聘して開催。http://www.ndl.go.jpにプレゼンテーションや予稿等が掲載されている。
- http://www.ndl.go.jp/toukan/c_toushin.pdf
- 「国立国会図書館メタデータ記述要素」(平成13年3月7日)についてはhttp://www.ndl.go.jp/service/bookdata/ndlmeta.pdf参照。
- ロボットは起点URLから指定された深さまでのファイルを機械的に収集するだけであるため、職員が想定した範囲外のたくさんの不要なファイルをも収集する可能性がある。このため、不要なファイルを取り除き個体の内容を整える必要があり、これを「トリミング」と呼ぶ。ただし非常に手間のかかる作業であるため、実際にトリミングを行うのはごく一部の重要な情報資源のみとなるであろう。
- 平成14年3月1日、国立国会図書館館長より納本制度審議会に対し、「日本国内で発行されるネットワーク系電子出版物を納本制度に組み入れることについて」の諮問が行われた。
- 単純比較はできないが、例えば、国立国会図書館の2000年末の蔵書数は図書約750万冊、逐次刊行物約17万タイトルであるのに対し、米国Cyveillance社の2000年時点の調査ではインターネットの規模は20億ページ以上である。http://www.cyveillance.com/web/us/newsroom/releases/2000/2000-07-10.htm参照。
- 厳密には、フィンランド国立図書館ではより広く、「制限アクセス資源(access protected online resources)」という概念で検討が進められている。
- 基準に則ったメタデータによってインターネット上のさまざまな主題の情報資源の探索を支援するサービス。
email: nhirose@ndl.go.jp