Proposed methods for testing and selecting the ERCC external RNA controls (original) (raw)
Testing strategy
The testing work is divided into five sequential phases to coincide with the specific aims listed above. Milestones will be used to indicate the completion of each phase (Table 2).
Table 2 Summary of testing phases
The proposed methods and specific tasks associated with each phase of testing are described in the following sections. The testing will be performed in parallel by three working groups: microarray group, QRT-PCR group and informatics group. A fourth group responsible for RNA production will be contracted by NIST during phase 1. All of the ERCC members will participate in the documentation and publication tasks.
Tasks for transcript and other reagent production subgroup
This section describes the production and quality control processes for the candidate external RNA clones used in testing. NIST will be soliciting these manufacturing tasks through standard governmental procurement process.
Phase 1 – design and development
• Collect clones
DNA clones for candidate external RNA controls will be collected and stored in a NIST laboratory. Preliminary sequence information will also be collected from each clone contributor. Each clone will be assigned a unique identification number that coincides with all bioinformatic nomenclature specification requirements. A list of all candidate external RNA controls with vector, insert characteristics for the DNA plasmids and E. coli clones (strains carrying plasmids) will be compiled. This file will also contain the potential plasmids, which will be used for the production of the external RNA controls. A portion of the DNA plasmid or E. coli stock will be sent to the selected manufacturer(s) for the production of the ERCC reagents to be used in the testing project.
• Verify DNA sequence
Each plasmid will be grown in a small scale (~10 ml culture), purified and used for DNA sequence verification. Primer extension reactions will be designed to obtain full-length insert sequences. Both strands will be sequenced. These sequence files will be compared to the sequence submitted by the clone contributor. It will be important to verify both the presence of a polyA tail and the 3' restriction site to be used for linearization during in vitro transcription (IVT) template preparation. Ambiguities will be noted and will be further investigated by re-sequencing and database comparisons. The ERCC Informatics subgroup will determine the "correct" sequences to be used for microarray probe and QRT-PCR primer design. Once all of the sequences have been collated and verified, these plasmids will be used for the next phase of production.
• Produce bacterial stocks and plasmids
All of the clones will be grown in 1 liter cultures to generate 1–2 mg of plasmid DNA. Samples of the bacterial cultures will be saved to create two sets of triplicate glycerol stocks properly labeled and stored at -80°C. One set will be sent to NIST and one set will remain at the manufacturer's site until the completion of the project, at which time the second set will be also be returned to NIST. Each purified plasmid will undergo a set of quality control tests to measure DNA concentration, confirm purity and verify the ability to be linearized at a restriction site located 3' of the polyA tail region. This last confirmation ensures the usability of the clones in the IVT reactions. The sequence will be re-verified using a single pass primer extension from the RNA polymerase promoter sequence (e.g., T7, T3).
• Digest plasmids
Each plasmid will be linearized by restriction digestion using the appropriate amount of DNA needed to produce the specified amount of transcript. The plasmids will be inspected by high quality agarose gel electrophoresis to ensure complete digestion. The linear plasmids will be purified and concentrations will be normalized to 1 mg/ml.
• Test IVT template
Approximately 1 ug of each linear plasmid will be used in a 20 ul IVT reaction. The resulting RNA transcript will be diluted and inspected on an Agilent 2100 Bioanalyzer. This analysis will determine whether the size of the RNA transcript matches the expected length for each plasmid and whether any of the IVT reactions produced aborted products. At this stage, the observed transcript RNA yields will be used to calculate the efficiency of IVT reactions for each plasmid. Transcription problems will be addressed at this stage and will help dictate reaction volumes needed for the large scale IVT reactions in the next phase of production.
• Produce RNA transcripts
The IVT reactions will be scaled-up to produce the desired specified amount of RNA transcript, with considerations of RNA recovery and reasonable overage. Immediately after IVT, a small amount of RNA will be analyzed on the Agilent 2100 Bioanalyzer. If the transcript RNA is the expected size, it will enter into a large scale RNA purification method. The final purified RNA will be normalized to a concentration of ~1 mg/ml. These will be known as the "Production RNA Transcript Stocks".
• Verify quality of transcript stocks
The quality of the Production RNA Transcript Stocks will be assessed for several characteristics, including concentration, purity, integrity, stability and size. Concentration will be determined using rigorously developed standard operating procedures for UV absorbance. Purity has two aspects: the integrity of the transcript (i.e., percentage of full length transcript) and the stability of the transcript (i.e., presence of low levels of nucleases). The quality of the stock transcripts will also be confirmed by measuring the length of the RNA to determine if it matches the expected size. The Agilent 2100 Bioanalyzer will be used for analysis of integrity, stability and nucleotide length.
• Prepare individual stocks of RNA transcripts
The individual RNA transcripts will be diluted in RNA Storage Buffer (citrate buffer pH 6.3) and normalized to 100 ng/ul at 1000 nt in length. For example, RNA transcripts that are 750, 1200, and 2000 nt in length will be diluted to 75, 120 and 200 ng/ul respectively.
To determine the molar concentration of 1000 nt transcript, a formula or software script will be used to calculate exact molecular weight (MW) given RNA sequence. The RNA (single-stranded) molecular weight will be calculated for the phosphorylated, protonated form of the molecule using the following formula:
MW = (#A × 329.21) + (#C × 305.18) + (#G × 345.21) + (#U × 306.17) + 18.02
Stocks of individual RNA transcripts will be available in two forms: 96- well plates or screw-top tubes. Each RNA will be diluted and 50 ul aliquots of each normalized concentration will be transferred to a pre-specified well of a 96-well plate. Wells will be spot-checked for volume. Plates will be sealed with tape. Barcode tracking will be utilized to identify lots and all other tracked information. Plates will be labeled, dated and stored at -80°C until final packaging and shipping. The RNA transcripts will also be distributed in individual tubes at an equal molar concentration (to be determined).
• Prepare pools of RNA transcripts
A series of RNA mixtures will be made according to the experimental plans. A description of all the pools required for microarray testing is presented in Table 3. The QRT-PCR testing generally relies on a series of dilutions of equal molar pools of the RNA transcripts (pools 0 and 11 in Table 3).
Table 3 Description of pools and experiments in microarray testing
• Manufacture pre-labeled cRNA
The RNA transcripts will be reverse transcribed with an oligo(dT)-T7 promoter primer and second strand synthesis will be performed to create cDNA templates for the synthesis of pre-labeled cRNA for each external RNA control. To allow testing in multiple microarray platforms, three types of cRNA labels will be used: biotin, DIG and amino-allyl. This labeled cRNA will be purified and quantified as above, normalized to equal molar concentrations, and pooled as shown in Table 3 to construct accurate standard signal intensity response curves for each oligonucleotide probe feature corresponding to the external RNA controls.
Tasks for microarray subgroup
This section describes the testing methods necessary to develop a set of external RNA controls that can be used to assess the technical performance of microarray experiments. It is anticipated that many of the microarray vendors will participate in the ERCC testing, including Applied Biosystems, Affymetrix, Agilent, GE Healthcare and Illumina. Spotted, non-commercial microarrays will also be contributed by the USDA and NCI. This collection of microarray products include both one-color platforms, which hybridize one labeled target to a single microarray, and two-color platforms, which hybridize two targets with different labels to a single microarray.
The microarray testing phases are designed to evaluate the candidate external RNA controls on both one-color and two-color platforms using the same pools of transcripts. Many of the experiments are designed to initially generate sufficient, quality data using relatively few microarrays and pools of transcripts. They may be expanded to a larger range of transcript concentrations and/or a greater number of replicate samples, as desired. A description of all required external RNA control pools is presented in Table 3. This plan assumes that phase 1 begins with 144 candidate external RNA controls and that a putative set of approximately 96 clones has been selected for further characterization by phase 3.
Phase 1 – design and development
• Design probes and generate commercial microarrays
After sequence verification, each array manufacturer will design probes targeting all of the candidate external RNA controls and generate microarrays to be used during testing.
• Design probes and generate non-commercial microarrays
Long DNA oligonucleotide (70-mer) probes will be designed by a joint effort of USDA and TIGR upon completion of sequence collection and in silico validation. The oligonucleotides will be synthesized with 5' amine modifications through a custom synthesis and spotted on glass slides.
Phase 2 – prototype testing
The goals of the Prototype Testing phase, addressed in two experiments, are to ensure that the RNA transcript stocks and the probes to detect each of the external RNA controls exhibit a basic level of functionality.
• Test probes for cross-hybridization
The first experiment is designed to check for unacceptable levels of cross-hybridization between the full set of candidate probes. To observe hybridization characteristics apart from labeling efficiencies, cRNA targets for each external RNA control will be pre-labeled with biotin, DIG or amino allyl molecules and pooled before hybridization. Assuming 144 candidate external RNA controls, the pre-labeled targets will be split into three pools (e.g., controls 1–48 in pool 1, controls 49–96 in pool 2 and controls 97–144 in pool 3) and a fourth pool of all pre-labeled transcripts will be generated. For one-color platforms, each pool of targets will be hybridized separately in triplicate against the test arrays. For two-color platforms, the pool 1–3 transcripts will be coupled to Cy3, while the pool 4 transcripts will be coupled to Cy5. Each test pool of Cy3-labeled transcripts will be hybridized in triplicate against reference pool 4 of Cy5-labeled transcripts.
Each pool will initially be tested in the absence of labeled background cRNA. The expected result is that probes will only show a significant signal when the target they were designed against is in the pool hybridized to the array (i.e., 1 of the 3 pools). Examination of the relative signals for the probes whose targets were hybridized to the arrays should allow identification of probes that show potential cross-reactivity to another sequence included in the same pool. As a negative control, three arrays will be hybridized to cRNA targets generated from at least one representative background human sample in the absence of any external RNA controls. This representative background RNA sample will be from a human tissue (or set of tissues) chosen from the Microarray Quality Control Project [[18](/articles/10.1186/1471-2164-6-150#ref-CR18 "MicroArray Quality Control Project. [ http://www.fda.gov/nctr/science/centers/toxicoinformatics/maqc/index.htm
]")\] currently underway at the FDA-NCTR. As described in the previous section, RNA from other species can also be tested for cross hybridization. Probes with minimal cross hybridization will be incorporated into the set of 96 external RNA controls that are further characterized in phase 3.• Confirm labeling and dose response abilities
The second experiment in the Prototype Testing phase will test whether the external RNA controls can be labeled in the presence of a complex background of total RNA. It will also demonstrate their ability to detect known differences in transcript abundance between two pools. One pool will contain external RNA controls in one of two concentrations (e.g., controls 1–72 at 1:10,000 and controls 73–144 at 1:40,000) in the representative human background total RNA. A second pool will be created in which the concentrations are reversed. Both pools will go through three independent target preparation reactions and hybridizations. For one-color platforms, each labeled pool of transcripts will be hybridized to a separate microarray. For two-color platforms, targets from both pools can be labeled with different Cy dyes and hybridized to the same microarray. The observed ratios across the two pools will be compared to the expected 4-fold change. External RNA controls that do not label or give the expected response (something reasonably close to a 4:1 intensity ratio) will be removed from the pool of candidate external RNA controls.
Phase 3 – proof of concept
• Perform modified latin square and graeco-latin square experiments
During the Proof of Concept phase, specific acceptance metrics will be determined and the performance of each external RNA control will be tested over a range of concentrations. 1:5,000,000 to 1:1,000. The experimental design for this phase of array testing must meet the following three criteria: 1) Require a minimal number of arrays and pools; 2) Introduce transcripts as series of pools with balanced cRNA load that are made at a central site, rather than in individual testing labs; and 3) Use the same pools on both one-color and two-color platforms.
To best achieve these objectives, this phase of array testing is based on modified versions of a Latin Squares design for one-color platforms and a Graeco-Latin Square design for two-color platforms [19]. Illustrations of these types of experiments are given in Figure 1. Panels A and B describe a 4 × 4 experiment where four different transcripts are tested at four different concentrations. Panels C, D and E show how the same 4 × 4 experiment can be accomplished on two different platforms using the same four pools of transcripts.
Figure 1

Illustrations of latin square and graeco-latin square designs. "A1" to "A4" number the 4 arrays used in the experiment, "G1" to "G4" number the 4 transcripts being studied and "L1" to "L4" denote 4 different concentrations for each transcript. The four pools of transcripts are labeled "W" to "Z". "g" and "r" note the gene concentrations or pools used in the green or red channel, respectively of a two-color experiment.
Phase 3 will characterize a putative set of clones that are selected based on their performance in phase 2. In this discussion, we will assume the set includes 96 clones. These external RNA controls will be split into four groups of 24 controls each (groups A through D in Table 4). Four pools of external RNA controls will be created such that for each pool, each of the four groups of controls will be at a different concentration (i.e., a different relative mass). For simplicity, multiple transcripts are present at the same concentration in this modified design, rather than each transcript at a different concentration. This design can be referred to as a modified (or semi-) latin square experiment.
Table 4 Concentration of controls in dilution 1 pools for modified latin square experiments
The four pools will be spiked into four independent target preparation reactions in the presence of the complex background human total RNA. A single experiment will consist of triplicate hybridizations of these four samples (see Table 5). For one-color platforms, each pool will be hybridized to a separate microarray. For two-color platforms, one pool labeled with Cy3 and another pool labeled with Cy5 will be hybridized to the same microarray. As a negative control, three arrays will be hybridized to cRNA targets generated from the background human sample without any external RNA controls. During analysis, data from both the one-color and two-color arrays will be normalized using the distribution of signals from the external RNA control probes, rather than to signals from the probes that hybridize to the background RNA. This normalization approach eliminates the need for dye swap experiments with two-color arrays.
Table 5 Modified latin square hybridization setup
• Expand the range of concentrations tested
A benefit of this simplified design is that it measures the performance of a large number of external RNA controls with only 12 arrays (plus the three negative control arrays), allowing for wider participation during this phase of testing, instead of limiting participation to those facilities that are able to run the potentially hundreds of arrays required for complete Latin Square or Graeco-Latin Square experiments. The potential drawback to this design is that it allows for measurement of only a limited number of target concentrations. For those interested in measuring the external RNA control performance across a wider range of target concentrations, the experiment can be expanded without the requirement of additional pools. This expansion can be accomplished by diluting each of the pools further to establish other concentration ranges, prior to introducing them into the background human total RNA.
Examples of three such dilution ranges are provided in Table 6. In this illustration, the four pools described in Table 3 are diluted 2-fold, 4-fold or 40-fold to generate Dilution 2, Dilution 3 and Dilution 4 pools, respectively. Sixteen possible pools for testing are generated, which are labeled based on their pool and dilution numbers: P7-D1; P7-D2; P7-D3; P7-D4; P8-D1; P8-D2; P8-D3; P8-D4; P9-D1; P9-D2; P9-D3; P9-D4; P10-D1; P10-D2; P10-D3; and P10-D4.
Table 6 Concentration of controls in dilution pools for expanded range experiments
Participants can choose to test a few or many different ranges. Testing all four ranges (i.e., the original stock plus Dilutions 2–4) would consume 48 arrays (plus the three negative control arrays) and would measure each of the 96 potential external RNA controls at 16 concentrations ranging from an estimated mass ratio of 1:1,000 down to 1:5,000,000.
For one-color arrays, each pool would be hybridized to a separate array, so that 48 microarrays would be required to generate triplicate sets of data. For two-color platforms, one pool labeled with Cy3 and another pool labeled with Cy5 will be hybridized to the same microarray. From these experiments we will determine the concentration range over which each target responds linearly. Additionally, we will determine the limit of detection, linear range, and resolvable fold-change across the linear range for each external RNA control. As shown in Table 7, the simultaneous hybridizations on two-color platforms enable differential expression evaluations of red/green ratios from 1/125 (0.008) to 125.
Table 7 Expected red:green ratios in two-color hybridizations
Phase 4 – functional testing
• Test dose response curve pools
A typical dose response curve (DRC) experiment consists of testing each external RNA control at multiple concentrations, one per array, requiring several arrays. In contrast, a single array DRC experiment consists of multiple concentrations and multiple external RNA controls per concentration, all tested on a single array. Because the entire experiment is contained within a single array, each external RNA control is measured only at a single concentration. Therefore, the intensities from all of the probes are used together to construct the DRC across the entire concentration range. During the Functional Testing phase, the target metrics determined during the Proof of Concept phase will be used to create a single-array DRC external RNA control pool. An example single array DRC pool is shown in Table 8.
Table 8 Example single array DRC pool
To keep the ratio of external RNA controls to background RNA as low as possible, the higher concentrations of external RNA controls (e.g., 1:1,000) are under-represented compared with the lower concentrations (e.g., 1:100,000). Additionally, external RNA controls originating from the same species will be evenly distributed across the concentration range to minimize the effects of removing them from experiments performed with background RNA from the same species.
Up to three pooling schemes will be tested, each with triplicate hybridizations. For one-color platforms, each labeled DRC pool of transcripts will be hybridized to a separate microarray. For two-color platforms, targets from different DRC pools can be labeled with different Cy dyes and hybridized to the same microarray (e.g., pool 12 and 13 or pool 13 and 14).
• Perform forced failure experiments
Once the final single array DRC pool has been chosen, a small series of forced failure experiments will be carried out to mimic how the system will respond to common failure modes (e.g., incorrect temperature, incorrect buffer composition, extreme washing stringency, etc.).
Phase 5 – performance review
• Review and publish the experimental results
Results will be shared within the ERCC for review and evaluation to determine if additional data or redesign is indicated.
• Repeat experiments in different labs
Tasks for QRT-PCR subgroup
The QRT-PCR testing phases are designed to use the same pools of transcripts developed for microarray testing and to evaluate the candidate external RNA controls on multiple QRT-PCR platforms. There are two commonly used methods of detecting the QRT-PCR amplicons: DNA-binding dyes (e.g., SYBR Green I) and target-specific probes with fluorescent 5' exonuclease activity (e.g., TaqMan®). The testing plan will generate data on both platforms, using the same primer sets. The DNA-binding detection assays will use a single tube, one enzyme (rTth) and SYBR Green I based protocols. The target-specific detection assays will use a two-step protocol developed for the TaqMan® system.
Phase 1 – design and development
• Design QRT-PCR primers and detection probes
All primers for external RNA controls will be designed using commonly used software. Two sets of QRT-PCR primers (one at 3' and one at 5' end) will be finalized and used to determine the entirety and specificity of RNA transcripts. For target-specific detection assays, a fluorescent 5' exonuclease detection probe will also be designed. The sequences of all QRT-PCR reagents and their locations on the RNA transcripts as well as the sizes of amplicons and their predicted Tm will be provided to the community. All primers and detection probes will be blasted against Genbank for potential cross-reactivity.
• Define cycling parameters
With the DNA-binding detection assays, the concentration and ratio of primers must be optimized to prevent fluorescent signal from "primer dimers" or nonspecific amplicons. Experiments will be performed to develop amplification parameters for ABI 7900HT and Stratagene MX3000 using a single tube, one enzyme (rTth) and SYBR Green I based QRT-PCR protocol. With the target-specific detection assays, the primer and detection probe concentrations and thermal cycling conditions will be as suggested by the manufacturer. cDNA will be generated using standard kits and random primers prior to amplification.
• Assist in verifying quality of transcript stocks
QRT-PCR will be used to assess the quality of the RNA transcripts produced for each of the candidate external RNA controls. Individual transcripts will be evaluated for entirety, stability, and DNA contamination. The specificity of each primer set and detection probe will be determined by amplifying individual transcripts in equal molar pools of the candidate controls. QRT-PCR can also be used to verify transcript ratios in pools with variable concentrations of the candidate controls.
Phase 2 – prototype testing
• Test primers for cross-reactivity
Each set of QRT-PCR primers as well as any detection probes will be tested for cross-reactivity with other external RNA transcripts by amplifying its perspective RNA transcript from three different RNA sources. First, individual transcripts will be amplified from a pool containing multiple RNA transcripts at equal molar concentration (pool 0 in Table 1). Second, individual transcripts will be amplified from the same pools of multiple RNA transcripts at equal molar concentration introduced into a human total RNA background. The human background RNA increases the complexity of the reaction and may be based on a reference RNA sample, for example a pool of RNA derived from 10 different human tissues. Third, individual transcripts will be amplified from the human total RNA that lacks external RNA controls. All amplicons will be examined by gel electrophoresis or melting dissociation curves. The Ct values of amplification for each transcript under other RNA background should be very similar to those with only pure RNA transcripts. If any QRT-PCR reagent gives unexpected products, the primers and/or the detection probe will be re-designed and re-tested.
• Optimize efficiency of QRT-PCR
A 10-fold serial dilution from 108 copies to 1 copy will be made for a pool of all candidate RNA transcripts in an equal molar concentration. The RNA dilutions will be used for examining the amplification efficiency of at least one QRT-PCR primer set, and for some platforms the corresponding detection probe, for each RNA transcript. Ideally, with a given dilution of the pool, all QRT-PCR primer sets will amplify their perspective targets with similar efficiency. Otherwise, the primer sets and detection probes with a low efficiency should be re-designed and re-tested.
• Determine limit of detection
Since all molecular weights and sequences are known, the physical copies of each RNA transcript in the pool of all candidate RNA transcripts can be calculated. One RNA transcript will be chosen as a standard for concentration determination and the relative concentrations of other RNA transcripts will be determined based on this standard. All possible efforts should be made to determine the copy number of each transcript by QRT-PCR close to its physical copy number of the RNA transcript in the pool. The lowest concentration of each transcript in the pool of all candidate RNA transcripts, which can be detected by QRT-PCR amplification, can be considered as the limit of detection for that transcript.
• Assist in verifying quality of pools
QRT-PCR will be used to assess the ratios of different RNA transcripts in different pools. Note that due to different amplification efficiencies in RT and PCR, there may be a discrepancy between the ratios determined by QRT-PCR and those measured by physical quantity.
Phase 3 – proof of concept
• Establish acceptance criteria for RNA transcripts
Based on the phase 2 results, a set of up to 96 external RNA controls will be selected for further testing. Using the 10-fold serial dilutions of a pool of these 96 RNA transcripts (pool 11 in Table 1), limit of quantification, linearity, precision and accuracy for each of RNA transcript will be determined, and the acceptance criteria of assay performance for each RNA transcript will be established. Those criteria should be established for the pure RNA transcripts as well as for the pure RNA transcripts under a background of other total RNA, such as human RNA reference.
Phase 4 – functional testing
• Compare QRT-PCR platforms and instruments
The QRT-PCR testing will generate data from both DNA-binding and target-specific detection assays on multiple thermal cycling instruments, including ABI 7000, ABI 7900HT and Stratagene MX3000. The results will be useful to evaluate the technical performance between those different instruments and platforms.
• Compare microarray and QRT-PCR platforms
Assay performance of a set of selected external RNA transcripts or pools with the same or different concentrations will be evaluated by microarray and QRT-PCR. The results will be very useful to guide the comparison of experimental results generated by microarray and QRT-PCR.
• Optimize external RNA concentrations
External RNA controls can be used for monitoring the amplification processes or for detecting the presence of possible inhibitors in QRT-PCR amplification. Optimal concentrations of external RNA transcripts should be established so that the concentrations of the introduced external RNA controls are low enough to detect the presence of possible inhibitors, but not too low that the variation of the assay would be indistinguishable from the low assay performance caused by inhibitors. Different concentrations of a given external RNA transcript will be spiked in total human RNA. The optimal concentration of an external RNA transcript would give a Ct about 30–32. Clinical RNA specimens extracted from different tissues and purified by different sample preparation methods can be used for evaluating the optimal concentrations of external RNA transcripts.
• Conduct forced failure experiments
To establish the utility of external RNA controls for detecting potential QRT-PCR inhibitors, a few known QRT-PCR inhibitors, such as ethanol and guanidine thiocyanate, will be introduced into QRT-PCR reactions along with external RNA controls. An impaired QRT-PCR reaction of external RNA controls could indicate the presence of possible QRT-PCR inhibitors in the RNA preparation.
• Evaluate multiplex QRT-PCR assays
Multiplex assays are possible when different reporter dyes are coupled to different target-specific probes so that cleavage of the multiple probes can be detected in a single PCR. These multi-color assays may also be performed.
Phase 5 – performance review
• Review and publish the experimental results
• Repeat experiments in different labs
To establish the reproducibility of the research and diagnostic utilities of external RNA controls, the experiments described in phase 4, multi-site testing will be performed.
Tasks for informatics subgroup
The ERCC is committed to delivering an informatics approach that can be used to establish the technical performance of an expression measurement through the analysis of the measured response of external spiked-in RNA controls. This approach will be implemented and delivered in an open-source manner, such as R code for a bioconductor package.
The informatics requirements for ERCC development will include sequence bioinformatics links to public annotation databases. Sequence informatics will be delivered via these public resources.
The scope of ERCC informatics activity will not include examination of the application of external RNA controls for purposes other than evaluation of the technical performance of an expression measurement. Such applications as normalization to spike-in controls, or calibration, or evaluation of selectivity and specificity, while potentially useful, are left to assay development efforts for specific intended use applications.
Phase 1 – design and development
• Develop sequence bioinformatics
The sequence data will need to be managed in a sustainable fashion using established tools and approaches. At this stage, sequence bioinformatics includes both a nomenclature system and a maintainable archive of sequences. The nomenclature system requires unique identifiers as well as consistent annotation for RNA control sequences and the related PCR reagents and microarray probes across various platforms. A preliminary nomenclature system is presented in Table 9.
Table 9 Illustration of a nomenclature system
The sequence archive requirements are as follows: 1) data will be stored in FASTA format; 2) where appropriate, annotation will include unambiguous cross-references to gene identifiers in public databases; and 3) maintainability and version control.
• Explore analytical approaches
The Analytical Informatics work in this phase is exploratory and will establish prototype tools for the potential analysis approaches. The major tasks for the analytical informatics work at this phase are: 1) identify appropriate QRT-PCR analysis approaches; 2) investigate various analysis approaches for microarray technical performance, including evaluation of preprocessing strategies (e.g., data normalization); 3) develop prototype tools that can be used for the exploration of the analysis approaches; and 4) test prototype tools using existing or synthetic data.
The analysis approaches that will be explored in this phase will include:
Approach 1 – chi square fit of a linear portion of a calibration curve from the external RNA controls (Figure 2).
Figure 2
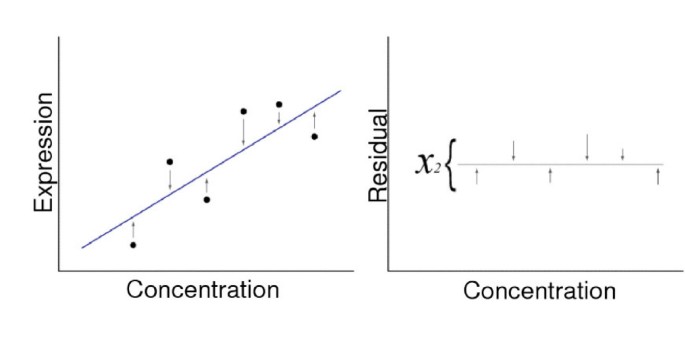
Illustration of chi square fit. Panel A. The distances from a straight-line fit (arrows) are calculated. Panel B. The Chi square fit of the distances is then determined.
Approach 2 – ratio of observed/known concentration ratios between nearest-neighbor spikes versus concentration of low spike in pair (Figure 3).
Figure 3

Illustration of spike performance.
Approach 3 – linear range
1. To characterize an external RNA transcript response we can describe signal in response to target concentration by the following general function.

Here, S – signal from microarray element, a – variable incorporating parameters such as number of probes per microarray element, number of fluorescent label molecules per target molecule, power of light etc., φ – a function describing thermodynamics of hybridization isotherm and this function has a vector of parameters ( ) which is unique for each probe, c – concentrations of spike-in target, _b_-background due to dark detector counts and sources of light other than labeled targets.
) which is unique for each probe, c – concentrations of spike-in target, _b_-background due to dark detector counts and sources of light other than labeled targets.
2. Let μ s (c) be a function describing relationship between expected signal and spike concentration. Also, let ε S (c) be a function describing relationship between standard deviation of signal and spike concentration.
3. Define signals S and S* (S < S*) as reliably resolved if

Define concentration levels

and  ( <) as reliably resolved if expected signals produced by these concentrations are reliably resolved.
( <) as reliably resolved if expected signals produced by these concentrations are reliably resolved.
Define concentration fold change –

as reliably resolved if concentration levels and are reliably resolved.
Define linear range as

where and are the ends of the longest interval of target concentrations such that f (c t ) ≤ 2 ∀ c t ∈ (, ).
Thus, the linear range is the largest continuous interval of target concentrations such that a two fold increase of concentration anywhere within this interval gives rise to reliably resolved expected signal levels.
4. Using these assumptions we will explore several models to determine linear range and minimal reliable resolved concentration fold change.
Approach 4 – fitting the spike-in probe behavior on an individual array to a reference model of known, acceptable performance (Figure 4).
Figure 4
Illustration of model data (including modeled noise). The values of m and b that were input into the model were m = 0.85 and b = 0.08. The noise model is realistic, in that it includes both constant (scanner) and proportional (chemical) noise.
For 1-color arrays signal intensity can be described as:
Log2_I_ = target concentration + probe affinity + background + E
A reference dataset can be used to estimate probe affinity and background for each of the probes or probe sets. This should allow for a more accurate estimation of the target concentration of the external RNA controls.
For 2-color arrays we can use the following model to analyze spike-in ratios:

Where m and b are the slope and intercept from a least-squares fit.
This model has the nice feature of physically reasonable and appealing interpretations of the slope and intercept. The intercept is the log of the bulk normalization constant for the external RNA control (i.e., the model is self-normalizing, independent of the normalization of the background samples carrying the spike-ins). The slope measures ratio flattening (i.e., reduction of the absolute value of the log ratio from its expected value, due to such effects as cross-hybridization of other targets to the spike-in probes). The model clearly differentiates between failures to observe expected ratios that are due to normalization and effects that are due to ratio flattening. This is important, because the two effects are often confused and misdiagnosed.
Approach 5 – ANOVA modeling.
There are several potential approaches to analyzing the variance in the experiment:
• The variability between repeated probes on the same array. This will give an indication of the variability due to spatial distribution and spot deposition.
• Other ANOVA models are possible depending on the experimental design and the variables captured in the experiment.
Approach 6 – additional robust measures for performance metrics will be explored.
Phase 2 – prototype testing
• Develop and test prototype analytic code
Implementations for the analytical approaches will be developed in the prototyping phase. These implementations will be tested against modeled/simulated data, as well as against existing data, where possible. As data become available from the QRT-PCR and microarray testing activities, those data will be used to evaluate the prototype analytical implementations. The analyses may be implemented with a variety of numeric and graphical tools (e.g., spreadsheets or proprietary statistical tools).
Phase 3 – proof of concept
• Qualify analytic models
At this stage of the project, data will become available from the array and QRT-PCR testing activities. These data will be used to test the prototype implementations of the analysis approaches, and those approaches will be refined as appropriate. Refinements will be tested and qualified. At the end of this stage, the approaches will be sufficiently refined to move forward to implementation for functional testing.
Phase 4 – functional testing
• Prototype open source code for analytics
This stage of the project will focus on developing implementations of the analysis approaches in R as a bioconductor package. This package should be validated to work with array data from the variety of microarray platforms being tested. Refinement of the graphical display of analysis results will emphasize platform-to-platform consistency where possible (so similar analytical graphs are presented for 1- and 2-color, and the variety of platforms). The QRT-PCR analysis approach may be developed as a separate bioconductor package, with the emphasis likely to be on a graphical display of performance measures as a time series.
• Develop web-based interface for analytics
Development of web-based implementations of the analysis implementations will be investigated, and common data formats for input and output will be specified and implemented.
• Qualify final analytic strategy
Phase 5 – performance review
• Publish bioconductor package
The bioconductor package will be published and released to the community. A manuscript will accompany publication of the package, describing the analytical approaches embodied in the package, and demonstrating performance with the validation data. All relevant performance data from the testing and development of the ERCC analytical informatics will be collated and published at this time.
• Publish sequence database
The reference sequence database will be published and made available on the web in both flat-file formats and a common sequence database format (FASTA).
• Publish relevant performance data
Performance data from the testing will be published. Collate performance data (from Test Reports), including probe performance data, in backgrounds.
Test plan tasks for ERCC
• Identify least burdensome path for collection and distribution of data
• Organize analysis jamboree
• Plan publication of results and timing for publication(s)
• Organize controls symposium