Web系女子がLispと出会って統計学に目覚めるまでのお話 (original) (raw)
この広告は、90日以上更新していないブログに表示しています。
こんにちは!今年の春からWeb系企業でHTML/CSSデザイナーとして働きだしたキラキラ女子(を目指してる)のあんちべ(23)です!よろしくお願いします!私は普段自社のWebサービスのCSSなどを書いている*1のですが、最近データマイニングに興味を持ち始め、データを分析して、自社サービスの売り上げ改善に貢献したいなーと思うようになりました!でも。。。私は文系出身で統計学とか全然わからない*2し、プログラミングも得意じゃない*3し、高価な統計解析ソフトを買うのも辛いです。。。無い無い尽くしですね><;!そんな私に救いの手が!インストール作業不要で、便利な統計処理機能が色々あって、しかも無料という素晴らしいソフト*4を発見しました!その名も"Incanter"です!なんでも、 Lispっていう古くから使われてきた実績のあるプログラミング言語で動いてて、Lispの文法でどんな処理をすればよいかを書くみたいです。Lispって全然知らないのですが、ちょっと勉強したらとっても簡単に使えるようになりました*5!皆さんもぜひこのIncanterでデータマイニングをしてみましょう!この記事は「殆どプログラミングとかしたことないし、とーけー学も知らないし、仮に手法を知ってても分析って何をどう進めていくのか全然イメージ着かないよ〜」という私みたいな人を対象に書きました!一緒に勉強しましょう!
この記事では次のようなトピックスについてご説明します。
- 「5分で入門Incanter!」
- 「最初は何をすればいいのかな?そうだ、探索的データ解析でデータをじっくり眺めよう!」
- 「コンバージョンに最も影響を与えるのは何?」→回帰分析
- 「本当に施策の効果はあったのかな?」→t検定で効果検証
5分でIncanter入門!
Incanterをこちら(http://incanter.org/downloads/incanter.jar)からダウンロードして、好きなフォルダに置きます。後はincanter.jarをダブルクリックするだけ!するとこのような画面が表示されます。
この画面に(str "hello world")と入力すると、"hello world"と出力されます。(+ 1 2)と入力すると3が表示されます。(+ 1 2 3 4 5)と入力すると15になります。これがLispの特徴である「前置記法」というもので、+とか-とかを括弧の一番前に置くから前置記法というらしいです。(+ 1 2 3 4 5)と打つの、1+2+3+4+5って打つより楽でいいですね、素敵!Incanterには統計処理やグラフ描画用のとっても便利な機能がいっぱいあります!それを利用するために、最初に(use '(incanter core charts io stats datasets))と打ち込みます。coreはその名の通りIncanterのコア部分、chartsはグラフ描画、ioはファイルの保存や読み込み、statsは統計関数、datasetsにはサンプル用のデータセットが中に詰まってるそうです。他にももっといっぱいあるみたいですが、まずはこれらの使い方を学んでいきましょう!
とりあえずはこれで大丈夫!もっと詳しく知りたい方はこっち(http://d.hatena.ne.jp/AntiBayesian/20111128)も読んでみてね!ではでは、準備も終わったことですし、Incanterを使ってデータマイニングをしていきましょう!
「最初は何をすればいいのかな?そうだ、探索的データ解析でデータをじっくり眺めよう!」*6
データマイニングがしたい!!。。。のですが、何から始めていいか全然分かりません><;!どうすればいいんでしょうか?う〜ん、困りました。。。。ふと本棚を見たら、テューキーという可愛い名前の先生が書いたExploratory Data Analysisというとーけー学の本がたまたま入っていたので*7、それを眺めてみると、
Graphs force us to note the unexpected; nothing could be important.
(グラフは私たちに思いもしなかったことを気付かせてくれるんだ、こんな大事なことってないよね!)
Different graphs show us quite different aspects of the same data.
(異なるグラフは私たちに、同じデータの全く異なる側面を見せてくれる)
というかっこいー言葉が書いてました*8。何でも、この本によると、最初にデータを色んなグラフで表現したり、平均や分散といったデータを要約してくれる統計量、その名も要約統計量(そのままですね><)というものを眺めるのがとても重要だそうです。。よくわからないけど、探索的データ解析っていうらしいです!確かに、データって数字や文字の羅列で、あれをそのまま眺めてても何もわからない気がします。パッと見で誰でもわかるように、データの特徴を掴むことがとっても大切ですね!よーし、まずは要約統計量を求めたりグラフを描いたりしましょう!じゃあ早速Excelやイラストレーターを立ち上げ。。。るんじゃなくて、Incanterを使いましょう。Incanterは色んな計算をしてくれたりグラフを描く機能も充実してるみたいです!うれしい><!
弊社はA,B,Cという3つのサービスを提供しています。その3サービスの月次売上データが以下の表であるとします。month列が1〜10月を、ABCの列は各サービスのその月の売上(単位:万円)を表しています。
| month | A | B | C |
|---|---|---|---|
| 1 | 278 | 112 | 268 |
| 2 | 302 | 132 | 232 |
| 3 | 298 | 155 | 210 |
| 4 | 312 | 188 | 180 |
| 5 | 334 | 178 | 156 |
| 6 | 347 | 202 | 0 |
| 7 | 372 | 211 | 158 |
| 8 | 382 | 232 | 188 |
| 9 | 376 | 273 | 227 |
| 10 | 365 | 288 | 265 |
ここから要約統計量を算出してみます!私にもできるかな。。。><;!このデータをメモ帳にコピペして各データをカンマ区切りにして、"data.csv"って名前を付けて、incanter.jarと同じフォルダに保存してね。ではでは、ファイルをIncanterに読み込んでもらって、分析できるように準備します。
(def data (read-dataset "data.csv" :header true))
これは、read-dataset "data.csv"の部分が「"data.csv"というファイルを分析用のデータセットとして読みこむよ!」という意味で、:header trueは「あ、でも、一行目はデータそのものじゃなくて、データを説明するヘッダーとして読みこんでね」っていうお願いです。def dataの部分は、そうして読みこんだデータをdataっていう箱*9みたいなのに入れてねっていうお願いです。さて、ちゃんとデータは入ったかな?Incanterにdataって入力すると、さっきdataに入れたデータ内容が表示されます。ちなみに、データは(view data)ってやると、Excelみたいな感じでdataの中身が表示されます。こっちの方が見やすいので、データの中身を詳細に確認したいときはviewを使いましょう。($ :month data)とすると、dataのmonth列だけを抽出することが出来ます。抽出したデータを後々便利なよう、各々以下のように割り当てます。
(def month ($ :month data)) (def A ($ :A data)) (def B ($ :B data)) (def C ($ :C data))
準備もできたところで、いよいよ要約統計量として、平均と中央値と分散を求めてみましょう。
(mean ($ :A data))
336.6 (median ($ :B data)) 195.0 (variance ($ :C data)) 5955.599999999996
これらを利用すると、色々わかってきます。なんとなくデータを眺めると、平均値はAが一番大きそうだなーって目星はつきますが、BとCはどっちが大きいかよくわからないですね。(str "Bの平均値:" (mean B))、(str "Cの平均値:" (mean C))とすると、Bの平均値の方が大きいことがわかりました。ふむふむ、ということは、Bの方が平均的に売り上げが高いということですね!出来るだけ売り上げの大きいサービスに、広告や開発スタッフなどのリソースを注力したいなーと思うので、この場合Bに注力すればいいってことがわかりました!やったー!そうだ、探索的データ解析では、様々なグラフも見るのでした。続いてグラフ描画をしてみましょう!(view (line-chart month C))とすると、横軸にmonth、縦軸にCの折れ線グラフが描かれます。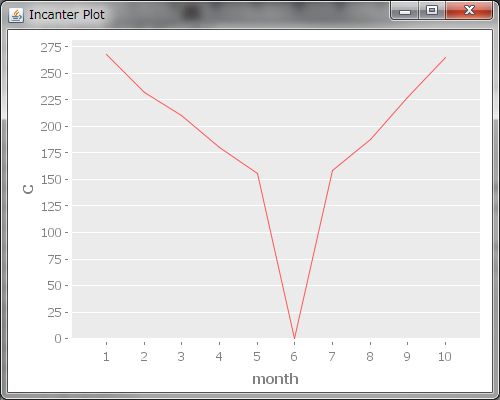
。。。あれっ?よく見てみると、サービスCは6月の売り上げが0になってますね?どうしてでしょう?いくらなんでもいきなり0になるのはおかしいんじゃないかな?疑問に思ったので、サービスC担当の開発スタッフの方にヒアリングしてみました*10。すると、サービスCは7月にリニューアルするため、6月はサービスを停止していたそうです。ふー、危ない危ない、折れ線グラフを見ずに平均値だけ見ていたら、困ったことになるところでした><。こういう何らかの要因によって、普段と全く違う値が出てくることがあって、これを外れ値*11って言うみたいです。平均値はこういう外れ値に大きく左右されてしまうってさっきのテューキー先生の本に書いてました。う〜ん、さっきも言いましたが、出来るだけ売り上げの大きいサービスに注力したいので、本当に売り上げの大きいサービスがどれかを知りたいですね。こういう外れ値を毎回見つけるのはちょっと面倒です。外れ値があっても大丈夫っぽい要約統計量ってないのかな?どうもテューキー先生の本を読むと、「頑健性」という概念があり、要するに「頑健性が高い=外れ値の影響を受けにくい」ということだそうです。そして、平均よりも中央値の方が頑健性が高い*12そうです。では中央値を比較してみましょう。(median B)と(median C)を実行してみると。。。今度はCの方が大きな値になりました。なるほど〜、外れ値の影響ってすごいですね。そして、色んな統計値やグラフを眺めなさいっていうテューキー先生の助言はこういう意味だったんですね!勉強になりました。じゃあ注力すべきサービスはCの方ですね!*13
次に、散布図も見てみましょう。散布図を見ると、サービス間の関係性がわかります。(view (scatter-plot A B))でAとBの散布図が描画されます。(view (scatter-plot B C))と(view (scatter-plot A C))も実行しましょう、えいっと。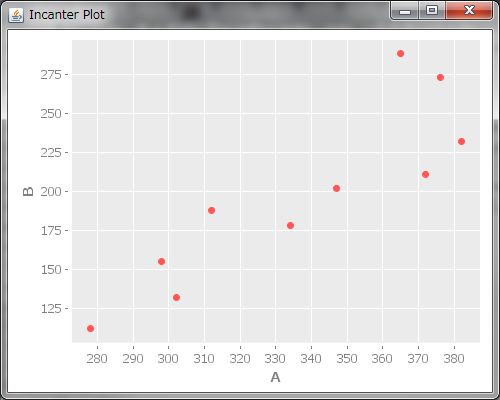
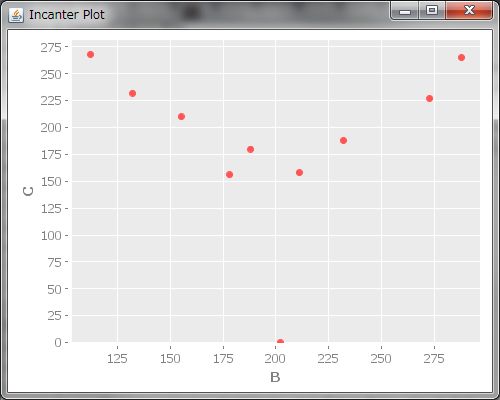
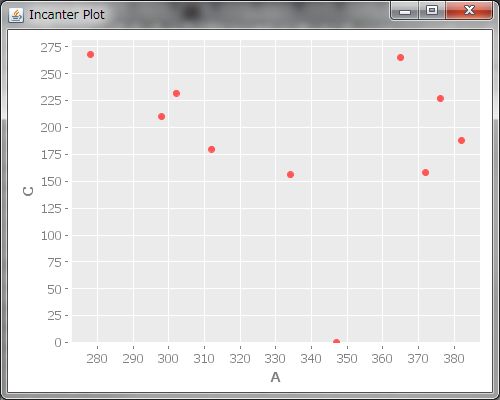
どうも、AB間は右上がりで、BC間はVの字、AC間は。。。なんでしょうねこれ。。。?AB間に右上がり、つまり、どっちかが上がるともう一方も上がるって関係があるということは、もしかするとAのサービスを利用して下さるお客様とBのお客様は何か共通点があるのかも?例えば、AとBは同じターゲティング層なのかもしれません。ということは、サービス間での連動キャンペーンを開催すると、売上が上がるかも!?散布図を描くと、どの変数とどの変数にどんな関連があるのかがわかるんですね、すごい!!なんとなく関係性があるのはわかりましたが、もっと具体的にどれくらい関係性があるのかを知りたくなってきました。そういう時は、相関係数というのを出すそうです。相関係数は(correlation A B)とすると計算してくれます。AB間の相関係数は0.88ととっても高いことが分かりました。さらにBC間の相関係数も出してみると。。。あれ、-0.03、とっても小さいですね。全然関係が無いということでしょうか?う〜ん、でも、さっき散布図を描いたら、BCにはV字の関係性があったように見えます。これはどういうことでしょうか?相関係数について調べてみると、どうやら、相関係数は直線的な関係性について調べるものであって、BC間のV字やAC間のような形の関係性については上手く表現できないみたいです。そういうときは、相関係数の値を鵜呑みにしてはいけませんね。またまた同じデータを散布図と相関係数という違った側面から眺めることで、データについてより深く学ぶことが出来ました。でも私は今回は散布図を見たら明らかに直線の関係じゃないってことがわかりましたが、微妙に直線っぽい散布図の時もあると思います。相関係数の妥当性を調べるにはどうすればいいんだろう。。。?調べると、Incanterにはとっても便利な機能がいっぱいあって、(correlation-linearity-test A B)とすると、AB間に直線の関係があるかどうか確認してくれるみたいです!やったー!出てきた値が0.05未満なら、直線の関係があるって言って良いそうです。(correlation-linearity-test A B)は0.044なので、線形の関係があるって言って良さそうですね。そして(correlation-linearity-test B C)としてみると。。。0.10なので、0.05の2倍です、線形の関係があるとはいえない*14ようです。
ふー、長かったけど、2つとってもいいことが分かりました。一つは外れ値の影響を考慮して、注力すべきサービスの順番がわかったこと。もう一つは、サービス間にどのような関係性があるかがわかったこと。こうして得られた知見をもとに、どんどん売り上げを改善していきましょう!
「コンバージョンに最も影響を与えるのは何?」→回帰分析
コンバージョンを伸ばしたいです。。。切実に伸ばしたいです。。。でも、どうやれば伸ばせるのでしょうか?コンバージョンに至るまでに、色んな変数が絡み合っているので、中々どの変数がどの程度関係するのか、よくわかりません。コンバージョンに一番関係しそうな変数がわかれば、その変数を改善するような施策に注力できるんですけど。。。困ったときはIncanter!とにかく何とかしてくれる可愛い子!今回は、Incanterのlinear-modelっていうのを使います。とーけー学の本に出てくる重回帰分析とかいうものらしいです!ふむふむ、この重回帰分析という分析をすると、「回帰係数」という「各説明変数が目的変数を説明するのにどれだけ役立ったか」を示す数値が出てくるらしいです。どういう意味でしょうか?え〜と、例えば、目的変数を売り上げとしたら、PVやクリック回数などが説明変数として利用できそうですね。そして、回帰分析をすると、PVやクリック回数がどの程度売り上げに影響するかを教えてくれるらしいです。回帰係数が大きければ大きい程、その変数は重要です。回帰係数がマイナスだったりすると、その変数は目的変数に対してマイナスの効果を与えるということを示しているみたいです。マイナスの効果を与える変数ってなんでしょう、、、う〜ん、障害回数とかかな?なるほど、私が欲しいのはこの回帰係数ですね!それと、もう一つ、「決定係数」というものも見ないといけないそうです。決定係数は分析の結果がどれくらい実際のデータに対して説明力を持つかということを表しているそうです。う〜ん、、、ちょっとよくわかりませんが、どうもこの値が低いと、分析結果をあんまり信用してはいけないみたいですね*15。なるほどー、ということは、まず回帰分析をするときは決定係数と回帰係数を見ればいいんですね!ではでは、そろそろ実践に移りたいと思います!
次のようなサービスAの売り上げと、それに関連しそうなログ(view:ページ閲覧回数(単位:千)、click:クリック回数(単位:千)、login:ログイン回数(単位:千)、discount:平均値下げ幅、bonus:平均付与特典ポイント)を集めたデータファイルがあるとします。これをコピーしてIncanterと同じフォルダにreg.csvと名付けて保存してね!その準備が終わったら、↓のコードをIncanterにコピペします!
| A | view | click | login | discount | bonus |
|---|---|---|---|---|---|
| 278 | 27 | 242 | 107 | 21 | 102 |
| 302 | 29 | 694 | 123 | 24 | 107 |
| 298 | 32 | 322 | 117 | 23 | 111 |
| 312 | 49 | 674 | 120 | 29 | 97 |
| 334 | 39 | 827 | 154 | 32 | 102 |
| 347 | 36 | 784 | 167 | 33 | 102 |
| 372 | 29 | 763 | 188 | 32 | 115 |
| 382 | 32 | 743 | 190 | 30 | 115 |
| 376 | 31 | 642 | 187 | 32 | 115 |
| 365 | 33 | 582 | 176 | 29 | 102 |
(use '(incanter core charts io stats datasets)) (def reg-matrix (to-matrix (read-dataset "reg.csv" :header true))) (def A (sel reg-matrix :cols 0)) (def lm (linear-model A (sel reg-matrix :cols (range 1 6))))
(str "回帰係数:" (:coefs lm) ", 自由度調整済み決定係数:" (:adj-r-square lm))
"回帰係数:(105.84756925102556 1.536568888859847 0.0038050803303892877 1.3632247569223068 -2.45697750029467 0.35739630831540126), 自由度調整済み決定係数:0.9932540338906779"
(simple-regression A (sel regma :cols (range 1 6)))
出てきた値は…決定係数は0.99、とっても高い!なので、このモデルは信頼できそうですね!そして回帰係数を見てみると、一番左が切片とかいうのらしいです。で、それ以降の数値が各説明変数の回帰係数です。ふむふむ、どうもviewは1.536と高いですね。あれ、discountがマイナスです。。。しかもすごく大きいマイナスです><;値下げ、実は売り上げに対して足を引っ張るみたいです、なんて悲しいんでしょう、涙が出そうですね。。。!!というわけで、viewを増やすと売り上げ改善!そして値下げはあんまりしない方がいいという衝撃の事実が判明しました。。。だってお客さん喜ぶと思ったんです。。。
さて、回帰分析のお陰で、どのKPIに一番注目すればいいのかが一目瞭然になりました!よーし、viewをどんどん増やして業績を上げるぞー!
「本当に施策の効果はあったのかな?」→t検定で効果検証
viewを増やせば業績改善!を合言葉に、色々イベントや広告を出したりしました!その効果は!?preがイベント前、postがイベント後のview回数(単位:千)です。
| pre | post |
|---|---|
| 27 | 37 |
| 29 | 36 |
| 32 | 37 |
| 49 | 39 |
| 39 | 38 |
| 36 | 39 |
| 29 | 38 |
| 32 | 36 |
| 31 | 38 |
| 33 | 37 |
やったー、viewを合計すると、1割以上数値が大きくなりました!やりました、私エライ!!もうテンションあげあげぽよぽよです!!!しかし、油断は禁物です。とーけー学には検定という概念があり、値の増減が単なる偶然の範囲内なのかそうじゃないのかを判定する方法があるそうです。もちろん私は信じています、viewは1割以上あがったもん、偶然じゃないもん、私努力したもん!きっと検定とかいうのやっても、偶然じゃなくて私の努力のたまものだっていう結果が出てくるはずです!では実際試してみましょう!検定にはいろいろな種類があるそうですが、今回はデータの平均値に偶然ではない程度の差があるかどうかを知りたいので、本を読むとt検定というのを使えばいいそうです。さっすがIncanter、t検定もばっちりあります!!このt検定ってのをやって、p値が決められた水準以下(有意水準っていうらしいです)だと、偶然程度の差ではないって言えるらしいです*16。早速レッツゴーです!有意水準は5%が慣例っぽいので、5%でやってみましょう!*17
(def t (read-dataset "t_test.csv" :header true)) (def PRE ($ :pre t)) (def POST ($ :post t)) (t-test PRE :y POST)
{:conf-int [-8.451959353280216 0.8519593532802219], :x-mean 33.7, :t-stat -1.8478659347675677, :p-value 0.09590804296406692, :n1 10, :df 9.510262082605253, :n2 10, :y-var 1.1666666666666667, :x-var 41.122222222222064, :y-mean 37.5}
えーと、p-valueが0.0959。。。えーと。。。えーと。。。え、え〜と!???こういうときはどうしたらいいんでしょうか?Incanterは賢いので、きっと何かいい手段があるはず。。。あれ、そもそもp値がなんで0.05以下じゃないといけないんだっけ?ってゆうか、p値って。。。何???
う〜ん、どうやら、良いソフトやたくさんのデータがありさえすれば、すべてが解決するというわけでは無さそうです。「統計学を拓いた異才たち」という本を読むと、統計学の各手法にはいろいろな制約や前提があり、それらをきちんと学ばないと正しい結果は得られない、それなのにたくさんの人たちがブラックボックスとして統計学を使って、自分の言いたいことや思い込みを統計学を使って科学の装いをさせて主張してるのはとっても良くない事だから、しっかり統計学のお勉強をしましょう。。。という趣旨の事が書いていました。今の時代、色んなデータが公開されているし、IncanterやRのような素晴らしい統計のフリーソフトがあるので、あとは統計学を学びさえすれば素晴らしい知見が得られると思います。せっかくIncanterと出会ったんだし、私はこれから一生懸命統計学のお勉強をして、もっともっと改善に役立てていきたいなーと思います。
終わりに
はい、皆さんお疲れ様でした!Incanterを使うととっても簡単に統計解析が出来て楽しいですね!最後に参考となるサイトや本と、私が勉強した時のメモをご紹介して終わりにしたいと思います。
(def data (sample-normal 10))
(covariance x y) (correlation x y)
(correlation-linearity-test a b)
(jaccard-distance a b)
user=> (n-grams 2 "hello, my friend") #{"ll" "lo" " f" "el" "y " "en" "fr" "my" " m" ", " "nd" "ri" "ie" "he" "o,"}
(quantile (sample-normal 100)) (quantile (sample-normal 100) :probs [0.025 0.975]) (quantile (sample-normal 100) :probs 0.975)
(rank-index x)
(def iris (to-matrix (get-dataset :iris) :dummies true)) (def y (sel iris :cols 0)) (def x (sel iris :cols (range 1 6))) (def iris-lm (linear-model y x))
(keys iris-lm) (:coefs iris-lm) (:sse iris-lm) (quantile (:residuals iris-lm)) (:r-square iris-lm) (:adj-r-square iris-lm) (:f-stat iris-lm) (:f-prob iris-lm) (:df iris-lm)
(def x1 (range 0.0 3 0.1)) (view (xy-plot x1 (cdf-f x1 :df1 4 :df2 144)))
(sample (range 10)) (sample [:red :green :blue] :size 10) (sample (seq "abcdefghijklmnopqrstuvwxyz") :size 4 :replacement false)
(skewness x)
(use '(incanter core stats charts))
(def mvn-samp (sample-mvn 1000 :mean [7 5] :sigma (matrix [[2 1.5] [1.5 3]])))
(def x (sel mvn-samp :cols 0))
(def y (sel mvn-samp :cols 1))
(def lm (linear-model y x))
(doto (scatter-plot x y) view (add-lines x (:fitted lm)))