xFormers optimized operators | xFormers 0.0.31 documentation (original) (raw)
Memory-efficient attention¶
class xformers.ops.AttentionOpBase[source]¶
Bases: BaseOperator
Base class for any attention operator in xFormers
See:
- xformers.ops.fmha.cutlass.FwOp
- xformers.ops.fmha.cutlass.BwOp
- xformers.ops.fmha.flash.FwOp
- xformers.ops.fmha.flash.BwOp
xformers.ops.fmha.triton.FwOpxformers.ops.fmha.triton.BwOp
classmethod not_supported_reasons(d: Inputs) → List[str][source]¶
Returns a list of reasons why this is not supported. The kernel can run these inputs only if the returned list is empty
xformers.ops.memory_efficient_attention(query: Tensor, key: Tensor, value: Tensor, attn_bias: Optional[Union[Tensor, AttentionBias]] = None, p: float = 0.0, scale: Optional[float] = None, *, op: Optional[Tuple[Optional[Type[AttentionFwOpBase]], Optional[Type[AttentionBwOpBase]]]] = None, output_dtype: Optional[dtype] = None) → Tensor[source]¶
Implements the memory-efficient attention mechanism following“Self-Attention Does Not Need O(n^2) Memory”.
Inputs shape
- Input tensors must be in format
[B, M, H, K], where B is the batch size, M the sequence length, H the number of heads, and K the embeding size per head - If inputs have dimension 3, it is assumed that the dimensions are
[B, M, K]andH=1 - Inputs can also be of dimension 5 with GQA - see note below
- Inputs can be non-contiguous - we only require the last dimension’s stride to be 1
Equivalent pytorch code
scale = 1.0 / query.shape[-1] ** 0.5 query = query * scale query = query.transpose(1, 2) key = key.transpose(1, 2) value = value.transpose(1, 2) attn = query @ key.transpose(-2, -1) if attn_bias is not None: attn = attn + attn_bias attn = attn.softmax(-1) attn = F.dropout(attn, p) attn = attn @ value return attn.transpose(1, 2).contiguous()
Examples
import xformers.ops as xops
Compute regular attention
y = xops.memory_efficient_attention(q, k, v)
With a dropout of 0.2
y = xops.memory_efficient_attention(q, k, v, p=0.2)
Causal attention
y = xops.memory_efficient_attention( q, k, v, attn_bias=xops.LowerTriangularMask() )
Supported hardware
NVIDIA GPUs with compute capability above 6.0 (P100+), datatype f16, bf16 and f32.
EXPERIMENTAL
Using with Multi Query Attention (MQA) and Grouped Query Attention (GQA):
MQA/GQA is an experimental feature supported only for the forward pass. If you have 16 heads in query, and 2 in key/value, you can provide 5-dim tensors in the [B, M, G, H, K] format, where G is the number of head groups (here 2), andH is the number of heads per group (8 in the example).
Please note that xFormers will not automatically broadcast the inputs, so you will need to broadcast it manually before calling memory_efficient_attention.
GQA/MQA example
import torch import xformers.ops as xops
B, M, K = 3, 32, 128 kwargs = dict(device="cuda", dtype=torch.float16) q = torch.randn([B, M, 8, K], **kwargs) k = torch.randn([B, M, 2, K], **kwargs) v = torch.randn([B, M, 2, K], **kwargs) out_gqa = xops.memory_efficient_attention( q.reshape([B, M, 2, 4, K]), k.reshape([B, M, 2, 1, K]).expand([B, M, 2, 4, K]), v.reshape([B, M, 2, 1, K]).expand([B, M, 2, 4, K]), )
Raises
- NotImplementedError – if there is no operator available to compute the MHA
- ValueError – if inputs are invalid
Parameters
- query – Tensor of shape
[B, Mq, H, K] - key – Tensor of shape
[B, Mkv, H, K] - value – Tensor of shape
[B, Mkv, H, Kv] - attn_bias – Bias to apply to the attention matrix - defaults to no masking. For common biases implemented efficiently in xFormers, see xformers.ops.fmha.attn_bias.AttentionBias. This can also be a
torch.Tensorfor an arbitrary mask (slower). - p – Dropout probability. Disabled if set to
0.0 - scale – Scaling factor for
Q @ K.transpose(). If set toNone, the default scale (q.shape[-1]**-0.5) will be used. - op – The operators to use - see xformers.ops.AttentionOpBase. If set to
None(recommended), xFormers will dispatch to the best available operator, depending on the inputs and options.
Returns
multi-head attention Tensor with shape [B, Mq, H, Kv]
Available implementations¶
class xformers.ops.fmha.cutlass.FwOp[source]¶
xFormers’ MHA kernel based on CUTLASS. Supports a large number of settings (including without TensorCores, f32 …) and GPUs as old as P100 (Sm60)
class xformers.ops.fmha.cutlass.BwOp[source]¶
xFormers’ MHA kernel based on CUTLASS. Supports a large number of settings (including without TensorCores, f32 …) and GPUs as old as P100 (Sm60)
class xformers.ops.fmha.flash.FwOp[source]¶
Operator that computes memory-efficient attention using Flash-Attention implementation.
class xformers.ops.fmha.flash.BwOp[source]¶
Operator that computes memory-efficient attention using Flash-Attention implementation.
class xformers.ops.fmha.ck.FwOp[source]¶
xFormers’ MHA kernel based on Composable Kernel.
class xformers.ops.fmha.ck.BwOp[source]¶
xFormers’ MHA kernel based on Composable Kernel.
class xformers.ops.fmha.ck_decoder.FwOp[source]¶
An operator optimized for K=256 (so the contiguous dim fits into registers). Tested to work on MI250x.
Attention biases¶
This file contains biases that can be used as the attn_bias argument inxformers.ops.memory_efficient_attention. Essentially, a bias is a Tensor which will be added to the Q @ K.t before computing the softmax.
The goal of having custom made classes (instead of dense tensors) is that we want to avoid having to load the biases from memory in the kernel, for performance reasons. We also want to be able to know before-hand which parts of the attention matrix we will need to compute (eg causal masks).
Some very common biases are LowerTriangularMask and BlockDiagonalMask.
class xformers.ops.fmha.attn_bias.AttentionBias[source]¶
Bases: object
Base class for a custom bias that can be applied as the attn_bias argument inxformers.ops.memory_efficient_attention.
That function has the ability to add a tensor, the attention bias, to the QK^T matrix before it is used in the softmax part of the attention calculation. The attention bias tensor with shape (B or 1, n_queries, number of keys) can be given as the attn_bias input. The most common use case is for an attention bias is to contain only zeros and negative infinities, which forms a mask so that some queries only attend to some keys.
Children of this class define alternative things which can be used as the attn_bias input to define an attention bias which forms such a mask, for some common cases.
When using an xformers.ops.AttentionBiasinstead of a torch.Tensor, the mask matrix does not need to be materialized, and can be hardcoded into some kernels for better performance.
See:
- xformers.ops.fmha.attn_bias.LowerTriangularMask
- xformers.ops.fmha.attn_bias.LowerTriangularFromBottomRightMask
- xformers.ops.fmha.attn_bias.LowerTriangularMaskWithTensorBias
- xformers.ops.fmha.attn_bias.BlockDiagonalMask
- xformers.ops.fmha.attn_bias.BlockDiagonalCausalMask
materialize(shape: Tuple[int, ...], dtype: dtype = torch.float32, device: Union[str, device] = 'cpu') → Tensor[source]¶
Materializes the bias as a torch.Tensor. This is very slow and we don’t attempt to make it fast. Only use for debugging/testing.
Shape should be like [*, q_seqlen, k_seqlen]
class xformers.ops.fmha.attn_bias.LocalAttentionFromBottomRightMask(window_left: int, window_right: int)[source]¶
Bases: AttentionBias
A local attention mask
The query at position \(q\) can attend the key at position \(k\) if\(q - window\_left <= k + s <= q + window\_right\)
With \(s = num\_queries - num\_keys\)
Example
import torch from xformers.ops import fmha
bias = fmha.attn_bias.LocalAttentionFromBottomRightMask(window_left=1, window_right=2) print(bias.materialize(shape=(4, 4)).exp()) print(bias.materialize(shape=(4, 5)).exp())
4x4
tensor([[1., 1., 1., 0.], [1., 1., 1., 1.], [0., 1., 1., 1.], [0., 0., 1., 1.]])
4x5
tensor([[1., 1., 1., 1., 0.], [0., 1., 1., 1., 1.], [0., 0., 1., 1., 1.], [0., 0., 0., 1., 1.]])
Illustration

The total window size is \(window\_left + 1 + window\_right\)¶
class xformers.ops.fmha.attn_bias.LowerTriangularFromBottomRightMask[source]¶
Bases: AttentionBias
A causal masking.
This mask is exactly the same as LowerTriangularMask when there is the same number of queries and keys. When the number of queries is different from the number of keys, it is a triangular mask shifted so that the last query can attend to the last key. In other words, a query Q cannot attend to a key which is nearer the final key than Q is to the final query.
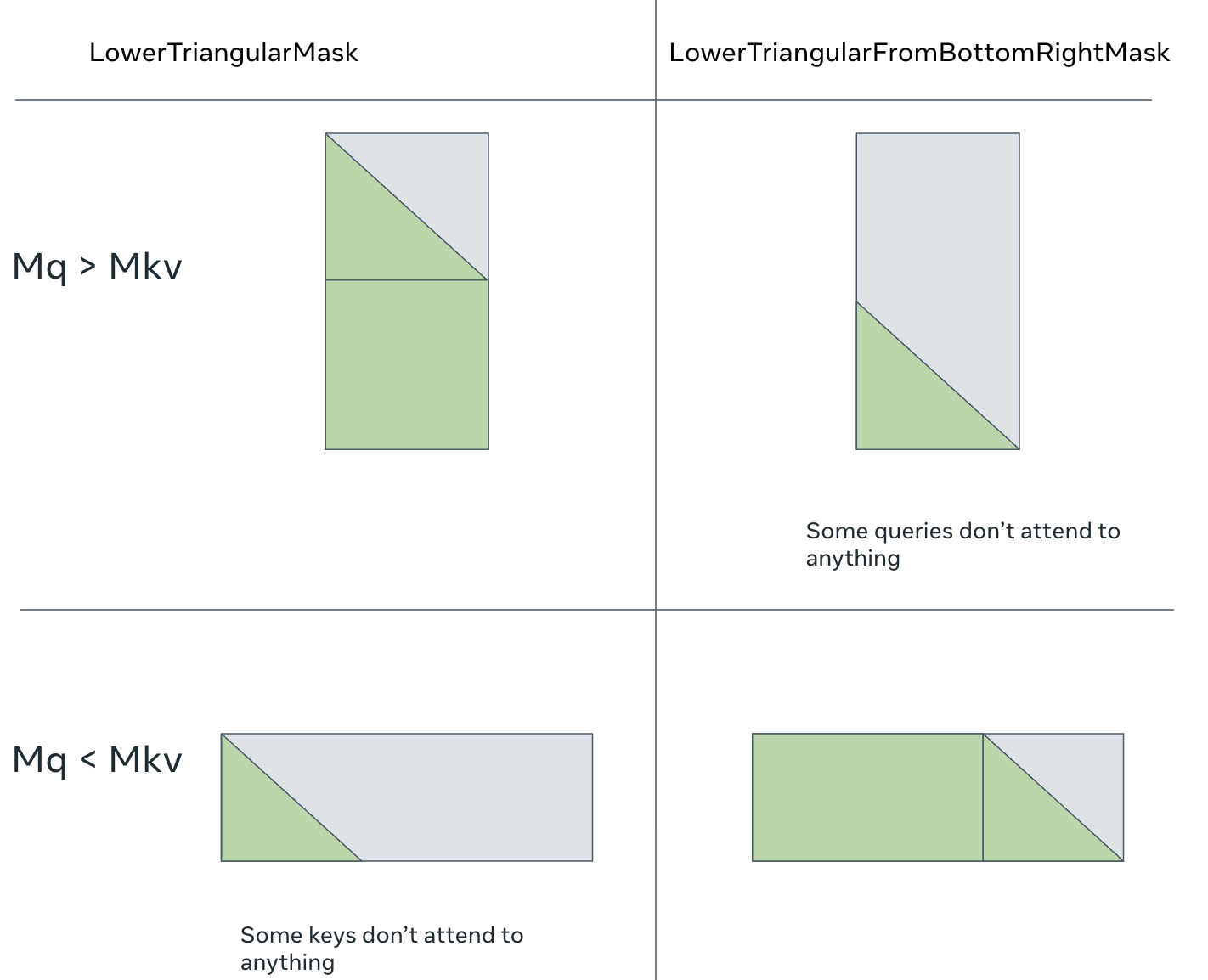
The difference between LowerTriangularMask (left) andLowerTriangularFromBottomRightMask (right). They become equivalent if the number of queries equals the number of keys.¶
make_local_attention(window_size: int) → LowerTriangularFromBottomRightLocalAttentionMask[source]¶
Create a new bias which combines local + causal attention.
See LowerTriangularFromBottomRightLocalAttentionMask
class xformers.ops.fmha.attn_bias.LowerTriangularFromBottomRightLocalAttentionMask(_window_size: int)[source]¶
Bases: LowerTriangularFromBottomRightMask
A mask that combines both LowerTriangularFromBottomRightMask and local attention.
A query whose distance from the final query is X cannot attend to a key whose distance to the final key is either of:
- less than X (i.e. “causal attention”, same as LowerTriangularFromBottomRightMask)
- greater than or equal to X + window_size (i.e. “local attention”)
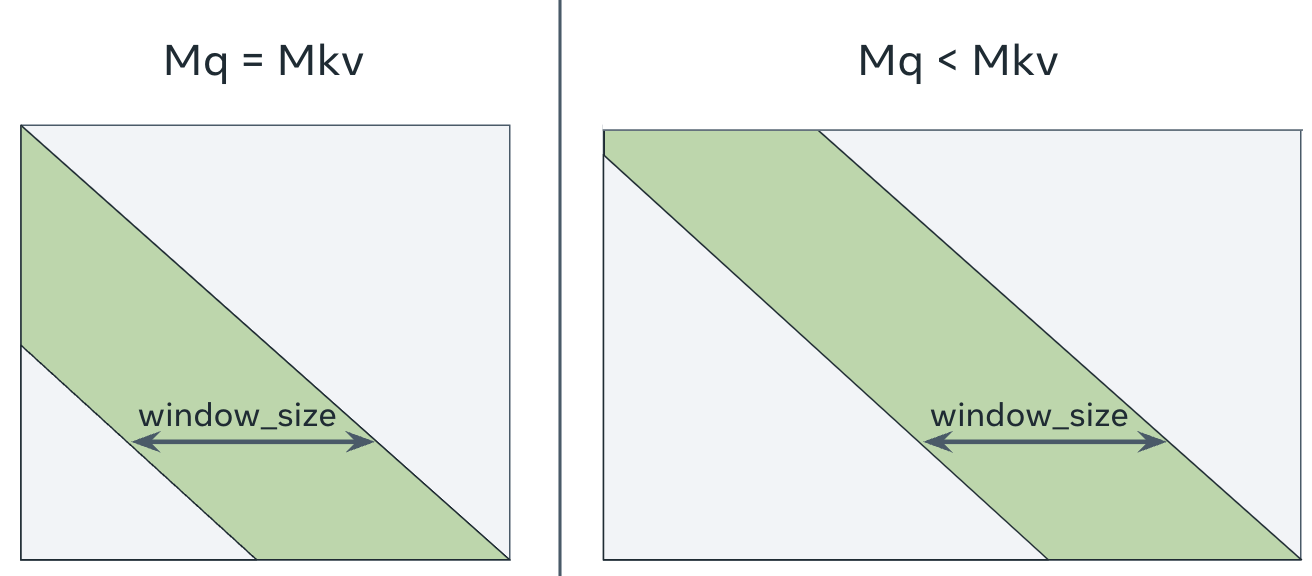
The mask from LowerTriangularFromBottomRightLocalAttentionMask. The green area is calculated, and the grey area is masked out.¶
class xformers.ops.fmha.attn_bias.BlockDiagonalMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _SeqLenInfo, _batch_sizes: Optional[Sequence[int]] = None)[source]¶
Bases: AttentionBias
A block-diagonal mask that can be passed as attn_biasargument to xformers.ops.memory_efficient_attention.
Queries and Keys are each divided into the same number of blocks. Queries in block i only attend to keys in block i.
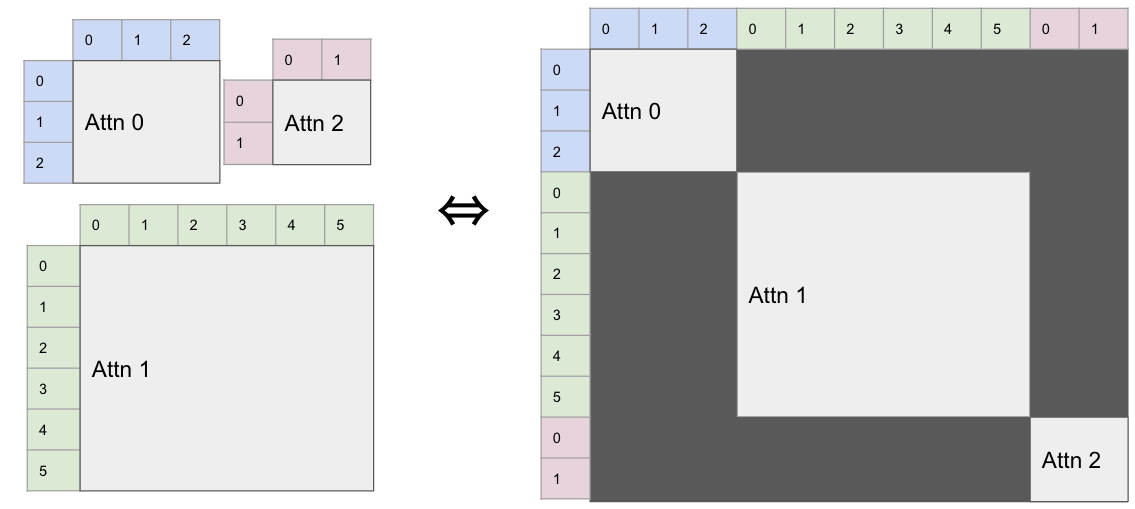
This bias can be used to handle a batch of sequences of different lengths, via BlockDiagonalMask.from_tensor_list¶
Example
import torch from xformers.ops import fmha
K = 16 dtype = torch.float16 device = "cuda" list_x = [ torch.randn([1, 3, 1, K], dtype=dtype, device=device), torch.randn([1, 6, 1, K], dtype=dtype, device=device), torch.randn([1, 2, 1, K], dtype=dtype, device=device), ] attn_bias, x = fmha.BlockDiagonalMask.from_tensor_list(list_x) linear = torch.nn.Linear(K, K * 3).to(device=device, dtype=dtype)
q, k, v = linear(x).reshape([1, -1, 1, 3, K]).unbind(-2) out = fmha.memory_efficient_attention(q, k, v, attn_bias=attn_bias) list_out = attn_bias.split(out) print(list_out[0].shape) # [1, 3, 1, K] assert tuple(list_out[0].shape) == (1, 3, 1, K)
materialize(shape: Tuple[int, ...], dtype: dtype = torch.float32, device: Union[str, device] = 'cpu') → Tensor[source]¶
Materialize the attention bias - for debugging & testing
classmethod from_seqlens(q_seqlen: Sequence[int], kv_seqlen: Optional[Sequence[int]] = None, *, device: Optional[device] = None) → BlockDiagonalMask[source]¶
Creates a BlockDiagonalMask from a list of tensors lengths for query and key/value.
Parameters
- q_seqlen (Union _[_ _Sequence_ _[_int] , torch.Tensor ]) – List or tensor of sequence lengths for query tensors
- kv_seqlen (Union _[_ _Sequence_ _[_int] , torch.Tensor ] , optional) – List or tensor of sequence lengths for key/value. (Defaults to
q_seqlen.)
Returns
BlockDiagonalMask
classmethod from_tensor_list(tensors: Sequence[Tensor]) → Tuple[BlockDiagonalMask, Tensor][source]¶
Creates a BlockDiagonalMask from a list of tensors, and returns the tensors concatenated on the sequence length dimension
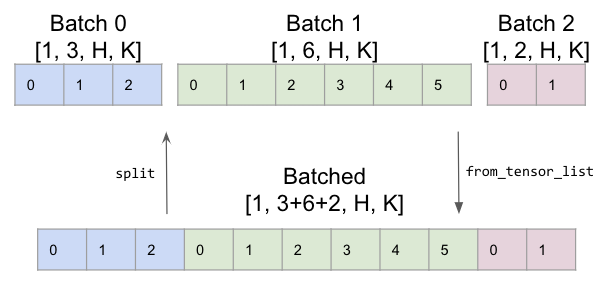
See also BlockDiagonalMask.split to split the returnedtorch.Tensor back to a list of tensors of varying sequence length¶
Parameters
tensors (Sequence [ torch.Tensor ]) – A list of tensors of shape [B, M_i, *]. All tensors should have the same dimension and the same batch size B, but they can have different sequence length M.
Returns
Tuple[BlockDiagonalMask, torch.Tensor] – The corresponding bias for the attention along with tensors concatenated on the sequence length dimension, with shape [1, sum_i{M_i}, *]
split(tensor: Tensor) → Sequence[Tensor][source]¶
The inverse operation of BlockDiagonalCausalMask.from_tensor_list
Parameters
tensor (torch.Tensor) – Tensor of tokens of shape [1, sum_i{M_i}, *]
Returns
Sequence[torch.Tensor] – A list of tokens with possibly different sequence lengths
make_causal() → BlockDiagonalCausalMask[source]¶
Makes each block causal
make_causal_from_bottomright() → BlockDiagonalCausalFromBottomRightMask[source]¶
Makes each block causal with a possible non-causal prefix
make_local_attention(window_size: int) → BlockDiagonalCausalLocalAttentionMask[source]¶
Experimental: Makes each block causal with local attention
make_local_attention_from_bottomright(window_size: int) → BlockDiagonalCausalLocalAttentionFromBottomRightMask[source]¶
Experimental: Makes each block causal with local attention, start from bottom right
class xformers.ops.fmha.attn_bias.BlockDiagonalCausalMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _SeqLenInfo, _batch_sizes: Optional[Sequence[int]] = None)[source]¶
Bases: BlockDiagonalMask
Same as xformers.ops.fmha.attn_bias.BlockDiagonalMask, except that each block is causal.
Queries and Keys are each divided into the same number of blocks. A query Q in block i cannot attend to a key which is not in block i, nor one which is farther from the initial key in block i than Q is from the initial query in block i.
class xformers.ops.fmha.attn_bias.BlockDiagonalCausalFromBottomRightMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _SeqLenInfo, _batch_sizes: Optional[Sequence[int]] = None)[source]¶
Bases: BlockDiagonalMask
Same as xformers.ops.fmha.attn_bias.BlockDiagonalMask, except that each block is causal. This mask allows for a non-causal prefix NOTE: Each block should have num_keys >= num_queries otherwise the forward pass is not defined (softmax of vector of -inf in the attention)
Queries and keys are each divided into the same number of blocks. A query Q in block i cannot attend to a key which is not in block i, nor one which nearer the final key in block i than Q is to the final query in block i.
class xformers.ops.fmha.attn_bias.BlockDiagonalPaddedKeysMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _PaddedSeqLenInfo)[source]¶
Bases: AttentionBias
Same as xformers.ops.fmha.attn_bias.BlockDiagonalMask, except we support padding for k/v
The keys and values are divided into blocks which are padded out to the same total length. For example, if there is space for 12 keys, for three blocks of max length 4, but we only want to use the first 2, 3 and 2 of each block, use kv_padding=4 and kv_seqlens=[2, 3, 2]. The queries are divided into blocks, without padding, of lengths given by q_seqlen.
A query Q in block i cannot attend to a key which is not in block i, nor one which is not in use (i.e. in the padded area).
materialize(shape: Tuple[int, ...], dtype: dtype = torch.float32, device: Union[str, device] = 'cpu') → Tensor[source]¶
Materialize the attention bias - for debugging & testing
classmethod from_seqlens(q_seqlen: Sequence[int], kv_padding: int, kv_seqlen: Sequence[int], causal_diagonal: Optional[Any] = None, *, device: Optional[device] = None) → BlockDiagonalPaddedKeysMask[source]¶
Creates a BlockDiagonalPaddedKeysMask from a list of tensor lengths for query and key/value.
Parameters
- q_seqlen (Sequence _[_int]) – List or tensor of sequence lengths for query tensors
- kv_padding (int) – Padding for k/v - also an upperbound on each individual key length
- kv_seqlen (Sequence _[_int]) – List or tensor of sequence lengths for key/value.
- causal_diagonal – unused, for BC only
Returns
BlockDiagonalPaddedKeysMask
class xformers.ops.fmha.attn_bias.BlockDiagonalCausalWithOffsetPaddedKeysMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _PaddedSeqLenInfo, causal_diagonal: Optional[Any] = None)[source]¶
Bases: BlockDiagonalPaddedKeysMask
Same as xformers.ops.fmha.attn_bias.BlockDiagonalCausalMask, except an offset on causality is allowed for each block and we support padding for k/v
The keys and values are divided into blocks which are padded out to the same total length. For example, if there is space for 12 keys, for three blocks of max length 4, but we only want to use the first 2, 3 and 2 of each block, use kv_padding=4 and kv_seqlens=[2, 3, 2]. The queries are divided into blocks, without padding, of lengths given by q_seqlen.
A query Q in block i cannot attend to a key which is not in block i, nor one which is not in use (i.e. in the padded area), nor one which is nearer to the final key in block i than Q is to the final query in block i.
classmethod from_seqlens(q_seqlen: Sequence[int], kv_padding: int, kv_seqlen: Sequence[int], causal_diagonal: Optional[Any] = None, *, device: Optional[device] = None) → BlockDiagonalCausalWithOffsetPaddedKeysMask[source]¶
Creates a BlockDiagonalCausalWithOffsetPaddedKeysMask from a list of tensor lengths for query and key/value.
Parameters
- q_seqlen (Sequence _[_int]) – List or tensor of sequence lengths for query tensors
- kv_padding (int) – Padding for k/v - also an upperbound on each individual key length
- kv_seqlen (Sequence _[_int]) – List or tensor of sequence lengths for key/value.
- causal_diagonal – unused, for BC only
Returns
BlockDiagonalCausalWithOffsetPaddedKeysMask
class xformers.ops.fmha.attn_bias.BlockDiagonalLocalAttentionPaddedKeysMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _PaddedSeqLenInfo, window_left: int, window_right: int)[source]¶
Bases: BlockDiagonalPaddedKeysMask
Like xformers.ops.fmha.attn_bias.BlockDiagonalCausalLocalAttentionPaddedKeysMask, except that this is non-causal.
A query Q in block i cannot attend to a key which is not in block i, nor one which is not in use (i.e. in the padded area), nor one whose distance to the final key in block i is more than window_left further or window_right nearer than Q is to the final query in block i.
A query attends to at most window_left + window_right - 1 keys.
NOTE that if window_right is 0, then this is like a BlockDiagonalCausalLocalAttentionPaddedKeysMask whose window_size is equal to window_left - 1.
class xformers.ops.fmha.attn_bias.BlockDiagonalCausalLocalAttentionPaddedKeysMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _PaddedSeqLenInfo, _window_size: int)[source]¶
Bases: BlockDiagonalPaddedKeysMask
Like xformers.ops.fmha.attn_bias.BlockDiagonalCausalWithOffsetPaddedKeysMask, except with a window size.
A query Q in block i cannot attend to a key which is not in block i, nor one which is not in use (i.e. in the padded area), nor one which is nearer to the final key in block i than Q is to the final query in block i, nor one that is at least window_size further from the final key in block i than Q is to the final query in block i.
class xformers.ops.fmha.attn_bias.PagedBlockDiagonalPaddedKeysMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _PaddedSeqLenInfo, block_tables: Tensor, page_size: int)[source]¶
Bases: AttentionBias
Same as BlockDiagonalPaddedKeysMask, but for paged attention. block_tables has shape [batch_size, max_num_pages] and K/V have shape [1, max_num_pages * page_size, num_heads, head_dim] or [1, max_num_pages * page_size, num_groups, num_heads, head_dim]
materialize(shape: Tuple[int, ...], dtype: dtype = torch.float32, device: Union[str, device] = 'cpu') → Tensor[source]¶
Materialize the attention bias - for debugging & testing
classmethod from_seqlens(q_seqlen: Sequence[int], kv_seqlen: Sequence[int], block_tables: Tensor, page_size: int, *, device: Optional[device] = None) → PagedBlockDiagonalPaddedKeysMask[source]¶
Creates a PagedBlockDiagonalPaddedKeysMask from a list of tensor lengths for query and key/value.
Parameters
- q_seqlen (Sequence _[_int]) – List or tensor of sequence lengths for query tensors
- kv_padding (int) – Padding for k/v - also an upperbound on each individual key length
- kv_seqlen (Sequence _[_int]) – List or tensor of sequence lengths for key/value.
- causal_diagonal – unused, for BC only
Returns
PagedBlockDiagonalPaddedKeysMask
class xformers.ops.fmha.attn_bias.PagedBlockDiagonalCausalWithOffsetPaddedKeysMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _PaddedSeqLenInfo, block_tables: Tensor, page_size: int)[source]¶
Bases: PagedBlockDiagonalPaddedKeysMask
Same as BlockDiagonalCausalWithOffsetPaddedKeysMask, but for paged attention. block_tables has shape [batch_size, max_num_pages] and K/V have shape [1, max_num_pages * page_size, num_heads, head_dim] or [1, max_num_pages * page_size, num_groups, num_heads, head_dim]
class xformers.ops.fmha.attn_bias.BlockDiagonalGappyKeysMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _GappySeqInfo)[source]¶
Bases: AttentionBias
Same as xformers.ops.fmha.attn_bias.BlockDiagonalMask, except k/v is gappy.
A query Q in block i only attends to a key which is in block i.
materialize(shape: Tuple[int, ...], dtype: dtype = torch.float32, device: Union[str, device] = 'cpu') → Tensor[source]¶
Materialize the attention bias - for debugging & testing
classmethod from_seqlens(q_seqlen: Sequence[int], kv_seqstarts: Sequence[int], kv_seqlen: Sequence[int], *, device: Optional[device] = None) → BlockDiagonalGappyKeysMask[source]¶
Creates a BlockDiagonalGappyKeysMask from a list of tensor lengths for query and key/value.
make_paged(block_tables: Tensor, page_size: int, notional_padding: int, paged_type: Type[PagedBlockDiagonalGappyKeysMask]) → AttentionBias[source]¶
Assuming our keys actually live in separate blocks of length notional_padding, convert to a Paged version, avoiding GPU syncs.
class xformers.ops.fmha.attn_bias.BlockDiagonalCausalWithOffsetGappyKeysMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _GappySeqInfo)[source]¶
Bases: BlockDiagonalGappyKeysMask
Same as xformers.ops.fmha.attn_bias.BlockDiagonalCausalMask, except k/v is gappy.
A query Q in block i cannot attend to a key which is not in block i, nor one which is nearer to the final key in block i than Q is to the final query in block i.
materialize(shape: Tuple[int, ...], dtype: dtype = torch.float32, device: Union[str, device] = 'cpu') → Tensor[source]¶
Materialize the attention bias - for debugging & testing
class xformers.ops.fmha.attn_bias.PagedBlockDiagonalGappyKeysMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _GappySeqInfo, block_tables: Tensor, page_size: int)[source]¶
Bases: AttentionBias
Equivalent BlockDiagonalGappyKeysMask, but for paged attention. block_tables has shape [batch_size, max_num_pages] and K/V have shape [1, max_num_pages * page_size, num_heads, head_dim] or [1, max_num_pages * page_size, num_groups, num_heads, head_dim]
materialize(shape: Tuple[int, ...], dtype: dtype = torch.float32, device: Union[str, device] = 'cpu') → Tensor[source]¶
Materialize the attention bias - for debugging & testing
classmethod from_seqlens(q_seqlen: Sequence[int], kv_seqstarts: Sequence[int], kv_seqlen: Sequence[int], block_tables: Tensor, page_size: int, *, device: Optional[device] = None) → PagedBlockDiagonalGappyKeysMask[source]¶
Creates a PagedBlockDiagonalGappyKeysMask from a list of tensor lengths for query and key/value.
Note that unlike BlockDiagonalGappyKeysMask, kv_seqstarts is addressing in a different space for each batch element. For example if you were doing a BlockDiagonalPaddedKeysMask with two batch elements and padding=100, but wanted to change it so that the first key is ignored, then you would use BlockDiagonalGappyKeysMask with kv_seqstarts [1, 101, 200]. But if you were using PagedBlockDiagonalPaddedKeysMask but wanted to ignore the first key, you would provide this function with kv_seqstarts = [1, 1].
class xformers.ops.fmha.attn_bias.PagedBlockDiagonalCausalWithOffsetGappyKeysMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _GappySeqInfo, block_tables: Tensor, page_size: int)[source]¶
Bases: PagedBlockDiagonalGappyKeysMask
Same as BlockDiagonalCausalWithOffsetGappyKeysMask, but for paged attention. block_tables has shape [batch_size, max_num_pages] and K/V have shape [1, max_num_pages * page_size, num_heads, head_dim] or [1, max_num_pages * page_size, num_groups, num_heads, head_dim]
class xformers.ops.fmha.attn_bias.BlockDiagonalCausalLocalAttentionMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _SeqLenInfo, _batch_sizes: Optional[Sequence[int]] = None, _window_size: int = 0)[source]¶
Bases: BlockDiagonalCausalMask
(Experimental feature) Same as xformers.ops.fmha.attn_bias.BlockDiagonalCausalMask. This makes the mask “local” and the attention pattern banded.
The ith query in a block only attends to keys in its block with index greater than i - window_size and less than or equal to i.
class xformers.ops.fmha.attn_bias.BlockDiagonalCausalLocalAttentionFromBottomRightMask(q_seqinfo: _SeqLenInfo, k_seqinfo: _SeqLenInfo, _batch_sizes: Optional[Sequence[int]] = None, _window_size: int = 0)[source]¶
Bases: BlockDiagonalCausalFromBottomRightMask
(Experimental feature) Same as xformers.ops.fmha.attn_bias.BlockDiagonalCausalMask. This makes the mask “local” and the attention pattern banded.
A query with distance j from the last query in its block only attends to keys in the same block, and only those whose distance to the last key in the block is greater than or equal to j and less than window_size + j.
class xformers.ops.fmha.attn_bias.LowerTriangularMask(*, _subtensor=None, device='cpu', **kwargs)[source]¶
Bases: AttentionBiasSubTensor
A lower-triangular (aka causal) mask
A query Q cannot attend to a key which is farther from the initial key than Q is from the initial query.
See also LowerTriangularFromBottomRightMask if the number of queries is not equal to the number of keys/values.
static __new__(cls, *, _subtensor=None, device='cpu', **kwargs)[source]¶
Note: create on CPU by default to avoid initializing CUDA context by mistake.
add_bias(bias: Tensor) → LowerTriangularMaskWithTensorBias[source]¶
Creates a new causal mask with an arbitrary torch.Tensor bias
class xformers.ops.fmha.attn_bias.LowerTriangularMaskWithTensorBias(bias)[source]¶
Bases: LowerTriangularMask
A lower-triangular (aka causal) mask with an additive bias
Partial Attention¶
xformers.ops.fmha.memory_efficient_attention_partial(query: Tensor, key: Tensor, value: Tensor, attn_bias: Optional[Union[Tensor, AttentionBias]] = None, p: float = 0.0, scale: Optional[float] = None, *, op: Optional[Union[Tuple[Optional[Type[AttentionFwOpBase]], Optional[Type[AttentionBwOpBase]]], Type[AttentionFwOpBase]]] = None, output_dtype: Optional[dtype] = None) → Tuple[Tensor, Tensor][source]¶
Returns a tuple (output, lse), where output is the attention in the style of memory_efficient_attention, and lse is extra data, a log-sum-exp. The outputs of calls to this with the same query and separate keys and values can be merged with merge_attentions to obtain the attention of the queries against the disjoint union of the keys and values.
Warning: The backward pass of this function is quite restricted. In particular we assume that in the forward pass the outputs were only used in merge_attention calculations, and that LSEs weren’t used anywhere except in merge attentions.
xformers.ops.fmha.merge_attentions(attn_split: Union[Tensor, Sequence[Tensor]], lse_split: Union[Tensor, Sequence[Tensor]], write_lse: bool = True, output_dtype: Optional[dtype] = None) → Tuple[Tensor, Optional[Tensor]][source]¶
Combine attention output computed on different parts of K/V for the same query to get attention on the whole K/V. See https://arxiv.org/abs/2402.05099The result is equal to
Out_full = (Out1 * exp(LSE1) + Out2 * exp(LSE2) + …) / (exp(LSE1) + exp(LSE2) + …) LSE_full = log(exp(LSE1) + exp(LSE2) + …)
Parameters
- attn_split – attention outputs for chunks, either as a list of tensors of shapes [B, M, G, H, Kq] or [B, M, H, Kq] or as a single tensor of shape [num_chunks, B, M, G, H, Kq] or [num_chunks, B, M, H, Kq]
- lse_split – LSE for chunks, either as a list of tensors of shapes [B, G, H, M] or [B, H, M] or as a single tensor of shape [num_chunks, B, G, H, M] or [num_chunks, B, H, M]
- write_lse – whether to output LSE
- output_dtype – dtype of attn_out
Returns
attn_out – [B, M, G, H, Kq] or [B, M, H, Kq] lse_out: [B, G, H, M] or [B, H, M] if write_lse
or None otherwise
Non-autograd implementations¶
xformers.ops.fmha.memory_efficient_attention_backward(grad: Tensor, output: Tensor, lse: Tensor, query: Tensor, key: Tensor, value: Tensor, attn_bias: Optional[Union[Tensor, AttentionBias]] = None, p: float = 0.0, scale: Optional[float] = None, *, op: Optional[Type[AttentionBwOpBase]] = None) → Tuple[Tensor, Tensor, Tensor][source]¶
Computes the gradient of the attention. Returns a tuple (dq, dk, dv) See xformers.ops.memory_efficient_attention for an explanation of the arguments.lse is the tensor returned byxformers.ops.memory_efficient_attention_forward_requires_grad
xformers.ops.fmha.memory_efficient_attention_forward(query: Tensor, key: Tensor, value: Tensor, attn_bias: Optional[Union[Tensor, AttentionBias]] = None, p: float = 0.0, scale: Optional[float] = None, *, op: Optional[Type[AttentionFwOpBase]] = None, output_dtype: Optional[dtype] = None) → Tensor[source]¶
Calculates the forward pass of xformers.ops.memory_efficient_attention.
xformers.ops.fmha.memory_efficient_attention_forward_requires_grad(query: Tensor, key: Tensor, value: Tensor, attn_bias: Optional[Union[Tensor, AttentionBias]] = None, p: float = 0.0, scale: Optional[float] = None, *, op: Optional[Type[AttentionFwOpBase]] = None, output_dtype: Optional[dtype] = None) → Tuple[Tensor, Tensor][source]¶
Returns a tuple (output, lse), where lse can be used to compute the backward pass later. See xformers.ops.memory_efficient_attention for an explanation of the arguments See xformers.ops.memory_efficient_attention_backward for running the backward pass