GitHub - lucas-ventura/chapter-llama: Official PyTorch implementation of the paper "Chapter-Llama: Efficient Chaptering in Hour-Long Videos with LLMs" (original) (raw)
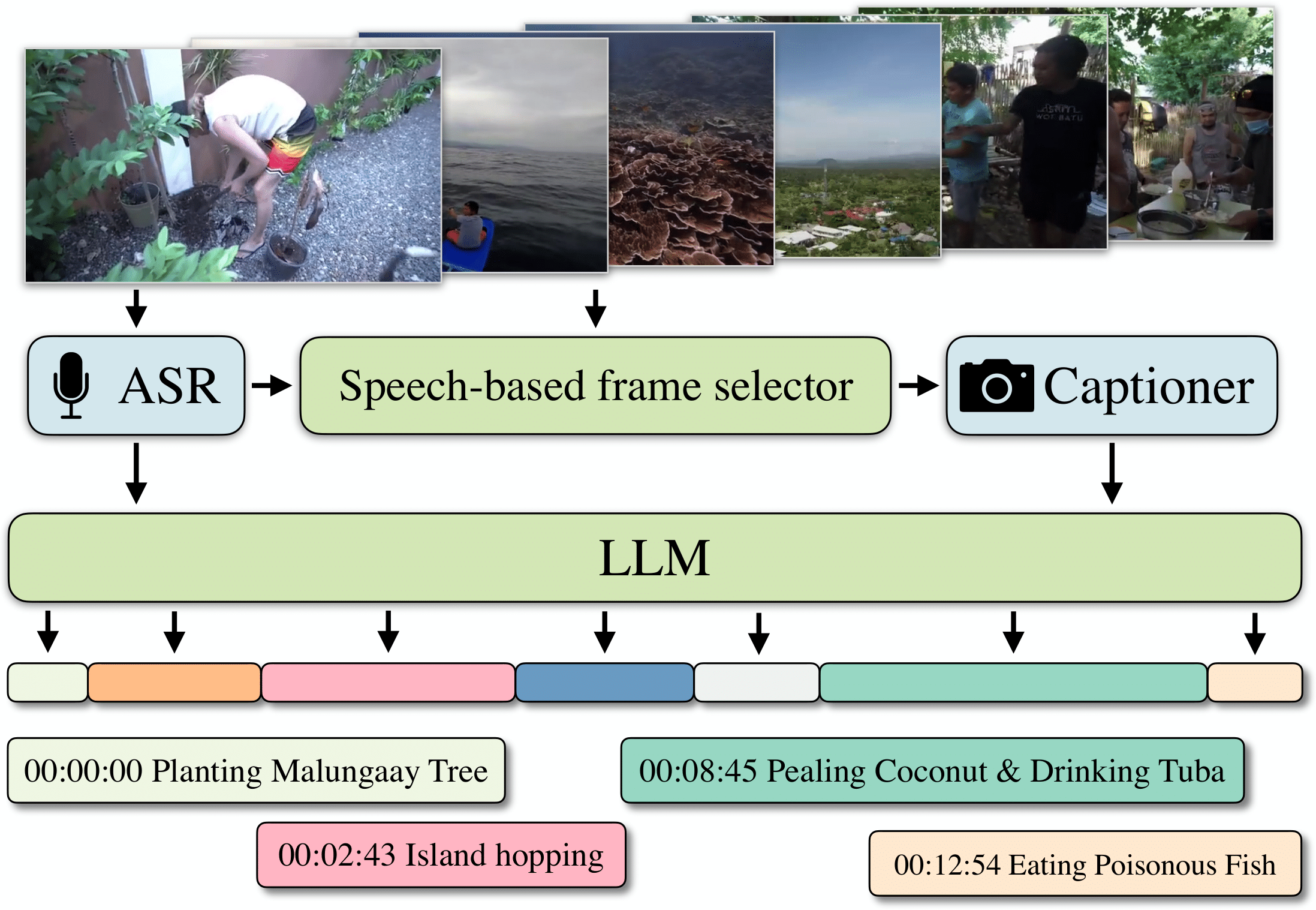
We address the task of video chaptering, i.e., partitioning a long video timeline into semantic units and generating corresponding chapter titles. While relatively underexplored, automatic chaptering has the potential to enable efficient navigation and content retrieval in long-form videos. In this paper, we achieve strong chaptering performance on hour-long videos by efficiently addressing the problem in the text domain with our 'Chapter-Llama' framework. Specifically, we leverage a pretrained large language model (LLM) with large context window, and feed as input (i) speech transcripts and (ii) captions describing video frames, along with their respective timestamps. Given the inefficiency of exhaustively captioning all frames, we propose a lightweight speech-guided frame selection strategy based on speech transcript content, and experimentally demonstrate remarkable advantages. We train the LLM to output timestamps for the chapter boundaries, as well as free-form chapter titles. This simple yet powerful approach scales to processing one-hour long videos in a single forward pass. Our results demonstrate substantial improvements (e.g., 45.3 vs 26.7 F1 score) over the state of the art on the recent VidChapters-7M benchmark. To promote further research, we release our code and models.
Description
This repository contains the code for the paper "Chapter-Llama: Efficient Chaptering in Hour-Long Videos with LLMs" (CVPR 2025).
Please visit our webpage for more details.
Project Structure
📦 chapter-llama/
├── 📂 configs/ # Hydra configuration files
│ ├── 📂 data/ # Data loading configurations
│ │ ├── asr.yaml # ASR-only data loading
│ │ ├── captions.yaml # Captions-only data loading
│ │ ├── ...
│ │ └── captions_asr.yaml # Combined captions and ASR
│ ├── 📂 experiment/ # Experiment-specific configs
│ ├── 📂 model/ # Model architectures and parameters
│ ├── 📄 test.yaml # Test configuration
│ └── 📄 train.yaml # Main training configuration
├── 📂 src/
│ ├── 📂 data/
│ ├── 📂 models/
│ ├── 📂 test/
│ └── 📂 utils/
├── 📂 tools/
│ ├── 📂 captions/ # Caption extraction
│ ├── 📂 download/ # Download data (captions, docs, models, ids)
│ ├── 📂 extract/ # Extract embeddings
│ ├── 📂 results/ # Visualize results
│ ├── 📂 shot_detection/ # Shot detection
│ └── 📂 slurm/ # SLURM job submission
├── 🗃️ dataset/ # symlink to VidChapters dataset
├── 🗄️ outputs/ # output directory
├── 📄 inference.py # Inference script
├── 📄 test.py # Testing script
└── 📄 train.py # Main training script
Installation 👷
Create environment
conda create python=3.12 --name chapter-llama -y conda activate chapter-llama
To install the necessary packages for training and testing, you can use the provided requirements.txt file:
python -m pip install -r requirements.txt
or
python -m pip install -e .
The code was tested on Python 3.12.9 and PyTorch 2.6.0
For inference on videos that are not in the VidChapters-7M dataset, you will need to install the following dependencies to extract ASR and captions from the video (not required for training):
python -m pip install -e ".[inference]"
Download models
The Llama-3.1-8B-Instruct model will be downloaded automatically from Hugging Face, make sure you agree to the license terms here. If you already have it downloaded, please check the llama3.1_8B.yaml config file to specify the checkpoint path.
We provide 3 LoRA parameter sets for Llama-3.1-8B-Instruct:
asr-10k: Model trained with ASR from 10k videos of the VidChapters-7M dataset. Used for our Speech-based frame selector.captions_asr-10k: Model trained with Captions+ASR from 10k videos of the VidChapters-7M dataset. Used for most of our experiments.captions_asr-1k: Model trained with Captions+ASR from 1k videos of the VidChapters-7M dataset. Used for the full test set.
To download the LoRA parameter sets, run:
python tools/download/models.py "asr-1k" --local_dir "." python tools/download/models.py "asr-10k" --local_dir "." python tools/download/models.py "captions_asr-1k" --local_dir "." python tools/download/models.py "captions_asr-10k" --local_dir "."
Download captions
First, create a directory to store the data and create a symlink to it from the VidChapters directory:
mkdir path/to/VidChapters/ ln -s path/to/VidChapters/ dataset/
The dataset/captions/ directory contains the video captions organized by the captioning model used (HwwwH_MiniCPM-V-2) and the sampling method. To download the captions for our sampling method (asr_s10k-2_train_preds+no-asr-10s), run:
bash tools/download/captions.sh asr_s10k-2_train_preds+no-asr-10s
This method uses predictions from an ASR model trained on the s10k-2 subset when ASR is available for the video, and falls back to sampling frames every 10 seconds when ASR is not available. The other sampling methods available are:
bash tools/download/captions.sh 10s bash tools/download/captions.sh 100f bash tools/download/captions.sh shot_boundaries
Please refer to the how_to_extract_captions.md documentation for more details.
Download docs
The dataset/docs/ directory contains the ASR and chapter data for the VidChapters-7M dataset. We provide:
- Complete dataset: Contains 817k videos with approximately 20 GB of ASR data.
- Specific subsets used in our paper experiments (recommended for most users as it is much faster to load and download).
To download a specific subset's data (which includes video ids, ASR and chapter information), run:
bash tools/download/docs.sh subset_name
Where subset_name can be full for the complete dataset or one of the following:
Training sets:
sml1k_train: Training set with 1k videos (short+medium+long), used for ablation studies.sml10k_train: Training set with 10k videos (short+medium+long), used for Table 1 and the data scaling experiment (Figure 4).s10k-2_train: Training set with 10k videos (short), used for our Speech-based frame selector.
Validation sets:
sml300_val: Validation set with 300 videos (short+medium+long)s100_val: Validation set with 100 videos (short)m100_val: Validation set with 100 videos (medium)l100_val: Validation set with 100 videos (long)
Test sets:
s_test: Short videos (<15 min) from the test setm_test: Medium videos (15-30 min) from the test setl_test: Long videos (30-60 min) from the test settest: All videos from the test seteval: All videos from the test + validation sets
If you want to train/test with a different subset of videos, you can generate a file at dataset/docs/subset_data/subset_name.jsonwith the video ids you want to use. The ASR and chapter data will be created automatically when calling the Chapter class.
Download videos
**Note:**Downloading videos is not necessary for training or testing since we provide the extracted captions and ASR data via Hugging Face (see commands above). This step is only required if you want to process new videos from different subsets or extract additional captions.
To download videos, install the yt-dlp library and run:
python tools/download/videos.py dataset/docs/subset_data/subset_name.json
The videos will be downloaded to dataset/videos/.
If you encounter any issues with yt-dlp, you can find the video subsets sml1k_train, sml300_val, and test on Hugging Face. Access them here: Hugging Face Datasets - lucas-ventura/chapter-llama.
Dataset structureHere's how the dataset folder should be structured:
dataset/
├── captions/
│ └── HwwwH_MiniCPM-V-2/
│ ├── 100f/
│ ├── ...
│ └── asr_s10k-2_train_preds+no-asr-10s/ # You only need this one
├── docs/
│ ├── asrs.json # Optional, ASR for the full dataset
│ ├── chapters.json # Optional, Chapter data for the full dataset
│ └── subset_data/
│ ├── sml1k_train.json # Video ids for our training subset
│ ├── asrs/
│ │ └── asrs_sml1k_train.json # ASR data for our training subset
│ ├── chapters/
│ │ └── chapters_sml1k_train.json # Chapter data for our training subset
│ └── ...
├── videos/ # Optional, for testing on new videos
└── embs/ # Optional, for embedding experiments
Usage 💻
Training and testing
The command to launch a training experiment is the following:
python train.py [OPTIONS]
or to run both train.py and test.py with the same options:
For only testing, run:
Note: You might need to run the test script with a single GPU (CUDA_VISIBLE_DEVICES=0).
Configuration
The project uses Hydra for configuration management. Key configuration options:
data: asr, captions, captions_asr, captions_asr_given_times, captions_asr_given_titles, captions_asr_windowsubset_train: Training dataset subset (default: "s1k_train")paths: To change default paths, create adefault.yamlfile inconfigs/local/and modify it as inconfigs/local/example.yamlmodel:llama3.1_8B(default),zero-shot,llama3.2_3B, etc.
For example, to run training with the sml1k_train subset with ASR only, run:
bash train.sh data=asr subset_train=sml1k_train subset_test=sml300_val
Results
To get results from a single test experiment, run:
python tools/results/evaluate_results.py path/to/experiment/test_dir --subset subset_name
For example:
python tools/results/evaluate_results.py outputs/chapterize/Meta-Llama-3.1-8B-Instruct/captions_asr/asr_s10k-2_train_preds+no-asr-10s/sml1k_train/default/test/
Additionally, you can use the tools/results/evaluate_results.ipynb notebook to compare results from different video chapter generation experiments.
Quick Start ⚡
Single Video Chaptering 📹
If you just want to generate chapters for a single video:
Clone the repository
git clone https://github.com/lucas-ventura/chapter-llama.git cd chapter-llama
Create a conda environment (optional but recommended)
conda create python=3.12 --name chapter-llama -y conda activate chapter-llama
Install the package with inference dependencies
python -m pip install -e ".[inference]"
Run the chaptering command
python inference.py /path/to/your/video.mp4
Currently, the command only uses the audio (via ASR extraction) to generate chapters. Support for automatic visual caption extraction will be added soon.
Chapters and the full output text will be saved in outputs/inference/<video_name>/.
Interactive Demo 🎮
We also provide an interactive demo where you can upload videos and visualize the generated chapters:
Clone the repository
git clone https://github.com/lucas-ventura/chapter-llama.git cd chapter-llama
Install demo dependencies
python -m pip install -e ".[demo]"
Launch the demo
python demo.py
The demo will start a local web server that you can access in your browser. You can upload videos, generate chapters, and see them visualized on the video timeline.
Citation 📝
If you use this code in your work, please cite our paper:
@InProceedings{ventura25chapter, title = {{Chapter-Llama}: Efficient Chaptering in Hour-Long Videos with {LLM}s}, author = {Lucas Ventura and Antoine Yang and Cordelia Schmid and G{"u}l Varol}, booktitle = {CVPR}, year = {2025} }
Acknowledgements
Based on llama-cookbook and lightning-hydra-template.
License 📚
This code is distributed under an MIT License.
Our models are trained using the VidChapters-7M dataset, which has its own license that must be followed. Additionally, this project depends on several third-party libraries and resources, each with their own licenses: PyTorch, Hugging Face Transformers, Hydra, Lightning, Llama models.