Replicate Multi-Datacenter Topics Across Kafka Clusters in Confluent Platform (original) (raw)
Confluent Replicator allows you to easily and reliably replicate topics from one Kafka cluster to another. In addition to copying the messages, Replicator will create topics as needed preserving the topic configuration in the source cluster. This includes preserving the number of partitions, the replication factor, and any configuration overrides specified for individual topics. Replicator is implemented as a connector.
Features¶
Replicator supports the following features:
- Topic selection using whitelists, blacklists, and regular expressions.
- Dynamic topic creation in the destination cluster with matching partition counts, replication factors, and topic configuration overrides.
- Automatic resizing of topics when new partitions are added in the source cluster.
- Automatic reconfiguration of topics when topic configuration changes in the source cluster.
- Timestamp Preservation, Using Provenance Headers to Prevent Duplicates or Cyclic Message Repetition, and Consumer Offset Translation (supported on Confluent Platform 5.0.1 and later).
- Using Provenance Headers to Prevent Duplicates or Cyclic Message Repetition, and Consumer Offset Translation (supported on Confluent Platform 5.0.1 and later).
- You can migrate from MirrorMaker to Replicator on existing datacenters (Confluent Platform 5.0.0 and later). Migration from MirrorMaker to Replicator is not supported in earlier versions of Confluent Platform (pre 5.5.0).
- At least once delivery, meaning the Replicator connector guarantees that records are delivered at least once to the Kafka topic. If the connector restarts, there may be some duplicate records in the Kafka topic.
Limitations¶
- Starting with Confluent Platform 7.0, using custom converters at the Replicator level to do schema migration is no longer supported. The recommended approach is to use the combination of Schema Linking plus Replicator with Byte Array Converters.
Multi-Datacenter Use Cases¶
Replicator can be deployed across clusters and in multiple datacenters. Multi-datacenter deployments enable use-cases such as:
- Active-active geo-localized deployments: allows users to access a near-by datacenter to optimize their architecture for low latency and high performance
- Active-passive disaster recover (DR) deployments: in an event of a partial or complete datacenter disaster, allow failing over applications to use Confluent Platform in a different datacenter.
- Centralized analytics: Aggregate data from multiple Apache Kafka® clusters into one location for organization-wide analytics
- Cloud migration: Use Kafka to synchronize data between on-prem applications and cloud deployments
Replication of events in Kafka topics from one cluster to another is the foundation of Confluent’s multi datacenter architecture.
Replication can be done with Confluent Replicator or using the open source Kafka MirrorMaker. Replicator can be used for replication of topic data as well as migrating schemas in Schema Registry.
This documentation focuses on Replicator, including architecture, quick start tutorial, how to configure and run Replicator in different contexts, tuning and monitoring, cross-cluster failover, and more. A section on how to migrate from MirrorMaker to Replicator is also included.
Some of the general thinking on deployment strategies can also apply to MirrorMaker, but if you are primarily interested in MirrorMaker, see Mirroring data between clusters in the Kafka documentation.
Architecture¶
The diagram below shows the Replicator architecture. Replicator uses the Kafka Connect APIs and Workers to provide high availability, load-balancing and centralized management.
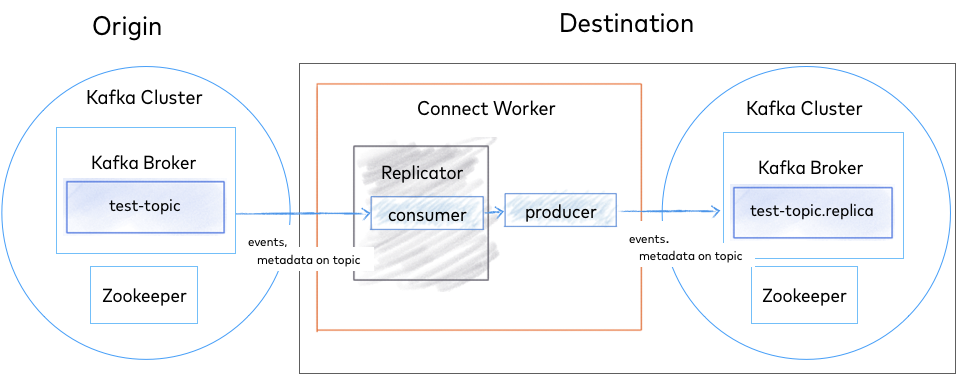
Replicator Architecture¶
Tip
You can deploy Replicator near the destination cluster or the origin cluster, and it will work either way. However, a best practice is to deploy Replicator closer to the destination cluster for reliability and performance over networks. Therefore, if the destination cluster is Confluent Cloud, we recommend that you deploy Replicator on an instance in the same region as your Confluent Cloud cluster. However, if the origin cluster does not permit external connections, you may deploy Replicator in the origin cluster. (See also Migrate Topics on Confluent Cloud Clusters.)
Example Deployment¶
In a typical multi-datacenter deployment, data from two geographically distributed Kafka clusters located in separate datacenters is aggregated in a separate cluster located in another datacenter. The origin of the copied data is referred to as the “source” cluster while the target of the copied data is referred to as the “destination.”
Each source cluster requires a separate instance of Replicator. For convenience you can run them in the same Connect cluster, located in the aggregate datacenter.

Replication to an Aggregate Cluster¶
Guidelines for Getting Started¶
Follow these guidelines to configure a multi-datacenter deployment using Replicator:
- Use the Replicator quick start to set up replication between two Kafka clusters.
- Learn how to install and configure Replicator and other Confluent Platform components in multi datacenter environments.
- Before running Replicator in production, make sure you read the monitoring and tuning guide.
- For a practical guide to designing and configuring multiple Kafka clusters to be resilient in case of a disaster scenario, see the Disaster Recovery white paper. This white paper provides a plan for failover, failback, and ultimately successful recovery.
Demos and Examples¶
After completing the Replicator quick start, explore these hands-on working examples of Replicator in multi-datacenter deployments, for which you can download the demo from GitHub and run yourself. Refer to the diagram below to determine the Replicator examples that correspond to your deployment scenario.
- Kafka on-premises to Kafka on-premises
- Example: Replicate Data in an Active-Active Multi-DataCenter Deployment on Confluent Platform: fully-automated example of an active-active multi-datacenter design with two instances of Replicator copying data bidirectionally between the datacenters
- Schema translation: showcases the transfer of schemas stored in Schema Registry from one cluster to another using Replicator
- Confluent Platform demo: deploy a Kafka streaming ETL, along with Replicator to replicate data
- Kafka on-premises to Confluent Cloud
- Hybrid On-premises and Confluent Cloud: on-premises Kafka cluster and Confluent Cloud cluster, and data copied between them with Replicator
- Connect Cluster Backed to Destination: Replicator configuration with Kafka Connect backed to destination cluster
- On-premises to Cloud with Connect Backed to Origin: Replicator configuration with Kafka Connect backed to origin cluster
- Confluent Cloud to Confluent Cloud
- Cloud to Cloud with Connect Backed to Destination: Replicator configuration with Kafka Connect backed to destination cluster
- Cloud to Cloud with Connect Backed to Origin: Replicator configuration with Kafka Connect backed to origin cluster
- Migrate Topics on Confluent Cloud Clusters: migrate topics from the origin Confluent Cloud cluster to the destination Confluent Cloud cluster
Topic Renaming¶
By default, the replicator is configured to use the same topic name in both the source and destination clusters. This works fine if you are only replicating from a single cluster. When copying data from multiple clusters to a single destination (i.e. the aggregate use case), you should use a separate topic for each source cluster in case there are any configuration differences between the topics in the source clusters.
It is possible to use the same Kafka cluster as the source and destination as long as you ensure that the replicated topic name is different. This is not a recommended pattern since generally you should prefer Kafka’s built-in replication within the same cluster, but it may be useful in some cases (e.g. testing).
Starting with Confluent Platform 5.0, Replicator protects against circular replication through the use of provenance headers. This guarantees that if two Replicator instances are configured to run, one replicating from DC1 to DC2 and the second instance configured to replicate from DC2 to DC1, Replicator will ensure that messages replicated to DC2 are not replicated back to DC1, and vice versa. As a result, Replicator safely runs in each direction.
Although Replicator can enable applications in different datacenters to access topics with the same names, you should design client applications with a topic naming strategy that takes into consideration a number of factors.
If you plan to have the same topic name span datacenters, be aware that in this configuration:
- Producers do not wait for commit acknowledgment from the remote cluster, and Replicator asynchronously copies the data between datacenters after it has been committed locally.
- If there are producers in each datacenter writing to topics of the same name, there is no “global ordering”. This means there are no message ordering guarantees for data that originated from producers in different datacenters.
- If there are consumer groups in each datacenter with the same group ID reading from topics of the same name, in steady state, they will be reprocessing the same messages in each datacenter.
In some cases, you may not want to use the same topic name in each datacenter. For example, in cases where:
- Replicator is running a version less than 5.0.1
- Kafka brokers are running a version prior to Kafka 0.11 that does not yet support message headers
- Kafka brokers are running Kafka version 0.11 or later but have less than the minimum required
log.message.format.version=2.0for using headers - Client applications are not designed to handle topics with the same name across datacenters
In these cases, refer to the appendix on “Topic Naming Strategies to Prevent Cyclic Repetition” in the Disaster Recovery white paper.
Security and ACL Configurations¶
ACLs Overview¶
Replicator supports communication with secure Kafka over TLS/SSL for both the source and destination clusters. Replicator also supports TLS/SSL or SASL for authentication. Differing security configurations can be used on the source and destination clusters.
All properties documented here are additive (i.e. you can apply both TLS/SSL Encryption and SASL Plain authentication properties) except for security.protocol. The following table can be used to determine the correct value for this:
| Encryption | Authentication | security.protocol |
|---|---|---|
| TLS/SSL | None | SSL |
| TLS/SSL | TLS/SSL | SSL |
| TLS/SSL | SASL | SASL_SSL |
| Plaintext | SASL | SASL_PLAINTEXT |
You can configure Replicator connections to source and destination Kafka with:
- TLS/SSL Encryption. You can use different TLS/SSL configurations on the source and destination clusters.
- SSL Authentication
- SASL/SCRAM
- SASL/GSSAPI
- SASL/PLAIN
To configure security on the source cluster, see the connector configurations for Source Kafka: Security. To configure security on the destination cluster, see the connector configurations Destination Kafka: Security and the general security configuration for Connect workers here.
See also
To see the required security configuration parameters for Replicator consolidated in one place, try out the docker-compose environments in GitHub confluentinc/examples.
When using SASL or TLS/SSL authentication and ACL is enabled on source or destination or both, Replicator requires the ACLs described in the following sections.
ACL commands are provided for both Confluent Platform (Confluent Platform CLI Command Reference) andConfluent Cloud.
For more information on configuring ACLs, see Use Access Control Lists (ACLs) for Authorization in Confluent Platform.
Principal Users (Confluent Platform) and Service Accounts (Confluent Cloud)¶
Commands to configure ACLs are given here for both Confluent Platform and Confluent Cloud.
On Confluent Platform, associate ACLs with a service principal.
On Confluent Cloud, associate ACLs with a Confluent Cloud service account.
To create a service account for Confluent Cloud, run the following the command:
confluent iam service-account create --description ""
For example:
confluent iam service-account create my-first-cluster-test-acls --description "test ACLs on Cloud"
+-------------+----------------------------+ | Id | 123456 | | Resource ID | ab-123abc | | Name | my-first-cluster-test-acls | | Description | test ACLs on Cloud | +-------------+----------------------------+
Save the service account ID to use in the following commands to create the ACLs.
Tip
You can retrieve service account IDs by listing them with confluent iam service-account list.
ACLs for License Management¶
For license management, you need the following ACLs:
| Cluster | Resource | Operation |
|---|---|---|
| Destination (or other cluster configured with confluent.topic.bootstrap.servers) | TOPIC - _confluent-command | All |
Commands to configure the above ACLs on Confluent Platform:
kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation ALL --topic _confluent-command
ACLs to Read from the Source Cluster¶
To read from the source cluster, you need the following ACLs:
| Cluster | Resource | Operation |
|---|---|---|
| Source | CLUSTER | Describe |
| Source | TOPIC - all topics Replicator will replicate | Describe |
| Source | TOPIC - all topics Replicator will replicate | Read |
| Source | GROUP - The consumer group name is determined by the Replicator name or by the src.consumer.group.id property | Read |
Commands to configure the above ACLs on Confluent Platform:
kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation DESCRIBE --cluster kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation DESCRIBE --topic kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation READ --topic
ACLs to Write to the Destination Cluster¶
To write to the destination cluster, you need the following ACLs:
| Cluster | Resource | Operation |
|---|---|---|
| Destination | CLUSTER | Describe |
| Destination | TOPIC - all topics Replicator will replicate | Describe |
| Destination | TOPIC - all topics Replicator will replicate | Write |
| Destination | TOPIC - all topics Replicator will replicate | Read |
Commands to configure the above ACLs on Confluent Platform:
kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation DESCRIBE --cluster kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation DESCRIBE --topic kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation WRITE --topic kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation READ --topic
ACLs for Topic Creation and Config Sync¶
If using the topic creation and config sync features of Replicator (enabled by default), you need the following ACLs:
| Cluster | Resource | Operation |
|---|---|---|
| Source | TOPIC - all topics Replicator will replicate | DescribeConfigs |
| Destination | TOPIC - all topics Replicator will replicate | Create |
| Destination | TOPIC - all topics Replicator will replicate | DescribeConfigs |
| Destination | TOPIC - all topics Replicator will replicate | AlterConfigs |
For configuration options relating to topic creation and config sync, see Destination Topics.
Commands to configure the above ACLs on Confluent Platform:
kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation DESCRIBECONFIGS --topic kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation DESCRIBECONFIGS --topic kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation CREATE --cluster kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation ALTERCONFIGS --cluster
ACLs for Offset Translation¶
If using the offset translation feature of Replicator (enabled by default), you need the following ACLs:
| Cluster | Resource | Operation |
|---|---|---|
| Source | TOPIC - __consumer_timestamps | All |
| Destination | GROUP - All consumer groups that will be translated | All |
For configuration options relating to offset translation, see consumer_offset_translation.
Commands to configure the above ACLs on Confluent Platform:
kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation ALL --topic {_consumer_timestamps} kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation ALL --topic {}
ACLs for the Timestamp Interceptor¶
Any clients instrumented with the Replicator timestamp interceptor must also have the following ACLs:
| Cluster | Resource | Operation |
|---|---|---|
| Source | TOPIC - __consumer_timestamps | Write |
| Source | TOPIC - __consumer_timestamps | Describe |
Commands to configure the above on Confluent Platform:
kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation WRITE --topic __consumer_timestamps kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation DESCRIBE --topic __consumer_timestamps
ACLs for Source Offset Management¶
If using the source offset management feature of Replicator (enabled by default), you need the following ACLs:
| Cluster | Resource | Operation |
|---|---|---|
| Source | GROUP - The consumer group name is determined by the Replicator name or by the src.consumer.group.id property | All |
For configuration options relating to offset management see Offset Management in the Replicator Configuration Reference.
Commands to configure the above ACLs on Confluent Platform:
kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf --add --allow-principal User: --operation ALL --group
Replicator with RBAC¶
When using RBAC, Replicator clients should use token authentication as described in Configure Clients for SASL/OAUTHBEARER authentication in Confluent Platform. These configurations should be prefixed with the usual Replicator prefixes of src.kafka. and dest.kafka.. An example configuration for source and destination cluster that are RBAC enabled is below:
src.kafka.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required
username="sourceUser
password="xxx"
metadataServerUrls="http://sourceHost:8090";
src.kafka.security.protocol=SASL_PLAINTEXT
src.kafka.sasl.mechanism=OAUTHBEARER
src.kafka.sasl.login.callback.handler.class=io.confluent.kafka.clients.plugins.auth.token.TokenUserLoginCallbackHandler
dest.kafka.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required
username="destUser
password="xxx"
metadataServerUrls="http://destHost:8090";
dest.kafka.security.protocol=SASL_PLAINTEXT
dest.kafka.sasl.mechanism=OAUTHBEARER
dest.kafka.sasl.login.callback.handler.class=io.confluent.kafka.clients.plugins.auth.token.TokenUserLoginCallbackHandler
for Replicator executable these should not be prefixed and should be placed in files referred to by --consumer.config and --producer.config as shown below:
in --consumer.config
sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required
username="sourceUser
password="xxx"
metadataServerUrls="http://sourceHost:8090";
security.protocol=SASL_PLAINTEXT
sasl.mechanism=OAUTHBEARER
sasl.login.callback.handler.class=io.confluent.kafka.clients.plugins.auth.token.TokenUserLoginCallbackHandler
in --producer.config
sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required
username="destUser
password="xxx"
metadataServerUrls="http://destHost:8090";
security.protocol=SASL_PLAINTEXT
sasl.mechanism=OAUTHBEARER
sasl.login.callback.handler.class=io.confluent.kafka.clients.plugins.auth.token.TokenUserLoginCallbackHandler
The configuration above requires that the Metadata Service (MDS) is running. For more information on this see Configure Metadata Service (MDS) in Confluent Platform
Important
The rolebindings below are based on the following assumptions:
- There are two “independent” RBAC deployments (one in each DC)
- Each RBAC deployment supports all other services local to it (Connect, Schema Registry, etc.)
- RBAC rolebindings will not be replicated (Replicator does not support this)
Replicator requires the rolebindings listed below.
For the backing Connect cluster:
| Cluster | Resource | Role |
|---|---|---|
| Destination | GROUP - name given by the group.id property | ResourceOwner |
| Destination | TOPIC - name given by the offset.storage.topic property (default connect-offsets) | ResourceOwner |
| Destination | TOPIC - name given by the config.storage.topic property (default connect-configs) | ResourceOwner |
| Destination | TOPIC - name given by the status.storage.topic property (default connect-status) | ResourceOwner |
For license management:
| Cluster | Resource | Role |
|---|---|---|
| Destination (or other cluster configured with confluent.topic.bootstrap.servers) | TOPIC - _confluent-command | DeveloperRead |
| Destination (or other cluster configured with confluent.topic.bootstrap.servers) | TOPIC - _confluent-command | DeveloperWrite |
| Destination (or other cluster configured with confluent.topic.bootstrap.servers) | TOPIC - _confluent-command | DeveloperManage |
To read from the source cluster:
| Cluster | Resource | Role |
|---|---|---|
| Source | TOPIC - all topics that Replicator will replicate | DeveloperRead |
| Source | TOPIC - all topics that Replicator will replicate | DeveloperManage |
To write to the destination cluster:
| Cluster | Resource | Role |
|---|---|---|
| Destination | TOPIC - all topics that Replicator will replicate | ResourceOwner |
Important
If not using the topic configuration sync feature of Replicator (enabled by default) then the following roles can be used in place of ResourceOwner:
| Cluster | Resource | Role |
|---|---|---|
| Destination | TOPIC - all topics that Replicator will replicate | DeveloperRead |
| Destination | TOPIC - all topics that Replicator will replicate | DeveloperWrite |
| Destination | TOPIC - all topics that Replicator will replicate | DeveloperManage |
If using the offset translation feature of Replicator (enabled by default):
| Cluster | Resource | Role |
|---|---|---|
| Source | TOPIC - __consumer_timestamps | DeveloperRead |
| Source | TOPIC - __consumer_timestamps | DeveloperManage |
| Destination | GROUP - All consumer groups that will be translated (if you do not know these use the literal * to allow all) | DeveloperRead |
Also, any consumers on the source cluster using the Replicator timestamp interceptor will require:
| Cluster | Resource | Role |
|---|---|---|
| Source | TOPIC - __consumer_timestamps | DeveloperWrite |
| Source | TOPIC - __consumer_timestamps | DeveloperManage |
For configuration options relating to offset translation see Consumer Offset Translation.
If using the source offset management feature of Replicator (enabled by default):
| Cluster | Resource | Role |
|---|---|---|
| Source | GROUP - The consumer group name is determined by the Replicator name or by the src.consumer.group.id property | ResourceOwner |
If using the schema migration feature of Replicator (disabled by default):
| Cluster | Resource | Role |
|---|---|---|
| Source | TOPIC - underlying Schema Registry topic (default _schemas) | DeveloperRead |
| Destination | CLUSTER - Schema Registry cluster | ClusterAdmin |
For more information on configuring RBAC, see Use Role-Based Access Control (RBAC) for Authorization in Confluent Platform.
Replicating messages with schemas¶
Replicator does not support an “active-active” Schema Registry setup. It only supports migration (either one-time or continuous) from an active Schema Registry to a passive Schema Registry.
Starting with Confluent Platform 7.0.0, Schema Linking is available in preview on Confluent Platform, as described in Link Schemas on Confluent Platform.This is the recommended method of migrating schemas. For migrating schemas from one Confluent Cloud cluster to another, use cloud specific Schema Linking.
For pre Confluent Platform 7.0.0 releases, use Replicator with Schema Translationto migrate schemas from a self-managed cluster to a target cluster which is either self-managed or in Confluent Cloud. (This was first available in Confluent Platform 5.2.0.)
To learn more about schema migration, see Use Schema Registry to Migrate Schemas in Confluent Platform and Link Schemas on Confluent Platform.
Schema ID Validation and Replicator¶
By default, Replicator is configured with topic.config.sync=true. If the source cluster has a topic with Validate Broker-side Schemas IDs in Confluent Platform enabled (confluent.value.schema.validation=true), then Replicator will copy this property to the destination cluster’s replicated topic.
When using Replicator to replicate data from one cluster of brokers to another, you would typically want to avoid another validation on the secondary cluster to skip the overhead of doing so.
Therefore, you might want to either disable Schema ID Validation on the source cluster before replicating to the destination, or set topic.config.sync=false on Replicator and explicitly set the configurations you want on the destination cluster broker properties files.
Requirements¶
From a high level, Replicator works like a consumer group with the partitions of the replicated topics from the source cluster divided between the connector’s tasks. Replicator periodically polls the source cluster for changes to the configuration of replicated topics and the number of partitions, and updates the destination cluster accordingly by creating topics or updating configuration. For this to work correctly, the following is required:
- The Origin and Destination clusters must be Apache Kafka® or Confluent Platform. For version compatibility see connector interoperability
- The Replicator version must match the Kafka Connect version it is deployed on. For instance Replicator 8.0 should only be deployed to Kafka Connect 8.0.
- The ACLs mentioned in here are required.
- The default topic configurations in the source and destination clusters must match. In general, aside from any broker-specific settings (such as
broker.id), you should use the same broker configuration in both clusters. - The destination Kafka cluster must have a similar capacity as the source cluster. In particular, since Replicator will preserve the replication factor of topics in the source cluster, which means that there must be at least as many brokers as the maximum replication factor used. If not, topic creation will fail until the destination cluster has the capacity to support the same replication factor. Note in this case, that topic creation will be retried automatically by the connector, so replication will begin as soon as the destination cluster has enough brokers.
- The
dest.kafka.bootstrap.serversdestination connection setting in the Replicator properties file must be configured to use a single destination cluster, even when using multiple source clusters. For example, the figure shown at the start of this section shows two source clusters in different datacenters targeting a single_aggregate_ destination cluster. Note that the aggregate destination cluster must have a similar capacity as the total of all associated source clusters. - On Confluent Platform versions 5.3.0 and later, Confluent Replicator requires the enterprise edition ofKafka Connect. Starting with Confluent Platform 5.3.0, Replicator does not support the community edition of Connect. You can install the enterprise edition of Connect as part of the Confluent Platform on-premises bundle, as described in Production Environments and in the Quick Start for Confluent Platform (choose self-managed Confluent Platform). Demos of enterprise Connect are available at Quick Start for Confluent Platform and on Docker Hub at confluentinc/cp-server-connect.
- The
timestamp-interceptorfor consumers supports only Java clients, as described in Configuring the consumer for failover (timestamp preservation).
Tip
For best performance, run Replicator as close to the destination cluster as possible to provide a low latency connection for Kafka Connect operations within Replicator.
Compatibility¶
For data transfer Replicator maintains the same compatibility matrix as Java clients, detailed in Kafka Java clients. However some Replicator features have different compatibility requirements:
- Schema Translation requires that both source and destination clusters are running Confluent 5.2.0 or later.
- Offset Translation requires that both source and destination clusters are running Confluent 5.1.0 or later.
- Automatic topic creation and config sync requires that the destination cluster is at a later version than the source cluster.
- The
timestamp-interceptorfor consumers supports only Java clients, as described in Configuring the consumer for failover (timestamp preservation). - Newer versions of Replicator cannot be used to replicate data from early version Kafka clusters to Confluent Cloud. Specifically, Replicator version 5.4.0 or later cannot be used to replicate data from clusters Apache Kafka® v0.10.2 or earlier nor from Confluent Platform v3.2.0 or earlier, to Confluent Cloud. If you have clusters on these earlier versions, use Replicator 5.0.x to replicate to Confluent Cloud until you can upgrade. Keep in mind the following, and plan your upgrades accordingly:
- Kafka Connect workers included in Confluent Platform 3.2 and later are compatible with any Kafka broker that is included in Confluent Platform 3.0 and later as documented in Cross-component compatibility.
- Confluent Platform 5.0.x has an end-of-support date of July 31, 2020 as documented in Supported Versions and Interoperability for Confluent Platform.
Known Issues, Limitations, and Best Practices¶
- While the use of Single Message Transformations (SMTs) in Replicator is supported, it is not a best practice. The use of Apache Flink® or Kafka Streams is considered best practice because these are more scalable and easier to debug.
- Replicator should not be used for serialization changes. In these cases, the recommended method is to use ksqlDB. To learn more, see the documentation on ksqlDB and the tutorial onHow to convert a stream’s serialization formaton the Confluent Developer site.
- When running Replicator with version 5.3.0 or above, set
connect.protocol=eageras there is a known issue where using the default ofconnect.protocol=compatibleorconnect.protocol=sessionedcan cause issues with tasks rebalancing and duplicate records. - If you encounter
RecordTooLargeExceptionwhen you use compressed records, set the record batch size for the Replicator producer to the highest possible value. When Replicator decompresses records while consuming from the source cluster, it checks the size of the uncompressed batch on the producer before recompressing them and may throwRecordTooLargeException. Setting the record batch size mitigates the exception, and compression proceeds as expected when the record is sent to the destination cluster. - The Replicator latency metric is calculated by subtracting the time the record was produced to the source from the time it was replicated on the destination. This works in the real time case, when there is active production going on in the source cluster and the calculation we are doing is in real time. However if you are replicating old data, you will see very large latency due to the old record timestamps. In the historical data case, the latency does not indicate how long Replicator is taking to replicate data. It indicates how much time has passed between the original message and now for the message that Replicator is currently replicating. As Replicator proceeds over historical data, the latency metric should decrease quickly.
- There’s an issue with the Replicator lag metric where the value
NaNis reported if there has not been a sample of lag being reported in a given time window. This can happen if you have limited production in the source cluster or if Replicator is not flushing data fast enough to the destination cluster, thus causing it to not be able to record enough samples in the given time window. This will cause the JMX metrics to reportNaNfor the Replicator metrics.NaNmay not necessarily mean that the lag is 0; it means that there aren’t enough samples in the given time window to report lag.
Replicator Connector¶
Replicator is implemented as a Kafka connector, and listed in Supported Connectors. Some general information related to connectors may apply in some cases, but most of the information you’ll need to work with Replicator is in this Replicator specific documentation.
Important
This connector is bundled natively with Confluent Platform. If you have Confluent Platform installed and running, there are no additional steps required to install.
If you are using Confluent Platform using only Confluent Community components, you can install the connector using the Confluent Hub Client (recommended) or you can manually download the ZIP file.
Related content¶
Getting Started Guides¶
- Tutorial: Replicate Data Across Kafka Clusters in Confluent Platform shows you how to get started using Replicator
- Example: Replicate Data in an Active-Active Multi-DataCenter Deployment on Confluent Platform provides a Docker based quick start
References¶
- Replicator Configuration Reference for Confluent Platform provides a full reference for configuration
- Confluent Platform and Cloud CLI Command Reference
Security¶
- Use Access Control Lists (ACLs) for Authorization in Confluent Platform
- Operations
- Manage Confluent Cloud Accounts and Access
- Service Accounts for Confluent Cloud
Migration Guides¶
- Migrate Topics on Confluent Cloud Clusters describes how to use Replicator to migrate topic data from one cloud cluster to another.
- Use Schema Registry to Migrate Schemas in Confluent Platform describes how to use Replicator to migrate a self-managed Schema Registry to Confluent Cloud.