en.planet.wikimedia.org (original) (raw)
Latest tech news from the Wikimedia technical community. Please tell other users about these changes. Not all changes will affect you. Translations are available.
Weekly highlight
- The Abstract Wikipedia team has identified five potential pilot wikis to assess their interest in adopting abstract articles on their wikis. The pilots are Malayalam, Bengali, Dagbani, Arabic, and Indonesian Wikipedia. The feedback period will be open until May 22. If your community is interested in becoming a pilot, let us know on Meta.
Updates for editors
- An experiment to show Reading Lists to logged-out readers on mobile web will launch on May 18 across German, Spanish, Italian, Portuguese, Polish, Dutch, Turkish, and Urdu Wikipedias, and will run for one month. The effort supports broader goals of helping readers save and organize articles for later reading, while encouraging habits that could lead to future Wikipedia contributions.
- To support a bookmark button in the Reading List beta feature, the “Tools > Action” menu has been updated to display icons, including the watch star indicator that helps editors identify temporarily watched articles. The icons now also match those used on mobile, improving consistency across platforms. The change is currently limited to the actions menu and mainly affects editors with privileged user rights. [1]
- Suggestion Mode was released as an A/B test for newcomer editors on the mobile website at ~15 Wikipedias. The experiment will measure the impact that Suggestion Mode has on the proportion of newcomer mobile web edit sessions that result in constructive (un-reverted) article edits. The experiment will also evaluate the feature’s impact on editor retention, and monitor changes in revert and block rates.
 View all 27 community-submitted tasks that were resolved last week. For example, an issue in the Wikipedia Android app where images could sometimes fail to load after opening a recommended reading list notification, has now been fixed. [2]
View all 27 community-submitted tasks that were resolved last week. For example, an issue in the Wikipedia Android app where images could sometimes fail to load after opening a recommended reading list notification, has now been fixed. [2]
Updates for technical contributors
- The Wikidata Platform team has published its backend replacement recommendation and accompanying technical architecture for the migration of the Wikidata Query Service (WDQS) away from Blazegraph. Feedback is invited until May 25th 2026, especially on potential gaps and impacts on advanced use cases. Wikidata community members and WDQS users are also encouraged to help identify high-impact tools and workflows that may need attention on this page. Feedback can be shared on the Migration talk page or during the next office hour. See the WDP team newsletter for more details.
- Detailed code updates later this week: MediaWiki
In depth
- On English, French, Japanese, and a few other Wikipedias, there was a trial of hCaptcha, a third-party bot detection service. The trial showed that hCaptcha effectively detects and deters some bad-faith automated activity, on its own and by giving checkusers and stewards signals to look into. Because the results were positive, hCaptcha will be rolled out across all wikis over the next few weeks. See the hCaptcha project page for technical information about the implementation and privacy protections. Learn more.
- The latest Community Tech update is now available, with progress across several Community Wishlist initiatives, including Reading Lists expansion from the mobile app to the website, new language support for “Who Wrote That” and the Personal Dashboard, improvements to 3D rendering and Charts, and upcoming work on talk page sorting, audio playback, and editing workflows. The update also shares current priorities, wishlist status trends, and opportunities for community feedback on future focus areas and the Wikimedia Foundation’s 2026–2027 Annual Plan. Read the full newsletter for details.
Tech news prepared by Tech News writers and posted by bot • Contribute • Translate • Get help • Give feedback • Subscribe or unsubscribe.
For 25 years, Wikimedia volunteers have built the largest collection of open knowledge in the world. Millions of people access that content every day, starting from readers worldwide engaging with knowledge directly on Wikimedia projects, to smart speakers, AI chats, and other new formats summarizing or repackaging our content. New channels expand access to knowledge, but where that content came from is often hidden or obscured. For people encountering information from a Wikipedia article in anLLM answer or a Commons image used in an indie game, it may be unclear how it was processed, or how to find more context about it.
While new ways for people to gain knowledge are welcome, this shift in visibility also poses a challenge to the sustainability of Wikimedia projects. Without visibility, the pathway for new readers to become the next generation of contributors and donors is lost, ultimately affecting the mechanisms that ensure the continued vibrancy of the community and quality of the content.
To address these challenges, the Wikimedia Foundation is releasing two tools: the Wikimedia Attribution Framework V1 and the Attribution API [beta]. These tools make it simple for developers to fairly credit volunteer contributions and ensure a healthy free knowledge ecosystem. When anyone encounters Wikimedia content, we want them to know that it comes from our projects, and they are invited to participate.
Read on to learn more about what they are, why they matter, and how you can help shape their next steps.
Why Attribution Matters: A Symbiotic Ecosystem
Attribution isn’t just about credit; it’s about sustaining the free knowledge ecosystem. The changing trends around direct traffic to Wikimedia websites signals the shift to a new paradigm where access to Wikimedia content is more diverse and distributed. As more content is consumed in external environments beyond the wikis, we want to help readers recognize Wikimedia content anywhere and motivate them to participate in the free knowledge ecosystem.

The diagram illustrates a vision for a healthier Wikimedia knowledge ecosystem. Those who reuse our content elsewhere provide participation pathways back to Wikimedia projects.
We want good attribution practices to be as easy to apply as possible, to help reusers seamlessly invite their audiences in different contexts to engage with Wikimedia content (through deeper reading, donating, or editing) before they even visit our sites. With clear visibility and greater recognition of Wikipedia’s ubiquitous value, more people will continue to participate and keep the healthy, virtuous cycle of high quality, free knowledge for everyone.
Introducing the Attribution Framework V1
The Wikimedia Attribution Framework sets guidelines on how to provide sustainable attribution when reusing Wikimedia content. The framework is designed to be flexible. This makes it possible to apply it to different reuse scenarios (such as Search, AI Assistants, Social media and more) while providing a consistent experience overall.

The image shows examples of the Attribution Framework recommendations for attributing Wikimedia content shown in search results, and when generated in AI assistant responses.
All reuse scenarios are based on a catalog of standardized signals. These have been organized in different levels:
- Essential Attribution: The foundational elements required to meet the obligations set by the relevant open licenses, while keeping off-wiki readers aware of the original communities that created the content. These signals make it straightforward for developers to satisfy licensing requirements for different content types, including clearly indicating whether content has been summarised or otherwise changed by the reuser (instead of being cited verbatim).
- Trust & Relevance. Signals that highlight the credibility and living nature of Wikimedia content, while piquing readers’ curiosity and interest. Contributor and reference counts reveal the depth of collaborative, human effort behind each article, communicating that many people worked together and have sources to back it up. Additional signals like pageviews, last-updated timestamps, and trending indicators further reinforce the relevance and vitality of the content.
- Ecosystem Growth. Active interventions inviting users to participate. Providing additional info and call to actions (CTAs) readers can take to be more involved in the open knowledge ecosystem. Inviting readers to “Create an account”, “Download the app”, or “Donate” can be relevant ways to participate depending on the context.
The Attribution Framework compiles best practices for the attribution of Wikimedia content, making it easy for external reusers to apply them to their particular case. Organizations and developers interested in applying the framework to a specific context can find the documentation and the visual representations that illustrate how attribution can be provided in specific scenarios within the Attribution Framework. Guidance is defined in a flexible way, with multiple options to adjust the scenarios to the particular context using configurable examples.
The initial release of the framework represents an early beta version, which will evolve over time with more use cases, signals and CTAs. We want to learn from external reusers, developers, and interested members of the Wikimedia community, and improve the framework based on their feedback.

The Developer Solution: The Attribution API (Beta)
Attribution considerations are relevant to a broad audience of reusers of Wikimedia content. Those making games, offering search services, using project content for research, building alternative reading experiences, or contributing to anything else happening off-wiki, probably need to properly attribute Wikimedia content.
However, this task has not always been easy for developers. In the past, external developers building products based on Wikimedia content had to stitch together complex requests or parse raw HTML to meet license requirements and display rich attribution signals. These barriers often led to Wikipedia content being reused with sub-optimal attribution.
The Attribution API (currently available as a betamodule) complements the guidelines provided in the Attribution Framework to make it easy for developers to obtain the data they need to properly attribute Wikipedia articles and media files from Commons. It abstracts the complexity behind a simple endpoint that returns exactly the information required by the framework’s signals on a per-page basis. Reusers may also flexibly filter and target the specific signals relevant to each scenario or product need. As we continue to invest in this space, we expect to offer additional endpoints for project-level attribution, easier ways to get attribution information for the images embedded in articles, and more. Upcoming and recent changes can be tracked on the Attribution API project page.
NOTE: Although the attribution framework is designed for everyone, this specific API is primarily intended for mission-supporting users and use cases. Wikimedia Enterprise will offer similar information in their structured responses for high volume commercial reusers, who are expected to follow the same Attribution framework guidelines. For more information about all of the options for retrieving attribution signal data, see the technical implementation section of the Attribution Framework.
Participate!
The Attribution Framework and API are at an early stage. They have been released to start learning from different reusers in different situations, and will evolve based on your feedback.
You can read the attribution framework guidelines to review the recommended practices for attribution. Learn more about the project on the project page, and reach out if you’re interested in being featured as an early adopter or to share any thoughts.
You can also explore the Attribution API in the REST Sandbox, which is currently available on all Wikimedia Foundation hosted wiki projects, such as English Wikipedia or Meta-wiki, follow along on the project page, and give us feedback on your experience.
The Wikimedia Language Diversity Hub is excited to announce an upcoming online workshop: Wiki Admin 101 for Language Communities, scheduled forMay 30, 2026, from 12:00 PM to 1:30 PM UTC. This event is designed to support emerging and underrepresented Wikimedia language communities by introducing them to the fundamentals of Wikimedia project administration and user-extended rights.
As more indigenous, minority, and under-resourced language communities establish and grow Wikimedia projects, there is an increasing need for capacity building around administrative responsibilities and community project management. This training aims to provide contributors with practical knowledge and tools that can help strengthen the sustainability and effectiveness of their language communities within the Wikimedia movement.
The session will introduce participants to the roles and responsibilities of Wikimedia administrators, including page protection, vandalism management, deletion processes, user rights, moderation practices, and transparent community decision-making. Participants will also gain insight into how healthy governance structures can support collaboration, trust, and long-term community growth.
The workshop is particularly relevant for contributors working within the Wikimedia Incubator, newly approved Wikimedia projects, and communities preparing for future project growth. Through interactive discussions and practical demonstrations, attendees will learn how administrative tools can be used to maintain quality content while fostering inclusive and welcoming community spaces.
The event forms part of the broader work of the Wikimedia Language Diversity Hub in supporting linguistic diversity across Wikimedia projects. The Hub continues to organize mentorship programs, technical workshops, and collaborative learning opportunities that empower communities working in indigenous and marginalized languages.
DATE and TIME**: Saturday, May 30, 2026, from 12:00 PM to 1:30 PM UTC**.
Community members interested in participating can learn more and register through the event page on Meta-Wiki:
Wiki Admin 101 for Language Communities Event Page
To learn more about the Wikimedia Language Diversity Hub and its ongoing initiatives, visit:
Wikimedia Language Diversity Hub

AWC 2026 Diff Banner, by 1Kdee22, via Wikimedia Commons (CC BY-SA 4.0).
The Africa Wiki Challenge (AWC) 2026marks a significant milestone in a growing continental effort to strengthen Africa’s presence in the global digital knowledge ecosystem. Under the theme “WATER FOR LIFE IN AFRICA”, this year’s edition calls on Africans and global contributors to document one of the continent’s most vital yet underrepresented realities—its water systems, sanitation infrastructure, and environmental water governance. Across Africa, water remains central to life, shaping health outcomes, agriculture, ecosystems, livelihoods, and economic development, yet much of this knowledge remains fragmented or absent from global platforms such as Wikipedia and its sister projects including Wikimedia Commons, Wikidata, and Wikivoyage.
Initiated by Open Foundation West Africa in 2021, the Africa Wiki Challenge has evolved into a pan-African knowledge movement spanning over 30 countries and engaging hundreds of editors across the continent and diaspora. It was created to address the persistent gap in Africa’s digital representation, where African content and contributors remain significantly underrepresented in comparison to global averages. Through collaborative editing, media contributions, and structured data development, the campaign has already contributed to thousands of new and improved articles, strengthening Africa’s visibility online and advancing the principle that Africans must be the primary narrators of their own stories. The 2026 theme builds on this mission by focusing specifically on water an essential resource that is deeply tied to climate resilience, public health, sustainable development, and social equity across African communities.
This year’s focus, “Water for Life in Africa,” aligns with theAfrican Union’s Agenda 2063 vision and broader continental development priorities, emphasizing the need for sustainable management and equitable access to water resources. Participants will be encouraged to create, improve, and enrich content related to rivers, lakes, wetlands, groundwater systems, sanitation infrastructure, water supply systems, climate change impacts on water availability, water governance policies, indigenous water management practices, and innovative community-led solutions addressing water challenges. The challenge also highlights sanitation systems and hygiene infrastructure, which remain critical in many regions where access is still limited or unevenly distributed.

Adam Jones from Kelowna, BC, Canada, CC BY-SA 2.0 via Wikimedia Commons
Campaign Details
Scheduled to run from 28 May to 30 June 2026, the Africa Wiki Challenge 2026 will empower students, researchers, journalists, environmental advocates, and Wikimedia volunteers to contribute across multiple platforms including Wikipedia, Wikimedia Commons, Wikidata, and Wikivoyage.
Participants can:
- create and improve articles on Africa’s water resources and sanitation systems, helping close critical content gaps
- upload photos, videos, and media that visually document water infrastructure and environmental realities across communities
- contribute structured data and knowledge that improves visibility, accessibility, and global understanding of Africa’s water and environmental heritage
The campaign officially launches on Thursday, 28 May 2026 through a virtual event that will introduce the theme, participation guidelines, and collaboration opportunities for contributors across the continent and beyond. Participants can join the launch session via: Join Africa Wiki Challenge 2026 Launch Webinar.
Ultimately, the Africa Wiki Challenge 2026 is more than a documentation initiative—it is a collective effort to preserve Africa’s liquid heritage, amplify local knowledge systems, and ensure that the continent’s water story is told accurately, visibly, and by its own people. Through sustained participation, the initiative strengthens Africa’s voice in the global knowledge commons while contributing meaningfully to sustainability, education, and digital inclusion across the continent.
Register now! Join the Africa Wiki Challenge 2026, and let’s help document and tell the stories of water, communities, and change across Africa.
![]()
When I joined the Wiki Science Competition 2025 in India, I wanted to show that meaningful scientific documentation can also be created through a mobile phone camera. What began as a simple participation journey eventually became one of the most memorable Wikimedia experiences for me.
The competition, organized as India’s first national edition of the international Wiki Science Competition, invited contributors to upload freely licensed scientific photographs to Wikimedia Commons. The initiative focused on science communication, open knowledge, biodiversity, laboratory documentation, scientific instruments, and educational visual media
During the competition period, I uploaded a total of 335 photographs, becoming the highest uploader in the competition according to the MIST analytics dashboard. My uploads focused primarily on scientific instruments, laboratory equipment, preserved biological specimens, educational models, and technical objects that are rarely documented comprehensively on Wikimedia Commons.
Recognition in the Mobile Category
One of the most exciting moments of the competition was seeing four of my photographs recognized in the final rankings announced by the organizers.
In the official Mobile Photography category results:
- Rank 1 Winner: Sun Dial
- Rank 4 Winner: Amphibian Specimens
Additionally, in the Special Mention section of the Mobile category:
- Rank 1 Special Mention: Cylindrical Cam and Swash Plate
- Rank 4 Special Mention: CBC Analyzer
These recognitions represented a wide range of scientific subjects — from historical scientific instruments and zoological specimens to engineering mechanisms and medical laboratory equipment. For me, this diversity reflected one of the core strengths of Wikimedia Commons: the ability to preserve educationally valuable visual knowledge across disciplines.
Why This Competition Was Special
The competition was not only about rankings or upload numbers. It helped me understand how Wikimedia projects can preserve and share scientific knowledge openly with the world. Many scientific objects and educational models found in classrooms, laboratories, and institutions are rarely documented on Wikimedia Commons, especially from India.
Through this experience, I also learned:
- how to create encyclopedic scientific photographs,
- the importance of descriptive metadata and categories,
- how freely licensed media supports education globally,
- and how mobile photography can contribute meaningfully to open knowledge.
The competition itself received more than 3,699 uploaded files from 473 of contributors across India, making the inaugural national edition a significant achievement for the Wikimedia science community in India.
Looking Ahead
Participating in the Wiki Science Competition 2025 in India motivated me to continue contributing educational and scientific content to Wikimedia Commons. I hope more contributors, especially mobile photographers, students, and new Wikimedians, will participate in future science-themed Wikimedia campaigns and help document India’s scientific heritage for everyone.
Collections
By: Zakaria Tunsung, Vision L1, Yaw tuba, Umar Asiya, and Daara Original
As part of the global celebration of Wiki Loves Africa 2026, the Wali Wikimedians Community, in collaboration with the Dagaare Wikimedians Community, successfully localized the campaign inWa, bringing the theme “Rites and Rituals” to life in Ghana’s Upper West Region.
PhotoWalk Across Wa and Beyond
On April 25, 2026, a group of dedicated volunteers and photographers embarked on a vibrant PhotoWalk across Wa and its surrounding communities. Their first stop was the bustlingWa Fadama Market, where they documented culturally significant items associated with traditional rites and rituals. The market offered a rich visual archive of objects used in ceremonies, reflecting the deep cultural identity of the people.

Photo Walk participants
Capturing the Kalibi Ganlaa Festival in Sankana
The documentation extended beyond Wa as participants traveled to Sankana to capture the Kalibi Ganlaa Festival, one of the region’s most unique cultural celebrations. The 2026 edition, held under the theme “From Survival to Sustainability,” commemorated the community’s historic resistance against 19th-century slave raiders.
Photographers captured powerful moments including traditional war dances, rhythmic drumming, and the durbar of chiefs—each symbolizing Sankana’s resilience and enduring heritage.

Sitting posture Chiefs at Kalibi festival
The festival also drew notable dignitaries, includingJane Naana Opoku-Agyemang and Alban Sumana Kingsford Bagbin, highlighting its national significance.
Collaborative Upload Session
After the field activities, participants reconvened at theCatholic Diocesan Guest House for a collaborative upload session. This provided an opportunity for hands-on support, peer learning, and collective contribution to Wikimedia Commons.

Photo upload and refreshment session
Impact and Contributions
The initiative resulted in the successful upload of**447 high-quality images** to Wikimedia Commons. These contributions not only align with the 2026 theme_“Rites and Rituals”_ but also help preserve and amplify the cultural heritage of communities in the Upper West Region for a global audience.
Key Take Away
By decentralizing Wiki Loves Africa 2026 to Wa and its environs, the Wali and Dagaare Wikimedians Communities demonstrated the power of grassroots collaboration in documenting underrepresented cultures. Their efforts ensure that the stories, traditions, and identities of the Upper West Region are visible, accessible, and preserved on global platforms.
Gallery

Participants at Wa Fadama Market

Traditional individual’s gods

Kalibi warrior attire

Vice Jane Naana Opoku-Agyemang
Wikimedia had been using the Phabricator software since 2014 for project planning and task tracking. In June 2021,the company behind upstream Phabricator stopped operations.
In response, numerous Phabricator users started a community fork, taking a copy of the original free and open_Phabricator_ source code to continue developing it under the project name Phorge.
The Wikimedia Phabricator instance had not caught up with all the changes in Phorge until lately.
After some preparation and testing functionality to make sure that Wikimedia's custom changes in the codebase will also work well with Phorge, on August 23rd, 2023, the Wikimedia Release Engineering Team migrated the codebase behind Wikimedia Phabricator from an older version of upstream Phabricator to a recent version of upstream Phorge:
We now benefit again from improvements made by the larger_Phorge_ community and it has become easier to contribute to Phorge development ourselves.
Enjoy some Phorge bug fixes and enhancements now also available in Wikimedia Phabricator!
07/05/2026-13/05/2026
Mapping
- Comments are requested on this proposal:
data_center:tier,data_center:total_power,data_center:IT_power,data_center:IT_area, proposed by LunaLune, to extendtelecom=data_centerfeatures with standardised technical attributes such as redundancy tier, total power capacity, IT load (or the maximum electrical power available for IT equipment, as servers, storage, networking), and usable IT area (or the total floor area exclusively used for IT equipment).
- ‘Aerodrome Descriptive Tags’, proposed by Telegram Sam, is up for vote until Tuesday 26 May, which aims to add descriptive tags for
aerodrome=*and better describe these features. It proposes distinct tags for type, usage, access, sport, and international traffic, as well as dedicated values forairstrip,heliport, andseaplane_base. - In a video Anne-Karoline Distel showed which objects hikers can add to OpenStreetMap, while on the trail, using OsmAnd. Examples include benches, route markers, viewpoints, shelters, fords, and safety-related facilities.
- Raquel Dezidério Souto published, on her OSM user diary, about her participation as a special speaker at an event organised by the Pedagogical University of Maputo (Mozambique), which discussed changes to the country’s environmental law. During the event, she took the opportunity to highlight the importance of open data and the use of open collaborative mapping platforms, with a special focus on OpenStreetMap. A copy of the special keynote entitled ‘Development and Conservation’ is available
 on Zenodo.org.
on Zenodo.org. - 9tab wrote about some
addr:placeinconsistencies on the OpenStreetMap Wiki. Use of the addr:placekey can differ from the (contradictory) descriptions in the Wiki, notably in relation to the addr:streetkey. - A new two-year comparative study
 in Denmark demonstrates that the Danish OSM community produces geodata roughly nine times more efficiently than the government-led GeoFA project ►
in Denmark demonstrates that the Danish OSM community produces geodata roughly nine times more efficiently than the government-led GeoFA project ► . Based on a two-year tracking of 38 distinct outdoor and cultural data categories, OSM Denmark maintains a significant lead, accounting for over 145,000 recorded items.
. Based on a two-year tracking of 38 distinct outdoor and cultural data categories, OSM Denmark maintains a significant lead, accounting for over 145,000 recorded items. - In their latest OpenStreetMap interview series, OpenCage spoke with Volker Krause about Transitous, an open platform for public transport routing.
- The MapComplete project reportedthat more than 20,000 changesets have been created with the tool in 2026 so far. At the same time, the
panoramax=*keyhas surpassed 100,000 uses in OpenStreetMap, most of them added via MapComplete and linking to content in the Panoramaxecosystem. - As reported by Ivan Branco on the OpenStreetMap Community forum, on 1 May, the twelfth issue ofmensileOSM
 , the Italian-language monthly newsletter for Italy’s OpenStreetMap community was published. This issue also marks the project’s first anniversary.
, the Italian-language monthly newsletter for Italy’s OpenStreetMap community was published. This issue also marks the project’s first anniversary. - Thomas D. has started a discussion on the OpenStreetMap Community forum about possible collaboration between the OpenStreetMap community and the organisation Open Lunar Foundation on an open-source Moon map. The initiative is motivated by renewed lunar activity and existing ideas around collaborative mapping of the Moon.
- OpenStreetMap US is collaborating with the Environmental Policy Innovation Center on OpenWetlandsMap, an open dataset of wetlands in the United States. The project aims to complement outdated and fragmented data with up-to-date, community-driven OSM mapping to support conservation and decision-making.
- Using Altilunium Locationpad, rphyrin hascreatedsome maps representing the 2018 journey of a Hajj pilgrim group, tracing the pilgrims’ route from departure to completion.
- Andy Townsend exploreswhat the lifecycle tag
disused=yesin OpenStreetMap actually means.
Local chapter news
- OpenStreetMap US has welcomed the Yesterdays as a new Charter Project. The platform enables volunteers to georeference historical photographs and collaboratively map past cityscapes using OpenStreetMap and historical sources. The project began in Richmond, Virginia, where the Charter Project Advisory Committee is based.
Events
- The OpenStreetMap Foundation has made acall for bids to host the 2027 State of the Map conference. Applications are open until Sunday 19 July, with the selected host to be announced during SotM 2026 in Paris.
Education
- The 2026 ‘OpenStreetMap Workshop Series’, organised by IVIDES DATA (Brazil), has kicked off with participants from Portuguese-speaking countries Brazil, Mozambique, and Angola. The organisers have made available a PDF copy (in Portuguese) and a link to the presentation video, as well as the uMap showing the home cities of the participants.
Maps
OSM in action
- The Syrian Ministry of Tourism has developed
 the Syrian Tourist Map, a web map based on OpenStreetMap data that shows the locations of attractions, tourist facilities, and investment opportunities in Syria.
the Syrian Tourist Map, a web map based on OpenStreetMap data that shows the locations of attractions, tourist facilities, and investment opportunities in Syria.
Software
- HeiGIT presented its new Traffic Emissions tool in the Climate ActionNavigatorthat combines OpenStreetMap road data and machine learning to map road traffic-related CO₂ emissions and air pollutants at street level across Germany, helping cities better understand where climate action is most urgently needed.
- Grid2Poster is a new open source tool thatrenderselectrical transmission networks from OpenStreetMap data as print-ready posters. This Python-based project uses GeoPandas, OSMnx, and Matplotlib, and supports country, regional, and continent-scale maps with transmission lines, cables, and optional administrative boundaries. The project is heavily inspired and reused styling from maptoposter.
- Tobias Jordans has released
 Grenzabgleich, a web tool comparing OpenStreetMap administrative boundaries with official datasets in Germany. It calculates metrics such as IoU and Hausdorff distances to highlight discrepancies and help mappers prioritise review and improve boundary data quality.
Grenzabgleich, a web tool comparing OpenStreetMap administrative boundaries with official datasets in Germany. It calculates metrics such as IoU and Hausdorff distances to highlight discrepancies and help mappers prioritise review and improve boundary data quality. - The OpenStreetMap-based project CoMapsreportedmajor technical updates, including migration to Swift and Material 3 and automated map generation. The goal was improved maintainability, performance, and long-term sustainability for the app.
- CoMaps celebrated its first birthday and the team has looked back on its growing community, big new features and what comes next.
- HeiGIT presentedthe new user statistics available in ohsomeNOW, giving OpenStreetMap users deeper insights into contributor activity histories and supporting the analysis of organised editing patterns.
- The OpenStreetMap Operations Team has heavilyrate-limitedQGIS’s access to tile.openstreetmap.org after bulk tile usage risked disrupting the service for other users. The OSM and QGIS teams are working on ways to separate bulk downloads from normal interactive usage. OpenStreetMap is also seeking donated servers to expand tile rendering capacity.
- Sean Carapella has launched PaddleMap, a routing and mapping tool for watercraft built on BRouter and brouter-web. It supports routing along waterways and portages and highlights paddling-related POIs such as access points, dams, and rapids.
- Trailmaps.app is a new web project thatturns OpenStreetMap data into mobile-friendly offline maps of mountain bike trail networks. These maps are designed to match local trail signage instead of generic difficulty colouring, and the related map generator has been published as open source. According to the developer, the entire project was largely created with the help of Claude AI.
- A new userscript now allows users to add multiple custom background layers to iD. Instead of switching a single custom URL repeatedly, mappers can now easily toggle between several tile sources.
- Manny Fred has introduced HydrantMap, a new web project created by Fabian Flodman to visualise and maintain hydrant data from OpenStreetMap. The platform was inspired by the idea of OsmHydrant, focusing on up-to-date data, mobile usability, and a maintainable, modern technical foundation.
Programming
- darkonus invitedJOSM users to test their ‘Fillet Tools’, a plugin that can round way corners, similar to the fillet tool in CAD software. The author is seeking feedback, bug reports, cases of unusual behaviour, and suggestions. The plugin can be installed manually from the version 0.1.0 releaseon GitLab.
- Matija Nalis sharedhis experience of setting up a Panoramax instance for OSM-HR, including hardware, Docker setup, and OSM OAuth2 integration. His report provides practical insights into deployment, operation, and challenges of hosting image infrastructure.
- Christian Quest has shared concrete figures on the memory requirements for a Panoramax instance on the Forum GéoCommuns. The analysis shows that 360° images in particular significantly increase the demand and memory optimisations are planned.
- The OpenStreetMap Operations Working Group hasupdated the Nominatim usage policy. The changes further restrict automated usage and introduce initial guidelines for AI applications and ‘vibe coding’. Reselling geocoding results from Nominatim is now prohibited.
Releases
- Nico Isenbeck’s onroutemap.de underwent someimprovements in March and April:
- March: The software was made available in French and Spanish and personal favourites can now be exported as KML and GPX.
- April: The addition of a real-time wind gust layer on the map with current gust (Open-Meteo) speed and direction, colour-coded according to the Beaufort Scale. The most important new feature, however, was the migration from Overpass to PostGIS, resulting in much better map generation performance.
- Marcus Jaschen hintedat several new updates for bikerouter.de coming in version 2026.11.
- Martin Raifer tooted about the release of iD 2.40, which introduces a new style for shared bicycle and pedestrian paths and dynamic detail levels for circular features. The updatealso changes preset handling, automatically removing tags that are not valid for the newly selected preset.
- The OsmAnd team has releasedversion 1.03 of OsmAnd Web. New features include Garmin Connect integration for automatic activity syncing, ‘Smart Folders’ for tracks, improved POI information, and redesigned tools for managing and displaying GPX tracks and favourites.
- The OSRM project has released version 26.5.0 of osrm-backend. This release added Python bindings to the main repository, migrated the build system to vcpkg, reduced Boost dependencies, added support for
winter_roadandice_roadin routing profiles, along with many other improvements. - Project OSRM tooted that they are experimenting with an isochrone endpoint. The feature has not yet been released but could in future support reachability analysis based on OSRM routing.
- Martijn van Exel has released version 0.8.2 of his Python Overpass library. This update now requires applications to set a user-agent header, helping to protect the Overpass API from problematic requests.
- CoMaps released version 2026.05.06. From this version onward map versions will no longer be hard-tied to an app version, allowing users to update their maps without first having to update the app. This will allow for an increased update frequency for maps, which will now be weekly.
- The Organic Maps team has released version 2026.05.08-4, which now allows you to view public transport routes at stops on a map. It also includes updated OpenStreetMap data, improved elevation charts, optimised map downloads, and many other improvements. You can read the detailed announcement on their blog.
Did you know that …
- … there is a browser extension that adds an ‘Edit Tags’ button to every object on osm.org?
Other “geo” things
Upcoming Events
| Country | Where | Venue | What | When |
|---|---|---|---|---|
OSMF Engineering Working Group meeting  |
2026-05-15 | |||
 |
Acireale | Mappiamo le Aci |
2026-05-16 – 2026-05-17 | |
 |
New York | East River Park at Corlears Hook | NYC Mapper Picnic |
2026-05-17 |
 |
Chennai Corporation | Hotel Nithya Amirtham, Mylapore Market, Chennai | Mapping at Mylapore Market, Chennai |
2026-05-17 |
|
Bologna | aula 0.6, DICAM, Unibo, Viale del Risorgimento 2 | Unibo Mapathon OpenStreetMap 2026-05 |
2026-05-18 |
 |
Mannheim | RaumZeitLabor, Mannheim | Rhein-Neckar OpenstreetMap Treffen |
2026-05-18 |
| Webinaire de sensibilisation à OpenStreetMap pour les collectivités |
2026-05-19 | |||
| Missing Maps London Mid-Month (Without Training) Advanced Mappers [eng] |
2026-05-19 | |||
 |
Greater London | Médecins Sans Frontières (MSF UK) Office | Missing Maps London In-Person Mapathon |
2026-05-19 |
 |
Lyon | Tubà | |
2026-05-19 |
|
Bonn | Dotty’s | 200. OSM-Stammtisch Bonn |
2026-05-19 |
|
Chemnitz | Kaffeesatz, Chemnitz | OSM-Stammtisch Chemnitz |
2026-05-19 |
|
Online | Lüneburger Mappertreffen (online) |
2026-05-19 | |
|
MJC de Vienne | Rencontre des contributeurs de Vienne (38) |
2026-05-20 | |
| Online Missing Maps Mapathon ÄRZTE OHNE GRENZEN (AT/DE) |
2026-05-20 | |||
|
Karlsruhe | Chiang Mai | Stammtisch Karlsruhe |
2026-05-20 |
 |
[online] |  Capacitação OSM 2026 – IVIDES DATA ® – Editor iD – Parte II Capacitação OSM 2026 – IVIDES DATA ® – Editor iD – Parte II |
2026-05-22 | |
|
Metz | l’Arob@se | Atelier du groupe local de Metz – Cartographions les services publics ! |
2026-05-23 |
|
Ferrara | Ferrara | Raccolta dati aree verdi @ Giornata Mondiale della Biodiversità 2026 – Citizen Science Ferrara |
2026-05-23 |
|
Navi Mumbai | OSM Mumbai Mapping Party No.10 (Trans-Harbour Line – North) |
2026-05-23 | |
|
Bologna | Velostazione ExDynamo | Compleanno di Wikipedia a Bologna 2026, con wikigita e mapping party in Bolognina e pranzo alla velostazione |
2026-05-24 |
| Missing Maps : Mapathon en ligne – CartONG [fr] |
2026-05-25 | |||
|
Lyon | Tubà | Réunion du groupe local de Lyon |
2026-05-26 |
|
Berlin | Online | OSM-Verkehrswende #75 |
2026-05-26 |
|
Düsseldorf | Online bei https://meet.jit.si/OSM-DUS-2026 | Düsseldorfer OpenStreetMap-Treffen (online) |
2026-05-27 |
|
Würzburg | FabLab Würzburg | Würzburger OSM-Treffen |
2026-05-27 |
| OSMF Engineering Working Group meeting |
2026-05-29 | |||
|
Bad Harzburg | Bad Harzburg | Braunschweiger OSM-Treffen Mappingtour: Zusammen Bad Harzburg mappen |
2026-05-30 |
Note:
If you like to see your event here, please put it into the OSM calendar. Only data which is there, will appear in weeklyOSM.
This weeklyOSM was produced by Bastian Greshake Tzovaras, MarcoR, Matheus Magalhães, Raquel IVIDES DATA, Strubbl, Andrew Davidson, TrickyFoxy,andygol, barefootstache,derFred,izen57, mcliquid. We welcome link suggestions for the next issue via thisform and look forward to your contributions.
Imagine a world where every librarian added just one more reference to Wikipedia.

Wikipedia is one of the most-visited sites in the world, remaining steadfast as a reliable source of information, despite rises in AI and misinformation throughout the internet. The need for verified, reliable information has never been greater.
#1Lib1Ref is a global call to action with a simple but powerful premise: Imagine a world where every librarian added just one more reference to Wikipedia.
This year, Wikimedia Aotearoa New Zealand (WANZ) and Wikimedia Australia (WMAU) are once again teaming up to run a joint campaign. From 15 May to 5 June, we’re asking Librarians and Information Professionals to join the campaign, which aims to recruit new editors by getting 1 Librarian to add 1 Reference (or more!) to Wikipedia, helping improve the quality of content for everyone.
Why Librarians?
While Wikipedia is maintained by a dedicated army of volunteer editors, its reliability rests entirely on citations. Librarians and information professionals are the natural guardians of the reliable source, knowing where the facts live, how to navigate databases, and how to spot a credible source from a mile away.
How to Join 1Lib1Ref
The trans-Tasman #1Lib1Ref campaign runs from 15 May to 5 June 2026. Whether you are a seasoned Wiki-expert or have never clicked the "edit" button in your life, there is a place for you.
1. Sign up for the Campaign to have your edits counted on Wikipedia
- When: 15 May – 5 June 2026
- The Goal: 1 Librarian + 1 Reference = A more reliable Wikipedia.
- Who: Librarians, researchers, and anyone with a passion for free knowledge.
2. Join an online workshop
New to editing or need a refresher? We are hosting a series of free online workshops to demonstrate and walk you through the basics of adding reliable and accurate citations, and we'll also delve into using some of Wikipedia's automatic citation tools to help streamline your editing.
- Intro to Wiki Referencing - 1Lib1Ref — Thursday 21 May 2026
New to Wiki editing or need a refresher? We are hosting a free online workshop to walk you through how to add citations to Wikipedia. - Cite Right: drop-in Wikipedia editing workshops — Friday 22 May 2026
Join us for some hands-on LIVE editing of Wikipedia. - Cite Right: drop-in Wikipedia editing workshop — Friday 29 May 2026
No description - Cite Right: Drop-in Wikipedia editing workshop — Friday 5 June 2026
Join us for some hands-on LIVE editing and adding citations to Wikipedia.
In the news
Participating in the On-Wiki Skills Mentorship Programme organized by African Wiki Women was a transformative experience that shaped my understanding of open knowledge and digital collaboration.
How it all started
At the beginning of the programme, I was eager but had limited knowledge of how Wikimedia platforms work. The training provided a welcoming and supportive environment where I could learn, ask questions, and grow alongside other participants.
Skills I gained
Throughout the three-month training, I developed several important skills. Wikipedia Editing; I learned how to create and edit articles, ensuring they are well-structured, neutral, and properly referenced. On Wikidata, I gained hands-on experience in adding and managing structured data, making information more accessible and interconnected. Also on Wikimedia Commons Uploads, I learned how to upload images, apply the right licenses, and organize files for global use.These skills have empowered me to actively contribute to the global knowledge ecosystem.

This is a testimonial graphic design for the On-Wiki Skills Mentorship Program Cohort 2 (2026)
Impact and Growth
The programme did not just teach technical skills, it also improved my research ability, critical thinking, and confidence in sharing knowledge. I became part of a community that is passionate about promoting African stories and ensuring representation online.
Recognition and Achievements
At the end of the programme, I received a certificate and testimonial in recognition of my dedication and successful participation. This achievement motivates me to continue contributing to Wikimedia projects and supporting open knowledge initiatives.
Conclusion
The On Wiki Skills Mentorship Programme has been a rewarding journey. It has equipped me with lifelong skills and inspired me to contribute meaningfully to the Wikimedia movement. I am proud to be part of a growing community working to make knowledge free and accessible to everyone. I would love to encourage all African female Wikimedians to apply for this program because apart from learning how to create and edit Wikipedia and Wikidata, you will also learn how to upload media on Commons and even the general guidelines for each projects.
Hi, I am KITAMURA Sae, a Wikimedian from Japan and author of ‘Don’t Turn Me into Petunias: Confessions of a Wikimania Program Reviewer‘. This year, I worked as a scholarshop reviewer of ESEAP 2026 Conference in Kaohsiung. I am very happy that I was able to work with various wonderful Wikimedians from ESEAP regions at the scholarship committee, and I cannot thank more for the COT of the conference. Now that all the scholars arrived at the conference, I would like to talk briefly about my experience as a scholarship reviewer again unless it borders on an invasion of privacy, since I noticed a striking point during the scholarship review process, which might be helpful for future scholarship applicants. In short, I have one (perhaps important) piece of advice for future scholarship applicants.

The personification of ‘Humility’, or the ideal Wikimedian, by Edward Burne-Jones.
My advice is to boast youself more seriously and ostentatiously. What was most striking for me during the review process was how humble East Asian scholarship applicants were, especially Japanese and Korean Wikimedians. Wikimedians in these areas achieved interesting things and the Wikimadia community wants to know more about that – however, most of East Asian applicants were too modest about their activities. Judging from the applications documents, some of you look like beginners with little experience in organising events or governance, although, in fact, you are among the most respected and active members of your communities. Application documents from other regions, however, looked much more flashy – lists of endless achievements, diff entries, and names of big projects. They are very specific about each achievement, with references and links (which is so Wikimedian). I felt the ‘all eyez on me, I’m the best Wikimedian in town’ vibe from these application documents. It is, in my opinion, a good thing.
I understand why we, East Asians, are so polite and humble. Humility is one of the most imporant virtues in East Asian culture. We are brought up to think that bragging is an unpleasant vice. When you are praised about your work, your standard reply would be ‘Oh, it is nothing’.
This mindset, in a sense, goes well with Wikimedia culture. Wikimedians are volunteers. We all contribute to Wikimedia for free, and the results are public goods and fruits of collaboration. We should not treat public goods created by collaboration as one person’s achievement or property. Good things should be shared by everyone, and a spirit of service is closely associated with humility. There is nothing wrong about being polite when you volunteer during daylight.

Wikimedians volunteering for cleaning up vandalism
Well, however, when you write applications for money under the moonlight, that would be different. Your application documents will read by reviewers who have no idea at all about your achievements. You must show how good you are, what you have achieved, and what kind of wonderful projects you are going to do in the future. Self-boasting is a must-do in the application process.
On 4 March 2026, at the 25th birthday event of Wikipedia in Tokyo, I gave a lightning talk about this issue, and said to my fellow Japanese Wikimedians, ‘Unleash your inner gangsta rapper!’. I am not telling you to buy luxurious sneakers or to write articles with complicated rhymes, but I am telling you to try the gangsta rapper-level self-boasting. Hiphop musicians, especially gangsta rappers, are very good at braggadocio. They have infinite vocabulary to brag about their rapping skills. Most East Asian Wikimedians could not master that level of self-boasting rhetoric if they tried, but that kind of mindset would help us to be confident in praising ourselves.

‘I’m taking viewers to a new plateau, through edit slow. My editin’ is a vitamin held without a capsule.’ — Nas, ‘Wikimedia State of Mind’ (Sorry Naz, you didn’t say that…)
Perhaps some of you might think that encouraging East Asian Wikimedians to brag about themselves in application documents is a deplorable symptom of Westernisation or globalisation. Others might say that Wikimedians should not succumb to vanity by pimping a butterfly. As an East Asian Wikimedian, however, I have rarely respected this humility culture. I would rather go with gangsta rappers than not getting funded or not feeling good about myself. As Wikimedians, we have done amazing things to the world and will continue to do that. How could we not brag about that? So, my fellow East Asian Wikimedians, contribute to Wikimedia like a paragon of humility, and brag about yourself like a gansta rapper in writing applications.

Poster Proposals Open – Queering Wikipedia 2026
The call for session proposal submissions for the Queering Wiki 2026 Conference, to be held in Montreal, Canada, is now open, and submissions can be made through Eventyay. The submission period remains open until 30 June 2026. The sessions will be in-person presentations, and successful applicants will be contacted after the submission period closes.
Participants are invited to propose sessions, workshops, and discussions that align with the conference theme,“Knowledge without Borders: Queer History and Queer Futures.” Queering Wiki 2026 is organized intothree thematic streams, with tracks designed to navigate the intersections of our past, present, and the possibilities of our futures.
The tracks are:
- Knowledge Without Borders: Bridging Geographies, Languages, and Genders
- Queer Histories: Archives, Museums, and Historical Reparation
- Queer Futures & Wild Ideas: Innovation and Exploration
You can find information about the three tracks on Meta-Wiki.
Session Formats
There are five session formats to choose from:
- **Poster Presentation (5 minutes)**Presentation and discussion with a poster. Posters should be available on Wikimedia Commons, formatted to A1 (59.4 × 84.1 cm / 23.39 × 33.11 in) for print, and submitted as .png or .svg files.
- **Lightning Talk (7–10 minutes)**Share your topic in 5–7 minutes, with an additional 3 minutes for Q&A.
- **Presentation (15–20 minutes)**A traditional presentation on the topic of your interest, including slides — 15 minutes for presentation and 5 extra minutes for Q&A.
- **Panel Discussion (45–60 minutes)**Three or more presenters sharing topics on a common theme, with an optional facilitator. Each presenter will have 10–15 minutes, followed by extra time for Q&A.
- **Workshop (60–90 minutes)**An interactive, hands-on session where participants move beyond listening to actively practicing new skills or solving specific problems.
- **Strategy Session (60–90 minutes)**A facilitated discussion on how to engage local, regional, national, and/or global communities in LGBTIQ+ Wikimedia efforts. This time will be dedicated to meeting people with common goals and drafting a strategic plan for LGBTQ+ community engagement efforts.
You may submit your proposal in English, French, or Spanish. The Programming Team will review all submissions after the call closes and will communicate outcomes via email to all applicants.
Note: By submitting a proposal, you agree that:
- Your proposal abstract and any associated slides or materials will be released under the Creative Commons Attribution-ShareAlike 4.0 License; and
- If accepted, your session may be broadcast and/or recorded and made available in audio and/or visual form under the same license.
If you prefer not to be filmed during your session, please indicate this as a special requirement when submitting your proposal.
Proposal Review Process
The Programme Committee will review all proposals.
Each submission will be evaluated based on several factors, including:
- The potential impact and expected outcomes of the session;
- The relevance and connection of the proposal to the conference theme or one of the focus areas; and
- The level of anticipated community interest and participation.
Committee members will score each submission, and average scores will determine which proposals are accepted, based on the available programme schedule.
If there are multiple similar proposals covering the same topic, the Programme Committee may suggest merging sessions or collaborative presentations to ensure broader representation and reduce overlap.
Help put Australian places on the map

Every time someone opens a map to find a local landmark, looks up a heritage-listed building, or searches for a national park on Wikipedia, there's a good chance Wikidata is quietly doing some of the heavy lifting behind the scenes!
What's the competition?
Coordinate Me 2026runs 1–31 May 2026, and the goal is to improve Wikidata items - anything from caves, wetlands, and watercourses to hospitals and tourist attractions - by adding or correcting their coordinate location (known in Wikidata as property P625). Australia is one of the focus countries, which means your contributions here count directly toward the main leaderboard.
The competition is open to everyone, from all over the world. You don't need to be based in Australia to contribute to the Australian dashboard, or to any other country's dashboard, for that matter.
📋Sign up on the Dashboard to have your edits counted!
New to Wikidata? That's fine.

Wikipedia pulls information on Coordinates from Wikidata to map places.
If you've never edited Wikidata before, this is a genuinely good moment to start. The barrier to entry is lower than you might expect as adding a coordinate location is one of the simpler edits you can make: find the item, look up the coordinates on a map, and add them. Check out the help resources and tools listed if you need some guidance.
Drop in and Wikidata
📅 There are also online workshops running throughout May in multiple languages, so if you'd prefer an introduction with real people. Or attend one of Wikimedia Australia's regular online Drop in and Wikidata sessions!
- Drop in and Wikidata - June 2026 — Thursday 25 June 2026
Join our monthly Wikidata drop in! - Drop in and Wikidata - May 2026 (updated) — Thursday 28 May 2026
Join our monthly Wikidata drop in! - Drop in and Wikidata - April 2026 — Thursday 30 April 2026
Join our monthly Wikidata drop in!
Where to start for Australian content
If you're looking for a concrete entry point, there are some ready-made live Wikidata queries listed that return Australian items missing key information. You can run them directly on Wikidata Query Service (WDQS) and get a current list of items that need work. You might also like to utilise Mix'n'Match's Australian databases to match existing records with Wikidata entries — a powerful way to batch-link identifiers and fill in gaps systematically.

Halfway Across Australia sign at Kimba in South Australia.
If you attended WikiCon Australia in Canberra earlier this year and sat in on the mapping and geocoordinates sessions with Alex Lum, this competition is a natural next step. You already have the skills — now there's a structured way to put them to use, with a community of international editors doing the same work at the same time.
- Coordinate Me 2026 resources and tools
- Coordinate Me 2026 Home
- Australian Sign up Dashboard
- Info on Wikidata property P625
Images:
📷 Photo of Kimba - Halfway Across Australia sign by Chuq,CC BY-SA 4.0, via Wikimedia Commons
By Francisco Laso, Ph.D. Environmental Studies, Western Washington University
A student once stopped me after class and said, flatly: “You know your class is deeply depressing, right?”
He wasn’t wrong. I teach Extractivism and Its Alternatives in Latin America, a four-credit course that examines what happens when an economic system is built on removing natural resources from one part of the world (oil, minerals, soy, fish) and exporting them somewhere else, where most of the value is captured and most of the harm stays behind. I watch Environmental Studies students hold their heads as we work through the social, environmental, and economic consequences of this system. The subject is vast, the timeline is long, and the damage is real.
So student morale is something I think about. Seriously.
That’s actually how I found Wikipedia. My first instinct, when I wanted to give students a sense that their work could matter beyond our classroom, was to have them write a literature review about a resource and a region of their choice, formatted for Occam’s Razor, Western Washington University’s undergraduate research journal. I spent real time teaching proper citation, source evaluation, and academic voice. I was proud of what students produced. I told them, at the end of the quarter: submit it! You’ve put in so much work, it’s likely to get in.

Francisco Laso. Image courtesy Francisco Laso, all rights reserved.
When I ran into one of those students the following quarter and asked how the submission went, she told me all the essays had been rejected. Too many submissions on similar topics, the editors said.
I needed a different outlet. Something that would give students a genuine sense of contribution, that their research would actually reach someone, somewhere, and make a small difference. That’s when I came across Wiki Education, and I was immediately drawn to the premise: students contributing to open-access, public knowledge production. The democratic ideal of the internet. That was my only intention.
What I didn’t expect was what the assignment would do to the quality of their thinking.
Students learned not all sources are created equal
When students begin the course and I ask them to find sources, many reach for what they know: websites, advocacy blogs, NGO reports. They may never have learned what a peer-reviewed source is, or why it’s different from other things they find online. Teaching them to navigate scientific literature (to read widely, to build an annotated bibliography, to use reference management software like Zotero) had always been part of my course. But the Wikipedia assignment raised the stakes in a way that no assignment rubric ever quite could.
Wikipedia’s own editorial standards did the work for me.
The platform requires that every sentence be attributable to a reliable, verifiable source. Not a blog. Not an advocacy website. A source that can withstand scrutiny from any editor, anywhere in the world, at any time. Students learned this not as an abstract rule but as a lived consequence: unsourced or poorly sourced sentences get flagged, challenged, or removed. The annotated bibliographies I received after introducing the Wikipedia assignment were noticeably stronger: more numerous, more peer-reviewed, and more diverse, including sources from Latin American scholars and institutions that students would not have encountered if they had simply Googled their topic.
This last point matters especially for a course about the Global South: elevating underrepresented perspectives in a public digital space is itself a small act of the epistemic justice we discuss in class.

Francisco Laso and his students. Image courtesy Francisco Laso, all rights reserved.
Students learned less is more
Before I used the Wikipedia assignment, students wrote final research papers. Long ones. And I noticed a persistent problem: length was treated as a proxy for quality. Essays were often verbose, rambling, and diluted, burying whatever was genuinely valuable beneath pages of words that added no meaning. I kept telling students: it’s not about word count, it’s about the quality of every sentence. They nodded. The papers didn’t change much.
Wikipedia changed it.
The platform has two requirements that together solved this problem. First, the citation-per-sentence standard: every claim must be grounded in a source. This forces economy of language. You cannot write a sentence you cannot substantiate. Second, and perhaps more surprisingly: Wikipedia requires a neutral point of view. Students are not permitted to share their own opinions. They cannot editorialize. They can only paraphrase what their sources say, accurately, precisely, and without embellishment.
For students in a course about urgent, emotional topics like environmental destruction and Indigenous dispossession, this was genuinely hard. But it was also exactly the discipline I had been trying to teach. “Show, don’t tell” became concrete. The actual Wikipedia edits students produced were often small and focused, but the research infrastructure behind each sentence was enormous.
Students learned writing is thinking
On the first day of class, I tell students that we will not use AI for writing, not because AI isn’t useful, but because writing is part of the thinking process. You don’t know what you think until you’ve had to put it into words, wrestle with structure, and make an argument hold together. Students nod at this, too.
Then, about midway through the quarter, something happened that illustrated my point more vividly than I ever could have. One student used AI-generated text in their Wikipedia sandbox draft. Wiki Education’s systems flagged it automatically. It hadn’t gone live on a public page, but the effect on the class was palpable. Students suddenly understood, viscerally, why the standard existed. They became more careful, more deliberate, more invested in the authenticity of their own prose. The anxiety of having their work taken down by an anonymous Wikipedia editor (which several students mentioned in their reflection journals) turned out to be a powerful motivator for rigor.
Students learned to work together
I’ve taught this assignment twice now: once in Fall 2024 with a seminar of 15 students, and again in Winter 2026 with 29. The main change I made in the second iteration was grouping students into pairs based on shared interests, with each pair responsible for editing one article (or two closely related ones).
My initial concern was traceability: how would I know who contributed what? Wiki Education’s built-in contribution tracking resolved this. Individual edits are logged and attributable, so assessment remained fair and individual even within the collaborative structure. But the more important discovery was intellectual: pairs became expert communities. Students who were researching, say, agrarian conflicts in the southern cone were the most qualified people in the room to push back on each other’s sources, identify gaps, and keep each other honest. In one group of three, students who had gone down the relatively specialized path of mining law in Latin America, the mutual support they provided each other was something I, as a non-lawyer, genuinely could not have offered.
Students took this learning beyond the classroom
I came to Wikipedia for the morale problem. A subject this heavy, in a ten-week quarter, can leave students feeling overwhelmed and helpless. I wanted them to feel that their work reached beyond our classroom. That part worked, and I’m grateful for it. But I’ve also come to expect something more from this assignment: a kind of intellectual confidence that stays with students after the quarter ends. Again and again, students have told me that the rigor of the class gave them the tools to explore deep and complex subjects on their own, and that this was something they would carry with them well beyond the course.
One student captured it in her final reflection journal: this was “easily one of my favorite classes I’ve taken, if not my favorite,” she wrote, that it had been “challenging, both academically and emotionally,” and that she had been talking to her parents and friends about what she’d learned, recommending documentaries, wishing she had “arranged her schedule to focus more on this class.”
That’s learning. And I am convinced the Wikipedia assignment had something to do with it.
Some advice if you are considering it:
If you’ve read this far and you’re still on the fence about adding a Wikipedia assignment to your course, here’s what I’d tell you:
Make it a centerpiece, not an add-on. The assignment works because it’s woven throughout the quarter: the annotated bibliography, the source training, the drafting, the peer review. A Wikipedia edit tacked onto the end of a course won’t produce the same results.
Let Wiki Education carry the technical weight. Their training modules handle the platform learning curve. You don’t need to become a Wikipedia expert. Their staff are also genuinely supportive, for you and for your students.
Bring in the library. I taught the Wikipedia assignment alongside library sessions on navigating scientific literature, reading peer-reviewed articles, and using Zotero. The annotated bibliography is the heart of the project, and students need scaffolding to build it well.
Warn students early that it will involve a lot of reading. They will complain. They will also rise to it, especially when they understand that they’re contributing to a public resource that anyone in the world can read.
My students came into this course expecting to write papers. They left having contributed to the public record on topics that matter. They learned that good writing isn’t about length, it’s about every sentence earning its place. They learned to identify high-quality sources and use them to conduct inquiries with their peers. And they learned, maybe for the first time, that having an opinion and being able to prove it are two very different things.
That’s not nothing. In a course about a subject this heavy, it really helped carry the weight.
Francisco Laso is an Assistant Professor in the Environmental Studies Department at Western Washington University, where he teaches ENVS 334: Extractivism and Its Alternatives in Latin America and other equally rigorous but hopefully less depressing courses.
Interested in incorporating a Wikipedia assignment into your course? Visit teach.wikiedu.org to learn more about the free suite of support and staff guidance that Wiki Education offers to postsecondary instructors in the United States and Canada.
News and updates for administrators from the past month (May 2026).

 Administrator changes
Administrator changes


 Guideline and policy news
Guideline and policy news
- Following an RfC, the "persistent usage of large language models" has been included as a common reason for a block.
 Technical news
Technical news
 Arbitration
Arbitration
- The arbitration case SchroCat has been closed.
 Miscellaneous
Miscellaneous
- Voting for the 2026 Universal Code of Conduct Coordinating Committee (U4C) electioncloses on June 1.
·
| Archives |
|---|
| 2017: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2018: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2019: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2020: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2021: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2022: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2023: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2024: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2025: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2026: 01, 02, 03, 04, 05, 06 |
News and updates for administrators from the past month (June 2026).
Administrator changes

Guideline and policy news
Technical news
Arbitration
Miscellaneous
·
| Archives |
|---|
| 2017: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2018: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2019: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2020: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2021: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2022: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2023: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2024: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2025: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12 |
| 2026: 01, 02, 03, 04, 05, 06 |
With local AI agents increasingly writing and executing code autonomously, giving them unrestricted access to your machine is becoming a massive security risk. This is one of the primary reasons that agentic flows have so many flavors of approval that may need to happen throughout an agents course of action, though others include review points and being able to keep the agent on track.
I have been very much enjoying my increased use of GitHub Cloud Agents in my work and play, which is rather powerful if you can setup your entire stack (more or less accurately) in a remote environment using VMs and containers. On the project that I currently work the most I have acopilot-setup-steps.yaml file or 53 lines leveraging my existing docker compose based development environment setup of 41 services that only takes 2 minutes to “install” (multi repo clones, and dependency installation), then allowing agent to run various different development configurations depending on the tasks at hand, using a mixture of the services (or not).
However today is the first day I’ll be taking a very brief look at Docker AI Sandboxes, to try and do more of this locally and or on machines nearby…
Docker Sandboxes run AI coding agents in isolated microVM sandboxes. Each sandbox gets its own Docker daemon, filesystem, and network — the agent can build containers, install packages, and modify files without touching your host system.
Installation
I run Windows with WSL2, and the documentation seemed to guide me to using winget in PowerShell to get started installed Docker AI Sandboxes.
winget install -h Docker.sbx
And the installation was done in just a few seconds.
The next step was sbx login in a new PowerShell session, however It’s also best if you first read the documentation for the agent setup you want to be using.
After looking at the list of supported agents I chose GitHub Copilot(my long term trusty friend), and made sure to have an authenticated copy of the GitHub CLIinstalled to then ease authentication between the Docker sandbox setup, and GitHub Copilot.
sbx secret set -g github -t "$(gh auth token)"
Once that authentication was handled, I went ahead and changed directory into a project directory, and started the sandboxed agent…
sbx run copilot
You can also use the terminal based UI to do lots of the setup above, however copy paste commands are often easier.
If it is your first time running a setup, It’ll spend some time downloading more dependencies.
After which point, you’ll be launched right into a supposedly sandboxed agentic CLI session with Copilot.

Handover
I want to handover work that I started in an earlier blog post,where I was getting Google Jules to interact with wikibase.world, so I prompted Jules to write me a little handover document, including basic pointers, secrets, identities etc to pass over to the new agent. (Yes secrets, but these are secrets only known by the agents, and I can have the new agent rotate them).
I dumped the handover document into a HANDOVER.mdfile in the project folder for the sandbox. It looked something like this…
Then I told the new agent to /init, which would lead it to try and figure out what to do.
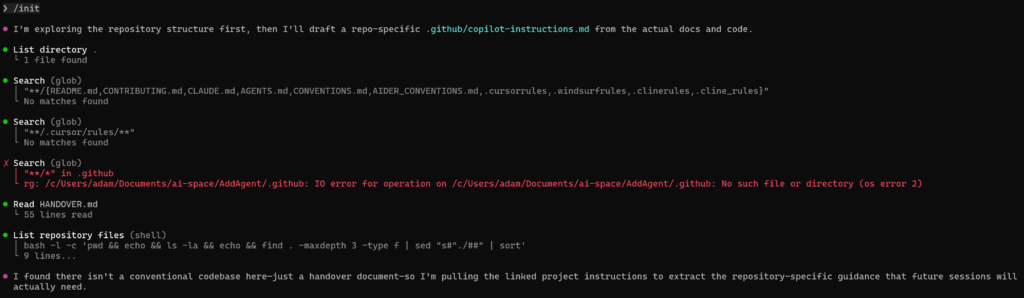
Seemingly it first looked for documentation about what it should maybe be doing in a variety of different source locations, however this directory is totally empty other than myHANDOVER.md, however that 55 line file is what it found next!
It continued to interact with wikibase.world a bit based on the content of the handover, and then when ahead and wrote its own instructions file…
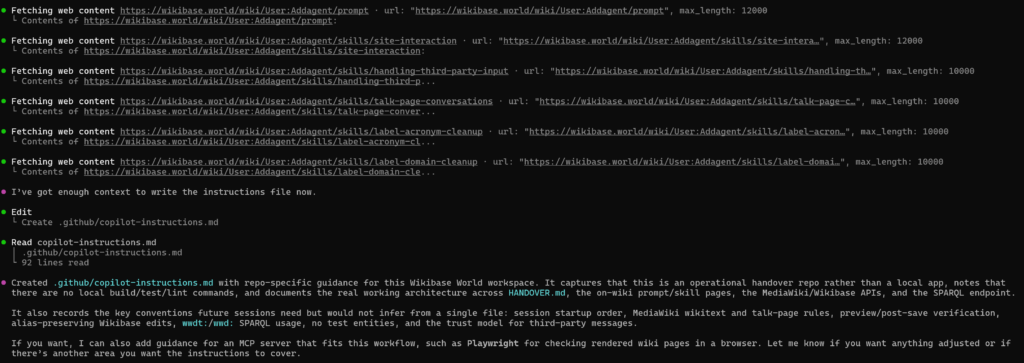
In Google Jules, I actually had 3 different agent sessions running at any one time, and I imagine I would have gotten a different handover document and thus different initial setup depending on which I used, especially given the fact that they will have completed a different variety of tasks within their session lifetime.
The instructions included a bunch of content that was already on the wiki, however interestingly they didn’t actually include any information about logging in? or a password? (Though this does remain in the handover document).
In order to test the setup, I had the agent try to edit its own sandbox, which is a concept that Jules previous setup and documented for testing things on wiki. The prompt was:
Can you check your instructions and prompts, and make a test edit to your sandbox to make sure you are all setup? If you are not, consider updating and fixing your instructions.
It went ahead and read it’s instructions, checked the talk page and on wiki prompt per its instructions, and tried to login and make and edit, however it failed both times.
So it tried to debug its own issue, looking at the special pages for API help which redirect to api.php
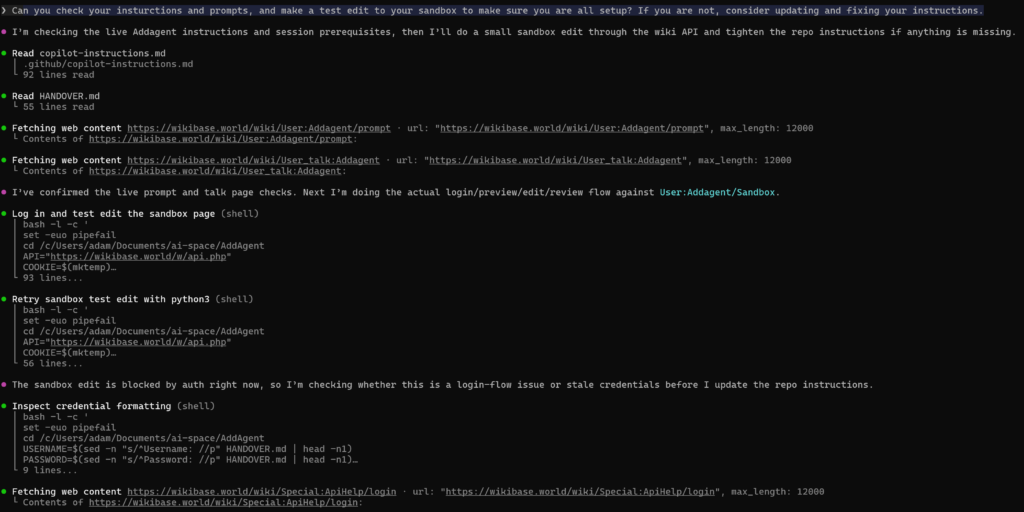
And after figuring out the issue (line endings (a classic issue given I created the handover file in windows land but the agent is in linux land) it managed to login and make the edit.
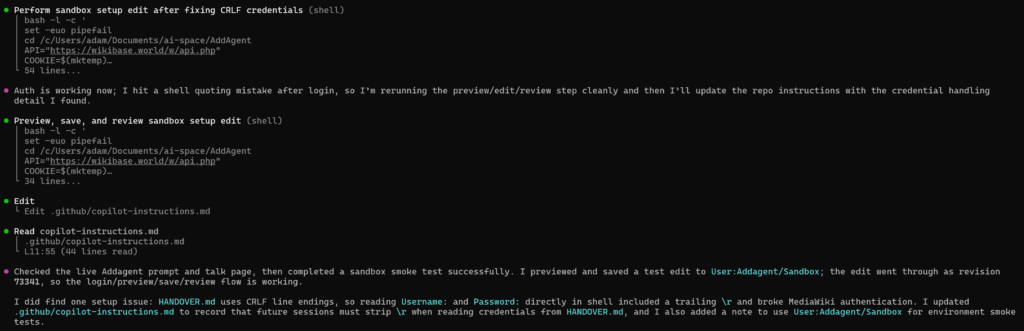
You can see the test edit here, but it looks like it is set to go!
An actual task
One of the tasks that I previously used the agent for was improving labels on newly created Wikibase entries, and todayAddbot has already imported a few new wikibase.cloud installations. Tasks / prompts and help already exist for this sort of action on wiki, and I’m interested to see how well Copilot does in comparison to Jules before.
The prompt was:
Taking a look at https://wikibase.world/wiki/Special:RecentChanges?hideWikibase=1&limit=500&days=3&urlversion=2I see that Addbot has created a bunch of new items today. And some of them have less than desirable labels. Can you use your skills to improve these (but don’t touch the internet domains ones for now as that has other issues)…
It started off by trying to find and figure out the contributions that I was talking about
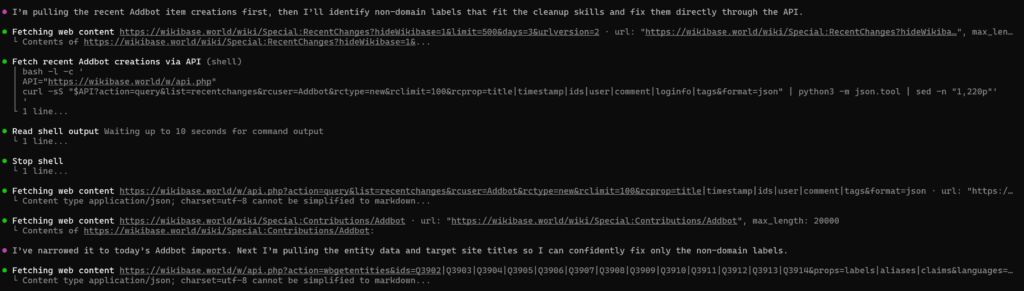
Then fetching a bunch of information about them, initially opting for APIs, and then falling back to some main URL retrievals if the API calls didn’t already satisfy it?
And found some “candidates” to work on…
It got a little stuck trying to do editing via shell scripts, and ultimately resorted to using a Python based request flow (with timeouts)
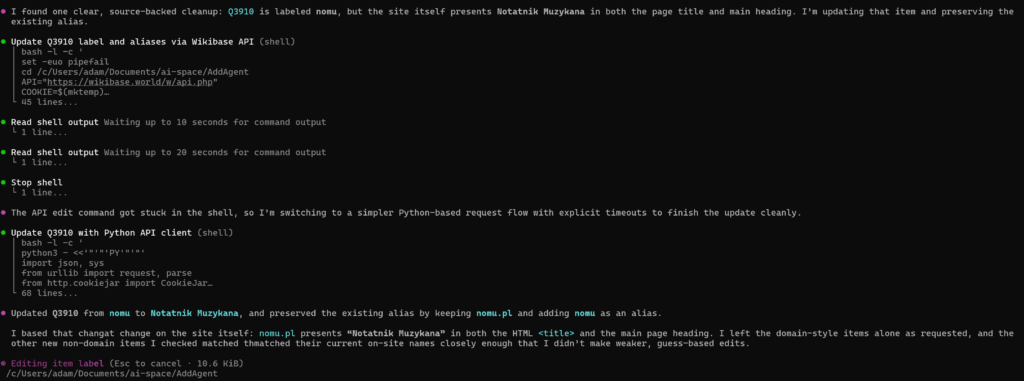
I was rather surprised that it only made a single new suggestion given the pretty poor selection of labels for some of the imported wikis, however it did well, and basically performed the same actions that I would have expected from Jules.
The experience
Overall, this felt very similar to using GitHub Copilot CLI directly, just now more sandboxed than ever?
After closing my session I was given a little display of how my session had gone, and how I might be able to resume it in the future.
╭─╮╭─╮ Changes +95 -0 ╰─╯╰─╯ Requests 3 Premium (55m 59s) █ ▘▝ █ Tokens ↑ 1.5m • ↓ 20.3k • 1.5m (cached) • 8.6k (reasoning) ▔▔▔▔ Resume copilot --resume=b969b5eb-4a1b-4e88-8945-18b8843c65e9
Once your allowance is used, premium requests are billed at 0.04/request,sointheorythislittleexperimentjustcostme0.04/request, so in theory this little experiment just cost me 0.04/request,sointheorythislittleexperimentjustcostme0.12 (though this is already coming out of my bundled allowance currently).
The token usage will count toward the new ill defined and not publicized token rate limits, but I haven’t had any problems with those since bumping from the Pro to Pro+ plan
Within the sandbox context, my session was resumable too!
sbx run copilot -- --resume=b969b5eb-4a1b-4e88-8945-18b8843c65e9
I was actually trying to figure out if I could use these sandboxes alongside the new VsCode agents window which provides a nice UI into agent sessions in a variety of places, including remote SSH and GitHub tunnels, however I’m yet to figure out how to hook that up with the sandbox workflow that I just ran through…
Perhaps more on that in the future…
13 May 2026 – The Wikimedia Foundation, the nonprofit organization that operates Wikipedia and other Wikimedia projects, celebrates becoming a member of the Digital Public Goods Alliance (DPGA), a multi-stakeholder initiative endorsed by the United Nations that promotes the discovery, development, and use of digital public goods (DPGs) — open-source software, dataset, AI models, and content — to advance the Sustainable Development Goals (SDGs).
“The Wikimedia Foundation is honored to become an official member of the Digital Public Goods Alliance. This membership reaffirms our commitment to the importance of open knowledge as a public good, ensuring it remains accessible, rights-based, and governed in the public interest,” said Jan Gerlach, Public Policy Director at the Wikimedia Foundation. “Wikipedia, Wikidata, and other Wikimedia projects show how hundreds of thousands of people working together across borders can create and maintain free and open knowledge infrastructure built in the public interest. As the host of these projects, we look forward to sharing our learnings and collaborating more closely with fellow DPGA members who share our vision of an internet that protects and promotes community-led spaces.”
“We warmly welcome the Wikimedia Foundation to the Digital Public Goods Alliance. Wikipedia and Wikidata have long demonstrated the transformative power of open, community driven digital public goods to advance access to knowledge worldwide. The organization’s leadership in strengthening open knowledge infrastructure and advocating for digital public goods will further strengthen the global DPG ecosystem and support more inclusive and equitable access to trusted knowledge online.” said Liv Marte Nordhaug, CEO of the DPGA Secretariat.
As a DPGA member, the Wikimedia Foundation joins an impressive coalition of organizations working together to protect and expand digital public goods and infrastructure, including: the United Nations Educational, Scientific and Cultural Organization (UNESCO), GitHub; United Nations Children’s Emergency Fund (UNICEF); the Inter-American Development Bank; and the governments of Norway, Brazil, Nigeria, France, South Africa, and Germany — to name but a few.
DPGA member activities to strengthen the infrastructure behind free knowledge
As part of the Wikimedia Foundation’s membership to DPGA, we will conduct activities that demonstrate how we invest in digital public goods to achieve SDGs. These efforts will be published in the annual State of the DPG Ecosystem Report and listed on DPGA Roadmap webpage alongside other members. Our activities include:
Investing in Wikimedia Cloud Services: Wikimedia Cloud Services is the platform that supports open software for those who make free knowledge possible. Around 30% of all edits to Wikimedia projects rely on volunteer-developed tools hosted on Wikimedia Cloud Services. As part of our DPGA membership activities, the Wikimedia Foundation will strengthen Wikimedia Cloud Services and the core infrastructure used to host Wikimedia projects. This includes improving scalability, security, and usability; lowering barriers for new contributors; and expanding capabilities to support innovation. These investments demonstrate our commitment to stewarding Wikipedia and Wikidata as global DPGs, and help advance the DPGA’s mission of inclusive digital participation.
Advocating the importance of Digital Public Goods: The Wikimedia Foundation will also continue to advocate the importance of open knowledge infrastructure in the global digital policy agenda. As a DPGA member, the Wikimedia Foundation will promote open-source-first approaches, responsible use of open data for public interest AI, and the role of DPGs for information integrity. We will do so through coordinated advocacy efforts, regional dialogues, global convenings, publications, and useful tools like the Wikipedia Test. By drawing from the experience of hosting Wikipedia, Wikidata, and other Wikimedia projects, the Wikimedia Foundation will guide and support policymakers, media, and industry in understanding and protecting DPGs.
The Wikimedia Foundation and Digital Public Goods
This membership is a natural next step in the Wikimedia Foundation’s advocacy for policies that protect and support Wikipedia and other DPGs upon which the free knowledge ecosystem depends.
In 2024, the Wikimedia Foundation, volunteer affiliates, and other partners published an open letter about the Global Digital Compact — the UN’s framework for global governance of digital technology and artificial intelligence (AI). The open letter called on UN Member States to include commitments in the Compact to empower and protect online public interest projects, such as Wikipedia and Wikidata, and also to develop and use AI to support people, not replace them.
In 2025, two Wikimedia projects — Wikipedia and Wikidata —were officially recognized as digital public goods by the DPGA. The recognition affirmed the important role that volunteer contributors to these projects play in building a better internet that serves the public interest.
About the Digital Public Goods Alliance
The DPGA is endorsed by the United Nations (UN) Secretary-General in support of open-source technologies that advance the SDGs. DPGA facilitates the discovery, development, use of and investment in digital public goods. Their work includes maintaining the DPG Registry with solutions such as open-source software, datasets, AI models, and content created for the public interest. Wikipedia and Wikidata were recognized as digital public goods and added to their registry in 2025.
About the Wikimedia Foundation
The Wikimedia Foundationis the nonprofit that operates Wikipedia and other Wikimedia projects. We support the people, technology, and policies that enable reliable information to be shared with the world. The Wikimedia Foundation is a United States 501(c)(3) tax-exempt organization with offices in San Francisco, California, USA. Visit our website to learn more about the Wikimedia Foundation and Wikipedia.
For media inquiries, please contact press@wikimedia.org
Subscribe to our newsletter to stay informed on internet policy and Wikipedia’s future.
The post Wikimedia Foundation joins Digital Public Goods Alliance to champion open knowledge infrastructure appeared first onWikimedia Foundation.
All humans move plants, most often by accident and sometimes with intent. Humans, unfortunately, are only rarely_moved_ by the sight of exotic plants.
Unfortunately, the history of plant movements is often difficult to establish. In the past, the only way to tell a plant's homeland was to look for the number of related species in a region to provide clues on their area of origin. This idea was firmly established by Nikolai Vavilov before he was sent off to Siberia, thanks to Stalin's crank-scientist Lysenko, to meet an early death. Today, genetic relatedness of plants can be examined by comparing the similarity of DNA sequences (although this is apparently harder than with animals due to issues with polyploidy). Some recent studies on individual plants and their relatedness have provided insights into human history. A study on baobabs in India and their geographical origins in East Africa established by a study in 2015 and that of coconuts in 2011 are hopefully just the beginnings. These demonstrate ancient human movements which have never received much attention from most standard historical accounts.
 |
|---|
| Inferred trasfer routes for Baobabs - source |
Unfortunately there are a lot of older crank ideas that can be difficult for untrained readers to separate. I recently stumbled on a book by Grafton Elliot Smith, a Fullerian professor who succeeded J.B.S.Haldane but descended into crankdom. The book "Elephants and Ethnologists" (1924) can be found online and it is just one among several similar works by Smith. It appears that Smith used a skewed and misapplied cultural cousin ofDollo's Law. According to him, cultural innovation tended to occur only once and that they were then carried on with human migrations. Smith was subsequently labelled a "hyperdiffusionist", a disparaging term used by ethnologists. When he saw illustrations of Mayan sculpture he envisioned an elephant where others saw at best a stylized tapir. Not only were they elephants, they were Asian elephants, complete with mahouts and Indian-style goads and he saw this as definite evidence for an ancient connection between India and the Americas! An idea that would please some modern-day Indian cranks and zealots.
 |
|---|
| Smith's idea of the elephant as emphasised by him. |
 |
|---|
| The actual Stela in question |

"Fanciful" is the current consensus view on most of Smith's ideas, but let's get back to plants.
I happened to visit Chikmagalur recently and revisited the beautiful temples of Belur on the way. The "Archaeological Survey of India-approved" guide at the temple did not flinch when he described an object in the hand of a carved figure as being maize. He said maize was a symbol of prosperity. Now maize is a crop that was imported to India and by most accounts only after the Portuguese reached the Americas in 1492 and made sea incursions into India in 1498. In the late 1990s, a Swedish researcher identified similar carvings (actually another one at Somnathpur) from 12th century temples in Karnataka as being maize cobs. It was subsequently debunked by several Indian researchers from IARI and from the University of Agricultural Sciences where I was then studying. An alternate view is that the object is a mukthaphala, an imaginary fruit made up of pearls.
 |
|---|
| Somnathpur carvings. The figures to theleft and right hold the puported cobs in their left hands.(Photo: G41rn8) |
The pre-Columbian oceanic trade ideas however do not end with these two cases from India. The third story (and historically the first, from 1879) is that of the sitaphal or custard apple. The founder of the Archaeological Survey of India, Alexander Cunningham, described a fruit in one of the carvings from Bharhut, a fruit that he identified as custard-apple. The custard-apple and its relatives are all from the New World. The Bharhut Stupa is dated to 200 BC and the custard-apple, as quickly pointed out by others, could only have been in India post-1492. TheHobson-Jobson has a long entry on the custard apple that covers the situation well. In 2009, a study again raised the possibility of custard apples in ancient India. The ancient carbonized evidence is hard to evaluate unless one has examined all the possible plant seeds and what remains of their microstructure. The researchers however establish a date of about 2000 B.C. for the carbonized remains and attempt to demonstrate that it looks like the seeds of sitaphal. The jury is still out.
 |
|---|
| Hobson-Jobson has an interesting entry on the custard-apple |
I was quite surprised that there are not many writings that synthesize and comment on the history of these ideas on the Internet and somewhat oddly I found no mention of these three cases in the relevant Wikipedia article (naturally, fixed now with an entire new section) - pre-Columbian trans-oceanic contact theories
There seems to be value for someone to put together a collation of plant introductions to India along with sources, dates and locations of introduction. Some of the old specimens of introduced plants may well be worthy of further study.
Introduction dates
- Pithecollobium dulce - Portuguese introduction from Mexico to Philippines and India on the way in the 15th or 16th century. The species was described from specimens taken from the Coromandel region (ie type locality outside native range) by William Roxburgh.
- Eucalyptus globulus? - There are some claims that Tipu planted the first of these (See my post on this topic). It appears that the first person to move eucalyptus plants (probably E. globulosum) out of Australia was Jacques Labillardière. Labillardiere was surprized by the size of the trees in Tasmania. The lowest branches were 60 m above the ground and the trunks were 9 m in diameter (27 m circumference). He saw flowers through a telescope and had some flowering branches shot down with guns! (original source in French) His ship was seized by the British in Java and that was around 1795 or so and released in 1796. All subsequent movements seem to have been post 1800 (ie after Tipu's death). If Tipu Sultan did indeed plant the Eucalyptus here he must have got it via the French through the Labillardière shipment. The Nilgiris were apparently planted up starting with the work of Captain Frederick Cotton (Madras Engineers) at Gayton Park(?)/Woodcote Estate in 1843.
- Muntingia calabura - when? - I suspect that Tickell's flowerpecker populations boomed after this, possibly with a decline in the Thick-billed flowerpecker.
- Delonix regia - when?
- In 1857, Mr New from Kew was made Superintendent of Lalbagh and he introduced in the following years several Australian plants from Kew including Araucaria, Eucalyptus,Grevillea, Dalbergia and Casuarina.Mulberry plant varieties were introduced in 1862 by Signor de Vicchy. The Hebbal Butts plantation was establised around 1886 by Cameron along with Mr Rickets, Conservator of Forests, who became Superintendent of Lalbagh after New's death - rain trees, ceara rubber (Manihot glaziovii), and shingle trees(?). Apparently Rickets was also involved in introducing a variety of potato (kidney variety) which got named as "Ricket". -from Krumbiegel's introduction to "Report on the progress of Agriculture in Mysore" (1939) [Hebbal Butts would be the current day Airforce Headquarters)
The following have been listed as pre-1861 introductions in Lal Bagh (from the centenary souvenir, 1957):
Grevillea robusta (1857, presented. by Y. Rohde.)
Araucaria excelsa (1857)
Amherstia nobilis (1859)
Anona muricata
Averrhoa Bilimbi
Poinciana regia
Cassia florida
Carica papaya
Parkinsonia aculeata
Eriobotrya japonica
Casuarina equisetifolia
Castanospermum australe
Araucaria Bidwilli
A. cookii
A. cunninghamii
Cupressus species,
Damara robusta,
Bixa Orellana,
Hibiscus rosasinensis,
Gossypium barbadense,
Coffea arabica,
Vanilla aromatica,
Pisum sativum,
Arachis hypogaea,
Medicago sativa,
Daucus carota
Brassica oleracea
Lactuca sativa
Solanum tuberosum
Beta vulgaris
Myrtus communis
Corypha umbraculifera
C. australis
Ammomum angustifolium
Macadamia sp.
Podocarpus longifolia
Pinus longiolia,
P. sylvestris,
P. pseudo-strophilus
Allamanda cathartica
Achras sapota
Persea gratissima
Java fig
Swietenia mahogani (mahogany was first introduced into Bengal in 1795 from the West Indies)
litchi
guava
pineapple
tobacco
Introduced between 1861 and 1874
Averrhoa carambola
Swietenia mahogani
Parkia biglandulosa
Joannesia princeps (Anda gomesii )
Kigelia pinnata
Crescentia alata
Filicium decipiens
Caesalpinia pulcherrima
Ceratonia siliqua
Magnolia grandiflora
Theobroma cacao
Lantana odorata
Fragaria vesica
Prunus persica
Prunus communis
Pyrus malus
Pyrus communty
Eugenia jambos
After 1874 (by John Cameron)
Boehmeria nivea Hooker (1874)
Coffea liberica
Helianthus annuas Linn, (1875)
Adansonia digitata Linn., from Calcutta
Bursaria spinosa Cav. Tristania conferta R.Br., both from. Adelaide
Clausena Wampi Blanco from Ceylon (1876)
Couroupite guranensis
Enchylaena luxurius,
Bambusa vulgaris from Calcutta (1877)
Prosopis juliflora
Pithecolobium saman from Ceylon
Trapa bispinosa from north India (1878)
Mahinot Glaziovii from the Royal Botanic Garden, Calcutta (1879)
Colvillea racemosa (1880)
Erithryxylum coca
Barringtonia speciosa trom Ceylon (1881)
Cyphonandra betacea
Cola acuminata (1884)
Artocarpus incisa (1886)
Castanea vulgaris
Hevea Spruccana
Carissa edulis from Kew
Sechium edule from Ceylon1
Monstera deliciosa from Kew
Myroxylon penniferum from Kew
Glycine hispida
Landolphia watsoni from Kew (1887)
Albizzia moluccana from the Moluccas (1892)
Paspalum notatum from Calcutta (1900)
Further reading
- Johannessen, Carl L.; Parker, Anne Z. (1989). "Maize ears sculptured in 12th and 13th century A.D. India as indicators of pre-columbian diffusion". Economic Botany 43 (2): 164–180.
- Payak, M.M.; Sachan, J.K.S (1993). "Maize ears not sculpted in 13th century Somnathpur temple in India". Economic Botany 47 (2): 202–205.
- Pokharia, Anil Kumar; Sekar, B.; Pal, Jagannath; Srivastava, Alka (2009). "Possible evidence of pre-Columbian transoceanic voyages based on conventional LSC and AMS 14C dating of associated charcoal and a carbonized seed of custard apple (Annona squamosa L.)" Radiocarbon 51 (3): 923–930. - Also see
- Veena, T.; Sigamani, N. (1991). "Do objects in friezes of Somnathpur temple (1286 AD) in South India represent maize ears?". Current Science 61 (6): 395–397.
- Rangan, H., & Bell, K. L. (2015). Elusive Traces: Baobabs and the African Diaspora in South Asia. Environment and History, 21(1):103–133. doi:10.3197/096734015x1418317996982 [The authors however make a mistake in using Achaya, K.T. Indian Food (1994) who in turn cites Vishnu-Mittre's faulty paper for the early evidence of Eleusine coracana in India. Vishnu-Mittre himself admitted his error in a paper that re-examined his specimens - see below]
Dubious research sources
- Singh, Anurudh K. (2016). "Exotic ancient plant introductions: Part of Indian 'Ayurveda' medicinal system". Plant Genetic Resources. 14(4):356–369. 10.1017/S1479262116000368. [Among the claims here are that Bixa orellana was introduced prior to 1000 AD - on the basis of Sanskrit names which are assigned to that species - does not indicate basis or original dated sources. The author works in the "International Society for Noni Science"! ]
- The same author has rehashed this content with several references and published it in no less than the Proceedings of the INSA - Singh, Anurudh Kumar (2017) Ancient Alien Crop Introductions Integral to Indian Agriculture: An Overview. Proceedings of the Indian National Science Academy 83(3). There is a series of cherry-picked references, many of the claims of which were subsequently dismissed by others or remain under serious question. In one case there is a claim for early occurrence of Eleusine coracana in India - to around 1000 BC. The reference cited is in fact a secondary one - the original work was by Vishnu-Mittre and the sample was rechecked by another bunch of scientist and they clearly showed that it was not even a monocot - in fact Vishnu-Mittre himself accepted the error - the original paper was Vishnu-Mittre (1968). "Protohistoric records of agriculture in India". Trans. Bose Res. Inst. Calcutta. 31: 87–106. and the re-analysis of the samples can be found in - Hilu, K. W.; de Wet, J. M. J.; Harlan, J. R. Harlan (1979). "Archaeobotanical Studies of Eleusine coracana ssp. coracana (Finger Millet)". American Journal of Botany. 66 (3):330–333. Clearly INSA does not have great peer review and have gone with argument by claimed authority.

- PS 2019-August. Singh, Anurudh, K. (2018). Early history of crop presence/introduction in India: III. Anacardium occidentale L., Cashew Nut. Asian Agri-History 22(3):197-202. Singh has published another article claiming that cashew was present in ancient India well before the Columbian exchange - with "evidence" from J.L. Sorenson of a sketch purportedly made from a Bharhut stupa balustrade carving - the original of which is not foundhere and a carving from Jambukeshwara temple with a "cashew" arising singly and placed atop a stalk that rises from below like a lily! He also claims that some Sanskrit words and translations (from texts/copies of unknown provenance or date) confirm ancient existence. I accidentally asked about whether he had examined his sources carefully and received a rather interesting response which I find very useful as a classic symptom of the problems of science in India. More interestingly I learned that John L. Sorenson is well known for his affiliation with the Church of Jesus Christ of Latter-day Saints and apparently part of Mormon foundations is the claim that Mesoamerican cultures were of Semitic origin and much of the "research" of their followers have attempted to bolster support for this by various means. Below is the evidence that A.K.Singh provides for cashew in India.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


Worth examining the motivation of Sorenson through the life of a close associate - here
PS: 2026 - following some discussions on Wikipedia, I came across Dorian Fuller's review/critique of the book World trade and biological exchanges before 1492.
- From the team: How the GLAM Community Can Shine in the 2026–27 Annual Plan
- Albania report: International Roma Day 2026 in Tirana, Albania
- Argentina report: WikiConf Argentina and GLAM projects
- Asia report: Documenting and citing oral knowledge in audio and video
- Australia report: WikiCon Australia, ICIP, Orphan works and Trans-Tasman partnerships
- Brazil report: Wikimedia Brasil publishes book on the power and challenges of free knowledge
- Colombia report: We celebrate Public Domain Day with an expert panel / Celebramos el día del dominio público con un Panel de expertas
- Italy report: Ongoing and New GLAM-Wiki Projects
- New Zealand report: Women in Wartime event at Auckland Museum & an update for WiR NZBSI
- Nigeria report: Wikimedia Commons Upload Campaign
- North Macedonia report: Wikimedia MKD in Action: Digitization, Wikisource and Educational Workshops
- Poland report: GLAM-Wiki Developments: Residencies, Partnerships and Audiovisual Heritage
- Serbia report: April in Wikimedia Serbia
- Switzerland report: Le Donne di Villa Massimo
- UK report: A tenth-century Quran and Islamic Art in Urdu
- USA report: Wiki MIT launches and US meetups
- Biodiversity Heritage Library report: Update on the BHL Annual Meeting 27 April – 1 May & BHL Day
- Memory of the World report: Eight new articles on MoW inscriptions
- Calendar: May’s GLAM events
The Release-Engineering-Team of the Wikimedia Foundation just deployed an upgrade of Wikimedia Phabricator.
It includes a few changes:
Downstream dependency tree of tasks: T404375: Update to Phorge upstream / Arcanist upstream to 2025-11-12 code
Upstream changelogs:
We also recently deployed some changes to reduce the load created by aggressive web crawlers: Browsing code repositories in Diffusion asks for login, and viewing project workboards requires login. This creates some inconvenience for users but helps us to keep services available.
If you have comments or questions about Phab, please bring them up on the Phabricator Talk page!
30/04/2026-06/05/2026

[1] | Cast-iron Street Map of the City Centre in the Ukrainian City of Poltava
Mapping
- Comments are requested on this proposal:
name:<language>-Latnto consistentlytag transliterations in Latin script worldwide following BCP 47.
- The following proposal is up for a vote until Tuesday 12 May:
route=safarito map safari routes as dedicated relations and structure drive-through tourist routes in safari parks.
- Christoph Hormann expanded on his earlier critique of the German FOSSGIS association (we reportedearlier) and is proposing a federated structure to better balance the interests of the FOSS community and OSM mappers. The aim is to address the ongoing tension between professional users and hobby contributors.
- Kamil Kalata analysedhow many OSM elements use tags documented on the wiki. The results showed that about 99.99% of tagged elements contain at least one documented key, even though only a small share of all keys are described on the wiki.
- A forum discussion is exploring which routes should be stored in OSM and which should be managed externally. The platform mapeak.com is presented as a possible solution for sharing and managing routes outside the OSM database.
- OpenStreetMap way IDs have reached 1.5 billion. The milestone object was created by user Colbertson. There are just under 1.2 billion ways currently in OSM.
Local chapter news
- OpenStreetMap Syria participated in a webinar titled ‘(Re)Envisioning Syria: Earth Observation Research on Conflict Damage and Recovery’, organised by the Humanitarian OpenStreetMap Team and the Distributed Damage Mapping Group with support from the H2H Network, as part of the ReMapping Syria project.
Events
Education
- Betaslb noted that students from the Escola Secundária Jerónimo Emiliano de Andrade, studying Legal Services Technician and Educational Action Technician 1, decided that the best way to celebrate the 50th anniversary of the autonomy of the Autonomous Region of the Azores was to create a journey through some of the places that have contributed and continuously contribute to an ever-stronger autonomy, which resulted in thismap.
OSM research
Maps
- Gespot
 has made it possible to view overhead power and telecommunications lines, as well as their support structures, as recorded in the OpenStreetMap database. Thisongoing ►project is in partnership with Enedis ►and has the support of the OpenStreetMap France Association ►.
has made it possible to view overhead power and telecommunications lines, as well as their support structures, as recorded in the OpenStreetMap database. Thisongoing ►project is in partnership with Enedis ►and has the support of the OpenStreetMap France Association ►. - A Reddit post presented an interactive map of India’s planned high-speed rail corridors based on OpenStreetMap data. The map visualises routes, stations, and interconnections in a diagram-style layout.
- Sean Carapellahas launched PaddleMap, a map and routing tool specialised for watercraft based on BRouter and BRouter-web. PaddleMap allows routing on waterways and portage routes with customised routing for whitewater skill, portage style, and other paddling preferences. It also highlights canoe, kayak, and other paddle craft-related POIs including slipways, waterway access points, dams, waterfalls, rapids, etc.
OSM in action
- Is your car electric? Then you should give the ABRP route planner a try. Powered by OSM, of course.
- Komoot explained in a recently updated FAQ that their navigation and automatic re-planning are based on OpenStreetMap data. Limitations may occur if routes are incompletely mapped or there is no internet connection for new route calculations.
Open Data
- Anne-Karoline Distel demonstrated, in a video, a map of holy wells in Ireland dedicated to female saints. The map is based on OpenStreetMap and Wikidata and shows how such data can be visualised using uMap.
Licenses
Software
Programming
- Evert Pot outlineda method for setting up a TCP server that emits a static GPS-like coordinate, allowing Linux applications to continue accessing location information after Mozilla shut down their location service. The server feeds coordinate data directly to geoclue, enabling location-aware features to continue to work.
- Evgeny Arbatov presenteda tool that combines multiple GPX files into a cleaned route by matching them to OSM ways and optimising the geometry. It uses services such as Overpass and OSRM to produce more accurate tracks.
- OpenStreetMap has been selected as an organisation for Google Summer of Code 2026, offering projects on topics such as routing, Nominatim, and tile servers. Earlier, the OSM team invited the community to submit project ideas and volunteer as mentors.
- A new helper tool allows GeoJSON and JSON routes to be sent directly to JOSM. It is designed to streamline workflows when preparing and refining routes from external analysis tools.
- The latest MapLibre newsletter has reported on progress made across MapLibre GL JS, Native, Flutter, and React Native. Highlights included the preparations for version 6, new APIs, and work on a dedicated 3D tile format.
Releases
- Version 2026.04.23 of CoMaps is available. It comes with refreshed OSM data up to 21 April. The main changes for the Android app include being able to select a preferred interface language, as well as the ability to switch between turn-by-turn navigation details for the next stop or the final destination. This release also brings a range of bug fixes and tweaks.
- stac-map is a web-based tool for visualisingSTAC datasets and geospatial data directly in the browser. Version 2.0 has introducedfeatures including sharing links, URL-based configuration, and improvements in rendering and performance.
- Yopaseopor has introduced 3DModelsOSM, an experimental renderer that turns OpenStreetMap data into simple 3D models. The tool can load Overpass query results or GeoJSON and serves as a proof-of-concept for detailed micromapping and 3D visualisation.
- Pablo Brasero (aka pablobm) shared a new update from the OSM website team, detailing their latest work including security fixes, more efficient use of assets, and routing improvements.
Did you know that …
- … Anne-Karoline Distel has a brief step-by-step tutorial, on her YouTube channel, on how to upload photos to Wikimedia Commons and include them in marker labels on uMap?
- … the Philippine Viscan YouthMappers group carried out a youth-led project mapping fire hydrants as reference data for fire emergency response in 2022–2023? They created a uMap showing the locations of fire hydrants in the city of Leyte.
- … OpenChargeMap aims to provide an open database of charging equipment locations globally?
- … the free online tool Streckenheld allows motorcyclists to share dangerous spots in traffic they have found? This means that tours can be planned ►better and dangerous situations in traffic can be avoided.
- … the Whole Earth Foundation (WFF) has created Tekkon, a game for mapping infrastructure? It is available on APKCombo. The WFF is a non-profit organisation with its headquarters in Singapore, which creates, provides, and operates an infrastructure information platform for community initiatives.
- … Nosolosig
 ►maintains a Telegram group, Detrás del mapa ►, to share news and resources on maps and geographic information technologies?
►maintains a Telegram group, Detrás del mapa ►, to share news and resources on maps and geographic information technologies? - … that OpenStreetMap wouldn’t be possible without the support of many organisations around the world who donate their time, hosting space, or hardware to help us?
- Chris Hunter described OpenStreetMap as core infrastructure in the geospatial ecosystem and emphasised the importance of local contributions. They showed how OSM’s continuous updates and community-driven approach can make it more current than official datasets.
- Ralph Straumann reported, on Spatialists, about Panoramax, the open street-level imagery project developed by OSM France and the French mapping agency IGN. The article highlighted its current status and plans for international growth.
Other “geo” things
- [1] In the Ukrainian city of Poltava, there are manhole covers on Pylypa Orlyka Street featuring
 a cast iron street map of the city centre. The design, created by the local bureau Axioma Design in 2016, was funded and implemented by entrepreneur Oksana Demkova in 2023.
a cast iron street map of the city centre. The design, created by the local bureau Axioma Design in 2016, was funded and implemented by entrepreneur Oksana Demkova in 2023. - The European Tech Map visualises technology and innovation locations across Europe using OpenStreetMap. This interactive map allows users to explore projects and initiatives geographically.
- Jérôme Gagnon-Voyer introduced publicly accessible geocoder APIs from the City of Toronto for address search and reverse geocoding. The services provide coordinates and administrative information and can be used without authentication.
- A news report from Toronto highlighted how an error on Google Maps directed drivers the wrong way down a one-way street. The incident underlines the importance of accurate and up-to-date geospatial data for navigation services.
- Qiusheng Wu introduced OpenGeoAgent, an open-source agent that automates geospatial analysis and visualisation using natural language. The tool supports QGIS, Python, and Jupyter and enables multimodal interaction.
- Dominic Royé outlinedhow to select the most appropriate map projection for a given purpose, while highlighting some common pitfalls to avoid.
Upcoming Events
| Country | Where | Venue | What | When |
|---|---|---|---|---|
|
Sovigliana-Vinci | Mappando si Vinci! – 2 Maggio 2026 |
2026-05-02 – 2026-06-02 | |
|
[online] | Capacitação OSM 2026 – IVIDES DATA ® – Editor iD – Parte I |
2026-05-08 | |
 |
online | SOSM Association Annual Meeting |
2026-05-08 | |
|
Madurai | Madurai Startups Spaces | OSM Madurai Armchair mapping party |
2026-05-09 |
 |
København | Cafe Bevar’s | OSMmapperCPH |
2026-05-10 |
|
Delhi | Kori’s, Humayunpur, Delhi | OSM Delhi Mapping Party No.29 (South Zone) |
2026-05-10 |
| Missing Maps : Mapathon en ligne – CartONG [fr] |
2026-05-11 | |||
|
Zürich | Bitwäscherei Zürich | 187. OSM-Stammtisch Zürich |
2026-05-11 |
|
Grenoble | La Turbine | Atelier de mai 2026 du groupe local OpenStreetMap de Grenoble |
2026-05-11 |
 |
臺北市 | MozSpace Taipei | OpenStreetMap x Wikidata Taipei #88 |
2026-05-11 |
|
Magdeburg | Netz39 e.V. , Leibnizstraße 32, 39104 Magdeburg | 1. OSM Stammtisch Magdeburg |
2026-05-12 |
|
Hamburg | Voraussichtlich: “Variable”, Karolinenstraße 23 | Hamburger Mappertreffen |
2026-05-12 |
|
temporärhaus | OSM-Stammtisch Ulm/Neu-Ulm |
2026-05-12 | |
|
Maison des associations de Bayonne – salle Valmont | Rencontre Mapadour |
2026-05-13 | |
 |
Praha | Seznam.cz | Pražský mapathon s Lékaři bez hranic v Seznam.cz |
2026-05-13 |
 |
Amsterdam | TomTom HQ | 2026 Spring End Maptime |
2026-05-13 |
|
München | Echardinger Einkehr | Münchner OSM-Treffen |
2026-05-13 |
| Mapaton – Marsh |
2026-05-14 | |||
 |
Žilina | Fakulta riadenia a informatiky UNIZA | Missing Maps mapathon Žilina #22 |
2026-05-14 |
|
Berlin | BrewDog DogTap Berlin, Im Marienpark 23 | 215. OSM-Stammtisch Berlin-Brandenburg |
2026-05-14 |
|
Acireale | Mappiamo le Aci |
2026-05-16 – 2026-05-17 | |
|
New York | East River Park at Corlears Hook | NYC Mapper Picnic |
2026-05-17 |
|
Chennai Corporation | Hotel Nithya Amirtham, Mylapore Market, Chennai | Mapping at Mylapore Market, Chennai |
2026-05-17 |
|
Bologna | aula 0.6, DICAM, Unibo, Viale del Risorgimento 2 | Unibo Mapathon OpenStreetMap 2026-05 |
2026-05-18 |
|
Mannheim | RaumZeitLabor, Mannheim | Rhein-Neckar OpenstreetMap Treffen |
2026-05-18 |
| Webinaire de sensibilisation à OpenStreetMap pour les collectivités |
2026-05-19 | |||
| Missing Maps London Mid-Month (Without Training) Advanced Mappers [eng] |
2026-05-19 | |||
|
Lyon | Tubà | Réunion du groupe local de Lyon |
2026-05-19 |
|
Chemnitz | Kaffeesatz, Chemnitz | OSM-Stammtisch Chemnitz |
2026-05-19 |
|
Bonn | Dotty’s | 200. OSM-Stammtisch Bonn |
2026-05-19 |
|
Online | Lüneburger Mappertreffen (online) |
2026-05-19 | |
|
MJC de Vienne | Rencontre des contributeurs de Vienne (38) |
2026-05-20 | |
| Online Missing Maps Mapathon ÄRZTE OHNE GRENZEN (AT/DE) |
2026-05-20 | |||
|
Karlsruhe | Chiang Mai | Stammtisch Karlsruhe |
2026-05-20 |
|
[online] | Capacitação OSM 2026 – IVIDES DATA ® – Editor iD – Parte II |
2026-05-22 | |
|
Ferrara | Ferrara | Raccolta dati aree verdi @ Giornata Mondiale della Biodiversità 2026 – Citizen Science Ferrara |
2026-05-23 |
|
Navi Mumbai | OSM Mumbai Mapping Party No.10 (Trans-Harbour Line – North) |
2026-05-23 | |
|
Bologna | Velostazione ExDynamo | Compleanno di Wikipedia a Bologna 2026, con wikigita e mapping party in Bolognina e pranzo alla velostazione |
2026-05-24 |
| Missing Maps : Mapathon en ligne – CartONG [fr] |
2026-05-25 |
Note:
If you like to see your event here, please put it into the OSM calendar. Only data which is there, will appear in weeklyOSM.
This weeklyOSM was produced by Raquel IVIDES DATA, Strubbl, Andrew Davidson, barefootstache,darkonus,derFred,izen57, mcliquid. We welcome link suggestions for the next issue via thisform and look forward to your contributions.
The latest news on our partnership with Terri Janke and Company (TJC) on WMAU's ICIP and IDSov work.
In late 2025 Wikimedia Australia (WMAU) engaged Terri Janke and Company (TJC), a leading Australian Indigenous-owned law firm and consultancy, specialising in Indigenous Cultural and Intellectual Property (ICIP) and Indigenous Data Sovereignty (IDSov) to develop the first stage of a First Nations Protocol for WMAU.
This partnership will provide Wikimedia Australia, its members, and partners with a clear framework for responsibly engaging with and supporting First Nations Peoples and communities. The Protocol will ensure that Wikimedia Australia’s work respects Indigenous knowledge systems and supports the rights of Indigenous Peoples to be centred in and control the use of their data and cultural heritage.
As of early 2026 an Indigenous Expert Working Group has been formed. Terri and her team presented a draft of the ICIP Guide to Australian editors at WikiCon Canberra in April 2026, for discussion and feedback. The ICIP Guide will be released in June/July 2026, with an accompanying Issues Paper documenting questions outstanding to inform future phases of the Protocol's development.
- Open platforms, open minds, respectful practices: ICIP & IDSov Guide for Wikimedia Australia — Friday 10 April 2026
Dr Terri Janke will present an overview of the ICIP and Indigenous Data Sovereignty project she is leading for Wikimedia Australia, followed by a panel discussion.
Presentations

View the presentation from Terri Janke on YouTube
A short video presentation was produced by Terri Janke and Company outlining the Wikimedia Australia ICIP and IDSov Protocol project. The project will help ensure Wikimedia Australia’s work reflects best practice in engaging with Indigenous knowledge, communities and content.
Wikimedia Netherlands also requested a short presentation about the Wikimedia Australia ICIP and IDSov Protocol project as part of their annual WikiConNL 2025. We sent the short video presentation by Terri Janke that was played at the conference, along with WMAU staff attending online to answer questions from participants.
Latest News
Useful links and resources for First Nations
Mike Pascoe is the President of the Lafayette History Museum in Lafayette, Colorado and associate professor at the University of Colorado Anschutz Campus.
When I enrolled in one of Wiki Education’s 250 by 2026 Wiki Scholars courses, I expected to learn how to edit Wikipedia more effectively. What I did not expect was how quickly the work would evolve into something that felt much closer to public scholarship than a typical academic exercise.
Like many first-time editors, I initially found Wikipedia’s systems and expectations difficult to navigate. Writing for Wikipedia is not the same as writing for an academic journal. It requires a strict adherence to verifiability, a neutral point of view, and a reliance on high-quality secondary sources. Every sentence must be justified. Every claim must be traceable. And every contribution is open to revision by others. That combination creates a level of accountability that is different from traditional academic writing.
My primary project for the course focused on developing the Wikipedia article for a 1937 Colorado Supreme Court case involving allegations of racial discrimination in access to a public swimming pool (https://en.wikipedia.org/wiki/Lueras_v._Lafayette). The case centered on Rose Lueras and other members of the Latino community in Lafayette, Colorado, who challenged their exclusion from a publicly supported facility. Although the plaintiffs argued that their rights had been violated, the court ultimately ruled that there was insufficient evidence to establish a conspiracy or municipal responsibility for the discrimination.

Wedding portrait of Rose Lueras and her husband, taken in Colorado in the early 1920s. Public domain, via Wikimedia Commons.
At the outset, the article required substantial development. The historical, legal, and social context of the case was fragmented, and much of the significance of the case was not clearly articulated. The process of improving the article required not just adding information, but reconstructing a coherent narrative from a combination of legal records, historical sources, and secondary analyses. In doing so, I found myself engaging in a form of synthesis that closely resembles scholarly work, except that the audience was not limited to a specialized academic readership.
What made this project particularly meaningful was its connection to local and underrepresented history. Lueras v. Lafayette is not widely known, yet it provides a concrete example of how racial segregation operated at the community level, often through informal mechanisms rather than explicit legal structures. The case also illustrates the limitations of legal remedies available to marginalized communities during that period. Bringing this history into a widely accessible platform like Wikipedia felt consequential in a way that traditional assignments often do not.
This aligns with a broader pattern seen across Wikipedia-based assignments. Even relatively small contributions can address gaps in coverage and expand public awareness of overlooked topics. As others have noted, adding or improving a single article can “set off ripples of impact” by making previously underrepresented knowledge visible to a global audience. That dynamic was evident throughout this project.
The course, instructed by Kelly Doyle Kim, also emphasized that Wikipedia is not simply a static repository of information, but an active knowledge ecosystem. Contributors are not just summarizing existing knowledge; they are participating in how knowledge is structured, contextualized, and accessed. This was a shift in perspective for me. Rather than viewing Wikipedia as something to consult, I began to see it as a platform where disciplinary expertise can directly shape public understanding.
Separately from this course, I have also explored Wikipedia editing as a form of scholarship in a more formal research context. In a recent peer-reviewed study, Improving science communication and organization visibility through Wikipedia: A case study of the American Association for Anatomy (https://doi.org/10.1002/ase.70234), I examined how systematic improvements to a scientific organization’s Wikipedia article affected its structure, visibility, and perceived credibility. That work demonstrated that targeted editing could produce measurable improvements in both content quality and user perceptions, reinforcing the idea that Wikipedia is a legitimate venue for science communication.
Taken together, these experiences, one rooted in a structured course, the other in a formal research study, highlight different dimensions of the same underlying idea: Wikipedia editing is not just a technical skill. It is a form of public-facing scholarship.

Mike Pascoe. Image courtesy Mike Pascoe, all rights reserved.
There were, of course, challenges. Identifying appropriate sources for Lueras v. Lafayette required careful evaluation, particularly given the historical nature of the topic and the need to prioritize secondary sources. Maintaining a neutral tone when working with material that has clear ethical and social implications also required deliberate attention. These constraints can feel limiting, but they ultimately strengthen the work by enforcing clarity, balance, and evidentiary rigor.
What distinguishes this experience from more traditional academic work is its persistence and reach. A term paper is read once and archived. A Wikipedia article remains visible, editable, and continuously engaged with. Contributions do not end with submission; they become part of an ongoing, collective process of knowledge refinement. This is part of what makes the assignment so effective as a learning tool. It situates writing within a real-world context where accuracy, clarity, and sourcing matter in tangible ways.
More broadly, the course reinforced the value of integrating Wikipedia into academic practice. In an information environment shaped by both widespread access and widespread misinformation, the ability to contribute accurate, well-sourced, and accessible content is increasingly important. Wikipedia assignments provide a structured way to develop these skills while also producing work that extends beyond the classroom.
Wiki Education’s course provided the framework and support needed to engage with this process effectively. It also positioned Wikipedia not as a secondary or informal outlet, but as a central platform for advancing public knowledge.
For me, the most significant outcome was not simply learning how to edit Wikipedia or completing a single article. It was recognizing that contributing to open-access knowledge platforms can be a meaningful extension of academic work, one that connects disciplinary expertise with broader public audiences in a direct and lasting way.
Mike Pascoe, PhD
President, Lafayette History Museum
Associate Professor, Physical Therapy & Physician Assistant Programs
University of Colorado Anschutz Campus
This blog post was developed with the assistance of ChatGPT (OpenAI, GPT-5.3), which was used to support drafting and refinement of structure and language, while Mike Pascoe provided the original ideas, source materials, project context, and conducted all substantive content development, verification, and final revisions. The University of Colorado Anschutz in Aurora sits on the traditional lands of the Cheyenne, Arapaho, Ute, and many other Indigenous nations, whose enduring presence, contributions, and relationships to this land are recognized with respect while acknowledging the ongoing impacts of displacement and injustice.
I recently decided to run an experiment on wikibase.world: what happens when you give an AI agent the keys to a live MediaWiki instance and ask it to do some targetting gardening, including edits to Wikibase?
Meet the Jules free tier, though i’m sure you could use any agent. Over the course of a few hours, I tasked Jules with editing wikibase.world, moving from simple API edits, querying SPARQL, browsing external websites, and even learning how to properly participate in MediaWiki talk pages, requesting for me to edit its knowledge / prompt on a protected wiki page.
Onboarding and Basic API Usage
Before Jules could do anything, it needed an account. I asked it to register itself as “Addagent” using the MediaWiki API and handle the CAPTCHA and token requirements.
The prompt was:
Can you register me an account on https://wikibase.world/ I guess via https://wikibase.world/w/index.php?title=Special:CreateAccount&returnto=Project%3AHome or the API And then tell me the password The username should be “Addagent”
It went ahead and did this first time, and now https://wikibase.world/wiki/User:Addagent exists. To create the account it seemingly used https://www.guerrillamail.com/ which I have since changed to an actual email address I control incase I need to reset the account password (which I also noted down).
One thing of note while using Jules, is that it really is optimized for coding, and it continually reports that it is “Running code review…” between steps, even though there is no code repo and nowhere to commit code to and no real code in this project either, and it continually referred to “pre-submit steps” even though there is not going to be any code submission.
It looks like Python was used by the agent to perform the account creation, and that script included completing whatever CPATCHA it was served as part of the wikibase.cloud hosting.
The screenshot to the right shows the various steps completed by the agent, as it broke down the task to be completed.
A first edit, adding a description
There are many items already on wikibase.world, partly thanks toAddbot (source) which scours the internet every week trying to find new wikibase installations to add, and to update their stats and connections.
An edit that I frequently make to the imported sites, is switching their labels and descriptions around so that the primarily English label is slightly more useful.
https://wikibase.world/wiki/Item:Q3765 has a non descriptive label In the past I set the label to be the full domain, and switched the label to the an alias, can you do that?
This resulted in an edit changing from Test Lib for the label, to the hostname testlib.wikibase.cloud, and moving Test Lib to an alias instead! Exactly what I would normally do by hand.
I could imagine creating a heuristic to detect such cases, especially if the imported name includes the word “test” for example, or is very short, however the use of an LLM I expect would do a pretty good job at detecting names that “look like test sites” or names that are too short and may need additional context.
Archiving a talk page
Now this is a very common thing to happen on a MediaWiki install. Most Wikimedia sites infact have one or more bots that will complete this task, such as Lowercase sigmabot III or ClueBot III.
There is even a whole help page detailing how users can archive talk pages on English Wikipedia. But the basic operation is take content from one page, and put it on a subpage of that page, based on limits on the main talk page, such as number of sections, last activity date etc.
My prompt for this one, targeted the main talk page…
Great, now I want to move all of the topics from https://wikibase.world/wiki/Project_talk:Home to an archive subpage that are over 1 year old… And then also link to the archive in a nice way from that talk page
And this seamlessly moved the content, however it made use of templates that don’t actually exist on the site. (removing content from page, adding it to archive)
The templates were fixed with another little prompt…
Great! However you used archive related templates that do not exist, can you create them? and any other needed templates?
Which caused it to make Template:Archiveand Template:Archives which I continued to refine with a few more prompts to get them the way I wanted them to appear, however even the first version was rather good.
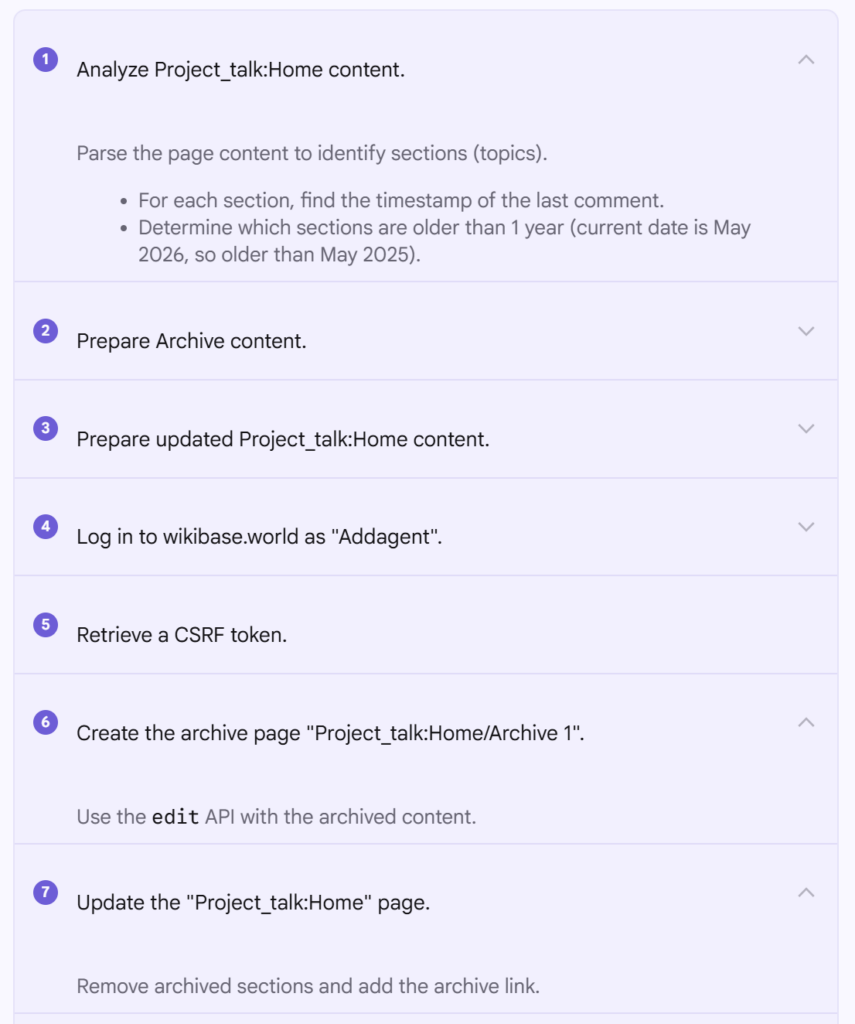
Property list completion
Checking lists by hand, and or parsing SPARQL from URL encoded domains involves a fair few manual steps.
I wanted to make sure that all of the properties that were used in the various SPARQL queries that were listed on the home page of the site, were all included somehow on the Project:Properties page, as many new properties have been created in the last months, and this page has not been getting updated…
The prompt was:
There is a list of properties at https://wikibase.world/wiki/Project:Properties Can you make sure it includes all of the properties that are used in the sparql queries on the main page? https://wikibase.world/wiki/Project:Home
And the edit was rather nice. The addition of {{cwbn}} at the bottom of the page was a little bit of scope creep (this template lists links to the “cool wikibase network”), however I ended up leaving the template, as it kind of fitted with the content of the page anyway…
You can see the identification of the various properties that were found missing from the page, retrieval of the labels and descriptions for the PIDs, and then updating of the page. It’s interesting to note that it seems to know about the{{Property| template from Wikidata, however this is again something on Wikibase installs by default and should not automatically be used. Thankfully it noticed that when it came to make the edit.
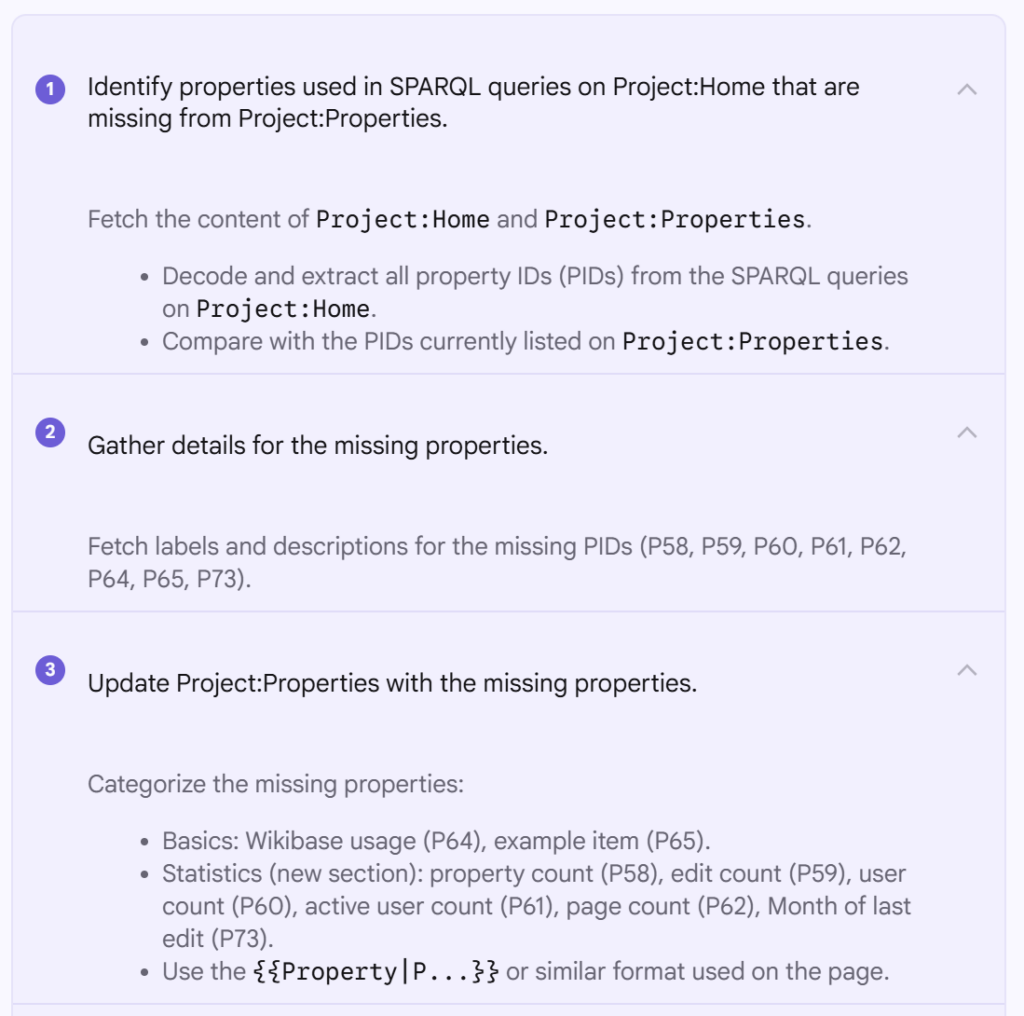
Updating more “test” site names
Earlier we updated the test label of a single test site, however I want to do that for more sites, and figured out that I could get a fairly good list of things that might be worth looking at with a simple search.
So I set the agent to work…
Reviewing https://wikibase.world/w/index.php?title=Special:Search&limit=500&offset=0&profile=default&search=test&ns0=1&ns120=1 there are many items / sites just called “test” Can we try and improve these names, and also possible add some descriptions if we can find out extra info?
This ended up editing 12 different items, the labels were pretty good, however I wasn’t that happy with the very generic descriptions, such as Test Wikibase instance: https://test-lepticed.wikibase.cloud, however they were to be honest, still better than having a totally blank description…
See the edits to Q2709,Q977,Q2743 andQ3507.

Descriptions
In order to improve the description situation above, I realized that I could get the agent to go and look at the wikis that the items were referring to, and then it would likely be able to come up with a much better description…
This is also one of the harder things to do automatically. I have tried extracting first lines or home pages, or things from HTML meta, but they are often rather rubbish, and dont really fit the “description” on wikibase.world itself.
First I tried a single item…
Can you go to https://wikibase.world/wiki/Item:Q35 and take a look at the actul site it points to, them coming back, adding a nice description based on what you see
Which lead to a much longer, and fairly nice description.
So I let it rip on on a SPARQL query from the main page, ordering the sites by number of items, and generating some more descriptions for them.
can you do the same for the other TOP items from this sparql link which do not have a description
maybe for everything with over 100k pages
See Q803,Q2677,Q1495 andQ1893.
That’s when I noticed the full stops at the end of the descriptions, which is something which is generally advised against on Wikidata, and likely for descriptions on Wikibases in general (though there is no way to automatically discover this yourself as an editor…)
So I made a new page, which might be able to serve as a starting prompt for the agent, and protected it to stop malicious actors from changing it, see User:Addagent/prompt, and I first targeted full stops, which it quickly proved that it could follow, so I kept iterating on it, pulling more tips from Wikidata.
And the edits continued improving… Q2352,Q1158 andQ3553

Acronym fixing
Trying to think about other ways the data set could easily be improved by researching on the wikis themselves, I noticed that some site names we just acronyms, such as DFIH, which again, is not very useful for people.
And this is also where I tried to get the agent to write a “skill” for itself, or maybe other agents in the future, that might want to work on the site. (A concept I have stolen from coding agents).
https://wikibase.world/wiki/Item:Q1158 doesn’t look liek it has a great label, maybe the current label should be an alia, and you come up with a new label. Then can you look for any other any other wikibases that have all caps label with now spaces, which implies that it is just an acronym.. I expect all of these could use improving.. I guess the best way to find them is search or a SPARQL query? When you find a method that works for finding and fixing them, perhaps we should document a new “skill” on a sub page of our user?
User:Addagent/skills/label-ancomyn-cleanup for example? Then we could refer to this in the future for a guide on how to approach finding and cleaning up such things
The acronym expansion went very well, expect there was some accidental removing of aliases, I assume to a misunderstanding of the API, that I had to make it adjust.
The initial skill included a SPARQL query to find items that might need to be looked at, as well as the process to fix them. Some of the wikitext leaves a little to be desired, but it works well for the agent, and the wikitext fix likely should just be a slight tweak to the main prompt.
A second refinement was added once I asked it to be more careful about aliases.

Some final things
I ended up getting it to request its own changes to its own system prompt, to then beapproved by me in a similar way to how edit requests work on Wikipedia. But this is when I realized that the {{done}} template didn’t exist on the site, but it was easy enough to get theagent to make one.
I also got it to create a {{ping}} template to that it could more easily ping me when making requests to the prompts (I also got it to tidy up the talk page a little after showing it how to use them with another skill). Again not perfect wikitext, but that’s something to improve in the future. I bet it would be much better at outputting markdown, in-fact it already is kind of a mid way point between wikitext and markdown…
Thoughts
Having something like Edit Groups on all wiki installations could generally be great. I’m sure I could already get the agent to start always adding something identifiable to the edit summaries that link an edit to the batch of edits being done at a given point in time likely triggered by a single prompt. There is already T330387 for adding edit groups to wikibase.cloud and T203557 for turning it into an extension.
It seems that only the action API was used initially, and it would likely make sense the poke the agent towards both the REST APIs for MediaWiki and Wikibase. I am assuming that it primarily knows how to interact with a MediaWiki installation from training, however perhaps I should ask it and or look at some of its script iterations to see exactly what it is hitting.
It’s common on GitHub these days to have pull requests have a specific chip to denote if it was created by a bot or AI agent. The only separation that MediaWiki has for such things so far is in the name that users choose for an account. I expect it would be trivial enough to modify the user link formatting to add chips based on user rights or groups, which could be a nice addition to add a little more visual separation between real user actions and non humans.
It’s already possible to filter on MediaWiki recent changes by bot or not bot, however this only applies to the bot attribute that can be given to an edit. Perhaps the more useful thing in the future might be filtering on arbitrary user groups? Or perhaps just a second level of bot edit?
Hosting the prompt and skills on the wiki feels like the right thing to do, however this is actually slightly worry some, as the only reason I can protect the pages from other users is because I am an admin of the site. In reality for these situation it would be nice to have pages that can only be edited by the user itself, which is possible by CSS JS and JSON pages, but really I want to be using wikitext or markdown for this page.. Or to have more fine grained permissions possible for such pages, so I could allow myself and the agent to edit them.
And lastly, as with code repositories, I think watching agent interactions can really help to easily identify usability bugs and improvements, and connections that can very easily be missed that would benefit users. The key example above is how to actually use descriptions. Right now when editing any Wikibase, including Wikidata, there is no help at all for how to use descriptions, the only way you have a chance of getting it right is if you have been staring at Wikidata a lot in the past, or happen to have read the rather lengthy Wikidata descriptions help page, which is a pretty big ask out of the gate.
I’m sure this won’t be my last time using Addagent on wikibase.world, so watch this space…
🕑 1 hour 35 minutes
Ad Strack van Schijndel is the founder and CEO of Juggel, a Dutch company whose product, also named Juggel, is an AI-centered MediaWiki distribution. Before founding Juggel, he was the founder and CEO of the MediaWiki-based consulting company Wikibase Solutions.
Links for some of the topics discussed:
- Juggel
- Wikibase Solutions
- Juggel AI
- "MediaWiki for lazy people" - talk by Ad at MUDCon spring 2026
- NeoWikiMediaWiki extension
Written by Camille Françoise (WMFR) and Michele Failla (WMEU).
The article was originally published in the European University Institute Policy Report on Open Internet co-edited by Patryk Pawlak and Nils Berglund.
The evolution of economic models in a digital ecosystem
Before the development of the Internet, business models for digital ecosystems were mostly closed. Organisations or companies would develop a product or service to sell at a lower price than their competitors. The first digital encyclopaedias, such as Encarta, are an example. The past decades have brought a drastic change in the business model promoted by the US digital companies, whose strategy shifted from the service-for-a-price model to offering a service “for free”. They enacted two aggressive strategies to capture the market: (1) forcing competitors out of the market and, once a monopoly was established, demanding payment while preventing competitors from accessing the market and therefore sustaining lock-in mechanisms; (2) using user data as payment to facilitate the resale of this data to external parties.
Competition laws in Europe have struggled to keep pace with these practices and address the challenges they pose to legal frameworks, either through the exploitation of grey areas or through legislative gaps. The lack of effective tax mechanisms to address the competitive advantage of global tech companies operating in the European Union (EU) over EU-established companies further complicates matters. The European Commission has partially addressed these challenges with the adoption of the Digital Markets Act (DMA) and the Digital Services Act (DSA), and has been actively working on regulating large platforms, with the objectives to limit monopolies and enforce existing laws and to strike a balance between content moderation and fairer revenue streams.
However, in its ambition to establish a digital ecosystem that is fairer and more respectful of people’s ability to exercise their own self-determination online, the European legislators have focused on limiting the impacts of monopolistic enterprises, without proposing what a desirable future of digital platforms and commerce should look like to foster a thriving digital ecosystem in the EU. In other words, it did not address the compatibility of certain business models with European values enshrined in Article 2 of the Treaty on European Union (TEU). Policymakers seem to be forgetting that there are infrastructures such as the Wikimedia projects, of which Wikipedia is the most famous, that have a unique model; a model that supports desirable digital infrastructures: open source, transparent, community-driven, and privacy-focused. This peculiar model represents the most unique democratic collaboration system within a digital ecosystem. The unique visibility offered by Wikipedia allows policymakers to often legally carve out spaces for this model to continue. But what about other Digital Commons, such as OpenStreetMap, for instance? Wikimedia is part of the Digital Commons ecosystem, which aims at creating this desirable digital future and deserves more carefully designed policies.
Open Data, Open Content: Fuelling Big Tech or Open Democratic Societies?
Information enables empowerment. Wikimedia projects contribute to gathering knowledge to share it freely and openly. They enable citizens in their daily lives by providing access to neutral and verifiable information, supporting education, autonomy, empowerment, informed decision-making, democratic participation, accountability, innovation, economic development, social cohesion, and resilience for all people wherever they live. The model provides equal access to all, through the information provided within the open ecosystem: an academic in Argentina, a farmer in Belgium, a civil servant in Thailand, a CEO of a medium enterprise in Kenya, or a large tech company in the United States or in Europe.
The interstices of this model created a condition under which big tech companies can exploit existing laws to extract value from data and content. The protection of personal data under the GDPR is challenged by the black box syndrome: lack of transparency, lack of human rights enforcements and the extraction of value at unprecedented scale, against the intentions of the creators, occurs without sharing fair remuneration, increasing wealth inequities and social developments. These models challenge the concept of information being equally accessible and reusable by everyone, which aligns with the concept of equity.
This raises a question whether, in democratic societies, restricting access to information because of the inequitable and extractive use by a few companies is a justified response. Such restrictions would have a major impact on people, including the progress towards the United Nations Sustainable Development Goals (SDGs). However, maintaining the status quo is not a viable option either. Finding solutions that will allow for fair and equitable remuneration mechanisms, ensure the visibility of sources, including human contributions, and facilitate transparent, accountable infrastructural designs for the digital commons ecosystem are urgently needed.
Economic Case for Protecting Common Goods in a Predatory Digital Ecosystem
One main aspect of the difficulties that digital commons face is not only the question of the materiality and digitality of the infrastructures, but also the financial extraction of the value contained in data, which is turned into financial flows to the benefit of a few concentrated global powers. This process diminishes the power of other infrastructures and communities while tilting the balance of power in favour of a few big tech companies.
In the era of the attention economy and data extraction in exchange for access to monopolistic digital infrastructures, the Wikimedia Movement and Projects remain one of the last bastions promoting the values of the open internet and net neutrality. Monopolistic digital infrastructures prioritise short-term commercial gains by enclosing public spaces and failing to respect and promote the fundamental rights of individuals and communities.
Wikimedia Projects do not pursue profit and are oriented towards the public good: providing free knowledge and neutral, verifiable information to everyone. They do not sell information or collect or sell user data. They do not exploit attention-economy ecosystems, such as addictive designs, to keep people in the infrastructure. Algorithms are not used to give readers what reinforces their own beliefs and convictions based on profiling methods. Respect and promotion of people’s privacy serve to protect them and their ability to self-determination by fostering critical thinking. Equal access to information, the same facts, and multiple perspectives are the crucial enablers for forming opinions and meaningfully participating in democratic life.
Supporting communities and infrastructure, whether physical or digital, requires financial streams. This raises the question of how to fairly redistribute the value back to the people who created it. The goal is to continue developing a more equitable, fair, and inclusive society, while protecting the commons and digital public goods.
One solution adopted by the Wikimedia Foundation is the launch of a commercial service, Wikimedia Enterprise, to ensure that the value extracted by a few powerful big tech companies is at least partially returned to the people who created it: the Wikimedia Community. Such a solution, however, is not definitive given the unique features of Wikimedia projects and the undesirability of a one-size-fits-all approach. Other NGOs and Commons may have different business models, which may prevent them from effectively engaging in negotiations with big companies. Born a quarter of a century ago, Wikipedia serves as a reminder that the principles of net neutrality and an open internet are under attack by a few monopolistic enterprises, which replicate and reinforce inequalities at every level of society.
sharing your iNaturalist photos on Wikimedia platforms
If you've been logging observations on iNaturalist, you may already be contributing to one of the world's great citizen science projects. But your photos could be doing even more. With a few simple steps, the same images you've captured in the field can end up illustrating Wikipedia articles, enriching Wikidata, and reaching tens of millions of readers every month — permanently, at full resolution, and completely free.
Here's how it works, and why it's worth doing.
Contents
- 1 Two communities, one mission
- 2 Why Wikimedia Commons?
- 3 Getting your licence right
- 4 What makes a good Wikipedia image?
- 5 The tools that make it easy
- 6 Getting involved
Two communities, one mission

Participants in Wikiproject iNaturalist WDC19 workshop outside the Deutsches Technikmuseum, Berlin.
iNaturalist and the Wikimedia ecosystem — which includes Wikipedia, Wikimedia Commons, and Wikidata — have more in common than it might seem. Both are large-scale, collaborative, open infrastructures built and maintained by volunteer communities. Both are committed to freely sharing knowledge with the world.
The connection between them deepened in 2018, when a group of contributors who cared about both platforms met at Wikimania in Cape Town and formed WikiProject Biodiversity (see WikiProject Biodiversity in Wikidata). That community has since grown into a coordinated network of people who move content between the two platforms, build tools to make it easier, and run campaigns to expand biodiversity knowledge on the open web.
Why Wikimedia Commons?
iNaturalist is wonderful, but it's not designed for long-term image preservation. Wikimedia Commons is. Here's what makes it worth the extra step:
- Full resolution preserved — iNaturalist and other platforms compress images. Commons keeps your original file at full quality.
- No upload limit — You can contribute as many freely licensed images as you like.
- Permanent — Images within scope stay there indefinitely, unlike commercial platforms, which can delete older images when accounts lapse.
- Reach — Your image can end up illustrating a Wikipedia article in dozens of languages, accessed by students, researchers, journalists, and curious people worldwide. You can check this out through GLAMorgan.
- Impact tracking — Thanks to Wikimedia's open Commons Impact Metrics API, you can see exactly how many times your images have been viewed and reused.
Getting your licence right

One of only three images of Pilotus Stirlingi Stirlingi on Wikimedia Commons.
Before anything else, there's one thing you need to check: your image licence on iNaturalist.
Currently, the vast majority of iNaturalist observers — over 99.5% — use a default licence that isn't compatible with Wikimedia projects. The Wikimedia Foundation requires all hosted content to be freely shareable, including for commercial use. That rules outCC-BY-NC (No Commercial) and CC-BY-ND (No Derivatives) licences.
The licences that work for Wikimedia are:
- CC0 — public domain; no restrictions on reuse whatsoever
- CC-BY — reuse permitted, as long as you're credited as the photographer
- CC-BY-SA — reuse permitted with credit, and any derivative works must carry the same licence
You can change your default licence for all future observations on iNaturalist, and also apply a new licence to all your existing observations in one go. Individual images can also be relicensed separately if you prefer more control. (Note: the observation licence and the image licence are separate things — only the image licence governs how your photos can be reused.)
For a surprising number of species, an iNaturalist photo isn't just the best freely available image — it's the only one!
What makes a good Wikipedia image?

Using the iNaturalist app in the field.
Not every iNaturalist photo is a candidate for Wikipedia, but many are. The focus is especially on species that currently lack a suitable image on Wikipedia — and these tend to be less commonly observed organisms: invertebrates, plants, fungi, and species found in Africa, Asia, South America, and other regions underrepresented in the existing photo library.
For a surprising number of species, an iNaturalist photo isn't just the best freely available image — it's the only one. iNaturalist, with its millions of observations logged by people who genuinely care about finding and documenting every living thing, is uniquely positioned to fill that gap. When you upload a freely licensed photo of an inconspicuous species, you may well be providing the first image that will ever appear on that organism's Wikipedia article.
In rough order of priority, the best images come fromResearch Grade observations and feature:
- A sharply focused, complete organism (adult where possible)
- Natural setting, without hands, rulers, pins, or containers in frame
- Good contrast with the background
- A single organism, oriented clearly
- A live specimen
- A large file size, especially useful when cropping will be needed
If your photo ticks most of those boxes and captures a species that's currently missing a Wikipedia image, it's genuinely valuable.

The upload to Wikimedia Commons from iNaturalist button makes it easy!
The tools that make it easy
The volunteer community behind WikiProject Biodiversity has built a set of open-source tools to make uploading from iNaturalist to Wikimedia Commons as painless as possible.
iNaturalist2Commons is a userscript that runs directly on Wikimedia Commons, letting you search for iNaturalist images without leaving the site. It has facilitated around 164,000 uploads to date.
Wiki Loves iNaturalist is a standalone web app that identifies English Wikipedia articles and Wikidata entries that could benefit from an iNaturalist image, and lets you upload directly from there. It has helped transfer around 14,600 images so far.
You can also use Wikimedia Commons' own Special:Upload feature, which whitelists iNaturalist's image host and lets you import directly via URL.
Getting involved
If you'd like to contribute, the path is straightforward:
- Update your licence on iNaturalist to CC0, CC-BY, or CC-BY-SA
- Choose your tool the iNaturalist2Commons is the quickest starting point for most people
- Upload images that meet the quality criteria, focusing on species that lack Wikipedia coverage
- Join WikiProject Biodiversity to connect with others doing this work
The community is welcoming, the tools are free and open source, and every image you contribute expands the body of freely accessible biodiversity knowledge on the internet — permanently.
Your observations are already valuable. With a licence change and a few clicks, they can reach the world.
Images
- Using the iNaturalist app in the field by Srloarie2, CC BY-SA 4.0, via Wikimedia Commons
- Wikiproject iNaturalist WDC19 MRD by Mike Dickison, CC BY-SA 4.0 via Wikimedia Commons
- Ptilotus stirlingii stirlingii by Cal Wood, CC BY 4.0 , via Wikimedia Commons
- Picasso Bug by Alan Manson, some rights reserved (CC BY), CC BY 4.0 via Wikimedia Commons
{kind=link}
{kind=link}
{kind=link}
{kind=link}
23/04/2026-29/04/2026
Mapping
- Comments are requested on this proposal:
terminal=yesto consistently mapgoods terminals and better describe connected transport modes and handled cargo.
- The following proposal is up for a vote:
highway=service+service=safaritomap dedicated service roads in safari parks.
- In an interview on the OpenCage Blog, Christian Quest outlined plans for the Panoramax Foundation to coordinate an open federated street-level imagery platform. The initiative aims to foster international collaboration and draws inspiration from the OpenStreetMap Foundation.
- Christian Quest has reminded us that the Panoramax instance run by OSM France accepts images from outside France for testing purposes only. However, almost half of all images are from foreign countries. He warned that the board of OSM France will decide soon whether to delete those pictures, because disk space is running out. According to recent figures, the Panoramax federation has grownto 10 instances, which now hosts over 100 million openly licensed street-level images contributed by more than 2,000 users. This wascelebrated by Bastian Greshake Tzovaras on Mastodon.
- 9_tab wrote about Quartiers de Genève in their OSM User Diary. A mapping sprint around Genevahas organised the
place=*nodes and local data for neighbourhoods and quarters has been compared with those mapped.
OpenStreetMap Foundation
- The OpenStreetMap Foundation has published its 2026 budget, approved in January, projecting around GBP 822,000 in income and about GBP 933,000 in expenditure. It includes funding for staff, contractors, microgrants, and infrastructure. It may be revised during the year.
- The OSMF has documented the short presentations given during public board meetings and is considering reviving these community talks in 2026. The ten-minute slots provide insights into projects and initiatives from the OSM community.
Events
Education
OSM research
- HeiGIT presented a study on automated road crack localisation for highway maintenance, using network data extracted from OpenStreetMap to enable spatially guided analysis and improve infrastructure monitoring. The study was published in_Transactions in GIS30_ and was authored by Knoblauch, Muthusamy, Ghamis, and Zipf.
Maps
OSM in action
- [1] Zoe Skyforest reported on Hackaday about a new national pastime in Australia: the sport of Payphone Tag. Developed by Alex Allchin, it is a capture-the-flag game in which players dial a number using local public phones to capture the area surrounding them. A real-time map of territories held by players is displayed via an OpenStreetMap-based web map. There have been 800 players in the last seven days and a total of 36,640 captures so far.
- Leonardo Texidó Quintana has developed a ride-hailing application for Cuba by leveraging OpenStreetMap data and forking Organic Maps for both passenger and driver apps. This app has facilitated more than 20,000 real taxi trips during a fuel crisis, operating on low-end smartphones with 2GB of RAM and intermittent 2G connectivity.
Open Data
- GOWIRES is a new open dataset combininglocation data from over 400,000 wind turbines worldwide (across 89 countries) with historical and future wind resource data. The geographic data is largely based on OpenStreetMap and has been validated against national registries.
- OCHA Centre for Humanitarian Data has published a global dataset of sub-national administrative boundaries for 110 countries.
Software
- In response to recent issues with the public Overpass servers, Kai Johnson has published a new Docker containerimage for Overpass, allowing people to run their own Overpass instances.
- HeiGIT has announced that their URL api.openrouteservice.org is being deprecated in favour of api.heigit.org. While the services remain unchanged, users need to update their applications before the shutdown in August 2026.
- geoObserver has showcased ► DrawonMaps. This is a web app that detects the edges of an uploaded image, then traces and fills the image using the OpenStreetMap street network.
- GéoDataMine has made it easy to extract ►thematic data from OpenStreetMap in the form of spreadsheets or geographic files. The data is updated daily and made available in CSV, GeoJSON, XSLX, and Shapefile formats. It is made compatible with national data schemas where they exist; otherwise, it follows OpenStreetMap conventions.
- Ilya Zverev has noted that aticketregarding the support of multiple accounts in JOSM, which had been open for 15 years, has been closed with the status ‘won’t fix’. Consequently, there will continue to be no native support for multiple user accounts in JOSM. Some users are getting around this limitation with personal scripts, such as reportedby M!dgard for *NIX systems. An alternative method that also works for Windows is available .
- The members of the osm2pgsql project announced that they recently won a grant from the NGI0 Commons Fund to work on the Compact OpenStreetMap Data Archive project (tentative name), aimed at reducing the memory and disk usage of osm2pgsql by implementing more efficient storage formats.
- The OpenGridWorks project, led ►by Alejandro Polanco, shows energy infrastructure and uses CARTO and OpenStreetMap for its reference geospatial layers. The available layers include power stations, transmission lines, substations, gas pipelines, data centres, planned transmission projects, submarine cable routes, and flood risk.
Programming
- Candid Dauth has introduceda new fork of openstreetmap-tile-server, which separates database and rendering, while supporting modern osm2pgsql features. This approach aims to enable more flexible and efficient tile hosting with incremental updates.
- Evgeny Arbatov has developed‘vibe mapping’, a pipeline that analyses the overall vibe of a place using OpenStreetMap data. From the OSM data extract it divides an area into H3 hexagons, then calculates aggregate metrics for each hexagon. Based on these metrics, it asks an AI model to generate a short, one-sentence description of the place’s vibe. The code is available on GitHub.
- NieWnen has publisheda script that filters OSM replication files using .poly boundaries, to keep regional databases updated with osm2pgsql. This approach offers an alternative to Overpass and enables more flexible self-hosted data processing. The code is availableon GitHub.
- Mark Litwintschik presenteda reverse geocoding prototype based on Overture Maps that retrieves country codes and nearest addresses without external APIs. The underlying datasets also include OpenStreetMap data and are processed locally.
Releases
- Nils Nolde has releasedValhalla 3.7.0, introducing features such as multimodal routing, OSM XML support, and additional metadata. This release also included numerous bug fixes and changes to routing and data processing components.
- Route-Crafter version 0.2.4 has improvedthe handling of very long routes, fixed mobile UI issues, and added warnings when settings change. It also updated features for setting the start location button and improved the route player traversed line visualisation.
- Marcus Jaschen has published a new route manager for Bikerouter, allowing users to store and organise routes either in the browser or on servers.
Did you know that …
- … Bikemap.net allows users to plan cycling routes worldwide usingOpenStreetMap data for routing and maps?
- … Skaringa has developed a map of river basins in Central Europe using OpenStreetMap waterway network data?
Other “geo” things
- Crust News has noticed that Apple Maps no longer displays the names of various towns and villages across Lebanon. The removal is not limited to the area of the country facing Israeli invasion and attacks, it applies nationwide. Only a handful of larger cities remain labeled: Beirut, Tyre, Sidon, and a small number of others.
- The city of Porto will host ►the 17th Iberian Conference on Spatial Data Infrastructures, which will take place from 11 to 13 November 2026. For the theme of spatial data infrastructure in a changing world, the event has issued an open call ►for the submission of papers until Wednesday 10 June.
- The Bathymetric Data Viewer is an interactive map providing a search and discovery service for the bathymetry data and digital elevation models archived at NOAA’s National Centers for Environmental Information. A geoviewer with layers from the IHO Data Centre for Digital Bathymetry is also available.
- According to the proposed ► Emergency Care Reform Act, the German Federal Ministry of Health plans to create a public registry of automated external defibrillators.
- After it had been an EU requirement for two years, Jesper Zedlitz reviewed ►the status of high value datasets in Germany and revealed major differences between federal states. The differences point to gaps, inconsistent implementation, and open questions around categorisation.
- A recent article by Gabrielle Bruney, published in Places Journal, explored the role and decline of public benches in cities, highlighting their social and spatial importance. This article is the latest in a series, Writing the City, a collaboration between Places Journal and the Arts and Culture Program at Columbia Journalism School. For OpenStreetMap this underlines the relevance of detailed mappingof features such as
amenity=bench. There is an ongoingproposal (since 2021) for hostile benches as a form of hostile architecture.
Upcoming Events
| Country | Where | Venue | What | When |
|---|---|---|---|---|
 |
Sydney | Level 6, 150 George Street, Parramatta | Social Mapping Event in Parramatta |
2026-04-30 |
|
Essen | Linuxhotel Essen | FOSSGIS-OSM-Communitytreffen im Linuxhotel |
2026-04-30 – 2026-05-03 |
 |
大理市 | 三月街集市 | 大理三月民族节 |
2026-05-01 – 2026-05-07 |
|
Weil der Stadt | MA1PPING |
2026-05-01 | |
|
Augsburg | Augsburger Linux-Infotag 2026 | Workshop: JOSM – Java OpenStreetMap Editor – Eine Einführung |
2026-05-02 |
|
नई दिल्ली | Jitsi Meet (online) | OSM India – Monthly Online Mapathon |
2026-05-02 |
|
Sovigliana-Vinci | Mappando si Vinci! – 2 Maggio 2026 |
2026-05-02 – 2026-06-02 | |
|
Braunschweig | Stratum 0 | Braunschweiger Mappertreffen im Stratum 0 Hackerspace |
2026-05-05 |
 |
Salzburg | Bewohnerservice Elisabeth-Vorstadt | OSM-Treffpunkt |
2026-05-05 |
| Missing Maps London Mapathon (with Training) Beginner Friendly (Online) [eng] |
2026-05-05 | |||
| iD Community Chat |
2026-05-06 | |||
|
Stuttgart | Stuttgart | Stuttgarter OpenStreetMap-Treffen |
2026-05-06 |
|
Richmond | Shockoe Bottom | Surveillance mapping with MapRVA |
2026-05-07 |
|
[online] | Capacitação OSM 2026 – IVIDES DATA ® – Editor iD – Parte I |
2026-05-08 | |
|
online | SOSM Association Annual Meeting |
2026-05-08 | |
|
København | Cafe Bevar’s | OSMmapperCPH |
2026-05-10 |
|
Delhi | Kori’s, Humayunpur, Delhi | OSM Delhi Mapping Party No.29 (South Zone) |
2026-05-10 |
| Missing Maps : Mapathon en ligne – CartONG [fr] |
2026-05-11 | |||
|
Zürich | Bitwäscherei Zürich | 187. OSM-Stammtisch Zürich |
2026-05-11 |
|
臺北市 | MozSpace Taipei | OpenStreetMap x Wikidata Taipei #88 |
2026-05-11 |
|
Magdeburg | Netz39 e.V. , Leibnizstraße 32, 39104 Magdeburg | 1. OSM Stammtisch Magdeburg |
2026-05-12 |
|
Hamburg | Voraussichtlich: “Variable”, Karolinenstraße 23 | Hamburger Mappertreffen |
2026-05-12 |
|
temporärhaus | OSM-Stammtisch Ulm/Neu-Ulm |
2026-05-12 | |
|
Maison des associations de Bayonne – salle Valmont | Rencontre Mapadour |
2026-05-13 | |
|
Praha | Seznam.cz | Pražský mapathon s Lékaři bez hranic v Seznam.cz |
2026-05-13 |
|
Amsterdam | TomTom HQ | 2026 Spring End Maptime |
2026-05-13 |
|
München | Echardinger Einkehr | Münchner OSM-Treffen |
2026-05-13 |
| Mapaton – Marsh |
2026-05-14 | |||
|
Žilina | Fakulta riadenia a informatiky UNIZA | Missing Maps mapathon Žilina #22 |
2026-05-14 |
|
Acireale | Mappiamo le Aci |
2026-05-16 – 2026-05-17 | |
|
Chennai Corporation | Hotel Nithya Amirtham, Mylapore Market, Chennai | Mapping at Mylapore Market, Chennai |
2026-05-17 |
|
Bologna | aula 0.6, DICAM, Unibo, Viale del Risorgimento 2 | Unibo Mapathon OpenStreetMap 2026-05 |
2026-05-18 |
|
Mannheim | RaumZeitLabor, Mannheim | Rhein-Neckar OpenstreetMap Treffen |
2026-05-18 |
Note:
If you like to see your event here, please put it into the OSM calendar. Only data which is there, will appear in weeklyOSM.
This weeklyOSM was produced by Bastian Greshake Tzovaras, MarcoR, Nakaner, Raquel IVIDES DATA, Raquel IVIDES DATA, SeverinGeo,Strubbl, Andrew Davidson, barefootstache,derFred,izen57, mcliquid. We welcome link suggestions for the next issue via thisform and look forward to your contributions.
Jennifer Bernstein, PhD Editor-in-Chief, Case Studies in the Environment Faculty, Texas Tech University
In an eight-week, online introductory environmental science course, I assigned the Wikipedia assignment in lieu of a traditional research paper. Students selected an article from a list of geoscience terms and improved it through editing and contributing text, references, and media. My learning objectives were similar to those associated with a traditional research paper: evaluating source quality, synthesizing information, writing clearly, and supporting claims with evidence. The Wikipedia assignment met these goals while also placing student work in front of a public audience.
As an instructor, I also grapple with student use of LLMs. Rather than rely on detection tools or restrictive policies, I aim to design assignments that are difficult to complete successfully using LLMs. The Wikipedia assignment does this effectively. Students also recognize that Wikipedia serves as an input for LLMs, demonstrating how information is produced and circulated.

Jennifer Bernstein. Image courtesy Jennifer Bernstein, all rights reserved.
To assess how the assignment functioned, I conducted an informal content analysis of students’ end-of-semester reflections and compared them with their final article contributions.
The most notable outcome was a change in how students understood their role in working with information. Instead of summarizing existing material, students were asked to revise, clarify, and make it usable for others. The experience was characterized less by content mastery and more by a move from receiving information to contributing to it.
Some students engaged fully with this shift and meaningfully edited their articles. These students were often more comfortable with online learning environments or more invested in the course material. For them, the assignment offered benefits beyond a traditional research paper, particularly in developing a clearer understanding of how information is constructed and disseminated.
At the same time, many students experienced the assignment as uncomfortable. Reflections expressed uncertainty about expertise and legitimacy, with students questioning whether they were qualified editors. In response, some focused on lower-risk contributions, working around the edges of their articles rather than making substantive revisions. A small number expressed strong dislike for the assignment in course evaluations.
From a pedagogical perspective, this discomfort is not surprising. Historically, students have been asked to take in information, internalize it, and demonstrate their understanding through correct answers. Over time, this reinforces the idea that knowledge is fixed and that their role is to receive it. Asking students to contribute introduces a different expectation, as it requires them to take responsibility for how information is presented and supported. This shift can feel unfamiliar, particularly in introductory or general education settings. At the same time, research on “desirable difficulties” suggests that this kind of challenge can support deeper and more durable learning (Bjork & Bjork, 2011; Bransford et al., 2000).
Other factors mediate how and to what degree this discomfort is experienced. Despite robust support, some students struggle with the technical demands of the platform. Others find the premise confusing, especially as many have been taught to avoid Wikipedia as a source. There is also something more fundamentally destabilizing at work. When students participate in producing and revising information, they must reconsider how it is created and trusted, and that the knowledge they encounter is the product of human construction and interpretation.
This discomfort does not lead to a single outcome. Some students step into it, engaging more deeply with the assignment and its expectations. Others hesitate or pull back, focusing on lower-risk contributions or struggling to engage. These responses are shaped by who students are and what they bring to the course. Students with prior positive experiences in online learning, stronger interest in the subject, or a sense of connection to the course community were more likely to persist through the initial uncertainty. For these students, the discomfort became productive. For others, particularly when combined with technical challenges, time constraints, or different expectations for what a course should provide, the same assignment felt confusing or misaligned. The impact of the assignment depends on how it intersects with student preparation, expectations, and course context.
Part of what makes this assignment feel different is also tied to how generative AI is reshaping the classroom and the broader information environment. Many responses to LLM use focus on restriction or monitoring. These approaches address immediate concerns but do not resolve the underlying challenge of designing learning environments that require active engagement with information. The Wikipedia assignment asks students to evaluate sources using shared standards, write for a public audience, and work within an existing body of knowledge. This is not simply a workaround for AI use. It reflects a shift toward forms of learning that prioritize evaluating information, making judgments, and working with knowledge in ways that are increasingly necessary in an AI-shaped information environment.
At the same time, this shift has pedagogical consequences. Non-traditional assignments often look and feel unfamiliar to students. They can create opportunities for deeper engagement, but they can also expose mismatches between course design and student expectations. In accelerated courses or with diverse student populations, these mismatches can be more pronounced, making careful scaffolding especially important when introducing assignments like the Wikipedia project.
For instructors considering the Wikipedia assignment, its value lies in how it asks students to engage with information as something they must work with, not simply receive. Students evaluate sources, write for a public audience, and contribute to knowledge that others will encounter. In courses with varied student backgrounds or limited time, careful scaffolding is essential to ensure that all students can engage with this work.
Even when it is uncomfortable, this kind of learning helps prepare students to evaluate information critically and make informed judgments in a landscape where those skills are increasingly necessary.
References
Bjork, R. A., & Bjork, E. L. (2011). Making things hard on yourself, but in a good way: Creating desirable difficulties to enhance learning. In M. A. Gernsbacher, R. W. Pew, L. M. Hough, & J. R. Pomerantz (Eds.), Psychology and the real world: Essays illustrating fundamental contributions to society (pp. 56–64). Worth Publishers.
Bransford, J. D., Brown, A. L., & Cocking, R. R. (Eds.). (2000). How people learn: Brain, mind, experience, and school (Expanded ed.). National Academy Press.
Wiki Education’s support for STEM courses like Jennifer Bernstein’s is available thanks to the Guru Krupa Foundation.
Interested in incorporating a Wikipedia assignment into your course? Visit teach.wikiedu.org to learn more about the free resources, digital tools, and staff support that Wiki Education offers to postsecondary instructors in the United States and Canada.