original ) (raw )
本项目主要面向第 1414 14 A16A16 A 16 2D2D 2 D VITONVITON V I TON DNNDNN D NN PFAFNPFAFN PF A FN OpenVINOOpenVINO Op e nV I NO
开发平台
版本
开发工具
版本
Pycharm
2022.3.2
Visual Studio Code
1.80.1
Visual Studio
17.5.5
开发环境
版本
开发环境
版本
neural-compressor
2.2.1
nncf
2.5.0
numpy
1.23.4
onnx
1.14.0
opencv-python
4.7.0.72
onnxruntime
1.15.1
openvino
2022.3.0
pandas
1.3.5
pytorch-fid
0.3.0
rembg
2.0.50
pytorch
2.0.0
torch-pruning
1.1.9
intel-openmp
2021.4.0
git clone https://github.com/LZHMS/Virtual-Tryon.git
pip install -r requirements.txt
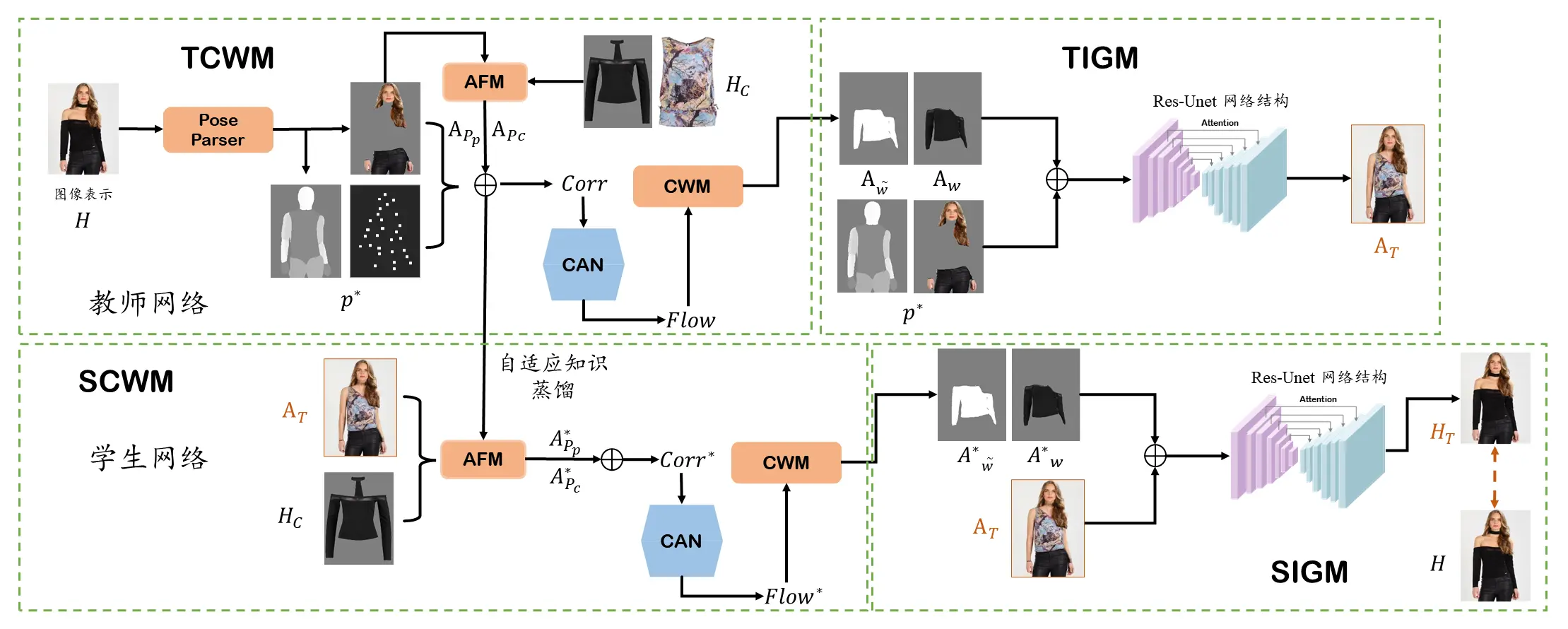
本项目主要分为模型训练和工程化落地两部分,因此仓库创建了两个分支 main 和 PruingQuantization。
main 分支是模型的推理部分,其中包括原始 Pytorch 模型、ONNX 模型、剪枝后模型、量化后模型的推理;
Img2Col模块用来对 corr_pure_torch模块做推理加速,模型训练中采用 corr_pure_torch模块而在推理阶段采用 Img2Col模块; afwmafwm a f w m networksnetworks n e tw or k s PFAFNPFAFN PF A FN
PruningQuantization 分支是模型工程化落地部分,其中还包括模型训练部分和模型剪枝量化;
ModelTraining 是 PFAFNPFAFN PF A FN ModelPruningQuantization 是本项目主要的工程化落地部分,模型剪枝主要针对于 WarpWarp Wa r p NerualCompressorNerual\ Compressor N er u a l C o m p ressor
本项目基于 PFAFNPFAFN PF A FN
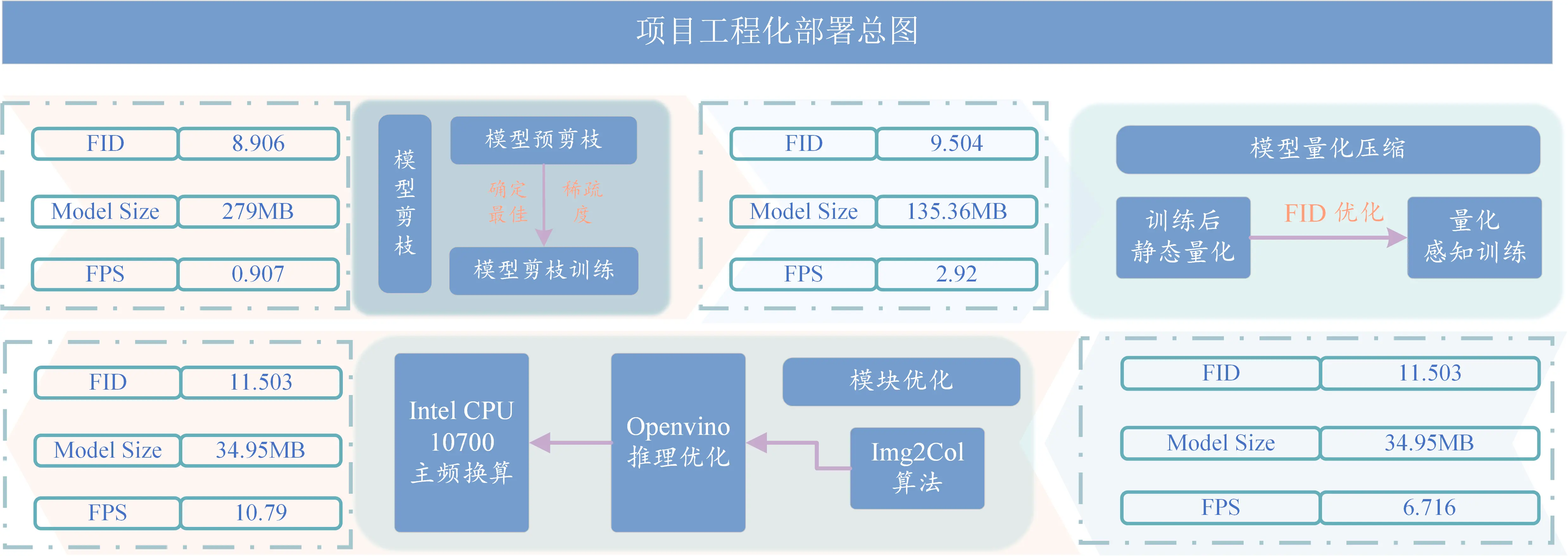
为了满足赛题方的要求,本项目开展了工程化落地部分,主要分为两个部分,模型训练和模型剪枝量化。项目工程化部署总图如下所示:
Metrics
GFLOPs
Para(M)
SIZE(MB)
Total SIZE(MB)
Compresion Ratio
FID
FID Loss
Original Module
6.63
9.37
35.8
112.0
100.00%
8.906
0.00%
Ratio=0.2 with FineTuning
5.23
7.28
27.6
88.69
79.19%
9.013
1.20%
Ratio=0.3 with FineTuning
4.40
6.48
24.8
65.73
58.69%
9.113
2.32%
Ratio=0.4 with FineTuning
3.79
5.61
20.4
40.97
36.58%
9.304
4.47%
Ratio=0.5 with FineTuning
3.42
4.55
16.8
35.47
31.67%
9.977
12.03%
Metrics
GFLOPs
Para(M)
SIZE(MB)
Total SIZE(MB)
Compresion Ratio
FID
FID Loss
Original Module
21.93
43.90
167
167
100.00%
8.906
0.00%
Ratio=0.2 with FineTuning
16.54
35.02
112.3
112.3
67.25%
9.212
3.44%
Ratio=0.25 with FineTuning
15.45
31.93
94.39
94.39
56.52%
9.405
5.60%
Ratio=0.3 with FineTuning
13.90
29.89
80.25
80.25
48.05%
9.679
8.68%
Ratio=0.35 with FineTuning
12.78
27.31
73.49
73.49
44.01%
9.835
10.43%
Ratio=0.4 with FineTuning
11.20
26.12
68.52
68.52
41.03%
10.527
18.20%
Model
Original Model
Sparsity
Pruned Model
FID
FPS
CWM
112MB
40%
40.97MB
9.504
2.92
IGM
167MB
25%
94.39MB
9.504
2.92
Optimization
CPU-FID
GPU-FID
Original Model
Quantized Model
Unquantized
9.504
9.483
135.36MB
135.36MB
Quantize CWM
9.783
9.701
40.97MB
10.85MB
Quantize IGM
10.382
10.249
94.39MB
24.10MB
Quantize CWM & IGM
11.503
11.379
135.36MB
34.95MB
img2col 优化加速
Runtimes
CorrTorch(s)
Img2Col(s)
FPS
Acceleration Rate
n=1000
147.8491
94.7902
10.81
1.5598
n=10000
1489.1325
927.4293
10.77
1.6057
Average Time
0.1488
0.029
10.79
1.6017
Y. Ge, Y. Song, R. Zhang, C. Ge, W. Liu, and P. Luo, "Parser-Free Virtual Try-on via Distilling Appearance Flows," arXiv preprint arXiv:2103.04559, 2021.
Y. Cheng, D. Wang, P. Zhou and T. Zhang, "Model Compression and Acceleration for Deep Neural Networks: The Principles, Progress, and Challenges," in IEEE Signal Processing Magazine, vol. 35, no. 1, pp. 126-136, Jan. 2018, doi: 10.1109/MSP.2017.2765695.
PyTorch Quantization Aware Training