Developing OpenType Fonts for Khmer Script - Typography (original) (raw)
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Developing OpenType Fonts for Khmer Script
- Article
- 06/24/2022
In this article
This document presents information that will help font developers create or support OpenType fonts for the Khmer script languages covered by the Unicode Standard.
Introduction
In this specification, font developers will learn how to encode complex script features in their fonts, choose character sets, organize font information, and use existing tools to produce Khmer fonts. Registered features of the Khmer script are defined and illustrated, encodings are listed, and templates are included for compiling Khmer layout tables for OpenType fonts.
This document also presents information about the Khmer OpenType shaping engine of Uniscribe, the Windows component responsible for text layout.
In addition to being a primer and specification for the creation and support of Khmer fonts, this document is intended to more broadly illustrate the OpenType Layout architecture, feature schemes, and operating system support for shaping and positioning text.
Glossary
The following terms are useful for understanding the layout features and script rules discussed in this document.
Base Glyph – The one and only consonant, independent vowel, or number in the syllable that is written in its “full” (nominal) form. In Khmer, the first consonant or independent vowel of the syllable usually forms the base glyph. Layout operations are defined in terms of a base glyph, not a base character, since the results of the shaping process are a series of glyphs.
U+17D2 (COENG) – Code point before a consonant or independent vowel, which causes the formation of the subscript form of that letter. The COENG is always tied to the letter following it and is always handled as a unit with the following letter. NOTE: The shape of the COENG is arbitrary and is not rendered.
Consonant - Represents a single consonant sound. Consonants may exist in different contextual forms, and have an inherent vowel (usually, the long vowel “A”). Therefore, those illustrated in the examples to follow are named, for example, “KA” and “TA,” rather than just “K” or “T.”
Consonant Shifters – Used to shift the base consonant between registers (U+17C9, U+17CA).
Khmer Syllable – Effective orthographic “unit” of Khmer writing systems, consisting of a consonant and a vowel core, and optionally with one or two subscripts inserted between the two, and followed by signs. Syllables are composed of consonant letters, independent vowels, dependant or inherent vowels, and signs. In a text sequence, these characters are stored in phonetic order, although they may not be represented in phonetic order when displayed. Once a syllable is shaped, it is indivisible (but deletions of its characters may take place starting from the end). The cursor cannot be positioned within the syllable. Transformations discussed in this document do not cross syllable boundaries.
ROBAT (U+17CC) – Above-base or combining form of the letter RO, used in most scripts if RO is the first consonant in the syllable and is not the base consonant. It is ordered as one would write the text. For example, the word KARMA would be encoded as KA + MA + ROBAT.
Subscript Glyph – Subscript form of a consonant or independent vowel. An example of this is COENG KA. Subscripts are formed by a combination of COENG glyph, followed by a consonant or independent vowel. COENG does not have a conventional visual form in Khmer, as it is a control character to cause the formation of a subscript. An implementer of Khmer should never allow the entry of the COENG character by itself.
There are three types of subscript glyphs: Type 1 is positioned below the base glyph; Type 2 is the form (currently only COENG RO) that has an “arm” for spacing the left side of the base glyph; and Type 3 is the subscript form with an “arm” for spacing the right side of the base glyph.
There may be up to two subscript glyphs per base glyph, which may be of different subscript types. The ordering of subscripts must be in the order of: Type 1 (may be doubled), Type 2, and then Type 3 (may be doubled). Exceptions to this ordering are invalid, and will cause a new cluster to be formed that has the dotted circle glyph as the base glyph.
Vowel - A Khmer syllable is permitted to have only one vowel. In the notation, four different types are indicated, based on the position when rendered. There are five vowels (U+17BE, U+17BF, U+17C0, U+17C4, U+17C5), composed of two glyph pieces, although these two pieces are treated as one vowel in the backing store. The shaping engine will take care of pre-pending the syllable, with the glyph piece shaped like U+17C1.
Notation
The following notation is used in this document to illustrate layout operations:
Cons – Consonant character
IndV – Independent vowel character
COENG – The COENG code
PreV – Vowel that is positioned before the base glyph; it is not possible to have both a PreV and a PstV in the same syllable; vowels that have both prebase and postbase glyphs (U+17BF, U+17C0, U+17C4, U+17C5) are classified as PstV; the shaping engine will take care of prepending the U+17C1 glyph to the syllable
BlwV – Vowel that is positioned below the base glyph; a base glyph cannot have both a BlwV and an AbvV (the combination U+17BB + U+17C6 is of a vowel and a sign)
RegShift – Triisap or Muusikatoan character that is normally situated immediately above the Base glyph, but often changes to an ambiguous glyph at the extreme below position when there is an above-base vowel/vowel-part glyph
AbvV - Vowel that is positioned above the base glyph; a base glyph cannot have both a BlwV and an AbvV; note as above: the combination U+17BB + U+17C6 is of a vowel and a sign; the vowel with pre and above glyphs (U+17BE) is considered an AbvV; in this case, the shaping engine prepends the U+17C1 to the beginning of the syllable
AbvS – A sign character that is positioned above the base glyph
Robat – The Robat glyph
PstV – Vowel that is positioned after the base glyph; in some cases, the PstV has a part (U+17C1) that is prepended to the the syllable; therefore, a PreV and a PstV cannot exist in the same syllable
PstS – Sign character that is positioned after the base glyph
Nikahit – Sign which on its own or in combination with vowel characters creates a constructed vowel; it adds an ‘m’ or ‘n’ sound; this is classified as an AbvS
Reahmuk – Sign which on its own or in combination with vowel characters creates a constructed vowel; it adds an ‘h’ aspiration; this is classified as a PstS
{ } – Indicates 0 to 2 occurrences
[ ] – Indicates 0 or 1 occurrence
| – Exclusive OR
+ - Cumulative AND
Shaping Engine
- Analyze syllables and reorder characters
- Shape glyphs with OTLS
- Position glyphs with OTLS
- Base elements
- Invalid combining marks
The Uniscribe Khmer shaping engine processes text in stages. The stages are:
- Analyze syllables and reorder characters
- Shape (substitute) glyphs with OTLS (OpenType Library Services)
- Position glyphs with OTLS
The descriptions which follow will help font developers understand the rationale for the Khmerf feature encoding model, and help application developers better understand how layout clients can divide responsibilities with operating system functions.
Analyze syllables and reorder characters
All Khmer syllables begin with a consonant, independent vowel, or number. The following should be considered as canonical ordering for Khmer Unicode input. The ordering is in the same order that the Khmer syllable is formed and produces the correct sort/search order. Any device using Khmer Unicode should use this input sequence order to correctly handle Khmer text. One complex and two simple constructs are elaborated below.
Canonical ordering
It is important for the user inputting the text to remember that although it is possible to input some of the formed sequences by using individual glyphs, the Unicode characters that are input must be in a correctly defined and consistent order for sorting and searching mechanisms to work. For example, a person might try to enter a syllable with U+17C1 and U+17B6. A user might think that they look the same as inserting U+17C4. However, the meaning is very different. Any devices, like text-to-speech, that require correct characters for correct output would not consider these the same. More importantly, the user's attempt to incorrectly use U+17C1 and U+17B6 in the same syllable would result in breaking the rule of having only one vowel character per syllable.
Syllables beginning with consonants
Consonant based syllables are formed in the following order:
Cons + {COENG + (Cons | IndV)} + [PreV | BlwV] + [RegShift] + [AbvV] + {AbvS} + [PstV] + [PstS]
RegShift case
The RegShift glyphs automatically take positioning based on the context of the vowel above. Normally, the RegShift will be rendered immediately above the base glyph. In the event that the RegShift character precedes an AbvV, the RegShift is normally rendered as a vertical stroke at the lowest extreme of the syllable. In some cases it is necessary to force the RegShift to be placed above the base glyph. In this case a ZERO WIDTH NON-JOINER (ZWNJ) is inserted between the RegShift and the AbvV to prevent the context rule of the shaping engine from being applied.
U+179F U+17CA U+17B8 (for a child or animal 'to eat') is an example where the below base form of TRIISAP is used.
U+1784 17C9 U+17B7 U+1780 U+1784 U+17C9 U+1780 U+17CB ('sulky') is an example where the first MUUSIKATOAN is in a below base form and the second in an above base form.
U+17A2 U+200C(ZWNJ) U+17CA U+17B7 U+17A2 U+17BB U+17CA U+17C7 is an interesting case where the first TRIISAP needs to be escaped, but the second does not (as there is a below base vowel)
An overview of the logic used when analyzing and reordering characters in the shaping engine looks something like the following;
- Khmer shaping assumes that a syllable will begin with a Cons, IndV, or Number.
- When a COENG + (Cons | IndV) combination are found (and subscript count is less than two) the character combination is handled according to the subscript type of the character following the COENG.
- Subscript Type 1 - The COENG + (Cons | IndV) characters are assigned to have the 'blwf' OpenType feature applied to them.
- Subscript Type 2 - The COENG + RO characters are reordered to immediately before the base glyph. Then the COENG + RO characters are assigned to have the 'pref' OpenType feature applied to them.
- Subscript Type 3 - The COENG + Cons characters are assigned to have the 'pstf' OpenType feature applied to them.
- When a RegShift character is followed by an AbvV character, the RegShift character is assigned have the 'blwf' OpenType feature applied to change the shape to the below base form of the RegShift glyph (like U+17BB).
- When a AbvV character with KHF_ABVSPLIT assigned is found, the pre-base vowel part (U+17C1) is prepended to the beginning of the cluster. The AbvV character is then assigned to have the 'abvf' OpenType feature applied so the glyph form is changed to the shape of the above vowel ( like U+17B8).
- When a PstV character with KHF_PSTSPLIT assigned is found, the pre-base vowel part (U+17C1) is prepended to the beginning of the cluster. The PstV character is then assigned to have the 'pstf' OpenType feature applied so the glyph form is changed to the shape of the second half.
Shape Glyphs with OTLS
The first step Uniscribe takes in shaping the reordered character string is to apply the assigned layout features to the glyph string during the shaping process. These features, described and illustrated later in this document, are always applied in the order in which they are listed below.
Next, Uniscribe calls OTLS to apply the features. All OTL processing is divided into a set of predefined features (described and illustrated in the Features section). Each feature is applied, one by one, to the appropriate glyphs in the syllable and OTLS processes them. Uniscribe makes as many calls to the OTL Services as there are features. This ensures that the features are executed in the desired order.
The steps of the shaping process are outlined below.
Shaping features:
- Language forms
- Apply feature 'pref' to get pre based ligatures
- Apply feature 'blwf' to get below based ligatures or below base RegShift.
- Apply feature 'abvf' to Ro and the following COENG to get the Robat glyph, or to the AbvV that has KHF_ABVSPLIT to get the above glyph.
- Apply feature 'pstf' to get post base ligatures.
- Conjuncts and Typographical forms
- Apply feature 'pres' to get pre-base substitutions on the COENG RO glyph when there is a subscript type 1 on the syllable.
- Apply feature 'blws' to get below base substitutions that might be required for typographical correctness.
- Apply feature 'abvs' to get above base substitutions that might be required for typographical correctness.
- Apply feature 'psts' to get post base substations that might be required for typographical correctness. For example, a subscript type 3 glyph that needs to have a lower descent when a subscript type 1 glyph is on the syllable.
- Apply feature 'clig' to form ligatures that are desired for typographical correctness. For example, a subscript type 3 glyph that is followed by the OO glyph (U+17C4.secondhalf).
Position Glyphs with OTLS
Uniscribe next applies features concerned with positioning, calling functions of OTLS to position glyphs.
Positioning features:
- Distances
- Apply feature 'dist' to adjust other distances, e.g. to provide kerning between post- and pre-base elements and the base glyph.
- Below-base marks
- Apply feature 'blwm' to position below-base forms, vowel modifiers and or stress/tone marks on base glyph.
- Above-base marks
- Apply feature 'abvm' to position above-base forms, vowel modifiers and or stress/tone marks on base glyph.
- Mark to mark
- Apply feature 'mkmk' to position AbvS glyphs above AbvV glyphs or BlwV glyphs below subscript glyphs.
Base elements
Commonly, a feature is required for dealing with the base glyph and one of the post-base, pre-base or above-base elements. Since it is not possible to reorder ALL of these elements next to the base glyph, we need to skip over the elements "in the middle" (reordering-wise).
The solution is to assign different mark attachment classes to different elements of the syllable and positional forms, and in any given lookup work with one mark type only. For example, in above-base substitutions we need only consider above-base elements most of the time.
Generally, it is good practice to mark as "mark" glyphs that are denoted as marks in the Unicode standard as well as below-base/above-base forms of consonants. Then, different attachment classes should be assigned to different marks depending on their position with respect to the base.
Invalid Combining Marks
Combining marks and signs that appear in text not in conjunction with a valid consonant base are considered invalid. Uniscribe displays these marks using the fallback rendering mechanism defined in the Unicode standard (section 5.12, 'Rendering Non-Spacing Marks' of Unicode Standard 3.1), i.e. positioned on a dotted circle.
Please note that to render a sign standalone (in apparent isolation from any base) one should apply it on a space (see section 2.5 'Combining Marks' of Unicode Standard 3.1).
For the fallback mechanism to work properly, a Khmer OTL font should contain a glyph for the dotted circle (U+25CC). In case this glyph is missing form the font, the invalid signs will be displayed on the missing glyph shape (white box).
In addition to the "dotted circle" other Unicode code points that are recommended for inclusion in any Khmer font are the ZWJ (zero width joiner; U+200D), the ZWNJ (zero width non-joiner; U+200C) and the ZWSP (zero width space; U+200B) which can be used for word boundaries.
If an invalid combination is found; more than one vowel character in a syllable, more than two subscripts on the same base character, or the incorrect ordering of subscripts, a new cluster will be formed that has the dotted circle as the base glyph. The shaping engine for non-OpenType fonts will cause invalid mark combinations to overstrike. This is the problem that inserting the dotted circle for the invalid base solves. It should also be noted that the dotted circle is not inserted into the application's backing store. This is a run-time insertion into the glyph array that is returned from the ScriptShape function.
Following is a chart of character classes for the Khmer script.
| Class | Subclass | Member Characters |
|---|---|---|
| Consonant | SubscriptType1 | U+1780-U+1782, U+1784-U+1787, U+1789-U+178C, U+178E-U+1793, U+1795-U+1798, U+179B-U+179D, U+17A0, U+17A2 |
| Consonant | SubscriptType2 | U+179A |
| Consonant | SubscriptType2 | U+1783, U+1788, U+178D, U+1794, U+1799, U+179E-U+179F, U+17A1 |
| Independent Vowel | (No Subscript) | U+17B4-U+17B5 |
| SubscriptType1 | U+17A3-U+17B3 | |
| Coeng | U+17D2 | |
| Dependent Vowel | Above-base | U+17B7-U+17BA, U+17BE (split) |
| Below-base | U+17BB-U+17BD | |
| Pre-base | U+17C1-U+17C3 | |
| Post-base | U+17B6, U+17BF-U+17C0 (split), U+17C4-U+17C5 (split) | |
| Register Shifter | U+17C9-U+17CA | |
| Robat | U+17CC | |
| Sign | Above-base | U+17C6, U+17CB, U+17CD-U+17D1, U+17DD |
| Post-base | U+17C7-U+17C8 | |
| Above numbers | U+17D3 | |
| Punctuation | U+17D4-U+17DA, U+17DC, U+19E0-U+19FF | |
| Currency | U+17DB | |
| Number | U+17E0-U+17E9, U+17F0-U+17F9 | |
| Reserved | U+17DE-U+17DF, U+17EA-U+17EF, U+17FA-U+17FF |
Features
The features listed below have been defined to create the basic forms for the languages that are supported on Khmer systems. Regardless of the model an application chooses for supporting layout of complex scripts, Uniscribe requires a fixed order for executing features within a run of text to consistently obtain the proper basic form. This is achieved by calling features one-by-one in the standard order listed below.
The order of the lookups within each feature is also very important. For more information on lookups and defining features in OpenType fonts, see the Encoding section of the OpenType Font Development document.
The standard order for applying Khmer features encoded in OpenType fonts:
| Feature | Feature function | Layout operation | Required |
|---|---|---|---|
| Language based forms: | |||
| pref | Pre-base forms | GSUB | X |
| blwf | Below-base forms | GSUB | X |
| abvf | Above-base forms | GSUB | X |
| pstf | Post-base forms | GSUB | X |
| Conjuncts & typographical forms: | |||
| pres | Pre-base substitution | GSUB | X |
| blws | Below-base substitution | GSUB | X |
| abvs | Above-base substitution | GSUB | X |
| psts | Post-base substitution | GSUB | X |
| clig | Contextual ligature substitution | GSUB | X |
| Positioning features: | |||
| dist | Distances | GPOS | |
| blwm | Below-base mark positioning | GPOS | |
| abvm | Above-base mark positioning | GPOS | |
| mkmk | Mark to mark positioning | GPOS | |
| [GSUB = glyph substitution, GPOS = glyph positioning] |
Feature examples
Pre-base form
Feature Tag: "pref"
The 'pref' feature is used to substitute the pre-base form of a consonant in conjuncts. (GSUB lookup type 4).
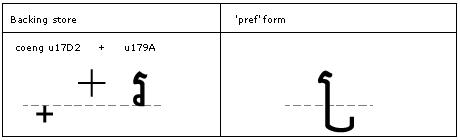
Example: the COENG typed before a consonant will substitute the subscript form.
Below-base form
Feature Tag: "blwf"
The 'blwf' feature is used to substitute the below-base form of a consonant in conjuncts or the below-base RegShift. (GSUB lookup type 4).
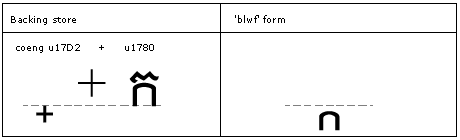
Example: the below-base form of the letter Ka is formed when it is preceded by COENG.
Above-base form
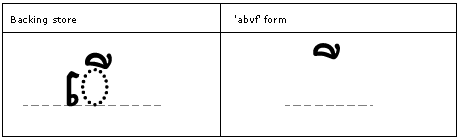
Feature Tag: "abvf"
The 'abvf' feature is applied to the glyph to substitute the Unicode defined shape to the portion of the glyph that is located above the base glyph (GSUB lookup type 1). This is possible because the piece of the letter which is displayed before the letter has been inserted into the glyph store in front of the base glyph by the Uniscribe engine.
Post-base form
Feature Tag: "pstf"
The 'pstf' feature is used to substitute the post-base form with a post-base ligature. (GSUB lookup type 4).
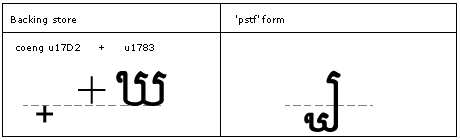
Conjuncts and typographical forms
Feature Tags: "pres", "blws", "abvs", "psts"
All previous features have dealt with language features only, dedicated to forming glyph shapes dictated by the languages. The remaining shaping features cover optional features. Although it is hard to imagine a Khmer font without any consonant conjuncts encoded within it, almost none are, strictly speaking, required. In fact, different fonts may contain different subsets. Thus the range of features covered here spans from those that will exist in every font to rare typographical ornaments. It is important to stress once more however that all features discussed here operate only within one orthographic syllable.
Since the language features do not limit typographical processing here, Uniscribe passes the entire syllable to the OTL Services library. Uniscribe does not strictly specify the format of lookup tables to use or their inputs, allowing for context-dependent processing of any of the conjuncts and forms below.
OTL Services library processes the syllable "left to right", executing lookups in the order they are specified in the font. First, pre-base substitutions will be handled, then below-base, above-base and post-base ones.
Thus a font developer should first take care of all ligatures to the left of the base glyph and then work your way to the right, substituting below-bases, above-bases and then finally post-base elements. The lookups in the font should be ordered in the same way.
With every new element and feature, the following operations should be considered, as appropriate, in this order:
- Ligatures with the base glyph
- Ligatures with preceding (in the canonical syllable form below) elements, and
- Contextual forms of the element
At every feature step, one should take into account all ligatures and forms that were produced by previous steps.
Pre-base substitutions
Feature Tag: "pres"
The 'pres' feature is used to produce the pre-base form of conjuncts.
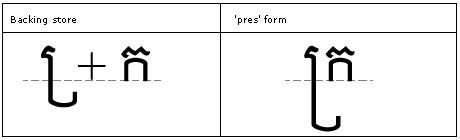
Below-base substitutions
Feature Tag: "blws"
The 'blws' feature is used to produce the below-base substitutions that may be required for typographical correctness.
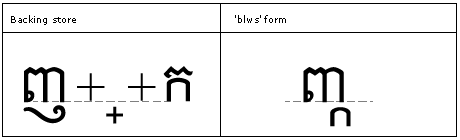
Above-base substitutions
Feature Tag: "abvs"
The 'abvs' feature is used to substitute the above-base substitutions that may be required for typographical correctness.
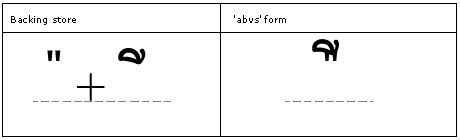
Post-base substitutions
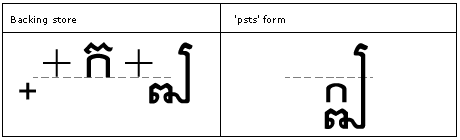
Feature Tag: "psts"
The 'psts' feature is used to substitute the post-base substitutions that may be required for typographical correctness. For example, a subscript type 3 glyph that needs to have a lower descent when a subscript type 1 glyph is on the syllable.
Contextual ligatures
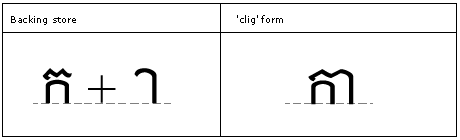
Feature Tag: "clig"
The 'clig' feature is used to map glyphs to their contextual ligated form. Unlike other ligature features, 'clig' specifies the context in which the ligature is recommended. This capability is important in some script designs and for swash ligatures. The 'clig' table maps sequences of glyphs to corresponding ligatures in a chained context (GSUB lookup type 8). Ligatures with more components must be stored ahead of those with fewer components in order to be found.
Distances
Feature Tag: "dist"
The 'dist' feature is used to provide a means to control distance between glyphs. The 'dist' table provides distances by which a glyph needs to move towards or away from another glyph (GPOS lookup type 2). This feature covers all other positioning lookups defining various distances between glyphs, such as kerning between pre- and post-base elements and the base glyph.
NOTE: The 'dist' feature is a theoretically possible item for which examples of usage are not currently available.
Below-base mark positioning
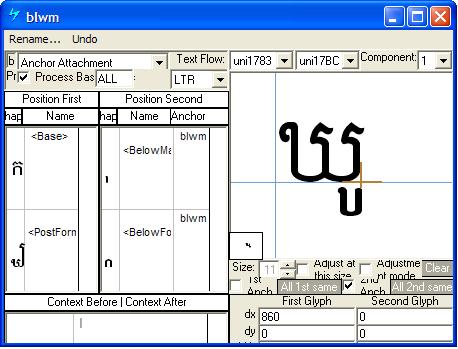
Feature Tag: "blwm"
The 'blwm' feature is used to position all below-base marks on base glyphs. The best method for encoding this feature in an OpenType font is to use a chaining context positioning lookup that triggers mark-to-base and mark-to-mark attachments for below-base marks. The 'blwm' table provides positioning information (x,y) to enable mark positioning (GPOS lookup type 4, 5).
positioning marks below base glyphs using Microsoft VOLT
Above-base mark positioning
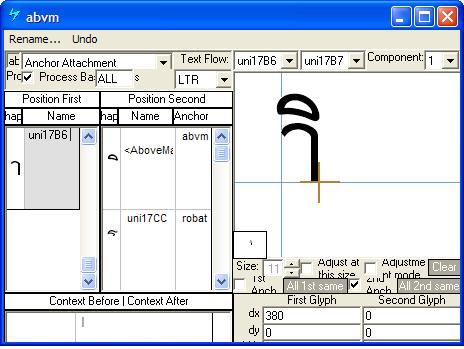
Feature Tag: "abvm"
The 'abvm' feature is used to position all above-base marks on base glyphs. The best method for encoding this feature in an OpenType font is to use a chaining context positioning lookup that triggers mark-to-base and mark-to-mark attachments for below-base marks. The 'abvm' table provides positioning information (x,y) to enable mark positioning (GPOS lookup type 4, 5).
positioning marks above base glyphs using Microsoft VOLT
Mark to mark positioning
Feature Tag: "mkmk"
The 'mkmk' feature positions mark glyphs in relation to another mark glyph. This feature may be implemented as a MarkToMark Attachment lookup (GPOS LookupType = 6).
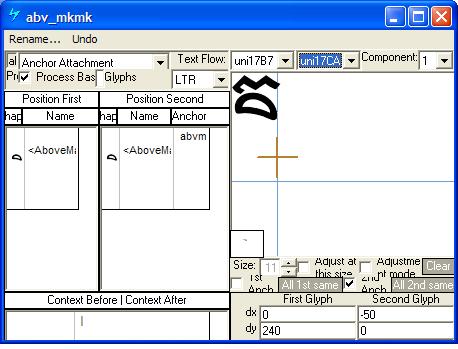
positioning mark to mark using Microsoft VOLT
Appendix
Features are encoded according to both a designated script and language system. The language system tag specifies a typographic convention associated with a language or linguistic subgroup
Currently, the Uniscribe engine only supports the "default" language for each script. However, font developers may want to build language specific features which are supported in other applications and will be supported in future Microsoft OpenType implementations.
- NOTE: It is strongly recommended to include the "dflt" language tag in all OpenType fonts because it defines the basic script handling for a font. The "dflt" language system is used as the default if no other language specific features are defined or if the application does not support that particular language. If the "dflt" tag is not present for the script being used, the font may not work in some applications.
The following tables list the registered tag names for scripts and language systems.
| Registered tags for the Khmer script | Registered tags for Khmer language systems | ||
|---|---|---|---|
| Script tag | Script | Language system tag | Language |
| "khmr" | Khmer | "dflt" | *default script handling |
| "KHM " | Khmer |
Note: both the script and language tags are case sensitive (script tags should be lowercase, language tags are all caps) and must contain four characters (ie. you must add a space to the three character language tags).
Collaborate with us on GitHub
The source for this content can be found on GitHub, where you can also create and review issues and pull requests. For more information, see our contributor guide.