What is dbt? | dbt Developer Hub (original) (raw)
dbt is the industry standard for data transformation. Learn how it can help you transform data and deploy analytics code following software engineering best practices like version control, modularity, portability, CI/CD, and documentation.
dbt is a transformation workflow that helps you get more work done while producing higher quality results. You can use dbt to modularize and centralize your analytics code, while also providing your data team with guardrails typically found in software engineering workflows. Collaborate on data models, version them, and test and document your queries before safely deploying them to production, with monitoring and visibility.
dbt compiles and runs your analytics code against your data platform, enabling you and your team to collaborate on a single source of truth for metrics, insights, and business definitions. This single source of truth, combined with the ability to define tests for your data, reduces errors when logic changes, and alerts you when issues arise.
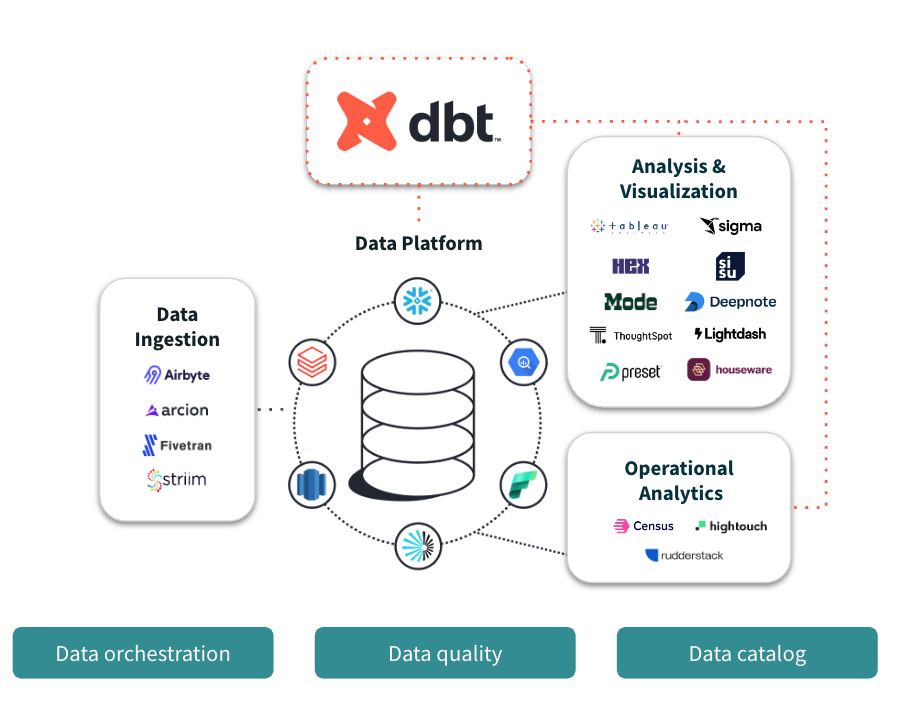 dbt works alongside your ingestion, visualization, and other data tools, so you can transform data directly in your cloud data platform.
dbt works alongside your ingestion, visualization, and other data tools, so you can transform data directly in your cloud data platform.
Read more about why we want to enable analysts to work more like software engineers in The dbt Viewpoint. Learn how other data practitioners around the world are using dbt by joining the dbt Community.
Use dbt to quickly and collaboratively transform data and deploy analytics code following software engineering best practices like version control, modularity, portability, CI/CD, and documentation. This means anyone on the data team comfortable with SQL can safely contribute to production-grade data pipelines.
dbt Cloud
dbt Cloud offers the fastest, most reliable, and scalable way to deploy dbt. Allowing data teams to optimize their data transformation by developing, testing, scheduling, and investigating data models using a single, fully managed service through a web-based user interface (UI).
You can learn about plans and pricing on www.getdbt.com
Learn more about dbt Cloud features and try one of the dbt Cloud quickstarts.
dbt Core
dbt Core is an open-source tool that enables data practitioners to transform data and is suitable for users who prefer to manually set up dbt and locally maintain it. You can install dbt Core through the command line. Learn more with the quickstart for dbt Core.
For more information on dbt Cloud and dbt Core, refer to How dbt Cloud compares with dbt Core.
- Avoid writing boilerplate DML and DDL by managing transactions, dropping tables, and managing schema changes. Write business logic with just a SQL
selectstatement, or a Python DataFrame, that returns the dataset you need, and dbt takes care of materialization. - Build up reusable, or modular, data models that can be referenced in subsequent work instead of starting at the raw data with every analysis.
- Dramatically reduce the time your queries take to run: Leverage metadata to find long-running models that you want to optimize and use incremental models which dbt makes easy to configure and use.
- Write DRYer code by leveraging macros, hooks, and package management.
- No longer copy and paste SQL, which can lead to errors when logic changes. Instead, build reusable data models that get pulled into subsequent models and analysis. Change a model once and that change will propagate to all its dependencies.
- Publish the canonical version of a particular data model, encapsulating all complex business logic. All analysis on top of this model will incorporate the same business logic without needing to reimplement it.
- Use mature source control processes like branching, pull requests, and code reviews.
- Write data quality tests quickly and easily on the underlying data. Many analytic errors are caused by edge cases in the data: testing helps analysts find and handle those edge cases.
As a dbt user, your main focus will be on writing models (select queries) that reflect core business logic – there’s no need to write boilerplate code to create tables and views, or to define the order of execution of your models. Instead, dbt handles turning these models into objects in your warehouse for you.
| Feature | Description |
|---|---|
| Handle boilerplate code to materialize queries as relations | For each model you create, you can easily configure a materialization. A materialization represents a build strategy for your select query – the code behind a materialization is robust, boilerplate SQL that wraps your select query in a statement to create a new, or update an existing, relation. Read more about Materializations. |
| Use a code compiler | SQL files can contain Jinja, a lightweight templating language. Using Jinja in SQL provides a way to use control structures in your queries. For example, if statements and for loops. It also enables repeated SQL to be shared through macros. Read more about Macros. |
| Determine the order of model execution | Often, when transforming data, it makes sense to do so in a staged approach. dbt provides a mechanism to implement transformations in stages through the ref function. Rather than selecting from existing tables and views in your warehouse, you can select from another model. |
| Document your dbt project | In dbt Cloud, you can auto-generate the documentation when your dbt project runs. dbt provides a mechanism to write, version-control, and share documentation for your dbt models. You can write descriptions (in plain text or markdown) for each model and field. Read more about the Documentation. |
| Test your models | Tests provide a way to improve the integrity of the SQL in each model by making assertions about the results generated by a model. Build, test, and run your project with a button click or by using the Cloud IDE command bar. Read more about writing tests for your models Testing |
| Manage packages | dbt ships with a package manager, which allows analysts to use and publish both public and private repositories of dbt code which can then be referenced by others. Read more about Package Management. |
| Load seed files | Often in analytics, raw values need to be mapped to a more readable value (for example, converting a country-code to a country name) or enriched with static or infrequently changing data. These data sources, known as seed files, can be saved as a CSV file in your project and loaded into your data warehouse using the seed command. Read more about Seeds. |
| Snapshot data | Often, records in a data source are mutable, in that they change over time. This can be difficult to handle in analytics if you want to reconstruct historic values. dbt provides a mechanism to snapshot raw data for a point in time, through use of snapshots. |