TensorRT-LLM Speculative Decoding Boosts Inference Throughput by up to 3.6x (original) (raw)
NVIDIA TensorRT-LLM support for speculative decoding now provides over 3x the speedup in total token throughput. TensorRT-LLM is an open-source library that provides blazing-fast inference support for numerous popular large language models (LLMs) on NVIDIA GPUs. By adding support for speculative decoding on single GPU and single-node multi-GPU, the library further expands its supported optimizations to provide the best performance for generative AI applications.
TensorRT-LLM uses the NVIDIA TensorRT deep learning compiler. It includes the latest optimized kernels for cutting-edge implementations of different attention mechanisms for LLM model execution. It also consists of pre– and post-processing steps and multi-GPU/multi-node communication primitives in a simple, open-source Python API for groundbreaking LLM inference performance on GPUs.
Speculative decoding, also referred to as speculative sampling, works by paying a small additional computation cost to speculatively generate the next several tokens and then using the target model to perform a built-in verification step to ensure the quality of output generation while giving a throughput boost.
In this post, we describe the step-by-step setup to get speculating decoding working with TensorRT-LLM. For more information, including other optimizations, different models, and multi-GPU execution, see the full list of TensorRT-LLM examples.
Achieving throughput speedups with speculative decoding
Table 1 and Figure 1 show the difference in throughput (output tokens/second) between no draft model (that is, no speculative decoding) to varying-sized draft models along with the Llama 3.1 405B target model.
| Throughput Performance – Output Tokens/Second Four NVIDIA H200 Tensor Core GPUs | ||||
|---|---|---|---|---|
| Draft | Target Models | Llama 3.2 1B | Llama 3.1 405B | Llama 3.2 3 | Llama 3.1 405B | Llama 3.1 8B | Llama 3.1 405B | Llama 3.1 405B (without draft model) |
| Tokens/Sec | 111.34 | 120.75 | 101.86 | 33.46 |
| Speedups (with vs. without draft models) | 3.33x | 3.61x | 3.04x | N/A |
Table 1. Throughput performance using four NVIDIA H200 Tensor Core GPUs with TensorRT-LLM internal measurements
Data measured on 11/18/2024. Output tokens/second is inclusive of time to generate the first token – tok/s =total generated tokens / total latency. DGX H200, 4 GPUs, TensorRT Model Optimizer version 0.21 (pre-release), TensorRT-LLM version 0.15.0.dev.
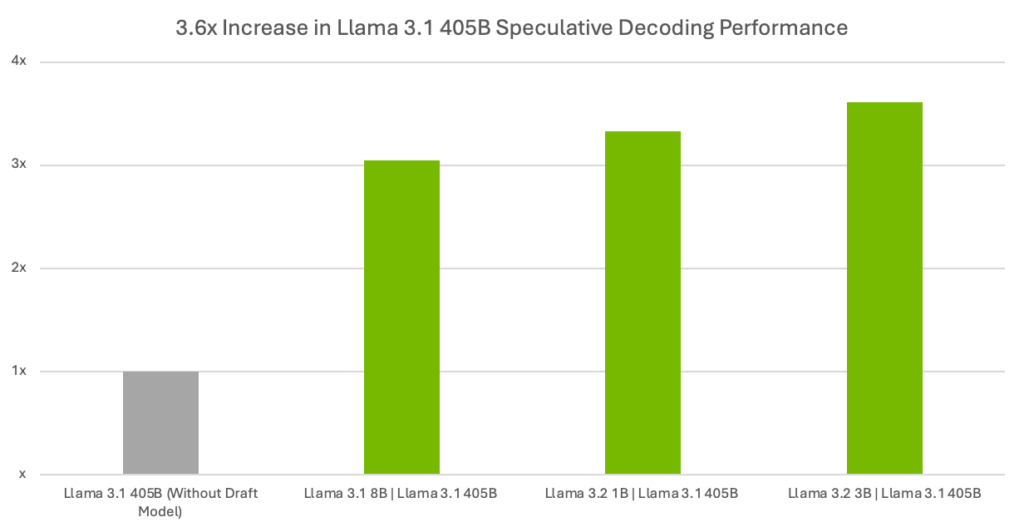
Figure 1. Throughput speedups using speculative decoding with Llama 3.1 405B target model
Table 2 and Figure 2 demonstrate the difference in throughput (output tokens/second) between no draft model (that is, no speculative decoding) to varying-sized draft models along with the Llama 3.1 70B target model.
| Throughput Performance – Output Tokens/Second One NVIDIA H200 Tensor Core GPU | ||||
|---|---|---|---|---|
| Draft | Target Models | Llama 3.2 1B | Llama 3.1 70B | Llama 3.2 3 | Llama 3.1 70B | Llama 3.1 8B | Llama 3.1 70B | Llama 3.1 70B (without draft model) |
| Tokens/Sec | 146.05 | 140.49 | 113.84 | 51.14 |
| Speedups (with vs without draft models) | 2.86x | 2.75x | 2.23x | N/A |
Table 2. Throughput performance using one NVIDIA H200 Tensor Core GPU with TensorRT-LLM internal measurements
Data measured on 11/18/2024. Output tokens/second is inclusive of time to generate the first token – tok/s =total generated tokens / total latency. DGX H200, 1 GPU, TensorRT Model Optimizer version 0.21 (pre-release), TensorRT-LLM version 0.15.0.dev.
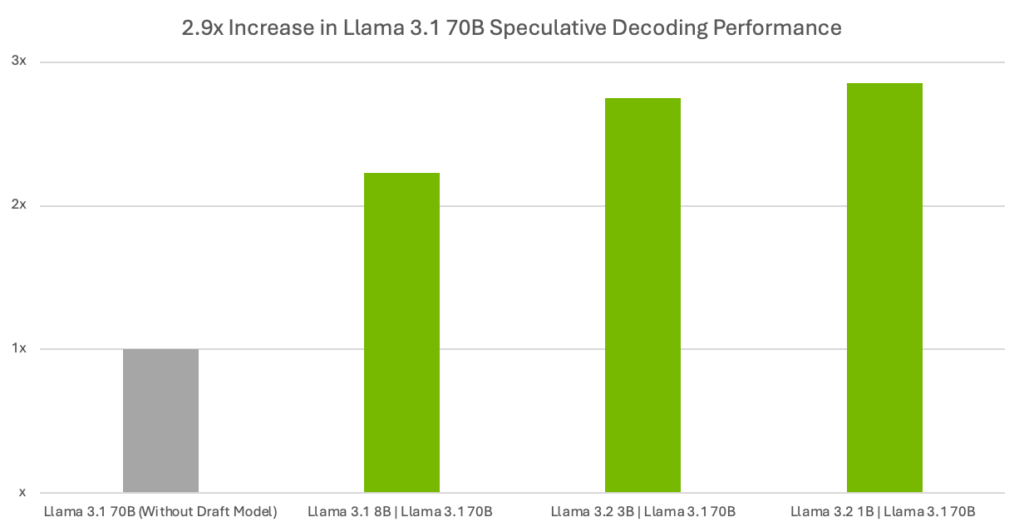
Figure 2. Throughput speedups using speculative decoding with the Llama 3.1 70B target model
TensorRT-LLM speculative decoding setup
Speculative decoding works by using two models running sequentially: A smaller, faster draft model (example: Llama2-7B) and a larger, slower target model (Llama2-70B). The draft model speculates the future output tokens, while the target model determines how many of those tokens it should accept.
As long as the draft model is sufficiently faster than the target model while also maintaining a high enough acceptance rate, the speculative sampling yields a lower end-to-end request latency by generating statistically more than one token per iteration (Figure 3).

Figure 3. Speculative decoding workflow
Speculative decoding tutorial
This tutorial walks you through the set-up steps to launch two models in parallel and the steps to enable speculative decoding within TensorRT-LLM.
Download the following model checkpoints from Hugging Face and store them in a directory for easy access through the setup process:
git lfs install
Download target models
git clone https://huggingface.co/meta-llama/Meta-Llama-3.1-405B-Instructgit clone https://huggingface.co/meta-llama/Meta-Llama-3.1-70B-Instruct
Download draft models
git clone https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct git clone https://huggingface.co/meta-llama/Llama-3.2-3B-Instructgit clone https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct
After the model checkpoints have been downloaded, install TensorRT-LLM:
Obtain and start the basic docker image environment (optional).
docker run --rm --ipc=host --runtime=nvidia --gpus all --entrypoint /bin/bash -it nvidia/cuda:12.5.1-devel-ubuntu22.04
Install dependencies, TensorRT-LLM requires Python 3.10
apt-get update && apt-get -y install python3.10 python3-pip openmpi-bin libopenmpi-dev git git-lfs
Fetch the library
git clone -b v0.14.0 https://github.com/NVIDIA/TensorRT-LLM.git cd TensorRT-LLM
Install the latest version (corresponding to the main branch) of TensorRT-LLM.
pip3 install tensorrt_llm -U --extra-index-url https://pypi.nvidia.com
Check installation
python3 -c "import tensorrt_llm"
Next, compile the downloaded model checkpoints into the draft and target TRT engines. These engines are optimized to run inference with the best accuracy and highest throughput.
cd examples
Steps to build 405B target and draft models in FP8 precision on 4 H200s
Create FP8 checkpoints
python3 quantization/quantize.py --model_dir
--model_dir=
--output_dir=./ckpt-target-405b
--dtype=float16 --qformat fp8 --kv_cache_dtype fp8 \ --calib_size 512 --tp_size 4
Build draft and target engines# Important flags for the engine build process:# --use_paged_context_fmha=enable must be specified since we need KVcache reuse for the draft/target model.
--speculative_decoding_mode=draft_tokens_external and --max_draft_len must be specified for target model.
trtllm-build
--checkpoint_dir ./ckpt-draft
--output_dir=./draft-engine \ --gpt_attention_plugin float16 \ --workers 4
--gemm_plugin=fp8 \ --reduce_fusion disable
--use_paged_context_fmha=enable \ --use_fused_mlp enable
--multiple_profiles enable
--max_batch_size=32
--max_num_tokens=8192
--max_seq_len=131072
trtllm-build
--checkpoint_dir=./ckpt-target-405b
--output_dir=./target-engine
--gpt_attention_plugin float16 \ --workers 4
--gemm_plugin=fp8 \ --use_paged_context_fmha=enable \ --use_fused_mlp enable
--multiple_profiles enable
--max_batch_size=32
--max_num_tokens=8192
--max_seq_len=131072 \ --low_latency_gemm_plugin fp8 \ --speculative_decoding_mode=draft_tokens_external \ --max_draft_len 10
Steps to build 70B target and draft models in FP8 precision on 1 H200
Create FP8 checkpoints
python3 quantization/quantize.py --model_dir
--model_dir=
--output_dir=./ckpt-target-70b
--dtype=float16 --qformat fp8 --kv_cache_dtype fp8 \ --calib_size 512 --tp_size 1
Build draft and target engines
trtllm-build
--checkpoint_dir ./ckpt-draft
--output_dir=./draft-engine \ --gpt_attention_plugin float16 \ --workers 1
--gemm_plugin=fp8 \ --reduce_fusion disable
--use_paged_context_fmha=enable \ --use_fused_mlp enable
--multiple_profiles enable
--max_batch_size=32
--max_num_tokens=8192
--max_seq_len=131072
trtllm-build
--checkpoint_dir=./ckpt-target-70b
--output_dir=./target-engine
--gpt_attention_plugin float16 \ --workers 1
--gemm_plugin=fp8 \ --use_paged_context_fmha=enable \ --use_fused_mlp enable
--multiple_profiles enable
--max_batch_size=32
--max_num_tokens=8192
--max_seq_len=131072 \ --low_latency_gemm_plugin fp8 \ --speculative_decoding_mode=draft_tokens_external \ --max_draft_len 10
Finally, run speculative decoding in TensorRT-LLM:
#Run decoding
Important flags to set during the run process:#--draft_engine_dir and --engine_dir must be specified for the draft and target engines.
#--draft_target_model_config is corresponding to the configuration of Draft-Target-Model. As an example, [4,[0],[1],False] means draft_len=4, device of draft model is GPU0, device of target model is GPU1, and use tokens rather than logits to accept.
Only CPP session (using executor as low-level API) is supported, while Python session (--use_py_session) is not supported.
Run with 405B target model
mpirun -n 4 --allow-run-as-root python3 ./run.py
--tokenizer_dir
--draft_engine_dir ./draft-engine
--engine_dir ./target-engine \ --draft_target_model_config = "[10,[0,1,2,3,4,5,6,7],[0,1,2,3,4,5,6,7], False]"
--kv_cache_free_gpu_memory_fraction=0.35
--max_output_len=1024
--kv_cache_enable_block_reuse
--input_text="Implement a program to find the common elements in two arrays without using any extra data structures."
Run with 70B target model
mpirun -n 1 --allow-run-as-root python3 ./run.py
--tokenizer_dir
--draft_engine_dir ./draft-engine
--engine_dir ./target-engine \ --draft_target_model_config = "[10,[0,1,2,3,4,5,6,7],[0,1,2,3,4,5,6,7], False]"
--kv_cache_free_gpu_memory_fraction=0.35
--max_output_len=1024
--kv_cache_enable_block_reuse
--input_text="Implement a program to find the common elements in two arrays without using any extra data structures."
To benchmark throughput performance without speculative decoding, follow the steps in the following code example:
Run throughput benchmark for the 405B model without the draft model
trtllm-build --checkpoint_dir ./ckpt-target-405b --output_dir /data/405B-TRT/ --gpt_attention_plugin float16 --workers 4 --max_batch_size 32 --max_seq_len 131072 --max_num_tokens 8192 --use_fused_mlp enable --reduce_fusion enable --use_paged_context_fmha enable --multiple_profiles enable --gemm_plugin fp8
python3 /app/tensorrt_llm/benchmarks/cpp/prepare_dataset.py --output token-norm-dist.json --tokenizer /llama-3_1-405b/ token-norm-dist --num-requests 1000 --input-mean 500 --input-stdev 0 --output-mean 200 --output-stdev 0 > /tmp/synthetic.txt
trtllm-bench --model
Repeat the steps for 70B model by replacing with --workers 1 during engine build process
TensorRT-LLM speculative decoding is also supported with the NVIDIA Triton Inference Server backend for production-ready deployments.
Triton Inference Server is an open-source inference serving software that streamlines AI inferencing. With Triton TensorRT-LLM Backend, you can take advantage of all the different features to enhance the performance and functionality of your production deployment:
Summary
TensorRT-LLM provides several features for optimizing and efficiently running large language models of different model architectures. For more information about low-latency optimizations and improved throughput, see the following posts: