Knowledge Catalog overview (original) (raw)
Knowledge Catalog is a Gemini-powered data catalog that provides universal business context and governance for your entire data estate. By automatically extracting semantics from structured and unstructured data, it builds a dynamic context graph that grounds AI agents in enterprise truth and reduces hallucinations. Data teams and AI developers use Knowledge Catalog to discover data, enforce policies, and retrieve rich context for both analytics and autonomous applications. For a detailed walkthrough of Knowledge Catalog, see the embedded video.
Dataplex Universal Catalog is now Knowledge Catalog
To better reflect the vision of unifying data governance with generative AI capabilities, Dataplex Universal Catalog is now Knowledge Catalog. This evolution of the product name represents a shift from a conventional, passive metadata registry to an active, AI-powered context graph.
Why did Dataplex become Knowledge Catalog
As organizations accelerate their generative AI adoption, AI agents need deep business context to provide accurate, grounded responses. Knowledge Catalog bridges the gap between enterprise data governance and AI agent workflows.
What is the difference between Dataplex and Knowledge Catalog
Knowledge Catalog updates reflect new AI-centric capabilities. Unlike conventional passive catalogs, Knowledge Catalog automatically curates metadata, business logic, and data relationships into a unified context graph. This graph provides the reliable enterprise truth that AI agents need to run complex tasks accurately. It leverages features like automatic context curation, verified example queries, and local and remote Model Context Protocol (MCP) integrations.
What is not changing
Your existing Dataplex deployments, APIs, and configurations remain operational. Core features like data discovery, lineage, data quality, and business glossaries are unchanged and supported. Your existing metadata, aspects, and configurations transition to the new Knowledge Catalog experience without any manual migration, data movement, or downtime.
APIs and client libraries
The rebranding to Knowledge Catalog doesn't change existing API endpoints, gcloud dataplex commands, or client libraries. You can continue to use the Knowledge Catalog APIs and client libraries to interact with Knowledge Catalog:
- REST API. See the Knowledge Catalog REST API documentation.
- RPC API. See the Knowledge Catalog RPC API documentation.
- Client libraries. Get started with Knowledge Catalog in your language of choice using the Knowledge Catalog client libraries.
- gcloud commands. Manage Knowledge Catalog resources using the
gcloud dataplexcommand group. See the gcloud Dataplex command reference.
How Knowledge Catalog works
Knowledge Catalog unifies governance and context through three core pillars:
- Governance foundation. Knowledge Catalog automatically collects technical metadata from Google Cloud services like BigQuery, AlloyDB for PostgreSQL, and Spanner, alongside third-party systems. It establishes a trusted data foundation through a centralized business glossary, data quality checks, anomaly detection, and policy-based governance.
- Context curation. Using Gemini, the service infers business intent by analyzing schemas, query logs, and semantic models across your data. It generates natural language descriptions, discovers relationships, and proposes verified SQL patterns in the form of example queries that capture complex business logic.
- Context retrieval. AI agents and applications can instantly discover assets and retrieve enriched context through semantic search and tools supporting the Model Context Protocol (MCP). This lets agents access organizational truth for reliable decision-making.
The following diagram illustrates the architecture of Knowledge Catalog and how it unifies data governance with generative AI workflows:
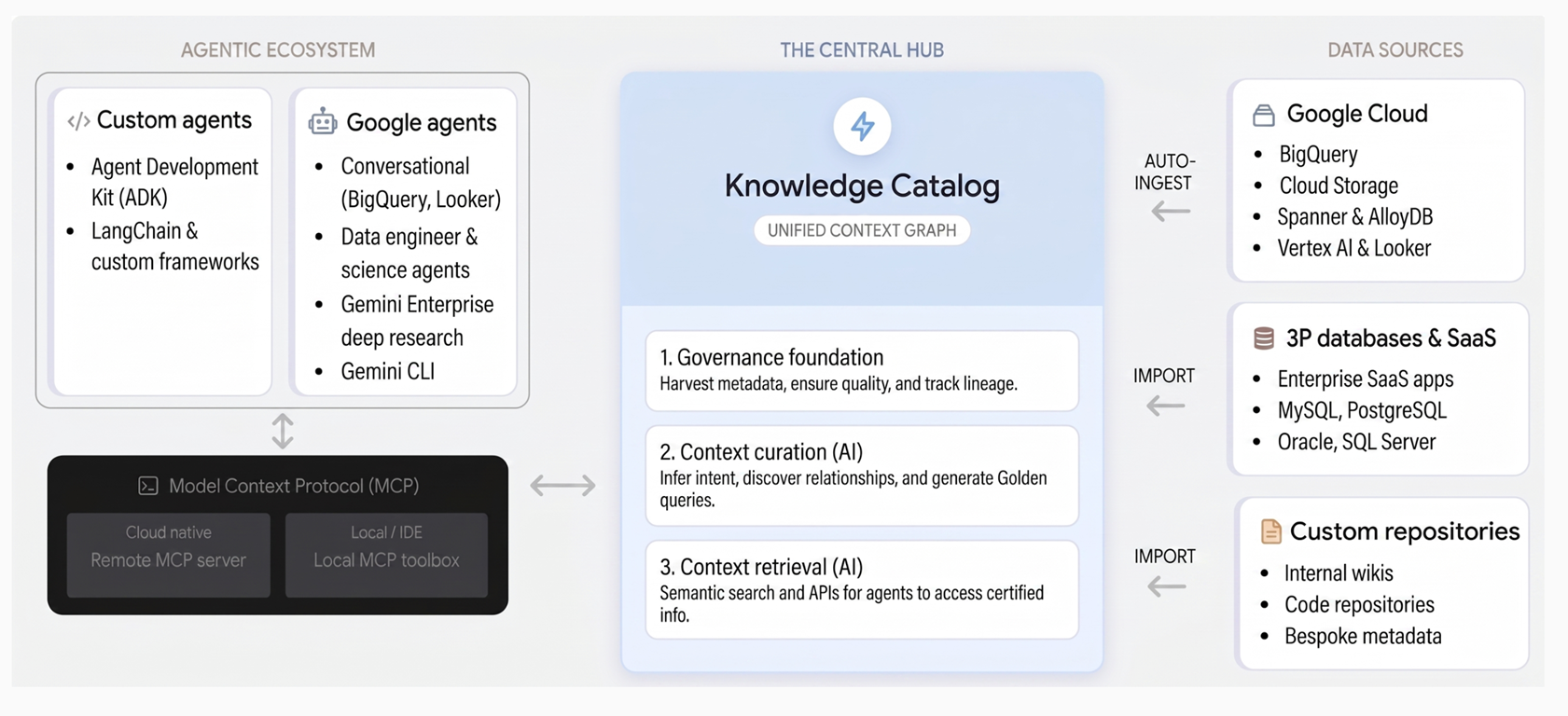
Figure 1. Architecture of Knowledge Catalog (click to enlarge)
Common use cases
Knowledge Catalog helps data engineers, data scientists, and AI developers solve challenges across data management and AI development:
- Enrich data for AI. Use data insights for unstructured data to automatically extract metadata and entities from unstructured files such as PDFs in Cloud Storage. This makes dark data and organizational knowledge accessible to AI models.
- Reduce AI hallucinations. Provide AI agents with pre-verified example queries and semantic guardrails, letting them execute complex data retrievals with more deterministic accuracy.
- Accelerate data discovery. Use semantic search and a centralized context graph to locate relevant data assets across disparate sources for analytics and data science workflows.
- Automate data product creation. Infer relationships across your data estate to package assets into self-contained data products with built-in service-level agreements (SLAs) and governance constraints.
Sample workflows in Knowledge Catalog
To see how you can build your context graph and manage your data estate, consider how an online retail company might use the following Knowledge Catalog features:
- Discover and catalog data. The retailer automatically ingests transaction data and collects metadata from Google Cloud services like BigQuery, Pub/Sub, and Cloud Storage. The service also imports metadata from custom inventory databases to build a unified view of the entire retail data estate. For more information, seeDiscover data.
- Search for data assets. A data scientist finds the exact customer data assets they need using the Knowledge Catalog search engine with faceted filtering, natural language semantic search, and logical operators. For more information, see Search for data assets.
- Enrich data with business context. The data governance team defines retail terminology (such as "Lifetime Value" or "SKU") using business glossaries, and uses AI-powered data insights to automatically generate descriptions for new product tables. They also manually apply structured custom metadata and tags (aspects) uniformly across their assets. For more information, seeManage aspects and enrich metadata andManage a business glossary.
- Understand data relationships with lineage. The engineering team automatically tracks data lineage to see how order data moves, is transformed, and is consumed across their systems. They use lineage graphs to troubleshoot reporting pipelines, perform root-cause analysis on checkout errors, and ensure compliance. For more information, see Data lineage overview.
- Profile data and measure quality. The retailer uses automated data profiling to identify patterns and anomalies in their BigQuery pricing tables. They define and run data quality checks to ensure customer shipping addresses are accurate, complete, and reliable for downstream AI and fulfillment workloads. For more information, see Data profiling overview andAuto data quality overview.
- Curate and share data products. The data platform team packages regional sales assets and their related metadata, quality scores, and lineage into curated "Customer 360" data products that are discovered and consumed by marketing and inventory teams. For more information, see Data products overview.
Knowledge Catalog in the Google Cloud ecosystem
When building a data foundation, it is important to understand how Knowledge Catalog integrates with related Google Cloud services:
| Service | Primary role | When to use |
|---|---|---|
| Knowledge Catalog | Agentic context and data governance | Use to catalog metadata, manage data quality, and provide semantic grounding for AI agents. |
| BigQuery | Enterprise data warehouse | Use to store, query, and analyze massive datasets. Knowledge Catalog enriches BigQuery data with business context. |
| Vertex AI | AI and machine learning platform | Use to build and deploy ML models and AI agents. Agents use Knowledge Catalog APIs to retrieve accurate enterprise context. |
| Cloud Storage | Unstructured data storage | Use to store raw files. Knowledge Catalog scans Cloud Storage buckets to extract searchable metadata and entities. |
Core concepts
To use Knowledge Catalog effectively, understand the following key concepts:
- Context graph. A dynamic, unified map of how data relates to your business. It connects technical schemas with business entities and unstructured knowledge.
- Example queries. Pre-generated, verified SQL patterns that capture complex business logic. These queries let both humans and AI agents query data accurately without reinventing complex table joins.
- Model Context Protocol (MCP). An open standard that lets AI agents discover and adaptively use available tools. Knowledge Catalog uses MCP tools to serve certified organizational truth directly to agents, offering both remote and local MCP servers to accommodate accessibility and security requirements.
-- Example: An example query retrieved by an AI agent to ensure accurate revenue calculation
SELECT customer_id, SUM(transaction_amount) AS total_revenue
FROM `sales.processed_transactions`
WHERE transaction_status = 'COMPLETED'
GROUP BY customer_id;
Ingestions
Knowledge Catalog automatically ingests metadata from the following Google Cloud sources. For some services, such as AlloyDB for PostgreSQL and Cloud SQL, you must first enable Knowledge Catalog integration before metadata can be ingested:
- Analytics and lakehouse
- BigQuery datasets, tables, views, models, routines, connections, and linked datasets
- BigQuery sharing (formerly Analytics Hub) exchanges and listings
- Dataform repositories and code assets
- Dataproc Metastore services, databases, and tables
- Iceberg REST Catalog tables (including Google Cloud Lakehouse runtime catalog IRC, Databricks Unity IRC, AWS Glue Data Catalog IRC, and Snowflake Horizon IRC)
- AI and Machine learning
- Vertex AI models, datasets, feature groups, feature views, and online store instances
- Business intelligence
- Looker (Google Cloud core) instances, dashboards, dashboard elements, Looks, LookML projects, models, Explores, and views (Preview)
- Databases
- Bigtable instances, clusters, and tables (including column family details)
- Spanner instances, databases, tables, and views
- Streaming and messaging
- Pub/Sub topics
- Unstructured data
- Operational databases
- AlloyDB for PostgreSQL clusters, instances, databases, schemas, tables, and views (Preview). Knowledge Catalog retrieves metadata only from AlloyDB for PostgreSQL primary instances and not from read replicas. For more information, seeManage your AlloyDB for PostgreSQL resources using Knowledge Catalog.
- Cloud SQL instances, databases, schemas, tables, views. Knowledge Catalog retrieves metadata only from Cloud SQL primary instances and not from read replicas. For more information, seeManage your Cloud SQL resources using Knowledge Catalog.
To import metadata from a third-party source into Knowledge Catalog, you can use a managed connectivity pipeline. For more information, see Managed connectivity overview.
Limitations
When planning your deployment, consider the following limitations:
- Supported integrations. While Knowledge Catalog supports major third-party systems, certain automated semantic extractions might be limited to built-in Google Cloud services.
- Quota limits. Standard Google Cloud API quotas apply to context retrieval and metadata extraction operations.
What's next
- Read the Introduction to Knowledge Catalog for AI.
- Learn about metadata management in Knowledge Catalog.
- Learn how to search for data assets.
- Learn about data lineage.
- Learn about data profiling.
- Learn about auto data quality.
- Get hands-on with Knowledge Catalog.