Mixtral (original) (raw)
Overview
Mixtral-8x7B was introduced in the Mixtral of Experts blogpost by Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
The introduction of the blog post says:
Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts models (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.
Mixtral-8x7B is the second large language model (LLM) released by mistral.ai, after Mistral-7B.
Architectural details
Mixtral-8x7B is a decoder-only Transformer with the following architectural choices:
- Mixtral is a Mixture of Experts (MoE) model with 8 experts per MLP, with a total of 45 billion parameters. To learn more about mixture-of-experts, refer to the blog post.
- Despite the model having 45 billion parameters, the compute required for a single forward pass is the same as that of a 14 billion parameter model. This is because even though each of the experts have to be loaded in RAM (70B like ram requirement) each token from the hidden states are dispatched twice (top 2 routing) and thus the compute (the operation required at each forward computation) is just 2 X sequence_length.
The following implementation details are shared with Mistral AI’s first model Mistral-7B:
- Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
- GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
- Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
For more details refer to the release blog post.
License
Mixtral-8x7B is released under the Apache 2.0 license.
Usage tips
The Mistral team has released 2 checkpoints:
- a base model, Mixtral-8x7B-v0.1, which has been pre-trained to predict the next token on internet-scale data.
- an instruction tuned model, Mixtral-8x7B-Instruct-v0.1, which is the base model optimized for chat purposes using supervised fine-tuning (SFT) and direct preference optimization (DPO).
The base model can be used as follows:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", device_map="auto") tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
prompt = "My favourite condiment is"
model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda") model.to(device)
generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True) tokenizer.batch_decode(generated_ids)[0] "My favourite condiment is to ..."
The instruction tuned model can be used as follows:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1", device_map="auto") tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
messages = [ ... {"role": "user", "content": "What is your favourite condiment?"}, ... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"}, ... {"role": "user", "content": "Do you have mayonnaise recipes?"} ... ]
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True) tokenizer.batch_decode(generated_ids)[0] "Mayonnaise can be made as follows: (...)"
As can be seen, the instruction-tuned model requires a chat template to be applied to make sure the inputs are prepared in the right format.
Speeding up Mixtral by using Flash Attention
The code snippets above showcase inference without any optimization tricks. However, one can drastically speed up the model by leveraging Flash Attention, which is a faster implementation of the attention mechanism used inside the model.
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
pip install -U flash-attn --no-build-isolation
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the flash attention repository. Make also sure to load your model in half-precision (e.g. torch.float16)
To load and run a model using Flash Attention-2, refer to the snippet below:
import torch from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2", device_map="auto") tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
prompt = "My favourite condiment is"
model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda") model.to(device)
generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True) tokenizer.batch_decode(generated_ids)[0] "The expected output"
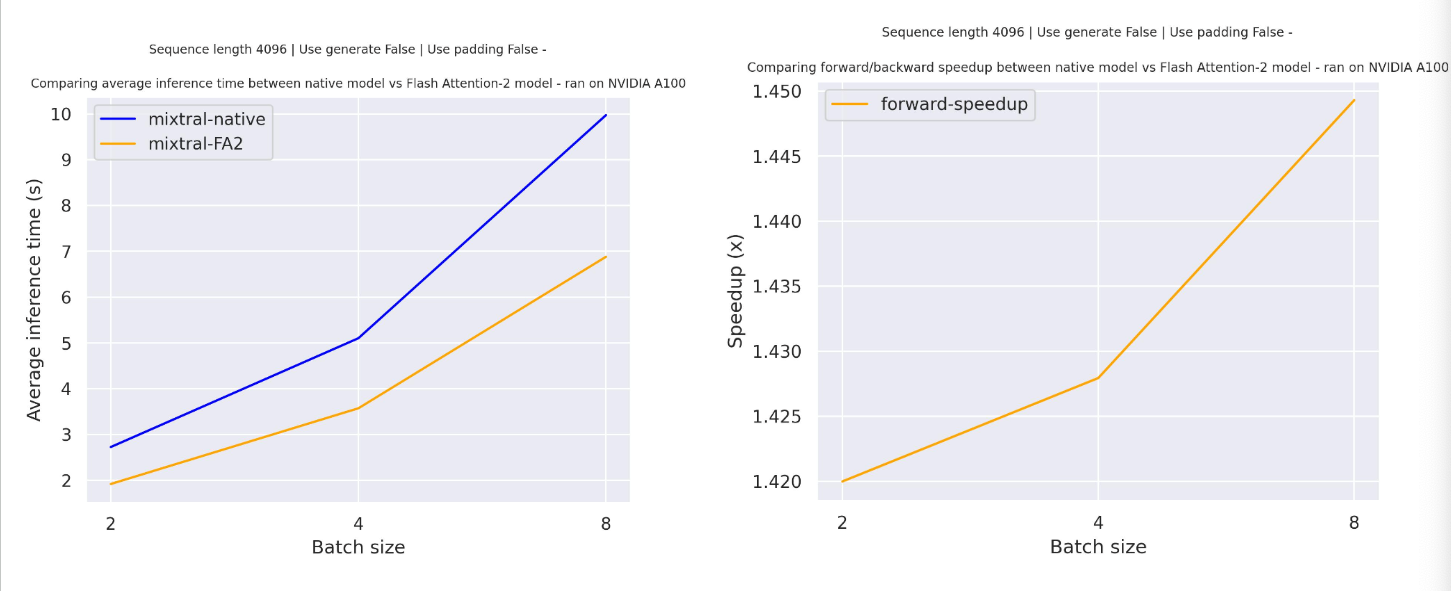
Expected speedups
Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using mistralai/Mixtral-8x7B-v0.1 checkpoint and the Flash Attention 2 version of the model.
Sliding window Attention
The current implementation supports the sliding window attention mechanism and memory efficient cache management. To enable sliding window attention, just make sure to have a flash-attn version that is compatible with sliding window attention (>=2.3.0).
The Flash Attention-2 model uses also a more memory efficient cache slicing mechanism - as recommended per the official implementation of Mistral model that use rolling cache mechanism we keep the cache size fixed (self.config.sliding_window), support batched generation only for padding_side="left" and use the absolute position of the current token to compute the positional embedding.
Shrinking down Mixtral using quantization
As the Mixtral model has 45 billion parameters, that would require about 90GB of GPU RAM in half precision (float16), since each parameter is stored in 2 bytes. However, one can shrink down the size of the model using quantization. If the model is quantized to 4 bits (or half a byte per parameter), a single A100 with 40GB of RAM is enough to fit the entire model, as in that case only about 27 GB of RAM is required.
Quantizing a model is as simple as passing a quantization_config to the model. Below, we’ll leverage the bitsandbytes quantization library (but refer to this page for alternative quantization methods):
import torch from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig( ... load_in_4bit=True, ... bnb_4bit_quant_type="nf4", ... bnb_4bit_compute_dtype="torch.float16", ... )
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1", quantization_config=True, device_map="auto") tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = "My favourite condiment is"
messages = [ ... {"role": "user", "content": "What is your favourite condiment?"}, ... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"}, ... {"role": "user", "content": "Do you have mayonnaise recipes?"} ... ]
model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True) tokenizer.batch_decode(generated_ids)[0] "The expected output"
This model was contributed by Younes Belkada and Arthur Zucker . The original code can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mixtral. If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A demo notebook to perform supervised fine-tuning (SFT) of Mixtral-8x7B can be found here. 🌎
- A blog post on fine-tuning Mixtral-8x7B using PEFT. 🌎
- The Alignment Handbook by Hugging Face includes scripts and recipes to perform supervised fine-tuning (SFT) and direct preference optimization with Mistral-7B. This includes scripts for full fine-tuning, QLoRa on a single GPU as well as multi-GPU fine-tuning.
- Causal language modeling task guide
MixtralConfig
class transformers.MixtralConfig
( vocab_size = 32000 hidden_size = 4096 intermediate_size = 14336 num_hidden_layers = 32 num_attention_heads = 32 num_key_value_heads = 8 head_dim = None hidden_act = 'silu' max_position_embeddings = 131072 initializer_range = 0.02 rms_norm_eps = 1e-05 use_cache = True pad_token_id = None bos_token_id = 1 eos_token_id = 2 tie_word_embeddings = False rope_theta = 1000000.0 sliding_window = None attention_dropout = 0.0 num_experts_per_tok = 2 num_local_experts = 8 output_router_logits = False router_aux_loss_coef = 0.001 router_jitter_noise = 0.0 **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 32000) — Vocabulary size of the Mixtral model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling MixtralModel - hidden_size (
int, optional, defaults to 4096) — Dimension of the hidden representations. - intermediate_size (
int, optional, defaults to 14336) — Dimension of the MLP representations. - num_hidden_layers (
int, optional, defaults to 32) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 32) — Number of attention heads for each attention layer in the Transformer encoder. - num_key_value_heads (
int, optional, defaults to 8) — This is the number of key_value heads that should be used to implement Grouped Query Attention. Ifnum_key_value_heads=num_attention_heads, the model will use Multi Head Attention (MHA), ifnum_key_value_heads=1the model will use Multi Query Attention (MQA) otherwise GQA is used. When converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed by meanpooling all the original heads within that group. For more details, check out this paper. If it is not specified, will default to8. - head_dim (
int, optional, defaults tohidden_size // num_attention_heads) — The attention head dimension. - hidden_act (
strorfunction, optional, defaults to"silu") — The non-linear activation function (function or string) in the decoder. - max_position_embeddings (
int, optional, defaults to4096*32) — The maximum sequence length that this model might ever be used with. Mixtral’s sliding window attention allows sequence of up to 4096*32 tokens. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - rms_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the rms normalization layers. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). Only relevant ifconfig.is_decoder=True. - pad_token_id (
int, optional) — The id of the padding token. - bos_token_id (
int, optional, defaults to 1) — The id of the “beginning-of-sequence” token. - eos_token_id (
int, optional, defaults to 2) — The id of the “end-of-sequence” token. - tie_word_embeddings (
bool, optional, defaults toFalse) — Whether the model’s input and output word embeddings should be tied. - rope_theta (
float, optional, defaults to 1000000.0) — The base period of the RoPE embeddings. - sliding_window (
int, optional) — Sliding window attention window size. If not specified, will default to4096. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - num_experts_per_tok (
int, optional, defaults to 2) — The number of experts to route per-token, can be also interpreted as thetop-krouting parameter - num_local_experts (
int, optional, defaults to 8) — Number of experts per Sparse MLP layer. - output_router_logits (
bool, optional, defaults toFalse) — Whether or not the router logits should be returned by the model. Enabling this will also allow the model to output the auxiliary loss. See here for more details - router_aux_loss_coef (
float, optional, defaults to 0.001) — The aux loss factor for the total loss. - router_jitter_noise (
float, optional, defaults to 0.0) — Amount of noise to add to the router.
This is the configuration class to store the configuration of a MixtralModel. It is used to instantiate an Mixtral model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Mixtral-7B-v0.1 or Mixtral-7B-Instruct-v0.1.
mixtralai/Mixtral-8x7B mixtralai/Mixtral-7B-Instruct-v0.1
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
from transformers import MixtralModel, MixtralConfig
configuration = MixtralConfig()
model = MixtralModel(configuration)
configuration = model.config
MixtralModel
class transformers.MixtralModel
( config: MixtralConfig )
Parameters
- config (MixtralConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out thefrom_pretrained() method to load the model weights.
The bare Mixtral Model outputting raw hidden-states without any specific head on top.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[list[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None output_router_logits: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None **flash_attn_kwargs: typing_extensions.Unpack[transformers.modeling_flash_attention_utils.FlashAttentionKwargs] ) → transformers.modeling_outputs.MoeModelOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() andPreTrainedTokenizer.call() for details.
What are input IDs? - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
What are attention masks?
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1].
What are position IDs? - past_key_values (
list[torch.FloatTensor], optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.
Two formats are allowed:- a Cache instance, see our kv cache guide;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If nopast_key_valuesare passed, the legacy cache format will be returned.
Ifpast_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length).
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - output_router_logits (
bool, optional) — Whether or not to return the logits of all the routers. They are useful for computing the router loss, and should not be returned during inference. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length.
Returns
transformers.modeling_outputs.MoeModelOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.MoeModelOutputWithPast or a tuple oftorch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the configuration (MixtralConfig) and inputs.
- last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. - past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.
Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally ifconfig.is_encoder_decoder=Truein the cross-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. - router_logits (
tuple(torch.FloatTensor), optional, returned whenoutput_router_probs=Trueandconfig.add_router_probs=Trueis passed or whenconfig.output_router_probs=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, sequence_length, num_experts).
Raw router logtis (post-softmax) that are computed by MoE routers, these terms are used to compute the auxiliary loss for Mixture of Experts models.
The MixtralModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
MixtralForCausalLM
class transformers.MixtralForCausalLM
( config )
Parameters
- config (MixtralForCausalLM) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out thefrom_pretrained() method to load the model weights.
The Mixtral Model for causal language modeling.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[list[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None output_router_logits: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None logits_to_keep: typing.Union[int, torch.Tensor] = 0 **kwargs: typing_extensions.Unpack[transformers.models.mixtral.modeling_mixtral.KwargsForCausalLM] ) → transformers.modeling_outputs.MoeCausalLMOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() andPreTrainedTokenizer.call() for details.
What are input IDs? - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
What are attention masks?
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1].
What are position IDs? - past_key_values (
list[torch.FloatTensor], optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.
Two formats are allowed:- a Cache instance, see our kv cache guide;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If nopast_key_valuesare passed, the legacy cache format will be returned.
Ifpast_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length).
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - output_router_logits (
bool, optional) — Whether or not to return the logits of all the routers. They are useful for computing the router loss, and should not be returned during inference. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length. - logits_to_keep (
Union[int, torch.Tensor], defaults to0) — If anint, compute logits for the lastlogits_to_keeptokens. If0, calculate logits for allinput_ids(special case). Only last token logits are needed for generation, and calculating them only for that token can save memory, which becomes pretty significant for long sequences or large vocabulary size. If atorch.Tensor, must be 1D corresponding to the indices to keep in the sequence length dimension. This is useful when using packed tensor format (single dimension for batch and sequence length).
Returns
transformers.modeling_outputs.MoeCausalLMOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.MoeCausalLMOutputWithPast or a tuple oftorch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the configuration (MixtralConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). - logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). - aux_loss (
torch.FloatTensor, optional, returned whenlabelsis provided) — aux_loss for the sparse modules. - router_logits (
tuple(torch.FloatTensor), optional, returned whenoutput_router_probs=Trueandconfig.add_router_probs=Trueis passed or whenconfig.output_router_probs=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, sequence_length, num_experts).
Raw router logtis (post-softmax) that are computed by MoE routers, these terms are used to compute the auxiliary loss for Mixture of Experts models. - past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The MixtralForCausalLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
from transformers import AutoTokenizer, MixtralForCausalLM
model = MixtralForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1") tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
prompt = "Hey, are you conscious? Can you talk to me?" inputs = tokenizer(prompt, return_tensors="pt")
generate_ids = model.generate(inputs.input_ids, max_length=30) tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0] "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
MixtralForSequenceClassification
class transformers.MixtralForSequenceClassification
( config )
Parameters
- config (MixtralForSequenceClassification) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out thefrom_pretrained() method to load the model weights.
The Mixtral Model transformer with a sequence classification head on top (linear layer).
MixtralForSequenceClassification uses the last token in order to do the classification, as other causal models (e.g. GPT-2) do.
Since it does classification on the last token, it requires to know the position of the last token. If apad_token_id is defined in the configuration, it finds the last token that is not a padding token in each row. If no pad_token_id is defined, it simply takes the last value in each row of the batch. Since it cannot guess the padding tokens when inputs_embeds are passed instead of input_ids, it does the same (take the last value in each row of the batch).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() andPreTrainedTokenizer.call() for details.
What are input IDs? - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
What are attention masks?
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1].
What are position IDs? - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.
Two formats are allowed:- a Cache instance, see our kv cache guide;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If nopast_key_valuesare passed, the legacy cache format will be returned.
Ifpast_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length).
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy). - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail.
Returns
transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutputWithPast or a tuple oftorch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the configuration (MixtralConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The MixtralForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example of single-label classification:
import torch from transformers import AutoTokenizer, MixtralForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("mixtralai/Mixtral-8x7B") model = MixtralForSequenceClassification.from_pretrained("mixtralai/Mixtral-8x7B")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
with torch.no_grad(): ... logits = model(**inputs).logits
predicted_class_id = logits.argmax().item() model.config.id2label[predicted_class_id] ...
num_labels = len(model.config.id2label) model = MixtralForSequenceClassification.from_pretrained("mixtralai/Mixtral-8x7B", num_labels=num_labels)
labels = torch.tensor([1]) loss = model(**inputs, labels=labels).loss round(loss.item(), 2) ...
Example of multi-label classification:
import torch from transformers import AutoTokenizer, MixtralForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("mixtralai/Mixtral-8x7B") model = MixtralForSequenceClassification.from_pretrained("mixtralai/Mixtral-8x7B", problem_type="multi_label_classification")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
with torch.no_grad(): ... logits = model(**inputs).logits
predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
num_labels = len(model.config.id2label) model = MixtralForSequenceClassification.from_pretrained( ... "mixtralai/Mixtral-8x7B", num_labels=num_labels, problem_type="multi_label_classification" ... )
labels = torch.sum( ... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1 ... ).to(torch.float) loss = model(**inputs, labels=labels).loss
MixtralForTokenClassification
class transformers.MixtralForTokenClassification
( config )
Parameters
- config (MixtralForTokenClassification) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out thefrom_pretrained() method to load the model weights.
The Mixtral transformer with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() andPreTrainedTokenizer.call() for details.
What are input IDs? - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
What are attention masks?
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1].
What are position IDs? - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.
Two formats are allowed:- a Cache instance, see our kv cache guide;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If nopast_key_valuesare passed, the legacy cache format will be returned.
Ifpast_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length).
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy). - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail.
A transformers.modeling_outputs.TokenClassifierOutput or a tuple oftorch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the configuration (MixtralConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification loss. - logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels)) — Classification scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The MixtralForTokenClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
from transformers import AutoTokenizer, MixtralForTokenClassification import torch
tokenizer = AutoTokenizer.from_pretrained("mixtralai/Mixtral-8x7B") model = MixtralForTokenClassification.from_pretrained("mixtralai/Mixtral-8x7B")
inputs = tokenizer( ... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt" ... )
with torch.no_grad(): ... logits = model(**inputs).logits
predicted_token_class_ids = logits.argmax(-1)
predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]] predicted_tokens_classes ...
labels = predicted_token_class_ids loss = model(**inputs, labels=labels).loss round(loss.item(), 2) ...
MixtralForQuestionAnswering
class transformers.MixtralForQuestionAnswering
( config )
Parameters
- config (MixtralForQuestionAnswering) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out thefrom_pretrained() method to load the model weights.
The Mixtral transformer with a span classification head on top for extractive question-answering tasks like SQuAD (a linear layer on top of the hidden-states output to compute span start logits and span end logits).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Union[list[torch.FloatTensor], transformers.cache_utils.Cache, NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None start_positions: typing.Optional[torch.LongTensor] = None end_positions: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None **kwargs ) → transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() andPreTrainedTokenizer.call() for details.
What are input IDs? - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
What are attention masks?
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1].
What are position IDs? - past_key_values (
Union[list[torch.FloatTensor], ~cache_utils.Cache, NoneType]) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.
Two formats are allowed:- a Cache instance, see our kv cache guide;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If nopast_key_valuesare passed, the legacy cache format will be returned.
Ifpast_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length).
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - start_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the start of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss. - end_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the end of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail.
A transformers.modeling_outputs.QuestionAnsweringModelOutput or a tuple oftorch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the configuration (MixtralConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Total span extraction loss is the sum of a Cross-Entropy for the start and end positions. - start_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-start scores (before SoftMax). - end_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-end scores (before SoftMax). - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The MixtralForQuestionAnswering forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
from transformers import AutoTokenizer, MixtralForQuestionAnswering import torch
tokenizer = AutoTokenizer.from_pretrained("mixtralai/Mixtral-8x7B") model = MixtralForQuestionAnswering.from_pretrained("mixtralai/Mixtral-8x7B")
question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
inputs = tokenizer(question, text, return_tensors="pt") with torch.no_grad(): ... outputs = model(**inputs)
answer_start_index = outputs.start_logits.argmax() answer_end_index = outputs.end_logits.argmax()
predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1] tokenizer.decode(predict_answer_tokens, skip_special_tokens=True) ...
target_start_index = torch.tensor([14]) target_end_index = torch.tensor([15])
outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index) loss = outputs.loss round(loss.item(), 2) ...