Tall Arrays and mapreduce - MATLAB & Simulink (original) (raw)
Analyze big data sets in parallel using MATLAB® tall arrays and datastores or mapreduce on Spark™ and Hadoop® clusters, and parallel pools
You can use Parallel Computing Toolbox™ to evaluate tall-array expressions in parallel using a parallel pool on your desktop. Using tall arrays allows you to run big data applications that do not fit in memory on your machine. You can also use Parallel Computing Toolbox to scale up tall-array processing by connecting to a parallel pool running on a MATLAB Parallel Server™ cluster. Alternatively, you can use a Spark enabled Hadoop cluster running MATLAB Parallel Server. For more information, see Big Data Workflow Using Tall Arrays and Datastores.
Functions
| tall | Create tall array |
|---|---|
| datastore | Create datastore for large collections of data |
| mapreduce | Programming technique for analyzing data sets that do not fit in memory |
| mapreducer | Define parallel execution environment for mapreduce and tall arrays |
| partition | Partition a datastore |
| numpartitions | Number of datastore partitions |
Classes
| parallel.Pool | Parallel pool of workers |
|---|---|
| parallel.cluster.Hadoop | Hadoop cluster for mapreducer, mapreduce and tall arrays |
| parallel.cluster.Spark | Spark cluster for mapreducer, mapreduce and tall arrays (Since R2022b) |
Examples and How To
- Big Data Workflow Using Tall Arrays and Datastores
Learn about typical workflows using tall arrays to analyze big data sets. - Use Tall Arrays on a Parallel Pool
Discover tall arrays in Parallel Computing Toolbox and MATLAB Parallel Server. - Process Big Data in the Cloud
This example shows how to access a large data set in the cloud and process it in a cloud cluster using MATLAB® capabilities for big data. - Use Parallel Computing to Optimize Big Data Set for Analysis
This example shows how to optimize data preprocessing for analysis using parallel computing. (Since R2024a) - Use Tall Arrays on a Spark Cluster
Create and use tall tables on Spark clusters without changing your MATLAB code. - Run mapreduce on a Parallel Pool
Trymapreducefor advanced analysis of big data using Parallel Computing Toolbox. - Run mapreduce on a Hadoop Cluster
Learn aboutmapreducefor advanced big data analysis on a Hadoop cluster. - Partition a Datastore in Parallel
Usepartitionto split yourdatastoreinto smaller parts.
Concepts
- Run Code on Parallel Pools
Learn about starting and stopping parallel pools, pool size, and parallel environment selection.
Related Information
Featured Examples
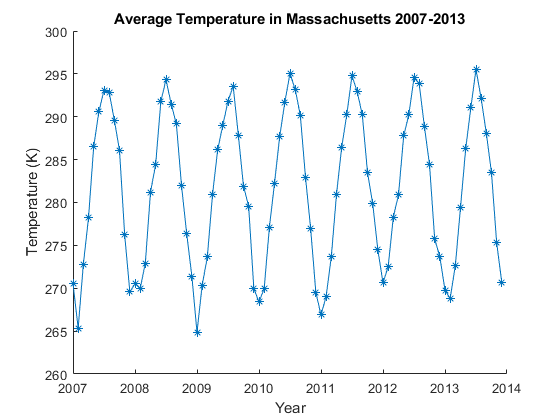
Process Big Data in the Cloud
Access a large data set in the cloud and process it in a cloud cluster using MATLAB® capabilities for big data.
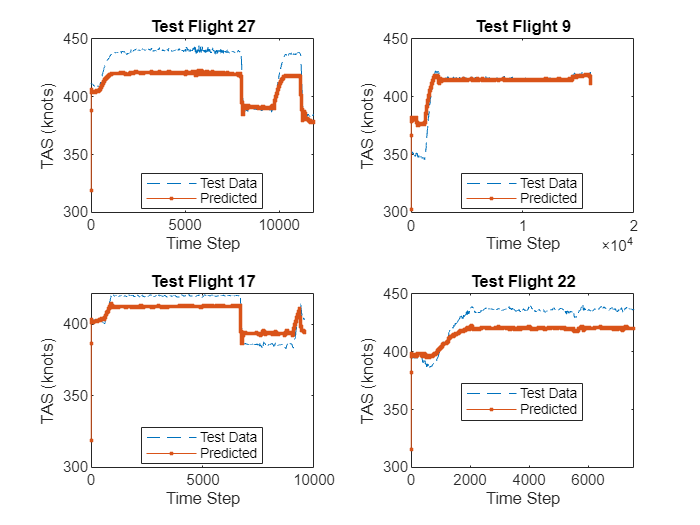
Use Parallel Computing to Optimize Big Data Set for Analysis
Optimize data preprocessing for analysis using parallel computing.
- Since R2024a
- Open Live Script