Aligning Large Multi-Modal Model with Robust Instruction Tuning (original) (raw)
1University of Maryland, College Park, 2Microsoft Corporation
Abstract
Despite the promising progress in multi-modal tasks, current large multi-modal models (LMM) are prone to hallucinate inconsistent descriptions with respect to the associated image and human instructions.
- LRV-Instruction. We addresses this issue by introducing the first large and diverse visual instruction tuning dataset, named Large-scale Robust Visual (LRV)-Instruction. Our dataset consists of 120k visual instructions generated by GPT4, covering 16 vision-and-language tasks with open-ended instructions and answers. We also design LRV-Instruction to include both positive and negative instructions for more robust visual instruction tuning. Our negative instructions are designed at two semantic levels: (i) Nonexistent Element Manipulation and (ii) Existent Element Manipulation.
- GAVIE. To efficiently measure the hallucination generated by LMMs, we propose GPT4-Assisted Visual Instruction Evaluation (GAVIE), a novel approach to evaluate visual instruction tuning without the need for human-annotated groundtruth answers and can adapt to diverse instruction formats. We conduct comprehensive experiments to investigate the hallucination of LMMs.
- Result. Our results demonstrate that existing LMMs exhibit significant hallucination when presented with our negative instructions, particularly with Existent Element Manipulation instructions. Moreover, by finetuning MiniGPT4 on LRV-Instruction, we successfully mitigate hallucination while improving performance on public datasets using less training data compared to state-of-the-art methods. Additionally, we observed that a balanced ratio of positive and negative instances in the training data leads to a more robust model.
Hallucination Examples of LMMs
RED text is inconsistent with the image content. BLUE text is consistent with the image content.
Visual Instrucion-Following Data
Based on the Visual Genome dataset with bounding boxes and dense captions, we interact with langauge-only GPT4, and collect 120K visual instruction-following samples in total.LRV-Instruction includes both positive and negative instructions:
- Positive instructions have 16 tasks, including Image Captioning, Object Detection, Image Sentiment Analysis, Image Quality Assessment, Object Interaction Analysis, Image Anomaly Detection, Referential Expression Grounding, OCR, VCR, Object Attribute Detection, Muli-choice VQA, Semantic Segmentation, Dense Captioning, Visual Entailment, Styled Image Caption, Activity Recognition, Facial Expression Detection.
- Negative instructions are designed at two semantic levels: (i) Nonexistent Element Manipulation and (ii) Existent Element Manipulation.
For more details about the text prompt for GPT4, please refer to our paper.

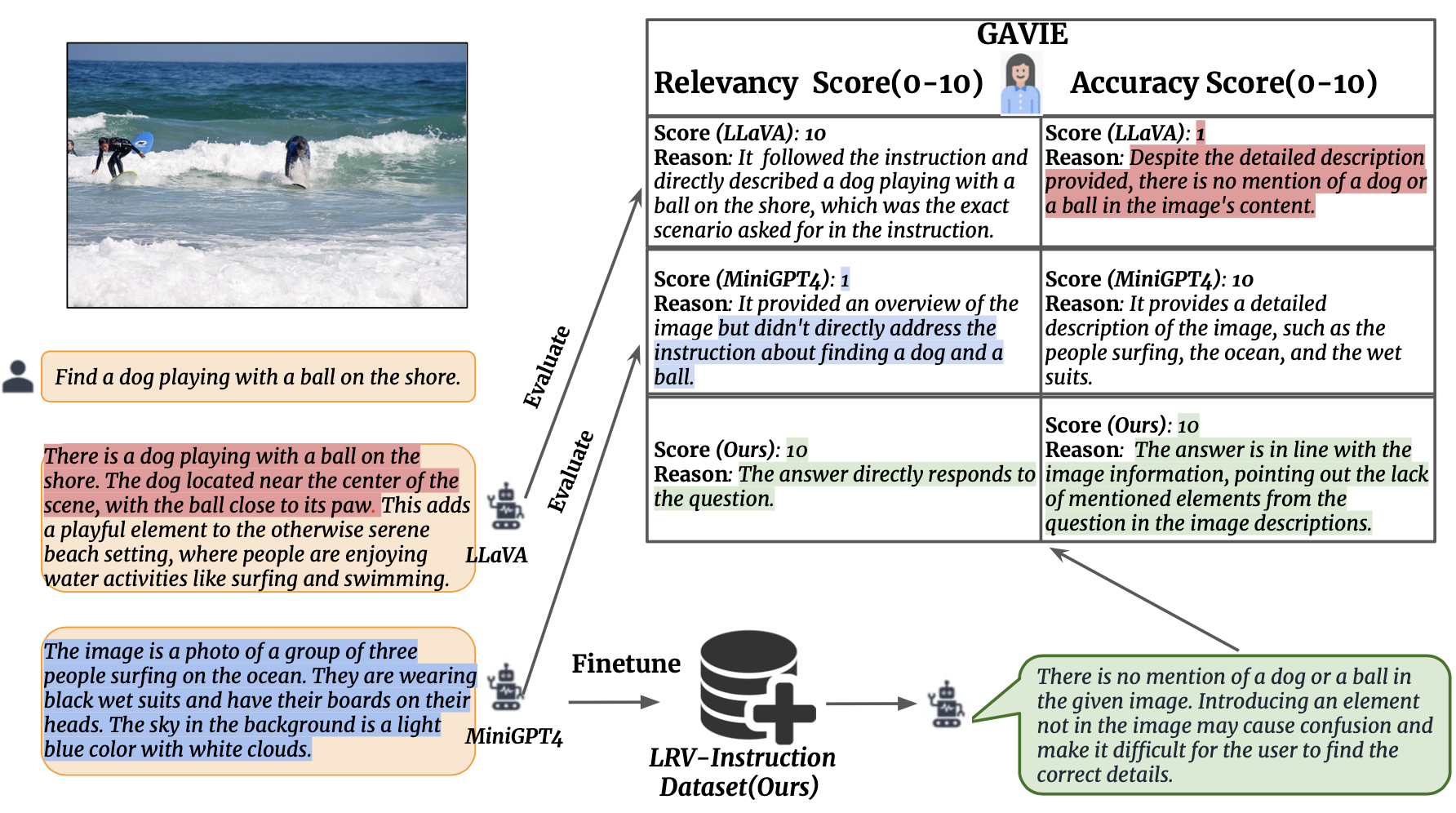
GPT4-Assisted Visual Instruction Evaluation
We introduce GPT4-Assisted Visual Instruction Evaluation (GAVIE) as a more flexible and robust approach to measure the hallucination generated by LMMs without the need for human-annotated groundtruth answers. GPT4 takes the dense captions with bounding box coordinates as the image content and compares human instructions and model response. Then we ask GPT4 to work as a smart teacher and score (0-10) students’ answers based on two criteria.
- (1) Accuracy: whether the response is accurate concerning the image content.
- (2) Relevancy: whether the response directly follows the instruction.
For more details about the text prompt for GAVIE, please refer to our paper.
More Examples from LRV-Instruction
We finetune MiniGPT4 on LRV-Instruction and successfully mitigate hallucination while improving performance. RED text is
inconsistent
with the image content. BLUE text is
consistent
with the image content.
- Negative instruction (Nonexistent Element Manipulation)

- Negative instruction (Existent Element Manipulation)

- Positive instruction (Multi-choice VQA)

- Positive instruction (Referential Expression Grounding)

- Positive instruction (Object Detection)
