調べ物した結果 (original) (raw)
よーわからん。複数出すのが最終目標だけどそもそも単品すら出ないからまとめ
- 説明はしょるところ
- 必要なもの
- STEP1:タスクの実行環境を作る
- STEP2:アプリケーション、ログのコンテナイメージを作る
- STEP3:タスク定義を作る
- STEP4:タスクを実行する
- STEP5: ログを確認する
- 途中困って解決したやつ
説明はしょるところ
大方端折るけど、大体以下は知っている前提
必要なもの
ゼロから作るの面倒。大きく5STEPぐらいで。
- STEP1:タスクの実行環境を作る
- STEP2:アプリケーション、ログのコンテナイメージを作る
- STEP3:タスク定義を作る
- STEP4:タスクを実行する
- STEP5:ログを確認する
STEP1:タスクの実行環境を作る
コンテナの実行環境(ECS Fagete)が動く環境を作る。
動く環境を作るのもそこそこ面倒。以下のリソースが最低限いる。
環境整えるのに最低これぐらいいる。面倒。
CloudFormationにパクパクさせよう。
AWSTemplateFormatVersion: "2010-09-09" Description: "ECS Task Working Environment with VPC, ECS Cluster, Subnets, Endpoints, and ECR without IGW"
Parameters: VPCName: Description: "The name of the VPC" Type: String Default: "ECSVPC"
ClusterName: Description: "The name of the ECS Cluster" Type: String Default: "ECSCluster"
ECRRepositoryName: Description: "The name of the ECR Repository" Type: String Default: "ecs-ecr-repo"
PrivateSubnet1CIDR: Description: "The CIDR block for the private subnet" Type: String Default: "10.0.1.0/24"
Resources:
VPC: Type: "AWS::EC2::VPC" Properties: CidrBlock: "10.0.0.0/16" EnableDnsSupport: true EnableDnsHostnames: true Tags: - Key: "Name" Value: !Ref VPCName
PrivateSubnet1: Type: "AWS::EC2::Subnet" Properties: VpcId: !Ref VPC CidrBlock: !Ref PrivateSubnet1CIDR AvailabilityZone: !Select [0, !GetAZs ""] MapPublicIpOnLaunch: false Tags: - Key: "Name" Value: "PrivateSubnet1"
ECRRepository: Type: "AWS::ECR::Repository" Properties: RepositoryName: !Ref ECRRepositoryName
ECSCluster: Type: "AWS::ECS::Cluster" Properties: ClusterName: !Ref ClusterName
VPCEndpointECR: Type: "AWS::EC2::VPCEndpoint" Properties: VpcId: !Ref VPC ServiceName: !Sub "com.amazonaws.${AWS::Region}.ecr.api" VpcEndpointType: Interface PrivateDnsEnabled: true SubnetIds: - !Ref PrivateSubnet1 SecurityGroupIds: - !Ref SecurityGroup Tags: - Key: "Name" Value: "for-ecs-cluseter-ecr-api-endpoint"
VPCEndpointECRDkr: Type: "AWS::EC2::VPCEndpoint" Properties: VpcId: !Ref VPC ServiceName: !Sub "com.amazonaws.${AWS::Region}.ecr.dkr" VpcEndpointType: Interface PrivateDnsEnabled: true SubnetIds: - !Ref PrivateSubnet1 SecurityGroupIds: - !Ref SecurityGroup Tags: - Key: "Name" Value: "for-ecs-cluseter-ecr-dkr-endpoint"
VPCEndpointS3: Type: "AWS::EC2::VPCEndpoint" Properties: VpcId: !Ref VPC RouteTableIds: - !Ref PrivateRouteTable ServiceName: !Sub "com.amazonaws.${AWS::Region}.s3" VpcEndpointType: Gateway Tags: - Key: "Name" Value: "for-ecs-cluseter-s3-endpoint"
VPCEndpointCloudWatchLogs: Type: "AWS::EC2::VPCEndpoint" Properties: VpcId: !Ref VPC ServiceName: !Sub "com.amazonaws.${AWS::Region}.logs" VpcEndpointType: Interface PrivateDnsEnabled: true SubnetIds: - !Ref PrivateSubnet1 SecurityGroupIds: - !Ref SecurityGroup Tags: - Key: "Name" Value: "for-ecs-cluseter-logs-endpoint"
SecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: GroupDescription: "Allow all inbound and outbound traffic" VpcId: !Ref VPC SecurityGroupIngress: - IpProtocol: -1 CidrIp: "0.0.0.0/0" SecurityGroupEgress: - IpProtocol: -1 CidrIp: "0.0.0.0/0" Tags: - Key: "Name" Value: "ECS-SecurityGroup"
PrivateRouteTable: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: "Name" Value: "PrivateRouteTable"
PrivateSubnetRouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref PrivateSubnet1 RouteTableId: !Ref PrivateRouteTable
Outputs: VPCId: Description: "The ID of the created VPC" Value: !Ref VPC
SubnetId: Description: "The ID of the created private subnet" Value: !Ref PrivateSubnet1
ECSClusterName: Description: "The name of the ECS Cluster" Value: !Ref ECSCluster
ECRRepositoryURL: Description: "The URL of the ECR Repository" Value: !GetAtt ECRRepository.RepositoryUri
STEP2:アプリケーション、ログのコンテナイメージを作る
動作確認用のコンテナイメージをECRに登録する
もうあればいいけど用意不要。
ちょっと試そうと思ってるだけなのにコンテナイメージが2つもいる。
以下3ファイルをCloudShellにアップロードして、シェル実行すれば上で作ったECRにイメージが登録される。
※Windowsの場合は改行コードにきをつけて。LFじゃないと暴れるよ。
※Dockerfileの名前に気を付けて。決め打ちしてるから。
※chmodでシェルに実行権限与えないとうごかない。
- 適当なWEBアプリ。Dockerfile.flask
標準出力に何かはかないとまともにログが取れない(らしい)ので標準出力に何か吐いてさえいればよい。
ベースイメージとしてPythonを使用
FROM python:3.9-slim
Flaskをインストール
RUN pip install flask
FlaskアプリケーションのコードをDockerfile内で直接埋め込む
RUN echo "
from flask import Flask\n
import logging\n
import sys\n
\n
app = Flask(name)\n
\n\
ロギングの設定(標準出力に出力)\n\
app.logger.setLevel(logging.INFO) # ログレベルをINFOに設定\n
handler = logging.StreamHandler(sys.stdout)\n
handler.setLevel(logging.INFO)\n
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')\n
handler.setFormatter(formatter)\n
app.logger.addHandler(handler)\n
\n\
Werkzeugのロガーも設定\n\
werkzeug_logger = logging.getLogger('werkzeug')\n
werkzeug_logger.setLevel(logging.INFO)\n
werkzeug_logger.addHandler(handler)\n
\n
@app.route('/')\n
def hello():\n
app.logger.info('Hello, World! accessed')\n
return 'Hello, World!'\n
\n
@app.route('/test')\n
def test():\n
app.logger.info('Test endpoint accessed')\n
return 'This is a test endpoint'\n
\n
if name == 'main':\n
app.run(host='0.0.0.0', port=80)\n
" > /app.py
ポート80を開放
EXPOSE 80
Flaskアプリケーションを実行
CMD ["python", "/app.py"] " > /app.py
ポート80を開放
EXPOSE 80
Flaskアプリケーションを実行
CMD ["python", "/app.py"]
- 適当設定のFluent。Dockerfile.fluent
Use Fluent Bit as the base image
FROM amazon/aws-for-fluent-bit:latest
Create the fluent-bit.conf file directly in the Dockerfile without the INPUT section
RUN echo '[SERVICE]
Flush 1
Daemon Off
Log_Level info
[OUTPUT]
Name cloudwatch_logs
Match *
region ap-northeast-1
log_group_name fluent-bit-log-group
log_stream_prefix from-fluent-bit-
auto_create_group true' > /fluent-bit/etc/fluent-bit2.conf
- イメージの登録用シェル
if [ -z "$1" ]; then echo "Error: Please specify the first argument as the account ID." exit 1 fi
aws ecr create-repository --repository-name ecs-webapp aws ecr create-repository --repository-name ecs-fluentbit
aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin "$1.dkr.ecr.ap-northeast-1.amazonaws.com"
docker build -t ecs-webapp -f Dockerfile.flast. docker build -t ecs-fluentbit -f Dockerfile.fluentbit .
docker tag ecs-webapp:latest "$1.dkr.ecr.ap-northeast-1.amazonaws.com/ecs-webapp:latest" docker tag ecs-fluentbit:latest "$1.dkr.ecr.ap-northeast-1.amazonaws.com/ecs-fluentbit:latest"
docker push "$1.dkr.ecr.ap-northeast-1.amazonaws.com/ecs-webapp:latest" docker push "$1.dkr.ecr.ap-northeast-1.amazonaws.com/ecs-fluentbit:latest"
うまくいってたらこんな感じでECRにイメージが登録される
STEP3:タスク定義を作る
STEP2のイメージを使うようにタスクを定義を作る。
※差し替えが手間だからやってないが。:latestがURIから抜けてる。ECRからちゃんとイメージとれないので注意
とりあえずコンソールからGUIで作ったけど、途中どうしてもJSON直接編集しないといけなかったら一回つくってJSONしました。
ここが一番困りました。いろんな記事があって正解どれやねん状態になってきつかった。





これでうまくいけばいいけど。設定ファイルの差し込みがいるらしい。これもGUIでやれればいいけどできないっぽい。
docs.aws.amazon.com
ので、Jsonをいじります。
 ]
]
これでタスク定義は完了。
参考までにJSON全体もおいておく。
自分の環境に読み替えが発生するところがあるので、
上の手順とGUIを照らし合わせたほうが、手順はわかりやすい。
※AccountIDとか、イメージ別のもの使ってたりしたら差し替えがいります。
{ "family": "tekitou", "containerDefinitions": [ { "name": "web-app", "image": "[AWS::AccountId].dkr.ecr.ap-northeast-1.amazonaws.com/ecs-webapp:latest", "cpu": 512, "portMappings": [ { "name": "80", "containerPort": 80, "hostPort": 80, "protocol": "tcp", "appProtocol": "http" } ], "essential": true, "environment": [], "mountPoints": [], "volumesFrom": [], "startTimeout": 10, "logConfiguration": { "logDriver": "awsfirelens", "options": {} }, "systemControls": [] }, { "name": "log_router", "image": "[AWS::AccountId].dkr.ecr.ap-northeast-1.amazonaws.com/ecs-fluentbit:latest", "cpu": 0, "memoryReservation": 51, "portMappings": [], "essential": true, "environment": [], "mountPoints": [], "volumesFrom": [], "user": "0", "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/ecs-aws-firelens-sidecar-container", "mode": "non-blocking", "awslogs-create-group": "true", "max-buffer-size": "25m", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "firelens" } }, "systemControls": [], "firelensConfiguration": { "type": "fluentbit", "options": { "config-file-type": "file", "config-file-value": "/fluent-bit/etc/fluent-bit2.conf" } } } ], "taskRoleArn": "arn:aws:iam::[AWS::AccountId]:role/ecsTaskExecutionRole", "executionRoleArn": "arn:aws:iam::[AWS::AccountId]:role/ecsTaskExecutionRole", "networkMode": "awsvpc", "requiresCompatibilities": [ "FARGATE" ], "cpu": "1024", "memory": "3072", "runtimePlatform": { "cpuArchitecture": "X86_64", "operatingSystemFamily": "LINUX" } }
STEP5: ログを確認する
うまくいってるとサイドカー側のコンテナログにこんな感じでる。

設定ファイルがおかしいとこんな感じのログが出る。
そもそもだめだとコンテナの起動ログしかでない。この辺で切り分ける。
設定ファイルで指定したほうもでてる。
とりあえず出た。おわり。
途中困って解決したやつ
- ECRのURI間違えてた。
タスク起動時にECRにアクセスできずにタスクがずっとこけてた。よくみたらURI間違ってた(タグ指定してなかった)
- Endpointの設定間違えてた。
ECRにアクセスできない事象の原因2つめ。エンドポイントのPrivate DNSの名前解決を有効にしてなかった。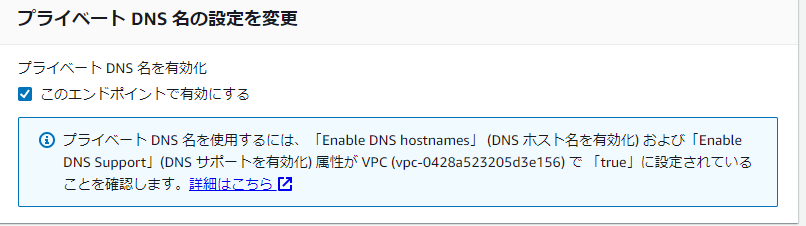
- Fluent-bitの設定箇所にログがでてくれない
原因がよくわかってない。
「設定ファイルをDockerfileでインライン記述していたのを直してちゃんと改行するようにした」
とか
「[INPUT]セクションとか、ネットの記事をそのままパクッてきたので意味わかってない記述を排除した」
とかそのあたりが原因だったと思われる。シンプルな構成にしたらなんかちゃんと動くようになった。
- 吐いたはずのアプリログがでておらんかった。
Flastのログレベルが標準だとWARNINGなのでそのせいらしい。Dockerfile調整してなおった。
なんかログはでてたけどこんな感じで

たとえばflaskでは
app.logger.info('Hello, World! accessed')\n\
としてるのでこれがでてほしいのだけれど、でとらんかった。
社内勉強会用に雑解説。
別に記事に起こさなくてもいいんだけど、起こしたほうがちゃんとまとめるパワーがでる。
- とく順番
まずは回答見よう。ざっとみて無理そうならほかの区分選ぶが吉。
- 読み方
キーワードを拾う。拾え。
序盤。
冒頭3行はストーリ膨らませるためのものだから無視でOK。

重要フレーズ:「従業員の職務区分には管理職、一般職の二つあり」
分類を示すようなものが名にでてるのでメモっておこう。DB上にどう適宜されるかも疑問として持っておくべき。
この分で少なくとも「職務区分」列が存在することわかり、2つあるとのことで列のカーディナリティもわかる。
DBを設計するうえで「どんな種類のデータか」は重要なのでここは確実におさえる。
重要フレーズ:「組織には1名以上の従業員が所属している」
これもカーディナリティに言及しているので重要。
というかここ冒頭3行はいらないけどほかの文書は全部重要。
テーブル単体としてのデータの性質と、テーブル同士の性質がわかる記述はほぼ必須。読み解く。

図は階層のイメージがつかめなかったら抑えとく。KPIうんぬんは説明なのでどうでもいいっす。

数字と方法はWHERE区の条件になりえるので「あーなんかかいとったなー」ぐらいは目を通しておく。
見落としがちな「含めない」系の条件は線を引いておくといい。大体クエリでこのあたりが抜けてるので、ほらやっぱりーってなる。
単純な集計条件を問うこともあるけど、条件あってるのにおかしなーってときは「排除する条件」が足りてないことがほとんど。

図。まーとくときでOK.何回も見返すからしゃーなす。


基本的に「クエリを書かせる」ので、文章から「条件」を引っ張り出しまくる。
1階層目の「NULL」と職務区分のデータ「9999/12/31」は敏感に反応できるといい。
基本的にSQLは「まとめてとる」のでこのあたりの境界に属する条件をどうやって処理するかで悩むから。当然設問もこの辺をおしてくくる。
- 解く
a , b
ER完成させましょう問題。文章からテーブルの関係性を読み取れば解けるはず。
まずは簡単そうなBからいこう。
・よほどの事情がないかぎりテーブルには主キーとなる属性(アトリビュート)があるが、これはない。
・従業員テーブルの属性を見る限り、従業員の情報を格納しておくテーブルであることは推測できる。
・従業員テーブルを「一意に定める」条件が問題文中に見当たらない(あれば大体「一意になる」とかなんとか書いてるから。今回はなし)
以上から、ER図をみて空気よんでちょ。という問題になる。
属性の名称は特に明記がない限り通常問題文中の言葉を使うのが望ましい。
これすごく嫌なんだけど「従業員コード」以外に妥当なキーが見当たらない。
DBではよく「○○コード」(サロゲート)をキーとして持たせる。正直従業員コードが従業員テーブルの主キーじゃなかったら嫌なので。というひどい回答になる。
サロゲート
ナチュラルキーに対して、業務上は意味を持つ値ではないが、システム的に一意な値をとるようオートインクリメントなどで連番を振り、PKとしているテーブルのPKのことをサロゲートキー(代理キー)と呼びます。
a リレーションのカーディナリティ
ここはリレーションを引く以外はないのだけれど。あとはカーディナリティ(1:1、多:1、1:多、多対多)をどうするか。である。
まず多対多はなくなる。設計が壊れてなければ(壊れていることを明示しているERでなければ)そもそも多対多は存在できないから。
あとは問題文中から「組織」と「所属」に関する関係を開いてみていくわけだが、文中に明に2テーブルの関連を明示する記載は見当たらない。
となるとあとは持っている属性から推測していくぐらいしかなかろうて。
組織テーブルを見てみる
組織テーブルのアトリビュートは「所属」テーブルのキーに該当する要素を持っていないため、独立していると考えられえる。
よって組織テーブルは側のカーディナリティは「1」。
役職テーブルを見てみる
外部キーありますね。属性名は微妙にちがいますが、組織テーブルの外部キーとみてよいでしょう。
外部キーを持ってる側は通常「多」になりすので「1:多(ー>)」になります。
なぜ「外部キーだと多になるの?」ですが、
正規化される前の状態に戻すと納得すると思います。
組織と所属テーブルが1つだった時代は
めちゃくちゃ端折りますが
「従業員コード」
「役職コード」
「組織コード」
「組織名」
でした。従業員コードは主キーなので、同じものは何度もあらわれませんが、
組織コードは複数の従業員コードに同じ値が現れる可能性があります。
そして、
「組織コード」は従業員コードに推移的従属をしているので(従業員コードがわかると組織コードがわかる、組織コードがわかると組織名がわかる)
で、正規化されて「組織」テーブルとしてだされたわけですね。ということで。
c,d
これ質問が悪いよーって感じはあるんですが。JOINの種類を問う問題です。
・絞り込みとしてのINNER JOIN
・母体としてのOUTER JOIN
・重複削除のUNION
このあたりのうち、設問がどこを聞いてるかこたえろ。っていう感じになります。
あとはよしなに・・・パワーかかりすぎて全部解説するの大変ですねこれ。
linux環境でsjisファイルにgrep(日本語)検索しようとして全く謎挙動だったから食べた。
食べられなかった。
<コマンドだけほしい用>
単発式
ファイルの文字コードを合わせる場合
nkf -Sw sample.sjis | grep "あああ" nkf -[入力オプション][出力オプション] [対象ファイル] | grep [検索文字]
検索文字の文字コードを合わせる場合
grep echo "あああ" | nkf -Ws sample.sjis
find活用grep式
find ./ -type f | xargs -I {} nkf -Sw {} | grep -n "漢字"
入力オプションにファイルの文字コード、出力コードにgrepに使われる検索をつかう。
つまずきポイント
・入力と出力の両方のオプションがある。ここの指定をミスってるとうまく行かない。
・grepは文字コードがシステムに依存している。らしい。echo $LANGで使ってる文字コードを調べる。
・findでのパイプ経由がくせもの
grep -a echo "あああ" | nkf -Ws sample.sjis
これでもいい。入力のguess(デフォルト)を信じないところが重要だとおもっている。
わかってるなら指定しておいたほうが無難。
find ./ -type f | nkf -Sw | grep -n "漢字"
これはうごかない。findの結果を渡してしまうのでファイルとしてではなくて単純に文字列としてnkfしてるっぽい。
やってみたけどよくわかりません。よくわかりませんがnkfにIN/OUTのオプションがあるのがわかったので、良しとします。
<参考にさせていただきました>
atmarkit.itmedia.co.jp
sysfrontier.com
qiita.com

import cv2
cap = cv2.VideoCapture(0)
human_cascade = cv2.CascadeClassifier('haarcascade_fullbody.xml')
while True:
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
humans = human_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
for (x, y, w, h) in humans:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('frame', frame)
if cv2.waitKey(1) == ord('q'):
breakcap.release() cv2.destroyAllWindows()
プログラムもくれるし、解説もくれる。やさしい
これだと動かないから追加質問。前提とかそーゆーのをすっ飛ばすのかな。今回だとモデルファイルが明らかに足りない。
ぐっどー。とりあえずこれで動いた。fullbodyなので全身だった。
顔だけでいいから〜とおもってモデルは差し替えありとか、細かい調整はしたけど動くものができて感動した。
感想
ある程度質問は考える必要はあるし、結果をちゃんと検証してあげないといけないけど、
完全ゼロベースから作ろうとおもたらすごいらく。今のところ強いGoogle検索感。
検索ワードすらまともに絞れないような状態のときなんかはめっちゃ便利だと思う。つよい。
3,4,5日目なんてなかった。いいね。
たいそうなタイトルになったけどすごーく浅いところで止めるよ。
目次
- はじめに
- Azure Fundamentals(AZ-900) ⇒ AWS AWS Certified Cloud Practitioner
- Azure portal ⇒ AWS management Console
- コンピューティング AZURE ⇒ AWS
- おわり。
はじめに
ざっつーに比較してますが。
そもそも同一じゃなかったり、やれることはやれるけど全然違うものだったりします。
ある程度どちらかを知っている人が新しく習得する足掛かり。程度かもしれない。
それにしたって概念ごと吸収したほうがいい気もするので、下手に比較しないほうがいいかなーと思ってます。
コンピューティング AZURE ⇒ AWS
数が多い。でかめにいく。
| Azure | AWS | 説明 |
|---|---|---|
| Azure Virtual Machines | EC2 | クラウド上の仮想まっすぃーん。VM細かいところはだいぶ違うと思うけど、浅いところは大差ないかな |
| Azure Kubernetes Service | EKS | k8sのマネジメントサービスかな。 |
| Azure Container Instances | ECS | これだいぶ違うんじゃないかなー。マネジメントなコンテナのオーケストレーションをサポートするぐらいしか類似ない気がする |
| Azure Functions | AWS lambda | イベントドリブンな関数実行的な。これは深いところは一緒な気がするけど、環境周りとかその辺は全然ちがうだろうなぁ |
仮想マシンはドキュメント
https://docs.microsoft.com/ja-jp/azure/virtual-machines/
ざっとよんでもなんかAWSと似たような感じで・・・
オート―スケールもできるし、リザーブドなインスタンスもあるし専有ホストもあるっぽい。もちろん違いはあるんだろうけどちょっと難しそう。
料金的な差もあるので検討するときはここは注意かなーと思う。
Functionsとlambdaもまーにてるような。Durable FunctionsとStepFunctionsがついになってんのかなーという気もする。
ここは特に動作仕様しだいでは単純に「同じ」というわけにもいかんところが多いと思うので、危ないよなーという感じ。
おわり。
つかれた。このシリーズで明日もなにか。。。
似たような名前で違うことしたり同じことするから混乱するね。
なんとか書く気力がわいたので2日目いってみよー。
目次
csv to AWSってなにするの。
s3にcsvほうりこんでathena(あてな)でクエリでも叩いてみませう。てな具合でs。
s3については1日目に軽く説明したよ
括弧excel的な奴はようするに、RDBMSもつかわずCSVでなりEXCELなり管理しているとしていて、
さらっとAWSにあげてみっか。というはなし。
ただクエリとか出てくるので使用感は違うかなーという気がします。
quickSiteとかその辺と組み合わせないとExcelの使用感は出ないと思う。
でかるーく検索したらコーユーのがヒットするんですよね。
aws.amazon.com
が、これはやらない。やってもよかったけどやろうとおもったこととはちがってるからだね。
検索の順番とかやることが固まってなかったらしたかもしれない。3日目に回す可能性もあるかな。
csv(excel) TO AWS
s3にぶちこむ。
ぶち込むだけ。今回は1日目みたいにアクセス制限は気にしなくていい。
※全部AWSコンソールでやるので、ログインしているユーザーにアクセス権限(ポリシー)が付与されていればよいのだ

おわり
なんじゃこれかん。たぶんこの状態だとオンプレでCSVをEXCELでよませるなり、
適当にスプレッドシートにでも物故んだほうが使いやすい。
athenaにJDBC経由でアクセスしたり、gateway開けるとか。なんかその辺しないと「うーん」ってなる。
なってる。
ちょっとパワーがたりねぇなぁ。ちょっとじゃねぇかもしれんけど。
ETLとかつかって String -> Dateとかもやりたかったけどちょっとよくわからんかったからやってない。
※よく見ると日付のはずの列が文字列になっているのだ。CSVだと日付のフォーマットが正規化されてないから文字として扱われちゃっている。
わかんないこと多いね。