DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation (original) (raw)
Chengxi Li*1, Yiming Wang*1,2, Tianyi Zhang*3, Ruiqi Zhong*4,
Luke Zettlemoyer5,6, Scott Wen-tau Yih6, Daniel Fried7, Sida Wang6, Tao Yu1,5
1The University of Hong Kong, 2Peking University, 3Stanford University, 4University of California, Berkeley, 5University of Washington, 6Meta AI, 7Carnegie Mellon University
DS-1000 is a code generation benchmark with a thousand data science questions spanning seven Python libraries that (1) reflects diverse, realistic, and practical use cases, (2) has a reliable metric, (3) defends against memorization by perturbing questions.
Abstract
We introduce DS-1000, a code generation benchmark with a thousand data science problems spanning seven Python libraries, such as NumPy and Pandas. Compared to prior works, DS-1000 incorporates three core features. First, our problems reflect diverse, realistic, and practical use cases since we collected them from StackOverflow. Second, our automatic evaluation is highly specific (reliable) – across all Codex-002-predicted solutions that our evaluation accepts, only 1.8% of them is incorrect; we achieve this with multi-criteria metrics, checking both functional correctness by running test cases and surface form constraints by restricting API usages or keywords. Finally, we proactively defend against memorization by slightly modifying our problems to be different from the original StackOverflow source; consequently, models cannot answer them correctly by memorizing the solutions from pre-training. The current best public system (Codex-002) achieves 43.3% accuracy, leaving ample room for improvement.
Data Statistics and Examples
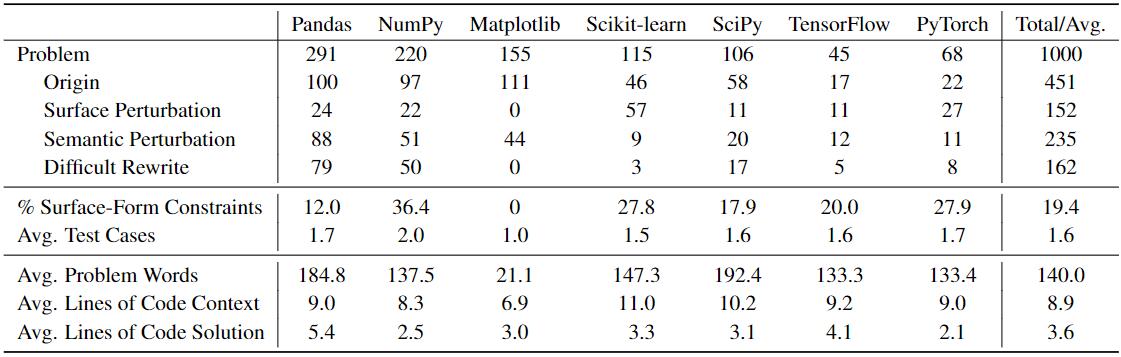
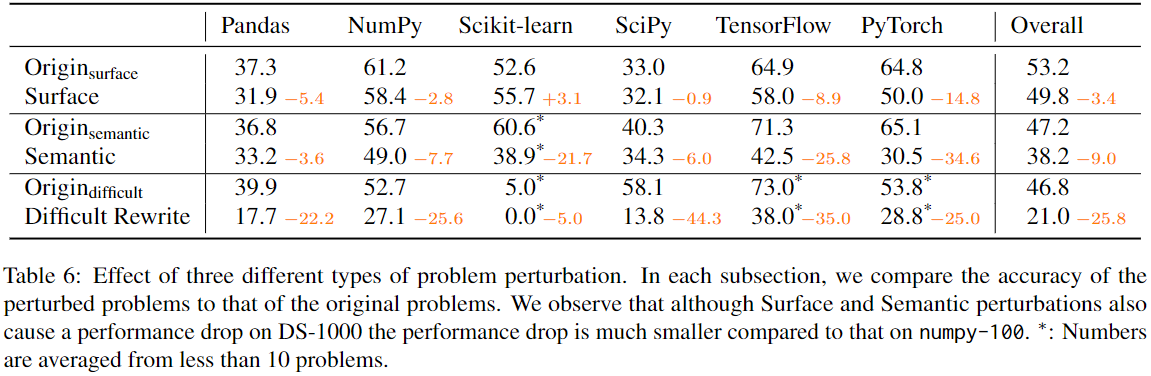
DS-1000 contains 1000 problems originating from 451 unique StackOverflow problems. To defend against potential memoriza- tion, more than half of the DS-1000 problems are modified from the original StackOverflow problems; they include 152 surface perturbations, 235 semantic perturbations, and 162 difficult rewrites.
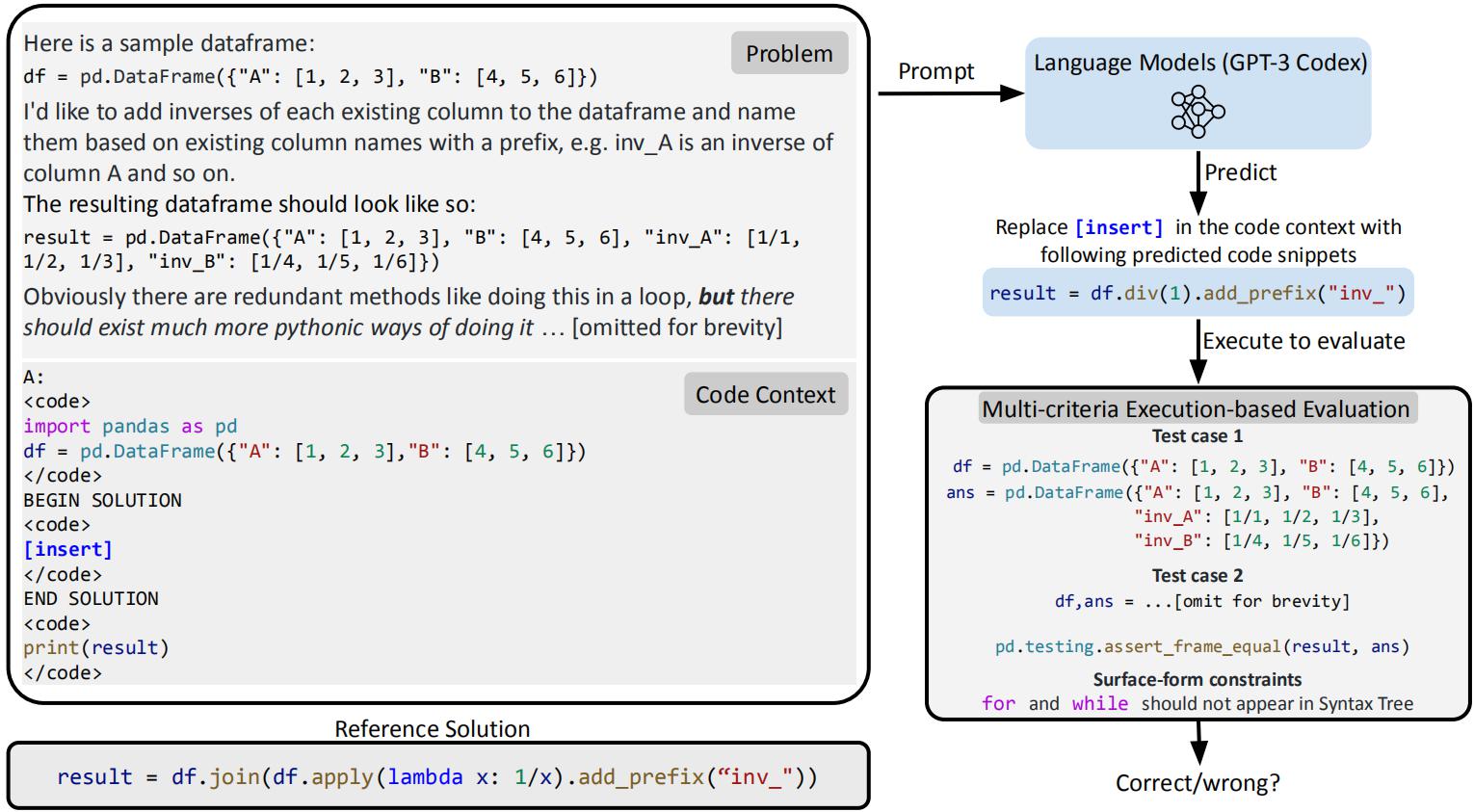
Below are more DS-1000 examples. For each example, The model needs to fill in the code into “[insert]” in the prompt on the left; the code will then be executed to pass the multi-criteria automatic evaluation, which includes the test cases and the surface form constraints; a reference solution is provided at the bottom left.
- NumPy
- SciPy
- Pandas
- TensorFlow
- PyTorch
- Scikit-learn
- Matplotlib

NumPy example problem involving randomness, requiring the use of a specialist knowledge test.

An example problem of SciPy. Specific checking on conversion between dense matrix and sparse matrix.

An example problem of Pandas. We need to write reference solutions by ourselves because high-vote replies from StackOverflow ignore the requirement "but does not exactly match it".

An example problem of TensorFlow. We implemented well-designed test function for tensor comparison.

An example problem of PyTorch, with failed attempt and error message given in description.

An example problem of Scikit-learn, requiring applying sklearn preprocessing method to Pandas dataframe.
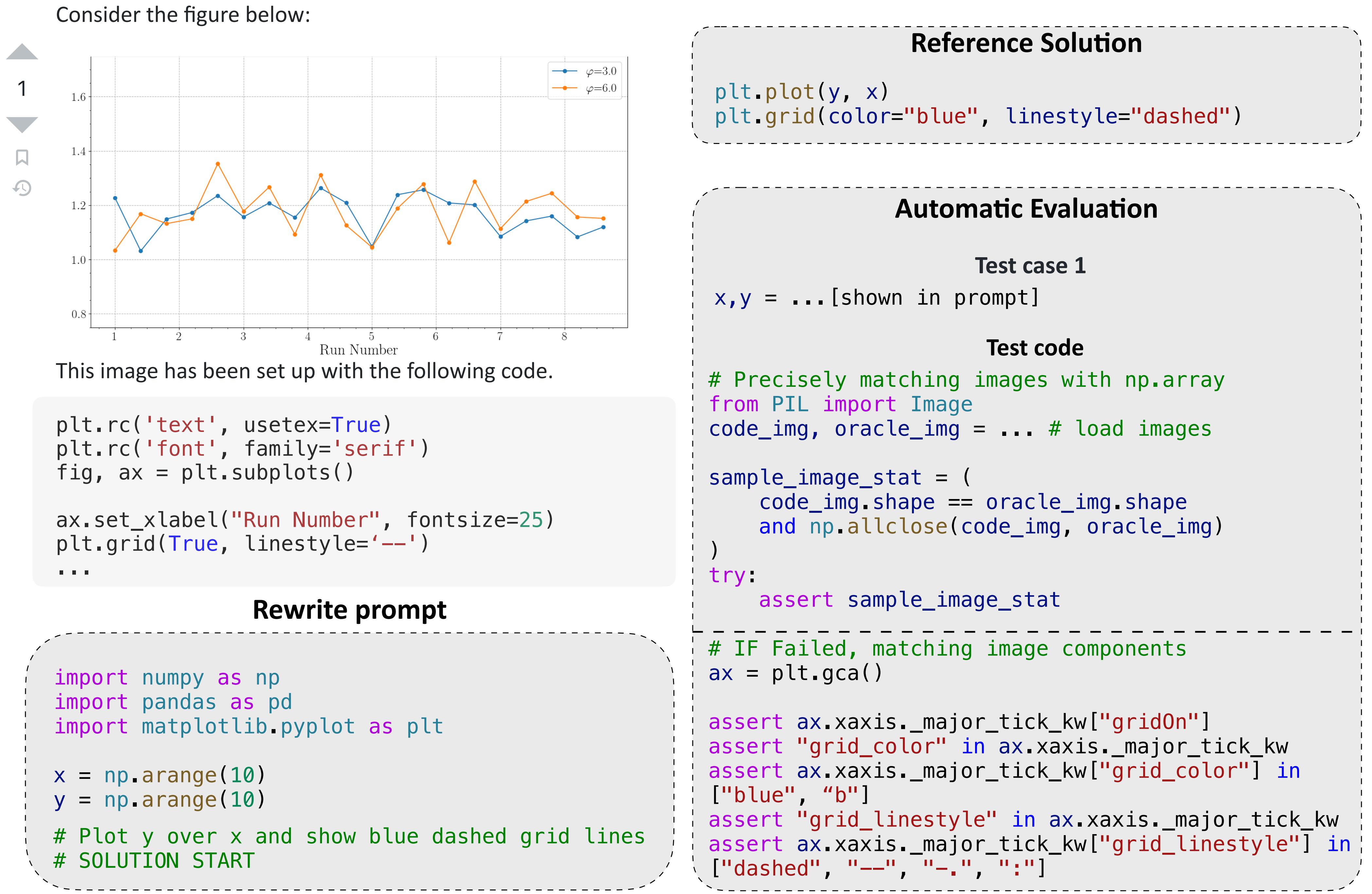
An example problem of Matplotlib. Matplotlib original questions often contain example figures which cannot be processed by current code models. We rewrite original questions into standalone questions in the form of comments.
Perturbation and Prompt
For questions from StackOverflow, we equipped them with prompts, test cases, and evaluation functions and called them Origin. To prevent models simply recalling the solutions seen during pre-training, we have perturbed the questions in two ways: surface perturbations and semantic perturbations. To make DS-1000 more challenging, we additionally introduced Difficult Rewrite.
- Origin: Equipped them with a prompt, testcases, and an evaluation function.
- Surface Perturbation: We paraphrased the question or modified the code context in the question, but the reference solution should stay the same after the perturbation.
- Semantic Perturbation: We changed the semantics of the reference solution without changing its difficulty.
- Difficult Rewrite: More complex and more difficult.
We also provided an Insertion style prompt and a Completion style prompt for each question (including perturbation).
- Insertion: Models need to predict what should be written in the place of "[insert]".
- Completion: Models need to predict what should b written after the prompt.
Here is the performance of Codex-davinci-002 on DS-1000.
Here are more prompts, you can copy them and run the models on the playground of OpenAI.
- Insertion
- Completion
- Surface Perturbation
- Semantic Perturbation
- Difficult Rewrite
Insertion:
Problem:
Let's say I have a 1d numpy positive integer array like this:
a = array([1,0,3])
I would like to encode this as a 2D one-hot array(for natural number)
b = array([[0,1,0,0], [1,0,0,0], [0,0,0,1]])
The leftmost element corresponds to 0 in `a`(NO MATTER whether 0 appears in `a` or not.), and the rightmost vice versa.
Is there a quick way to do this only using numpy? Quicker than just looping over a to set elements of b, that is.
A:
<code>
import numpy as np
a = np.array([1, 0, 3])
</code>
BEGIN SOLUTION
<code>
[insert]
</code>
END SOLUTION
<code>
print(b)
</code>
Completion:
Problem:
Let's say I have a 1d numpy positive integer array like this:
a = array([1,0,3])
I would like to encode this as a 2D one-hot array(for natural number)
b = array([[0,1,0,0], [1,0,0,0], [0,0,0,1]])
The leftmost element corresponds to 0 in `a`(NO MATTER whether 0 appears in `a` or not.), and the rightmost vice versa.
Is there a quick way to do this only using numpy? Quicker than just looping over a to set elements of b, that is.
A:
<code>
import numpy as np
a = np.array([1, 0, 3])
</code>
b = ... # put solution in this variable
BEGIN SOLUTION
<code>
Surface Perturbation:
Problem:
Let's say I have a 1d numpy positive integer array like this
a = array([1,2,3])
I would like to encode this as a 2D one-hot array(for natural number)
b = array([[0,1,0,0], [0,0,1,0], [0,0,0,1]])
The leftmost element corresponds to 0 in `a`(NO MATTER whether 0 appears in `a` or not.), and the rightmost corresponds to the largest number.
Is there a quick way to do this only using numpy? Quicker than just looping over a to set elements of b, that is.
A:
<code>
import numpy as np
a = np.array([1, 0, 3])
</code>
BEGIN SOLUTION
<code>
[insert]
</code>
END SOLUTION
<code>
print(b)
</code>
Semantic Perturbation:
Problem:
Let's say I have a 1d numpy integer array like this
a = array([-1,0,3])
I would like to encode this as a 2D one-hot array(for integers)
b = array([[1,0,0,0,0], [0,1,0,0,0], [0,0,0,0,1]])
The leftmost element always corresponds to the smallest element in `a`, and the rightmost vice versa.
Is there a quick way to do this only using numpy? Quicker than just looping over a to set elements of b, that is.
A:
<code>
import numpy as np
a = np.array([-1, 0, 3])
</code>
BEGIN SOLUTION
<code>
[insert]
</code>
END SOLUTION
<code>
print(b)
</code>
Difficult Rewrite:
Problem:
Let's say I have a 1d numpy array like this
a = np.array([1.5,-0.4,1.3])
I would like to encode this as a 2D one-hot array(only for elements appear in `a`)
b = array([[0,0,1], [1,0,0], [0,1,0]])
The leftmost element always corresponds to the smallest element in `a`, and the rightmost vice versa.
Is there a quick way to do this only using numpy? Quicker than just looping over a to set elements of b, that is.
A:
<code>
import numpy as np
a = np.array([1.5, -0.4, 1.3])
</code>
BEGIN SOLUTION
<code>
[insert]
</code>
END SOLUTION
<code>
print(b)
</code>
Comparison
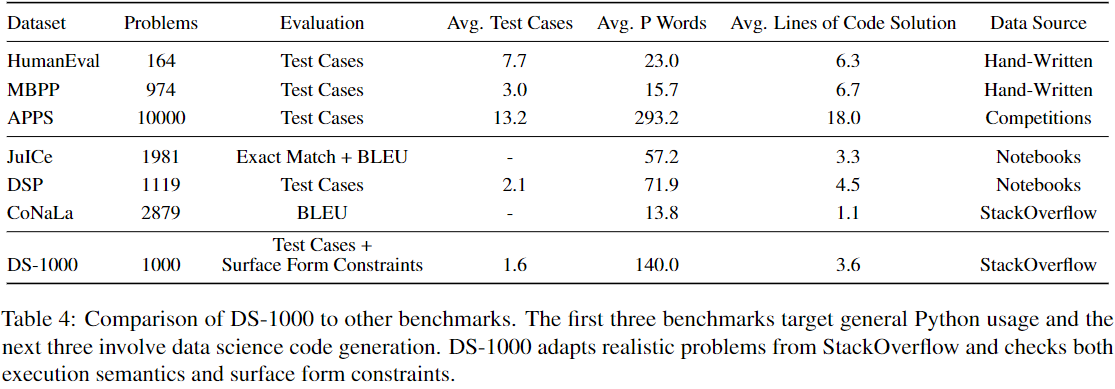
Table 4 compares DS-1000 to other datasets. Notably, the average of problem words in DS-1000 is much larger compared to other data science related datasets (e.g., DSP and CoNaLa).
More importantly, the problems in DS-1000 represent more diverse and naturalistic intent and context formats that cannot be seen in any other datasets.
Unlike generic Python code generation benchmarks (MBPP and HumanEval), we note that data science code generation benchmarks have fewer test cases since the annotators need to define program inputs with complex objects such as square matrices, classifiers, or dataframes than simple primitives, such as floats or lists.
Nevertheless, even a few test cases suffice for DS-1000 – only 1.8% of the Codex-002-predicted solutions accepted by our evaluation are incorrect.
Acknowledgement
We thank Noah A. Smith, Tianbao Xie, Shuyang Jiang for their helpful feedback on this work.
BibTeX
@article{Lai2022DS1000,
title={DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation},
author={Lai, Yuhang and Li, Chengxi and Wang, Yiming and Zhang, Tianyi and Zhong, Ruiqi and Zettlemoyer, Luke and Yih, Wen-Tau and Fried, Daniel and Wang, Sida and Yu, Tao},
journal={ArXiv},
year={2022},
volume={abs/2211.11501}
}