Getting Started — NVIDIA NIM for Large Language Models (LLMs) (original) (raw)
Prerequisites#
CPU#
- x86 processor with at least 8 cores (modern processor recommended)
- Memory requirements vary greatly depending on use case. For
trtllm_buildableprofiles, the memory requirements are approximately equal to the amount of memory used by GPUs.
GPU#
NVIDIA NIM for LLMs should, but is not guaranteed to, run on any NVIDIA GPU, as long as the GPU has sufficient memory, or on multiple, homogeneous NVIDIA GPUs with sufficient aggregate memory and CUDA compute capability > 7.0 (8.0 for bfloat16).
You can approximate the amount of required memory using the following guidelines. However, these guidelines do not apply to trtllm_buildable profiles:
- 5–10 GB for OS and other processes
- 16 GB for Docker (16 GB of shared memory is required by docker in multi-GPU, non-NVLink cases)
- # model parameters * 2 GB of memory
- Llama 8B: ~ 15 GB
- Llama 70B: ~ 131 GB
- Mistral 7B Instruct v0.3: ~ 14 GB
- Mixtral 8x7B Instruct v0.1: ~ 88 GB
These recommendations are a rough guideline and actual memory required can be lower or higher depending on hardware and NIM configuration.
Some model/GPU combinations, including vGPU, are optimized. Refer to Supported Models for further information.
Software#
- A Linux operating system (Ubuntu 20.04 or later recommended) that:
- Is supported by the NVIDIA Container toolkit
- Has
glibc>= 2.35 (see output ofld -v)
- NVIDIA Driver release 560 or later. However, if you are running on a data center GPU, such as an A100, you can use NVIDIA driver release 470.57 or later R470, 535.86 or later R535, or 550.54 or later R550.
- NVIDIA Docker >= 23.0.1
- CUDA 12.6.1
- NVIDIA AI Enterprise License: NVIDIA NIM for LLMs are available for self-hosting under the NVIDIA AI Enterprise License. Sign up for NVIDIA AI Enterprise license.
- NVIDIA GPU(s): NVIDIA NIM for LLMs runs on any NVIDIA GPU with sufficient GPU memory, but some model/GPU combinations are optimized. Homogeneous multi-GPUs systems with tensor parallelism enabled are also supported. See the Supported Models for more information.
- CUDA Drivers: Follow the installation guide. We recommend:
- Using a network repository as part of a package manager installation, skipping the CUDA toolkit installation as the libraries are available within the NIM container, then
- Installing the open kernels for a specific version:
- Install Docker
- Install the NVIDIA Container Toolkit
Note
After installing the toolkit, follow the instructions in the Configure Docker section in the NVIDIA Container Toolkit documentation.
To ensure that your setup is correct, run the following command (refer to the GPU Selection section for a note on using --gpus all):
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
This command should produce output similar to one of the following, where you can confirm CUDA driver version, and available GPUs.
+-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 550.54.14 Driver Version: 550.54.14 CUDA Version: 12.4 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA H100 80GB HBM3 On | 00000000:1B:00.0 Off | 0 | | N/A 36C P0 112W / 700W | 78489MiB / 81559MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
Important
This NIM does not support Multi-Instance GPU (MIG) mode.
Installing WSL2 for Windows#
Certain downloadable NIMs can be used on an RTX Windows system with Windows System for Linux (WSL). To enable WSL2, seeInstalling WSL2 for Windows.
Important
You should set NIM_RELAX_MEM_CONSTRAINTS=1 when you deploy this NIM on WSL2 due to high memory usage.
Launch NVIDIA NIM for LLMs#
You can download and run the NIM of your choice from either the API catalog or the NGC.
Option 1: From API Catalog#
Checkout this video, which illustrates the following steps.
Generate an API Key#
- Navigate to the API Catalog.
- Select a model.
- Select an Input option. The following example is of a model that offers a Docker option. Not all of the models offer this option, but all include a “Get API Key” link.
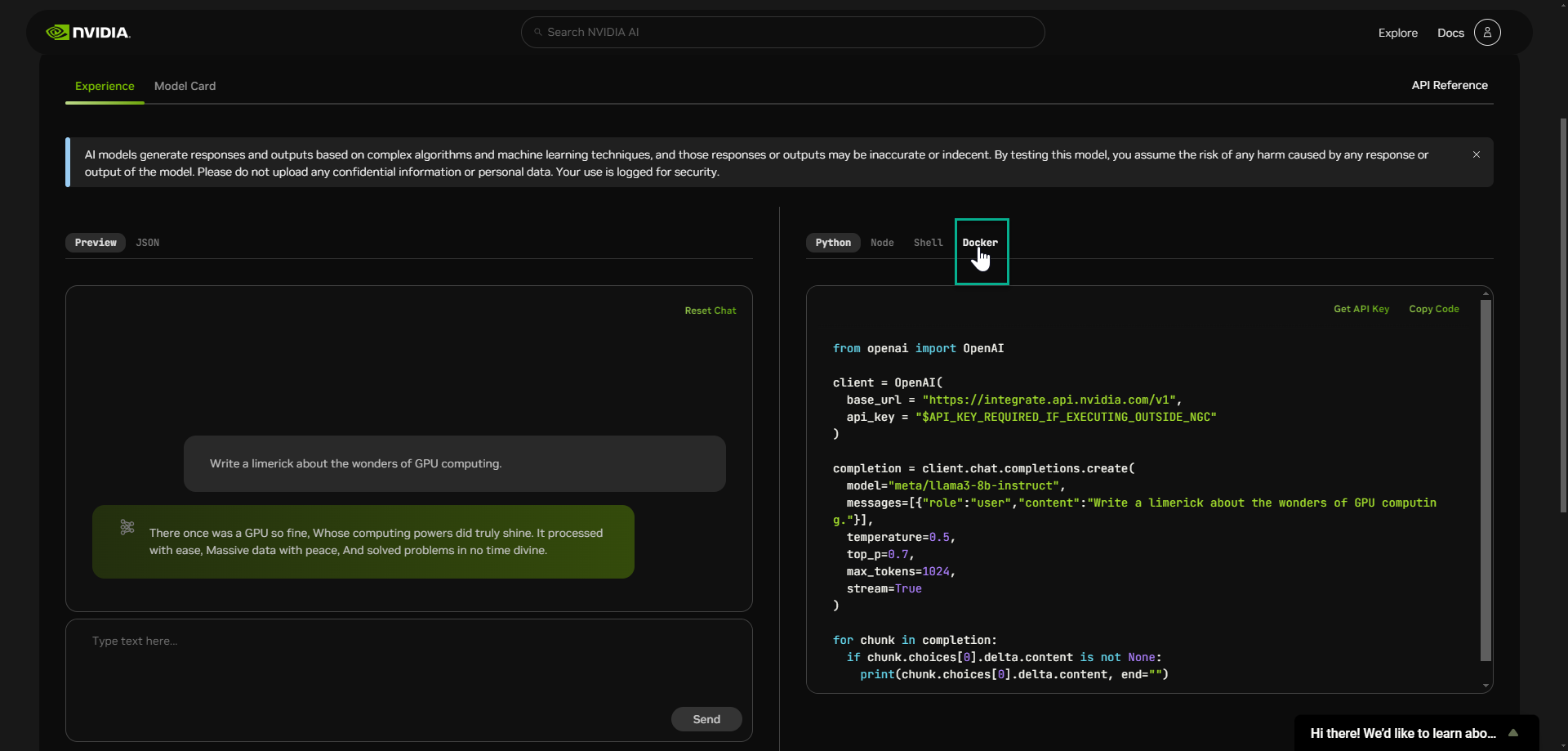
- Select “Get API Key” and login if prompted.
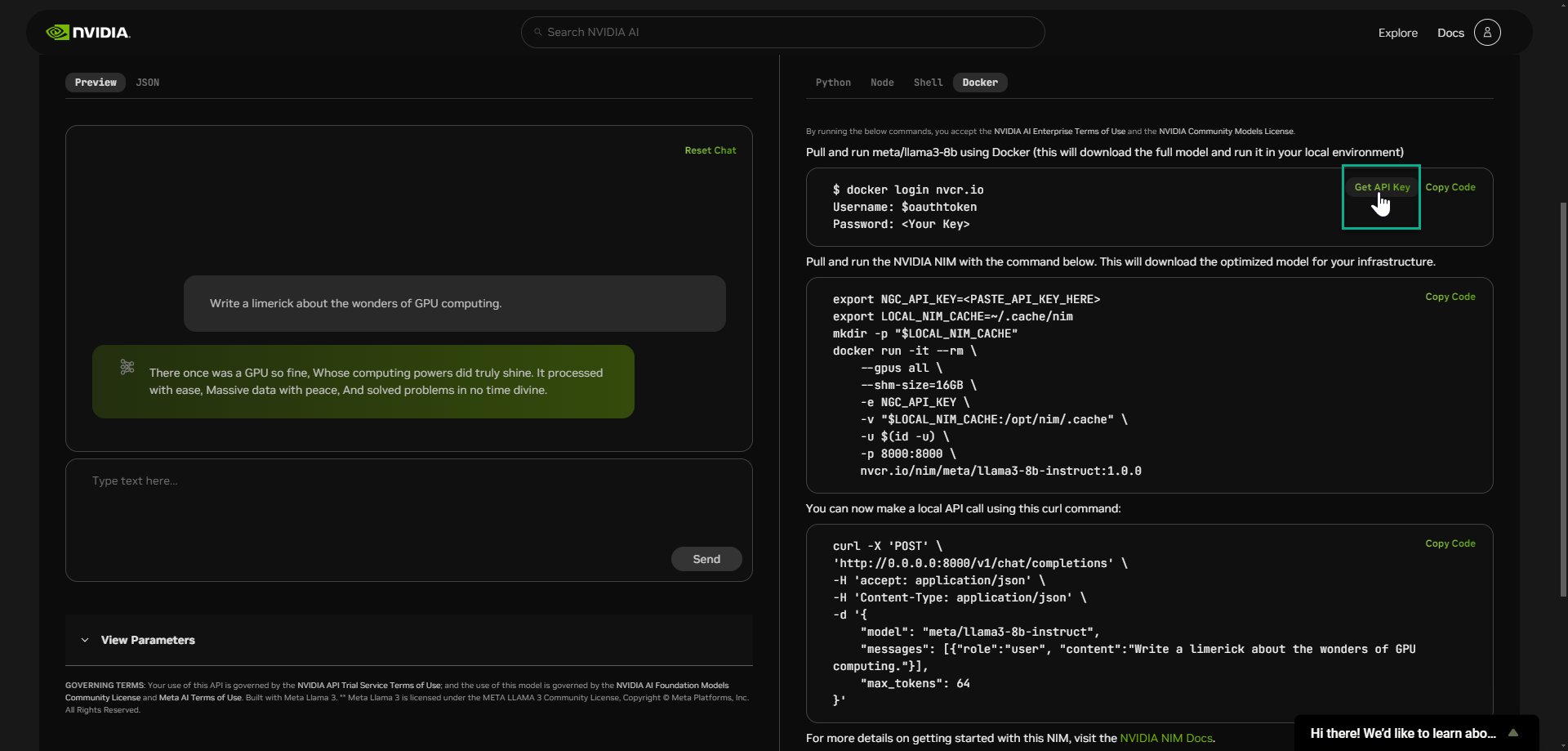
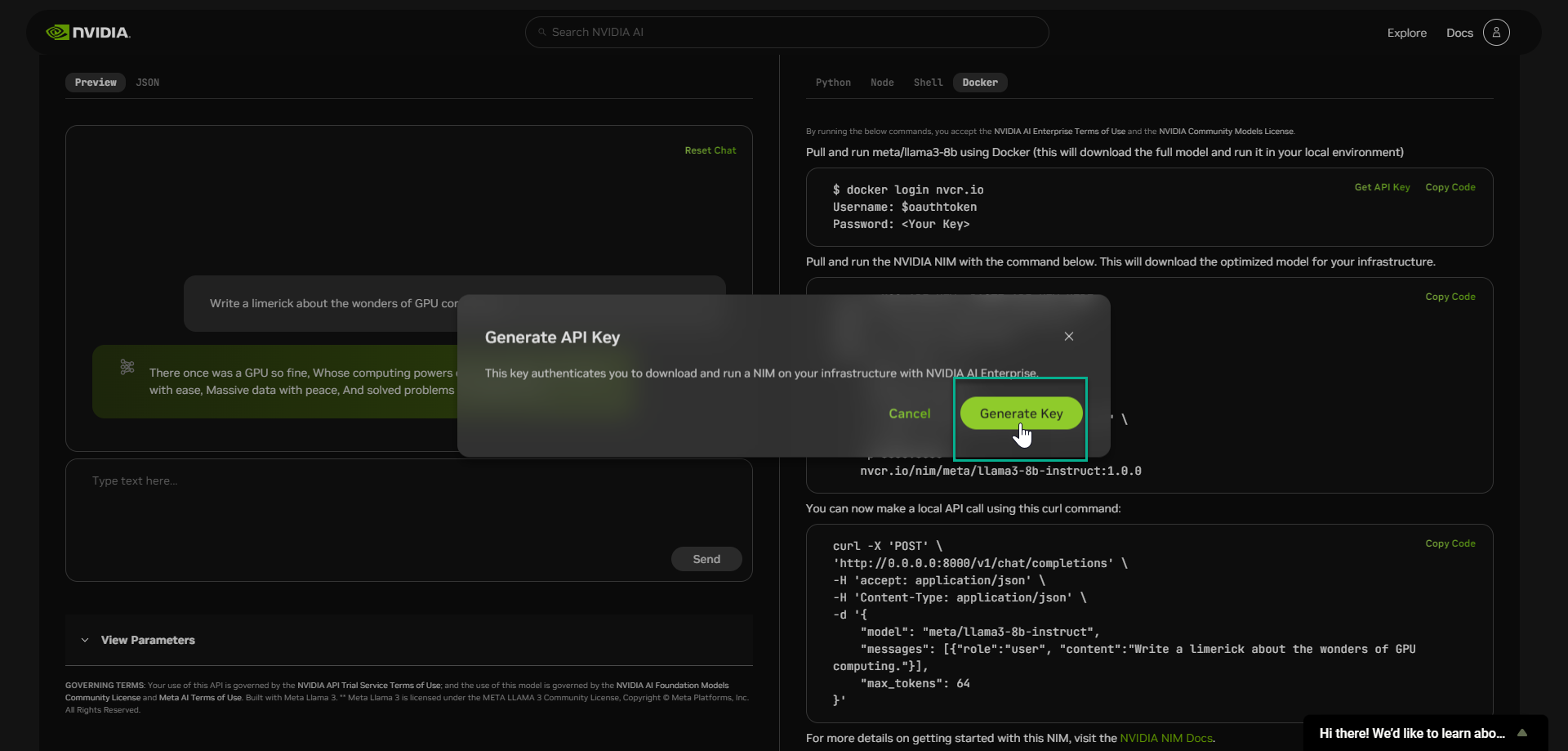
- Select “Generate Key”
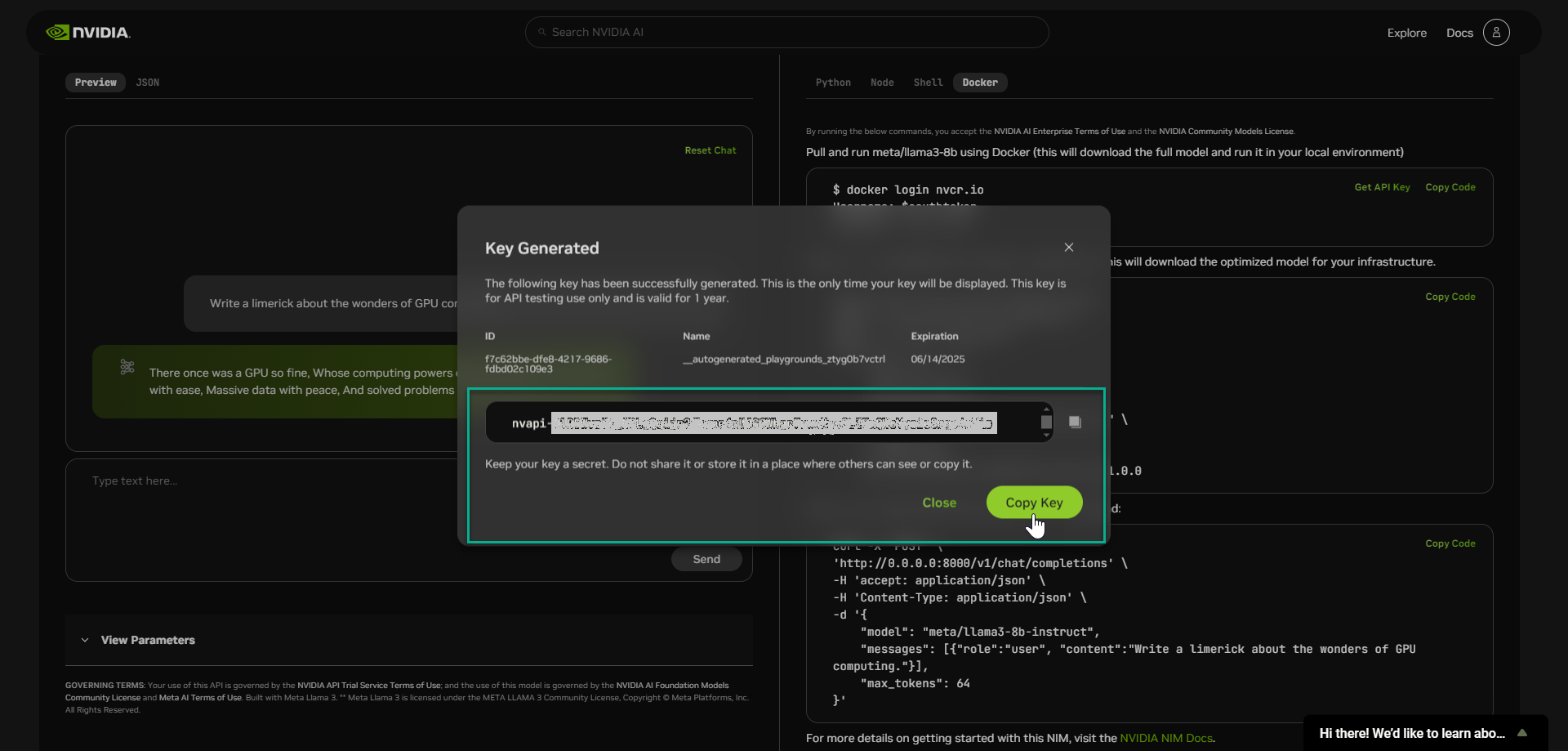
- Copy your key and store it in a secure place. Do not share it.
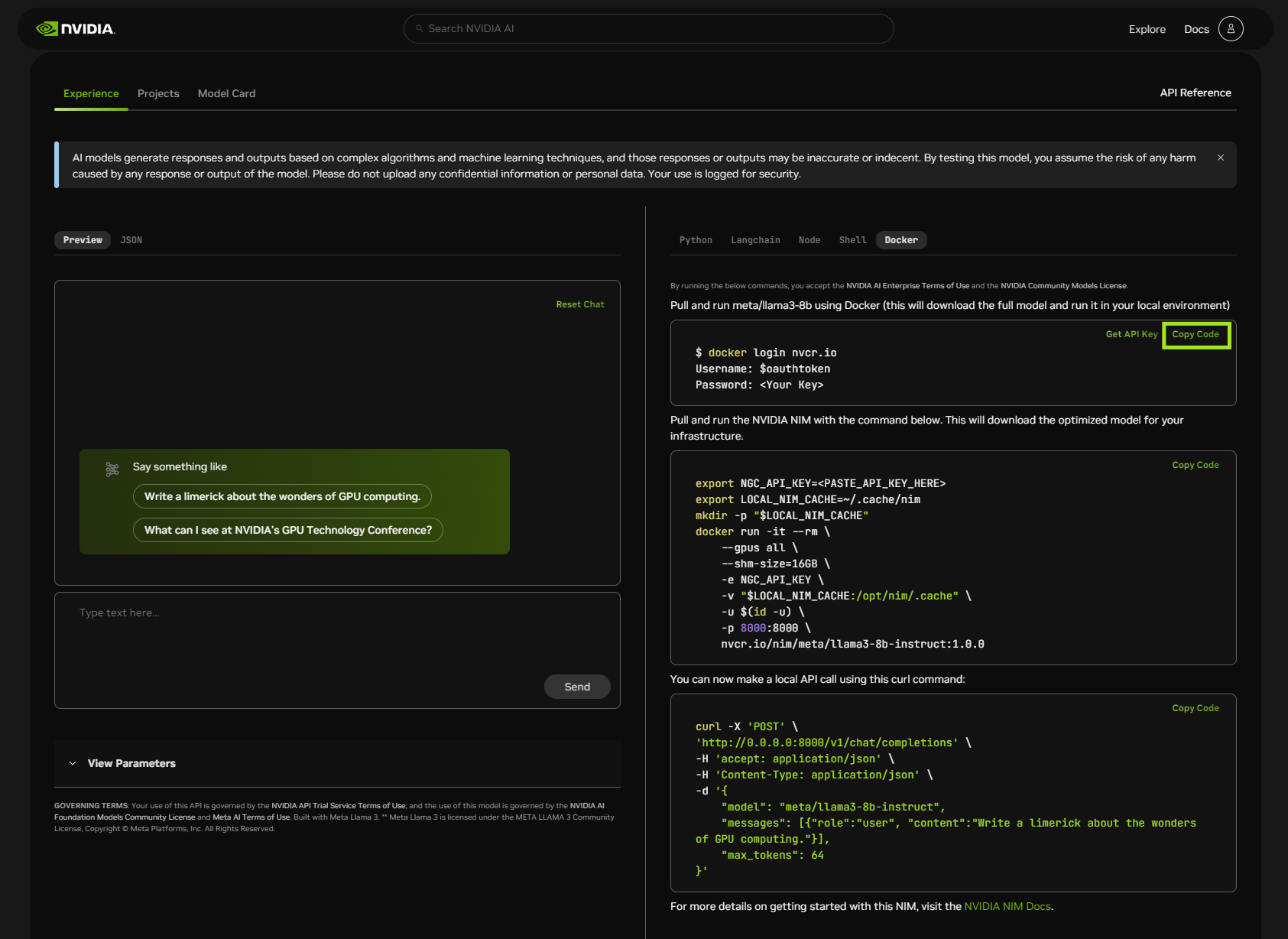
Login to Docker#
Use the docker login command, as shown in the following screenshot, to log in to Docker. Replace the placeholders for Username and Password with your values.
Download and Launch NVIDIA NIM for LLMs#
Use the following command to pull and run the NIM using Docker.
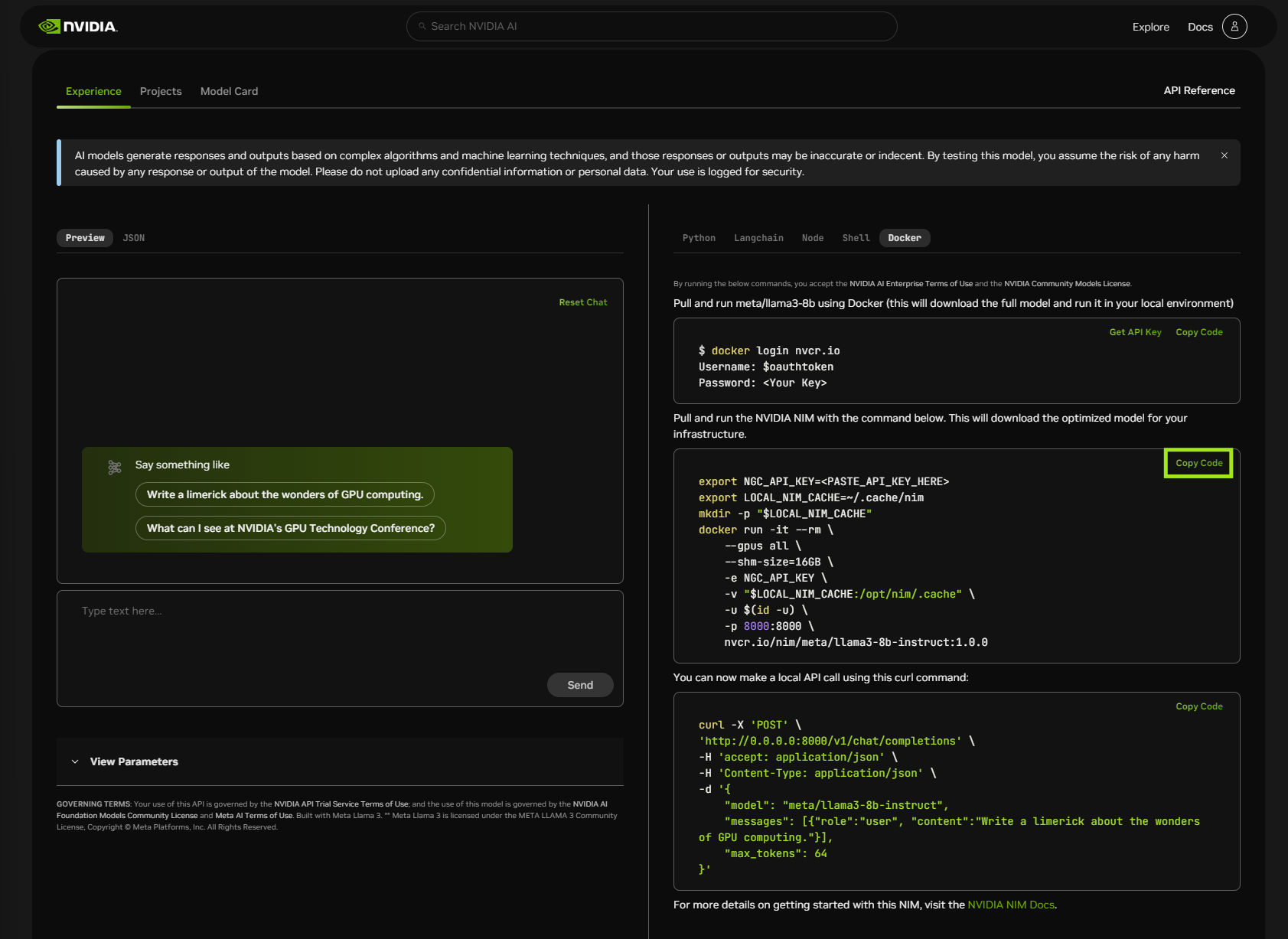
To modify the docker run parameters, see Docker Run Parameters.
Now, you can jump to running inference.
Option 2: From NGC#
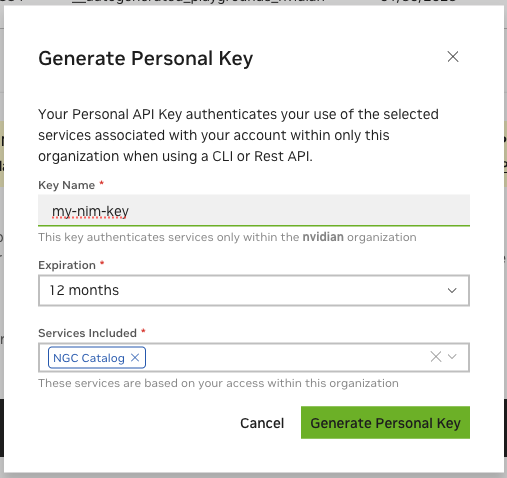
Generate an API key#
An NGC API key is required to access NGC resources and a key can be generated here: https://org.ngc.nvidia.com/setup/api-keys.
When creating an NGC API key, ensure that at least “NGC Catalog” is selected from the “Services Included” dropdown. More Services can be included if this key is to be reused for other purposes.
Export the API key#
Pass the value of the API key to the docker run command in the next section as the NGC_API_KEY environment variable to download the appropriate models and resources when starting the NIM.
If you’re not familiar with how to create the NGC_API_KEY environment variable, the simplest way is to export it in your terminal, as shown in the following example, where VALUE is the value of your API key:
Run one of the following commands to make the key available at startup:
If using bash
echo "export NGC_API_KEY=VALUE" >> ~/.bashrc
If using zsh
echo "export NGC_API_KEY=VALUE" >> ~/.zshrc
Note
Other, more secure options include saving the value in a file, so that you can retrieve with something like cat $NGC_API_KEY_FILE, or using a password manager.
Docker login to NGC#
To pull the NIM container image from NGC, first authenticate with the NVIDIA Container Registry with the following command:
echo "$NGC_API_KEY" | docker login nvcr.io --username '$oauthtoken' --password-stdin
Use $oauthtoken as the username and NGC_API_KEY as the password. The $oauthtoken username is a special name that indicates that you will authenticate with an API key and not a user name and password.
List available NIMs#
This documentation uses the ngc CLI tool in a number of examples. See the NGC CLI documentationfor information on downloading and configure the tool.
Use the following command to list the available NIMs, in CSV format.
ngc registry image list --format_type csv nvcr.io/nim/*
This command should produce output in the following format:
Name,Repository,Latest Tag,Image Size,Updated Date,Permission,Signed Tag?,Access Type,Associated Products ,,,,,,<signed tag?1>,, ... ,,,,,,<signed tag?N>,,
Use the Repository field when you call the docker run command, as shown in the following section.
Launch NIM#
The following command launches a Docker container for the llama3-8b-instruct model. To launch a container for a different NIM, replace the value of Repository with the value from the previous image list command and change the value of CONTAINER_NAME to something appropriate.
You can tell that you have the correct Repository value by getting information about the model with the following command:
ngc registry image info --format_type ascii ${Repository}:latest
Which should produce output like the following:
Model Version Information Id: 0.10.0+e6f46027-h100x1-fp16-balanced.24.06.15839955 Batch Size: Memory Footprint: Number Of Epochs: Accuracy Reached: GPU Model: Access Type: Associated Products: Created Date: 2024-06-14T22:28:17.604Z Description: Status: UPLOAD_COMPLETE Total File Count: 11 Total Size: 14.96 GB
Choose a container name for bookkeeping
export CONTAINER_NAME=Llama3-8B-Instruct
The container name from the previous ngc registgry image list command
Repository=nim/meta/llama3-8b-instruct
Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/${Repository}:latest"
Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim mkdir -p "$LOCAL_NIM_CACHE"
Add write permissions to the NIM cache for downloading model assets
chmod -R a+w "$LOCAL_NIM_CACHE"
Start the LLM NIM
docker run -it --rm --name=$CONTAINER_NAME
--runtime=nvidia
--gpus all
--shm-size=16GB
-e NGC_API_KEY=$NGC_API_KEY
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache"
-u $(id -u)
-p 8000:8000
$IMG_NAME
Docker Run Parameters#
Note
See the Configuring a NIM topic for information about additional configuration settings.
Note
If you have an issue with permission mismatches when downloading models in your local cache directory, add the -u $(id -u) option to the docker run call.
Note
NIM automatically selects the most suitable profile based on your system specification. For details, see Automatic Profile Selection
Run Inference#
During startup the NIM container downloads the required resources and begins serving the model behind an API endpoint.
INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Note
While log messages provide helpful information, they should not be relied upon to determine server readiness. Instead, use the /v1/health/ready endpoint to properly check if the server is ready to accept inference requests: curl http://0.0.0.0:8000/v1/health/ready. The server is ready when this endpoint returns a 200 status code with a success message.
Once the server is ready, you can validate the deployment of NIM by executing an inference request. In a new terminal, run the following command to show a list of models available for inference:
curl -X GET 'http://0.0.0.0:8000/v1/models'
To make the output easier to read, pipe the results of curl commands into a tool like jq or python -m json.tool. For example: curl -s http://0.0.0.0:8000/v1/models | jq.
This command should produce output similar to the following:
{ "object": "list", "data": [ { "id": "meta/llama3-8b-instruct", "object": "model", "created": 1715659875, "owned_by": "vllm", "root": "meta/llama3-8b-instruct", "parent": null, "permission": [ { "id": "modelperm-e39aaffe7015444eba964fa7736ae653", "object": "model_permission", "created": 1715659875, "allow_create_engine": false, "allow_sampling": true, "allow_logprobs": true, "allow_search_indices": false, "allow_view": true, "allow_fine_tuning": false, "organization": "*", "group": null, "is_blocking": false } ] } ] }
OpenAI Completion Request#
The Completions endpoint is typically used for base models. With the Completions endpoint, prompts are sent as plain strings, and the model produces the most likely text completions subject to the other parameters chosen. To stream the result, set "stream": true.
To update the model name, such as for a llama3-8b-instruct model, use the following command:
curl -X 'POST'
'http://0.0.0.0:8000/v1/completions'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"model": "meta/llama3-8b-instruct",
"prompt": "Once upon a time",
"max_tokens": 64
}'
You can also use the OpenAI Python API library.
from openai import OpenAI client = OpenAI(base_url="http://0.0.0.0:8000/v1", api_key="not-used") prompt = "Once upon a time" response = client.completions.create( model="meta/llama3-8b-instruct", prompt=prompt, max_tokens=16, stream=False ) completion = response.choices[0].text print(completion)
Prints:
, there was a young man named Jack who lived in a small village at the
OpenAI Chat Completion Request#
The Chat Completions endpoint is typically used with chat or instruct tuned models that are designed to be used through a conversational approach. With the Chat Completions endpoint, prompts are sent in the form of messages with roles and contents, giving a natural way to keep track of a multi-turn conversation. To stream the result, set "stream": true.
To update model name, such as for a llama3-8b-instruct model, use the following command:
curl -X 'POST'
'http://0.0.0.0:8000/v1/chat/completions'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"model": "meta/llama3-8b-instruct",
"messages": [
{
"role":"user",
"content":"Hello! How are you?"
},
{
"role":"assistant",
"content":"Hi! I am quite well, how can I help you today?"
},
{
"role":"user",
"content":"Can you write me a song?"
}
],
"max_tokens": 32
}'
You can also use the OpenAI Python API library.
from openai import OpenAI client = OpenAI(base_url="http://0.0.0.0:8000/v1", api_key="not-used") messages = [ {"role": "user", "content": "Hello! How are you?"}, {"role": "assistant", "content": "Hi! I am quite well, how can I help you today?"}, {"role": "user", "content": "Write a short limerick about the wonders of GPU computing."} ] chat_response = client.chat.completions.create( model="meta/llama3-8b-instruct", messages=messages, max_tokens=32, stream=False ) assistant_message = chat_response.choices[0].message print(assistant_message)
Which prints:
ChatCompletionMessage(content='There once was a GPU so fine,\nProcessed data in parallel so divine,\nIt crunched with great zest,\nAnd computational quest,\nUnleashing speed, a true wonder sublime!', role='assistant', function_call=None, tool_calls=None)
If you encounter a BadRequestError with an error message indicating that you are missing the messages or prompt field, you might inadvertently be using the wrong endpoint.
For example, if you make a Completions request with a request body intended for Chat Completions, you get the following error:
{ "object": "error", "message": "[{'type': 'missing', 'loc': ('body', 'prompt'), 'msg': 'Field required', ...", "type": "BadRequestError", "param": null, "code": 400 }
Conversely, if you make a Chat Completions request with a request body intended for Completions, you get the following error:
{ "object": "error", "message": "[{'type': 'missing', 'loc': ('body', 'messages'), 'msg': 'Field required', ...", "type": "BadRequestError", "param": null, "code": 400 }
Verify that the endpoint you are using, such as /v1/completions or /v1/chat/completions, is correctly configured for your request.
Improving TRT-LLM Performance#
TRT-LLM, which is the runtime for the model configurations listed as optimized in the Supported Models, has a number of parameters you can tune to improve performance. Refer to Best Practices for Tuning the Performance of TensorRT-LLM for details.
Parameter-Efficient Fine-Tuning#
Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of large pretrained models. Currently NIM only supports LoRA PEFT. See Parameter-Efficient Fine-Tuning for details.
Stopping the container#
If a Docker container is launched with the --name command line option, you can use the following command to stop the running container.
docker stop $CONTAINER_NAME
Use docker kill if stop is not responsive. Follow that command by docker rm <span class="katex"><span class="katex-mathml"><math xmlns="http://www.w3.org/1998/Math/MathML"><semantics><mrow><mi>C</mi><mi>O</mi><mi>N</mi><mi>T</mi><mi>A</mi><mi>I</mi><mi>N</mi><mi>E</mi><msub><mi>R</mi><mi>N</mi></msub><mi>A</mi><mi>M</mi><mi>E</mi><mi mathvariant="normal">‘</mi><mi>i</mi><mi>f</mi><mi>y</mi><mi>o</mi><mi>u</mi><mi>d</mi><mi>o</mi><mi>n</mi><mi>o</mi><mi>t</mi><mi>i</mi><mi>n</mi><mi>t</mi><mi>e</mi><mi>n</mi><mi>d</mi><mi>t</mi><mi>o</mi><mi>r</mi><mi>e</mi><mi>s</mi><mi>t</mi><mi>a</mi><mi>r</mi><mi>t</mi><mi>t</mi><mi>h</mi><mi>e</mi><mi>c</mi><mi>o</mi><mi>n</mi><mi>t</mi><mi>a</mi><mi>i</mi><mi>n</mi><mi>e</mi><mi>r</mi><mi>a</mi><mi>s</mi><mo>−</mo><mi>i</mi><mi>s</mi><mo stretchy="false">(</mo><mi>w</mi><mi>i</mi><mi>t</mi><mi>h</mi><mi mathvariant="normal">‘</mi><mi>d</mi><mi>o</mi><mi>c</mi><mi>k</mi><mi>e</mi><mi>r</mi><mi>s</mi><mi>t</mi><mi>a</mi><mi>r</mi><mi>t</mi></mrow><annotation encoding="application/x-tex">CONTAINER_NAME if you do not intend to restart the container as-is (with docker start </annotation></semantics></math></span><span class="katex-html" aria-hidden="true"><span class="base"><span class="strut" style="height:0.8889em;vertical-align:-0.1944em;"></span><span class="mord mathnormal" style="margin-right:0.13889em;">CONT</span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.07847em;">I</span><span class="mord mathnormal" style="margin-right:0.05764em;">NE</span><span class="mord"><span class="mord mathnormal" style="margin-right:0.00773em;">R</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height:0.3283em;"><span style="top:-2.55em;margin-left:-0.0077em;margin-right:0.05em;"><span class="pstrut" style="height:2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mathnormal mtight" style="margin-right:0.10903em;">N</span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height:0.15em;"><span></span></span></span></span></span></span><span class="mord mathnormal">A</span><span class="mord mathnormal" style="margin-right:0.05764em;">ME</span><span class="mord">‘</span><span class="mord mathnormal">i</span><span class="mord mathnormal" style="margin-right:0.10764em;">f</span><span class="mord mathnormal">yo</span><span class="mord mathnormal">u</span><span class="mord mathnormal">d</span><span class="mord mathnormal">o</span><span class="mord mathnormal">n</span><span class="mord mathnormal">o</span><span class="mord mathnormal">t</span><span class="mord mathnormal">in</span><span class="mord mathnormal">t</span><span class="mord mathnormal">e</span><span class="mord mathnormal">n</span><span class="mord mathnormal">d</span><span class="mord mathnormal">t</span><span class="mord mathnormal">ores</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">tt</span><span class="mord mathnormal">h</span><span class="mord mathnormal">eco</span><span class="mord mathnormal">n</span><span class="mord mathnormal">t</span><span class="mord mathnormal">ain</span><span class="mord mathnormal" style="margin-right:0.02778em;">er</span><span class="mord mathnormal">a</span><span class="mord mathnormal">s</span><span class="mspace" style="margin-right:0.2222em;"></span><span class="mbin">−</span><span class="mspace" style="margin-right:0.2222em;"></span></span><span class="base"><span class="strut" style="height:1em;vertical-align:-0.25em;"></span><span class="mord mathnormal">i</span><span class="mord mathnormal">s</span><span class="mopen">(</span><span class="mord mathnormal" style="margin-right:0.02691em;">w</span><span class="mord mathnormal">i</span><span class="mord mathnormal">t</span><span class="mord mathnormal">h</span><span class="mord">‘</span><span class="mord mathnormal">d</span><span class="mord mathnormal">oc</span><span class="mord mathnormal" style="margin-right:0.03148em;">k</span><span class="mord mathnormal">ers</span><span class="mord mathnormal">t</span><span class="mord mathnormal">a</span><span class="mord mathnormal" style="margin-right:0.02778em;">r</span><span class="mord mathnormal">t</span></span></span></span>CONTAINER_NAME), in which case you need to re-use the docker run ... instructions from the beginning of this section to start a new container for your NIM.
If you did not start a container with --name, examine the output of the docker ps command to get a container ID for the given image you used.
Kubernetes Installation#
The nim-deploy GitHub repository showcases several reference implementations for Kubernetes installations. These examples are experimental, and might require modification for you to run in your particular cluster set-up.
Serving models from local assets#
NIM for LLMs provides utilities which enable downloading models to a local directory either as a model repository or to NIM cache. See the Utilities section for details.
Use the following commands to launch a NIM container. From there, you can view and download models locally.
Choose a container name for bookkeeping
export CONTAINER_NAME=Llama-3.1-8B-instruct
The container name from the previous ngc registgry image list command
Repository=nim/meta/llama-3.1-8b-instruct
Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/${Repository}:latest"
Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/downloaded-nim mkdir -p "$LOCAL_NIM_CACHE"
Add write permissions to the NIM cache for downloading model assets
chmod -R a+w "$LOCAL_NIM_CACHE"
docker run -it --rm --name=$CONTAINER_NAME
-e LOG_LEVEL=$LOG_LEVEL
-e NGC_API_KEY=$NGC_API_KEY
--gpus all
-v $LOCAL_NIM_CACHE:/opt/nim/.cache
-u $(id -u)
$IMG_NAME
bash -i
Use the list-model-profiles command to list the available profiles.
list-model-profiles
-e NGC_API_KEY=$NGC_API_KEY
#SYSTEM INFO
#- Free GPUs:
- [26b3:10de] (0) NVIDIA RTX 5880 Ada Generation (RTX A6000 Ada) [current utilization: 1%]
- [26b3:10de] (1) NVIDIA RTX 5880 Ada Generation (RTX A6000 Ada) [current utilization: 1%]
- [1d01:10de] (2) NVIDIA GeForce GT 1030 [current utilization: 2%]
#MODEL PROFILES #- Compatible with system and runnable:
- 19031a45cf096b683c4d66fff2a072c0e164a24f19728a58771ebfc4c9ade44f (vllm-fp16-tp2)
- 8835c31752fbc67ef658b20a9f78e056914fdef0660206d82f252d62fd96064d (vllm-fp16-tp1)
- With LoRA support:
- c5ffce8f82de1ce607df62a4b983e29347908fb9274a0b7a24537d6ff8390eb9 (vllm-fp16-tp2-lora)
- 8d3824f766182a754159e88ad5a0bd465b1b4cf69ecf80bd6d6833753e945740 (vllm-fp16-tp1-lora)
#- Incompatible with system:
- dcd85d5e877e954f26c4a7248cd3b98c489fbde5f1cf68b4af11d665fa55778e (tensorrt_llm-h100-fp8-tp2-latency)
- f59d52b0715ee1ecf01e6759dea23655b93ed26b12e57126d9ec43b397ea2b87 (tensorrt_llm-l40s-fp8-tp2-latency)
- 30b562864b5b1e3b236f7b6d6a0998efbed491e4917323d04590f715aa9897dc (tensorrt_llm-h100-fp8-tp1-throughput)
- 09e2f8e68f78ce94bf79d15b40a21333cea5d09dbe01ede63f6c957f4fcfab7b (tensorrt_llm-l40s-fp8-tp1-throughput)
- a93a1a6b72643f2b2ee5e80ef25904f4d3f942a87f8d32da9e617eeccfaae04c (tensorrt_llm-a100-fp16-tp2-latency)
- e0f4a47844733eb57f9f9c3566432acb8d20482a1d06ec1c0d71ece448e21086 (tensorrt_llm-a10g-fp16-tp2-latency)
- 879b05541189ce8f6323656b25b7dff1930faca2abe552431848e62b7e767080 (tensorrt_llm-h100-fp16-tp2-latency)
- 24199f79a562b187c52e644489177b6a4eae0c9fdad6f7d0a8cb3677f5b1bc89 (tensorrt_llm-l40s-fp16-tp2-latency)
- 751382df4272eafc83f541f364d61b35aed9cce8c7b0c869269cea5a366cd08c (tensorrt_llm-a100-fp16-tp1-throughput)
- c334b76d50783655bdf62b8138511456f7b23083553d310268d0d05f254c012b (tensorrt_llm-a10g-fp16-tp1-throughput)
- cb52cbc73a6a71392094380f920a3548f27c5fcc9dab02a98dc1bcb3be9cf8d1 (tensorrt_llm-h100-fp16-tp1-throughput)
- d8dd8af82e0035d7ca50b994d85a3740dbd84ddb4ed330e30c509e041ba79f80 (tensorrt_llm-l40s-fp16-tp1-throughput)
- 9137f4d51dadb93c6b5864a19fd7c035bf0b718f3e15ae9474233ebd6468c359 (tensorrt_llm-a10g-fp16-tp2-throughput-lora)
- cce57ae50c3af15625c1668d5ac4ccbe82f40fa2e8379cc7b842cc6c976fd334 (tensorrt_llm-a100-fp16-tp1-throughput-lora)
- 3bdf6456ff21c19d5c7cc37010790448a4be613a1fd12916655dfab5a0dd9b8e (tensorrt_llm-h100-fp16-tp1-throughput-lora)
- 388140213ee9615e643bda09d85082a21f51622c07bde3d0811d7c6998873a0b (tensorrt_llm-l40s-fp16-tp1-throughput-lora)
You can download any of these profiles to the NIM cache using the download-to-cache command. The following example downloads the tensorrt_llm-l40s-fp8-tp1-throughput profile to the NIM cache.
download-to-cache --profile 09e2f8e68f78ce94bf79d15b40a21333cea5d09dbe01ede63f6c957f4fcfab7b
You can also let the download-to-cache decide the most optimal profile given the hardware to download by providing no profiles to download, as shown in the following example.
Further information on download-to-cache tool, execute the following command:
download-to-cache -h
Downloads selected or default model profiles to NIM cache. Can be used to pre-
cache profiles prior to deployment.
options:
-h, --help show this help message and exit
--profiles [PROFILES ...], -p [PROFILES ...]
Profile hashes to download. If none are provided, the
optimal profile is downloaded. Multiple profiles can
be specified separated by spaces.
--all Set this to download all profiles to cache
--lora Set this to download default lora profile. This
expects --profiles and --all arguments are not
specified.
For information about serving models in an air gap system, see Air Gap Deployment.