Ordia: A Web Application for Wikidata Lexemes (original) (raw)
Abstract
Since 2018, Wikidata has had the ability to describe lexemes, and the associated SPARQL endpoint Wikidata Query Service can query this information and visualize the results. Ordia is a Web application that displays the multilingual lexeme data of Wikidata based on embedding of the responses from the Wikidata Query Service via templated SPARQL queries. Ordia has also a SPARQL-based approach for online matching of the words of a text with Wikidata lexemes and the ability to use a knowledge graph embedding as part of a SPARQL query. Ordia is available from https://tools.wmflabs.org/ordia/.
This work is funded by the Innovation Fund Denmark through the projects DAnish Center for Big Data Analytics driven Innovation (DABAI) and Teaching platform for developing and automatically tracking early stage literacy skills (ATEL).
Similar content being viewed by others
1 Introduction
The multilingual collaboratively editable and freely-licensed knowledge base WikidataFootnote 1 [7] was set up in October 2012. On this website users can describe items and links between the items via properties, as well as add qualifiers and sources to support the individual claims. The Wikidata data—originally formatted in a nested JSON-like structure—is translated to a Semantic Web representation and continuously updated and made available via a SPARQL endpoint: The Wikidata Query Service (WDQS)Footnote 2 and as such part of the Linked Open Data cloud.
In 2016, the Wikidata developers announced dictionary support in Wikidata [[4](#ref-CR4 "Pintscher, L.: Let’s move forward with support for Wiktionary. Wikidata mailing list, September 2016. https://lists.wikimedia.org/pipermail/wikidata/2016-September/009541.html
")\], and in May 2018, Wikidata enabled the entering of basic data about _lexemes_ and their _forms_. Later that year, Wikidata also switched on support for _senses_, and links to the Q-items from senses[Footnote 3](#Fn3) can be established. As the rest of Wikidata, the lexeme part of Wikidata is multilingual and ontological definitions in one language are available in other languages.Below I will describe the Ordia Web application that takes advantage of the Wikidata lexeme data, aggregating the information via WDQS and presenting it on a website with added functionality in the form of lexeme extraction from a text and SPARQL integration of knowledge graph embedding information.
Fig. 1.
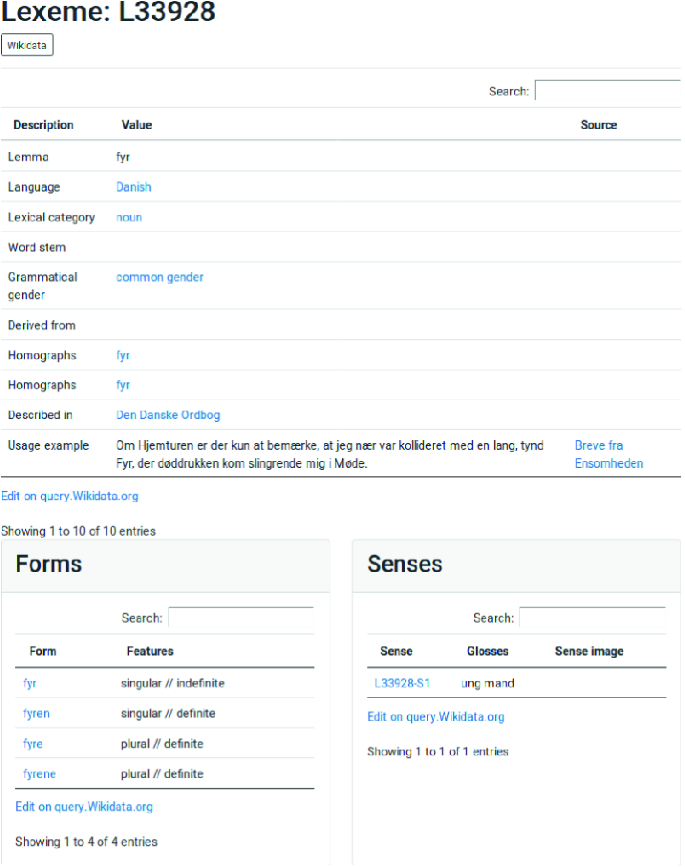
Screenshot of the page in Ordia for the Danish lexeme fyr at https://tools.wmflabs.org/ordia/L33928.
2 Ordia Web Application
Ordia is available from GitHub at http://github.com/fnielsen/ordia developed under the Apache 2.0 licens. It may be cloned from that repository and run locally. The canonical homepage for the Web application is at https://tools.wmflabs.org/ordia/ under the Toolforge cloud service provided by the Wikimedia Foundation.
As a Web application and Python package, Ordia is heavily inspired from our other current Wikidata Web application projects: Scholia [[3](#ref-CR3 "Nielsen, F.Å., Mietchen, D., Willighagen, E.: Scholia, scientometrics and Wikidata. In: Blomqvist, E., Hose, K., Paulheim, H., Ławrynowicz, A., Ciravegna, F., Hartig, O. (eds.) ESWC 2017. LNCS, vol. 10577, pp. 237–259. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-70407-4_36
")\], cvrminer[Footnote 4](#Fn4) and Wembedder \[[2](#ref-CR2 "Nielsen, F.Å.: Wembedder: Wikidata entity embedding web service, October 2017.
https://arxiv.org/pdf/1710.04099
")\]: Ordia uses the Flask web framework together with Javascript and SPARQL templates in Jinja[Footnote 5](#Fn5) to dynamically build webpages. The constructed SPARQL queries are sent to the WDQS SPARQL endpoint and the responses are added to the generated HTML pages, either with HTML embedding or via Javascript and the _DataTables_ library.[Footnote 6](#Fn6) The library provides means for sorting table rows and for drill down via a search field. The SPARQL queries used to generate the tables in Ordia are all linked from an anchor in the lower left corner of the tables, making a SPARQL-knowledgeable user able to inspect and modify the queries.Ordia creates separate pages for Q-items, lexemes, forms and senses, and makes panels with tables on each of them. Figure 1 shows an example for a lexeme. Ordia uses a URL scheme for Q-items inspired from Scholia’s notion of aspects and shows aspects for language, lexical category, grammatical features, propeties and references, e.g., the link /language/Q809 will show Polish (Q809) lexemes, while /Q809 shows Polish as a semantic concept in its own right. Some of the aspects show graphs for the ontology, e.g., the page for noun as a lexical category at /lexical-category/Q1084.
For searching after lexemes and forms, Ordia uses the MediaWiki API of Wikidata: The user types in a search in the Ordia interface and Ordia makes an API call to Wikidata and presents the results in the Ordia interface.
Fig. 2.
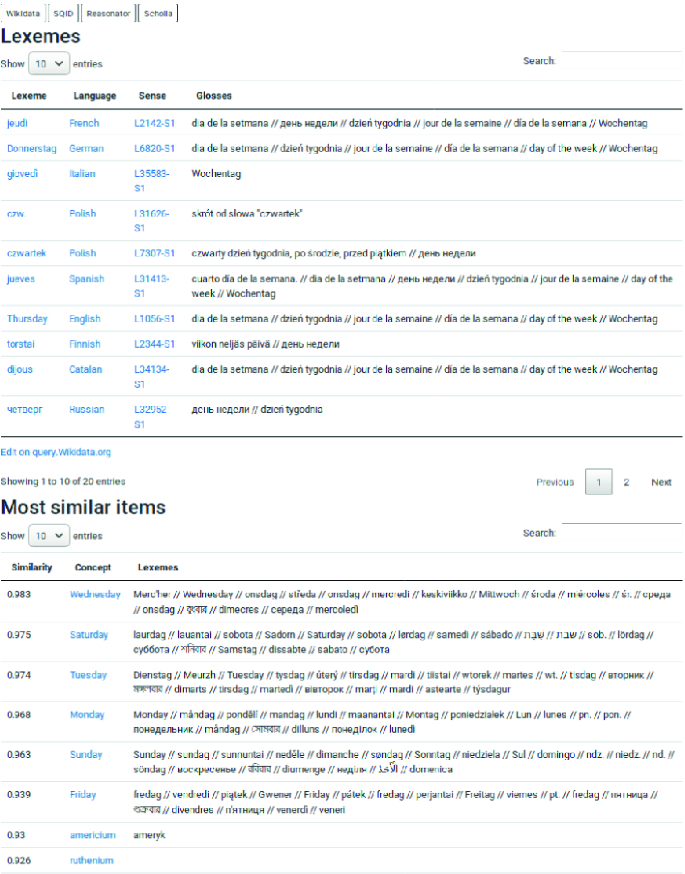
Screenshot of Ordia’s page for the Thursday Wikidata concept (Q129). The top panel shows the associated lexemes and senses in the languages that link to the concept, while the lower panel displays the result from the Wembedder knowledge graph embedding similarity computation.
Wembedder, a Wikidata-based knowledge graph embedding Web service [[2](#ref-CR2 "Nielsen, F.Å.: Wembedder: Wikidata entity embedding web service, October 2017. https://arxiv.org/pdf/1710.04099
")\], works with a simplified RDF2Vec approach implemented with Gensim’s word2vec model \[[1](#ref-CR1 "Mikolov, T., Chen, K., Corrado, G.S., Dean, J.: Efficient estimation of word representations in vector space, January 2013.
https://arxiv.org/pdf/1301.3781v3
"), [5](#ref-CR5 "Ristoski, P., Paulheim, H.: RDF2Vec: RDF graph embeddings for data mining. In: Groth, P., et al. (eds.) ISWC 2016. LNCS, vol. 9981, pp. 498–514. Springer, Cham (2016).
https://doi.org/10.1007/978-3-319-46523-4_30
"), [8](#ref-CR8 "Řehůřek, R., Sojka, P.: Software framework for topic modelling with large corpora. In: New Challenges For NLP Frameworks Programme, pp. 45–50, May 2010")\]. As Ordia, Wembedder runs as part of Toolforge.[Footnote 7](#Fn7) The current implementation only handles the Q-items and properties of Wikidata,—not lexemes, forms nor senses. The only functionality implemented in the Wembedder Web service so far is a _most similar_ service that returns the most similar items and properties based on a query item. Wembedder has no SPARQL endpoint capability, so federated SPARQL queries cannot be made. Instead Ordia calls the REST interface of Wembedder via a Javascript Ajax call from the server side and formats the received JSON with Wikidata identifier and similarity values as two-tuple values for the SPARQL VALUES construct. The VALUES construct is then interpolated into a SPARQL template and sent off to WDQS with the response formatted in Ordia in a table with the DataTable library.Ordia uses the Wembedder queries on pages for Q-items, where a table displays related Q-items sorted according to similarity and augmented with information from the lexeme part of Wikidata. Figure 2 shows an example of the output on the page for the concept Thursday corresponding to the page https://tools.wmflabs.org/ordia/Q129, where the top panel displays lexemes for languages linked (e.g., jeudi, Donnerstag, Thursday) and the lower panel shows the result from WDQS with Wembedder-included results. Here Wednesday and Saturday are the most related concepts to Thursday.
The text-to-lexeme facility in Ordia at https://tools.wmflabs.org/ordia/text-to-lexemes enables the user to write a short text into an HTML text area on the client side, and send it off to Ordia. Ordia then makes a simple sentencedetection and lowercases the first letter of the sentences before word tokenization with a simple regular expression pattern. Identified words are interpolated into a WDQS query via the VALUES keyword to search for matching forms, and the response from the SPARQL endpoint is shown in a table in the Ordia interface. The language of the input sentence must be specified. Currently, Ordia only handles a small number of selected languages, but in principle every language in Wikidata lexemes could be supported.
Fig. 3.

Screenshot of Ordia’s text-to-lexeme facility, where the sentence “Regeringen spiser grønne æbler om vinteren” (“The government is eating green apples during winter”): https://tools.wmflabs.org/ordia/text-to-lexemes?text=Regeringen+spiser+gr%C3%B8nne+%C3%A6bler+om+vinteren&language=da. (Color figure online)
Figure 3 displays the result after the Danish sentence “Regeringen spiser grønne æbler om vinteren” (“The government is eating green apples during winter”) has been submitted to Ordia. The result of the WDQS query here shows the word and—if matched—the form, lexeme, lexical category, lexical feature, sense and image associated with the sense. If a word matches several forms in a language, they are all shown, i.e., no word sense disambiguation is performed. Ordia’s text-to-lexemes responds within seconds. Usually Ordia responds with the HTML within 300 ms for a sentence like the above. The SPARQL query sent by the client to WDQS completes typically between 1.5 and 2 s after the user submitted the original query. The further download and rendering of the images from Wikimedia Commons—as shown in Fig. 3—may take an extra second. If the SPARQL query does not find a matching form, a link is created to Ordia’s search page, which links further on to lexeme creation to ease the setup of new lexemes.
3 Discussion
I have shown Ordia, a Web service that uses the WDQS SPARQL endpoint to build a site with lexicographic data from Wikidata. Compared to the Wiktionary-based DBnary [[6](#ref-CR6 "Sérasset, G.: DBnary: Wiktionary as a lemon-based multilingual lexical resource in RDF. Semant. Web 6(4), 355–361 (2015). https://doi.org/10.3233/SW-140147
")\], Ordia needs no extractor and presents the lexicographic information graphically and up-to-date via WDQS as changes occur in Wikidata.The conceptual choices that has been made in designing Ordia are: (1) A user should easily be able to perform powerful SPARQL queries by navigating the Ordia interface and without using any knowledge of SPARQL; (2) the URL pattern for each page should be easy to understand and predict; (3) Each page should link to other pages and in such a way let the user discover new lexemes, concepts, forms etc., and (4) the interface should use graphics when possible, e.g., graphs of word and concept relations and for displaying images associated with senses of words.
Other Wikidata lexeme Web applications beyond Ordia are available: Lucas Werkmeister has created Wikidata Lexeme Forms which enables easy HTML-form-based set up of lexemes and their lexical forms for a range of languages. In November 2018, Werkmeister found that this tool has been used for the creation of 10’827 lexemes out of a total of 37’886.Footnote 8 Alicia Fagerving has created Wikidata Senses which eases the setup of senses associated with lexemes. While the above tools focuses on input, Léa Lacroix’ DerDieDas game, tasks a language learner to guess and learn the grammatical gender of presented nouns. It uses the data in Wikidata via a WDQS query. Originally in German, it now has derived versions in French and Danish. Another of Werkmeister’s online tools, Wikidata Lexeme Graph Builder, constructs a graph based on a specified Wikidata item and a Wikidata property. These and further Wikidata lexicographical tools are listed at https://www.wikidata.org/wiki/Wikidata:Tools/Lexicographical_data.
Ordia can be used in a variety of ways: A copy-and-paste of a text into Ordia’s text-to-lexeme tool will quickly return an overview of missing lexeme data in Wikidata. Most words from a typical English news article are usually matched to a Wikidata lexeme,—except for proper nouns. Another useful overview that Ordia gives is the ontology of lexical categories. For instance, https://tools.wmflabs.org/ordia/lexical-category/Q36224 shows a graph with subconcepts and superconcepts of the pronoun concept independent of language. Such an overview is convenient to consult when entering lexeme data in Wikidata. The use of Ordia as, e.g., a translation or synonymy dictionary is still constrained by the yet low number of lexemes that have been entered and linked.
Notes
- The “ordinary” Wikidata items are referred to by an identifier consisting of the letter ‘Q’ and an integer, while the properties are identified by the letter ‘P’ and an integer. Lexemes are identified by the initial letter ‘L’.
- Descriptions of cvrminer at https://tools.wmflabs.org/cvrminer/ has not been published. The Web application displays information about organizations as listed in Wikidata.
References
- Mikolov, T., Chen, K., Corrado, G.S., Dean, J.: Efficient estimation of word representations in vector space, January 2013. https://arxiv.org/pdf/1301.3781v3
- Nielsen, F.Å.: Wembedder: Wikidata entity embedding web service, October 2017. https://arxiv.org/pdf/1710.04099
- Nielsen, F.Å., Mietchen, D., Willighagen, E.: Scholia, scientometrics and Wikidata. In: Blomqvist, E., Hose, K., Paulheim, H., Ławrynowicz, A., Ciravegna, F., Hartig, O. (eds.) ESWC 2017. LNCS, vol. 10577, pp. 237–259. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-70407-4_36
Chapter Google Scholar - Pintscher, L.: Let’s move forward with support for Wiktionary. Wikidata mailing list, September 2016. https://lists.wikimedia.org/pipermail/wikidata/2016-September/009541.html
- Ristoski, P., Paulheim, H.: RDF2Vec: RDF graph embeddings for data mining. In: Groth, P., et al. (eds.) ISWC 2016. LNCS, vol. 9981, pp. 498–514. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46523-4_30
Chapter Google Scholar - Sérasset, G.: DBnary: Wiktionary as a lemon-based multilingual lexical resource in RDF. Semant. Web 6(4), 355–361 (2015). https://doi.org/10.3233/SW-140147
Article Google Scholar - Vrandečić, D., Krötzsch, M.: Wikidata: a free collaborative knowledgebase. Commun. ACM 57, 78–85 (2014)
Article Google Scholar - Řehůřek, R., Sojka, P.: Software framework for topic modelling with large corpora. In: New Challenges For NLP Frameworks Programme, pp. 45–50, May 2010
Google Scholar
Author information
Authors and Affiliations
- Cognitive Systems, DTU Compute, Technical University of Denmark, Kongens Lyngby, Denmark
Finn Årup Nielsen
Authors
- Finn Årup Nielsen
You can also search for this author inPubMed Google Scholar
Corresponding author
Correspondence toFinn Årup Nielsen .
Editor information
Editors and Affiliations
- Kansas State University, Manhattan, KS, USA
Pascal Hitzler - Vienna University of Economics and Business, Vienna, Austria
Sabrina Kirrane - Linköping University, Linköping, Sweden
Olaf Hartig - Vrije Universiteit Amsterdam, Amsterdam, The Netherlands
Victor de Boer - Leibniz Information Centre for Science and Technology University Library (TIB), Hannover, Germany
Maria-Esther Vidal - University of Bonn, Bonn, Germany
Maria Maleshkova - Vrije Universiteit Amsterdam, Amsterdam, The Netherlands
Stefan Schlobach - Jönköping University, Jönköping, Sweden
Karl Hammar - F. Hoffmann-La Roche AG, Basel, Switzerland
Nelia Lasierra - Robert Bosch GmbH, Stuttgart, Germany
Steffen Stadtmüller - Aalborg University, Aalborg, Denmark
Katja Hose - IMEC, Ghent University, Ghent, Belgium
Ruben Verborgh
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper
Cite this paper
Nielsen, F.Å. (2019). Ordia: A Web Application for Wikidata Lexemes. In: Hitzler, P., et al. The Semantic Web: ESWC 2019 Satellite Events. ESWC 2019. Lecture Notes in Computer Science(), vol 11762. Springer, Cham. https://doi.org/10.1007/978-3-030-32327-1\_28
Download citation
- .RIS
- .ENW
- .BIB
- DOI: https://doi.org/10.1007/978-3-030-32327-1\_28
- Published: 10 October 2019
- Publisher Name: Springer, Cham
- Print ISBN: 978-3-030-32326-4
- Online ISBN: 978-3-030-32327-1
- eBook Packages: Computer ScienceComputer Science (R0)