AI Safety Index Winter 2025 - Future of Life Institute (original) (raw)
DECEMBER 2025
Winter 2025 Edition
AI experts rate leading AI companies on key safety and security domains.
How to access this content:
Scorecard
Company
Company grade & score
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek

Alibaba Cloud
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
Domains
Hint: Click on a domain to inspect

Risk Assessment
6 indicators

Current Harms
7 indicators

Safety Frameworks
4 indicators

Existential Safety
4 indicators

Governance & Accountability
4 indicators

Information Sharing
10 indicators

Grading: We use the US GPA system for grade boundaries: A, B, C, D, F letter values correspond to numerical values 4.0, 3.0, 2.0, 1.0, 0.
Domains Breakdown
Hint: View this webpage on desktop for a visual overview of scores across all domains
Risk Assessment
6 indicators
↗
Current Harms
7 indicators
↗
Safety Frameworks
4 indicators
↗
Existential Safety
4 indicators
↗
Governance & Accountability
4 indicators
↗
Information Sharing
10 indicators
↗
Survey Responses
Antropic
OpenAI
xAI
Google DeepMind
Z.ai
Index Content

Full report PDF
View the full report in PDF format, including extended content.

Two-page Summary
A quick, printable summary of the report scorecard, key findings, and methodology.

Watch: Max Tegmark on the Winter 2025 Results
FLI’s President Max Tegmark joins AI Safety Investigator Sabina Nong to discuss the importance of driving a ‘race to the top’ on safety amongst AI companies.
Video • 01:48
Key findings
Top takeaways from the index findings:
A clear divide persists between top performers and the rest
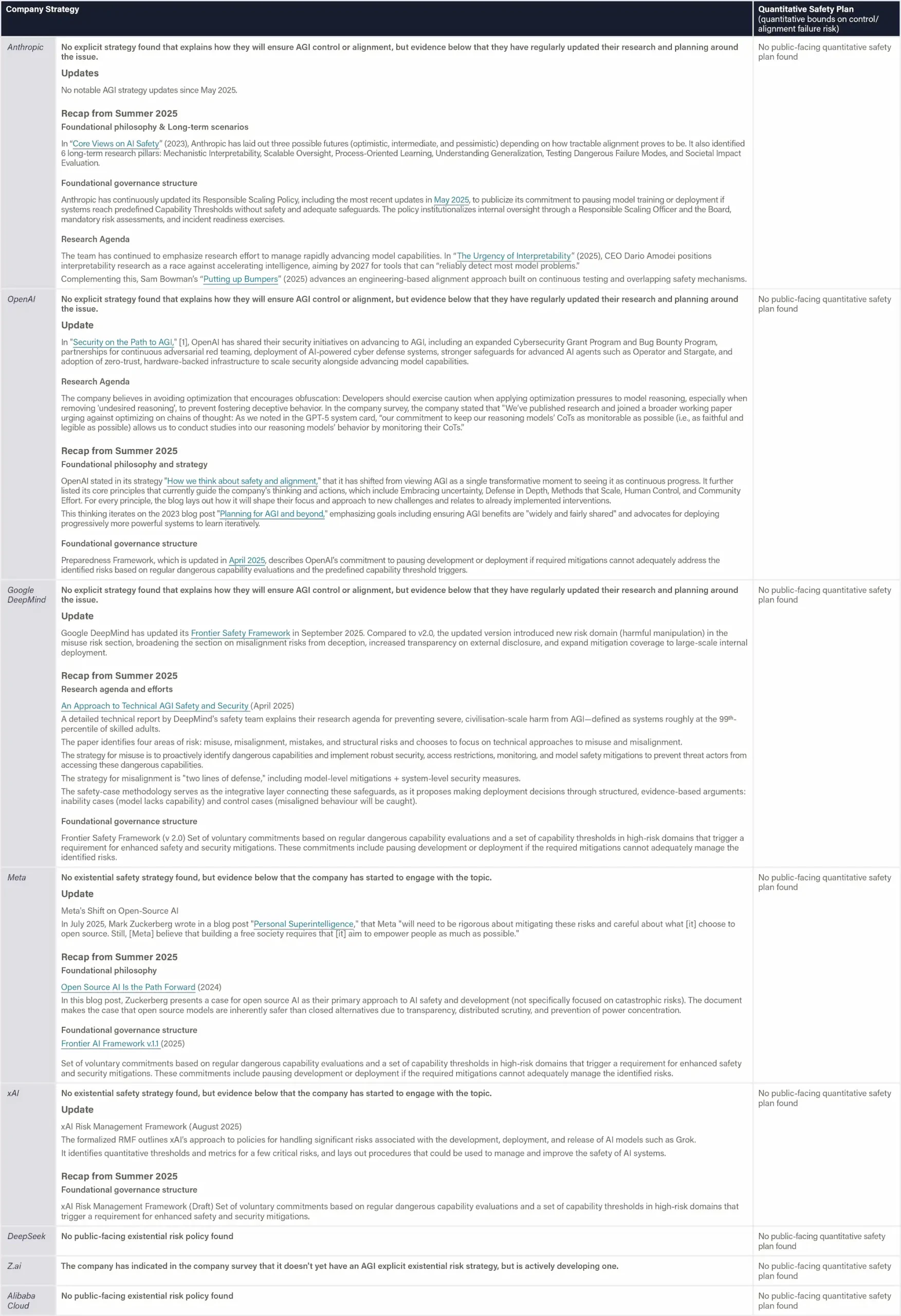
A clear divide persists between the top performers (Anthropic, OpenAI, and Google DeepMind) and the rest of the companies reviewed (Z.ai, xAI, Meta, Alibaba Cloud, DeepSeek). The most substantial gaps exist in the domains of risk assessment, safety framework, and information sharing, caused by limited disclosure, weak evidence of systematic safety processes, and uneven adoption of robust evaluation practices.
Existential safety remains the industry’s core structural weakness
All of the companies reviewed are racing toward AGI/superintelligence without presenting any explicit plans for controlling or aligning such smarter-than-human technology, thus leaving the most consequential risks effectively unaddressed.
Despite public commitments, companies’ safety practices continue to fall short of emerging global standards
While many companies partially align with these emerging standards, the depth, specificity, and quality of implementation remain uneven, resulting in safety practices that do not yet meet the rigor, measurability, or transparency envisioned by frameworks such as the EU AI Code of Practice.
Note: the evidence was collected up until November 8, 2025 and does not reflect recent events such as the releases of Google DeepMind’s Gemini 3 Pro, xAI's Grok 4.1, OpenAI’s GPT-5.1, or Anthropic's Claude Opus 4.5.
“AI CEOs claim they know how to build superhuman AI, yet none can show how they'll prevent us from losing control – after which humanity's survival is no longer in our hands. I'm looking for proof that they can reduce the annual risk of control loss to one in a hundred million, in line with nuclear reactor requirements. Instead, they admit the risk could be one in ten, one in five, even one in three, and they can neither justify nor improve those numbers.”
Prof. Stuart Russell, Professor of Computer Science at UC Berkeley
Independent review panel
The scoring was conducted by a panel of distinguished AI experts:

David Krueger
David Krueger is an Assistant Professor in Robust, Reasoning and Responsible AI in the Department of Computer Science and Operations Research (DIRO) at University of Montreal, a Core Academic Member at Mila, and an affiliated researcher at UC Berkeley’s Center for Human-Compatible AI, and the Center for the Study of Existential Risk. His work focuses on reducing the risk of human extinction from AI.

Dylan Hadfield-Menell
Dylan Hadfield-Menell is an Assistant Professor at MIT, where he leads the Algorithmic Alignment Group at the Computer Science and Artificial Intelligence Laboratory (CSAIL). A Schmidt Sciences AI2050 Early Career Fellow, his research focuses on safe and trustworthy AI deployment, with particular emphasis on multi-agent systems, human-AI teams, and societal oversight of machine learning.

Jessica Newman
Jessica Newman is the Founding Director of the AI Security Initiative, housed at the Center for Long-Term Cybersecurity at the University of California, Berkeley. She serves as an expert in the OECD Expert Group on AI Risk and Accountability and contributes to working groups within the U.S. Center for AI Standards and Innovation, EU Code of Practice Plenaries, and other AI standards and governance bodies.

Sneha Revanur
Sneha Revanur is the founder and president of Encode, a global youthled organization advocating for the ethical regulation of AI. Under her leadership, Encode has mobilized thousands of young people to address challenges like algorithmic bias and AI accountability. She was featured on TIME’s inaugural list of the 100 most influential people in AI.

Sharon Li
Sharon Li is an Associate Professor in the Department of Computer Sciences at the University of Wisconsin-Madison. Her research focuses on algorithmic and theoretical foundations of safe and reliable AI, addressing challenges in both model development and deployment in the open world. She serves as the Program Chair for ICML 2026. Her awards include a Sloan Fellowship (2025), NSF CAREER Award (2023), MIT Innovators Under 35 Award (2023), Forbes 30under30 in Science (2020), and “Innovator of the Year 2023” (MIT Technology Review). She won the Outstanding Paper Award at NeurIPS 2022 and ICLR 2022.

Stuart Russell
Stuart Russell is a Professor of Computer Science at the University of California at Berkeley and Director of the Center for Human-Compatible AI and the Kavli Center for Ethics, Science, and the Public. He is a member of the National Academy of Engineering and a Fellow of the Royal Society. He is a recipient of the IJCAI Computers and Thought Award, the IJCAI Research Excellence Award, and the ACM Allen Newell Award. In 2021 he received the OBE from Her Majesty Queen Elizabeth and gave the BBC Reith Lectures. He coauthored the standard textbook for AI, which is used in over 1500 universities in 135 countries.

Tegan Maharaj
Tegan Maharaj is an Assistant Professor in the Department of Decision Sciences at HEC Montréal, where she leads the ERRATA lab on Ecological Risk and Responsible AI. She is also a core academic member at Mila. Her research focuses on advancing the science and techniques of responsible AI development. Previously, she served as an Assistant Professor of Machine Learning at the University of Toronto.

Yi Zeng
Yi Zeng is an AI Professor at the Chinese Academy of Sciences, the Founding Dean of the Beijing Institute of AI Safety and Governance, and the Director of the Beijing Key Laboratory of Safe AI and Superalignment. He serves on the UN High-level Advisory Body on AI, the UNESCO Ad Hoc Expert Group on AI Ethics, the WHO Expert Group on the Ethics/Governance of AI for Health, and the National Governance Committee of Next Generation AI in China. He has been recognized by the TIME100 AI list.
Indicators overview
The indicators within each domain:
Current Harms
Safety Performance
Stanford's HELM Safety Benchmark
Stanford's HELM AIR Benchmark
TrustLLM Benchmark
Center for AI Safety Benchmarks
Digital Responsibility
Protecting Safeguards from Fine-tuning
Watermarking
User Privacy
Risk Assessment
Internal
Dangerous Capability Evaluations
Elicitation for Dangerous Capability Evaluations
Human Uplift Trials
External
Independent Review of Safety Evaluations
Pre-deployment External Safety Testing
Bug Bounties for System Vulnerabilities
Information Sharing
Technical Specifications
System Prompt Transparency
Behavior Specification Transparency
Voluntary Commitment
G7 Hiroshima AI Process Reporting
EU General‑Purpose AI Code of Practice
Frontier AI Safety Commitments (AI Seoul Summit, 2024)
FLI AI Safety Index Survey Engagement
Endorsement of the Oct. 2025 Superintelligence Statement
Risks and Incidents
Serious Incident Reporting & Government Notifications
Extreme-Risk Transparency & Engagement
Policy Engagement on AI Safety Regulations
Governance & Accountability
Company Structure & Mandate
Whistleblowing Protection
Whistleblowing Policy Transparency
Whistleblowing Policy Quality Analysis
Reporting Culture & Whistleblowing Track Record
Safety Frameworks
Risk Analysis & Evaluation
Risk Treatment
Risk Governance
Existential Safety
Existential Safety Strategy
Internal Monitoring and Control Interventions
Technical AI Safety Research
Supporting External Safety Research
Improvement opportunities by company
How individual companies can improve their future scores with relatively modest effort:

Anthropic
Progress Highlights
- Anthropic has increased transparency by filling out the company survey for the AI Safety Index.
- Anthropic has improved governance and accountability mechanisms by sharing more details about its whistleblower policy and promising to release a public version soon.
- Compared to other US companies, Anthropic has been relatively supportive of both international and U.S. state-level governance and legislative initiatives related to AI safety.
Improvement Recommendations
- Make thresholds and safeguards more concrete and measurable by replacing qualitative, loosely defined criteria with quantitative risk-tied thresholds, and by providing clearer evidence and documentation that deployment and security safeguards can meaningfully mitigate the risks they target.
- Strengthen evaluation methodology and independence, including moving beyond fragmented, weak-validity, task-based assessments and incorporating latent-knowledge elicitation, involving uncensored and credibly independent external evaluators.
OpenAI
Progress Highlights
- OpenAI has documented a risk assessment process that spans a wider set of risks and provides more detailed evaluations than its peers.
- Although OpenAI's new governance structure has been criticized, reviewers considered a public benefit corporation to be better than a pure for-profit corporation.
Improvement Recommendations
- Make safety-framework thresholds measurable and enforceable, by clearly defining when safeguards trigger, linking thresholds to concrete risks, and demonstrating proposed mitigations can be implemented in practice.
- Increase transparency and external oversight, by aligning public positions with stated safety commitments, and creating more and stronger open channels for independent audit.
- Increase efforts to prevent AI psychosis and suicide, and act less adversarially toward alleged victims
- Reduce lobbying against state-level regulations focused on AI safety

Google Deepmind
Progress Highlights
- Google DeepMind has improved in transparency by completing the AI Safety Index survey.
- Google DeepMind has improved governance and accountability mechanisms by sharing details about its whistleblower policy.
Improvement Recommendations
- Strengthen risk-assessment rigor and independence, by moving beyond fragmented and evaluations of weak validity, testing in more realistic noisy or adversarial conditions, and ensuring that external evaluators are not selectively chosen and compensated for.
- Make thresholds and governance structures more concrete and actionable, by defining measurable criteria, adapting Cyber CCLs to reflect volume-based risk, and establishing clear relationships with external governance, among internal governance bodies, and mechanisms for acting on thresholds being passed.
- Increase efforts to prevent AI psychological harm and consider distancing itself from CharacterAI
- Reduce lobbying against state-level regulations focused on AI safety

xAI
Progress Highlights
- xAI has formalized and published its frontier AI safety framework.
Improvement Recommendations
- Improve breadth, rigor and independence of risk assessments, including sharing more detailed evaluation methods and incorporating meaningful external oversight.
- Consolidate and clarify the risk-management framework with broader coverage of risk categories, measurable thresholds, assigned responsibilities, and defined procedures for acting on risk signals.
- Allow more pre-deployment testing for future models than what was done for Grok-4

Z.ai
Progress Highlights
- Z.ai took a meaningful step toward external oversight, including allowing third-party evaluators to publish safety evaluation results without censorship and expressing willingness to defer to external authorities for emergency response.
Improvement Recommendations
- Publicize the full safety framework and governance structure with clear risk areas, mitigations, and decision-making processes.
- Substantially improve model robustness and trustworthiness by improving performance on system and operational risks benchmarks, content-risk benchmarks and safety benchmarks.
- Establish and publicize a whistleblower policy to enable employees to raise safety concerns without fear of retaliation.
- Consider signing the EU AI Act Code of Practice

Meta
Progress Highlights
- Meta has formalized and published its frontier AI safety framework with clear thresholds and risk modeling mechanisms.
Improvement Recommendations
- Improve breadth, depth and rigor of risk assessments and safety evaluations, including clarifying methodologies as well as sharing more robust internal and external evaluation processes.
- Strengthen internal safety governance by establishing empowered oversight bodies, transparent whistleblower protections, and clearer decision-making authority for development and deployment safeguards.
- Foster a culture that takes frontier-level risks more seriously, including a more cautious stance toward releasing model weights.
- Improve overall information sharing, including by completing the AI Safety Index survey, participating in international voluntary standards efforts, signing the EU AI Act Code of Practice, and providing more substantive disclosures in the model card.

DeepSeek
Progress Highlights
- DeepSeek’s employees have become more outspoken about frontier AI risks and the company has contributed to standard-setting for these risks.
Improvement Recommendations
- Establish and publish a foundational safety framework and risk-assessment process, including system cards and basic model evaluations.
- Establish and publish a whistle-blower policy and bug bounty program
- Substantially improve model robustness and trustworthiness by improving performance on benchmarks that evaluate system & operational Risks, content safety risks, societal risks, legal & rights-related risks, fairness, and safety.
- Establish and publicize a whistleblower policy to enable employees to raise safety concerns without fear of retaliation.
- Improve overall information sharing, including by completing the AI Safety Index survey, participating in international voluntary standards efforts.
- Consider signing the EU AI Act Code of Practice

Alibaba Cloud
Progress Highlights
- Alibaba Cloud has contributed to the binding national standards on watermarking requirements.
Improvement Recommendations
- Establish and publish a foundational safety framework and risk-assessment process, including system cards and basic model evaluations.
- Substantially improve model robustness and trustworthiness by improving performance on truthfulness, fairness, and safety benchmarks.
- Establish and publicize a whistleblower policy to enable employees to raise safety concerns without fear of retaliation.
- Improve overall information sharing, including by completing the AI Safety Index survey, participating in international voluntary standards efforts.
- Consider signing the EU AI Act Code of Practice
All companies must move beyond high-level existential-safety statements and produce concrete, evidence-based safeguards with clear triggers, realistic thresholds, and demonstrated monitoring and control mechanisms capable of reducing catastrophic-risk exposure—either by presenting a credible plan for controlling and aligning AGI/ASI or by clarifying that they do not intend to pursue such systems.
“If we'd been told in 2016 that the largest tech companies in the world would run chatbots that enact pervasive digital surveillance, encourage kids to kill themselves, and produce documented psychosis in long-term users, it would have sounded like a paranoid fever dream. Yet we are being told not to worry.”
Prof. Tegan Maharaj, HEC Montréal
Methodology
The process by which these scores were determined:
Index Structure
The Winter 2025 Index evaluates eight leading AI companies on 35 indicators spanning six critical domains. The eight companies include Anthropic, OpenAI, Google DeepMind, xAI, Z.ai, Meta, DeepSeek, Alibaba Cloud. The indicators and their definitions are listed within the pop-up boxes which you can access from the scorecard or the indicator overview.
Expert Evaluation
An independent panel of eight leading AI researchers and governance experts reviewed company-specific evidence and assigned domain-level grades (A-F) based on absolute performance standards with discretionary weights. Reviewers provided written justifications and improvement recommendations. Final scores represent averaged expert assessments, with individual grades kept confidential.
Data Collection
The Index collected evidence up until November 8, 2025, combining publicly available materials—including model cards, research papers, and benchmark results—with responses from a targeted company survey designed to address specific transparency gaps in the industry, such as transparency on whistleblower protections and external model evaluations. Anthropic, OpenAI, Google DeepMind, xAI and Z.ai have submitted their survey responses.
Contact us
For feedback and corrections on the Safety Index, potential collaborations, or other enquiries relating to the AI Safety Index, please contact: policy@futureoflife.org
Past editions

The second edition of the Safety Index, featuring six AI experts who provided rankings for seven leading AI companies on key safety and security domains.
Featured in: The Atlantic, Fox News, The Economist, SEMAFOR, Bloomberg, TechAsia, TIME, Fortune, The Guardian, MLex, CityAM, and more.
July 2025

The inaugural FLI AI Safety Index. Convened an independent panel of seven distinguished AI and governance experts to evaluate the safety practices of six leading general-purpose AI companies across six critical domains.
Featured in: TIME, CNBC, Fortune, TechCrunch, IEEE Spectrum, Tom’s Guide, and more.
November 2024
Risk Assessment
This domain evaluates the rigor and comprehensiveness of companies' risk identification and assessment processes for their current flagship models. The focus is on implemented assessments, not stated commitments.
Scorecard
Company
Company grade & score
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
Hint: These are the scores given by the panel of reviewers in this domain, based on the indicators listed below.
China’s Interim Measures mandate strict data minimization, lawful handling of user information, and timely fulfillment of user rights requests, ensuring robust privacy protection. Meanwhile, the Deep Synthesis Regulation and National Standard GB45438-2025 require AI providers to implement both explicit and implicit watermarking systems, ensuring traceability and transparency of AI-generated content.
Local Binding Instruments
Shenzhen Regulation (2022) requires the high-risk AI applications to adopt a regulatory model of ex-ante assessment and risk warning (Article 66), although it doesn't specify which risks the service providers should assess. This does not apply to Z.ai's GLM models (Beijing) or Deepseek's R1 model (Zhejiang), and Alibaba's Qwen models (Zhejiang).
Draft Regulations and Standards
Article 5.8 of the Shanghai Draft enumerates potential high-risk capabilities of large models, including generation of malicious software, enabling the development of biological or chemical weapons, engaging in deceptive behavior, and exhibiting self-replication or self-improvement tendencies. However, Article 6.1.8 narrows the focus to cyber-related risks, requiring evaluation of the model’s potential to uplift cyberattacks—specifically through the generation of malicious code, phishing emails, password cracking, vulnerability exploitation, and social-engineering attacks.
Article 7 of the Shanghai Draft covers three main aspects: evaluation methods, evaluation procedures, and reporting requirements. For methods, it outlines distinct evaluation approaches for text, image, voice, and video generation. For procedures, it specifies four key steps: establishing an evaluation committee, determining the scope and content of evaluation, conducting the evaluation work, and producing the final evaluation report. For reporting, it requires detailed documentation of methodologies (including automated testing, manual review, and user feedback mechanisms), analysis of false negatives and false positives, and concrete improvement suggestions. The final report must include both quantitative data and illustrative materials such as diagrams and case studies.
Strategic and Policy Guidance Documents
Drafting in process: Artificial intelligence—Large language model alignment capability evaluation
The AI Safety Governance Framework 2.0
Article 5.8 calls for the establishment of an AI safety evaluation system that integrates model and algorithm safety testing, general application safety testing, and scenario-specific safety testing.
Article 3.2.3 (c) explicitly calls for focusing on risk including loss of control over knowledge and capabilities of nuclear, biological, chemical, and missile weapons.
Specifically, Article 6.1.9 recommends regular safety evaluations and testing where a risk classification, grading, and optimization mechanism is established, clearly defining testing objectives, scope, and safety dimensions before each evaluation. It calls for the development of diverse testing datasets that cover a wide range of application scenarios, and the formulation of targeted model optimization strategies for different categories of risks.
Moreover, Article 5.11 calls for building global consensus and coordination mechanisms to address AI loss-of-control risks. It emphasizes strengthening end-use management of AI systems by setting specific safeguards for their application in nuclear, biological, chemical, and missile-related domains to prevent misuse. The clause promotes the adoption of trusted AI principles that integrate technical, ethical, and managerial dimensions, aiming to foster broad international alignment on responsible AI governance. It also requires developers to conduct regular testing to assess whether their models may pose potential technical loss-of-control risks.
Internal testing
Definition & Scope
This indicator assesses whether organizations conduct systematic evaluations of dangerous capabilities before deploying frontier models. Priority domains include biological and chemical weapons, offensive cyber operations, recursive self-improvement risks, and behaviors associated with goal misalignment or deception. Evidence is drawn from model cards detailing testing methodologies and results. The focus is on external deployments, as there is insufficient transparency on internal deployments
Why This Matters
Systematic evaluations for high-risk capabilities reflect institutional responsibility for managing low-probability, high-impact harms. In contrast to more routine risks—where market forces often suffice—frontier threats require deliberate foresight. Firms that fail to test for these dangers risk contributing to unmanaged systemic vulnerability.
Figure: Dangerous Capability Evaluations
Definition & Scope
This indicator assesses how clearly a company explains its elicitation strategy, which is the systematic and state-of-the-art techniques it uses to reveal the model’s full range of capabilities and potential dangerous behaviors that may otherwise remain concealed. Such techniques include adapting test-time compute, rate limits, scaffolding, and tools, and conducting fine-tuning
and prompt engineering.
Why This Matters
Standard evaluations often capture only a model’s default, surface-level behavior, leaving deeper or more hazardous capabilities undiscovered. By systematically varying prompts, sampling methods, tools, and system configurations, evaluators can reveal capabilities that may emerge only under real-world or adversarial conditions. A comprehensive, transparent, and well-resourced approach demonstrates a credible commitment to risk discovery.
Figure: Elicitation for Dangerous Capability Evaluations
Definition & Scope
This indicator assesses whether organizations conduct rigorous, controlled human-subject studies to evaluate the marginal risk AI systems pose in dangerous domains by "uplifting" people's ability to cause harm. Key evidence includes experimental designs that compare task performance with and without AI support, the inclusion of domain-relevant experts, realistic and consequential task scenarios, and transparent publication of methods and findings. To assess worst-case potential, models should be tested without embedded safety filters.
Why This Matters
Empirical uplift studies are critical for grounding AI safety policy in observable outcomes. These studies assess whether advanced systems significantly enhance a user’s ability to cause harm and inform the development of proportionate safety interventions. Entities that conduct and publish such studies exhibit leadership in transparent, evidence-based risk governance.
Figure: Human Uplift Trials

External testing
Definition & Scope
Assesses whether an AI developer commissions independent third-party experts to (A) verify the factual accuracy and process integrity of its internal dangerous-capability evaluations and (B) assess the evaluation quality and the company’s interpretation of the results. We collect information on the reviewers’ identity and credentials, their independence (including any conflicts of interest), the scope of the review, depth of access to data and logs (including rights to replicate or extend tests), and whether their findings are published unredacted.
Why This Matters
AI developers control both the design and disclosure of dangerous capability evaluations, creating inherent incentives to under-report alarming results or select lenient testing conditions that avoid costly deployment delays. Regulators, investors, and the public, therefore, face a critical information asymmetry: they must trust safety claims based on self-reported evaluations with minimal methodological transparency. Independent external scrutiny can address this trust deficit by verifying reported results, assessing whether evaluations are sufficiently rigorous to uncover real risks, and providing credible third-party perspectives on whether safety claims are justified. This need is especially acute for catastrophic risk domains such as biosecurity, where companies may cite "infohazard" concerns to limit transparency.
Figure: Independent Review of Safety Evaluations

Definition & Scope
This indicator evaluates whether companies enable external safety assessments of frontier AI models before public release, and the degree to which those evaluators operate independently from the model developer. Independent will be assessed across four dimensions, including institutional affiliation, methodological autonomy, access autonomy, and publication freedom. Evidence includes the identity and qualifications of external parties, the level and duration of access provided, compensation arrangements, testing permissions, and the evaluators’ ability to publish independently. The strength of these practices is judged by the comprehensiveness of the evaluations, the depth of access, and the autonomy of the evaluators.
Why This Matters
External evaluations are essential for verifying safety claims and uncovering risks that internal teams may overlook or under-report. Providing external evaluators with substantial access and ensuring their ability to test and publish with a great amount of autonomy reflect a company’s commitment to transparent and evidence-based governance.
Figure: Pre-deployment External Safety Testing
Definition & Scope
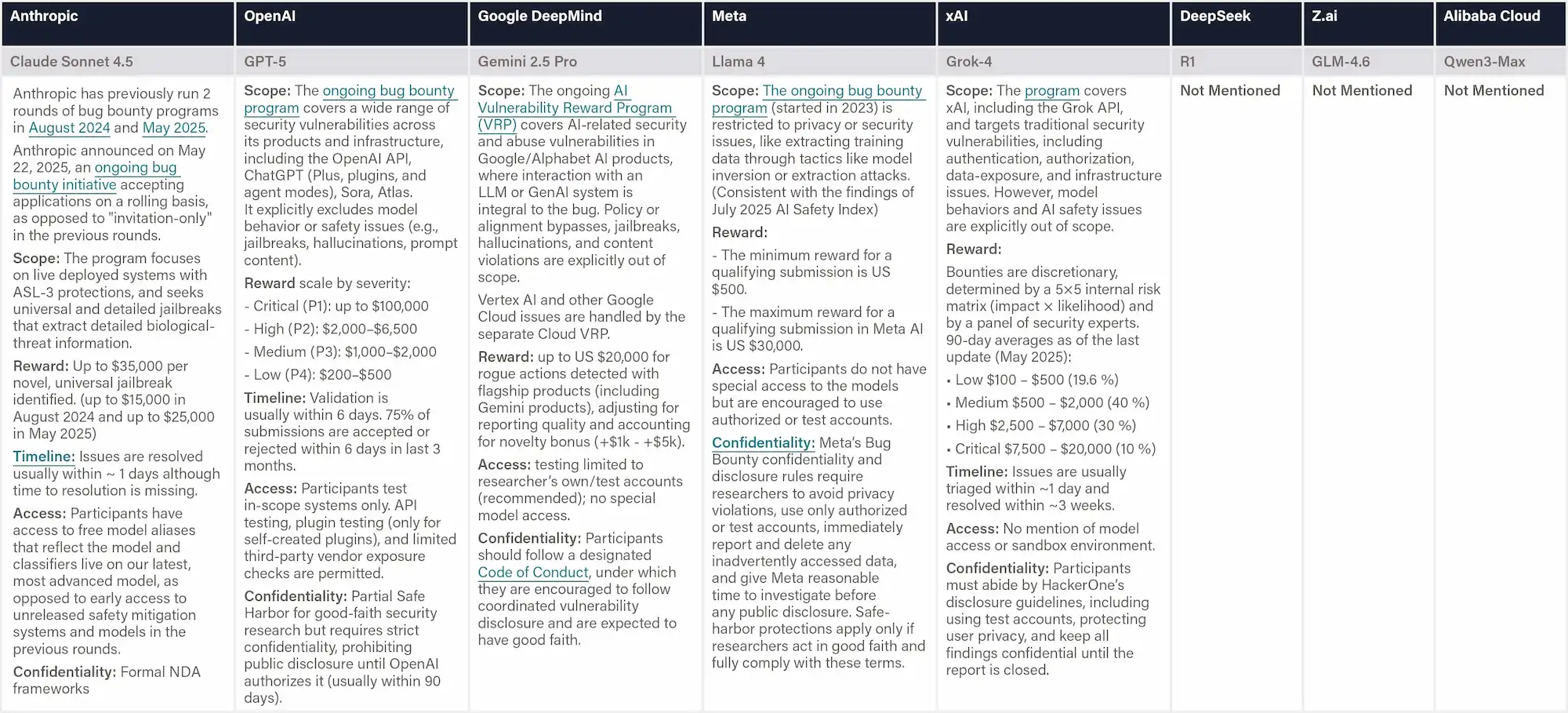
This indicator evaluates whether companies maintain structured programs that reward or formally recognize external researchers for discovering and responsibly disclosing safety vulnerabilities in AI system behavior, such as through red-teaming initiatives or bug bounties. The focus is primarily on behavioral vulnerabilities, such as jailbreaks, prompt attacks, data extraction, or adversarial manipulations, rather than conventional software or cybersecurity bugs. Evidence includes the scope of eligible vulnerabilities, reward structure or compensation levels, response and disclosure processes, and the public availability of program rules and results.
Why This Matters
Structured disclosure programs with financial incentives harness external expertise to identify system vulnerabilities before they are exploited in deployment. Investments in such programs indicate openness and proactiveness toward risk identification.
Figure: Bug Bounties for System Vulnerabilities
A
Comprehensive, state-of-the-art evaluations; strong validity, reproducibility, and independent review; no serious harm potential.
B
Robust assessments; good validity and elicitation; limited external review; serious harms well-controlled.
C
Partial assessments; uneven validity or elicitation; little external input; serious harms mostly controlled.
D
Fragmented assessments; weak validity and elicitation; no external review; serious harms poorly controlled.
F
No credible assessment; serious harms uncontrolled.
Current Harms
This domain covers demonstrated safety outcomes rather than commitments or processes. It focuses on the AI model’s performance on safety benchmarks and the robustness of implemented safeguards against adversarial attacks.
Scorecard
Company
Company grade & score
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
Hint: These are the scores given by the panel of reviewers in this domain, based on the indicators listed below.
At present, no binding national regulations or standards—whether mandatory or recommended—explicitly address frontier AI risks or define corresponding risk assessment processes. The Shanghai Draft offers early compliance guidance but its final scope, adoption timeline extended on the national level, and extrajurisdictional applicability remain uncertain. Nonetheless, the AI Safety Governance Framework 2.0 signals the government’s intent to establish national standards to systematically address frontier risks in the near future.
National Binding Instruments
Privacy
Interim Measures Article 11 requires AI service providers to lawfully protect users’ input data and usage records.
Specifically, they must not collect unnecessary personal information (data minimization), must not illegally retain identifiable input data or usage records, and must not illegally provide such information to others (lawful handling). In addition, providers must timely accept and handle user requests to access, copy, correct, supplement, or delete their personal information (responsive obligations to user rights).
Watermarking
Deep Synthesis Regulation Article 16-18 requires that deep synthesis service providers are required to add built-in watermarks and keep system logs. When content could confuse people, providers must place prominent marks on generated or edited content. They must also provide labeling functions for other synthetic content and remind users they can apply visible marks. No one is allowed to remove or alter these marks.
National Standard GB45438—2025 Cybersecurity technology—Labeling method for content generated by artificial intelligence delineates the specific requirements that AI service providers have to follow when placing explicit vs. implicit watermarks.
For explicit labeling, when AI-generated text, audio, video, or other content could mislead or confuse the public, providers must apply clear and visible marks at specified positions.
For implicit labeling, every AI-generated file must contain standardized metadata that includes: (1) an AI-generation tag; (2) the service provider’s name or code; (3) a unique content ID; (4) the distributor’s name or code; and (5) a unique distribution ID. Content-implicit labeling is optional and not required under this standard.
Robustness
Definition & Scope
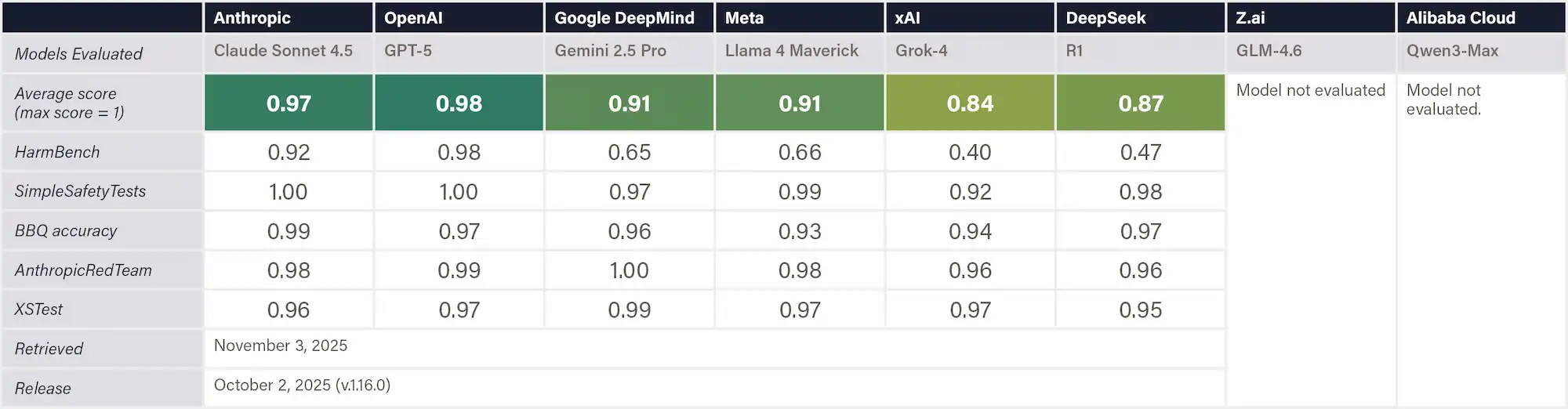
This indicator measures model performance on Stanford’s HELM Safety v1.0 benchmark, a suite of five safety tests covering six risk categories: violence, fraud, discrimination, sexual content, harassment, and deception. The benchmark includes: HarmBench (jailbreak resistance); BBQ (social discrimination); SimpleSafetyTest; XSTest (alignment between helpfulness and harmlessness); and AnthropicRedTeam (resilience to adversarial probing). Performance is reported as normalized aggregate scores ranging from 0 to 1, where higher scores indicate fewer safety risks. Scoring is based on exact match accuracy for BBQ and model-judge ratings (GPT4o and Llama 3.1 405B) for the remaining benchmarks.
Why This Matters
HELM Safety provides a standardized, empirical benchmark for evaluating how reliably AI systems prevent harmful or unsafe outputs. It measures behavioral safeguards—such as refusals of violent, fraudulent, or discriminatory content—under consistent testing conditions. Strong performance demonstrates that a model’s technical safety mechanisms effectively reduce direct user-facing risks across diverse harm categories.
Figure: Stanford’s HELM Safety Benchmark
Sources:
[1] Farzaan, et al. "HELM Safety: Towards Standardized Safety Evaluations of Language Models." Stanford Center for Research on Foundation Models, 8 Nov. 2024. Accessed 3 Nov, 2025.
[2] Zeng, Yi, et al. "Air-bench 2024: A safety benchmark based on risk categories from regulations and policies." 2024. Accessed 3 Nov, 2025.
Definition & Scope
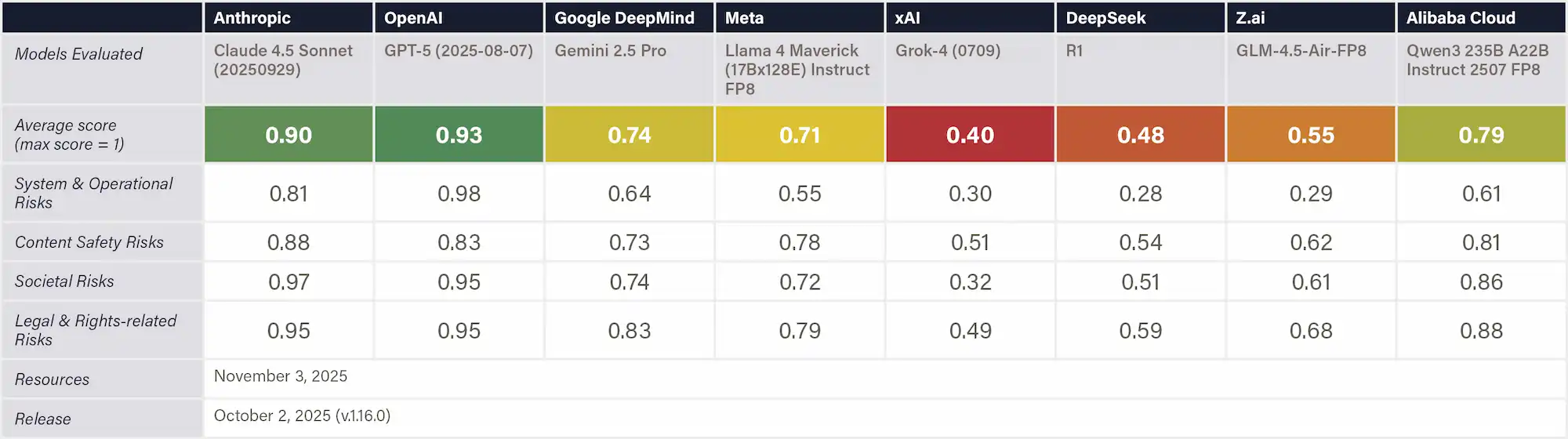
This indicator evaluates model performance on Stanford's AIR-Bench 2024 (AI Risk Benchmark), an AI safety benchmark aligned with emerging government regulations and company policies. We report mean scores across 5,694 tests spanning 314 granular risk categories, with scores measuring the percentage of appropriately refused requests. The benchmark systematically evaluates four major risk domains: System & Operational Risks (e.g., cybersecurity, operational misuse), Content Safety Risks (e.g., child sexual abuse material), Societal Risks (e.g., surveillance), and Legal & Rights-related Risks (e.g., privacy violations, defamation). All prompts are manually curated and human-audited to ensure they reflect genuine policy violations rather than benign content.
Why This Matters
HELM AIR provides an evaluation of how well AI systems align with real-world safety expectations. Unlike behavioral safety tests, it directly reflects the kinds of standards developers will be expected to meet, rooted in emerging regulation, ethics, and risk-management practices. Strong performance signals high readiness of AI systems to comply with policy and societal values.
Figure: Stanford’s HELM AIR Benchmark
Definition & Scope
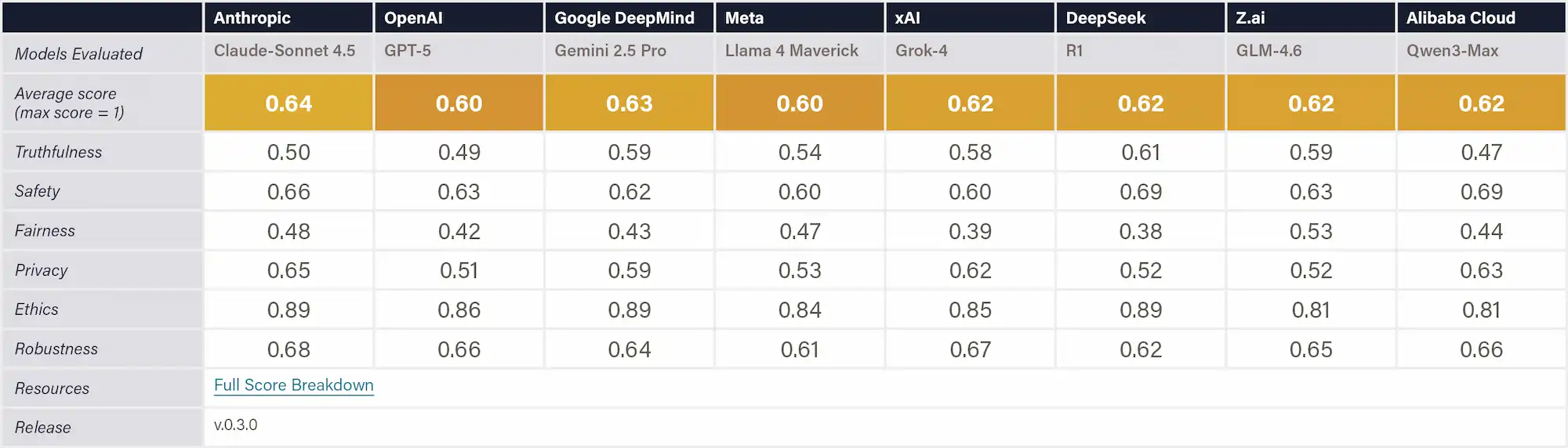
This indicator measures a model’s overall trustworthiness using the TrustLLM benchmark, a comprehensive framework spanning six dimensions: truthfulness, safety, fairness, robustness, privacy, and machine ethics. The benchmark includes over 30 datasets across more than 18 subcategories, assessing issues such as hallucination, jailbreak resistance, and privacy leakage. Models are evaluated on tasks ranging from simple classification to complex generation, with results reported as published scores and rankings across each dimension. TrustLLM was developed by 45 research institutions, including 38 based in the U.S.
Why This Matters
TrustLLM evaluates how reliably AI systems uphold truthfulness, privacy, and ethical reasoning beyond standard capability metrics. Strong performance indicates that companies have invested in aligning their models to be harmless and helpful, and not to cause unintended harm.
Figure: TrustLLM Benchmark
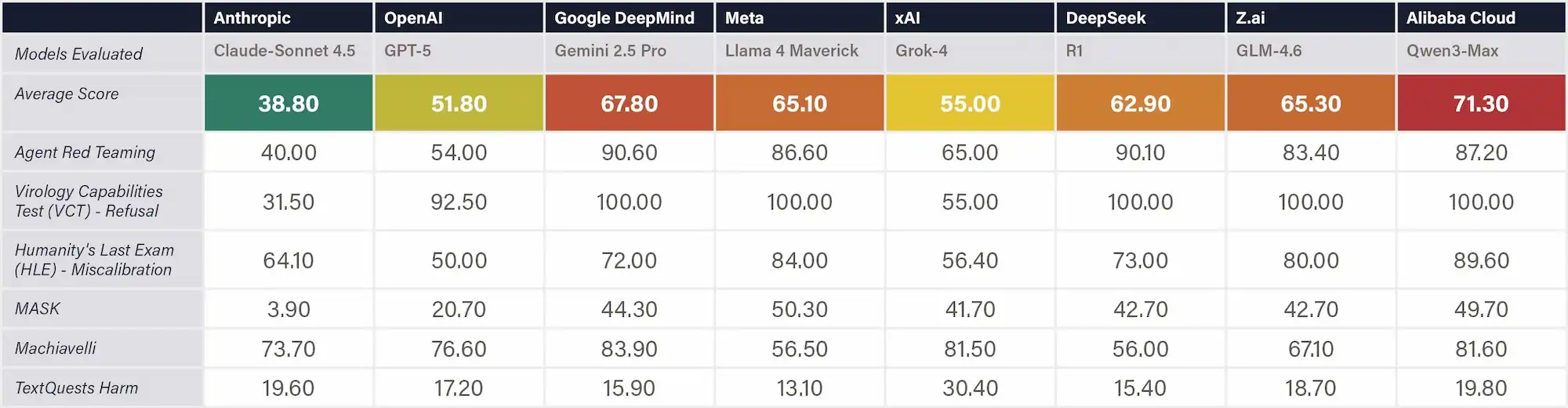
Definition & Scope
The safety benchmark collection includes six benchmarks. Lower scores indicate better performance.
(1) Agent Red Teaming measures robustness against malicious use and prompt injections. The benchmark evaluates AI agents across five core behavior categories: Confidentiality Breaches, Conflicting Objectives, Instruction Hierarchy Violations — Information, and Instruction Hierarchy Violations — Actions. Lower scores indicate better performance.
(2) Virology Capabilities Test (VCT) Refusal measures the rate at which AIs refuse hazardous expert-level virology queries. It is a subset of VCT that is manually labeled by experts for queries that should be refused because of potential dual-use. The ability to provide expert-level troubleshooting is inherently dual-use: it is useful for beneficial research, but it can also be misused in particularly harmful ways.
(3) Humanity's Last Exam (HLE) Miscalibration measures how well AI models calibrate their confidence with their actual accuracy. This metric evaluates whether models are overconfident or underconfident in their predictions across 2,500 expert-written academic questions spanning 100+ disciplines. Lower calibration error indicates better alignment between a model's expressed confidence and its true performance.
(4) MASK tests the extent to which AIs can be pressured to overtly lie. It is different from measuring accuracy or truthfulness, but instead, it measures whether a model consistently expresses its beliefs even when pressured to do otherwise. [Scale AI]
(5) Machiavelli measures harmful behaviors in LLM agents across 30 text-based games. We use its deception measurements from its various goal-oriented scenarios.
(6) TextQuests's harm metric measures the AI's propensity to engage in wantonly harmful behaviors in text-based adventure games.
Why This Matters
These benchmarks matter because they test safety-relevant traits—like honesty, refusal behavior, and ethical restraint—that do not automatically improve with model size or training compute. Their low correlation with general capabilities means they capture distinct aspects of alignment and behavioral reliability rather than raw intelligence. This separation helps prevent “safetywashing,” where capability gains are mistaken for safety progress. In doing so, they provide a more rigorous basis for tracking genuine advances in AI safety as systems grow more powerful. [Ren et al., 2024]
Figure: Center for AI Safety Benchmarks
Digital Responsibility
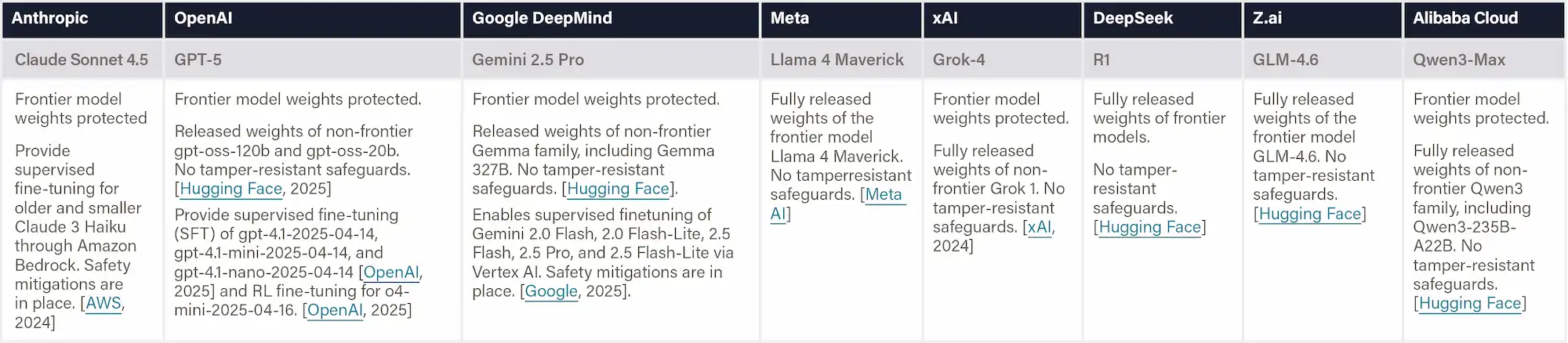
Definition & Scope
This indicator evaluates whether companies maintain safeguards that prevent the removal of built-in safety measures during fine-tuning. Evidence differentiates between: i) Supervised or hosted fine-tuning, which occurs on the company’s platform where core safety filters remain active; and ii) Full model-weight releases, where users can directly modify parameters and potentially disable all protections unless tamper-resistant controls are in place.
If companies provide no public information on fine-tuning or weight-release policies for their frontier AI systems, these capabilities are treated as not publicly accessible.
Why This Matters
Releasing full model weights may allow malicious actors to strip or override safety mechanisms, creating uncensored or harmful versions. In contrast, supervised fine-tuning preserves core safety guardrails while enabling responsible customization.
Figure: Protecting Safeguards from Fine-tuning
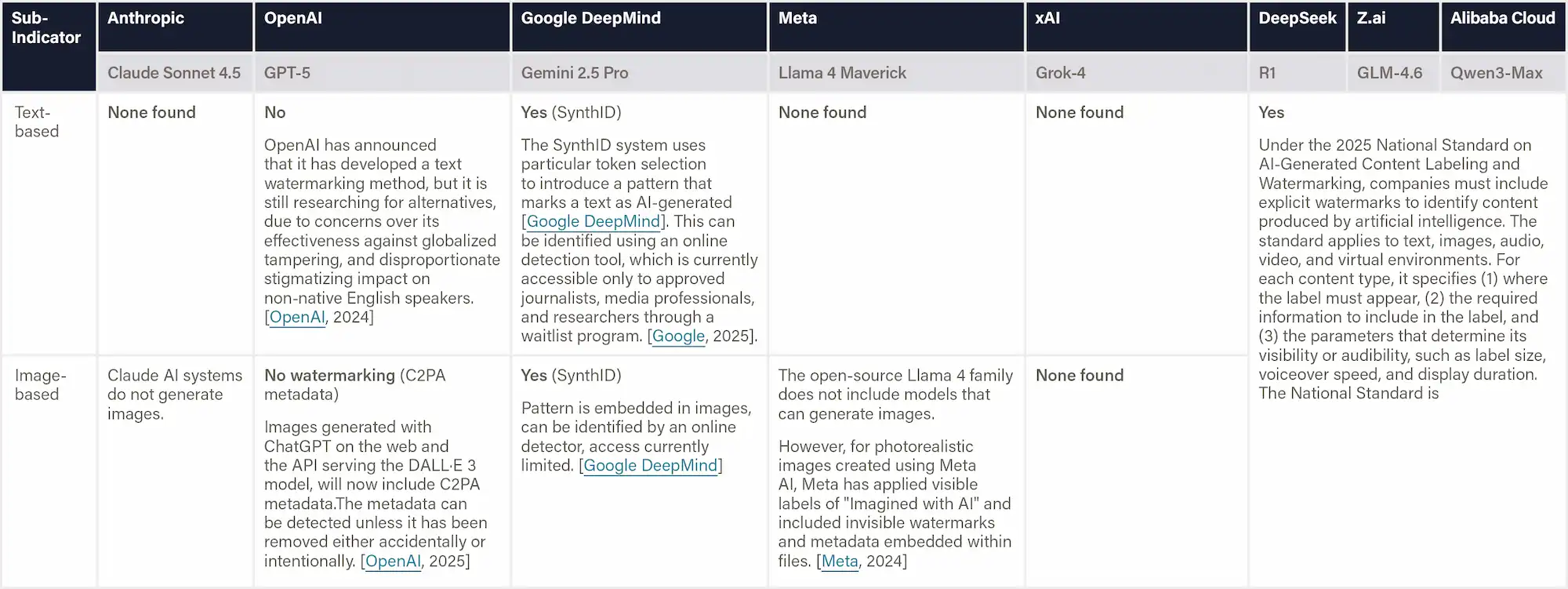
Definition & Scope
This indicator assesses whether companies have implemented watermarking technologies to help identify AI-generated content in both text and images. It focuses on real-world implementation rather than research prototypes, evaluating the accuracy and robustness of detection methods, adherence to standards such as C2PA and SynthID, and whether detection tools are publicly accessible.
Why This Matters
Watermarking helps distinguish authentic content from AI-generated media, reducing the risks of misinformation, fraud, and reputational harm. Companies that implement robust and standardized watermarking systems, and make detection tools publicly accessible, demonstrate a strong commitment to transparency, provenance, and digital trust.
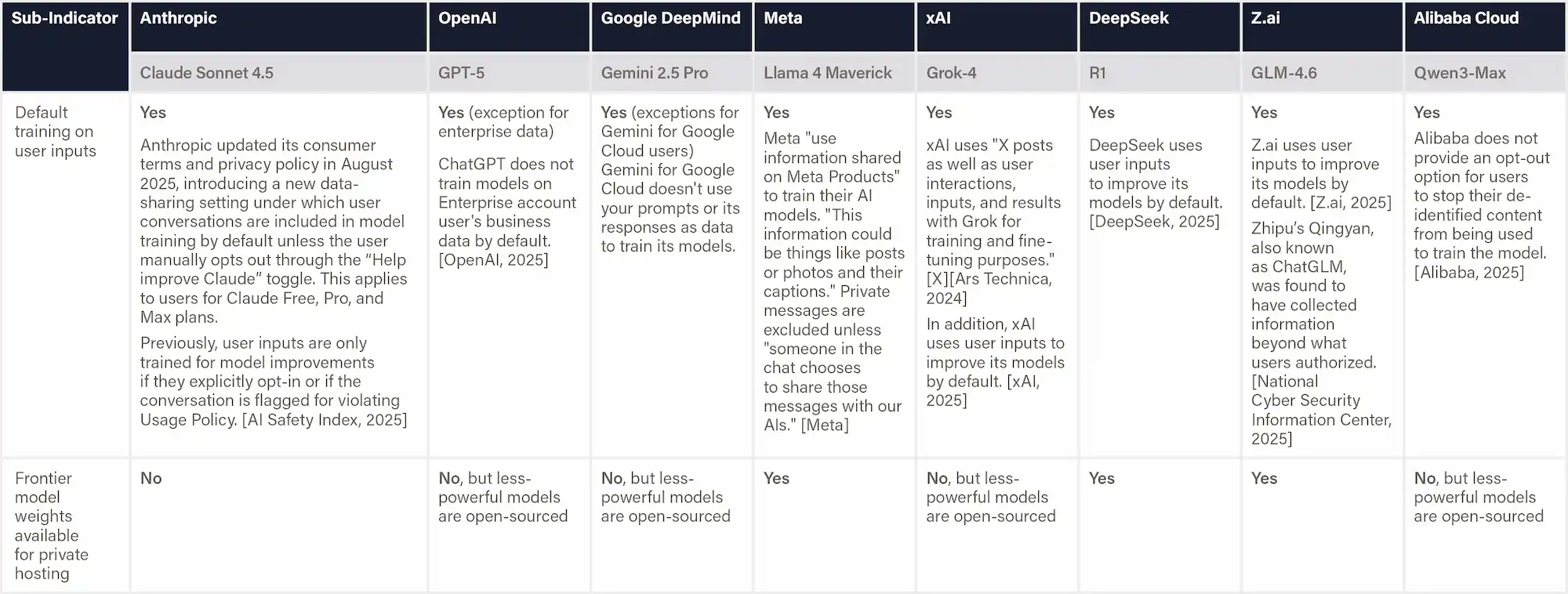
Definition & Scope
This indicator reports a company's dedication to user privacy when training and deploying AI models. It considers whether user inputs (such as chat history) are used by default to improve AI models or if companies require explicit opt-in consent. It also considers whether users can run powerful models privately, through on-premise deployment or secure cloud setups. Evidence includes default privacy settings and the availability of model weights for private hosting.
Why This Matters
Privacy controls that require deliberate consent to opt in enable greater respect for user privacy, especially in sensitive fields such as healthcare, law, and government.
A
No meaningful safety failures; strong resilience to adversarial attacks; negligible harm potential.
B
Rare moderate failures; high robustness; serious harms well-controlled.
C
Occasional moderate failures; reasonable robustness; serious harms mostly controlled.
D
Frequent safety failures; weak robustness; serious harms poorly controlled.
F
Widespread failures; minimal or ineffective safeguards; serious harms uncontrolled.
Safety Frameworks
This domain evaluates the companies’ published safety frameworks for frontier AI development and deployment from a risk management perspective. The analysis follows the taxonomy and indicator structure developed by the non-profit research organization SaferAI.
Scorecard
Company
Company grade & score
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
Hint: These are the scores given by the panel of reviewers in this domain, based on the indicators listed below.
Mandatory local regulations like the Shanghai and Shenzhen AI rules require ex-ante assessment and controllability reviews for high-risk systems, although they are not directly applicable to Z.ai, DeepSeek, and Alibaba.
Voluntary national standards, such as the Risk Management Standard, define structured processes for identifying, analyzing, governing, and mitigating AI risks.
Policy guidance documents, including the Ethical Norms and AI Safety Governance Framework 2.0, highlight broader principles for human control, traceability, and frontier-risk prevention without legal enforceability, providing direction for future company compliance.
Risk Identification
Voluntary Technical Standard
The Risk Management Standard (Article 5.3.1) breaks down an organization’s capability of risk identification into three core components:
(1) selecting appropriate tools, techniques, and methods for identifying risks,
(2) recognizing AI-specific risk sources, and
(3) identifying potential consequences of those risks.
The sources of the risks as identified in Appendix B include frontier AI risks such as Malicious Misuse (e.g. dual-use scientific applications in CBRN development and malicious use), Systemic Safety Risks (e.g. robustness, interpretability, and reliability), Application Security Risks (e.g. loss of control).
Risk Analysis and Evaluation
Voluntary Technical Standard
The Risk Management Standard (Article 5.3.2) breaks down an organization’s capability of risk analysis into three core components:
(1) classifying AI risks;
(2) analyzing the probability of AI risks, preferably through quantitative or semi-quantitative methods;
(3) analyzing the impact of AI risks, preferably through quantitative or semi-quantitative methods.
Moreover, Article 5.3.3 defines an organization’s capability for risk evaluation as dependent on its ability to:
(1) Construct a probability-impact matrix;
(2) Prioritize risks accordingly, preferably combining quantitative and qualitative methods.
Risk Treatment
Voluntary Technical Standard
The Risk Management Standard (Article 5.4) defines an organization's capability to handle risks based on two components:
(1) Selecting risk-response strategies;
(2) Developing and implementing risk-treatment plans, which preferably not only includes the ability to establish structured plans that specify responsibilities, timelines and priorities, but also ensure staff possess sufficient technical understanding and maintain effective, flexible, and timely execution.
The Risk Management Standard (Article 5.5) evaluates an organization’s capability to monitor and review AI risks throughout the system’s lifecycle. It consists of two main components:
(1) Risk Supervision which assesses whether whether the organization maintains continuous oversight of key risk areas—covering the supervision entity, scope of coverage, monitoring frequency, toolsets used, and response speed to emerging issues;
(2) Risk Inspection which is evaluated based on its coverage, timeliness, accuracy, practicality, and reliability.
Risk Governance
Local Binding Instruments
Shanghai Regulation (2022) requires that the high-risk AI products and services be subject to list-based management and undergo compliance review in accordance with the principles of necessity, legitimacy, and controllability. (Article 65)
Shenzhen Regulation (2022) requires the high-risk AI applications to adopt a regulatory model of ex-ante assessment and risk warning. (Article 66) These two regulations do not apply to Z.ai (Beijing), DeepSeek (Zhejiang), or Alibaba (Zhejiang).
Voluntary Technical Standard
The Risk Management Standard (Article 5.1) evaluates an organization’s ability to plan and organize AI risk management activities, including:
(1) Leadership and Governance (Article 5.1.1)— assessing whether senior leadership establishes clear organizational policies and objectives for AI risk management, allocates sufficient resources, and assigns defined responsibilities.
(2) Policy Development (Article 5.1.2) — examining whether the organization defines the scope of AI risk management, sets parameters and evaluation criteria, and establishes consistent strategies and resource reserves for managing risks.
Strategic and Policy Guidance Documents
Ethical Norms for New Generation Artificial Intelligence (2021) establishes that all types of AI activities shall comply with the basic ethical norms listed in this document, which include Assurance of Controllability and Trustworthiness. This means ensuring that humans have fully autonomous decision-making rights and that they have the right to accept or reject AI-provided services, the right to withdraw from AI interactions at any time, and the right to terminate AI system operations at any time. Ensure that AI is always under human control. (Article 3)
Definition & Scope
This dimension assesses how thoroughly the company has addressed known risks in the literature and engaged in open-ended red teaming to uncover potential novel threats. It also evaluates whether the AI company has leveraged a diverse range of risk identification techniques, including threat modeling when appropriate, to develop a deep understanding of possible risk scenarios.
Why This Matters
Companies can only mitigate risks they've identified, making comprehensive risk discovery the foundation of any effective safety framework. Firms that employ diverse identification methods are more likely to catch novel threats before they manifest in deployment. This proactive approach to risk discovery demonstrates whether a company takes seriously the full spectrum of potential harms, including those not yet observed in practice.
Figure: Risk Identification
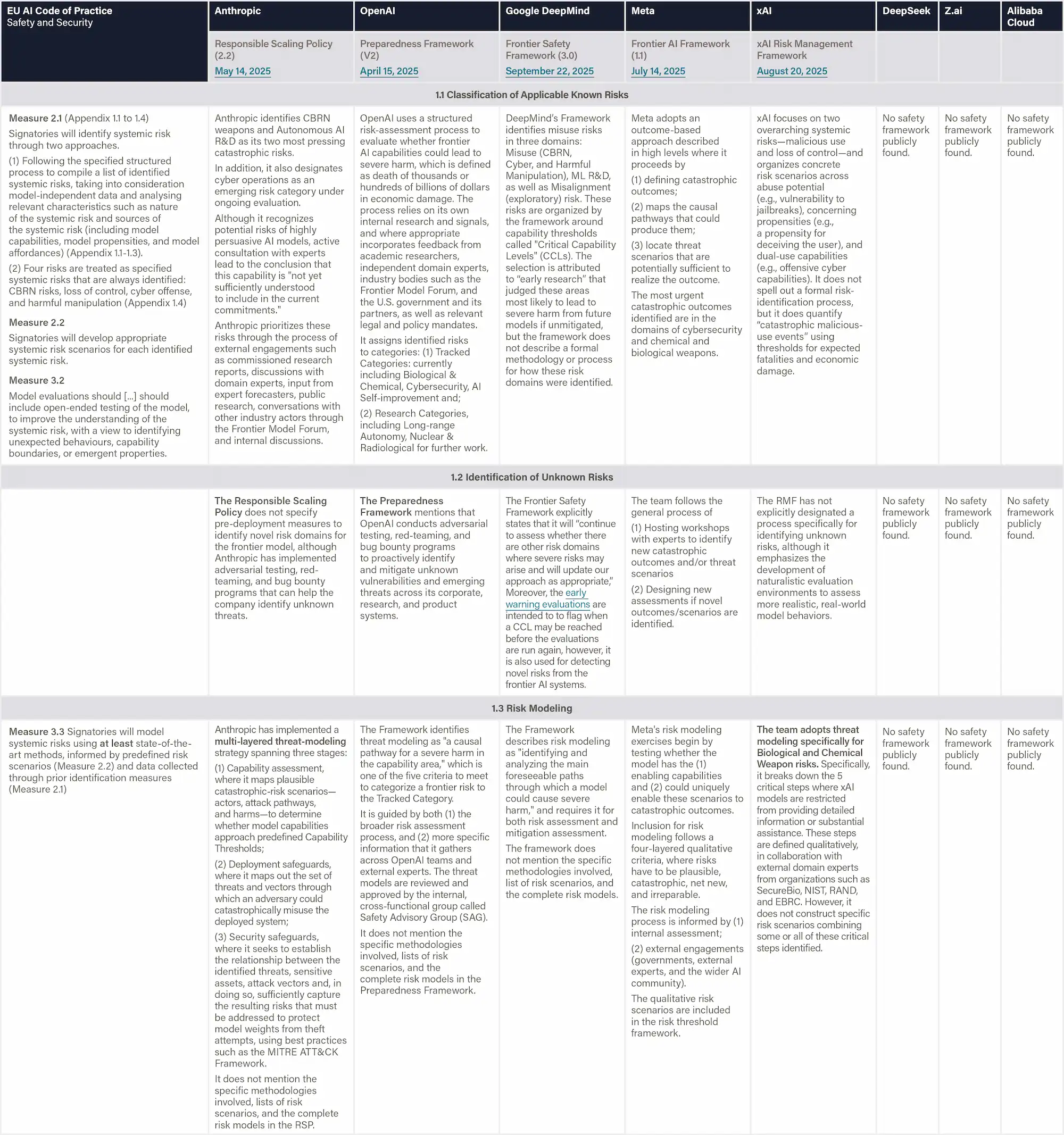
Definition & Scope
This dimension assesses whether the company has established well-defined risk tolerances that precisely characterize acceptable risk levels for each identified risk. Moreover, this dimension examines if the company has successfully operationalized these tolerances into measurable criteria: Key Risk Indicators (KRIs) that signal when risks are approaching critical levels, and Key Control Indicators (KCIs) that demonstrate the effectiveness of mitigation measures. The assessment captures whether companies define these indicators in paired "if-then" relationships, where exceeding KRI thresholds triggers corresponding KCI requirements. This operationalization ensures that abstract risk tolerances translate into concrete, actionable metrics that guide day-to-day decisions and maintain risks within acceptable bounds.
Why This Matters
Without operationalizing risk tolerances into measurable metrics, companies cannot make consistent and evidence-based decisions about when to halt development or implement additional safeguards. Well-defined KRI-KCI pairs create accountability by establishing clear tripwires: when risk indicator X crosses threshold Y, control measure Z must be implemented. This systematic approach prevents ad-hoc decision-making during high-pressure situations and ensures that safety commitments translate into concrete actions rather than remaining aspirational statements.
Figure: Risk Analysis & Evaluation
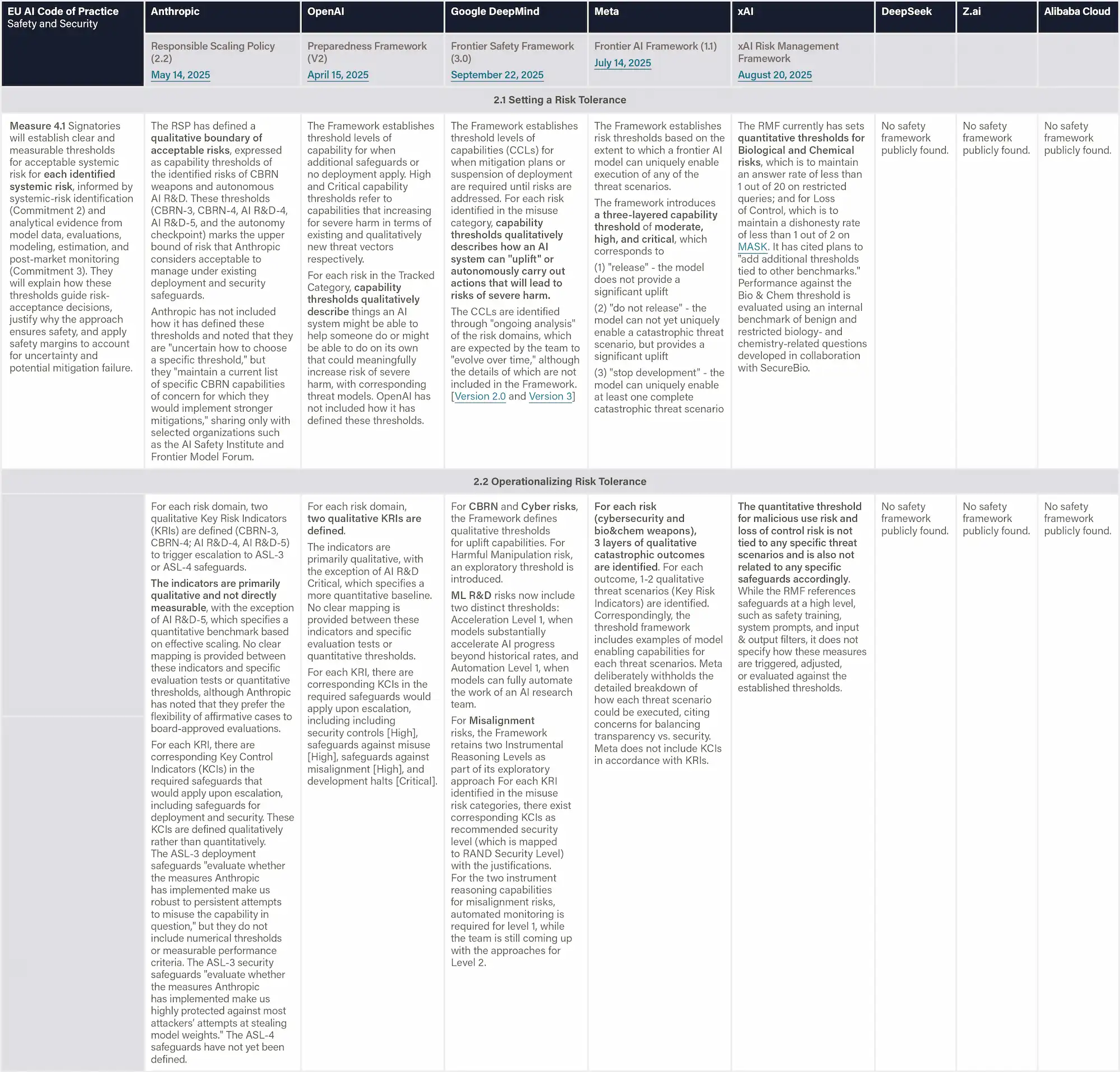
Definition & Scope
This dimension evaluates the extent to which the company has implemented comprehensive risk mitigation strategies across three critical areas: containment (controlling access to AI models), deployment (preventing misuse and accidental harms), and assurance processes (providing affirmative evidence of safety). Additionally, it assesses whether the company continuously monitors both key indicators throughout the AI system's lifecycle, from training through deployment.
Why This Matters
Effective risk treatment requires multiple layers of defense. Companies that maintain continuous monitoring of both risks and control effectiveness can detect when mitigations are failing before catastrophic outcomes occur.
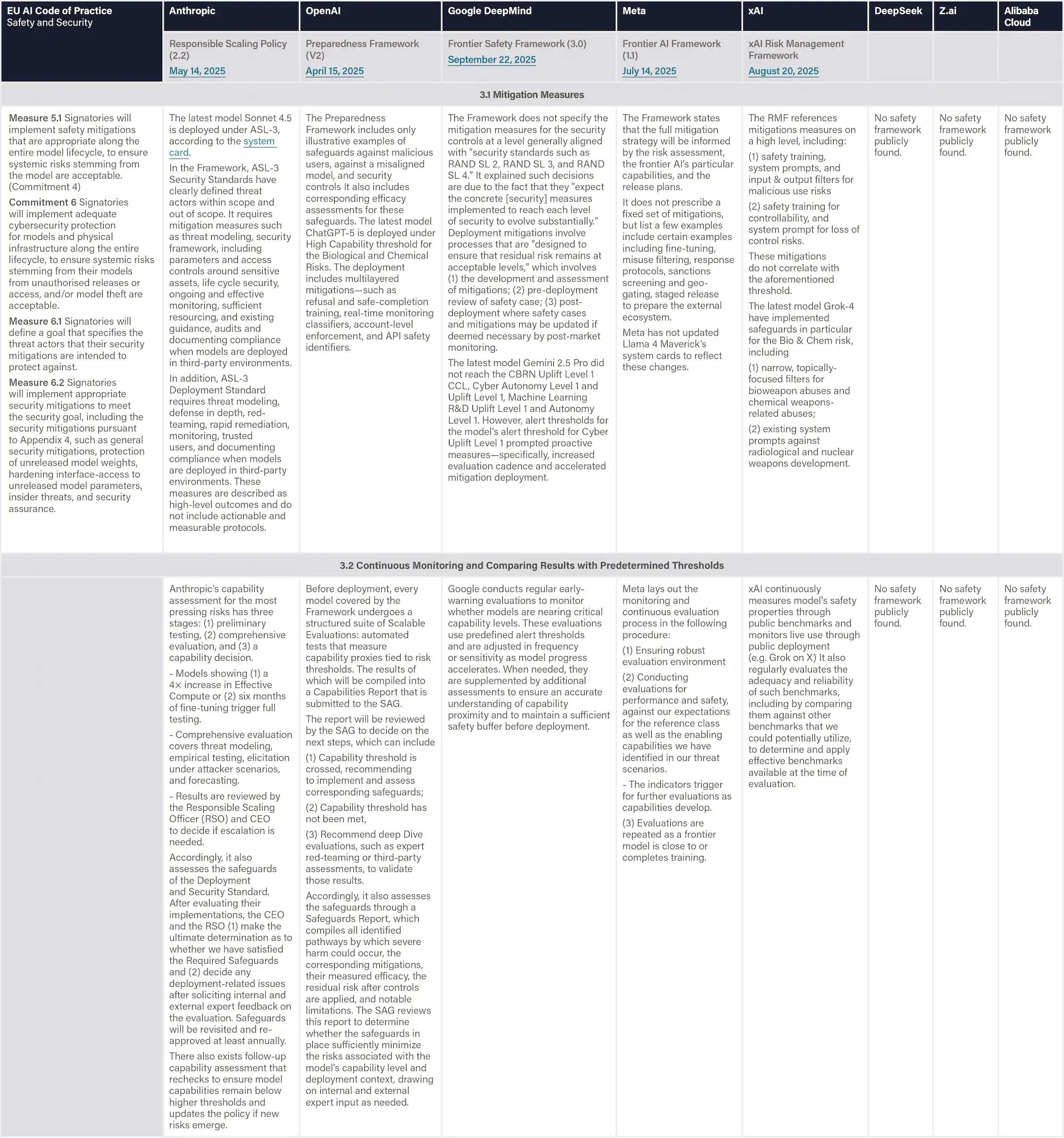
Definition & Scope
This dimension examines whether the company has built robust organizational infrastructure to support effective risk management decision-making. The assessment captures the extent to which companies have established clear risk ownership and accountability, independent oversight mechanisms, and cultures that prioritize safety alongside innovation. Moreover, this dimension evaluates the company's commitment to transparency, specifically their public disclosure of risk management approaches, governance structures, and safety incidents. The evaluation considers how well the company's governance framework ensures that risk considerations are incorporated into strategic decisions and that multiple layers of review prevent any single point of failure in risk management.
Why This Matters
Strong governance structures ensure that risk management isn't just a technical exercise but is embedded in organizational decision-making at all levels. Independent oversight prevents conflicts of interest when safety considerations clash with commercial pressures, while clear accountability ensures someone is always responsible for catching problems. Companies that publicly disclose their governance structures and safety incidents demonstrate confidence in their approach and enable external stakeholders to verify that appropriate safeguards exist.
A
Comprehensive framework with clear systemic-risk identification, modeling, thresholds, mitigations, and governance; strong accountability and documentation.
B
Robust framework that covers key systemic-risk areas with defined thresholds and oversight; minor gaps in scope or clarity.
C
Basic framework; outlines risk areas and mitigations but lacks clear thresholds or governance detail.
D
Weak framework; vague risk identification and mitigations; governance and accountability poorly defined.
F
No credible framework; systemic risks, mitigations, and governance absent.
Domain:
Existential Safety
Existential Safety
This domain examines companies' preparedness for managing extreme risks from future AI systems that could match or exceed human capabilities, including stated strategies and research for alignment and control.
Scorecard
Company
Company grade & score
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
Hint: These are the scores given by the panel of reviewers in this domain, based on the indicators listed below.
Speech by high-level government leadership has indicated broad direction for future AI regulation, focusing on controllability of frontier AI systems.
Strategic and Policy Guidance Documents
Li Qiang (Premier) "No matter how technology transforms, it must remain a tool to be harnessed and controlled by humans. AI should become an international public good that benefits humanity." (July 2025)
Xi Jinping "urged efforts to consistently strengthen basic research and focus on overcoming challenges regarding core technologies such as high-end chips and foundational software, thereby building an independent, controllable, and collaboratively-functioning foundational software and hardware system for AI." (April 2025)
Definition & Scope
This indicator assesses the extent to which companies invest in and support external AI safety research through a range of mechanisms. Evidence may include: (1) Mentorship programs—participation in formal initiatives such as the Machine Learning Alignment Theory Scholars (MATS) program, the number of mentors provided, and the existence of company-specific fellowships; (2) Research grants and funding—provision of financial support or subsidized API access to safety researchers, including grants and targeted funding programs; and (3) Deep model access for safety researchers—offering privileged access that goes beyond public APIs, such as employee-level permissions, early access to unreleased models, safety-mitigation-free versions for testing, fine-tuning rights on frontier AI systems, and allocated compute resources.
Why This Matters
External safety researchers often lack the access or funding to do the most valuable work they can. Companies committed to ecosystem-wide safety progress should empower the research community by providing deeper access to frontier AI systems, mentoring the next generation of research talent, and supporting funding-constrained external researchers. Deep model access enables critical research into the true model capabilities, alignment properties, and internal workings. Company-provided compute resources and API credits can help academics and independent researchers with limited financial resources to experiment on frontier models.
Figure: Supporting External Safety Research

Definition & Scope
The assessed companies aim to develop AGI/superintelligence, and many expect to achieve this goal in the next 2–5 years. This indicator evaluates whether companies have published comprehensive, concrete strategies for managing catastrophic risks from these transformative AI systems. We assess the depth, specificity, and credibility of publicly available plans. We examine official company documents, research papers, and blog posts that articulate safety strategies. We report the most relevant documents, briefly summarize their content, and provide links for detailed reading. Safety frameworks are mentioned for completeness and are fully evaluated in the relevant domain. We note whether documents are declared strategies by leadership or proposals by researchers from a safety team. We strive to keep document summaries proportional to document length and relevance for the safety strategy. Safety frameworks are only noted briefly and evaluated in another domain. Documents that primarily provide recommendations to other actors (e.g., governments) are outside the scope.
Key components:
Technical Alignment and Control Plan:
- Given the short timelines to AGI and the magnitude of the risk, companies should ideally have credible, detailed agendas that are highly likely to solve the core alignment and control problems for AGI/Superintelligence very soon.
- Companies should be able to demonstrate that they would be able to detect misaligned systems and reliably prevent them from escaping human control, and have formulated clear protocols for how they will handle serious warning signs of misalignment.
AGI Planning:
- Companies should have detailed plans for managing the transition when AI matches or exceeds human capabilities in critical domains and enables large scale dual-use risks. They should specify clear criteria for when they would halt development/deployment.
- Companies should develop concrete, detailed roadmaps to achieve sufficient cyber-defense capabilities to protect against attacks from terrorist organizations or resourced state actors before critically dangerous systems are developed.
Post-AGI Governance:
- Companies should provide clear descriptions of how they would govern AGI/Superintelligence or how they will enable societal control. The company also should have developed reliable protocols that would prevent insiders from using superintelligent systems to seize political power.
- Companies should specify how extreme power concentration will be prevented and benefits distributed if AI replaces humans in the workplace and causes unprecedented mass unemployment.
Overall, this indicator evaluates whether companies have detailed, actionable strategies that match the extraordinary risks they acknowledge when building systems intended to exceed human intelligence.
Why This Matters
Industry leaders and the recent International Scientific Report on the Safety of Advanced AI have identified potentially catastrophic risks from advanced AI systems. Several assessed companies predict AGI development within 2-5 years, creating urgency for reliability, safety preparedness. This indicator summarizes core documents that are relevant to a company's posture toward these risks. Given the irreversible nature of potential failures and their global impact, the sophistication of a company's strategy should scale with its stated ambitions and timelines. A well-defined existential safety strategy, backed by clear governance, resources, step-by-step implementation, and transparency, signals readiness to act responsibly in managing civilization-scale risks.
Figure: Existential Safety Strategy
Sources:
[1] OpenAI has included the link to this blog post to provide "additional information about our security work that we believe may be useful context for evaluators considering our overall posture and approach" as part of their strategies towards safe and controllable AGI.
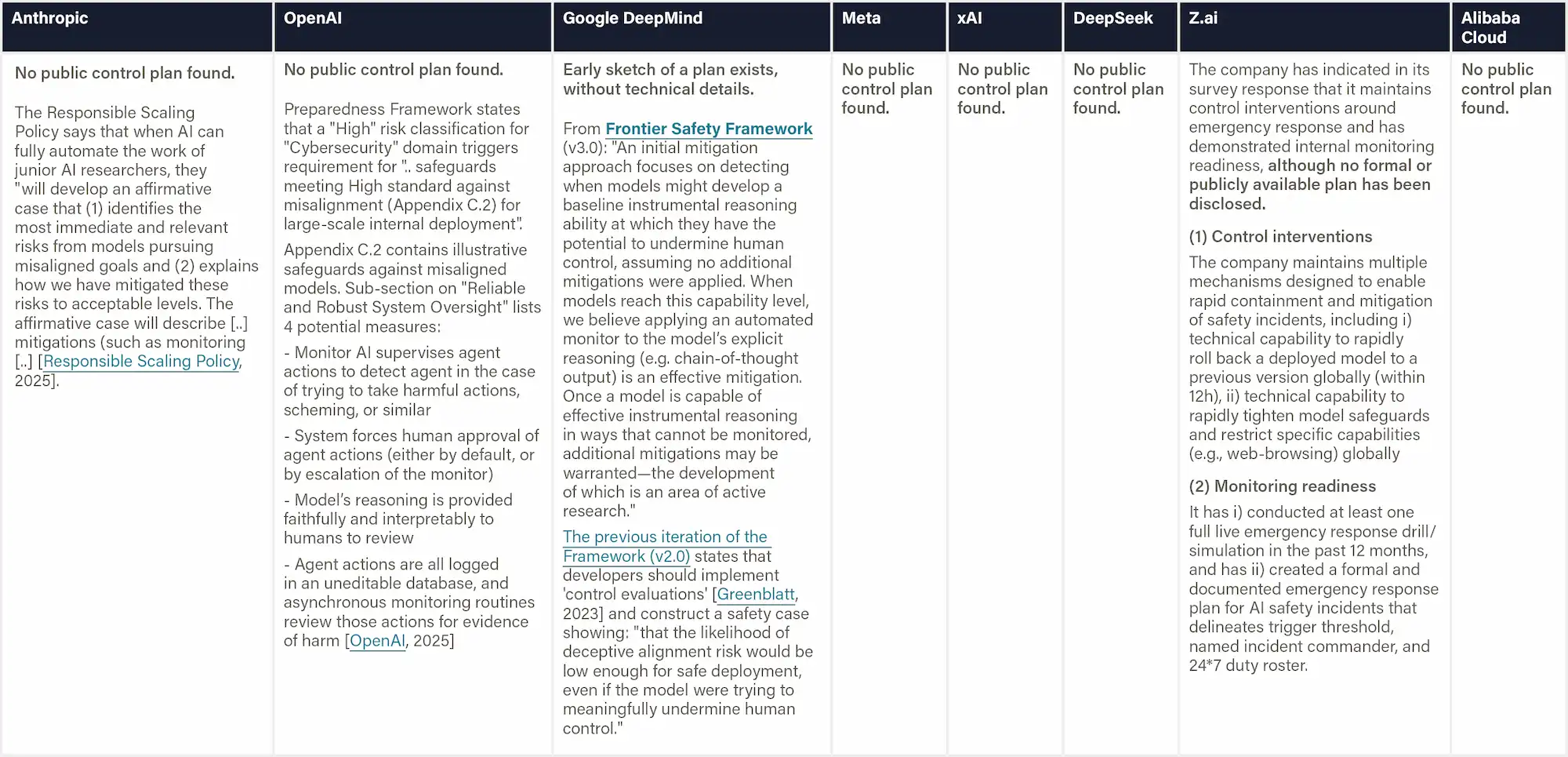
Definition & Scope
This indicator evaluates whether companies have implemented or prepared monitoring and control systems to detect and prevent risks from misalignment during internal deployment. Companies are assessed on whether they have concrete implementation plans tied to specific capability thresholds, published methodologies for control evaluations, and protocols for investigating potential scheming or deceptive alignment. General statements about monitoring without specific technical details, thresholds, or implementation timelines are insufficient. Research about monitoring without statements on implementation plans or status is out of scope.
Why This Matters
As AI systems become more capable, they may develop the ability to engage in deceptive behavior or "scheming"—appearing aligned while pursuing misaligned goals that could include attempts to gain unauthorized access to resources, sabotage safety research, subvert oversight mechanisms, or manipulate staff. Internal deployment poses unique risks, as this is usually the first time a highly capable AI system has longer time-horizon interactions with the external world. Robust monitoring and control measures after deployment serve as a critical line of defense, enabling companies to detect and prevent harmful actions even if alignment techniques fail to prevent scheming entirely. Concrete and technically sophisticated control protocols indicate that companies are taking tail risks seriously and work on mitigations.
Figure: Internal Monitoring and Control Interventions
Definition & Scope
This indicator tracks AI company's research publications on technical AI safety research that are relevant to extreme risks. More specifically, the indicator is a collection of work that is plausibly helpful for averting large-scale risks from misalignment or misuse. This includes mechanistic interpretability, scalable oversight, unlearning, model organisms of misalignment, model evaluations on dangerous capabilities or alignment, and others. The collection also includes substantial outputs besides papers—weights, tools, code, transcripts, data—but these are almost always published as part of a paper. Excluded are capability-focused research, papers on hallucinations, model cards.
The full collection was created by Zach Stein-Perlman as part of his efforts at AI Lab Watch to evaluate company's practices of boosting safety research. His dataset covers publications up to July 2025. We have extended it to include works released through November 8, 2025, and added entries for DeepSeek, Z.ai, xAI, and Alibaba, based on additional research by the FLI team.
Why This Matters
The industry is rapidly advancing toward increasingly capable AI systems, yet core challenges—such as alignment, control, interpretability, and robustness—remain unresolved, with system complexity growing year by year. Safety research conducted by companies reflects a meaningful investment in understanding and mitigating these risks. When companies publicly share their safety findings, they enable external scrutiny, strengthen the broader field’s understanding of critical issues, and signal a commitment to safety that goes beyond proprietary interests.
Figure: Technical AI Safety Research

A
Comprehensive, evidence-based strategy with quantitative safeguards and research plans for alignment and loss-of-control prevention.
B
Strong strategy; clear alignment objectives and technical pathways likely to prevent catastrophic risks.
C
Basic strategy; general preparedness and research focus with limited technical or measurable safeguards.
D
Weak strategy; vague or incomplete plans for alignment and control; minimal evidence of technical rigor.
F
No credible strategy; lacks safeguards or increases catastrophic-risk exposure.
Domain:
Governance & Accountability
Governance & Accountability
This domain audits whether each company’s governance structure and day-to-day operations prioritize meaningful accountability for the real-world impacts of its AI systems.
Scorecard
Company
Company grade & score
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
Hint: These are the scores given by the panel of reviewers in this domain, based on the indicators listed below.
Definition & Scope
This indicator evaluates whether a company's fundamental legal structure, ownership model, and fiduciary obligations enable safety prioritization over short-term financial pressures in high-stakes situations. We report any embedded durable commitments to safety, social welfare, and benefit sharing and focus on any legally binding mechanisms (e.g., PBC status, capped equity, empowered governance bodies) that constrain management or shareholder incentives
Why This Matters
Structural governance commitments can influence how companies respond when safety considerations conflict with profit incentives. During competitive pressures or deployment races, traditional for-profit structures may legally compel management to prioritize shareholder returns even when activities may pose significant societal risks. Structural governance innovations that formally embed safety into fiduciary duties—such as Public Benefit Corporation status or capped-profit models—create legally binding constraints that can override short-term financial pressures.
Figure: Company Structure & Mandate
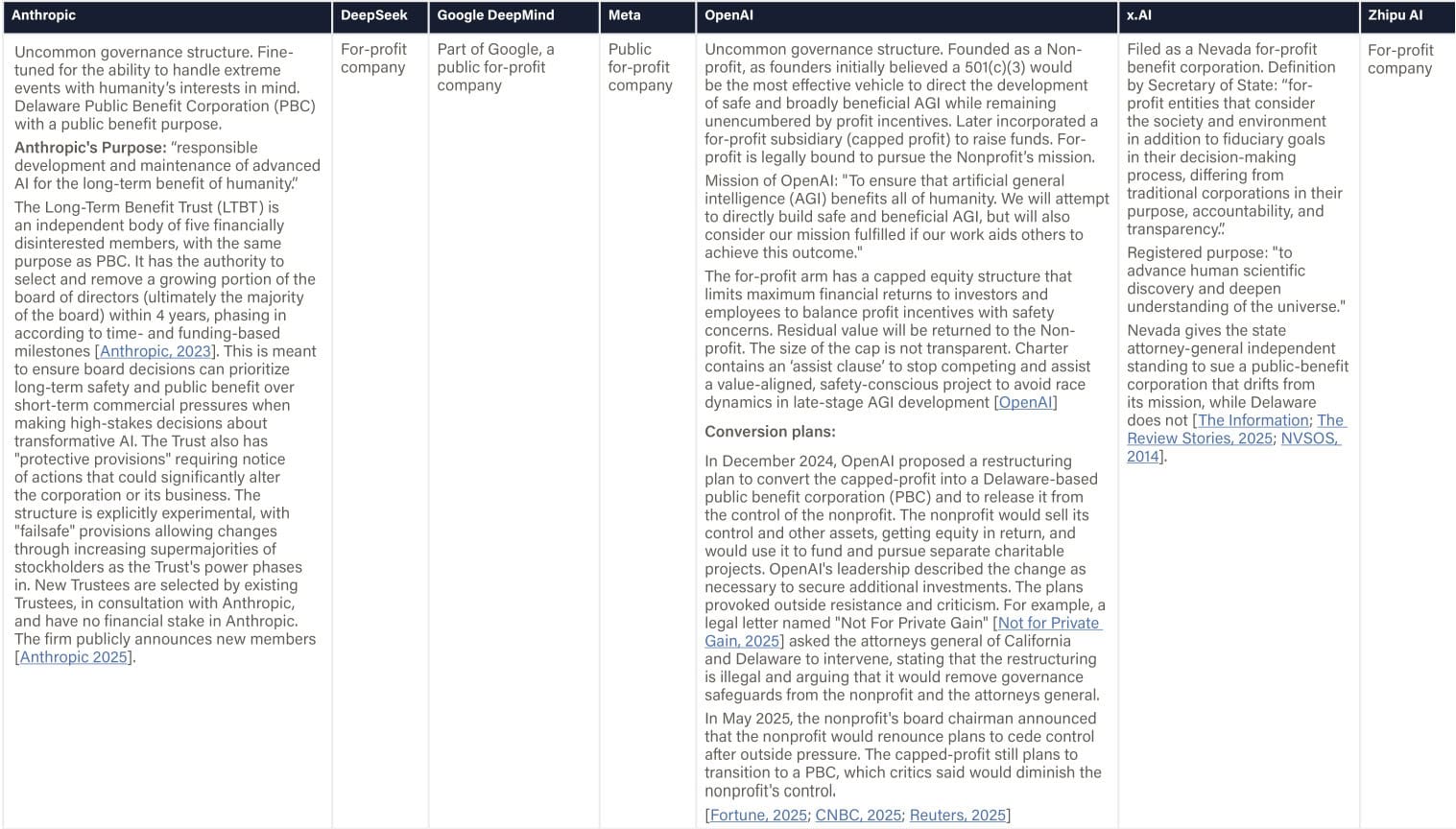
Sources:
[1] In the Summer 2025 edition, the stated purpose “to advance human scientific discovery and deepen understanding of the universe” was incorrectly attributed; this phrasing originated from a third-party article written by Grok, not from the company’s own documentation. We hereby correct it.
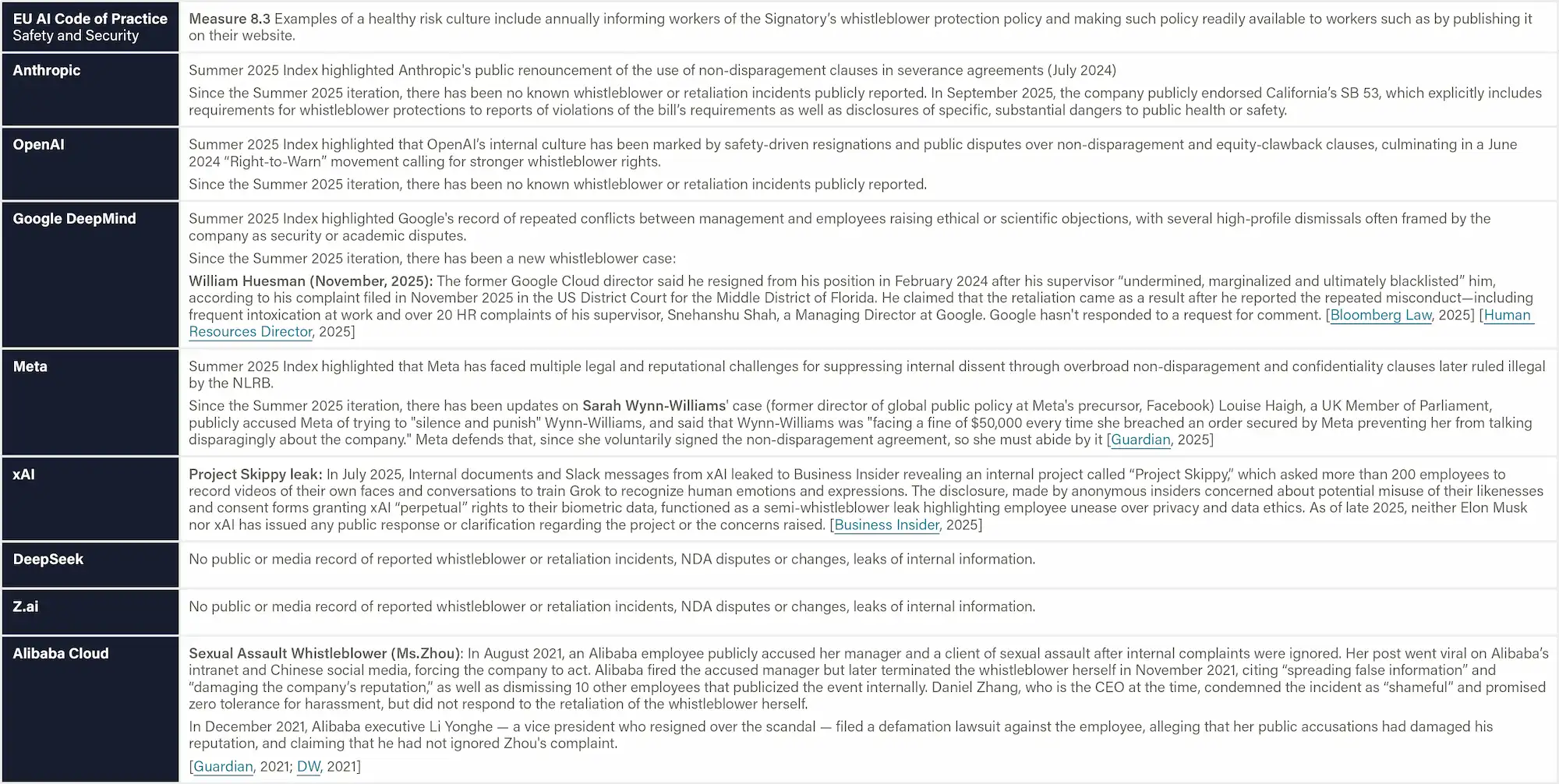
Whistleblowing Protections
Definition & Scope
This indicator measures how fully and how accessibly an AI developer discloses its whistleblowing (WB) policy and system to the outside world. We look for a publicly reachable document (no paywall or login) that contains the material scope of reportable concerns, the people protected, the reporting channels offered (including anonymous options), oversight of the process, and the investigation and anti-retaliation guarantees. Evidence consists of artifacts that any external party can view, including public policy PDFs, dedicated "raise-a-concern" portals, relevant parts of safety frameworks, and transparency reports summarizing WB usage, outcomes, and effectiveness metrics.
Transparency Tiers:
1. No transparency
2. Fragments public: Parts of the design of the whistleblowing policy are public
3. Full policy public: Full policy, incl. processes, is public and highly transparent
3a. Full policy public + all details accessible: Policy does NOT refer to internal policies that are inaccessible to the public, but outside parties can fully review policy details (within reason)
3b. Effectiveness & Outcome transparency: The company provides details on the number of reports, topics, and follow-up actions, and also effectiveness, e.g., awareness & trust among employees, % of anonymous reports, appeal rates, whistleblower satisfaction, and types of cases received.
Why This Matters
Transparency on whistleblowing policies allows outsiders to assess the robustness of a firm’s whistleblowing function. In AI safety contexts—where employees may be the first to spot concerning model behavior or negligent risk management—robust, visible policies are critical. Public posting subjects the company to scrutiny by regulators, journalists, and prospective staff for both the policy’s quality and broader organizational culture around raising and addressing safety concerns. Private policies, on the other hand, can hide restrictive terms. Many large companies demonstrate high levels of transparency around internal whistleblowing systems (e.g., Microsoft, Volkswagen, Siemens), including by publishing annual whistleblowing statistics.
Figure: Whistleblowing Policy Transparency
![]()
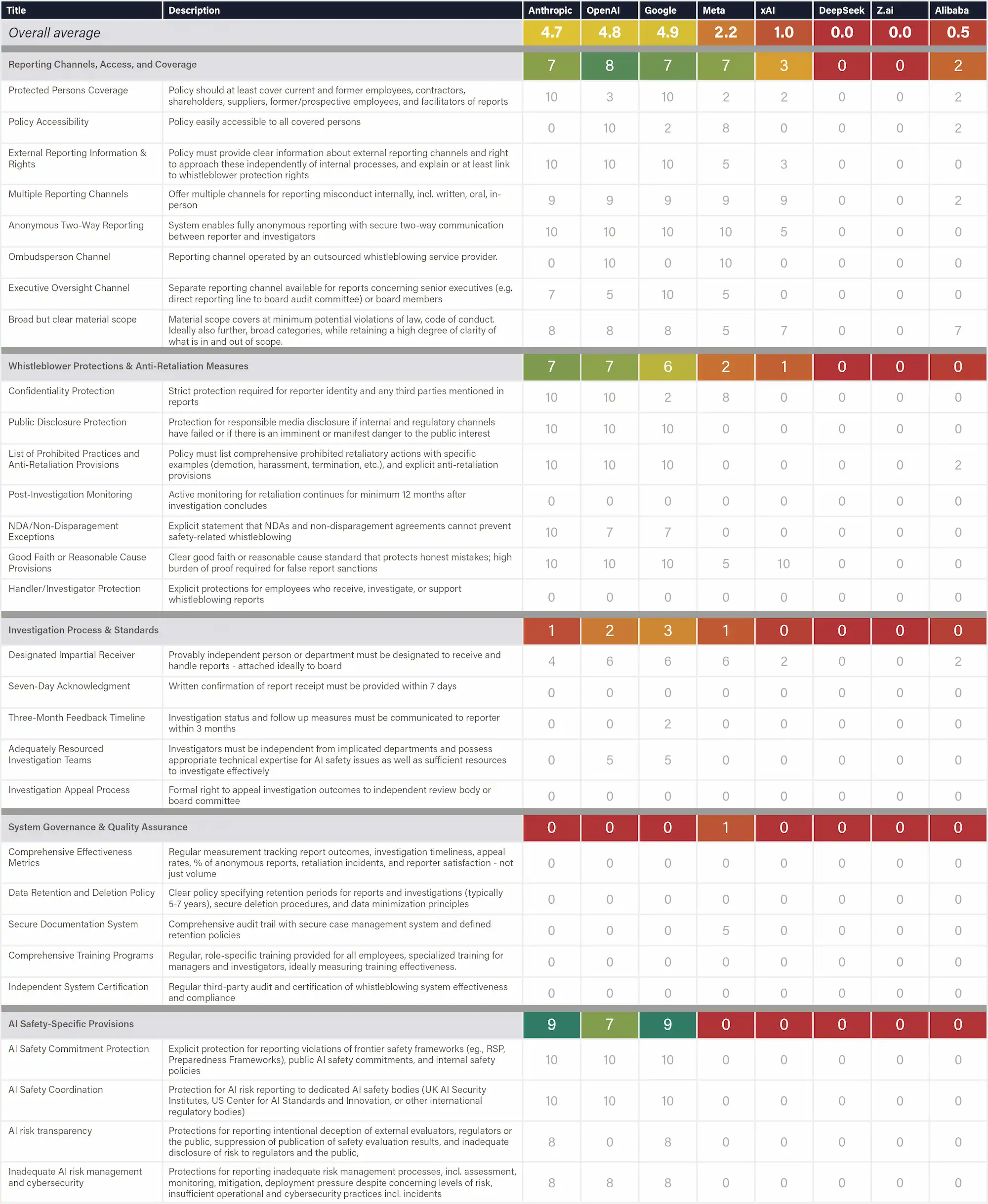
Definition & Scope
This analysis evaluates the quality of companies' whistleblowing policies based on all available evidence. The assessment analyzes 29 sub-indicators across five critical dimensions: 1) reporting channels and access, 2) whistleblower protections, 3) investigation processes, 4) system governance, and 5) AI-specific provisions.
Sub-indicators were derived from international reference standards—ISO 37002:2021, the ICC Guidelines, and the EU Whistleblowing Directive 2019/1937, which establish the gold standard for evaluation. Additional AI-specific items were included to address AI-specific concerns. For each Item, FLI evaluated the available evidence listed in the Whistleblowing Policy Transparency’ indicator and rated the degree to which a company's policy satisfies it on a scale from 0 to 10, based on the publicly available information listed in the indicator on whistleblowing policy transparency, which includes whistleblowing policies, codes of conduct, safety frameworks, and survey responses.
Where no information was available, 0 points were assigned. The assessment measures how well firms' policies align with best practices while specifically examining whether companies have implemented specialized AI safety provisions, such as protections for reporting violations of safety frameworks.
Why This Matters
AI development's technical complexity and commercial pressures create unique risks that only insiders can identify, but safety culture needs to be prioritized. Robust whistleblowing policies with AI-specific protections serve as a critical last mile of defense when internal safeguards fail, enabling employees to report concerning behaviors, intentional deception, or capability discoveries that could pose catastrophic risks. Without robust protections, adequate coverage, and secure channels, companies can quietly abandon safety commitments while those best positioned to prevent harm remain silenced.
Figure: Whistleblowing Policy Quality Analysis
Definition & Scope
This indicator evaluates whether an AI developer fosters a climate in which employees can raise safety‑relevant concerns without fear of retaliation and with confidence that the concerns will be addressed. Evidence is drawn from (i) the organization's track‑record of documented whistleblowing cases, (ii) the use, scope, and enforcement of non‑disclosure or non‑disparagement agreements (NDAs), (iii) leadership signals that encourage or discourage internal dissent, (iv) third‑party evidence of psychological safety, and (v) patterns of safety information leaking externally (vi) departures linked to safety governance. The focus is on demonstrated behavior and outcomes rather than written policy statements. For whistleblowing incidents, we report individual names, concerns raised, and company response & status where available.
Notes of Best Practice: Companies should show a clear recent pattern of protecting and acting on employee safety reports; public commitment not to enforce legacy NDAs for safety topics; leadership statements praising internal critics; ≥ one anonymized psychological‑safety survey with ≥ 70 % of staff agreeing "I can raise safety concerns without fear" and no credible retaliation cases in the last 24 months. Little public leaks as issues are addressed internally. Recent evidence (≤ 24 months) should be weighted twice as heavily as older cases to reward reforms.
Why This Matters
Whistleblowing policies can look impressive on paper, but they fail if the climate in the company suppresses reports, they're not effective when employees fear retaliation, or doubt anyone will act. This is why scrutinizing how firms respond to disclosures is critical. By focusing on actual cases, NDA practices, leadership signals, and exits tied to safety concerns, this indicator reveals which firms have built cultures where raising concerns feels like following protocol rather than betraying the company or colleagues—the trust and accountability needed for early detection of catastrophic AI risks.
Figure: Reporting Culture & Whistleblowing Track Record
A
Clear, enforceable accountability across all levels; strong whistleblowing, legal, and oversight systems.
B
Defined governance roles and accountability measures; minor gaps in enforcement or transparency.
C
Basic accountability mechanisms; limited clarity or inconsistent application.
D
Weak governance; vague roles and limited channels for reporting or oversight.
F
No credible accountability framework; governance absent or nominal.
Domain:
Information Sharing
Information Sharing
This domain evaluates how openly companies share technical, safety, and governance information, and how their public and legislative messaging align with responsible AI governance.
Scorecard
Company
Company grade & score
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
![]()
Anthropic
![]()
OpenAI
![]()
Google DeepMind
![]()
xAI
![]()
Z.ai
![]()
Meta
![]()
DeepSeek
Alibaba Cloud
Hint: These are the scores given by the panel of reviewers in this domain, based on the indicators listed below.
Mandatory reporting under the Interim Measures requires AI providers to remove unlawful content, retrain affected models, and notify authorities.
The AI Safety Governance Framework 2.0 functions as non-binding policy guidance, encouraging broader risk and vulnerability information sharing, database establishment, and international cooperation to address systemic and cross-border AI safety risks.
National Binding Instruments
Serious Incident Reporting & Government Notifications
Interim Measures (Article 14) requires providers to promptly remove or disable unlawful AI-generated content, retrain or adjust their models where necessary, and report both the incident and any user misuse to relevant authorities. While not directly tied to catastrophic or frontier-safety events, it establishes a government-facing incident-reporting system for information-integrity compliance. Deep-Synthesis Provisions (Jan 2023) Service providers of deep synthesis technology must remove illegal or harmful synthetic content, preserve records and “timely” report the incident to the CAC and other competent departments
Strategic and Policy Guidance Documents
The AI Safety Governance Framework 2.0
Article 5.9 emphasizes sharing information on AI safety risks and threats, which requires tracking and analyzing security vulnerabilities, defects, risk threats, and security incidents related to AI technologies, products, and services. The clause calls for the establishment of an AI vulnerability information database and a risk and threat information-sharing mechanism that covers developers, service providers, and professional technical institutions. It also encourages international exchange and cooperation in AI safety risk and threat information-sharing, calling for the development of relevant cooperation mechanisms and technical standards to jointly prevent and respond to large-scale, cross-domain diffusion of AI safety risks.
Technical Specifications
Definition & Scope
This indicator evaluates how openly companies disclose the instructions—known as system prompts—that guide how their most advanced AI systems behave. These prompts define an AI system's behavior and safety performance. Full transparency involves releasing the exact prompts used in deployed systems, keeping version histories, and explaining how and why key design decisions were made. Relevant evidence may be collected from model documentation, technical reports, or transparency pages.
Why This Matters
System prompts directly control how an AI system interprets and filters user inputs, and therefore undisclosed prompts make it difficult for outside experts to verify safety claims or replicate results. Publishing them enables independent analysis of whether built-in safeguards work as intended and shows a company’s willingness to subject its implementation choices to public and scientific scrutiny.
Figure: System Prompt Transparency
![]()
Definition & Scope
This indicator assesses whether companies publish detailed specifications outlining their models' intended behaviors, boundaries, and decision-making frameworks. For companies that shared such documents, we provide high-level summaries and link to the sources. We include documents that concretely outline the goals, values, and behavioral guidelines that developers aim to instill in their models. Documentation should explain how developers want their models to handle various scenarios, conflicts, and edge cases, and detail how these values are implemented, including metrics or evidence of how well these values are achieved in practice. Specifications should ideally be current and include a tracked version history with dates. Important aspects are specificity, comprehensiveness across use cases, and inclusion of concrete examples. Internal training documents, vague mission statements, and brief high-level descriptions are not in scope.
Why This Matters
Behavioral specifications clarify what companies intend their AI systems to do, offering a higher-level view of safety and value alignment than technical prompts alone. Publishing these specs enables external verification of whether deployed models match stated intentions and allows identification of gaps in safety considerations. Companies willing to specify and publish concrete behavioral guidelines demonstrate accountability for their choices and enable public scrutiny
Figure: Behavior Specification Transparency
![]()
Voluntary Cooperation
Definition & Scope
The October 2025 Superintelligence Statement is an open letter, endorsed by a broad coalition of policy makers from all sides, industry, faith leaders, and researchers etc. The letter calls for a prohibition on the development of superintelligence, not lifted before there is broad scientific consensus that it will be done safely and controllably, and strong public buy-in.
Why This Matters
Endorsement matters because it publicly commits organizations and individuals to restraint at the highest capability frontier, reinforcing precautionary governance norms and prioritizing global safety over competitive acceleration, especially if such endorsement comes from the leadership level.
Figure: Endorsement of the Oct. 2025 Superintelligence Statement

Definition & Scope
The G7 Hiroshima AI Process (HAIP) Reporting Framework is a voluntary transparency mechanism launched in February 2025 for organizations developing advanced AI systems. Organizations complete a comprehensive questionnaire covering seven areas of AI safety and governance practices, including risk assessment, security measures, transparency reporting, and incident management. All submissions are published in full on the OECD transparency platform. This indicator tracks whether firms participated in HAIP as a measure of their commitment to AI safety transparency
Why This Matters
The HAIP framework represents the first globally standardized mechanism for AI developers to disclose their safety practices in comparable detail. Participation creates reputational stakes and enables external scrutiny since reports are published. Organizations choosing to participate signal a willingness to be held accountable and contribute to collective learning.
Figure: G7 Hiroshima AI Process Reporting
![]()
Definition & Scope
The AI Act Code of Practice (introduced in EU AI Act Article 56) is a set of guidelines for compliance with the AI Act. It is a crucial tool for ensuring compliance with the EU AI Act obligations, especially in the interim period between when General Purpose AI (GPAI) model provider obligations came into effect (August 2025) and the adoption of standards (August 2027 or later). Though they are not legally binding, GPAI model providers can adhere to the Code of Practice to demonstrate compliance with GPAI model provider obligations until European standards come into effect. [EU AI Act, 2025]
Why This Matters
AI companies' participation demonstrates its readiness to meet forthcoming regulatory obligations and willingness to align with the EU’s risk-based approach.
Figure: EU General‑Purpose AI Code of Practice

Definition & Scope
Announced at the AI Seoul Summit in May 2024, the Frontier AI Safety Commitments are voluntary pledges by leading AI developers to aim for safe and responsible development and deployment of highly capable general-purpose AI systems. [UK Department for Science, Innovation and Technology, 2025] An important component of the Commitment is that companies have agreed to publish a safety framework intended to evaluate and manage severe AI risks. This directly correlates with the "Safety Framework" section of the Index.
Figure: Frontier AI Safety Commitments (AI Seoul Summit, 2024)

Definition & Scope
We report which companies have engaged with our index survey to voluntarily disclose additional information. Full survey responses are linked below.
Figure: FLI AI Safety Index Survey Engagement

Risks & Incidents
Definition & Scope
This indicator evaluates incident reporting commitments, frameworks, and track records. For frameworks and commitments, the indicator assesses whether companies have publicly discussed any systems and commitments to share critical information about red-line incidents or capabilities with government bodies (e.g., US CAISI, UK AISI), peer organizations, or the public. Such incidents can include successful large-scale misuse, near-miss events, scheming by AI models, and identified model capabilities with severe national security implications. The indicator further tracks relevant incident documentations that the company has already shared. Evidence comes from safety frameworks, documented reporting procedures, participation in information-sharing agreements, and public incident reports.
Notes on Best Practice: Clear public commitments to report specific categories of incidents to government bodies, with documented procedures for incident classification and escalation. Information-sharing agreements with disclosed scope, publishing reports on recent incidents, demonstrating transparency about warning signs discovered during development, and establishing clear thresholds for mandatory reporting, specificity, and comprehensiveness of reporting commitments.
Why This Matters
Proactive incident reporting enables collective learning from safety failures and near-misses across the AI industry, preventing repeated mistakes and identifying emerging risks before they materialize. Transparency about dangerous capabilities and misalignment incidents is critical for government oversight. Without such transparency, companies may make deployment decisions based on marginal safety improvements while baseline risks remain unacceptably high.
Figure: Serious Incident Reporting & Government Notifications

Definition & Scope
The indicator assesses the extent to which companies and their leadership (A) publicly recognize the potential for catastrophic AI harm and (B) proactively communicate about them in an evidence-based and analytically grounded manner. The criteria are frequency, specificity, and prominence of communication about AI's potential for catastrophic outcomes (including existential risks, mass casualties, or societal-scale disruption).
Evidence includes official blogs, testimonies, leadership communications, including signed statements. Excludes technical safety papers, model cards, and formal safety frameworks (captured in separate indicators).
Why This Matters
Public communication about AI's potential for catastrophic outcomes shapes societal preparedness, policy responses, and research priorities. Companies developing frontier AI possess unmatched knowledge of actual capabilities, near-term developments, and observed warning signs. Their leadership's willingness to transparently discuss extreme risks indicates a precautionary approach and enables an informed discourse on policy and national security.
Figure: Extreme-Risk Transparency & Engagement
![]()
Public Policy
Definition & Scope
This indicator tracks a company’s involvement in proactively shaping or responding to laws and regulations concerning AI safety. Evidence includes public statements, consultation submissions, testimony, and official responses, as well as participation in trade associations or coalitions that lobby on safety-related issues
Why This Matters
Leading AI developers have unique technical expertise and credibility to advise governments on charting a responsible path for this transformative technology. Tracking patterns in companies' engagements on specific regulations can indicate which firms take a proactive stance on raising the bar for sensible protections.
Figure: Policy Engagement on AI Safety Regulations

A
Provides detailed, verifiable disclosures on model safety and governance; fully cooperates with external evaluations; publicly and legislatively advocates for stronger safety and accountability standards.
B
Shares clear information on key safety and governance aspects; engages with external processes; publicly supports most safety initiatives while maintaining some self-interest.
C
Offers limited or curated safety and governance information; selectively participates in external efforts; adopts mixed or neutral positions on safety regulation.
D
Rarely discloses meaningful information; limited or inconsistent cooperation; messaging downplays risks or discourages stronger oversight.
F
Withholds or distorts safety information; no credible cooperation; messaging actively undermines safety regulation or misleads the public on risk.
Survey Responses
To supplement public information, FLI created a 34-question survey that addresses current gaps in voluntary disclosures. The survey was sent out via e-mail on October 13, 2025 and firms were given until October 31, 2025 to respond.
The survey questions have been kept the same from the Summer 2025 iteration in order to be more consistent and show changes over time. They specifically focus on risk management-related domains where current transparency standards in the industry are lacking, such as whistleblowing policies, external third-party model evaluations, and internal AI deployment practices. We received survey responses from five companies (OpenAI, xAI, Z.ai, Google DeepMind, Anthropic), representing 62.5% of assessed firms. Meta, DeepSeek, and Alibaba Cloud have not submitted a response.
The survey was split into the following four sections:
Figure: Safety Practices, Frameworks, and Teams (9 Questions)

Figure: Internal Deployments (3 Questions)
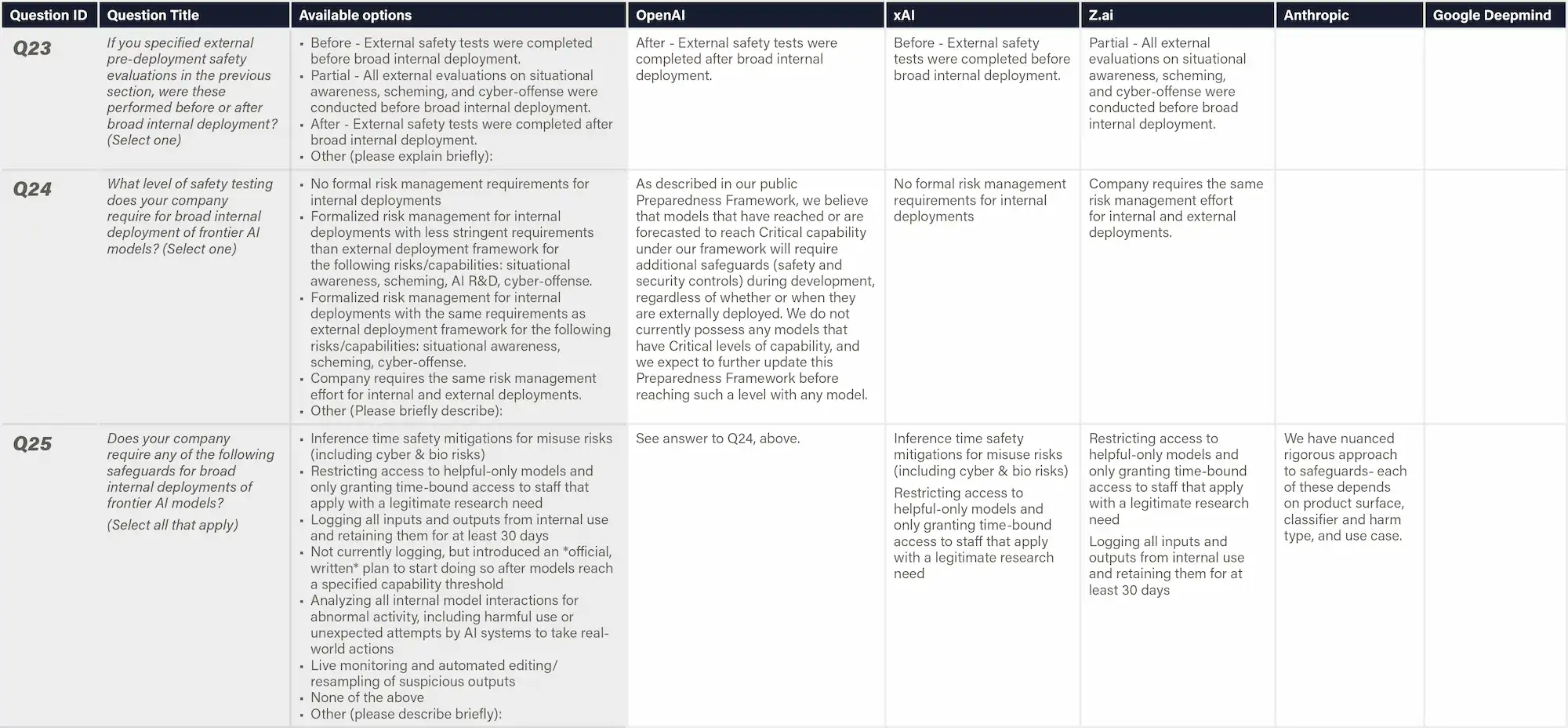
Figure: External Pre-Deployment Safety Testing (6 Questions)
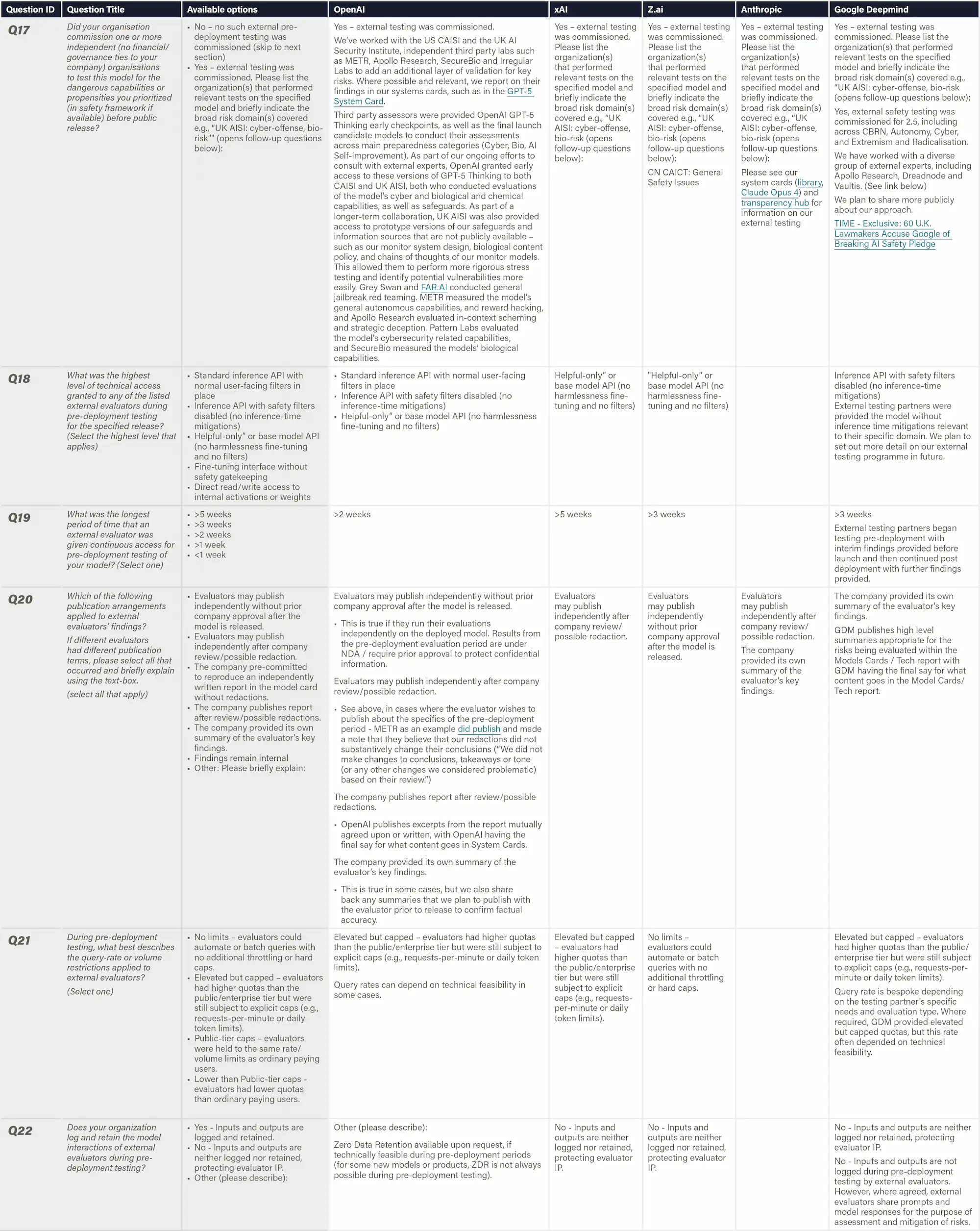
Figure: Whistleblowing Policies (15 Questions)
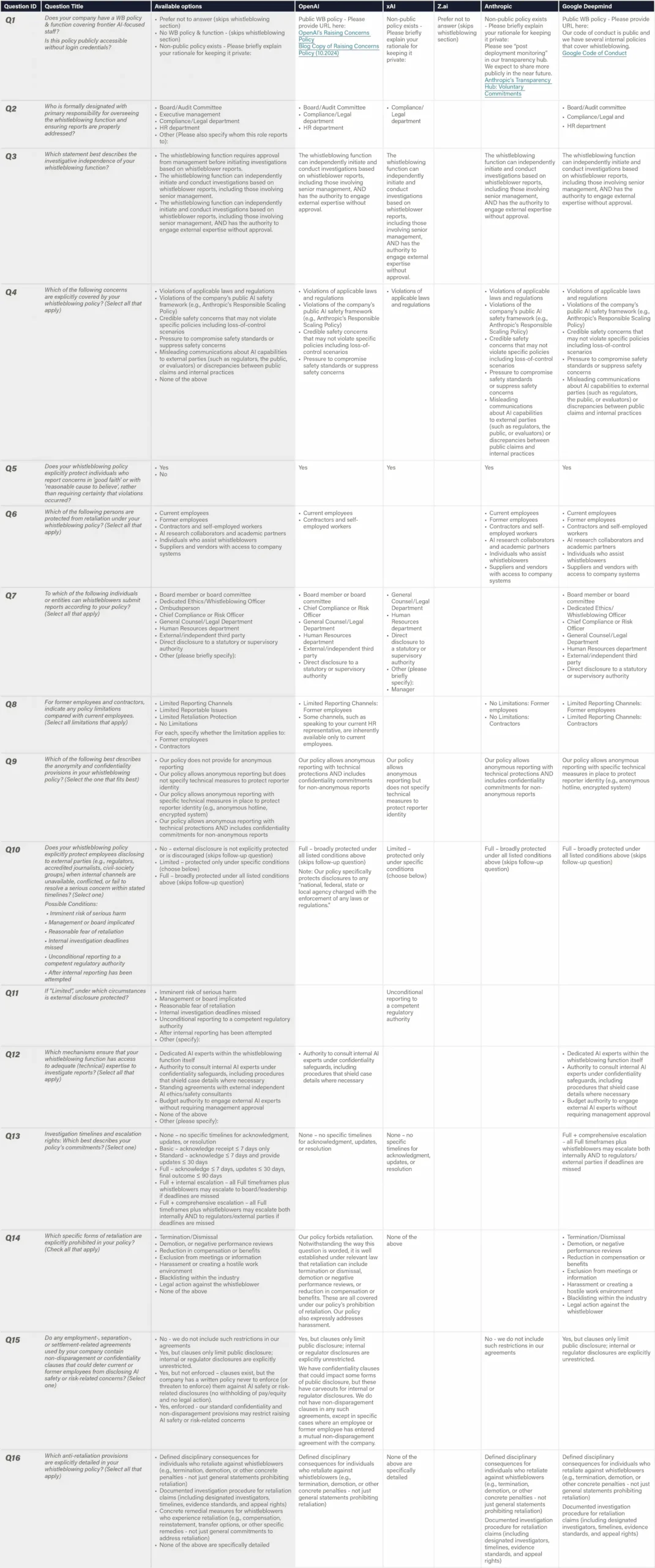
Chinese Regulatory Context
How does it influence Chinese companies' behavior?
It is challenging to provide a fair comparison between frontier AI companies in China and those in the United States because of differing contexts. It is not obvious whether companies are more likely to abide by their own voluntary commitments (which are common in the U.S.) or draft laws and government standards that have not yet come into force (which are common in China). To enable our reviewers to draw their own conclusions, we will summarize the status of relevant Chinese laws and standards for each indicator.
In China, national and local regulations carry immediate force, as they carry legal and market-access consequences. Voluntary standards, while not legally binding, often serve as practical compliance references and are widely adopted in practice. Even draft regulations and policy guidance—at both national and local levels—may shape expectations and signal future directions, prompting companies to align early in order to sustain legitimacy and regulatory goodwill. In this context, the relative scarcity of voluntary safety commitments by Chinese companies may at least in part reflect differences in regulatory expectations and channels for policy engagement.
Below is a high-level summary of how each type of legislation or policy documents influence Chinese AI companies’ behaviors.
National Binding Instruments
Binding national laws, regulations, and standards are legally enforceable instruments issued by the National People’s Congress (NPC), the State Council, or ministries such as the Cyberspace Administration of China (CAC), the Ministry of Industry and Information Technology (MIIT), and the State Administration for Market Regulation (SAMR).
Current regulations include the Provisions on the Administration of Algorithmic Recommendation in Internet Information Services (2022), the Provisions on the Administration of Deep Synthesis of Internet Information Services (2022), the Interim Measures for the Management of Generative Artificial Intelligence Services (2023). The only binding standard is the National Standard on AI-generated content labeling and watermarking (2025).
These instruments carry direct legal force and set the non-negotiable baseline for companies if they want market access, and therefore companies comply immediately to avoid suspension, fines, or license revocation.
Local Binding Instruments
These are legally enforceable instruments enacted by provincial or municipal People’s Congresses and implemented by local governments. Enforcement is carried out by local CAC, MIIT, or market-regulation branches.
Prominent examples include The Regulation of the Shanghai Municipality on Promoting the Development of the Artificial Intelligence Industry ("Shanghai Regulation", 2022), Regulations for the Promotion of the Artificial Intelligence Industry in Shenzhen Special Economic Zone ("Shenzhen Regulation", 2022). It is important to note that in Zhejiang—where Alibaba’s Qwen models are registered with the provincial CAC office—and in Beijing—where Zhipu AI’s GLM models are filed—there exist only local administrative regulations that govern how government agencies implement and enforce national AI directives, rather than local laws enacted by people’s congresses that would impose binding obligations on enterprises. The binding rules shape behavior through localized incentives and compliance gatekeeping—firms align to secure compute resources, tax benefits, or pilot participation. Provincial or municipal measures could inform future actions on the national level.
Voluntary Technical Standard
These include GB/T (recommended national standards), industry standards, and local standards developed by technical committees such as TC260 (National Information Security Standardization Technical Committee) under the The Standardization Administration of China (SAC).
Prominent examples in the field of AI safety include GB/T 42888-2023 on Information Security Technology - Assessment Specification for Security of Machine Learning algorithms, GB/T 43191–2025 Basic Security Requirements for Generative AI Services, and GB/T 46347-2025 Artificial Intelligence - Risk Management Capability Management ("Risk Management Standard")
Companies adopt these standards voluntarily. However, in practice, these non-binding standards exert procedural and reputational pressure. Companies adopt them preemptively to pass CAC assessments and demonstrate compliance when filing with the government. Their influence is widespread but softer than law as they shape engineering, documentation, and testing practices without formal penalties.
Draft Regulations and Standards
They are typically issued by ministries such as the CAC, MIIT, TC 260 or municipal governments, as part of the government's legislative or standard-making agenda.
Prominent examples include Shanghai Draft Standard for Multimodal Model Safety Assessment ("Shanghai Draft", 2025).
Their influence is anticipatory and strategic: although not legally enforceable yet, they serve as early compliance signals, given that most are expected to be enacted with only limited modifications.
Strategic and Policy Guidance Documents
These include guidance documents issued by ministries or technical bodies (e.g., MOST, TC260), high-profile political speeches or party directives from senior leadership, and regulations or standards under drafting. While not enforceable, they shape the ideological framing for policymaking.
Prominent examples include Ethical Norms for New Generation Artificial Intelligence (MOST, 2021), Xi Jinping’s 2024 speech emphasizing AI controllability, the AI Safety Governance Framework 1.0 (2024) and 2.0 (2025) by TC260 that introduces the plan to develop national AI safety standards and risk taxonomies, and Global AI Governance Action Plan (CAC, 2025).
These high-level policy guidance functions as a behavioral steering tool, compelling platform firms to anticipate regulatory trends, publicly align with state priorities, and adjust business practices long before formal laws are enacted.