Build your first Dagster pipeline | Dagster Docs (original) (raw)
Welcome to Dagster! In this guide, we'll cover:
- Setting up a basic Dagster project
- Creating a single Dagster asset that encapsulates the entire Extract, Transform, and Load (ETL) process
- Using Dagster's UI to monitor and execute your pipeline
Prerequisites
- Python 3.9+
- If using
uvas your package manager, you will need to installuv(Recommended). - If using
pipas your package manager, you will need to install thecreate-dagsterCLI with Homebrew,curl, orpip.
For detailed instructions, see the Installation guide.
- uv
- pip
- Open your terminal and scaffold a new Dagster project:
uvx -U create-dagster project dagster-quickstart - Respond
yto the prompt to runuv syncafter scaffolding
- Change to the
dagster-quickstartdirectory: - Activate the virtual environment:
- MacOS/Unix
- Windows
source .venv/bin/activate - Install the required dependencies in the virtual environment:
Your new Dagster project should have the following structure:
- uv
- pip
.
└── dagster-quickstart
├── pyproject.toml
├── src
│ └── dagster_quickstart
│ ├── __init__.py
│ ├── definitions.py
│ └── defs
│ └── __init__.py
├── tests
│ └── __init__.py
└── uv.lock
Use the dg scaffold defs command to generate an assets file on the command line:
dg scaffold defs dagster.asset assets.py
This will add a new file assets.py to the defs directory:
src
└── dagster_quickstart
├── __init__.py
└── defs
├── __init__.py
└── assets.py
Next, create a sample_data.csv file. This file will act as the data source for your Dagster pipeline:
mkdir src/dagster_quickstart/defs/data && touch src/dagster_quickstart/defs/data/sample_data.csv
In your preferred editor, copy the following data into this file:
src/dagster_quickstart/defs/data/sample_data.csv
id,name,age,city
1,Alice,28,New York
2,Bob,35,San Francisco
3,Charlie,42,Chicago
4,Diana,31,Los Angeles
To define the assets for the ETL pipeline, open src/dagster_quickstart/defs/assets.py file in your preferred editor and copy in the following code:
src/dagster_quickstart/defs/assets.py
import pandas as pd
import dagster as dg
sample_data_file = "src/dagster_quickstart/defs/data/sample_data.csv"
processed_data_file = "src/dagster_quickstart/defs/data/processed_data.csv"
@dg.asset
def processed_data():
## Read data from the CSV
df = pd.read_csv(sample_data_file)
## Add an age_group column based on the value of age
df["age_group"] = pd.cut(
df["age"], bins=[0, 30, 40, 100], labels=["Young", "Middle", "Senior"]
)
## Save processed data
df.to_csv(processed_data_file, index=False)
return "Data loaded successfully"
At this point, you can list the Dagster definitions in your project with dg list defs. You should see the asset you just created:
┏━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Section ┃ Definitions ┃
┡━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ Assets │ ┏━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━┳━━━━━━━┳━━━━━━━━━━━━━┓ │
│ │ ┃ Key ┃ Group ┃ Deps ┃ Kinds ┃ Description ┃ │
│ │ ┡━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━╇━━━━━━━╇━━━━━━━━━━━━━┩ │
│ │ │ processed_data │ default │ │ │ │ │
│ │ └────────────────┴─────────┴──────┴───────┴─────────────┘ │
└─────────┴───────────────────────────────────────────────────────────┘
You can also load and validate your Dagster definitions with dg check defs:
All components validated successfully.
All definitions loaded successfully.
- In the terminal, navigate to your project's root directory and run:
- Open your web browser and navigate to http://localhost:3000, where you should see the Dagster UI:
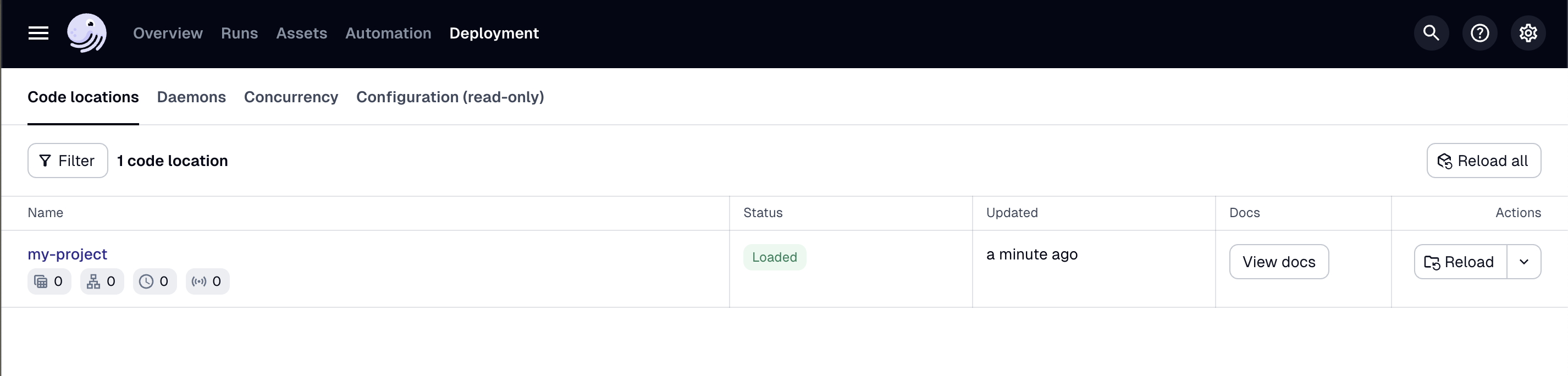
- In the top navigation, click Assets > View lineage.
- Click Materialize to run the pipeline.
- In the popup, click View. This will open the Run details page, allowing you to view the run as it executes.
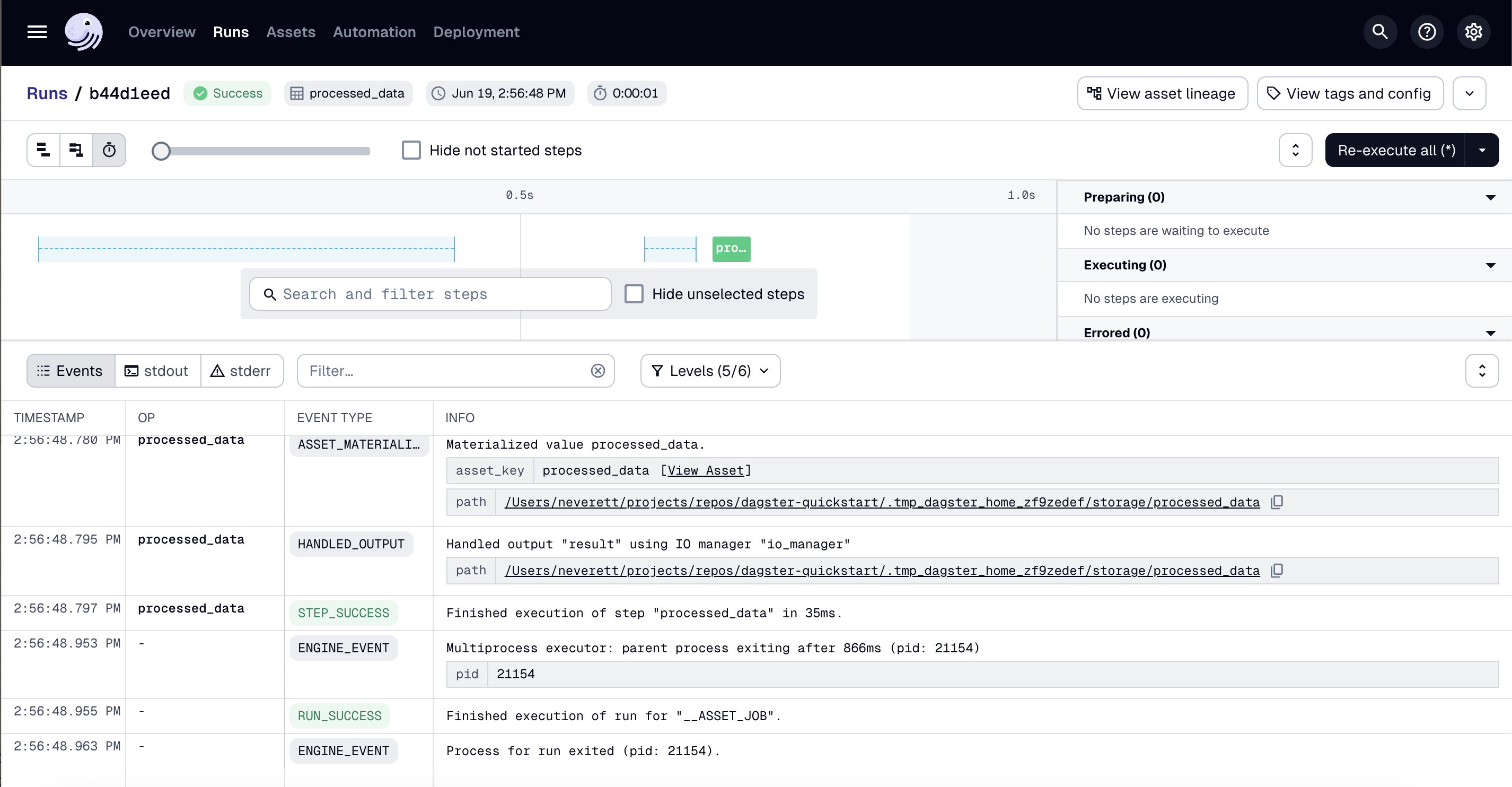
Use the view buttons in near the top left corner of the page to change how the run is displayed. You can also click the asset to view logs and metadata.
In your terminal, run:
cat src/dagster_quickstart/defs/data/processed_data.csv
You should see the transformed data, including the new age_group column:
id,name,age,city,age_group
1,Alice,28,New York,Young
2,Bob,35,San Francisco,Middle
3,Charlie,42,Chicago,Senior
4,Diana,31,Los Angeles,Middle
Congratulations! You've just built and run your first pipeline with Dagster. Next, you can:
- Continue with the ETL pipeline tutorial to learn how to build a more complex ETL pipeline
- Create your own Dagster project and add assets to it