SS-MVMETRO: Semi-supervised multi-view human mesh recovery transformer (original) (raw)
Abstract
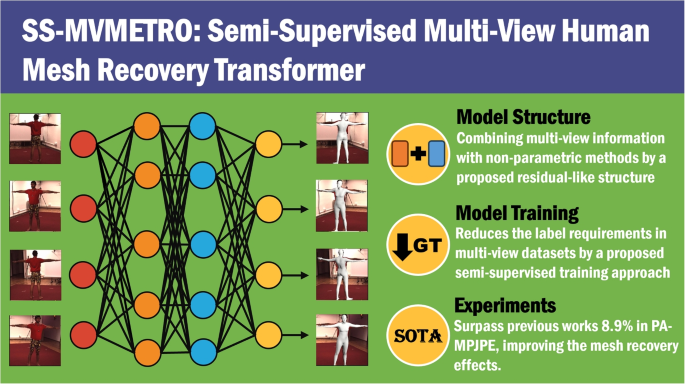
Parametric methods are widely utilized in RGB-based human mesh recovery, relying on precise statistical human body model parameters that are challenging to obtain. In contrast, non-parametric transformer-based approaches excel but are applied only to monocular RGB tasks. To address these limitations, this paper presents Semi-Supervised Multi-View Human Mesh Recovery Transformer (SS-MVMETRO), which combines multi-view information with non-parametric methods for the first time. Our model encodes different images according to their respective view directions, fusing local features around key points of joints and vertices. Then, a residual-like structure is proposed to integrate the fused features in the mesh recovery transformer, which subsequently predicts the 3D coordinates of the human mesh vertices. Additionally, we divide different views into the main view and auxiliary views and propose a semi-supervised training approach that requires fewer matching labels. The efficacy of our work is validated on two datasets, Human3.6M and Mpi_inf_3dph, through quantitative and qualitative experiments. The results indicate that SS-MVMETRO improves the reconstruction accuracy, surpassing previous image-based methods by at least 8.9% in terms of Procrustes Analysis Mean-Per-Joint-Position-Error (PA-MPJPE).
Graphical abstract
Access this article
Subscribe and save
- Starting from 10 chapters or articles per month
- Access and download chapters and articles from more than 300k books and 2,500 journals
- Cancel anytime View plans
Buy Now
Price excludes VAT (USA)
Tax calculation will be finalised during checkout.
Instant access to the full article PDF.
Data availability and access
The “Human3.6M” data that support the findings of this work are available in Human3.6M, the ”Mpi_inf_3dph” data are available in Mpi_inf_3dph, the ”Mpii” data are available in Mpii, the ”Muco” data are available in Muco, the ”Up3d” data are available in Up3d, the ”Coco” data are available in Coco. These datasets are publicly accessible.
References
- Loper M, Mahmood N, Romero J et al (2015) Smpl: A skinned multi-person linear model. ACM Transactions on Graphics 34(6):1–16. https://doi.org/10.1145/2816795.2818013
Article Google Scholar - Ran H, Ning X, Li W et al (2023) 3d human pose and shape estimation via de-occlusion multi-task learning. Neurocomputing 126284. https://doi.org/10.1016/j.neucom.2023.126284
- Wei G, Lan C, Zeng W et al (2020) View invariant 3d human pose estimation. IEEE Trans Circuits Syst Video Technol 30(12):4601–4610. https://doi.org/10.1109/TCSVT.2019.2928813
Article Google Scholar - Gu R, Wang G, Jiang Z et al (2020) Multi-person hierarchical 3d pose estimation in natural videos. IEEE Trans Circuits Syst Video Technol 30(11):4245–4257. https://doi.org/10.1109/TCSVT.2019.2953678
Article Google Scholar - Kolotouros N, Pavlakos G, Black MJ et al (2019) Learning to reconstruct 3d human pose and shape via model-fitting in the loop. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 2252–2261
- Zhang H, Tian Y, Zhou X et al (2021) Pymaf: 3d human pose and shape regression with pyramidal mesh alignment feedback loop. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 11446–11456
- Liang J, Lin MC (2019) Shape-aware human pose and shape reconstruction using multi-view images. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 4352–4362
- Lin K, Wang L, Liu Z (2021) Mesh graphormer. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 12939–12948
- Cho J, Youwang K, Oh TH (2022) Cross-attention of disentangled modalities for 3d human mesh recovery with transformers. In: Proceedings of the European conference on computer vision, Springer, pp 342–359
- Dong Y, Yuan Q, Peng R et al (2024) An iterative 3d human body reconstruction method driven by personalized dimensional prior knowledge. Appl Intell 54(1):738–748. https://doi.org/10.1007/s10489-023-05214-y
Article Google Scholar - Kim J, Gwon MG, Park H et al (2023) Sampling is matter: Point-guided 3d human mesh reconstruction. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 12880–12889
- Dai Y, Wen C, Wu H et al (2022) Indoor 3d human trajectory reconstruction using surveillance camera videos and point clouds. IEEE Trans Circuits Syst Video Technol 32(4):2482–2495. https://doi.org/10.1109/TCSVT.2021.3081591
Article Google Scholar - Zhang B, Ma K, Wu S et al (2023) Two-stage co-segmentation network based on discriminative representation for recovering human mesh from videos. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 5662–5670
- Zheng Z, Yu T, Liu Y et al (2022) Pamir: Parametric model-conditioned implicit representation for image-based human reconstruction. IEEE Trans Pattern Anal Mach Intell 44(6):3170–3184. https://doi.org/10.1109/TPAMI.2021.3050505
Article Google Scholar - Harvey FG, Yurick M, Nowrouzezahrai D et al (2020) Robust motion in-betweening. ACM Trans Graphics (TOG) 39(4):60–1. https://doi.org/10.1145/3386569.3392480
Article Google Scholar - Henter GE, Alexanderson S, Beskow J (2020) Moglow: Probabilistic and controllable motion synthesis using normalising flows. ACM Trans Graphics (TOG) 39(6):1–14. https://doi.org/10.1145/3414685.3417836
Article Google Scholar - Tian Y, Zhang H, Liu Y et al (2023) Recovering 3d human mesh from monocular images: A survey. IEEE Trans Pattern Anal Mach Intell 45(12):15406–15425. https://doi.org/10.1109/TPAMI.2023.3298850
Article Google Scholar - Bogo F, Kanazawa A, Lassner C et al (2016) Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. In: Proceedings of the European conference on computer vision, Springer, pp 561–578
- Mahendran S, Ali H, Vidal R (2018) A mixed classification-regression framework for 3d pose estimation from 2d images. In: Proceedings of the British machine vision conference. BMVA Press, pp 72–84
- Lin K, Wang L, Liu Z (2021) End-to-end human pose and mesh reconstruction with transformers. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 1954–1963
- Shin S, Halilaj E (2020) Multi-view human pose and shape estimation using learnable volumetric aggregation
- Li Z, Oskarsson M, Heyden A (2021) 3d human pose and shape estimation through collaborative learning and multi-view model-fitting. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 1888–1897
- Zhang S, Liu Y, Liu J et al (2022) Multi-view high precise 3d human body reconstruction method for virtual fitting. Int J Pattern Recognition Artif Intell 36(15):2256023. https://doi.org/10.1142/S0218001422560237
Article Google Scholar - Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need. In: Proceedings of the International Conference on neural information processing systems, pp 6000–6010
- Zhang J, Cai Y, Yan S et al (2021) Direct multi-view multi-person 3d pose estimation. In: Proceedings of the International Conference on neural information processing systems, pp 13153–13164
- Hao C, Kong D, Li J et al (2023) Hypergraph based human mesh hierarchical representation and reconstruction from a single image. Comput & Graphics 115:339–347. https://doi.org/10.1016/j.cag.2023.07.011
Article Google Scholar - Zhou K, Han X, Jiang N et al (2022) Hemlets posh: Learning part-centric heatmap triplets for 3d human pose and shape estimation. IEEE Trans Pattern Anal Machine Intell 44(6):3000–3014. https://doi.org/10.1109/TPAMI.2021.3051173
Article Google Scholar - Chen D, Song Y, Liang F et al (2023) 3d human body reconstruction based on smpl model. Visual Comput 39(5):1893–1906. https://doi.org/10.1007/s00371-022-02453-x
Article Google Scholar - Lu Y, Yu H, Ni W et al (2023) 3d real-time human reconstruction with a single rgbd camera. Appl Intell 53(8):8735–8745. https://doi.org/10.1007/s10489-022-03969-4
Article Google Scholar - Khirodkar R, Tripathi S, Kitani K (2022) Occluded human mesh recovery. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 1715–1725
- He K, Zhang X, Ren S et al (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 770–778
- Sun K, Xiao B, Liu D et al (2019) Deep high-resolution representation learning for human pose estimation. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 5693–5703
- Li Z, Oskarsson M, Heyden A (2022) Detailed 3d human body reconstruction from multi-view images combining voxel super-resolution and learned implicit representation. Appl Intell 52(6):6739–6759. https://doi.org/10.1007/s10489-021-02783-8
Article Google Scholar - Xu W, Xiang D, Wang G et al (2022) Multiview video-based 3-d pose estimation of patients in computer-assisted rehabilitation environment (caren). IEEE Trans Human-Mach Syst 52(2):196–206. https://doi.org/10.1109/THMS.2022.3142108
Article Google Scholar - Gerats BG, Wolterink JM, Broeders IA (2023) 3d human pose estimation in multi-view operating room videos using differentiable camera projections. Comput Methods Biomech Biomed Eng: Imaging & Visualization 11(4):1197–1205. https://doi.org/10.1080/21681163.2022.2155580
Article Google Scholar - Shuai H, Wu L, Liu Q (2023) Adaptive multi-view and temporal fusing transformer for 3d human pose estimation. IEEE Trans Pattern Anal Machine Intell 45(4):4122–4135. https://doi.org/10.1109/TPAMI.2022.3188716
Article Google Scholar - Zhou ZH (2018) A brief introduction to weakly supervised learning. National Sci Rev 5(1):44–53. https://doi.org/10.1093/NSR/NWX106
Article Google Scholar - Zhou ZH, Li M (2010) Semi-supervised learning by disagreement. Knowl Inform Syst 24:415–439. https://doi.org/10.1007/s10115-009-0209-z
Article Google Scholar - Eren ME, Bhattarai M, Joyce RJ et al (2023) Semi-supervised classification of malware families under extreme class imbalance via hierarchical non-negative matrix factorization with automatic model selection. ACM Trans Privacy Secur 26(4):1–27. https://doi.org/10.1145/3624567
Article Google Scholar - Wu L, Fang L, He X et al (2023) Querying labeled for unlabeled: Cross-image semantic consistency guided semi-supervised semantic segmentation. IEEE Trans Pattern Anal Mach Intell 45(7):8827–8844. https://doi.org/10.1109/TPAMI.2022.3233584
Article Google Scholar - Yang X, Song Z, King I et al (2023) A survey on deep semi-supervised learning. IEEE Trans Knowl Data Eng 35(9):8934–8954. https://doi.org/10.1109/TKDE.2022.3220219
Article Google Scholar - Zhao H, Jia J, Koltun V (2020) Exploring self-attention for image recognition. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 10076–10085
- Wenxuan Z, Yaqin Z, Zhaoxiang Z et al (2023) Lite transformer network with long-short range attention for real-time fire detection. Fire Technol 59(6):3231–3253. https://doi.org/10.1007/s10694-023-01465-w
Article Google Scholar - Ranjan A, Bolkart T, Sanyal S et al (2018) Generating 3d faces using convolutional mesh autoencoders. In: Proceedings of the European conference on computer vision, Springer, pp 704–720
- Pang S, Peng R, Dong Y et al (2023) Jointmetro: a 3d reconstruction model for human figures in works of art based on transformer. Neural Comput Appl pp 1–15. https://doi.org/10.1007/s00521-023-08844-y
- Kocabas M, Huang CHP, Hilliges O et al (2021) Pare: Part attention regressor for 3d human body estimation. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 11127–11137
- Ionescu C, Papava D, Olaru V et al (2013) Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans Pattern Anal Machine Intell 36(7):1325–1339. https://doi.org/10.1109/TPAMI.2013.248
- Andriluka M, Pishchulin L, Gehler P et al (2014) 2d human pose estimation: New benchmark and state of the art analysis. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 3686–3693
- Mehta D, Sotnychenko O, Mueller F et al (2018) Single-shot multi-person 3d pose estimation from monocular rgb. In: Proceedings of the IEEE International Conference on 3D vision, pp 120–130
- Lassner C, Romero J, Kiefel M et al (2017) Unite the people: Closing the loop between 3d and 2d human representations. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 6050–6059
- Lin TY, Maire M, Belongie S et al (2014) Microsoft coco: Common objects in context. In: Proceedings of the European conference on computer vision, Springer, pp 740–755
- Mehta D, Rhodin H, Casas D et al (2017) Monocular 3d human pose estimation in the wild using improved cnn supervision. In: Proceedings of the IEEE International Conference on 3D vision, pp 506–516
- Deng J, Dong W, Socher R et al (2009) Imagenet: A large-scale hierarchical image database. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pp 248–255
- Loshchilov I, Hutter F (2018) Decoupled weight decay regularization. In: Proceedings of the International Conference on Learning Representations, pp 1–18
- Wang L, Liu X, Ma X et al (2022) A progressive quadric graph convolutional network for 3d human mesh recovery. IEEE Trans Circuits Syst Video Technol 33(1):104–117. https://doi.org/10.1109/TCSVT.2022.3199201
Article Google Scholar - Kolotouros N, Pavlakos G, Jayaraman D et al (2021) Probabilistic modeling for human mesh recovery. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 11605–11614
- Yu Z, Zhang L, Xu Y et al (2022) Multiview human body reconstruction from uncalibrated cameras. In: Proceedings of the International Conference on neural information processing systems, pp 7879–7891
Funding
This work was supported in part by the Youth Innovation Promotion Association of Chinese Academy of Sciences (Y202072) and in part by the Natural Science Foundation of Shandong Province (ZR2021QE205).
Author information
Authors and Affiliations
- School of Biomedical Engineering (Suzhou), Division of Life Sciences and Medicine, University of Science and Technology of China, Hefei, Anhui, 230026, People’s Republic of China
Silong Sheng, Zhijie Ren & Weiwei Fu - Suzhou Institute of Biomedical Engineering and Technology, Chinese Academy of Science, Suzhou, Jiangsu, 215163, People’s Republic of China
Silong Sheng, Tianyou Zheng, Zhijie Ren, Yang Zhang & Weiwei Fu - Jinan Guoke Medical Technology Development Co., Ltd, Jinan, Shandong, 250000, People’s Republic of China
Yang Zhang
Authors
- Silong Sheng
- Tianyou Zheng
- Zhijie Ren
- Yang Zhang
- Weiwei Fu
Contributions
Conceptualization: Silong Sheng; Methodology: Silong Sheng, Tianyou Zheng, Zhijie Ren; Formal analysis and investigation: Silong Sheng, Tianyou Zheng; Writing - original draft preparation: Silong Sheng; Writing - review and editing: Tianyou Zheng, Weiwei Fu, Yang Zhang, Zhijie Ren; Funding acquisition: Weiwei Fu, Yang Zhang; Resources: Weiwei Fu, Yang Zhang; Supervision: Weiwei Fu.
Corresponding authors
Correspondence toTianyou Zheng or Weiwei Fu.
Ethics declarations
Competing interests
The authors have no competing interests to declare that are relevant to the content of this article.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article
Cite this article
Sheng, S., Zheng, T., Ren, Z. et al. SS-MVMETRO: Semi-supervised multi-view human mesh recovery transformer.Appl Intell 54, 5027–5043 (2024). https://doi.org/10.1007/s10489-024-05435-9
- Accepted: 29 March 2024
- Published: 13 April 2024
- Version of record: 13 April 2024
- Issue date: March 2024
- DOI: https://doi.org/10.1007/s10489-024-05435-9