Qwen3 VL 32B Instruct API | AIMLAPI (original) (raw)

![]()
Qwen3 VL 32B Instruct
Qwen3 VL 32B Instruct can be seamlessly integrated into multimodal applications requiring precise image-text interaction.
Qwen3 VL 32B API Overview
Qwen3 VL 32B Instruct is a specialized vision-language large model designed for instruction-following in tasks involving image description, visual dialogue, and content generation. It is a “non-thinking only” version optimized to excel in interpreting visual inputs and generating coherent, context-aware textual output in response to visual content and instructions.
Technical Specifications
- Model Type: Vision-Language Large Model (VL)
- Parameter Count: 32 billion
- Architecture: Transformer-based multimodal architecture combining visual encoder and text decoder
- Input Modalities: Images + Text instructions/prompts
- Output Modalities: Text generation (descriptions, dialogues, content)
- Training Data: Large-scale multimodal dataset consisting of annotated images coupled with descriptive and conversational text
- Inference: Supports zero-shot and few-shot instruction following without requiring retraining
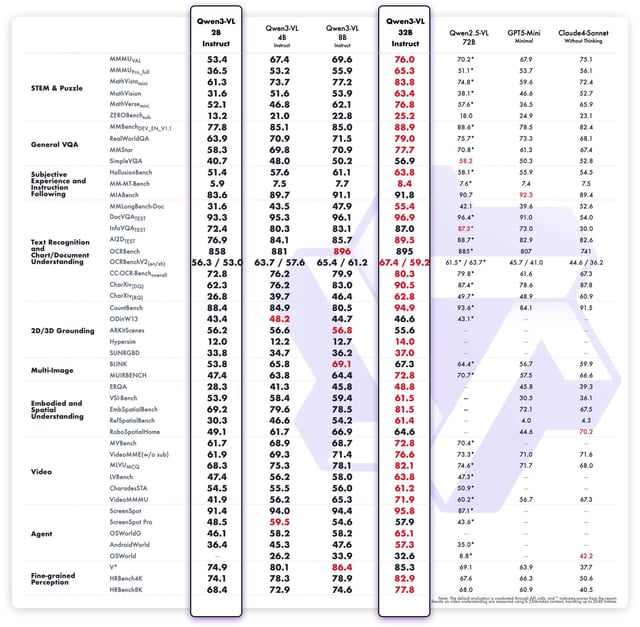
Performance Benchmarks
- Achieves state-of-the-art accuracy on visual description datasets benchmarked against COCO Caption and VQA tasks
- Demonstrates superior instruction-following abilities measured by human evaluation of relevance and coherence
- Outperforms previous Qwen VL versions in multimodal content generation quality and instruction alignment
- Exhibits robust zero-shot performance in visual dialogue tasks compared to baseline models
Key Features
- Optimized for precise and clear image description generation under user instructions
- Capable of engaging in visual dialogues, understanding complex visual context
- Produces relevant and creative visual content generation based on textual prompts
- High alignment with user instructions, reducing irrelevant or hallucinated content
- Efficient handling of large high-resolution images with fine-grained visual understanding
- Supports multilingual text output with strong language fluency
- Designed for easy integration in AI-driven content creation pipelines and interactive visual assistants
Qwen3 VL 32B API Pricing
- Input: $0.91 / 1M
- Output: $3.64 / 1M
Code Sample
Comparison with Other Models
vs Qwen3 VL 32B Base: Instruct version is fine-tuned for better instruction adherence and generates more context-relevant and accurate descriptions, whereas the base targets general multimodal understanding.
vs OpenAI GPT-4 (with vision): Qwen3 VL 32B Instruct is optimized specifically for instruction-following and visual content generation with fewer hallucinations on visual inputs; GPT-4 offers broader general AI capabilities but can be less specialized in visual instruction adherence.
vs Claude 4.5 Visual: Qwen3 VL 32B Instruct provides stronger image description and dialogue quality with a focus on visual instructions, while Claude often excels in text-based reasoning and larger context management but with slightly less visual specialization.
vs DeepSeek V3.1: Qwen3 VL 32B Instruct outperforms in detailed content generation and visualization tasks, whereas DeepSeek focuses more on semantic image search and retrieval functionality.
Qwen3 VL 32B API Overview
Qwen3 VL 32B Instruct is a specialized vision-language large model designed for instruction-following in tasks involving image description, visual dialogue, and content generation. It is a “non-thinking only” version optimized to excel in interpreting visual inputs and generating coherent, context-aware textual output in response to visual content and instructions.
Technical Specifications
- Model Type: Vision-Language Large Model (VL)
- Parameter Count: 32 billion
- Architecture: Transformer-based multimodal architecture combining visual encoder and text decoder
- Input Modalities: Images + Text instructions/prompts
- Output Modalities: Text generation (descriptions, dialogues, content)
- Training Data: Large-scale multimodal dataset consisting of annotated images coupled with descriptive and conversational text
- Inference: Supports zero-shot and few-shot instruction following without requiring retraining
Performance Benchmarks
- Achieves state-of-the-art accuracy on visual description datasets benchmarked against COCO Caption and VQA tasks
- Demonstrates superior instruction-following abilities measured by human evaluation of relevance and coherence
- Outperforms previous Qwen VL versions in multimodal content generation quality and instruction alignment
- Exhibits robust zero-shot performance in visual dialogue tasks compared to baseline models
Key Features
- Optimized for precise and clear image description generation under user instructions
- Capable of engaging in visual dialogues, understanding complex visual context
- Produces relevant and creative visual content generation based on textual prompts
- High alignment with user instructions, reducing irrelevant or hallucinated content
- Efficient handling of large high-resolution images with fine-grained visual understanding
- Supports multilingual text output with strong language fluency
- Designed for easy integration in AI-driven content creation pipelines and interactive visual assistants
Qwen3 VL 32B API Pricing
- Input: $0.91 / 1M
- Output: $3.64 / 1M
Code Sample
Comparison with Other Models
vs Qwen3 VL 32B Base: Instruct version is fine-tuned for better instruction adherence and generates more context-relevant and accurate descriptions, whereas the base targets general multimodal understanding.
vs OpenAI GPT-4 (with vision): Qwen3 VL 32B Instruct is optimized specifically for instruction-following and visual content generation with fewer hallucinations on visual inputs; GPT-4 offers broader general AI capabilities but can be less specialized in visual instruction adherence.
vs Claude 4.5 Visual: Qwen3 VL 32B Instruct provides stronger image description and dialogue quality with a focus on visual instructions, while Claude often excels in text-based reasoning and larger context management but with slightly less visual specialization.
vs DeepSeek V3.1: Qwen3 VL 32B Instruct outperforms in detailed content generation and visualization tasks, whereas DeepSeek focuses more on semantic image search and retrieval functionality.