Optimize Classifier Fit Using Bayesian Optimization - MATLAB & Simulink (original) (raw)
This example shows how to optimize an SVM classification using the fitcsvm function and the OptimizeHyperparameters name-value argument.
Generate Data
The classification works on locations of points from a Gaussian mixture model. In The Elements of Statistical Learning, Hastie, Tibshirani, and Friedman (2009), page 17 describes the model. The model begins with generating 10 base points for a "green" class, distributed as 2-D independent normals with mean (1,0) and unit variance. It also generates 10 base points for a "red" class, distributed as 2-D independent normals with mean (0,1) and unit variance. For each class (green and red), generate 100 random points as follows:
- Choose a base point m of the appropriate color uniformly at random.
- Generate an independent random point with 2-D normal distribution with mean m and variance I/5, where I is the 2-by-2 identity matrix. In this example, use a variance I/50 to show the advantage of optimization more clearly.
Generate the 10 base points for each class.
rng('default') % For reproducibility grnpop = mvnrnd([1,0],eye(2),10); redpop = mvnrnd([0,1],eye(2),10);
View the base points.
plot(grnpop(:,1),grnpop(:,2),'go') hold on plot(redpop(:,1),redpop(:,2),'ro') hold off
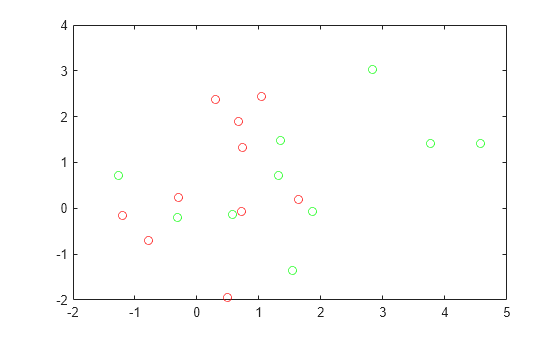
Since some red base points are close to green base points, it can be difficult to classify the data points based on location alone.
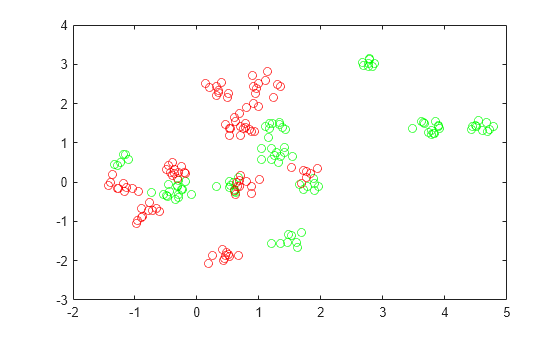
Generate the 100 data points of each class.
redpts = zeros(100,2); grnpts = redpts; for i = 1:100 grnpts(i,:) = mvnrnd(grnpop(randi(10),:),eye(2)*0.02); redpts(i,:) = mvnrnd(redpop(randi(10),:),eye(2)*0.02); end
View the data points.
figure plot(grnpts(:,1),grnpts(:,2),'go') hold on plot(redpts(:,1),redpts(:,2),'ro') hold off
Prepare Data for Classification
Put the data into one matrix, and make a vector grp that labels the class of each point. 1 indicates the green class, and –1 indicates the red class.
cdata = [grnpts;redpts]; grp = ones(200,1); grp(101:200) = -1;
Prepare Cross-Validation
Set up a partition for cross-validation.
c = cvpartition(200,'KFold',10);
This step is optional. If you specify a partition for the optimization, then you can compute an actual cross-validation loss for the returned model.
Optimize Fit
To find a good fit, meaning one with optimal hyperparameters that minimize the cross-validation loss, use Bayesian optimization. Specify a list of hyperparameters to optimize by using the OptimizeHyperparameters name-value argument, and specify optimization options by using the HyperparameterOptimizationOptions name-value argument.
Specify 'OptimizeHyperparameters' as 'auto'. The 'auto' option includes a typical set of hyperparameters to optimize. fitcsvm finds optimal values of BoxConstraint, KernelScale, and Standardize. Set the hyperparameter optimization options to use the cross-validation partition c and to choose the 'expected-improvement-plus' acquisition function for reproducibility. The default acquisition function depends on run time and, therefore, can give varying results.
opts = struct('CVPartition',c,'AcquisitionFunctionName', ... 'expected-improvement-plus'); Mdl = fitcsvm(cdata,grp,'KernelFunction','rbf', ... 'OptimizeHyperparameters','auto','HyperparameterOptimizationOptions',opts)
|====================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | Standardize | | | result | | runtime | (observed) | (estim.) | | | | |====================================================================================================================| | 1 | Best | 0.195 | 0.17686 | 0.195 | 0.195 | 193.54 | 0.069073 | false | | 2 | Accept | 0.345 | 0.074409 | 0.195 | 0.20398 | 43.991 | 277.86 | false | | 3 | Accept | 0.365 | 0.067395 | 0.195 | 0.20784 | 0.0056595 | 0.042141 | false | | 4 | Accept | 0.61 | 0.088302 | 0.195 | 0.31714 | 49.333 | 0.0010514 | true | | 5 | Best | 0.1 | 0.088837 | 0.1 | 0.10005 | 996.27 | 1.3081 | false | | 6 | Accept | 0.13 | 0.07052 | 0.1 | 0.10003 | 25.398 | 1.7076 | false | | 7 | Best | 0.085 | 0.10428 | 0.085 | 0.08521 | 930.3 | 0.66262 | false | | 8 | Accept | 0.35 | 0.11041 | 0.085 | 0.085172 | 0.012972 | 983.4 | true | | 9 | Best | 0.075 | 0.10584 | 0.075 | 0.077959 | 871.26 | 0.40617 | false | | 10 | Accept | 0.08 | 0.07901 | 0.075 | 0.077975 | 974.28 | 0.45314 | false | | 11 | Accept | 0.235 | 0.11811 | 0.075 | 0.077907 | 920.57 | 6.482 | true | | 12 | Accept | 0.305 | 0.06926 | 0.075 | 0.077922 | 0.0010077 | 1.0212 | true | | 13 | Best | 0.07 | 0.14496 | 0.07 | 0.073603 | 991.16 | 0.37801 | false | | 14 | Accept | 0.075 | 0.11466 | 0.07 | 0.073191 | 989.88 | 0.24951 | false | | 15 | Accept | 0.245 | 0.13465 | 0.07 | 0.073276 | 988.76 | 9.1309 | false | | 16 | Accept | 0.07 | 0.10712 | 0.07 | 0.071416 | 957.65 | 0.31271 | false | | 17 | Accept | 0.35 | 0.091912 | 0.07 | 0.071421 | 0.0010579 | 33.692 | true | | 18 | Accept | 0.085 | 0.092534 | 0.07 | 0.071274 | 48.536 | 0.32107 | false | | 19 | Accept | 0.07 | 0.09555 | 0.07 | 0.070587 | 742.56 | 0.30798 | false | | 20 | Accept | 0.61 | 0.084188 | 0.07 | 0.070796 | 865.48 | 0.0010165 | false | |====================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | BoxConstraint| KernelScale | Standardize | | | result | | runtime | (observed) | (estim.) | | | | |====================================================================================================================| | 21 | Accept | 0.1 | 0.084194 | 0.07 | 0.070715 | 970.87 | 0.14635 | true | | 22 | Accept | 0.095 | 0.090774 | 0.07 | 0.07087 | 914.88 | 0.46353 | true | | 23 | Accept | 0.07 | 0.082991 | 0.07 | 0.070473 | 982.01 | 0.2792 | false | | 24 | Accept | 0.51 | 0.065954 | 0.07 | 0.070515 | 0.0010005 | 0.014749 | true | | 25 | Accept | 0.345 | 0.064297 | 0.07 | 0.070533 | 0.0010063 | 972.18 | false | | 26 | Accept | 0.315 | 0.096242 | 0.07 | 0.07057 | 947.71 | 152.95 | true | | 27 | Accept | 0.35 | 0.078975 | 0.07 | 0.070605 | 0.0010028 | 43.62 | false | | 28 | Accept | 0.61 | 0.094067 | 0.07 | 0.070598 | 0.0010405 | 0.0010258 | false | | 29 | Accept | 0.555 | 0.070705 | 0.07 | 0.070173 | 993.56 | 0.010502 | true | | 30 | Accept | 0.07 | 0.089176 | 0.07 | 0.070158 | 965.73 | 0.25363 | true |
Optimization completed. MaxObjectiveEvaluations of 30 reached. Total function evaluations: 30 Total elapsed time: 15.5863 seconds Total objective function evaluation time: 2.8362
Best observed feasible point: BoxConstraint KernelScale Standardize _____________ ___________ ___________
991.16 0.37801 false Observed objective function value = 0.07 Estimated objective function value = 0.072292 Function evaluation time = 0.14496
Best estimated feasible point (according to models): BoxConstraint KernelScale Standardize _____________ ___________ ___________
957.65 0.31271 false Estimated objective function value = 0.070158 Estimated function evaluation time = 0.10138
Mdl = ClassificationSVM ResponseName: 'Y' CategoricalPredictors: [] ClassNames: [-1 1] ScoreTransform: 'none' NumObservations: 200 HyperparameterOptimizationResults: [1×1 BayesianOptimization] Alpha: [66×1 double] Bias: -0.0910 KernelParameters: [1×1 struct] BoxConstraints: [200×1 double] ConvergenceInfo: [1×1 struct] IsSupportVector: [200×1 logical] Solver: 'SMO'
Properties, Methods
fitcsvm returns a ClassificationSVM model object that uses the best estimated feasible point. The best estimated feasible point is the set of hyperparameters that minimizes the upper confidence bound of the cross-validation loss based on the underlying Gaussian process model of the Bayesian optimization process.
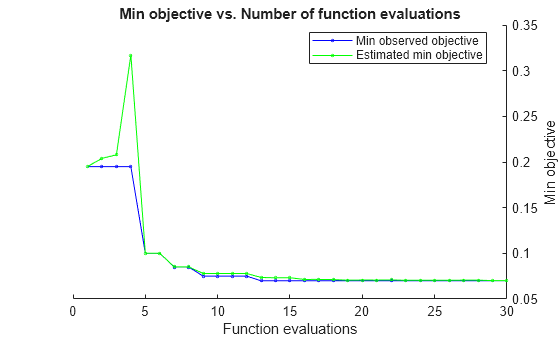
The Bayesian optimization process internally maintains a Gaussian process model of the objective function. The objective function is the cross-validated misclassification rate for classification. For each iteration, the optimization process updates the Gaussian process model and uses the model to find a new set of hyperparameters. Each line of the iterative display shows the new set of hyperparameters and these column values:
Objective— Objective function value computed at the new set of hyperparameters.Objective runtime— Objective function evaluation time.Eval result— Result report, specified asAccept,Best, orError.Acceptindicates that the objective function returns a finite value, andErrorindicates that the objective function returns a value that is not a finite real scalar.Bestindicates that the objective function returns a finite value that is lower than previously computed objective function values.BestSoFar(observed)— The minimum objective function value computed so far. This value is either the objective function value of the current iteration (if theEval resultvalue for the current iteration isBest) or the value of the previousBestiteration.BestSoFar(estim.)— At each iteration, the software estimates the upper confidence bounds of the objective function values, using the updated Gaussian process model, at all the sets of hyperparameters tried so far. Then the software chooses the point with the minimum upper confidence bound. TheBestSoFar(estim.)value is the objective function value returned by the predictObjective function at the minimum point.
The plot below the iterative display shows the BestSoFar(observed) and BestSoFar(estim.) values in blue and green, respectively.
The returned object Mdl uses the best estimated feasible point, that is, the set of hyperparameters that produces the BestSoFar(estim.) value in the final iteration based on the final Gaussian process model.
You can obtain the best point from the HyperparameterOptimizationResults property or by using the bestPoint function.
Mdl.HyperparameterOptimizationResults.XAtMinEstimatedObjective
ans=1×3 table BoxConstraint KernelScale Standardize _____________ ___________ ___________
957.65 0.31271 false [x,CriterionValue,iteration] = bestPoint(Mdl.HyperparameterOptimizationResults)
x=1×3 table BoxConstraint KernelScale Standardize _____________ ___________ ___________
957.65 0.31271 false By default, the bestPoint function uses the 'min-visited-upper-confidence-interval' criterion. This criterion chooses the hyperparameters obtained from the 16th iteration as the best point. CriterionValue is the upper bound of the cross-validated loss computed by the final Gaussian process model. Compute the actual cross-validated loss by using the partition c.
L_MinEstimated = kfoldLoss(fitcsvm(cdata,grp,'CVPartition',c, ... 'KernelFunction','rbf','BoxConstraint',x.BoxConstraint, ... 'KernelScale',x.KernelScale,'Standardize',x.Standardize=='true'))
The actual cross-validated loss is close to the estimated value. The Estimated objective function value is displayed below the plot of the optimization results.
You can also extract the best observed feasible point (that is, the last Best point in the iterative display) from the HyperparameterOptimizationResults property or by specifying Criterion as 'min-observed'.
Mdl.HyperparameterOptimizationResults.XAtMinObjective
ans=1×3 table BoxConstraint KernelScale Standardize _____________ ___________ ___________
991.16 0.37801 false [x_observed,CriterionValue_observed,iteration_observed] = ... bestPoint(Mdl.HyperparameterOptimizationResults,'Criterion','min-observed')
x_observed=1×3 table BoxConstraint KernelScale Standardize _____________ ___________ ___________
991.16 0.37801 false CriterionValue_observed = 0.0700
The 'min-observed' criterion chooses the hyperparameters obtained from the 13th iteration as the best point. CriterionValue_observed is the actual cross-validated loss computed using the selected hyperparameters. For more information, see the Criterion name-value argument of bestPoint.
Visualize the optimized classifier.
d = 0.02; [x1Grid,x2Grid] = meshgrid(min(cdata(:,1)):d:max(cdata(:,1)), ... min(cdata(:,2)):d:max(cdata(:,2))); xGrid = [x1Grid(:),x2Grid(:)]; [~,scores] = predict(Mdl,xGrid);
figure h(1:2) = gscatter(cdata(:,1),cdata(:,2),grp,'rg','+*'); hold on h(3) = plot(cdata(Mdl.IsSupportVector,1), ... cdata(Mdl.IsSupportVector,2),'ko'); contour(x1Grid,x2Grid,reshape(scores(:,2),size(x1Grid)),[0 0],'k'); legend(h,{'-1','+1','Support Vectors'},'Location','Southeast');
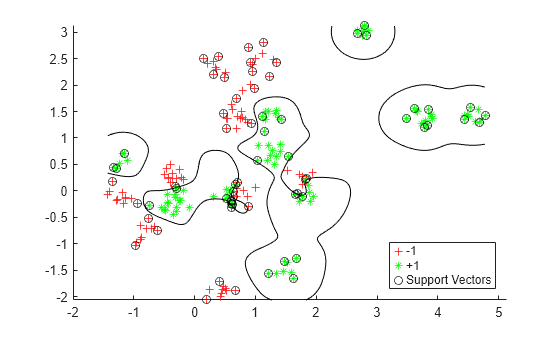
Evaluate Accuracy on New Data
Generate and classify new test data points.
grnobj = gmdistribution(grnpop,.2eye(2)); redobj = gmdistribution(redpop,.2eye(2));
newData = random(grnobj,10); newData = [newData;random(redobj,10)]; grpData = ones(20,1); % green = 1 grpData(11:20) = -1; % red = -1
v = predict(Mdl,newData);
Compute the misclassification rates on the test data set.
L_Test = loss(Mdl,newData,grpData)
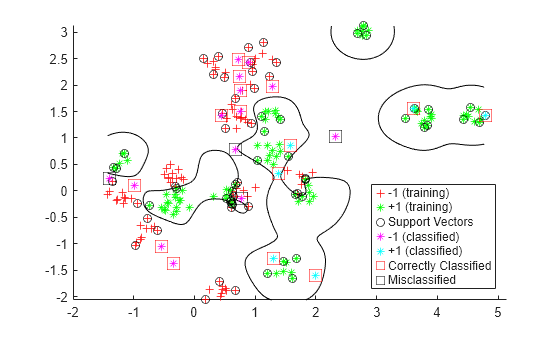
Determine which new data points are classified correctly. Format the correctly classified points in red squares and the incorrectly classified points in black squares.
h(4:5) = gscatter(newData(:,1),newData(:,2),v,'mc','**');
mydiff = (v == grpData); % Classified correctly
for ii = mydiff % Plot red squares around correct pts h(6) = plot(newData(ii,1),newData(ii,2),'rs','MarkerSize',12); end
for ii = not(mydiff) % Plot black squares around incorrect pts h(7) = plot(newData(ii,1),newData(ii,2),'ks','MarkerSize',12); end legend(h,{'-1 (training)','+1 (training)','Support Vectors', ... '-1 (classified)','+1 (classified)', ... 'Correctly Classified','Misclassified'}, ... 'Location','Southeast'); hold off