Guoxi Zhang (original) (raw)
I am a research scientist at the Beijing Institute for General Artificial Intelligence. Previously, I received my PhD from the Graduate School of Informatics at Kyoto University, where I was fortunate to work with Prof. Hisashi Kashima.
My research lies at the intersection of reinforcement learning, embodied AI, and robotics. I am interested in building learning systems that acquire robust and generalizable behaviors from offline data, human feedback, visual observations, and autonomous interaction.
My recent work focuses on reward learning, vision-language-guided robot learning, neuro-symbolic reinforcement learning, and reliable long-horizon memory for embodied agents.
Research Interests
Reinforcement learning, embodied AI, robot learning, reward learning, vision-language models, neuro-symbolic learning
Selected Publications
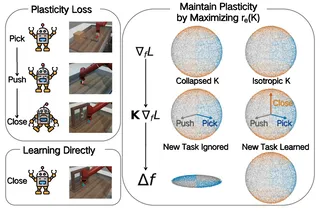
SPHERE: Mitigating the Loss of Spectral Plasticity in Mixture-of-Experts for Deep Reinforcement Learning
In Forty-Third International Conference on Machine Learning, 2026
In deep reinforcement learning (DRL), an agent is trained from a stream of experience. In a continual learning setting, such agents can suffer from plasticity loss: their ability to learn new skills from new experiences diminishes over training. Recently, Mixture-of-Experts (MoE) networks have been reported to enable scaling laws and facilitate the learning of diverse skills. However, in continual reinforcement learning settings, their performance can degenerate as learning proceeds, indicating a loss of plasticity. To address this, building on Neural Tangent Kernel (NTK) theory, we formalize the plasticity loss in MoE policies as a loss of spectral plasticity. We then derive a tractable proxy for spectral plasticity, one expressible in terms of individual expert feature matrices. Leveraging this proxy, we introduce SPHERE, a practical Parseval penalty tailored for MoE-based policies that alleviates the loss of spectral plasticity. On MetaWorld and HumanoidBench, SPHERE improves average success under continual RL by 133% and 50% over an unregularized MoE baseline, while maintaining higher spectral plasticity throughout training.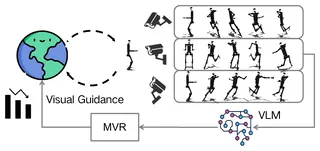
MVR: Multi-view Video Reward Shaping for Reinforcement Learning
Lirui Luo, Guoxi Zhang, Hongming Xu, Yaodong Yang, Cong Fang, and Qing Li
In The Fourteenth International Conference on Learning Representations, 2026
Reward design is of great importance for solving complex tasks with reinforcement learning. Recent studies have explored using image-text similarity produced by vision-language models (VLMs) to augment rewards of a task with visual feedback. A common practice linearly adds VLM scores to task or success rewards without explicit shaping, potentially altering the optimal policy. Moreover, such approaches, often relying on single static images, struggle with tasks whose desired behavior involves complex, dynamic motions spanning multiple visually different states. Furthermore, single viewpoints can occlude critical aspects of an agent’s behavior. To address these issues, this paper presents Multi-View Video Reward Shaping (MVR), a framework that models the relevance of states regarding the target task using videos captured from multiple viewpoints. MVR leverages video-text similarity from a frozen pre-trained VLM to learn a state relevance function that mitigates the bias towards specific static poses inherent in image-based methods. Additionally, we introduce a state-dependent reward shaping formulation that integrates task-specific rewards and VLM-based guidance, automatically reducing the influence of VLM guidance once the desired motion pattern is achieved. We confirm the efficacy of the proposed framework with extensive experiments on challenging humanoid locomotion tasks from HumanoidBench and manipulation tasks from MetaWorld, verifying the design choices through ablation studies.
SYNERGAI: Perception Alignment for Human-Robot Collaboration
Yixin Chen, Guoxi Zhang, Yaowei Zhang, Hongming Xu, Peiyuan Zhi, Qing Li, and Siyuan Huang
In 2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
Recently, large language models (LLMs) have shown strong potential in facilitating human-robotic interaction and collaboration. However, existing LLM-based systems often overlook the misalignment between human and robot perceptions, which hinders their effective communication and real-world robot deployment. To address this issue, we introduce SYNERGAI, a unified system designed to achieve both perceptual alignment and human-robot collaboration. At its core, SYNERGAI employs 3D Scene Graph (3DSG) as its explicit and innate representation. This enables the system to leverage LLM to break down complex tasks and allocate appropriate tools in intermediate steps to extract relevant information from the 3DSG, modify its structure, or generate responses. Importantly, SYNERGAI incorporates an automatic mechanism that enables perceptual misalignment correction with users by updating its 3DSG with online interaction. SYNERGAI achieves comparable performance with the data-driven models in ScanQA in a zero-shot manner. Through comprehensive experiments across 10 real-world scenes, SYNERGAI demonstrates its effectiveness in establishing common ground with humans, realizing a success rate of 61.9% in alignment tasks. It also significantly improves the success rate from 3.7% to 45.68% on novel tasks by transferring the knowledge acquired during alignment.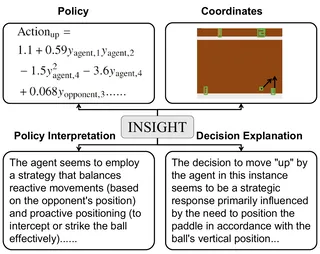
End-to-End Neuro-Symbolic Reinforcement Learning with Textual Explanations Spotlight (top 3.5%)
Lirui Luo, Guoxi Zhang, Hongming Xu, Yaodong Yang, Cong Fang, and Qing Li
In Proceedings of the Forty-First International Conference on Machine Learning, 2024
Neuro-symbolic reinforcement learning (NS-RL) has emerged as a promising paradigm for explainable decision-making, characterized by the interpretability of symbolic policies. NS-RL entails structured state representations for tasks with visual observations, but previous methods cannot refine the structured states with rewards due to a lack of efficiency. Accessibility also remains an issue, as extensive domain knowledge is required to interpret symbolic policies. In this paper, we present a neuro-symbolic framework for jointly learning structured states and symbolic policies, whose key idea is to distill the vision foundation model into an efficient perception module and refine it during policy learning. Moreover, we design a pipeline to prompt GPT-4 to generate textual explanations for the learned policies and decisions, significantly reducing users’ cognitive load to understand the symbolic policies. We verify the efficacy of our approach on nine Atari tasks and present GPT-generated explanations for policies and decisions.