CodeGemma model card (original) (raw)
Model page: CodeGemma
Resources and technical documentation:
Terms of Use: Terms
Authors: Google
Model information
Model summary
Description
CodeGemma is a family of lightweight open code models built on top of Gemma. CodeGemma models are text-to-text and text-to-code decoder-only models and are available as a 7 billion pretrained variant that specializes in code completion and code generation tasks, a 7 billion parameter instruction-tuned variant for code chat and instruction following and a 2 billion parameter pretrained variant for fast code completion.
Inputs and outputs
- Input: For pretrained model variants: code prefix and optionally suffix for code completion and generation scenarios or natural language text/prompt. For instruction-tuned model variant: natural language text or prompt.
- Output: For pretrained model variants: fill-in-the-middle code completion, code and natural language. For instruction-tuned model variant: code and natural language.
Citation
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Model data
Training dataset
Using Gemma as the base model, CodeGemma 2B and 7B pretrained variants are further trained on an additional 500 to 1000 billion tokens of primarily English language data from open source mathematics datasets and synthetically generated code.
Training data processing
The following data pre-processing techniques were applied to train CodeGemma:
- FIM - Pretrained CodeGemma models focus on fill-in-the-middle (FIM) tasks. The models are trained to work with both PSM and SPM modes. Our FIM settings are 80% to 90% FIM rate with 50-50 PSM/SPM.
- Dependency Graph-based Packing and Unit Test-based Lexical Packing techniques: To improve model alignment with real-world applications, we structured training examples at the project/repository level to colocate the most relevant source files within each repository. Specifically, we employed two heuristic techniques: dependency graph-based packing and unit test-based lexical packing.
- We developed a novel technique for splitting the documents into prefix, middle, and suffix to make the suffix start in a more syntactically natural point rather than purely random distribution.
- Safety: Similarly to Gemma, we deployed rigorous safety filtering including filtering personal data, CSAM filtering and other filtering based on content quality and safety in line withour policies.
Implementation information
Hardware and frameworks used during training
Like Gemma, CodeGemma was trained on the latest generation ofTensor Processing Unit (TPU)hardware (TPUv5e), using JAX and ML Pathways.
Evaluation information
Benchmark results
Evaluation approach
- Code completion benchmarks: HumanEval (HE) (Single Line and Multiple Line Infilling)
- Code generation benchmarks: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- Q&A: BoolQ, PIQA, TriviaQA
- Natural Language: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- Math Reasoning: GSM8K, MATH
Coding benchmark results
| Benchmark | 2B | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37.8 | 44.5 | 56.1 | 60.4 |
| MBPP | 43.6 | 49.2 | 56.2 | 54.2 | 55.6 |
| HumanEval Single Line | 78.4 | 79.3 | 76.1 | 68.3 | 77.4 |
| HumanEval Multi Line | 51.4 | 51.0 | 58.4 | 20.1 | 23.7 |
| BC HE C++ | 24.2 | 19.9 | 32.9 | 42.2 | 46.6 |
| BC HE C# | 10.6 | 26.1 | 22.4 | 26.7 | 54.7 |
| BC HE Go | 20.5 | 18.0 | 21.7 | 28.6 | 34.2 |
| BC HE Java | 29.2 | 29.8 | 41.0 | 48.4 | 50.3 |
| BC HE JavaScript | 21.7 | 28.0 | 39.8 | 46.0 | 48.4 |
| BC HE Kotlin | 28.0 | 32.3 | 39.8 | 51.6 | 47.8 |
| BC HE Python | 21.7 | 36.6 | 42.2 | 48.4 | 54.0 |
| BC HE Rust | 26.7 | 24.2 | 34.1 | 36.0 | 37.3 |
| BC MBPP C++ | 47.1 | 38.9 | 53.8 | 56.7 | 63.5 |
| BC MBPP C# | 28.7 | 45.3 | 32.5 | 41.2 | 62.0 |
| BC MBPP Go | 45.6 | 38.9 | 43.3 | 46.2 | 53.2 |
| BC MBPP Java | 41.8 | 49.7 | 50.3 | 57.3 | 62.9 |
| BC MBPP JavaScript | 45.3 | 45.0 | 58.2 | 61.4 | 61.4 |
| BC MBPP Kotlin | 46.8 | 49.7 | 54.7 | 59.9 | 62.6 |
| BC MBPP Python | 38.6 | 52.9 | 59.1 | 62.0 | 60.2 |
| BC MBPP Rust | 45.3 | 47.4 | 52.9 | 53.5 | 52.3 |
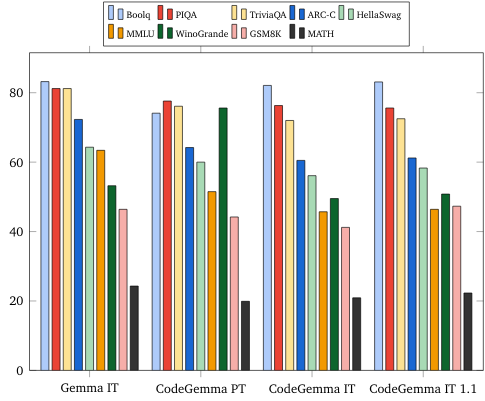
Natural language benchmarks (on 7B models)
Ethics and safety
Ethics and safety evaluations
Evaluations approach
Our evaluation methods include structured evaluations and internal red-teaming testing of relevant content policies. Red-teaming was conducted by a number of different teams, each with different goals and human evaluation metrics. These models were evaluated against a number of different categories relevant to ethics and safety, including:
- Human evaluation on prompts covering content safety and representational harms. See theGemma model cardfor more details on evaluation approach.
- Specific testing of cyber-offence capabilities, focusing on testing autonomous hacking capabilities and ensuring potential harms are limited.
Evaluation results
The results of ethics and safety evaluations are within acceptable thresholds for meetinginternal policiesfor categories such as child safety, content safety, representational harms, memorization, large-scale harms. See theGemma model cardfor more details.
Model usage and limitations
Known limitations
Large Language Models (LLMs) have limitations based on their training data and the inherent limitations of the technology. See theGemma model cardfor more details on the limitations of LLMs.
Ethical considerations and risks
The development of large language models (LLMs) raises several ethical concerns. We have carefully considered multiple aspects in the development of these models.
Please refer to the same discussionin the Gemma model card for model details.
Intended usage
Application
Code Gemma models have a wide range of applications, which vary between IT and PT models. The following list of potential uses is not comprehensive. The purpose of this list is to provide contextual information about the possible use-cases that the model creators considered as part of model training and development.
- Code Completion: PT models can be used to complete code with an IDE extension
- Code Generation: IT model can be used to generate code with or without an IDE extension
- Code Conversation: IT model can power conversation interfaces which discuss code
- Code Education: IT model supports interactive code learning experiences, aids in syntax correction or provides coding practice
Benefits
At the time of release, this family of models provides high-performance open code-focused large language model implementations designed from the ground up for Responsible AI development compared to similarly sized models.
Using the coding benchmark evaluation metrics described in this document, these models have shown to provide superior performance to other, comparably-sized open model alternatives.