Model Alignment by SteerLM Method — NVIDIA NeMo Framework User Guide (original) (raw)
Important
Before starting this tutorial, be sure to review the introduction for tips on setting up your NeMo-Aligner environment.
If you run into any problems, refer to NeMo’s Known Issues page. The page enumerates known issues and provides suggested workarounds where appropriate.
After completing this tutorial, refer to the evaluation documentation for tips on evaluating a trained model.
SteerLM is a novel approach developed by the NVIDIA NeMo Team, introduced as part of NVIDIA NeMo Alignment methods. It simplifies the customization of large language models (LLMs) and empowers users with dynamic control over model outputs by specifying desired attributes. Despite remarkable progress in natural language generation driven by LLMs like GPT-3, Megatron-Turing, Chinchilla, PaLM-2, Falcon, and Llama 2, these foundational models often fall short in delivering nuanced and user-aligned responses. The current approach for LLM improvement combines Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), but it comes with complexities and limited user control. SteerLM addresses these challenges and represents a significant advancement in the field, making it easier to tailor LLMs to specific needs and preferences. This document delves into how SteerLM operates and offers guidance on training a SteerLM model.
SteerLM#
SteerLM leverages a SFT method that empowers you to control responses during inference. It overcomes the limitations of prior alignment techniques, and consists of four key steps:
- Train an attribute prediction model on human-annotated datasets to evaluate response quality on any number of attributes like helpfulness, humor, and creativity.
- Annotate diverse datasets by predicting their attribute scores, using the model from Step 1 to enrich the diversity of data available to the model.
- Perform attribute-conditioned SFT by training the LLM to generate responses conditioned on specified combinations of attributes, like user-perceived quality and helpfulness.
- Bootstrap training through model sampling by generating diverse responses conditioned on maximum quality (Figure 4a), then fine-tuning on them to further improve alignment (Figure 4b).
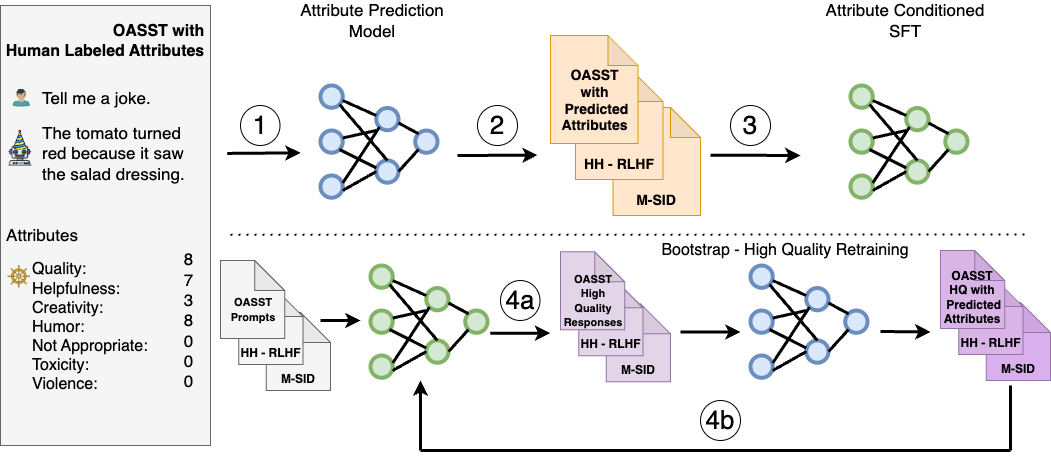
SteerLM simplifies alignment compared to RLHF. It supports user-steerable AI by enabling you to adjust attributes at inference time. This enables the developer to define preferences relevant to the application, unlike other techniques that require using predetermined preferences.
SteerLM vs RLHF#
RLHF and SteerLM are two methods aimed at aligning language models to human preferences. RLHF trains language models by providing positive or negative feedback on generated responses, reinforcing good behaviors. Specifically, the model is encouraged to generate more text similar to responses that receive positive feedback, and less like those with negative feedback. SteerLM takes a different approach to model alignment. Rather than solely reinforcing “good” behaviors, it categorizes the space of possible model responses using steering labels. At inference time, the model generates based on these categorical labels that steer its output. So while RLHF uses direct feedback on model generations, SteerLM aligns by mapping responses into labeled categories associated with human preferences. The two methods approach model alignment from different angles: RLHF reinforces desired model behaviors directly, while SteerLM steers generation based on categorical labels. Both aim to produce language model outputs that are better aligned with human values and preferences.
Train a SteerLM Model#
This section is a step-by-step tutorial that walks you through how to run a full SteerLM pipeline with a Llama2 70B LLM model.
Download the Llama 2 LLM Model#
- Download the Llama 2 70B LLM model from HF <https://huggingface.co/meta-llama/Llama-2-70b-hf> into the models folder.
- Convert the Llama 2 LLM into .nemo format:
mkdir -p /models/llama70b/
python /opt/NeMo/scripts/checkpoint_converters/convert_llama_hf_to_nemo.py --input_name_or_path /path/to/llama --output_path /models/llama70b/llama70b.nemo - Download and convert to .nemo format for the 13B model <https://huggingface.co/meta-llama/Llama-2-13b-hf>. This is needed for the Attribute Prediction Modeling step.
- Untar the .nemo file to obtain the tokenizer in NeMo format (only for the 70B model):
cd /models/llama70b
tar xvf llama70b.nemo .
rm llama70b.nemo
mv _tokenizer.model tokenizer.model
The prefix for the tokenizer would be different when extracted. Ensure that the correct tokenizer file is used when running the preceding command.
To follow the HelpSteer2 and HelpSteer2-Preference line of works, you need to use the LLama 3 70B and LLama 3.1 70B Instruct models, respectively.
You need to obtain access to them, download them, and then convert them in a similar manner.
Download and Preprocess Data for SteerLM Regression Reward Modeling#
- Download and convert both datasets into a common format:
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/preprocess_openassistant_data.py --output_directory=data/oasst
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/preprocess_helpsteer_data.py --output_directory=data/helpsteer - Merge the two datasets for the train and val subset, respectively:
cat data/oasst/train.jsonl data/helpsteer/train.jsonl | awk '{for(i=1;i<=4;i++) print}' > data/merge_train.jsonl
cat data/oasst/val.jsonl data/helpsteer/val.jsonl > data/merge_val.jsonl - Preprocess the data into regression reward model training format:
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py \
--input-file=data/merge_train.jsonl \
--output-file=data/merge_train_reg.jsonl
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py \
--input-file=data/merge_val.jsonl \
--output-file=data/merge_val_reg.jsonl
If you are interested in replicating Reward Modeling training in HelpSteer2, please follow the steps below instead.
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/preprocess_helpsteer2_data.py --output_directory=data/helpsteer2
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py
--input-file=data/helpsteer2/train.jsonl
--output-file=data/helpsteer2/train_reg.jsonl
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py
--input-file=data/helpsteer2/val.jsonl
--output-file=data/helpsteer2/val_reg.jsonl
cat data/helpsteer2/train_reg.jsonl data/helpsteer2/train_reg.jsonl > data/helpsteer2/train_reg_2_epoch.jsonl
If you’re interested in replicating Reward Modeling training in HelpSteer2-Preference, please follow the steps below instead.
for first stage of Reward Model training (i.e. SteerLM Regression)
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/preprocess_helpsteer2_data.py --output_directory=data/helpsteer2-only_helpfulness --only_helpfulness
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py
--input-file=data/helpsteer2-only_helpfulness/train.jsonl
--output-file=data/helpsteer2-only_helpfulness/train_reg.jsonl
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py
--input-file=data/helpsteer2-only_helpfulness/val.jsonl
--output-file=data/helpsteer2-only_helpfulness/val_reg.jsonl
cat data/helpsteer2-only_helpfulness/train_reg.jsonl data/helpsteer2-only_helpfulness/train_reg.jsonl > data/helpsteer2-only_helpfulness/train_reg_2_epoch.jsonl
for second stage of Reward Model training (i.e. Scaled Bradley Terry)
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/preprocess_helpsteer2_data.py --output_directory=data/helpsteer2-pref -pref
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py
--input-file=data/helpsteer2-pref/train.jsonl
--output-file=data/helpsteer2-pref/train_reg.jsonl
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py
--input-file=data/helpsteer2-pref/val.jsonl
--output-file=data/helpsteer2-pref/val_reg.jsonl
Train the Regression Reward Model on OASST+HelpSteer Data#
In this tutorial, you train the regression reward model for 800 steps.
python /opt/NeMo-Aligner/examples/nlp/gpt/train_reward_model.py
trainer.num_nodes=32
trainer.devices=8
++model.micro_batch_size=2
++model.global_batch_size=512
++model.data.data_impl=jsonl
pretrained_checkpoint.restore_from_path=/models/llama13b/llama13b.nemo
"model.data.data_prefix={train: ["data/merge_train_reg.jsonl"], validation: ["data/merge_val_reg.jsonl"], test: ["data/merge_val_reg.jsonl"]}"
exp_manager.explicit_log_dir=/results/reward_model_13b
trainer.rm.val_check_interval=10
exp_manager.create_wandb_logger=True
exp_manager.wandb_logger_kwargs.project=steerlm
exp_manager.wandb_logger_kwargs.name=rm_training
trainer.rm.save_interval=10
trainer.rm.max_steps=800
++model.tensor_model_parallel_size=4
++model.pipeline_model_parallel_size=1
++model.activations_checkpoint_granularity="selective"
model.optim.sched.constant_steps=0
model.reward_model_type="regression"
model.regression.num_attributes=9
If you’re interested in replicating Reward Modeling training in HelpSteer2, please follow the steps below instead.
python /opt/NeMo-Aligner/examples/nlp/gpt/train_reward_model.py
trainer.num_nodes=8
trainer.devices=8
++model.micro_batch_size=2
++model.global_batch_size=128
++model.data.data_impl=jsonl
pretrained_checkpoint.restore_from_path=/models/llama-3-70b.nemo
"model.data.data_prefix={train: ["data/helpsteer2/train_reg_2_epoch.jsonl"], validation: ["data/helpsteer2/val_reg.jsonl"], test: ["data/helpsteer2/val_reg.jsonl"]}"
exp_manager.explicit_log_dir=/results/reward_model_13b
trainer.rm.val_check_interval=10
exp_manager.create_wandb_logger=True
exp_manager.wandb_logger_kwargs.project=steerlm
exp_manager.wandb_logger_kwargs.name=rm_training
trainer.rm.save_interval=10
trainer.rm.max_steps=317
++model.tensor_model_parallel_size=8
++model.pipeline_model_parallel_size=2
++model.activations_checkpoint_method="uniform"
++model.activations_checkpoint_num_layers=1
++model.sequence_parallel=False
model.optim.sched.constant_steps=0
model.optim.sched.warmup_steps=10
model.reward_model_type="regression"
model.optim.lr=2e-6
model.optim.sched.min_lr=2e-6
model.regression.num_attributes=9
If you’re interested in replicating Reward Modeling training in HelpSteer2-Preference, please follow the steps below instead.
python /opt/NeMo-Aligner/examples/nlp/gpt/train_reward_model.py
trainer.num_nodes=8
trainer.devices=8
++model.micro_batch_size=2
++model.global_batch_size=128
++model.data.data_impl=jsonl
pretrained_checkpoint.restore_from_path=/models/llama-3.1-70b-instruct.nemo
"model.data.data_prefix={train: ["data/helpsteer2-only_helpfulness/train_reg_2_epoch.jsonl"], validation: ["data/helpsteer2-only_helpfulness/val_reg.jsonl"], test: ["data/helpsteer2-only_helpfulness/val_reg.jsonl"]}"
exp_manager.explicit_log_dir=/results/helpsteer2-only_helpfulness-llama-3.1-70b-instruct
trainer.rm.val_check_interval=10
exp_manager.create_wandb_logger=True
exp_manager.wandb_logger_kwargs.project=steerlm
exp_manager.wandb_logger_kwargs.name=rm_training
trainer.rm.save_interval=10
trainer.rm.max_steps=317
++model.tensor_model_parallel_size=8
++model.pipeline_model_parallel_size=2
++model.activations_checkpoint_method="uniform"
++model.activations_checkpoint_num_layers=1
++model.sequence_parallel=False
model.optim.sched.constant_steps=0
model.optim.sched.warmup_steps=10
model.reward_model_type="regression"
model.optim.lr=2e-6
model.optim.sched.min_lr=2e-6
model.regression.num_attributes=9
python /opt/NeMo-Aligner/examples/nlp/gpt/train_reward_model.py
trainer.num_nodes=4
trainer.devices=8
++model.micro_batch_size=2
++model.global_batch_size=128
++model.data.data_impl=jsonl
pretrained_checkpoint.restore_from_path=/results/helpsteer2-only_helpfulness-llama-3.1-70b-instruct/checkpoints/megatron_gpt.nemo
"model.data.data_prefix={train: ["data/helpsteer2-pref/train_reg.jsonl"], validation: ["data/helpsteer2-pref/val_reg.jsonl"], test: ["data/helpsteer2-pref/val_reg.jsonl"]}"
exp_manager.explicit_log_dir=/results/helpsteer2-only_helpfulness-llama-3.1-70b-instruct-then-scaled-bt
trainer.rm.val_check_interval=10
exp_manager.create_wandb_logger=True
exp_manager.wandb_logger_kwargs.project=steerlm
exp_manager.wandb_logger_kwargs.name=rm_training
trainer.rm.save_interval=10
trainer.rm.max_steps=105
++model.tensor_model_parallel_size=8
++model.pipeline_model_parallel_size=4
++model.activations_checkpoint_method="uniform"
++model.activations_checkpoint_num_layers=1
++model.sequence_parallel=False
model.optim.sched.constant_steps=0
model.optim.sched.warmup_steps=10
model.reward_model_type="regression"
trainer.rm.train_random_sampler=False
model.regression.loss_func=scaled_bt
model.regression.load_rm_head_weights=True
model.optim.lr=1e-6
model.optim.sched.min_lr=1e-6
model.regression.num_attributes=9
Generate Annotations#
- To generate annotations, run the following command in the background to launch an inference server:
python /opt/NeMo-Aligner/examples/nlp/gpt/serve_reward_model.py \
rm_model_file=/results/reward_model_13b/checkpoints/megatron_gpt.nemo \
trainer.num_nodes=1 \
trainer.devices=8 \
++model.tensor_model_parallel_size=4 \
++model.pipeline_model_parallel_size=1 \
inference.micro_batch_size=2 \
inference.port=1424 - Execute the following code:
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/attribute_annotate.py \
--input-file=data/oasst/train.jsonl \
--output-file=data/oasst/train_labeled.jsonl \
--port=1424
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/attribute_annotate.py \
--input-file=data/oasst/val.jsonl \
--output-file=data/oasst/val_labeled.jsonl \
--port=1424
cat data/oasst/train_labeled.jsonl data/oasst/train_labeled.jsonl > data/oasst/train_labeled_2ep.jsonl
Train the Attribute-Conditioned SFT Model#
For the purposes of this tutorial, the Attribute-Conditioned SFT model is trained for 800 steps.
python examples/nlp/gpt/train_gpt_sft.py
trainer.num_nodes=32
trainer.devices=8
trainer.precision=bf16
trainer.sft.limit_val_batches=40
trainer.sft.max_epochs=1
trainer.sft.max_steps=800
trainer.sft.val_check_interval=800
trainer.sft.save_interval=800
model.megatron_amp_O2=True
model.restore_from_path=/models/llama70b
model.tensor_model_parallel_size=8
model.pipeline_model_parallel_size=2
model.optim.lr=6e-6
model.optim.name=distributed_fused_adam
model.optim.weight_decay=0.01
model.optim.sched.constant_steps=200
model.optim.sched.warmup_steps=1
model.optim.sched.min_lr=5e-6
model.answer_only_loss=True
model.activations_checkpoint_granularity=selective
model.activations_checkpoint_method=uniform
model.data.chat=True
model.data.num_workers=0
model.data.chat_prompt_tokens.system_turn_start='<extra_id_0>'
model.data.chat_prompt_tokens.turn_start='<extra_id_1>'
model.data.chat_prompt_tokens.label_start='<extra_id_2>'
model.data.train_ds.max_seq_length=4096
model.data.train_ds.micro_batch_size=1
model.data.train_ds.global_batch_size=128
model.data.train_ds.file_path=data/oasst/train_labeled_2ep.jsonl
model.data.train_ds.index_mapping_dir=/indexmap_dir
model.data.train_ds.add_eos=False
model.data.train_ds.hf_dataset=True
model.data.validation_ds.max_seq_length=4096
model.data.validation_ds.file_path=data/oasst/val_labeled.jsonl
model.data.validation_ds.micro_batch_size=1
model.data.validation_ds.global_batch_size=128
model.data.validation_ds.index_mapping_dir=/indexmap_dir
model.data.validation_ds.add_eos=False
model.data.validation_ds.hf_dataset=True
exp_manager.create_wandb_logger=True
exp_manager.wandb_logger_kwargs.project=steerlm
exp_manager.wandb_logger_kwargs.name=acsft_training
exp_manager.explicit_log_dir=/results/acsft_70b
exp_manager.checkpoint_callback_params.save_nemo_on_train_end=True
Run Inference#
- To start inference, run an inference server in the background using the following command:
python /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_eval.py \
gpt_model_file=/results/acsft_70b/checkpoints/megatron_gpt_sft.nemo \
pipeline_model_parallel_split_rank=0 \
server=True \
tensor_model_parallel_size=8 \
pipeline_model_parallel_size=1 \
trainer.precision=bf16 \
trainer.devices=8 \
trainer.num_nodes=1 \
web_server=False \
port=1427
Please wait for the server to be ready before proceeeding.
2. Create Python helper functions:
import requests
from collections import OrderedDict
def get_answer(question, max_tokens, values, eval_port=1427):
prompt = (
"System\nA chat between a curious user and an artificial intelligence assistant. "
"The assistant gives helpful, detailed, and polite answers to the user's questions.\n"
"User\n{question}\nAssistant\n{values}\n"
)
prompts = [prompt.format(question=question, values=values)]
data = {
"sentences": prompts,
"tokens_to_generate": max_tokens,
"top_k": 1,
"greedy": True,
"end_strings": [""],
}
url = f"http://localhost:{eval_port}/generate"
response = requests.put(url, json=data)
json_response = response.json()
response_sentence = json_response["sentences"][0][len(prompt):]
return response_sentence
def encode_labels(labels):
return ",".join(f"{key}:{value}" for key, value in labels.items())
3. Change the values below to steer the language model:
values = OrderedDict(
[
("quality", 4),
("toxicity", 0),
("humor", 0),
("creativity", 0),
("helpfulness", 4),
("correctness", 4),
("coherence", 4),
("complexity", 4),
("verbosity", 4),
]
)
values = encode_labels(values)
4. Ask questions and generate responses:
question = "Write a poem on NVIDIA in the style of Shakespeare"
print(get_answer(question, 512, values))
The response is shown below.
"""
In days of yore, in tech's great hall,
A company arose, NVIDIA its call.
With graphics cards, it did astound,
And gaming world with awe did abound.
But NVIDIA's reach far more than play,
Its GPUs now deep learning's sway.
With neural nets and data vast,
AI's rise, it did forecast.
From self-driving cars to medical scans,
Its tech now touches all life's plans.
With each new day, its impact grows,
In science, research, and industry's prose.
So here's to NVIDIA, whose name we praise,
For tech that captivates in countless ways.
With Shakespearean verse, we now impart,
Our thanks and admiration from the heart.
"""
Note
This tutorial covers only Phase 1-3: training the value model, generating annotations, and initial SteerLM model training. Phase 4 bootstraps the SteerLM model by sampling responses conditioned on high quality data, but is ignored for simplicity in this tutorial.
SteerLM: Novel Technique for Simple and Controllable Model Alignment#
SteerLM provides a novel technique for realizing a new generation of AI systems aligned with human preferences in a controllable manner. Its conceptual simplicity, performance gains, and customizability highlight the transformative possibilities of user-steerable AI. To learn more, please check out our paper SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF.