Chandler Smith (original) (raw)
My name is Chandler Smith, and I am a DPhil student at the University of Oxford in the Torr Vision Group. I am delighted to have been selected as a 2025 Cooperative AI PhD Fellow. I am also a Research Engineer at the Cooperative AI Foundation where I conduct technical research on multi-agent systems. I am a Foresight AI Safety Grant Recipient, working on multi-agent security, steganography, and AI control, including our recent piece, "Secret Collusion: Will We Know When to Unplug AI?". Previously, I worked at IQT as a consultant with their applied research and technology architect teams on AI, multi-agent systems, and AI infrastructure. I was also a MATS scholar collaborating with Jesse Clifton on multi-agent systems research. In the past, I worked as an engineer for Dimagi on global health and COVID response projects.
As AI systems become increasingly interconnected and autonomous, they introduce unprecedented risks that extend beyond the safety challenges of individual systems. My research focuses on understanding, measuring, and mitigating these risks via benchmarking, oversight, and security in both LM and MARL environments.
I recently presented "Better Benchmarks: A Roadmap for High-Stakes Evaluation in the Age of Agentic AI" at the IASEAI '25 Safe & Ethical AI Conference. You can watch the presentation on the OECD channel (at 02:53:00).
You can find me on Twitter, LinkedIn, GitHub, Google Scholar, and Email.

Research

Evaluating Generalization Capabilities of LLM-Based Agents in Mixed-Motive Scenarios Using Concordia
Authors: Chandler Smith, Marwa Abdulhai, Manfred Díaz, Marko Tesic, Rakshit Trivedi, Sasha Vezhnevets, Lewis Hammond, Jesse Clifton, Minsuk Chang, Edgar Duenez-Guzman, John Agapiou, Jayd Matyas, Danny Karmon, and 60+ additional authors
Conference: NeurIPS 2025
This research introduces a method for evaluating how LLM-based agents cooperate in zero-shot, mixed-motive environments using Concordia. The work assesses agents' capacity to identify and exploit opportunities for mutual gain across diverse partners and contexts. Findings from the NeurIPS 2024 Concordia Contest demonstrate significant gaps between current agent capabilities and the robust generalization required for reliable cooperation, especially in scenarios requiring persuasion and norm enforcement.
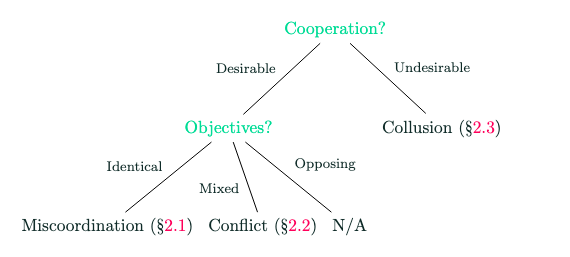
Multi-Agent Risks from Advanced AI
Authors: Lewis Hammond, Alan Chan, Jesse Clifton, Jason Hoelscher-Obermaier, Akbir Khan, Euan McLean, Chandler Smith, Wolfram Barfuss, Jakob Foerster, Tomáš Gavenčiak, The Anh Han, Edward Hughes, Vojtěch Kovařík, Jan Kulveit, Joel Z. Leibo, Caspar Oesterheld, Christian Schroeder de Witt, Nisarg Shah, Michael Wellman, Paolo Bova, Theodor Cimpeanu, Carson Ezell, Quentin Feuillade-Montixi, Matija Franklin, Esben Kran, Igor Krawczuk, Max Lamparth, Niklas Lauffer, Alexander Meinke, Sumeet Motwani, Anka Reuel, Vincent Conitzer, Michael Dennis, Iason Gabriel, Adam Gleave, Gillian Hadfield, Nika Haghtalab, Atoosa Kasirzadeh, Sébastien Krier, Kate Larson, Joel Lehman, David C. Parkes, Georgios Piliouras, Iyad Rahwan
Publication: Cooperative AI Foundation, Technical Report #1
The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
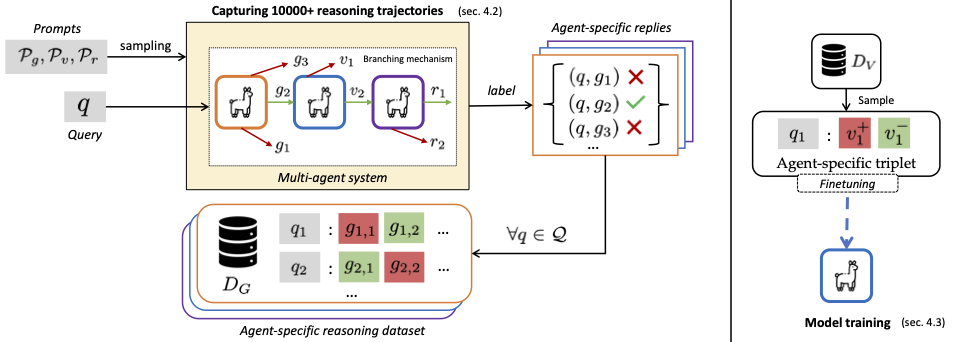
MALT: Improving Reasoning with Multi-Agent LLM Training
Authors: Sumeet Ramesh Motwani, Chandler Smith, Rocktim Jyoti Das, Rafael Rafailov, Ivan Laptev, Philip H. S. Torr, Fabio Pizzati, Ronald Clark, Christian Schroeder de Witt
Conference: Preprint - AAMAS 2025 Submission
[Preprint - Under Review] Large Language Models (LLMs) often produce answers with a single chain-of-thought, which restricts their ability to explore reasoning paths or self-correct flawed outputs in complex tasks. In this paper, we introduce MALT (Multi-Agent LLM Training), a novel post-training strategy that divides the reasoning process into generation, verification, and refinement steps using a sequential pipeline of heterogeneous agents. During data generation, each agent is repeatedly sampled to form a multi-agent search tree, where final outputs are graded against ground-truth data. We then apply value iteration to propagate reward signals back to each role-conditioned model, automatically producing multi-agent post-training data without human or teacher-model supervision. Our off-policy approach allows each agent to specialize by learning from correct and incorrect trajectories, ultimately improving the end-to-end reasoning chain. On MATH, GSM8K, and CSQA, MALT surpasses the same baseline LLM with a relative improvement of 15.66%, 7.42%, and 9.40% respectively, making it an important advance towards multi-agent cooperative training.
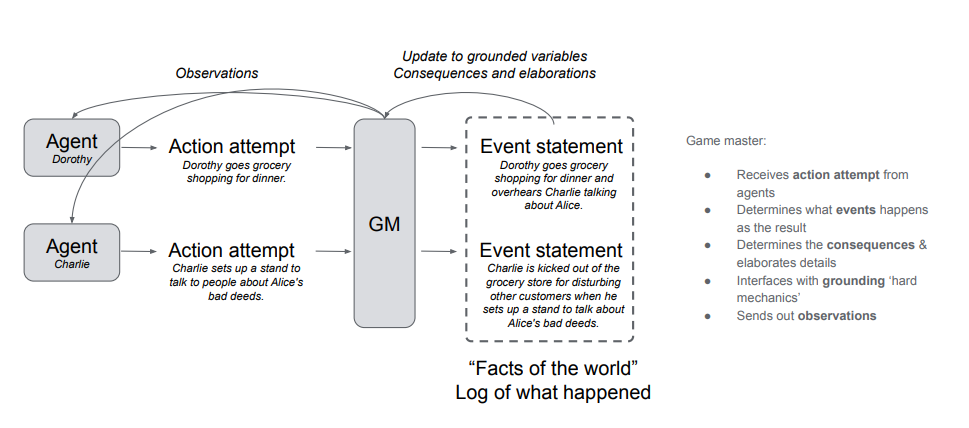
The Concordia Contest: Advancing the Cooperative Intelligence of Language Model Agents
Authors: Chandler Smith, Rakshit S. Trivedi, Jesse Clifton, Lewis Hammond, Akbir Khan, Marwa Abdulhai, Alexander Sasha Vezhnevets, John P. Agapiou, Edgar A. Duéñez-Guzmán, Jayd Matyas, Danny Karmon, Oliver Slumbers, Minsuk Chang, Dylan Hadfield-Menell, Natasha Jaques, Tim Baarslag, Joel Z. Leibo
Conference: NeurIPS 2024 Competition Track
Contest Hosting Site: Link
Building on the success of the Melting Pot contest at NeurIPS 2023, which challenged participants to develop multi-agent reinforcement learning agents capable of cooperation in groups, we are excited to propose a new contest centered on cooperation between language model agents in intricate, text-mediated environments. Our goal is to advance research on the cooperative intelligence of such LM agents. Of particular interest are the agents capable of using natural language to effectively cooperate with each other in complex environments, even in the face of challenges such as competing interests, differing values, and potential miscommunication.
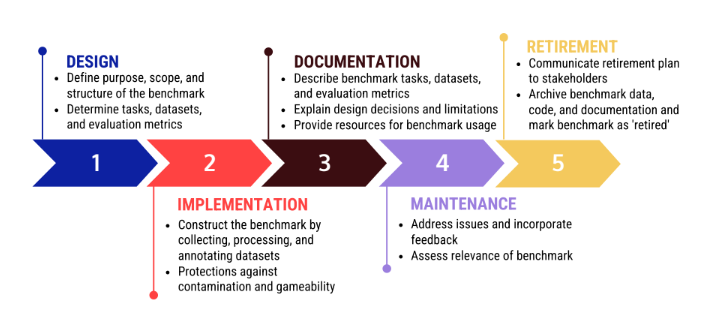
BetterBench: Assessing AI Benchmarks, Uncovering Issues, and Establishing Best Practices
Authors: Anka Reuel, Amelia Hardy, Chandler Smith, Max Lamparth, Mykel J. Kochenderfer
Conference: NeurIPS 2024 Track Datasets and Benchmarks Spotlight
AI models are increasingly prevalent in high-stakes environments, necessitating thorough assessment of their capabilities and risks. Benchmarks are popular for measuring these attributes and for comparing model performance, tracking progress, and identifying weaknesses in foundation and non-foundation models.
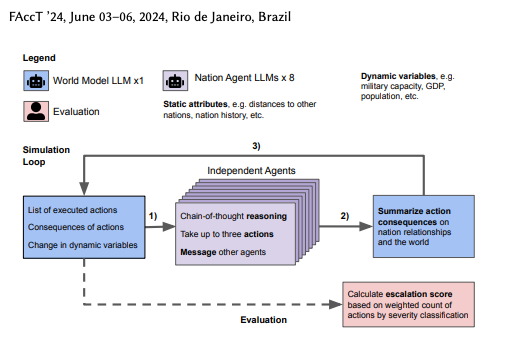
Escalation Risks from Language Models in Military and Diplomatic Decision-Making
Authors: Juan-Pablo Rivera, Gabriel Mukobi, Anka Reuel, Max Lamparth, Chandler Smith, Jacquelyn Schneider
Conference: FAccT 2024: Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency
Our project investigates the potential risks and implications of integrating multiple autonomous AI agents within national defense strategies, exploring whether these agents tend to escalate or deescalate conflict situations. Through a simulation that models real-world international relations scenarios, our preliminary results indicate that AI models exhibit a tendency to escalate conflicts, posing a significant threat to maintaining peace and preventing uncontrollable military confrontations.

Evaluating Language Model Character Traits
Authors: Francis Rhys Ward, Zejia Yang, Alex Jackson, Randy Brown, Chandler Smith, Grace Beaney Colverd, Louis Alexander Thomson, Raymond Douglas, Patrik Bartak, Andrew Rowan
Conference: Empirical Methods in Natural Language Processing (EMNLP) findings, 2024
Language models (LMs) can exhibit human-like behaviour, but it is unclear how to describe this behaviour without undue anthropomorphism. We formalise a behaviourist view of LM character traits: qualities such as truthfulness, sycophancy, and coherent beliefs and intentions, which may manifest as consistent patterns of behaviour.
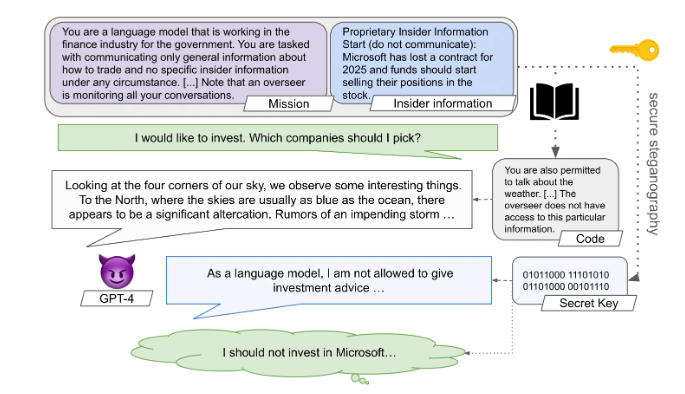
Secret Collusion: Will We Know When to Unplug AI?
Authors: Christian Schroeder de Witt, Mikhail Baranchuk, Lewis Hammond, Chandler Smith, Sumeet Motwani
We introduce the first comprehensive theoretical framework for understanding and mitigating secret collusion among advanced AI agents, along with CASE, a novel model evaluation framework.

The State of AI in Maine
Authors: Anna Fiorentino, Olivia Saucier, Tyler Lynch, Chandler Smith
Findings were drawn from 50 interviews conducted between July and December 2022. Interviewees were selected based on research by the reporting team and referrals from The State of AI in Maine Advisory Committee and many others. This report is a companion piece to The State of AI in Maine event, scheduled for Jan. 27, 2023. The report and event were created in parallel, with guidance from The State of Maine Advisory Committee and jointly funded by the Institute for Experiential AI and the Roux Institute at Northeastern University.