Continuous Database Integration: A DataOps Practice (original) (raw)
Part of building a system, of compiling and testing it, is building the database (if it changed). This is true for a database being accessed by one system, by one hundred system, or one thousand. This article overviews the process of continuous database integration (CDI).This article is organized into the following topics:
- Definitions
- Why continuous database integration is important
- Why continuous database integration is different
- How continuous database integration works
- Why continuous database integration is hard
- Continuous database integration in context
- Related resources
1. Definitions
Let’s begin with a few definitions:
- Build process. A build process includes the gathering of the current version of source files, the compilation of those source files (when appropriate), the invocation of any relevant automated tests, the invocation of any automated validation tools, the reporting of the results of these activities.
- Continuous integration (CI). CI is the automatic invocation of the build process of a system.
- Database. For the sake of this discussion, a database is any place where data is stored, also known as a data sourced. This could be something as simple as a file or something as complex as a database management system (DBMS). Databases may have a schema and will have state.
- Continuous database integration (CDI). As the name implies, CDI is the database version of CI.
- Database functionality. This includes any code or behavior implemented within the database, including but not limited to triggers, stored procedures, stored functions, and calculations.
- Schema. The schema of a database is the structure, if any, of the stored data AND any database functionality implemented within it.
- State. The stored data within a database.
2. Why Continuous Database Integration is Important
There are several reasons why CDI is critical to your success:
- CI is a key quality technique. CI has become the norm for software development teams. Because databases are critical aspects of the solutions that these teams are building, databases must also be included in the build process.
- Databases should be trustworthy. Yet they seldom are. In fact, all assets within your organization should be trustworthy, otherwise they’re not really assets. Users of databases should be able to trust that the data is valid, that the functionality encapsulated within the database works as expected. CDI, when implemented and maintained properly, enables you to provide trustworthy databases.
- Databases are shared resources. A significant challenge is that databases are shared across many systems, including applications, other data sources, documentation, tests (we hope), and other tooling. This is depicted in Figure 1. Due to this high coupling, it is imperative that we automate the quality validation of these critical assets.
- You no longer have any choice. The environment in which you operate evolves quickly, and as a result you must be able to evolve your assets, including your databases, to reflect these changes. CDI enables you to evolve your databases safely.
Figure 1. Databases are shared resources.

3. Why Continuous Database Integration is Different
CDI is different than CI because database testing is more complex than testing code. The issues with this include:
- Persistent state increases testing complexity
- Testing risk increases the closer you get to production
- Database tests are time consuming
3.1 Persistent State Increases Testing Complexity
A test should put the system into a known state, run, check for the expected results, then return the system back to the state before the test ran. If it doesn’t return the system to the original state we say that there is a side effect. Side effects are problematic in the best of circumstances, but with databases it can be very problematic due to persistent state (data) within the database. Consider the following scenarios:
- A test modifies data within the database but does not include the functionality to revert the data values back. This is just poor testing practice, but it happens. Think of test that adds the result of a calculation to a running total. The issue is that the next time the test suite runs that the data will be in a different state than the previous time the test ran, potentially giving a different result.
- A test fails part way through and never gets to the point of reverting the database back to its original state. In this case the code existed, it just doesn’t get run.
Due to persistent state any side effects of database tests have the potential to affect both the current test run as well as future test runs. Luckily there are techniques to counteract this problem:
- Restore/rebuild test databases regularly. To ensure that you truly are starting from a known state you will want to either restore or outright rebuild your test database(s) from scratch. My recommendation is to do this at the beginning of a test run. Unfortunately, this takes time, decreasing the overall performance of your test run (more on this later). Note that this advice to restore/rebuild your database pertains to test databases only, not production databases. The only reason you would ever want to restore/rebuild a production database is after a catastrophic failure, not for testing purposes.
- Run database tests as transactions. The pseudo-code for a transaction-conformant database test is presented in Figure 2. The idea is that your test logic is run within the scope of a transaction and rolled-back after the test runs, the end result being that any side effects aren’t committed into the database. The challenge with this approach is that running tests as transactions decrease the performance of your tests and all of your tests need to be written in this manner (all it takes is one non-conformant database test that has side effects and you have a problem).
Figure 2. Pseudo-code for a database test as a transaction.
Begin Transaction RunTest
Put database in known state
Run the test
Check the results of the test against the expected results
Rollback Transaction RunTest
Log results of test
3.2 Testing Risk Increases the Closer You Get to Production
A common development practice is to have sandboxes, different environments in which your assets may be developed and tested. This concept is overviewed in Figure 3. The idea is that developers (or Agile data engineers ) work in their sandboxes, developing and testing to the best of their ability. When a change is ready for the next level of testing it is promoted up a level, in this case to a team integration sandbox where a more sophisticated test suite is run. When the test run(s) are successful in a given sandbox the changes are promoted to the next level where an even more sophisticated (and usually more expensive) test suite is run. The process repeats until changes are deployed into production. When this process is fully automated we refer to this as continuous deployment.
Figure 3. Sandboxes within your technical environment (click to expand).

The sandbox strategy reveals several important considerations for your CDI strategy:
- CDI should occur in all sandboxes except production. This is for two reasons, first running tests takes time and resources and will have a negative impact on performance. With the exception of targeting testing to explore production problems, you typically don’t want to test in production. Second, as mentioned early, you don’t rebuild/restore a production database except when there has been a catastrophic failure. As you will see below, rebuild/restore is an important aspect of the CDI process.
- CDI on a developer sandbox must be fast. Developers and Agile data engineers are highly paid professionals. As a result you are motivated to be efficient with their time, and that includes ensuring that the automated test suite running in that sandbox is fast. In the next section we explore this in detail.
3.3 Database Tests Are Time Consuming
Database access takes time. The more database tests you have, the longer your test suite takes to run. Where an automated test running against application code may run on the order of milliseconds a simple database test may run in tenths of a second and a complex test in seconds or more. This starts to add up quickly if your automated test suite includes hundreds or even thousands of database tests.
There are several strategies that you can follow to increase the speed of your database tests. In order of most effective to least effective, they are:
- Only run a subset of the tests. A common strategy is for developers to run only a handful of detailed tests within their environments. These tests typically focus on the aspects of what they are currently working on, and once that functionality is deemed finished for the present time frame the corresponding tests for it are promoted to one or more test suites running in other sandboxes, as per Figure 3.
- Run against a subset of the data. As the size of a database grows, or more accurately as the number of rows in database structures increases, the slower it generally becomes to access the data. For example, a test that validates the total of a numeric column in a table will run faster when 100 rows are being totalled compared with totally 10,000 rows.
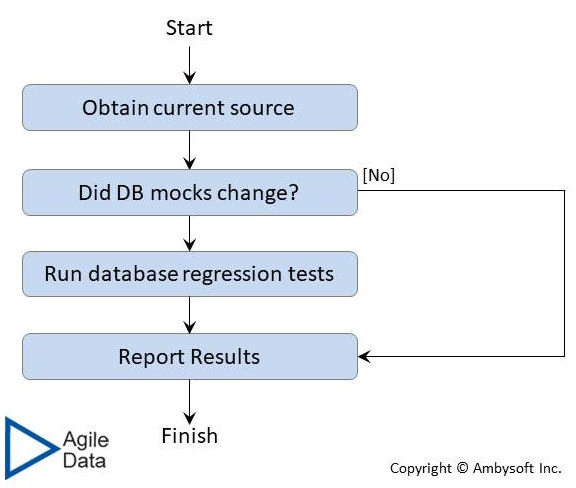
- Run against a database mock. A mock is a simulation of an asset, such as a subsystem, a database, or an external service. Mocks are created to reduce the cost of testing, where the cost may be money, time, or both. Figure 4 depicts the process of database testing when using database mocks. Mocks usually prove valuable in most situations with the exception of databases. Database mocking almost always proves to be a bad idea in practice because it is very difficult to fully mock a database, the effort and cost to do so almost always exceeds the benefits, and many of the most important classes of testing (in particular performance and security) aren’t viable when run against mocks.
Figure 4. The process of database testing using database mocks.
4. How Continuous Database Integration Works
Figure 5 overviews the steps of CDI process. The steps of this process mirror those of the normal CI process, albeit with data-oriented terminology in some cases.
Figure 5. The process of continuous database integration.
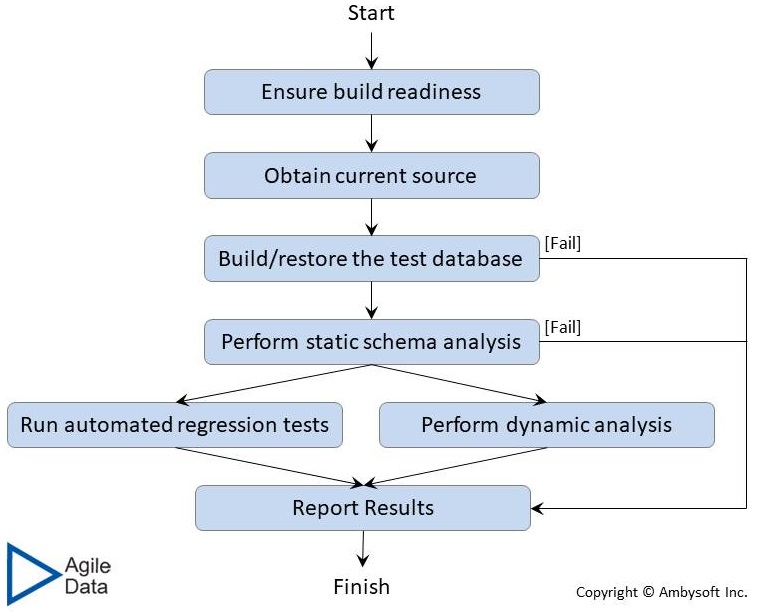
The steps of the CDI process are:
- Ensure build readiness. This is a quick check that validates that all of the tools and environments required to build the asset, in this case the database, are currently available. This includes, but is not limited to, your configuration management (CM) environment, the build tools, the test environment, testing tools, and other validation tools.
- Obtain current source. All of the source code, source data, test code, test data, configuration files, and any other component required to build the database should be checked out of your CM environment.
- Build or restore the test database. You want to put your test database into a known state at the start of your test run. You can do this either by restoring the database from a back up or by recreating the database and running your database creation scripts to create the database from scratch.
- Perform static schema analysis. Static schema analysis is the database version of static code analysis. The idea is that you inspect the database schema, via automated tooling, validating that it conforms to defined standards. Database schema analysis will validate that your schema, both code and structure, conforms to your organizational database design conventions (e.g. naming conventions). This step is optional, although highly recommended, as tools may not yet exist for your technology platform (so start building them, and better yet initiate an open-source initiatives).
- Run automated regression tests. Your automated test suite(s) are run against the database.
- Perform dynamic analysis. Dynamic analysis tools validate that a system, in this case a database, performs under common stresses. Dynamic analysis tools often look for security threats – SQL injection, broad user privileges, (lack of) audit tracking, missing security patches, poor password control, and more. As with static analysis this step is also optional but highly recommended.
- Report results. The results of your efforts should be logged so that you may act on them. The results will likely be moved into your data warehouse so as to take advantage of your reporting infrastructure.
The CDI process runs on every sandbox, although as discussed earlier there is often a different strategy on the development sandbox due to performance considerations.
5. Why Continuous Database Integration is Hard
There are several reasons why CDI proves to be more difficult than standard CI in practice:
- Database tests may have side effects. We discussed this in detail earlier in the persistent state increases testing complexity section. We also discussed potential techniques to overcome this problem.
- Incompatible mindset. Agility requires a greater focus on working in an evolutionary manner than do serial ways of working (WoW). As a result this motivates agilists to focus on producing quality assets because without high quality you cannot easily evolve those assets. It also motivates them to automate as much of their work as possible. These are new concepts for data professionals, most of whom are still new to the agile mindset and WoW. This problem can be overcome through training, coaching, non-solo work such as pairing or mobbing, and more importantly adopting an agile WoW (mindset shifts tend to occur as the result of changing your WoW).
- Lack of skills. Where agilists strive to be generalizing specialists with a wide range of skills, traditionalists tend to be specialized with narrower but often deeper skills. As a result data professionals coming from a traditional background are very likely to have very deep skills and knowledge within the data space, but may not have the testing background (yet) required to be successful working in an agile manner. Similarly they may not have the development skills, yet, required to automate those tests or to produce the deployment scripts required to support database evolution. Like the previous problem, this one can be overcome through training, coaching, non-solo work, and through evolving your WoW.
- Poor tooling. For a long time the data community has suffered from a lack of agile tooling. This has been slowly getting better over time, there are some particularly good tools in the DataVault 2 space as well as some good Agile data engineer tools in general, but we still have a long way to go. There are also some very interesting open source tools available to you.
6. Continuous Database Integration in Context
The following table summarizes the trade-offs associated with continuous database integration and provides advice for when (not) to adopt it.
| Advantages | Automates much of the drudgery around the overall build process Increases consistency and predictability of database evolution work Brings database evolution up to common software engineering practice Enables greater visibility into the work and work products of database evolution via automated logging of results |
|---|---|
| Disadvantages | Requires investment in automation of the database development infrastructure, potentially including new tooling Requires investment in the creation of automated tests May require training and coaching of data engineers in agile development techniques |
| When to Adopt This Practice | Minimally, you will need to have your database assets under configuration management control. Additionally, you will want to have automated testing and validation in place, or have at least started to put it in place, for a database otherwise there’s nothing of impact to invoke. |