FLAME (original) (raw)
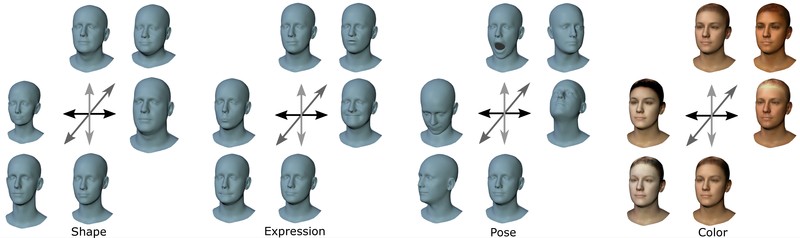
FLAME model variations for shape, expression, pose, and appearance. For shape, expression, and appearance variations, the first three three principal components are visualized at ±3 standard deviations. The pose variations are visualized at ±π/6 (head pose) and 0,π/8 (jaw articulation).
Abstract
The field of 3D face modeling has a large gap between high-end and low-end methods. At the high end, the best facial animation is indistinguishablefrom real humans, but this comes at the cost of extensive manual labor. At the low end, face capture from consumer depth sensors relies on 3D face models that are not expressive enough to capture the variability in natural facial shape and expression. We seek a middle ground by learning a facial model from thousands of accurately aligned 3D scans. Our FLAME model (Faces Learned with an Articulated Model and Expressions) is designed to work with existing graphics software and be easy to fit to data. FLAME uses a linear shape space trained from 3800 scans of human heads. FLAME combines this linear shape space with an articulated jaw, neck, and eyeballs, pose-dependent corrective blendshapes, and additional global expression blendshapes. The pose and expression dependent articulations are learned from 4D face sequences in the D3DFACS dataset along with additional 4D sequences. We accurately register a template mesh to the scan sequences and make the D3DFACS registrations available for research purposes. In total the model is trained from over 33, 000 scans. FLAME is low-dimensional but more expressive than the FaceWarehouse model and the Basel Face Model. We compare FLAME to these models by fitting them to static 3D scans and 4D sequences using the same optimization method. FLAME is significantly more accurate and is available for research purposes.
Video
News
- 05/23: Updated FLAME with revised eye region (FLAME2023)
- 11/22: Collection of public FLAME resources (i.e., code, publications, data).
- 07/22: Released MICA dataset obtained by unifying existing 3D face datasets under a common FLAME topology
- 07/22: Released MICA, a framework to reconstruct metrical 3D face shapes from images
- 04/22: Released EMOCA, a framework to reconstruct expressive FLAME meshes from images
- 02/21: FLAME vertices masks available for download
- 12/20: Released DECA, a framework to reconstruct FLAME meshes with animatable details from images
- 12/20: Released a Basel Face Model to FLAME converter
- 10/20: FLAME registrations for 1216 subjects from the Liverpool York Head Dataset (LYHM) available here
- 09/20: FLAME Blender Add-on available for download
- 08/20: Released PyTorch photometric FLAME fitting framework
- 06/20: AlbedoMM [CVPR 2020] now also available as FLAME texture model
- 04/20: FLAME texture space available for download
- 04/20: Website moved to new content management system. Please register again if you previously have registered on the old website.
- 04/20: Updated FLAME with better expression basis (FLAME 2020)
- 03/20: Released FLAME PyTorch framework
- 05/19: Updated FLAME with better mouth shape, and expression basis trained from more data (FLAME 2019)
- 05/19: Released FLAME Tensorflow framework
- 05/19: Released RingNet, a framework to reconstruct FLAME parameters from images
- 11/17: Released FLAME Chumpy framework
Interactive Model Viewer
Interactive tool to visualize the first 10 shape components (out of 300) and the first 10 expression components (out of 100), and pose articulations of head and jaw (without pose corrective blendshapes). The shape and expression parameters can be varied between ±2 standard deviations by changing the slider values. The dropdown menu within the viewer allows to switch between female, male, and generic model.
More Information
Referencing FLAME
Here is the Bibtex snippets for citing FLAME in your work.
@article{FLAME:SiggraphAsia2017,
title = {Learning a model of facial shape and expression from {4D} scans},
author = {Li, Tianye and Bolkart, Timo and Black, Michael. J. and Li, Hao and Romero, Javier},
journal = {ACM Transactions on Graphics, (Proc. SIGGRAPH Asia)},
volume = {36},
number = {6},
year = {2017},
pages = {194:1--194:17},
url = {https://doi.org/10.1145/3130800.3130813}
}
Acknowledgement
We thank Haiwen Feng for providing the MPI FLAME texture space, William Smith for support with converting and releasing AlbedoMM as FLAME texture model, and Joachim Tesch for the FLAME visualization and implementing and distributing the FLAME Blender Add-on.