The highly reduced genome of an enslaved algal nucleus (original) (raw)
Main
Soon after the symbiogenetic origin of chloroplasts from cyanobacteria1 to form the common ancestor of green plants, red and glaucophyte algae (kingdom Plantae6,7), even more complex eukaryotic cells arose by secondary symbiogenesis1,3,4 (Fig. 1). Such chimaeric integration of two evolutionarily distant eukaryotic cells occurred independently in the common ancestor of cryptomonads and other chromophytes, in which the endosymbiont was a red alga, and in chlorarachneans, which acquired a green alga1,3,4. In both cryptomonads and chlorarachneans, a flagellate host contributed the nucleus, endomembranes and mitochondria to the chimaera, whereas the photosynthetic endosymbiont provided its chloroplast, plasma membrane (the periplastid membrane1,3,4) and a second nucleus (the nucleomorph), which became miniaturized3,4,5. The nucleomorph of both groups kept its envelope, nuclear pores8 and three minute chromosomes9. In the ancestor of cryptomonads and chromobiotes (treated as kingdom Chromista6,8) but not chlorarachneans, the former food vacuole membrane originally enclosing the enslaved endosymbiont apparently fused with the nuclear envelope10, placing it in the rough endoplasmic reticulum8,10 (RER; Fig. 1). Cryptomonad cells depend on four genomes, each encoding distinct protein synthesis machineries in discrete compartments, between which proteins are translocated. Until now, understanding how these genomes cooperate has been limited by the availability of only partial sequences for nucleomorph genomes11,12.
Figure 1: Secondary symbiogenetic origin and membrane topology of cryptomonads.
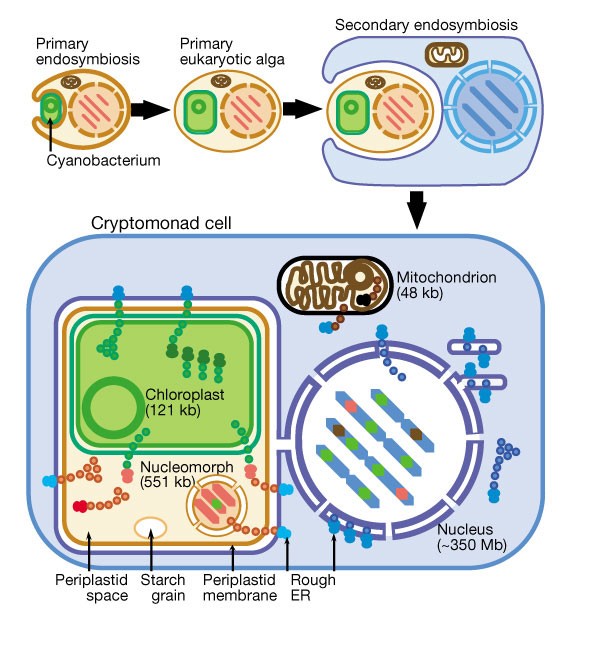
After the primary endosymbiotic incorporation of a cyanobacterium to form the first chloroplast (green), many of its genes were transferred into the host nucleus. After this ancestral plant diversified to form green plants, red algae and glaucophytes, more complex algae were formed by independent secondary symbioses involving green or red algae, after which many or all plastid protein genes were transferred from the algal to the secondary host's nucleus. Shown here is the symbiosis of a red alga to form cryptomonads, where (as in all chromists) the food vacuole membrane fused with the RER. This fusion did not occur in alveolates, chlorarachneans or euglenoids. Former cyanobacterial genes now inserted in nucleomorph or nuclear chromosomes are shown in green, and former red algal genes now in the host nucleus in red. In cryptomonads, the chloroplast and nucleomorph (former red algal nucleus) are topologically in the periplastid space (starch- and ribosome-containing residual cytoplasm of the former red algal cell, yellow) in the periplastid membrane (former red algal plasma membrane), which is located in the lumen of the host's rough endoplasmic reticulum (RER). Chloroplast proteins are coded by three genomes (chloroplast, nucleomorph and nucleus) and mitochondrial proteins by two genomes (mitochondrion and nucleus). Nucleomorph and periplastid proteins are coded by two genomes (nucleus and nucleomorph). Coloured dots indicate protein translocation pathways in the periplastid complex: nuclear- or nucleomorph-encoded proteins targeted to the chloroplast are green; nuclear-encoded proteins imported into the periplastid space, and both nuclear- and nucleomorph-encoded proteins imported into the nucleomorph, are red. Mitochondrial proteins (brown) are encoded by both nuclear and mitochondrial genomes.
We report the first complete genome sequence of a nucleomorph (551,264 base pairs (bp)), which proves conclusively that it is a vestigial nucleus13 and that cryptomonads comprise one eukaryotic cell nested in another. Gene density is extremely high (1 gene per 977 bp) and non-coding regions are ultrashort, with only one pseudogene ϕrpl24 (Fig. 2). The six chromosome ends are identical repeats, comprising telomeres ([AG]7AAG6A)11, 5S and 28S/5.8S/18S ribosomal RNA genes and five open reading frames (ORFs); the ubiquitin conjugation enzyme gene is repeated at five ends, and the TATA-box binding protein gene (tfIId) at three ends. Except in these repeats and five central 200–500-bp regions (possibly centromeric), intergenic spacers have few, if any, nucleotides. Forty-four genes overlap by up to seventy-six nucleotides (Fig. 2). One gene has three copies, one on chromosome 1 (ORF 160a) and two on chromosome 3 (ORF 160b,c); the only other repeated genes are in the termini. Coding regions of some genes are shorter than their homologues in other organisms.
Figure 2: The cryptomonad nucleomorph chromosomes showing gene locations.

Colours show the functional categories of the genes specified in Fig. 3. The number of overlapping nucleotides between adjacent genes is indicated beside the brackets. Each chromosome is displayed as if broken into two fragments near its midpoint. Labels on the left of each chromosome indicate genes transcribed towards its left end (top left); labels on the right show those transcribed towards the right end (bottom right).
Only 17 protein-coding genes contain spliceosomal introns (42–52 bp long; see Supplementary Information), all located in the 5′ region, as in yeast14, many immediately after the initiator AUG. Eleven are in ribosomal protein genes, as in yeast where their splicing negatively regulates messenger RNA levels14. Like the even shorter pygmy introns of chlorarachnean nucleomorphs12, they have standard GT/AG boundaries. Twelve transfer RNA genes have protein-spliced introns. The marked contrast between the effective elimination of non-coding DNA from cryptomonad nucleomorphs and the accumulation of vast amounts of non-coding DNA in coexisting cryptomonad nuclei indicates that nuclear non-coding DNA in general is functional and positively selected5, and is not purely selfish or junk. Chromosomal A+T content varies, suggesting that there have been three different mutational and selective pressures on base composition: on the terminal repeats (45.5% G+C); on housekeeping genes with a very low G+C content (23%); and on transfer RNA genes and genes for plastid proteins with intermediate G+C content (35%).
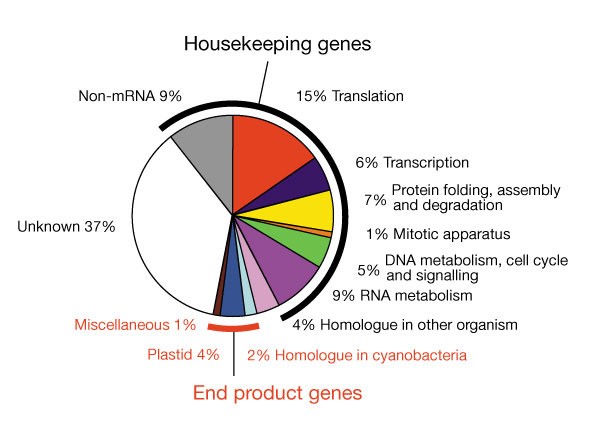
The function of 219 of the 464 putative protein-coding genes is unknown, but 31 have convincing database matches—11 to cyanobacteria and 20 to eukaryotes. Retention of the latter, even in this exceptionally compacted genome, shows that they must have important functions in all eukaryotes. The other 245 genes have homologues of known function, mostly for chromosome reproduction or gene expression, with very few for cytoplasmic functions such as protein assembly and degradation, signal transduction/regulation, cell-cycle control and membrane transport (Fig. 3). Only one gene for metabolism (carotenoid synthesis) was found. There are 47 different genes for non-mRNAs (rRNA, tRNA, small nuclear RNA, small nucleolar RNA).
Figure 3: The fraction of genes in each functional category and their classification as end-product or genetic housekeeping genes.
The genes in each category are listed in the Supplementary Information.
Three conclusions can be drawn about intergenome cooperation in these complex eukaryote/eukaryote chimaeras. First, most identified genes (> 250/302) are needed simply for self-perpetuation of the nucleomorph and its periplastid ribosomes. End products directly useful to the rest of the cell are encoded by only a few genes including 30 chloroplast proteins, 3 transporters (Sut1 for sulphate; Kea1 for potassium; Rli1, an ABC transporter), an anabolic enzyme (Ggt), and a few regulatory enzymes. Second, even fewer cryptomonad plastid proteins are encoded by the nucleomorph than by the plastid genome15, so at least a thousand more1 must be imported into the plastid across four membranes, not two membranes as for nucleomorph-encoded ones. Third, as certain well-conserved genes essential for nucleomorph functions are absent from the nucleomorph genome, these functions must be provided by nuclear genes and imported into the periplastid compartment.
It was not known previously that nuclear gene products not destined for the chloroplast were imported into the periplastid space4. As in mitochondria and chloroplasts, DNA polymerase genes are absent. DNA polymerases must be nuclear encoded and imported across the RER and periplastid membranes, and onwards into the nucleomorphs through their nuclear pores. As we identified so few genes for transporters, most must be encoded by nuclear genes or nucleomorph ORFs. As chromobiotes lost the nucleomorph, they are likely to have homologous transport proteins in their nuclei. If chromists are sisters of alveolate protozoa, sharing a photosynthetic common ancestor1,4,16, some may be also present in Sporozoa, such as malaria parasites, and important for their periplastid membranes and as potential drug targets.
Under 10% of the genes encode end-product functions5 that are useful to the rest of the cell. Originally three end-product functions were envisaged: plastid proteins not made in the chloroplast itself or in the host cytosol; periplastid space functions in starch metabolism; and periplastid membrane transporters mediating metabolite exchange between host and symbiont. We identified 30 genes encoding proteins for chloroplast function, including two known proteins11, but very few for periplastid functions.
Sequence comparisons show that two nucleomorph genes for plastid proteins are eukaryotic inventions (Iap100, Met), one (CbbX) is α-proteobacterial17, and the others are cyanobacterial. Only two encode molecules directly needed for photosynthesis: an electron transfer molecule (rubredoxin)11 and a carotene-binding protein (Hlip). Some genes are needed for chloroplast division (FtsZ11) or gene expression (ribosomal protein Rps15, products for DNA and RNA metabolism, and a factor for RuBisCo expression, CbbX). Others encode components of the chloroplast protein-import machinery (Iap100, Tic22), translocation into the thylakoid lumen (Tha4, SecE), chaperonins (Cpn60, Hcf136) and a protease (ClpP).
All are essential for chloroplast function, explaining why the nucleomorph has persisted for hundreds of millions of years. Compared with their cyanobacterial homologues, the nucleomorph-encoded plastid proteins have amino-terminal extensions (transit peptides; see Supplementary Information) to specify import into the chloroplast, although only those of Hcf136, Cpn60, Tic22 and GyrB were recognized by the search tool ChloroP (http://www.cbs.dtu.dk/services/ChloroP/). Nevertheless, in vitro the N-terminal extension of rubredoxin acts as a transit peptide with pea or cryptomonad plastids and is removed after import18.
Acquiring solar-powered carbohydrate synthesis is the main advantage of enslaving a photosynthetic cell. As glucose produced by degrading periplastid starch is used mainly in the host cytosol, starch metabolism must be responsive to its needs. If the phosphatidylinositol-4-OH kinase (PI(4)K) is associated with the periplastid membrane, it may mediate such signalling through the second messenger inositol trisphosphate. In response, nucleomorph-encoded GTP-binding proteins (GbIp, GTPbp) may regulate periplastid starch metabolism and protein synthesis, as may a protein kinase similar to glycogen synthase kinase; this AMP-activated kinase (AakB) might control starch degradation (like its homologue in animal glycogen degradation). The nucleomorph has four other kinase genes (gs, mps1, snf1, snf2). Protein phosphatase, Pp1, may function complementarily in starch regulation and/or kinase-regulated cell-cycle controls. The presence of a geranyl-geranyl-transferase (Ggt) lacking a transit peptide indicates that at least one intermediate stage in carotenoid synthesis may occur in the periplastid space. As plastids typically make carotenoids using isoprenoid precursors from the host, intermediates presumably traverse the periplastid space.
The red algal symbiont lost mitochondria, peroxisomes, lysosomes, Golgi membranes and most metabolic enzymes. Possibly it also lost all ER lumenal proteins and protein glycosylation, perhaps facilitating an unprecedented simplification of eukaryotic membrane-protein targeting. This red algal vestige may differ from true eukaryotic and bacterial cells by lacking co-translational protein insertion into membranes by the signal recognition particle (SRP): the nucleomorph outer membrane, phylogenetically equivalent to RER8, uniquely lacks obvious surface ribosomes13,19, and we found no 7S SRP RNA or other genes for SRPs. Perhaps nucleomorph envelope and periplastid membrane proteins are inserted post-translationally, as in mitochondria and plastids1 (which analogously both lost the ancestral eubacterial SRP RNA), using the nucleomorph-encoded Hsp70 chaperone.
Genes for DNA polymerase are absent, but there are genes for its sliding clamp (Pcna), a replication co-factor (RfC) for primer extension, and a RecA-like protein (Rad51). Replicon origins might lie in the terminal repeats proximal to the 18S rRNA genes, where there is more non-coding DNA than elsewhere; if there are no others, each chromosome will consist of just two 80–100-kilobase (kb) replicons. As eukaryotic replicons average 100 kb (ref. 20), no origins need lie in unique chromosome regions where intergenic spacers are almost all shorter than the minimal 250 bases needed for origins.
Genes for three core histones (H2b, H3, H4) are present. H2b is exceptionally divergent with its normally acetylated basic N-terminal tail mostly deleted, so nucleosomes may be simplified compared with those of typical nuclei. Histones probably undergo acetylation, as genes for a histone acetyltransferase (Hat) and deacetylase (Hda) are found, and all H3 and H4 acetylation sites are conserved. H3 and H4 genes are adjacent, divergently transcribed and relatively well-conserved, but have evolved more rapidly than nuclear homologues (like most nucleomorph genes). Although H2a and H1 are undetectable, neither is likely to be dispensable, as a string of nucleosomes, unlike a 30-nm filament requiring H1, would be too long for segregation without them.
One gene each for α-, β-, and γ-tubulin is present11, and in addition to γ-tubulin three other centrosomal proteins21 are nucleomorph-encoded—Ranbpm11; Hsp82 (in the cytosolic Hsp90 family) and Hsp 70 (cytosolic family). As centrosome activation involves the cyclinB–cdc2 complex22 (both nucleomorph encoded), mitotic control is present. Nuclear localization signals on Hsp82 and Hsp70 suggest that the centrosome is inside the nucleomorph, consistent with the intact envelope during division19 and the intranuclear red algal spindles. Presence of a centromere-specific H3-like histone (Cenp-A) suggests that nucleomorph chromosomes have centromeres, confirming that nucleomorphs have a relict mitotic apparatus11 despite the lack of ultrastructural evidence for a spindle19.
We cannot be certain of centromere positions. Only the terminal repeats have significant non-coding DNA regions repeated on all chromosomes, but we doubt that they are centromeric because two per chromosome would upset segregation. Assuming nucleomorph centromere sizes to be similar to Saccharomyces cerevisiae23, chromosome 1 has two non-genic regions long enough to be centromeric (520 nucleotides between ORFs 147 and 471; 540 nucleotides between ORFs 244 and 446); chromosome 2 has one (∼200 nucleotides between ORFs 80a and 231); chromosome 3 has two (374 nucleotides between ORFs 141 and 180; ∼300 nucleotides between ORF 62 and Ebi). As these candidate centromere regions are near chromosome midpoints and other intergenic regions seem too short, all three chromosomes may be metacentric.
Eukaryotic chromosomes are linear arrays of looped domains attached to a nuclear skeleton by their replicon origins24. Each nucleomorph chromosome may constitute a single loop domain, being similar in size. If nucleomorph histones compact the DNA into typical 30-nm chromatin threads, the longest chromosome would be 1.5 µm in the absence of higher-order condensation; if metacentric, each chromosome arm would be 0.75 µm. As nucleomorphs are about 1.5-µm across and longer when dividing19, extra folding would be unneccessary for mitotic segregation, unlike for other eukaryotic chromosomes. Compacted chromosomes cannot be seen during nucleomorph division19. Analogous folding constraints may explain why cryptomonad and chlorarachnean nucleomorphs retained three short chromosomes3,9,12 instead of aggregating them into a larger one, which would be feasible only with higher-order mitotic compaction.
Genes for key cell-cycle control proteins include a replication-licensing protein (Mcm2), which mediates the G1/S-phase transition22, and a cyclin-dependent Cdc2 kinase and its cyclin B, which are involved in the G2/M-phase checkpoint. The persistence of a nucleomorph-specific cell-cycle kinase system, even in this simplified cell vestige, emphasizes that it remains conceptually equivalent to a cell, despite its long integration and loss of metabolism and most genes. The nucleomorph encodes ubiquitin (fused to two ribosomal proteins), the ubiquitin-fusion-degradation enzyme (Ufd), and three E2 enzyme subunits (Ubc2, Ubc4, UbcE2). The cell-cycle regulatory role of proteasomes (degrading cyclin B to ensure exit from mitosis, and also controlling exit from S phase25) may be the key reason why such complex multiprotein assemblies as proteasomes and their associated ubiquitin pathway are conserved in the periplastid space, otherwise so reduced in normal cytosolic functions. Supporting this is a gene for an AAA-ATPase (Cdc48; plus a partially related gene cdc48a) implicated in ubiquitin-dependent mitotic events, including membrane fusion26. There are 21 nucleomorph genes for different subunits of the 20S core proteasome and its 19S cap. Two 20S proteasome subunits (α4 and β2) and ten 19S cap subunits are absent, and must be imported like all 11S activator subunits.
Elements of the nuclear pore-complex export/import machinery, the key nucleolar structural protein fibrillarin (Nop1), and elaborate RNA processing machinery confirm that the nucleomorph is a miniaturized nucleus. The surmise13 that nucleomorph envelope pores are genuine nuclear pores is confirmed by well-conserved importin genes (impA; imb1) and a protein interacting with nuclear pores and needed for transport (CRM). Neither transcription nor RNA processing was radically simplified by symbiogenesis. All three RNA polymerases and several transcription factors are nucleomorph encoded, including TfIID for promoter recognition, TfIIB for binding polymerase II, and two components (Rad3; Rad25) of TfIIH. Nucleomorph messengers are probably capped and polyadenylated, for mRNA-capping enzyme (Mce), cap-binding protein (Cbp), and poly(A)-binding protein (Pab) genes exist. Many spliceosomal splicing components (including U6 snRNA and snRNPE, as in chlorarachneans12) and some for tRNA intron removal are present, as are 5 RNAs and 17 proteins of the nucleolar snoRNP machinery for processing rRNA (cleavage, methylation and pseudouridylation). The gene for pseudouridylate synthase is of the eukaryotic type (cbf5) with ancillary centromere–microtubule binding properties, but lacks several normally conserved features. The thesis that snoRNAs are ancestral for all cells but were lost in eubacteria by ‘streamlining’27 is rendered implausible by their persistence in this ultra-streamlined genome.
Thirty-seven genes encode large subunit periplastid ribosomal proteins and 28 small subunit ones, so about 14 are imported or coded by unidentified ORFs. The nucleomorph encodes 37 tRNAs (12 with introns; Table 1) and standard protein synthesis initiation and elongation factors, but only one amino-acyl-tRNA synthetase (seryl). As we found no gene for glutamyl-tRNA, it must be imported unless its codons are recognized by another tRNA with ‘super-wobble’.
Table 1 Codon usage, introns and chromosomal location of tRNA genes
Cryptomonad and chlorarachnean nucleomorphs are natural experiments in genome miniaturization and cell simplification that can test basic ideas about genome and cell functions. If domain organization, folding, and mitotic segregation of nucleomorph chromosomes are indeed exceptionally simplified, they could become important models for understanding the more complex chromosomes of typical nuclei.
Methods
Nucleomorph DNA
As nucleomorph DNA is only about 0.1% of cellular DNA, we could not obtain pure enough samples or sufficient amounts of it for a single mechanically fragmented library. We prepared several libraries slightly contaminated by DNA from the other three genomes: random libraries from the nucleomorph DNA band on CsCl density gradients28 (with major mitochondrial DNA contamination) and others enriched in one individual nucleomorph chromosome extracted from bands excised from pulsed field gels9. DNA was partially digested by _Sau_3AI and cloned into phage λ as described11, or completely digested with one of _Eco_RI, _Hind_III, _Pst_I, _Bgl_II, _Xba_I, _Cla_I, _Spe_I, _Bcl_I or _Bam_HI and cloned into plasmids (pUC18).
Sequencing and gene identification
Sequencing, editing and contig assembly were done as described11. Clones were sequenced fully on both strands by primer walking, and gaps between contigs filled by polymerase chain reaction of genomic DNA. Preliminary gene identification and analysis used MAGPIE29. tRNA and snoRNA genes were detected using the search tools tRNAscan (http://www.genetics.wustl.edu/eddy/tRNAscan-SE) and snoscan30. Further gene analyses used a Perl script to identify all possible ORFs and search them against GenBank (BLAST results available at http://reith.imb.nrc.ca/nucleomorph/nucleomorph.html). Spliceosomal introns were first found manually, and then using a Perl script that searched for conserved splice junctions and extension of the ORF by removing the putative intron.
References
- Cavalier-Smith, T. Membrane heredity and early chloroplast evolution. Trends Plant Sci. 5, 174–182 (2000).
Article CAS Google Scholar - Douglas, S. E., Murphy, C. A., Spencer, D. F. & Gray, M. W. Cryptomonad algae are evolutionary chimaeras of two phylogenetically distinct unicellular eukaryotes. Nature 350, 148–151 (1991).
Article ADS CAS Google Scholar - Maier, U.-G., Douglas, S. & Cavalier-Smith, T. The nucleomorph genomes of cryptophytes and chlorarachniophytes. Protist 151, 103–109 (2000).
Article CAS Google Scholar - Cavalier-Smith, T. Principles of protein and lipid targeting in secondary symbiogenesis: euglenoid, dinoflagellate, and sporozoan plastid origins and the eukaryote family tree. J. Euk. Microbiol. 46, 347–366 (1999).
Article CAS Google Scholar - Cavalier-Smith, T. & Beaton, M. J. The skeletal function of non-genic nuclear DNA: new evidence from ancient cell chimaeras. Genetica 106, 3–13 (1999).
Article CAS Google Scholar - Cavalier-Smith, T. A revised six-kingdom system of life. Biol. Rev. 73, 203–266 (1998).
Article CAS Google Scholar - Moreira, D., Le Guyader, H. & Philippe, H. The origin of red algae: implications for the evolution of chloroplasts. Nature 405, 69–72 (2000).
Article ADS CAS Google Scholar - Cavalier-Smith, T. in Progress in Phycological Research Vol. 4 (eds Round, F. E. & Chapman, D. J.) 309–347 (Biopress, Bristol, 1986).
Google Scholar - Eschbach, S., Hofmann, C. J. B., Maier, U.-G., Sitte, P. & Hansmann, P. A eukaryotic genome of 660 kb: electrophoretic karyotype of nucleomorph and cell nucleus of the cryptomonad alga, Pyrenomonas salina. Nucleic Acids Res. 19, 1779–1781 (1991).
Article CAS Google Scholar - Whatley, J. M., John, P. & Whatley, F. R. From extracellular to intracellular: the establishment of mitochondria and chloroplasts. Proc. Roy. Soc. Lond. B. 204, 165–187 (1979).
Article ADS CAS Google Scholar - Zauner, S. et al. Chloroplast protein and centrosomal genes, a tRNA intron, and odd telomeres in an unusually compact eukaryotic genome, the cryptomonad nucleomorph. Proc. Natl Acad. Sci. USA 97, 200–205 (2000).
Article ADS CAS Google Scholar - Gilson, P. R. & McFadden, G. I. The miniaturized nuclear genome of a eukaryotic endosymbiont contains genes that overlap, genes that are cotranscribed, and the smallest known spliceosomal introns. Proc. Natl Acad. Sci. USA 93, 7737–7742 (1996).
Article ADS CAS Google Scholar - Ludwig, M. & Gibbs, S. P. Are the nucleomorphs of cryptomonads and Chlorarachnion the vestigial nuclei of eukaryotic endosymbionts? Ann. NY Acad. Sci. 503, 198–211 (1987).
Article ADS Google Scholar - Spingola, M., Grate, L., Haussler, D. & Ares, M. Genome-wide bioinformatic and molecular analysis of introns in Saccharomyces cerevisiae. RNA 5, 221–234 (1999).
Article CAS Google Scholar - Douglas, S. E. & Penny, S. L. The plastid genome of the cryptophyte alga, Guillardia theta: complete sequence and conserved synteny groups confirm its common ancestry with red algae. J. Mol. Evol. 48, 236–244 (1999).
Article ADS CAS Google Scholar - McFadden, G. I. Mergers and acquisitions: malaria and the great chloroplast heist. Genome Biol. 1, 1026.1–1026.4 (2000).
Article Google Scholar - Maier, U. G., Fraunholz, M., Zauner, S., Penny, S. & Douglas, S. A nucleomorph-encoded CbbX and the phylogeny of RuBisCo regulators. Mol. Biol. Evol. 17, 576–583 (2000).
Article CAS Google Scholar - Wastl, J. & Maier, U. -G. Transport of proteins into cryptomonads complex plastids. J. Biol. Chem. 275, 23194–23198 (2000).
Article CAS Google Scholar - Meyer, S. The taxonomic implications of the ultrastructure and cell division of a stigma-containing Chroomonas sp. (Cryptophyceae) from Rocky Bay, Natal, South Africa. S. Afr. J. Bot. 53, 129–139 (1987).
Article Google Scholar - Berezney, R., Dubey, D. D. & Huberman, J. A. Heterogeneity of eukaryotic replicons, replicon clusters, and replication foci. Chromosoma 108, 471–484 (2000).
Article CAS Google Scholar - Lange, B. H. M., Bachi, A., Wilm, M. & Gonzalez, C. Hsp90 is a core centrosomal component and is required at different stages in the centrosome cycle in Drosophila and vertebrates. EMBO J. 19, 1252–1262 (2000).
Article CAS Google Scholar - De Souza, C. P., Ellem, K. A. & Gabrielli, B. G. Centrosomal and cytoplasmic Cdc2/cyclin B1 activation precedes nuclear mitotic events. Exp. Cell Res. 257, 11–21 (2000).
Article CAS Google Scholar - Hegemann, J. H. & Fleig, U. N. The centromere of budding yeast. BioEssays 15, 451–460 (1993).
Article CAS Google Scholar - Paul, A. L. & Ferl, R. J. Higher-order chromatin structure: looping long molecules. Plant Mol. Biol. 41, 713–720 (1999).
Article CAS Google Scholar - Kawahara, H. et al. Inhibiting proteasome activity causes overreplication of DNA and blocks entry into mitosis in sea urchin embryos. J. Cell Sci. 113, 2659–2670 (2000).
CAS Google Scholar - Meyer, H. H., Shorter, J. G., Seemann, J., Pappin, D. & Warren, G. A complex of mammalian ufd1 and npl4 links the AAA-ATPase, p97, to ubiquitin and nuclear transport pathways. EMBO J. 19, 2181–2192 (2000).
Article CAS Google Scholar - Poole, A., Jeffares, D. & Penny, D. Early evolution: prokaryotes, the new kids on the block. BioEssays 21, 880–889 (1999).
Article CAS Google Scholar - Douglas, S. E. Physical mapping of the plastid genome from the chlorophyll c-containing alga, Cryptomonas φ. Curr. Gen. 14, 591–598 (1988).
Article CAS Google Scholar - Gaasterland, T. & Sensen, C. W. Fully automated genome analysis that reflects user needs and preferences: A detailed introduction to the MAGPIE system architecture. Biochimie 78, 302–310 (1996).
Article CAS Google Scholar - Lowe, T. M. & Eddy, S. R. A computational screen for methylation guide snoRNAs in yeast. Science 283, 1168–1171 (1999).
Article ADS CAS Google Scholar
Acknowledgements
We are grateful to M. Johannsen for technical assistance; P. Gordon for assistance with MAGPIE; T. Lowe for helping us identify tRNAs and snoRNAs; and R. Redfield for preparing Fig. 1 and valuable comments on the manuscript. Our research was supported by the Natural Sciences and Engineering Council (NSERC), Canada, the Deutsche Forshungsgemeinschaft, Germany, and the NERC (UK). We thank the Canadian Institute for Advanced Research and NERC for fellowships for T.C.-S. and NSERC for a fellowship for M.J.B.
Author information
Author notes
- Martin Fraunholz
Present address: Goddard Laboratories, University of Philadelphia, 415 South University Avenue, Philadelphia, Pennsylvannia, 19104-6018, USA - Margaret Beaton
Present address: Biology Department, Mount Allison University, 63B York Street, Sackville, NB, Canada, E4L 1G7 - Thomas Cavalier-Smith
Present address: Department of Zoology, University of Oxford, South Parks Road, Oxford, OX1 3PS, UK
Authors and Affiliations
- National Research Council of Canada Institute for Marine Biosciences and Program in Evolutionary Biology, Canadian Institute of Advanced Research, 1411 Oxford Street, Halifax, B3H 3ZI, Nova Scotia, Canada
Susan Douglas, Susanne Penny & Michael Reith - Cell Biology and Applied Botany, Philipps-University Marburg, Karl-von-Frisch-Strasse, Marburg, D-35032, Germany
Stefan Zauner, Martin Fraunholz & Uwe-G Maier - Department of Botany, Program in Evolutionary Biology, Canadian Institute of Advanced Research, University of British Columbia, Vancouver, V6T 1Z4, British Columbia, Canada
Margaret Beaton, Lang-Tuo Deng, Xiaonan Wu & Thomas Cavalier-Smith
Authors
- Susan Douglas
You can also search for this author inPubMed Google Scholar - Stefan Zauner
You can also search for this author inPubMed Google Scholar - Martin Fraunholz
You can also search for this author inPubMed Google Scholar - Margaret Beaton
You can also search for this author inPubMed Google Scholar - Susanne Penny
You can also search for this author inPubMed Google Scholar - Lang-Tuo Deng
You can also search for this author inPubMed Google Scholar - Xiaonan Wu
You can also search for this author inPubMed Google Scholar - Michael Reith
You can also search for this author inPubMed Google Scholar - Thomas Cavalier-Smith
You can also search for this author inPubMed Google Scholar - Uwe-G Maier
You can also search for this author inPubMed Google Scholar
Corresponding author
Correspondence toThomas Cavalier-Smith.
Supplementary information
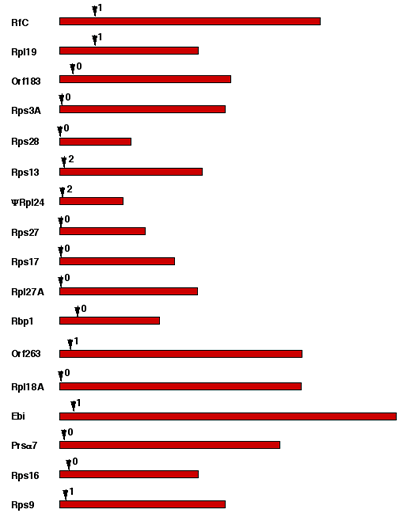
Figure 4.
Locations and phases of spliceosomal introns in nucleomorph genes (GIF 9.22 KB)

Figure 5.
Chloroplast protein transit sequences (GIF 44.6 KB)
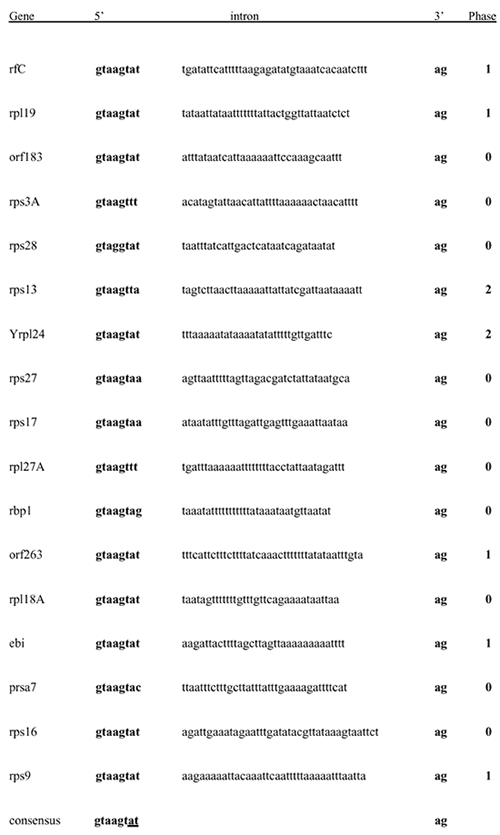
Table 2.
Spliceosomal intron sequences detected in nucleomorph genes (GIF 32.2 KB)
Categories of genes located on the nucleomorph genome
Translation
cbp, EF2, eif1a, eif2b, eif2g, eif4a, eif4e, eif5a, eif6, erf1, ncbP2, rla0, rla1, rpl1, rpl3, rpl5, rpl6B, rpl7, rpl7A, rpl8, rpl9, rpl10, rpl10A, rpl11B, rpl12, rpl13, rpl13A, rpl14, rpl15, rpl17, rpl18, rpl18A, rpl19, rpl21, rpl23 , rpl23A, rpl24, Y rpl24, rpl26, rpl27, rpl27A, rpl30, rpl31, rpl32, rpl34, rpl35A, rpl36, rpl37A, rpl40, rps2, rps3, rps3A, rps4, rps5, rps6, rps8, rps9, rps10B, rps11, rps13, rps14, rps15, rps15A, rps16, rps17, rps19, rps20, rps21, rps23, rps24, rps25, rps26, rps27, rps27A, rps28, rps29A, rsp4, sui1, tif211
Transcription
fet5, hira, hsf, pop2, rad3, rad25, reb1, rpa1, rpa2, rpa5, rpabc5, rpabc6, rpb1, rpb2, rpb3, rpb7, rpb8, rpb10, rpbY, rpc1, rpc2, rpc9, rpc10, tfIIA-S, tfIIB, tfIIB-brf, tfIID, taf30, taf90, trf
Protein folding and degradation
hsp70, hsp82, prsa1, prsa2, prsa3, prsa5, prsa6, prsa7, prsb1, prsb3, prsb4, prsb5, prsb6, prsb7, prsS1, prsS4, prsS6A, prsS6B, prsS7, prsS8, prsS10B, prsS12, prsS13, rbp1, tcpA, tcpB, tcpD, tcpE, tcpG, tcpH, tcpT, tcpZ, ubc2, ubc4, uceE2, ufd
Mitosis
cenp-A, ranbpm, tubA, tubB, tubG
DNA metabolism and cell cycle control
cdc2, cdc48a, cdc48b, crm, cycB, Ebi, H2B, H3, H4, hat, hda, kin(aaB), kin(cdc2), kin(gs), kin(mps1), kin(snf1), kin(snf2), mcm2, pcna, pp1, PI4K, rad51, rfC, ste4
RNA metabolism
ATP/GTP bp, cbf5, cdc28, dbp4, dhm, gblp1, gblp2, gsp2,GTP bp, has1, imb1, imp4, impA, mak16, mce, mrs2, nip7, nog1, nop1, nop2, nop5, nop56, pab1, pab2, prl1, prp8, rcl1, rrp3, sbp1, sen1, sen34, ski2, snrpD, snrpD1, snrpD2, snrpD3, snrpE, snrpF, snrpG, snu13, sof1, ste13, sys1, U5 snRNP (116 kD), U5 snRNP (200 kD)
ORFs with homologues identified in other organisms
orf127, 160, 180, 186, 201, 216, 236, 245, 270, 272, 312, 357, 365, 414, 477, 556, 755, 859
ORFs with homologues identified in cyanobacteria
orf125, 163, 176, 222, 227, 228, 249, 323, 467, 496, 773
Plastid-localised gene products
cbbX, clpP1, clpP2, cpn60, dnaG, ftsZ, gidA, gyrA, gyrB, hcf136, hlip, iap100, met, rpoD, rps15, rub, secE, tha4, tic22
Miscellaneous
fkbp, ggt, kea1, nmt1, rip1, rli1, sut
RNAs
18S rRNA, 28S rRNA, 5S rRNA, 5.8S rRNA, snR1, snR2, snR3, snR4, snR5, U6 snRNA,
tRNAArg(CGU), tRNACys(UGC), tRNAGly(GGA), tRNALeu(UUA), tRNAPro(CCU), tRNAMet(AUG), tRNAAla(GCA), tRNAThr(ACA), tRNAMet(AUG), tRNAGly(GGC), tRNAAsn(AAC), tRNAThr(ACG), tRNALeu(CUU), tRNATrp(UGG), tRNAArg(AGG), tRNAVal(AAC), tRNAPhe(GAA), tRNALeu(CAA), tRNAGln(CUG), tRNAArg(UCG), tRNASer(GCU), tRNALys(UUU), tRNAThr(AGU), tRNAHis(GUG), tRNALys(CUU), tRNASer(AGA), tRNAIle(UAU), tRNACys(ACA), tRNAArg(AGA), tRNASer(UCG), tRNAPro(CCG), tRNAGln(CAA), tRNATyr(UAC), tRNALeu(CUA), tRNAAsp(GAC), tRNAIle(AUU), tRNAVal(GUA)
Unidentified orfs
Not listed
Rights and permissions
About this article
Cite this article
Douglas, S., Zauner, S., Fraunholz, M. et al. The highly reduced genome of an enslaved algal nucleus.Nature 410, 1091–1096 (2001). https://doi.org/10.1038/35074092
- Received: 05 September 2000
- Accepted: 14 February 2001
- Issue Date: 26 April 2001
- DOI: https://doi.org/10.1038/35074092