Bartosz Milewski's Programming Cafe (original) (raw)
June 20, 2025
Previously: Fibrations and Cofibrations.
In topology, we say that two shapes are the same if there is a homeomorphism– an invertible continuous map– between them. Continuity means that nothing is broken and nothing is glued together. This is how we can turn a coffe cup into a torus. A homeomorphism, however, won’t let us shrink a torus to a circle. So if we are only interested in how many holes the shapes have, we have to relax our notion of equivalence.
Let’s go back to the definition of homeomorphism. It is defined as a pair of continuous functions between two topological spaces, 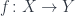




If we want to allow for extreme shrinkage, as with a torus shrinking down to a circle, we have to relax the identity conditions.
A homotopy equivalence is a pair of continuous functions, but their compositions don’t have to be equal to identities. It’s enough that they are homotopic to identities. In other words, it’s possible to create an animation that transforms one to another.
Take the example of a line 

Indeed, let’s construct the equivalence as a pair of constant functions: 




The composition 




(
![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=29303b&s=0&c=20201002)


When a space is homotopy equivalent to a point, we say that it’s contractible. Thus 
Another way of looking for holes in spaces is by trying to shrink loops. If there is a hole inside a loop, it cannot be continuously shrunk to a point. Imagine a loop going around a circle. There is no way you can “unwind” it without breaking something. In fact, you can have loops that wind n times around a circle. They can’t be homotopied into each other if their winding numbers are different.
In general, paths in a topological space 

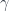





Moreover, two paths can be composed, as long as the endpoint of one coincides with the start point of the other (after performing appropriate reparametrizations).

There is a unit of such composition, a constant path; and every path has its inverse, a path that traces the original but goes in the opposite direction.

It’s easy to see that path composition induces a groupoid structure on the set of equivalence classes of paths. A groupoid is a category in which every morphism (here, path) is invertible. This particular groupoid is called the fundamental groupoid of the topological space
If we pick a base point 

Notice that, as long as there is a path 



So there is essentially a single fundamental group for the whole space, as long as
Going back to our example of a circle, its fundamental group is the group of integers 

Negative integers correspond to loops winding in the opposite direction. If you follow an n-loop with an m-loop, you get an (m+n)-loop. Zero corresponds to loops that can be shrunk to a point.
To tie these two notions of hole-counting together, it can be shown that two spaces that are homotopy equivalent also have the same fundamental groups. This makes sense, since equivalent spaces have the same holes.
Not only that, they also have the same higher homotopy groups (as long as both are path-connected).
We define the n-th homotopy group by replacing simple loops (which are homotopic to a circle, or a 1-dimensional sphere) with n-dimensional spheres. Attempts at shrinking those may detect higher-dimensional holes.
For instance, imagine an Earth-like ball with it’s inner core scooped out. Any 1-loop inside its bulk can be shrunk to a point (it will glide off the core). But a 2-sphere that envelops the core cannot be shrunk.

In fact such a 2-sphere can be wrapped around the core an arbitrary number of times. In math notation, we say:

Corresponding to these higher homotopy groups there is also a higher homotopy groupoid, in which there are invertible paths, surfaces between paths, volumes between surfaces, etc. Taken together, these form an infinity groupoid. It is exactly the inspiration behind the infinity groupoid in homotopy type theory, HoTT.
Spaces that are homotopy equivalent have the same homotopy groups, but the converse is not true. There are spaces that are not homotopy equivalent even though they have the same homotopy groups. This is why a weaker version of equivalence was introduced.
A map between topological spaces is called a weak homotopy equivalence if it induces isomorphisms between all homotopy groups.
There is a subtle difference between strong and weak equivalences. Strong equivalence can be broken by a local anomaly, like in the following example: Take 


The singleton set 
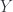
Grothendieck conjectured that the infinity groupoid captures all information about a topological space up to weak homotopy equivalence.
Weak equivalences, together with fibrations and cofibrations, form the foundation of weak factorization systems and Quillen model categories.
May 30, 2025
Previously: Subfunctor Classifier.
We are used to thinking of a mapping as either being invertible or not. It’s a yes or no question. A mapping between sets is invertible if it’s both injective and surjective. It means that it never merges two elements into one, and it covers the whole target set.
But if you are willing to look closer, the failures of invertibility are a whole fascinating area of research. Things get a lot more interesting if you consider mapping between topological spaces, which have to skillfully navigate around various holes and tears in the target space, and shrink or glue together parts of the source space. I will be glossing over some of the topological considerations, concentrating on the big-picture intuitions (both culinary and cinematographic).
Fibrations
In what follows, we’ll be considering a function 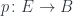

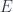

Let’s start by considering the first reason for a failure of invertibility: multiple elements being mapped into one. Even though we can’t invert such a mapping, we can use it to fibrate the source
To each element 
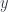


For some 

Notice that
A set-theoretic union of all fibers reconstructs the total set
Things get more interesting when we move to topological spaces and continuous functions. To begin with, we can define a path in ![I = [0, 1]](https://s0.wp.com/latex.php?latex=I+%3D+%5B0%2C+1%5D&bg=ffffff&fg=29303b&s=0&c=20201002)

We can then ask if it’s possible to lift this path to 



This setup can be summarized in the commuting square:

The lifting 

It’s helpful to imagine a path as a trajectory of a point moving through a topological space. The parameter 
In homotopy theory we generalize this idea to the movement, or deformation, of arbitrary shapes, not just points.
If we describe such a shape as the image of some topological space 
A homotopy lifting property is expressed as the existence of the diagonal function 

In other words, given a homotopy 



Cofibrations
In category theory, every construction has its dual, which is obtained by reversing all the arrows. In topology, there is an analogous relation called the Eckmann-Hilton duality. Besides reversing the arrows, it also dualizes products to exponentials (using the currying adjunction), and injections to surjections.
When dualizing the homotopy lifting diagram, we replace the trivial injection of 





The homotopy lifting property is thus dualized to the homotopy extension property:

Corresponding to the fibration that deals with the failure of the injectivity of 
If the mapping
Let’s deconstruct the meaning of the outer commuting square.

The commuting condition for this square means that the starting points of all these paths, the result of applying 
With this setup, we postulate the existence of the diagonal mapping 

The spaghetti extruded through the
Another intuitive description of this situation uses the idea of homotopy as animation. The strands of spaghetti become trajectories of particles.
We start by setting up the initial scene. We embed 
We have the embedding 

Then we animate the embedding of

The initial frame of this animation is given by 

We say that

whose starting frame is given by


The commuting condition (for the lower triangle) means that the two animations coincide for all 

Just like a fiber is an epitome of non-injectiveness, one can define a cofiber as an epitome of non-surjectiveness. It’s essentially the part of
As a topological space it’s the result of shrinking the image of
Notice that, unlike with fibers, there is just one cofiber for a given cofibration (up to homotopy equivalence).
Lifting Property
A category theorist looking at the two diagrams that define, respectively, homotopy lifting and extension, will immediately ignore all the superfluous details. She will turn the second diagram upside down and merge it with the first diagram to get:

This is how we read the new diagram: If for any morphisms 

Or we can say that the two morphisms are orthogonal to each other.
The motivation for this nomenclature is interesting. In the category of sets, the archetypal non-surjective function is the “absurd” 


Indeed, the function at the bottom 

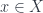


Similarly, we can show that all injective functions are orthogonal to the archetypal non-injective function 


Indeed, assume that 
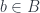




Incidentally, injections are also _right_-orthogonal to the archetypal non-injection.
Next: (Weak) Homotopy Equivalences.
April 21, 2025
Previously: Subobject Classifier.
In category theory, objects are devoid of internal structure. We’ve seen however that in certain categories we can define relationships between objects that mimic the set-theoretic idea of one set being the subset of another. We do this using the subobject classifier.
We would like to define a subobject classifier in the category of presheaves, so we could easily characterize subfunctors of a given presheaf. This will help us work with sieves, which are subfunctors of the hom-functor 
Recall that a presheaf 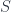

As category theory goes, this is a very low-level definition. We need something more abstract: We need to construct a subobject classifier in the category of presheaves. Recall that a subobject classifier is defined by the following pullback diagram:

This time, however, the objects are presheaves and the arrows are natural transformations.
To begin with we have to define a terminal presheaf, 
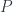




Next, let’s instantiate the subobject classifier diagram at a particular object 

Here, the component 




The second condition in the definition of a subfunctor is more interesting. It involves the mapping of morphisms.
The restriction condition
We have to consider all morphisms converging on our object of interest 




Specifically the restriction condition tells us that, if we pick an element 



Now consider an arbitrary 
If 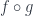

Moreover, if
We can now define a function

The function
It makes sense then to define
The mapping 





Notice that the resulting sieve 

It can be shown that the the functions 
What remains to be shown is that this 
To show that, let’s assume that there is another natural transformation 
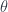

Let’s pick an 
The pullback condition:

tells us that 


Using naturality of

we can rewrite it as:

Both sides of this equation are sieves. By definition, the lifting of 


Since 

We have shown that the condition 

Subfunctor classifier
The subobject classifier in the category of presheaves is thus a presheaf 

Every natural transformation
But there’s not one but many different ways of failing the subset test. They are given by non-maximal sieves. We may think of them as satisfying the Anna Karenina principle, “All happy families are alike; each unhappy family is unhappy in its own way.”
Why sieves? Because once an element of a set 
Next: Fibrations and Cofibrations.
March 20, 2025
Proviously Sieves and Sheaves.
We have seen how topology can be defined by working with sets of continuous functions over coverages. Categorically speaking, a coverage is a special case of a sieve, which is defined as a subfunctor of the hom-functor
We’d like to characterize the relationship between a functor and its subfunctor by looking at them as objects in the category of presheaves. For that we need to introduce the idea of a subobject.
We’ll start by defining subobjects in the category of sets in a way that avoids talking about elements. Here we have two options.
The first one uses a characteristic function. It’s a predicate that answers the question: Is some element
But we still have to define a Boolean set. Let’s call this set 
The second way to define a subset 

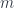
Notice that there can be many injections that define the same subset. It’s okay for them to permute the image of
The fact that the two definitions coincide can be summarized by one commuting diagram. In the category of sets, given a characteristic function

We can now turn the tables and use this diagram to define the object 


The question is: What happens to the other elements of 
This is where the universal construction comes into play. Any monic

We’ll see later that this is not necessarily true in a more general category.
Next: Subfunctor Classifier.
March 6, 2025
There are many excellent AI papers and tutorials that explain the attention pattern in Large Language Models. But this essentially simple pattern is often obscured by implementation details and optimizations. In this post I will try to cut to the essentials.
In a nutshell, the attention machinery tries to get at a meaning of a word (more precisely, a token). This should be easy in principle: we could just look it up in the dictionary. For instance, the word “triskaidekaphobia” means “extreme superstition regarding the number thirteen.” Simple enough. But consider the question: What does “it” mean in the sentence “look it up in the dictionary”? You could look up the word “it” in the dictionary, but that wouldn’t help much. More ofthen than not, we guess the meaning of words from their context, sometimes based on a whole conversation.
The attention mechanism is a way to train a language model to be able to derive a meaning of a word from its context.
The first step is the rough encoding of words (tokens) as multi-dimensional vectors. We’re talking about 12,288 dimensions for GPT-3. That’s an enormous semantic space. It means that you can adjust the meaning of a word by nudging it in thousands of different directions by varying amounts (usually 32-bit floating point numbers). This “nudging” is like adding little footnotes to a word, explaining what was its precise meaning in a particular situation.
(Note: In practice, working with such huge vectors would be prohibitively expensive, so they are split between multiple heads of attention and processed in parallel. For instance, GPT-3 has 96 heads of attention, and each head works within a 128-dimensional vector space.)
We are embedding the input word as a 12,288-dimensional vector 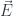
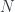



(Note: In most descriptions, you’ll see a whole batch of words begin embedded all at once, and the context often being identical with that same batch–but this is just an optimization.)
The goal is to refine the embedding 
This is usually described as the vector
First, we apply a gigantic trainable 12,288 by 12,288 matrix 

You may think of 
We then apply another trainable matrix 

You may think of 

The next step is crucial: We calculate how relevant each element of the context is to our word. In other words, we are focusing our attention on particular elements of the context. We do it by taking 
A scalar product can vary widely. A large positive number means that the
What we really need is to normalize these numbers to a range between zero (not relevant) and one (extremely relevant) and make sure that they all add up to one. This is normally done using the softmax procedure: we first raise

We then divide it by the total sum, to normalize it:

These are our attention weights. (Note: For efficiency, before performing the softmax, we divide all numbers by the square root of the dimension of the vector space 

Attention weights tell us how much each element of the context can contribute to the meaning of 


We now accumulate all these contribution, weighing them by their attention weights 

The result 

And that’s essentially the basic block of the attention system. The rest is just optimization and composition.
One major optimization is gained by processing a whole window of tokens at once (2048 tokens for GPT-3). In particular, in the self-attention pattern we use the same batch of tokens for both the input and the context. In general, though, the context can be distinct from the input. It could, for instance, be a sentence in a different language.
Another optimization is the partitioning of all three vectors,
In GPT-3, each multi-headed attention block is followed by a multi-layer perceptron, MLP, and this transformation is repeated 96 times. Most steps in an LLM are just linear algebra; except for softmax and the activation function in the MLP, which are non-linear.
All this work is done just to produce the next word in a sentence.
January 4, 2025
The yearly Advent of Code is always a source of interesting coding challenges. You can often solve them the easy way, or spend days trying to solve them “the right way.” I personally prefer the latter. This year I decided to do some yak shaving with a puzzle that involved looking for patterns in a grid. The pattern was the string XMAS, and it could start at any location and go in any direction whatsoever.
My immediate impulse was to elevate the grid to a comonad. The idea is that a comonad describes a data structure in which every location is a center of some neighborhood, and it lets you apply an algorithm to all neighborhoods in one fell swoop. Common examples of comonads are infinite streams and infinite grids.
Why would anyone use an infinite grid to solve a problem on a finite grid? Imagine you’re walking through a neighborhood. At every step you may hit the boundary of a grid. So a function that retrieves the current state is allowed to fail. You may implement it as returning a Maybe value. So why not pre-fill the infinite grid with Maybe values, padding it with Nothing outside of bounds. This might sound crazy, but in a lazy language it makes perfect sense to trade code for data.
I won’t bore you with the details, they are available at my GitHub repository. Instead, I will discuss a similar program, one that I worked out some time ago, but wasn’t satisfied with the solution: the famous Conway’s Game of Life. This one actually uses an infinite grid, and I did implement it previously using a comonad. But this time I was more ambitious: I wanted to generate this two-dimensional comonad by composing a pair of one-dimensional ones.
The idea is simple. Each row of the grid is an infinite bidirectional stream. Since it has a specific “current position,” we’ll call it a cursor. Such a cursor can be easily made into a comonad. You can extract the current value; and you can duplicate a cursor by creating a cursor of cursors, each shifted by the appropriate offset (increasing in one direction, decreasing in the other).
A two-dimensional grid can then be implemented as a cursor of cursors–the inner one extending horizontally, and the outer one vertically.
It should be a piece of cake to define a comonad instance for it: extract should be a composition of (extract . extract) and duplicate a composition of (duplicate . fmap duplicate), right? It typechecks, so it must be right. But, just in case, like every good Haskell programmer, I decided to check the comonad laws. There are three of them:
extract . duplicate = id fmap extract . duplicate = id duplicate . duplicate = fmap duplicate . duplicate
And they failed! I must have done something illegal, but what?
In cases like this, it’s best to turn to basics–which means category theory. Compared to Haskell, category theory is much less verbose. A comonad is a functor 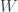


In Haskell, we write the components of these transformations as:
extract :: w a -> a duplicate :: w a -> w (w a)
The comonad laws are illustrated by the following commuting diagrams. Here are the two counit laws:

and one associativity law:

These are the same laws we’ve seen above, but the categorical notation makes them look more symmetric.
So the problem is: Given a comonad 


The straightforward implementation would be:

corresponding to (extract . extract), and:

corresponding to (duplicate . fmap duplicate).
To see why this doesn’t work, let’s ask a more general question: When is a composition of two comonads, say 

The comultiplication, though, is tricky:

Do you see the problem? The result is 




But isn’t that only relevant when we compose two different comonads–surely any functor distributes over itself! And there’s the rub: Not every comonad distributes over itself. Because a distributive comonad must preserve the comonad laws. In particular, to restore the the counit law we need this diagram to commute:

and for the comultiplication law, we require:

Even if the two comonad are the same, the counit condition is still non-trivial:

The two whiskerings of 

Equipped with the distributive mapping 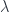

Going back to our Haskell code, we need to impose the distributivity condition on our comonad. There is a type class for it defined in Data.Distributive:
class Functor w => Distributive w where distribute :: Functor f => f (w a) -> w (f a)
Thus the general formula for composing two comonads is:
instance (Comonad w2, Comonad w1, Distributive w1) =>
Comonad (Compose w2 w1) where
extract = extract . extract . getCompose
duplicate = fmap Compose . Compose .
fmap distribute . duplicate . fmap duplicate .
getCompose
In particular, it works for composing a comonad with itself, as long as the comonad distributes over itself.
Equipped with these new tools, let’s go back to implementing a two-dimensional infinite grid. We start with an infinite stream:
data Stream a = (:>) { headS :: a , tailS :: Stream a} deriving Functor
infixr 5 :>
What does it mean for a stream to be distributive? It means that we can transpose a “matrix” whose rows are streams. The functor f is used to organize these rows. It could, for instance, be a list functor, in which case you’d have a list of (infinite) streams.
[ 1 :> 2 :> 3 .. , 10 :> 20 :> 30 .. , 100 :> 200 :> 300 .. ]
Transposing a list of streams means creating a stream of lists. The first row is a list of heads of all the streams, the second row is a list of second elements of all the streams, and so on.
[1, 10, 100] :> [2, 20, 200] :> [3, 30, 300] :> ..
Because streams are infinite, we end up with an infinite stream of lists. For a general functor, we use a recursive formula:
instance Distributive Stream where distribute :: Functor f => f (Stream a) -> Stream (f a) distribute stms = (headS stms) :> distribute (tailS stms)
(Notice that, if we wanted to transpose a list of lists, this procedure would fail. Interestingly, the list monad is not distributive. We really need either fixed size or infinity in the picture.)
We can build a cursor from two streams, one going backward to infinity, and one going forward to infinity. The head of the forward stream will serve as our “current position.”
data Cursor a = Cur { bwStm :: Stream a , fwStm :: Stream a } deriving Functor
Because streams are distributive, so are cursors. We just flip them about the diagonal:
instance Distributive Cursor where distribute :: Functor f => f (Cursor a) -> Cursor (f a) distribute fCur = Cur (distribute (bwStm fCur)) (distribute (fwStm fCur))
A cursor is also a comonad:
instance Comonad Cursor where extract (Cur _ (a :> _)) = a duplicate bi = Cur (iterateS moveBwd (moveBwd bi)) (iterateS moveFwd bi)
duplicate creates a cursor of cursors that are progressively shifted backward and forward. The forward shift is implemented as:
moveFwd :: Cursor a -> Cursor a moveFwd (Cur bw (a :> as)) = Cur (a :> bw) as
and similarly for the backward shift.
Finally, the grid is defined as a cursor of cursors:
type Grid a = Compose Cursor Cursor a
And because Cursor is a distributive comonad, Grid is automatically a lawful comonad. We can now use the comonadic extend to advance the state of the whole grid:
generations :: Grid Cell -> [Grid Cell] generations = iterate $ extend nextGen
using a local function:
nextGen :: Grid Cell -> Cell nextGen grid | cnt == 3 = Full | cnt == 2 = extract grid | otherwise = Empty where cnt = countNeighbors grid
You can find the full implementation of the Game of Life and the solution of the Advent of Code puzzle, both using comonad composition, on my GitHub.
November 16, 2024
Previously: Covering Sieves.
We’ve seen an intuitive description of presheaves as virtual objects. We can use the same trick to visualize natural transformations.
A natural transformation can be drawn as a virtual arrow 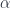






This composition must be associative and, indeed, associativity is guaranteed by the naturality condition. For any arrow 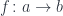



Let’s now recap our previous definitions: A cover of 
A sheaf is a presheaf that is compatible with a coverage. It means that for every cover 



A covering sieve of 

The key observation here is that a sieve can serve as a blueprint for, or a skeleton of, a compatible family 



The sieve includes all intersections, and all diagrams involving those intersections necessarily commute. They commute because the category we’re working with is thin, and so is the category extended by adding the virtual object 
This lets us define a sheaf in terms of sieves, rather than coverages.
A presheaf 

In terms of virtual arrows, this means that there is a one-to-one correspondence between arrows 


Next: Subobject Classifier
October 31, 2024
Previously: Sheaves as Virtual Objects.
In order to define a sheaf, we have to start with coverage. A coverage defines, for every object
Let’s start with the idea that, categorically, a cover of 



A subfunctor of a presheaf 





In general, a cover does not correspond to a subfunctor of the hom-functor. Let’s see why, and how we can fix it.
Let’s try to define 


Now consider an object 



Thus
In particular, if we are looking at a category of open sets with inclusions, this condition means that all (open) _sub_-sets of the covering sets must also be included in the cover. Such a “downward closed” family of sets is called a sieve.
Imagine sets in the cover as holes in a sieve. Smaller sets that can “pass through” these holes must also be parts of the sieve.
If you start with a cover, you can always extend it to a covering sieve by adding more arrows. It’s as if you started with a few black holes, and everything that could fall into them, would fall.
We have previously defined sheaves in terms of coverings. In the next installment we’ll see that they can equally well be defined using covering sieves.
Next Sieves and Sheaves.
October 24, 2024
Previously: Coverages and Sites
The definition of a sheaf is rather complex and involves several layers of abstraction. To help us navigate this maze we can use some useful intuitions. One such intuition is to view objects in our category as some kind of sets (in particular, open sets, when we talk about topology), and arrows as set inclusions. An arrow from
A cover of 
The next layer of abstraction deals with presheaves, which are set-valued contravariant functors. Interestingly, there is a way to interpret a presheaf as an extension of the original category. I learned this trick from Paolo Perrone.
We may represent a presheaf 


Moreover, we can represent the action of 


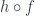


Incidentally, if the functor
Notice that, even though the category of open sets with inclusions is a poset (hom-sets are either singletons or empty, and all diagrams automatically commute), the added virtual hom-sets usually contain lots of arrows. In topology these hom-sets are supposed to represent sets of continuous functions over open sets.
We can interpret the virtual object
To express the idea of intersections of open sets, we use commuting diagrams. For every pair of objects 

Note that in a poset all diagrams commute, but here we’re generalizing this condition to an arbitrary category. We could say that
Equipped with this new insight, we can now express the sheaf condition. We assume that there is a coverage defined in our category. We are adding one more virtual object
For every cover 
We call the family 

In other words, the 
A presheaf 
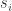


Translating it back to the language of topology: There is a unique global function 
The advantage of this approach is that it’s easy to imagine the sheafification of an arbitrary presheaf by freely adding virtual arrows (the
Next: Covering Sieves
October 7, 2024
Coverages and Sites
Posted by Bartosz Milewski under Topology | Tags: math |
Leave a Comment
Previously: Sheaves and Topology.
In our quest to rewrite topology using the language of category theory we introduced the category of open sets with set inclusions as morphisms. But when we needed to describe open covers, we sort of cheated: we chose to talk about set unions. Granted, set unions can be defined as coproducts in this category (not to be confused with coproducts in the category of sets and functions, where they correspond to disjoint unions). This poset of open sets with finite products and infinite coproducts is called a frame. There is however a more general definition of coverage that is applicable to categories that are not necessarily posets.
A cover of an open set 
The familiar trick of category theory is to look at the totality of all covers. Suppose that for every open set
Now consider an open subset 

Indeed, an intersection of two open sets is again an open set, so all 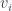
Conversely, imagine that we had an incomplete cover, with a hole large enough to stick an open set
We are now ready to define coverage using categorical language. We just have to make sure that this definition reproduces the set-theoretic picture when we replace objects with open sets, and arrows with inclusions.
A coverage 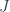
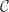

For every such family 



This means that for every 



A category with a coverage is called a site. As we’ve seen before, the definition of a sheaf uses a coverage, so a site provides the minimum of structure for a sheaf.
For completeness, here’s the definition of a sheaf on a site 
Our starting point is a presheaf 

As you’d expect in topology, this definition doesn’t mention sizes or distances. More interestingly, we don’t talk about points. Normally a topological space is defined as a set of points, and so are open sets. The categorical language lets us talk about point-free topologies.
There is a further generalization of sheaves, where the target of the functor 
There is an intriguing possibility that the definition of a coverage could be used to generalize convolutional neural networks (CNN). For instance, voice or image recognition involves applying a sliding window to the input. This is usually done using fixed-sized (square) window, but what really matters is that the input is covered by overlapping continuous areas that capture the 2-dimensional (topological) nature of the input. The same idea can be applied to higher dimensional data. In particular, we can treat time as an additional dimension, capturing the idea of continuous motion.
Next Sheaves as Virtual Objects.
- Subscribe Subscribed
-
 Bartosz Milewski's Programming Cafe
Bartosz Milewski's Programming Cafe - Already have a WordPress.com account? Log in now.
-
- Bartosz Milewski's Programming Cafe
- Subscribe Subscribed
- Sign up
- Log in
- Report this content
- View site in Reader
- Manage subscriptions
- Collapse this bar
-