ফাইল অনুসন্ধান (original) (raw)
জেমিনি এপিআই ফাইল সার্চ টুলের মাধ্যমে রিট্রিভ্যাল অগমেন্টেড জেনারেশন ("RAG") সক্ষম করে। প্রদত্ত প্রম্পটের উপর ভিত্তি করে প্রাসঙ্গিক তথ্য দ্রুত পুনরুদ্ধার সক্ষম করার জন্য ফাইল সার্চ আপনার ডেটা আমদানি, খণ্ড এবং সূচী করে। এই তথ্যটি তখন মডেলের প্রসঙ্গ হিসাবে ব্যবহার করা হয়, যা মডেলটিকে আরও সঠিক এবং প্রাসঙ্গিক উত্তর প্রদান করতে দেয়।
ডেভেলপারদের জন্য ফাইল সার্চ সহজ এবং সাশ্রয়ী করার জন্য, আমরা কোয়েরির সময় ফাইল স্টোরেজ এবং এম্বেডিং জেনারেশন বিনামূল্যে করছি। আপনি যখন আপনার ফাইলগুলি প্রথম ইনডেক্স করবেন (প্রযোজ্য এম্বেডিং মডেল খরচে) এবং সাধারণ জেমিনি মডেল ইনপুট / আউটপুট টোকেন খরচে তখনই এম্বেডিং তৈরির জন্য অর্থ প্রদান করবেন। এই নতুন বিলিং প্যারাডাইম ফাইল সার্চ টুলটিকে তৈরি এবং স্কেল করা সহজ এবং আরও সাশ্রয়ী করে তোলে।
সরাসরি ফাইল অনুসন্ধান স্টোরে আপলোড করুন
এই উদাহরণগুলি দেখায় কিভাবে ফাইল অনুসন্ধান স্টোরে সরাসরি একটি ফাইল আপলোড করতে হয়:
পাইথন
from google import genai
from google.genai import types
import time
client = genai.Client()
# File name will be visible in citations
file_search_store = client.file_search_stores.create(config={'display_name': 'your-fileSearchStore-name'})
operation = client.file_search_stores.upload_to_file_search_store(
file='sample.txt',
file_search_store_name=file_search_store.name,
config={
'display_name' : 'display-file-name',
}
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="""Can you tell me about [insert question]""",
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[file_search_store.name]
)
)
]
)
)
print(response.text)
জাভাস্ক্রিপ্ট
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
// File name will be visible in citations
const fileSearchStore = await ai.fileSearchStores.create({
config: { displayName: 'your-fileSearchStore-name' }
});
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
}
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation });
}
const response = await ai.models.generateContent({
model: "gemini-2.5-flash",
contents: "Can you tell me about [insert question]",
config: {
tools: [
{
fileSearch: {
fileSearchStoreNames: [fileSearchStore.name]
}
}
]
}
});
console.log(response.text);
}
run();
আরও তথ্যের জন্য uploadToFileSearchStore এর API রেফারেন্সটি দেখুন।
ফাইল আমদানি করা হচ্ছে
বিকল্পভাবে, আপনি একটি বিদ্যমান ফাইল আপলোড করতে পারেন এবং আপনার ফাইল অনুসন্ধান স্টোরে এটি আমদানি করতে পারেন :
পাইথন
from google import genai
from google.genai import types
import time
client = genai.Client()
# File name will be visible in citations
sample_file = client.files.upload(file='sample.txt', config={'name': 'display_file_name'})
file_search_store = client.file_search_stores.create(config={'display_name': 'your-fileSearchStore-name'})
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="""Can you tell me about [insert question]""",
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[file_search_store.name]
)
)
]
)
)
print(response.text)
জাভাস্ক্রিপ্ট
const { GoogleGenAI } = require('@google/genai');
const ai = new GoogleGenAI({});
async function run() {
// File name will be visible in citations
const sampleFile = await ai.files.upload({
file: 'sample.txt',
config: { name: 'file-name' }
});
const fileSearchStore = await ai.fileSearchStores.create({
config: { displayName: 'your-fileSearchStore-name' }
});
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name
});
while (!operation.done) {
await new Promise(resolve => setTimeout(resolve, 5000));
operation = await ai.operations.get({ operation: operation });
}
const response = await ai.models.generateContent({
model: "gemini-2.5-flash",
contents: "Can you tell me about [insert question]",
config: {
tools: [
{
fileSearch: {
fileSearchStoreNames: [fileSearchStore.name]
}
}
]
}
});
console.log(response.text);
}
run();
আরও তথ্যের জন্য importFile এর API রেফারেন্সটি দেখুন।
চাঙ্কিং কনফিগারেশন
যখন আপনি একটি ফাইল ফাইল সার্চ স্টোরে ইম্পোর্ট করেন, তখন এটি স্বয়ংক্রিয়ভাবে খণ্ডে বিভক্ত হয়ে যায়, এমবেড করা হয়, সূচীবদ্ধ করা হয় এবং আপনার ফাইল সার্চ স্টোরে আপলোড করা হয়। যদি আপনার চাঙ্কিং কৌশলের উপর আরও নিয়ন্ত্রণের প্রয়োজন হয়, তাহলে আপনি প্রতি চাঙ্কে সর্বাধিক সংখ্যক টোকেন এবং সর্বাধিক সংখ্যক ওভারল্যাপিং টোকেন সেট করার জন্য একটি chunking_config সেটিং নির্দিষ্ট করতে পারেন।
পাইথন
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
)
জাভাস্ক্রিপ্ট
let operation = await ai.fileSearchStores.uploadToFileSearchStore({
file: 'file.txt',
fileSearchStoreName: fileSearchStore.name,
config: {
displayName: 'file-name',
chunkingConfig: {
whiteSpaceConfig: {
maxTokensPerChunk: 200,
maxOverlapTokens: 20
}
}
}
});
আপনার ফাইল অনুসন্ধান স্টোর ব্যবহার করতে, এটিকে একটি টুল হিসেবে generateContent পদ্ধতিতে দিন, যেমনটি Upload এবং Import উদাহরণে দেখানো হয়েছে।
কিভাবে এটা কাজ করে
ফাইল অনুসন্ধান ব্যবহারকারীর প্রম্পটের সাথে প্রাসঙ্গিক তথ্য খুঁজে পেতে শব্দার্থিক অনুসন্ধান নামে একটি কৌশল ব্যবহার করে। স্ট্যান্ডার্ড কীওয়ার্ড-ভিত্তিক অনুসন্ধানের বিপরীতে, শব্দার্থিক অনুসন্ধান আপনার প্রশ্নের অর্থ এবং প্রেক্ষাপট বোঝে।
যখন আপনি একটি ফাইল আমদানি করেন, তখন এটি এম্বেডিং নামক সংখ্যাসূচক উপস্থাপনায় রূপান্তরিত হয়, যা পাঠ্যের অর্থগত অর্থ ধারণ করে। এই এম্বেডিংগুলি একটি বিশেষায়িত ফাইল অনুসন্ধান ডাটাবেসে সংরক্ষণ করা হয়। আপনি যখন একটি কোয়েরি করেন, তখন এটি একটি এম্বেডিংয়ে রূপান্তরিত হয়। তারপর সিস্টেমটি ফাইল অনুসন্ধান স্টোর থেকে সবচেয়ে অনুরূপ এবং প্রাসঙ্গিক ডকুমেন্ট খণ্ডগুলি খুঁজে পেতে একটি ফাইল অনুসন্ধান করে।
File Search uploadToFileSearchStore API ব্যবহারের প্রক্রিয়াটির একটি সংক্ষিপ্ত বিবরণ এখানে দেওয়া হল:
- একটি ফাইল অনুসন্ধান স্টোর তৈরি করুন : একটি ফাইল অনুসন্ধান স্টোরে আপনার ফাইলগুলি থেকে প্রক্রিয়াজাত ডেটা থাকে। এটি এমন এম্বেডিংয়ের জন্য স্থায়ী ধারক যার উপর শব্দার্থিক অনুসন্ধান পরিচালিত হবে।
- একটি ফাইল আপলোড করুন এবং একটি ফাইল অনুসন্ধান স্টোরে আমদানি করুন : একই সাথে একটি ফাইল আপলোড করুন এবং ফলাফলগুলি আপনার ফাইল অনুসন্ধান স্টোরে আমদানি করুন। এটি একটি অস্থায়ী
Fileঅবজেক্ট তৈরি করে, যা আপনার কাঁচা নথির একটি রেফারেন্স। সেই ডেটাটি তখন খণ্ডিত করা হয়, ফাইল অনুসন্ধান এম্বেডিংয়ে রূপান্তরিত হয় এবং সূচীবদ্ধ করা হয়।Fileঅবজেক্টটি 48 ঘন্টা পরে মুছে ফেলা হয়, যখন ফাইল অনুসন্ধান স্টোরে আমদানি করা ডেটা অনির্দিষ্টকালের জন্য সংরক্ষণ করা হবে যতক্ষণ না আপনি এটি মুছে ফেলার সিদ্ধান্ত নেন। - ফাইল অনুসন্ধানের সাথে প্রশ্ন : অবশেষে, আপনি একটি
generateContentকলেFileSearchটুল ব্যবহার করেন। টুল কনফিগারেশনে, আপনি একটিFileSearchRetrievalResourceনির্দিষ্ট করেন, যা আপনি যেFileSearchStoreঅনুসন্ধান করতে চান তার দিকে নির্দেশ করে। এটি মডেলটিকে তার প্রতিক্রিয়া ভিত্তি করার জন্য প্রাসঙ্গিক তথ্য খুঁজে পেতে নির্দিষ্ট ফাইল অনুসন্ধান স্টোরে একটি শব্দার্থিক অনুসন্ধান করতে বলে।
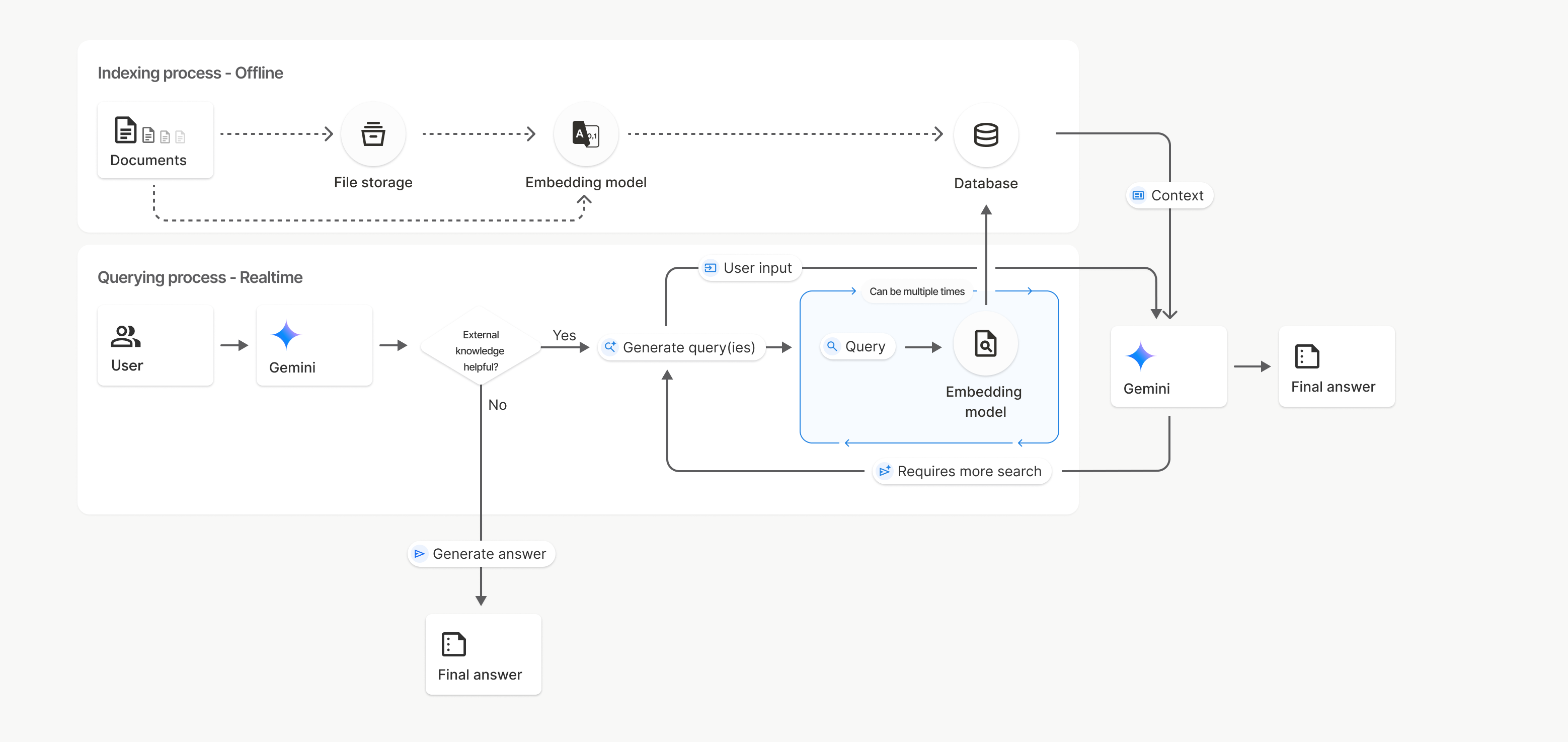
ফাইল অনুসন্ধানের সূচীকরণ এবং অনুসন্ধান প্রক্রিয়া
এই চিত্রে, Documents থেকে Embedding মডেলে ( gemini-embedding-001 ব্যবহার করে) বিন্দুযুক্ত রেখাটি uploadToFileSearchStore API ( ফাইল স্টোরেজ বাইপাস করে) উপস্থাপন করে। অন্যথায়, Files API ব্যবহার করে আলাদাভাবে ফাইল তৈরি এবং আমদানি করলে ইনডেক্সিং প্রক্রিয়াটি Documents থেকে File স্টোরেজ এবং তারপর Embedding মডেলে স্থানান্তরিত হয়।
ফাইল অনুসন্ধান স্টোর
ফাইল সার্চ স্টোর হল আপনার ডকুমেন্ট এম্বেডিংয়ের জন্য একটি কন্টেইনার। ফাইল এপিআই-এর মাধ্যমে আপলোড করা কাঁচা ফাইলগুলি ৪৮ ঘন্টা পরে মুছে ফেলা হলেও, ফাইল সার্চ স্টোরে আমদানি করা ডেটা অনির্দিষ্টকালের জন্য সংরক্ষণ করা হয় যতক্ষণ না আপনি ম্যানুয়ালি মুছে ফেলেন। আপনার ডকুমেন্টগুলি সংগঠিত করার জন্য আপনি একাধিক ফাইল সার্চ স্টোর তৈরি করতে পারেন। FileSearchStore API আপনাকে আপনার ফাইল সার্চ স্টোরগুলি পরিচালনা করার জন্য তৈরি, তালিকাভুক্ত, পেতে এবং মুছে ফেলার সুযোগ দেয়। ফাইল সার্চ স্টোরের নামগুলি বিশ্বব্যাপী বিস্তৃত।
আপনার ফাইল অনুসন্ধান স্টোরগুলি কীভাবে পরিচালনা করবেন তার কিছু উদাহরণ এখানে দেওয়া হল:
পাইথন
file_search_store = client.file_search_stores.create(config={'display_name': 'my-file_search-store-123'})
for file_search_store in client.file_search_stores.list():
print(file_search_store)
my_file_search_store = client.file_search_stores.get(name='fileSearchStores/my-file_search-store-123')
client.file_search_stores.delete(name='fileSearchStores/my-file_search-store-123', config={'force': True})
জাভাস্ক্রিপ্ট
const fileSearchStore = await ai.fileSearchStores.create({
config: { displayName: 'my-file_search-store-123' }
});
const fileSearchStores = await ai.fileSearchStores.list();
for await (const store of fileSearchStores) {
console.log(store);
}
const myFileSearchStore = await ai.fileSearchStores.get({
name: 'fileSearchStores/my-file_search-store-123'
});
await ai.fileSearchStores.delete({
name: 'fileSearchStores/my-file_search-store-123',
config: { force: true }
});
বিশ্রাম
curl -X POST "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
-H "Content-Type: application/json"
-d '{ "displayName": "My Store" }'
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores?key=${GEMINI_API_KEY}" \
curl "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
curl -X DELETE "https://generativelanguage.googleapis.com/v1beta/fileSearchStores/my-file_search-store-123?key=${GEMINI_API_KEY}"
আপনার ফাইল স্টোরে ডকুমেন্ট পরিচালনার সাথে সম্পর্কিত পদ্ধতি এবং ক্ষেত্রগুলির জন্য ফাইল অনুসন্ধান ডকুমেন্টস API রেফারেন্স।
আপনার ফাইলগুলিকে ফিল্টার করতে বা অতিরিক্ত প্রসঙ্গ প্রদান করতে আপনি কাস্টম মেটাডেটা যোগ করতে পারেন। মেটাডেটা হল কী-মান জোড়ার একটি সেট।
পাইথন
op = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
custom_metadata=[
{"key": "author", "string_value": "Robert Graves"},
{"key": "year", "numeric_value": 1934}
]
)
জাভাস্ক্রিপ্ট
let operation = await ai.fileSearchStores.importFile({
fileSearchStoreName: fileSearchStore.name,
fileName: sampleFile.name,
config: {
customMetadata: [
{ key: "author", stringValue: "Robert Graves" },
{ key: "year", numericValue: 1934 }
]
}
});
যখন আপনার ফাইল অনুসন্ধান স্টোরে একাধিক নথি থাকে এবং আপনি কেবল সেগুলির একটি উপসেট অনুসন্ধান করতে চান তখন এটি কার্যকর।
পাইথন
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="Tell me about the book 'I, Claudius'",
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[file_search_store.name],
metadata_filter="author=Robert Graves",
)
)
]
)
)
print(response.text)
জাভাস্ক্রিপ্ট
const response = await ai.models.generateContent({
model: "gemini-2.5-flash",
contents: "Tell me about the book 'I, Claudius'",
config: {
tools: [
{
fileSearch: {
fileSearchStoreNames: [fileSearchStore.name],
metadataFilter: 'author="Robert Graves"',
}
}
]
}
});
console.log(response.text);
বিশ্রাম
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent?key=${GEMINI_API_KEY}" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[{"text": "Tell me about the book I, Claudius"}]
}],
"tools": [{
"file_search": {
"file_search_store_names":["'$STORE_NAME'"],
"metadata_filter": "author = \"Robert Graves\""
}
}]
}' 2> /dev/null > response.json
cat response.json
metadata_filter এর জন্য তালিকা ফিল্টার সিনট্যাক্স বাস্তবায়নের নির্দেশিকা google.aip.dev/160 এ পাওয়া যাবে।
উদ্ধৃতি
যখন আপনি ফাইল অনুসন্ধান ব্যবহার করেন, তখন মডেলের প্রতিক্রিয়ায় উদ্ধৃতি অন্তর্ভুক্ত থাকতে পারে যা আপনার আপলোড করা নথির কোন অংশগুলি উত্তর তৈরি করতে ব্যবহার করা হয়েছিল তা নির্দিষ্ট করে। এটি তথ্য-পরীক্ষা এবং যাচাইকরণে সহায়তা করে।
আপনি প্রতিক্রিয়ার grounding_metadata বৈশিষ্ট্যের মাধ্যমে উদ্ধৃতি তথ্য অ্যাক্সেস করতে পারেন।
পাইথন
print(response.candidates[0].grounding_metadata)
জাভাস্ক্রিপ্ট
console.log(JSON.stringify(response.candidates?.[0]?.groundingMetadata, null, 2));
সমর্থিত মডেল
নিম্নলিখিত মডেলগুলি ফাইল অনুসন্ধান সমর্থন করে:
- gemini-3-pro-preview
- gemini-2.5-pro
- gemini-2.5-flash এবং এর প্রিভিউ ভার্সন
- gemini-2.5-flash-lite এবং এর প্রিভিউ ভার্সন
সমর্থিত ফাইলের ধরণ
ফাইল অনুসন্ধান বিভিন্ন ধরণের ফাইল ফর্ম্যাট সমর্থন করে, যা নিম্নলিখিত বিভাগগুলিতে তালিকাভুক্ত করা হয়েছে।
অ্যাপ্লিকেশন ফাইলের ধরণ
application/dartapplication/ecmascriptapplication/jsonapplication/ms-javaapplication/mswordapplication/pdfapplication/sqlapplication/typescriptapplication/vnd.curlapplication/vnd.dartapplication/vnd.ibm.secure-containerapplication/vnd.jupyterapplication/vnd.ms-excelapplication/vnd.oasis.opendocument.textapplication/vnd.openxmlformats-officedocument.presentationml.presentationapplication/vnd.openxmlformats-officedocument.spreadsheetml.sheetapplication/vnd.openxmlformats-officedocument.wordprocessingml.documentapplication/vnd.openxmlformats-officedocument.wordprocessingml.templateapplication/x-cshapplication/x-hwpapplication/x-hwp-v5application/x-latexapplication/x-phpapplication/x-powershellapplication/x-shapplication/x-shellscriptapplication/x-texapplication/x-zshapplication/xmlapplication/zip
টেক্সট ফাইলের ধরণ
text/1d-interleaved-parityfectext/REDtext/SGMLtext/cache-manifesttext/calendartext/cqltext/cql-extensiontext/cql-identifiertext/csstext/csvtext/csv-schematext/dnstext/encaprtptext/enrichedtext/exampletext/fhirpathtext/flexfectext/fwdredtext/gff3text/grammar-ref-listtext/hl7v2text/htmltext/javascripttext/jcr-cndtext/jsxtext/markdowntext/mizartext/n3text/parameterstext/parityfectext/phptext/plaintext/provenance-notationtext/prs.fallenstein.rsttext/prs.lines.tagtext/prs.prop.logictext/raptorfectext/rfc822-headerstext/rtftext/rtp-enc-aescm128text/rtploopbacktext/rtxtext/sgmltext/shaclctext/shextext/spdxtext/stringstext/t140text/tab-separated-valuestext/texmacstext/trofftext/tsvtext/tsxtext/turtletext/ulpfectext/uri-listtext/vcardtext/vnd.DMClientScripttext/vnd.IPTC.NITFtext/vnd.IPTC.NewsMLtext/vnd.atext/vnd.abctext/vnd.ascii-arttext/vnd.curltext/vnd.debian.copyrighttext/vnd.dvb.subtitletext/vnd.esmertec.theme-descriptortext/vnd.exchangeabletext/vnd.familysearch.gedcomtext/vnd.ficlab.flttext/vnd.flytext/vnd.fmi.flexstortext/vnd.gmltext/vnd.graphviztext/vnd.hanstext/vnd.hgltext/vnd.in3d.3dmltext/vnd.in3d.spottext/vnd.latex-ztext/vnd.motorola.reflextext/vnd.ms-mediapackagetext/vnd.net2phone.commcenter.commandtext/vnd.radisys.msml-basic-layouttext/vnd.senx.warpscripttext/vnd.sositext/vnd.sun.j2me.app-descriptortext/vnd.trolltech.linguisttext/vnd.wap.sitext/vnd.wap.sltext/vnd.wap.wmltext/vnd.wap.wmlscripttext/vtttext/wgsltext/x-asmtext/x-bibtextext/x-bootext/xctext/x-c++hdrtext/x-c++srctext/x-cassandratext/x-chdrtext/x-coffeescripttext/x-componenttext/x-cshtext/x-csharptext/x-csrctext/x-cudatext/xdtext/x-difftext/x-dsrctext/x-emacs-lisptext/x-erlangtext/x-gff3text/x-gotext/x-haskelltext/x-javatext/x-java-propertiestext/x-java-sourcetext/x-kotlintext/x-lilypondtext/x-lisptext/x-literate-haskelltext/x-luatext/x-moctext/x-objcsrctext/x-pascaltext/x-pcs-gcdtext/x-perltext/x-perl-scripttext/x-pythontext/x-python-scripttext/xr-markdowntext/x-rsrctext/x-rsttext/x-ruby-scripttext/x-rusttext/x-sasstext/x-scalatext/x-schemetext/x-script.pythontext/x-scsstext/x-setexttext/x-sfvtext/x-shtext/x-siestatext/x-sostext/x-sqltext/x-swifttext/x-tcltext/x-textext/x-vbasictext/x-vcalendartext/xmltext/xml-dtdtext/xml-external-parsed-entitytext/yaml
হারের সীমা
পরিষেবার স্থিতিশীলতা জোরদার করার জন্য ফাইল অনুসন্ধান API-এর নিম্নলিখিত সীমা রয়েছে:
- সর্বোচ্চ ফাইলের আকার / প্রতি নথির সীমা : ১০০ এমবি
- প্রকল্প ফাইল অনুসন্ধান স্টোরের মোট আকার (ব্যবহারকারী স্তরের উপর ভিত্তি করে):
- বিনামূল্যে : ১ জিবি
- স্তর ১ : ১০ জিবি
- স্তর ২ : ১০০ জিবি
- স্তর ৩ : ১ টিবি
- সুপারিশ : সর্বোত্তম পুনরুদ্ধার বিলম্ব নিশ্চিত করতে প্রতিটি ফাইল অনুসন্ধান স্টোরের আকার 20 গিগাবাইটের মধ্যে সীমাবদ্ধ করুন।
মূল্য নির্ধারণ
- বিদ্যমান এম্বেডিং মূল্যের উপর ভিত্তি করে ডেভেলপারদের থেকে ইনডেক্সিং সময়ে এম্বেডিংয়ের জন্য চার্জ নেওয়া হয় (প্রতি ১০ লক্ষ টোকেনে $০.১৫)।
- সংরক্ষণ বিনামূল্যে।
- কোয়েরি টাইম এম্বেডিং বিনামূল্যে।
- পুনরুদ্ধার করা ডকুমেন্ট টোকেনগুলি নিয়মিত প্রসঙ্গ টোকেন হিসাবে চার্জ করা হয়।
এরপর কি?
- ফাইল অনুসন্ধান স্টোর এবং ফাইল অনুসন্ধান নথির জন্য API রেফারেন্সটি দেখুন।